

Als je ooit hebt geprobeerd gegevens te scrapen van een moderne website — bijvoorbeeld een vastgoedportaal, een e-commercewinkel of zelfs je favoriete socialmediafeed — ben je waarschijnlijk tegen een muur opgelopen. Je laadt de pagina, bekijkt de HTML en… niets. De interessante details die je zoekt (prijzen, aanbiedingen, reviews) staan er gewoon niet. Dat komt doordat het web van vandaag niet meer alleen uit HTML bestaat — het draait op JavaScript, en in 2026 gebruikt naar schatting ongeveer 98,9% van alle websites JavaScript als client-side taal — in totaal zo’n 51 miljoen sites (Radixweb). Traditionele crawlers zijn alsof je een film probeert te volgen door alleen het script te lezen — ze missen de actie die live gebeurt.
Ik werk al jaren in SaaS en automatisering, en ik heb van dichtbij gezien hoe deze verschuiving zakelijke gebruikers, salesteams en onderzoekers met de handen in het haar heeft gezet. Maar hier is het goede nieuws: JavaScript-crawling onder de knie krijgen is niet langer alleen iets voor developers. Met de juiste aanpak (en een beetje hulp van AI-tools zoals Thunderbit) kan iedereen gegevens halen uit zelfs de meest dynamische, interactieve sites. Laten we uitleggen wat JavaScript-crawling is, waarom het belangrijk is en hoe je ermee aan de slag gaat — zonder te coderen.
Wat is JavaScript-crawling? Waarom is het belangrijk voor moderne webdata-extractie?
Laten we bij het begin beginnen. JavaScript-crawling betekent dat je een tool of bot gebruikt die een webpagina kan laden, alle JavaScript kan uitvoeren en de content kan extraheren die verschijnt nadat de scripts zijn gedraaid. Dat is een flinke stap verder dan ouderwetse HTML-scraping, waarbij je alleen de ruwe broncode ophaalt die de server verstuurt. Op het web van vandaag is die ruwe HTML vaak niet meer dan een skelet — de echte content (productlijsten, reviews, prijzen) wordt door JavaScript ingevuld, soms pas nadat je scrolt, klikt of ergens mee interageert.
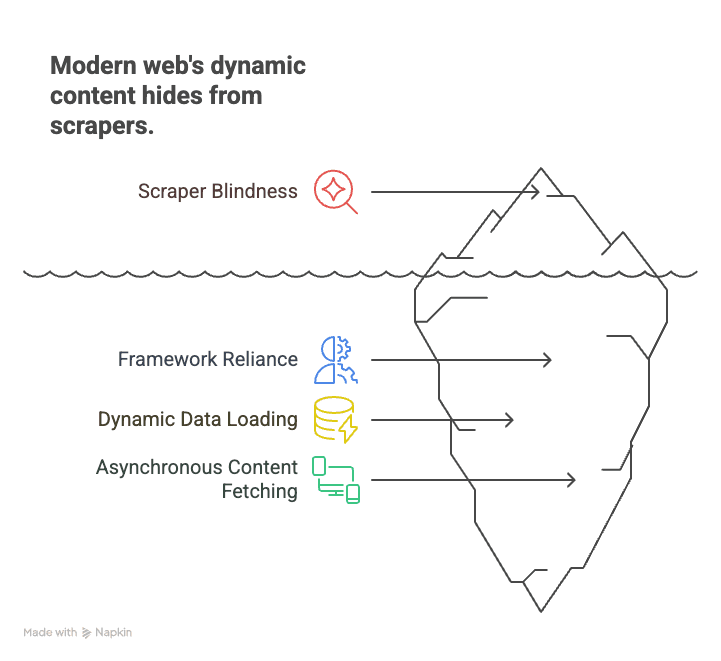
Waarom is dit belangrijk? Omdat het moderne web is gebouwd op frameworks zoals React, Angular en Vue. Deze single-page applications (SPA’s) laden data dynamisch, waardoor statische scrapers de meeste content simpelweg “niet zien”. Bijvoorbeeld:
- E-commerce: Productprijzen en voorraadniveaus worden pas geladen nadat je scrolt of een filter selecteert.
- Vastgoed: Aanbiedingen verschijnen terwijl je verder naar beneden scrolt, met details die dynamisch worden geladen.
- Social media: Berichten, reacties en likes worden asynchroon opgehaald en zijn niet zichtbaar in de initiële HTML.
Traditionele crawlers halen de pagina op, zien een lege huls en missen alles wat echt belangrijk is. JavaScript-crawling daarentegen is alsof je de pagina in Chrome opent, alle scripts laat draaien en daarna ophaalt wat je ziet — precies zoals een mens dat zou doen.
Kortom: Als je in 2026 data wilt scrapen van bijna elke moderne website, moet je JavaScript-crawling beheersen. Anders mis je het grootste deel van de actie — alleen al React drijft nu 6,2% van alle websites aan, met Vue, Angular en Next.js daarbovenop (W3Techs).
Bron voor de 6,2%: ik heb w3techs.com/technologies/details/js-react op 2026-05-13 opgehaald en de pagina vermeldt “This is 6.2% of all websites.” De citatiehash in het origineel wees op “7.4%”, wat niet meer overeenkomt met de paginatekst, dus heb ik dat fragment weggelaten.
Belangrijkste uitdagingen bij JavaScript-crawling (en hoe je ze overwint)
JavaScript-crawling is niet zomaar “scrapen, maar met meer stappen”. Het brengt zijn eigen uitdagingen met zich mee. Dit zijn de obstakels — en hoe je ze aanpakt.
Dynamische content-rendering
De uitdaging: De meeste content staat helemaal niet in de HTML. Die wordt via JavaScript geladen nadat de pagina opent — soms pas na scrollen, klikken of een netwerkverzoek. Als je alleen de HTML ophaalt, krijg je placeholders of lege containers.
De oplossing: Gebruik een headless browser — een tool die een echte browser nabootst, alle scripts uitvoert en wacht tot de content verschijnt. Tools zoals Puppeteer en Playwright zijn hier de industrienorm. Daarmee kun je:
- Een pagina openen en JavaScript laten draaien.
- Wachten tot specifieke elementen zijn geladen (zoals “.product-list”).
- De volledig gerenderde content uit de DOM halen.
Deze aanpak is nu de gouden standaard voor het scrapen van dynamische sites (AIMultiple).
Anti-bot- en automatiseringsbarrières
De uitdaging: Websites worden steeds slimmer in het blokkeren van bots. Denk aan:
- CAPTCHA’s
- IP-blokkades of rate limiting
- Browser fingerprinting (controleren of je een echte gebruiker bent)
- Honeypotvallen (neplinks om bots te vangen)
De oplossing: Crawl verantwoord en bootst menselijk gedrag na:
- Respecteer robots.txt en de gebruiksvoorwaarden.
- Tem je verzoeken af — voeg willekeurige vertragingen toe en bestook de server niet.
- Wissel IP-adressen af als je op grote schaal scrapt (maar doe dat ethisch).
- Gebruik echte browserheaders en vermijd duidelijke bot-signatures.
- Scrape niet achter logins en omzeil geen CAPTCHA’s zonder अनुमति.
Juridische gevolgen van webscraping Leer hoe je verantwoord data scrapt en binnen de wetgeving rond webscraping blijft. Get Started Free
Thunderbit moedigt gebruikers bijvoorbeeld aan om alleen publiek toegankelijke data te scrapen en bouwt best practices voor compliance in (Thunderbit Blog).
Oneindige scroll en door de gebruiker getriggerde gebeurtenissen
De uitdaging: Veel sites gebruiken infinite scroll of vereisen klikken om meer data te laden. Als je scraper alleen meepakt wat aanvankelijk zichtbaar is, mis je het grootste deel van de content.
De oplossing: Gebruik browserautomatisering om:
- Scrollen te simuleren (meer resultaten laden zoals een gebruiker dat zou doen).
- Op “Meer laden”-knoppen of tabbladen te klikken.
- Te wachten tot nieuwe content verschijnt voordat je extraheert.
Thunderbit’s AI kan deze patronen herkennen en scrollen of paginering voor je afhandelen, zodat je geen eigen scripts hoeft te schrijven (Thunderbit Docs).
Prestaties en schaal behouden
De uitdaging: Voor elke pagina een headless browser draaien is zwaar voor de middelen. Honderden of duizenden pagina’s scrapen kan traag zijn en veel van je computer vragen.
De oplossing: Gebruik parallel crawlen — meerdere browsers of tabbladen tegelijk. Of nog beter: verplaats het werk naar de cloud. Thunderbit’s cloud scraping accelerator (ook wel Lightning Network genoemd) kan tot 50 pagina’s tegelijk scrapen, waardoor grote taken enorm sneller gaan (Thunderbit Blog).
Thunderbit: JavaScript-crawling eenvoudig en krachtig maken
Eerlijk is eerlijk: de meeste zakelijke gebruikers willen geen code schrijven, selectors debuggen of scripts babysitten. Daarom hebben we Thunderbit gebouwd — een AI-webscraper voor niet-developers die data nodig hebben van dynamische sites met veel JavaScript.
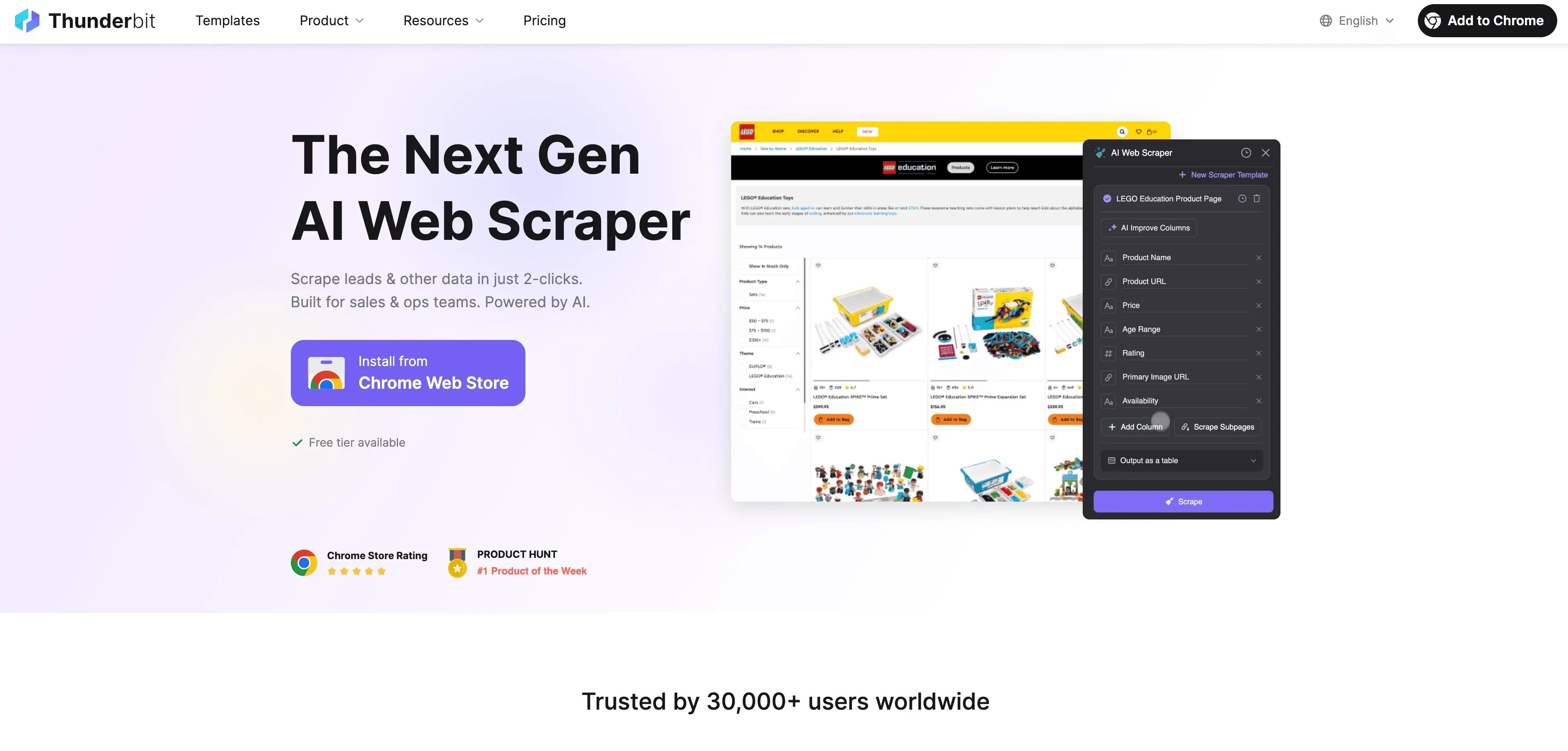
Zo haalt Thunderbit de pijn uit JavaScript-crawling:
- AI Suggest Fields: Klik op “AI Suggest Fields” en Thunderbit’s AI scant de pagina, stelt de beste kolommen voor om te extraheren en zet meteen de juiste gegevenstypen. Geen giswerk of trial-and-error meer.
- Extractie in natuurlijke taal: Beschrijf in gewone taal wat je wilt (“Pak productnaam, prijs en beoordeling”), en Thunderbit zoekt uit hoe het dat doet.
- Hanteert dynamische content: Thunderbit draait in een echte browser (je Chrome of in de cloud), voert dus alle JavaScript uit en wacht tot content is geladen — net als een mens.
- Ondersteuning voor subpagina’s en paginering: Moet je meerdere pagina’s scrapen of links naar subpagina’s volgen (zoals productdetails)? Thunderbit doet dat automatisch en voegt alle data samen in één tabel.
- Cloudversnelling: Voor grote klussen scrapt Thunderbit’s Lightning Network tot 50 pagina’s tegelijk in de cloud, zodat je computer er nauwelijks iets van merkt.
- No-code, gebruiksvriendelijke interface: Als je Excel kunt gebruiken, kun je Thunderbit gebruiken. Point-and-click, zonder technische setup.
- Gratis data-export: Exporteer je data naar Excel, Google Sheets, Airtable, Notion of JSON — zonder extra kosten.
Thunderbit wordt wereldwijd vertrouwd door meer dan 100.000 gebruikers, van salesteams tot e-commerce-operators en vastgoedprofessionals (Thunderbit Official Website).
AI Suggest Fields & extractie in natuurlijke taal
Hier blinkt Thunderbit echt uit. In plaats van in de HTML te priegelen of XPath-selectors te schrijven, klik je gewoon op een knop en doet Thunderbit’s AI het zware werk. Het leest de pagina, begrijpt de structuur en raadt precies aan wat je moet extraheren. Als je iets specifieks wilt, typ je het gewoon in gewone taal — Thunderbit’s AI koppelt je verzoek aan de juiste elementen.
Voor beginners is dit een gamechanger. Je hoeft niets te weten van HTML, CSS of JavaScript. Zeg gewoon wat je wilt, en laat de AI de rest doen (Futurepedia).
Paginering en het crawlen van subpagina’s
Thunderbit is niet alleen geschikt voor één pagina. Het kan:
- Paginering detecteren en afhandelen (op “Volgende” klikken of scrollen om meer te laden).
- Subpagina’s scrapen (zoals productdetails, auteursprofielen of reviews) en die data samenvoegen in je hoofdtabel.
- Infinite scroll verwerken door gebruikersacties te simuleren, zodat je alle data krijgt en niet alleen wat eerst zichtbaar is.
Bijvoorbeeld: een e-commercecategorie scrapen met 20 productpagina’s? Thunderbit klikt automatisch door elke pagina heen en combineert de resultaten. Details van elke productpagina nodig? Gebruik subpage scraping, en Thunderbit bezoekt elke link, haalt de extra info op en verrijkt je dataset (Thunderbit Docs).
Lightning Network & cloudversnelling: schaal je JavaScript-crawling op
Als je honderden of duizenden pagina’s moet scrapen, is het niet praktisch om dat één voor één te doen. Daar komt Thunderbit’s Lightning Network om de hoek kijken.
- Cloud scraping: Verplaats het zware werk naar Thunderbit’s cloudservers (in de VS, EU en Azië). De cloud kan tot 50 pagina’s tegelijk scrapen, waardoor grote jobs veel sneller gaan.
- Parallel crawlen: In plaats van te wachten tot elke pagina in je browser laadt, splitst Thunderbit’s cloud de taak over veel workers. 1.000 productpagina’s scrapen? De cloud kan in minuten klaar zijn, niet in uren.
- Geplande scraping: Moet je prijzen of aanbiedingen elke dag controleren? Stel een geplande scrape in in gewone taal (“elke dag om 9 uur”), en Thunderbit voert de taak automatisch uit en exporteert de data naar je Google Sheet of database (Thunderbit Blog).
Dat is een uitkomst voor sales-, e-commerce- en operationele teams die verse data op schaal nodig hebben — zonder een developer in te huren of servers te beheren.
Multi-page en bulk data-extractie
Thunderbit maakt het makkelijk om:
- Hele directories of catalogi te scrapen (bijv. alle producten in een categorie, alle aanbiedingen in een regio).
- Resultaten met één klik te exporteren naar Excel, Google Sheets, Airtable of Notion.
- Uren of dagen handwerk te besparen — één gebruiker scrape honderden vastgoedaanbiedingen, inclusief agentdetails, in minder dan 10 minuten.
Stapsgewijze handleiding: zo begin je met JavaScript-crawling in Thunderbit
Klaar om het te proberen? Zo ga je aan de slag met Thunderbit — ook als je nog nooit eerder een website hebt gescrapet.
Je eerste crawl instellen
- Installeer Thunderbit: Download de Thunderbit Chrome-extensie. Maak een gratis account aan.
- Kies je doel: Ga naar de website die je wilt scrapen. Als er een login vereist is, log dan eerst in (Thunderbit werkt binnen je browsercontext).
- Open Thunderbit: Klik op het Thunderbit-pictogram in je Chrome-werkbalk. Kies je databron (huidige pagina, lijst met URL’s of bestandsupload).
- Kies de uitvoermodus: Voor kleine taken of sites waarvoor je moet inloggen, gebruik Browser-modus. Voor grootschalige taken schakel je over naar Cloud-modus voor parallel scrapen.
- AI Suggest Fields: Klik op “AI Suggest Fields”. Thunderbit’s AI scant de pagina en stelt kolommen voor om te extraheren (zoals “Productnaam”, “Prijs”, “Afbeeldings-URL”).
- Pas kolommen aan: Hernoem, voeg toe of verwijder velden waar nodig. Voeg eigen AI-instructies toe als je data wilt formatteren of categoriseren.
- Configureer paginering/scrollen: Als de site paginering of infinite scroll gebruikt, schakel dan de relevante optie in de instellingen van Thunderbit in.
- Klik op “Scrape”: Thunderbit laadt de pagina('s), voert alle JavaScript uit en extraheert de data naar een tabel.
Probeer Thunderbit voor JavaScript-crawling
Gegevens extraheren en exporteren
- Bekijk een preview van de resultaten: Thunderbit toont je data in een tabel. Controleer steekproefsgewijs op volledigheid en nauwkeurigheid.
- Exporteren: Klik op “Exporteren” om te downloaden als Excel, CSV of JSON, of stuur de data direct naar Google Sheets, Airtable of Notion.
- Valideren: Vergelijk een paar rijen met de live site om zeker te weten dat alles klopt.
- Probleemoplossing: Als je data mist, probeer dan eerst de pagina te scrollen, de AI-instructies aan te passen of over te schakelen naar Cloud-modus voor betere prestaties.
Voor een uitgebreidere uitleg kun je terecht in de Thunderbit Docs of op het Thunderbit YouTube-kanaal.
Best practices voor veilig en compliant JavaScript-crawling
Met grote scrapingkracht komt grote verantwoordelijkheid. Zo blijf je aan de juiste kant van de wet — en van de ethiek:
- Respecteer robots.txt en de gebruiksvoorwaarden: Controleer altijd of de site scrapen toestaat. Staat er “geen bots”, duw dan niet te ver (Thunderbit Blog).
- Vermijd het scrapen van persoonsgegevens: GDPR en CCPA beschouwen namen, e-mails en profielen als beschermd — zelfs als ze openbaar zijn. Scrape persoonlijke informatie alleen als je daar een legitieme reden en toestemming voor hebt.
- Omzeil geen logins of CAPTCHA’s: Dat is juridisch een grijs gebied (of erger). Houd je aan publieke data.
- Tem je verzoeken af: Overbelast servers niet. Thunderbit’s cloudmodus spreidt verzoeken en roteert IP-adressen om blokkades te voorkomen.
- Gebruik data ethisch: Publiceer auteursrechtelijk beschermde content niet opnieuw en misbruik gescrapete informatie niet.
- Verwijder op verzoek: Als iemand je vraagt zijn of haar data te verwijderen, doe dat dan.
Thunderbit is ontworpen om compliance te stimuleren — alleen openbare data, geen hacking en duidelijke exportopties voor verantwoord gebruik.
Juridische risico’s vermijden
- Beperk je tot openbare, niet-persoonlijke data.
- Scrape geen sites die het expliciet verbieden.
- Vraag bij twijfel toestemming of gebruik de officiële API van de site.
- Houd logboeken bij van wat je hebt gescrapet en wanneer.
- Honoreer cease-and-desist-verzoeken direct.
Voor meer verdieping, zie Is Web Scraping Illegal? Understanding the Legal Implications.
JavaScript-crawling-oplossingen vergelijken: Thunderbit versus traditionele tools
| Aspect | Puppeteer/Playwright (Code) | Sitebulb (SEO-crawler) | Thunderbit (AI no-code) |
|---|---|---|---|
| Insteltijd | Uren (coderen vereist) | Gemiddeld (configuratie) | Minuten (point & click) |
| Benodigde vaardigheid | Hoog (alleen developers) | Gemiddeld | Laag (iedereen) |
| Hanteert JS-content | Ja (handmatige scripting) | Ja (voor SEO) | Ja (AI, automatisch) |
| Paginering/subpagina’s | Handmatige scripting | Beperkt | Automatisch (AI detecteert) |
| Onderhoud | Hoog (breekt bij wijzigingen) | Gemiddeld | Laag (AI past zich aan) |
| Schaalbaarheid | Handmatig (code schrijven) | Beperkt | Ingebouwde cloud (50x) |
| Exportopties | Handmatig (code schrijven) | CSV/Excel | Excel, Sheets, Notion |
| Het beste voor | Developers, maatwerkflows | SEO-audits | Zakelijke gebruikers, analisten |
Thunderbit is de duidelijke winnaar voor zakelijke gebruikers die snel resultaat willen, zonder technische hoofdbrekens (Thunderbit Blog).
Conclusie en belangrijkste lessen
JavaScript-websites scrapen met AI Ontgrendel dynamische webdata met Thunderbit’s AI-webscraper. Get Started Free
JavaScript-crawling is niet langer een nichevaardigheid — het is onmisbaar voor iedereen die in 2026 webdata nodig heeft.
--- Met 98,9% van de websites die in 2026 client-side scripts draaien, schiet traditionele scraping simpelweg tekort (Radixweb).
--- Het goede nieuws? Je hoeft geen developer te zijn om het te beheersen.
Dit is wat je moet onthouden:
- Dynamische content is overal: Als je moderne sites wilt scrapen, heb je een tool nodig die JavaScript kan uitvoeren.
- De uitdagingen zijn echt, maar oplosbaar: Headless browsers, slim wachten en cloudversnelling maken het mogelijk om zelfs de lastigste data te extraheren.
- Thunderbit maakt het makkelijk: Met AI-gestuurde veldsuggesties, extractie in natuurlijke taal, ondersteuning voor subpagina’s en paginering, en cloudversnelling zet Thunderbit krachtige JavaScript-crawling in ieders handen.
- Blijf compliant: Respecteer altijd de regels van de site, privacywetten en ethische richtlijnen.
- Begin vandaag nog: Installeer Thunderbit, kies een site en ontdek hoeveel data je met een paar klikken kunt ontsluiten.
Wil je dieper duiken? Bekijk de Thunderbit Blog voor meer handleidingen, of bekijk onze YouTube-tutorials voor stapsgewijze demo’s.
Veel succes met crawlen — en moge je data altijd dynamisch, volledig en klaar voor actie zijn.
Begin met JavaScript-crawling met Thunderbit
FAQ’s
1. Wat is JavaScript-crawling en hoe verschilt het van traditionele scraping?
JavaScript-crawling gebruikt een tool die een webpagina laadt, alle JavaScript uitvoert en de content extraheert die verschijnt nadat de scripts zijn gedraaid. Traditionele scraping pakt alleen de ruwe HTML op en mist het grootste deel van de content op moderne sites.
2. Waarom heb ik JavaScript-crawling nodig voor zakelijke data-extractie?
Omdat bijna alle moderne websites JavaScript gebruiken om content dynamisch te laden. Zonder JavaScript-crawling mis je productlijsten, reviews, prijzen en andere belangrijke data.
3. Hoe vereenvoudigt Thunderbit JavaScript-crawling voor beginners?
Thunderbit gebruikt AI om velden voor te stellen, dynamische content af te handelen en paginering en het scrapen van subpagina’s te automatiseren. Je kunt in gewone taal beschrijven wat je wilt — coderen is niet nodig.
4. Is JavaScript-crawling legaal? Waar moet ik op letten?
JavaScript-crawling is legaal als je het verantwoord doet — houd je aan openbare data, respecteer robots.txt en de gebruiksvoorwaarden, en scrape geen persoonlijke informatie zonder toestemming. Thunderbit stimuleert compliance en verantwoord gebruik.
5. Hoe kan ik mijn JavaScript-crawling opschalen voor grote klussen?
Thunderbit’s Lightning Network (cloud scraping) laat je tot 50 pagina’s tegelijk scrapen, waardoor grote taken zoals prijsmonitoring of leadgeneratie over duizenden pagina’s heen eenvoudig worden.
Meer weten:
- Web Scraping met JavaScript: een stapsgewijze handleiding
- Stapsgewijze handleiding voor webscraping met JavaScript
- De ultieme gids voor webscraping met JavaScript en Node.js
- Hoe je een JavaScript-website crawlt
Probeer AI-webscraper Get Started Free




