Webdata is tegenwoordig echt het nieuwe goud—maar het ligt verspreid over talloze websites, verstopt in chaotische HTML en beschermd door alles van lastige CAPTCHAs tot slimme anti-bot scripts. Heb je ooit handmatig productprijzen, concurrentie-informatie of leads zitten kopiëren? Dan weet je hoe snel je daar een muisarm aan overhoudt én hoeveel kansen je misloopt. Daarom is webscraping niet meer weg te denken voor moderne bedrijven. De markt voor alternatieve data (waar webscraping onder valt) was in en groeit als kool.

Toch krijgt Python meestal alle aandacht van beginners, terwijl Go (of Golang, als je het officieel wilt noemen) stiekem de snelste en meest stabiele webscrapers mogelijk maakt. Waarom is Go zo’n krachtpatser? Supersnelle gelijktijdigheid, een ijzersterke standaardbibliotheek en prestaties waar backend-developers van dromen. Ik heb teams hun scraping-tijd zien halveren door simpelweg over te stappen op Go—en je hoeft echt geen Google-engineer te zijn om ermee te starten.
Klaar om Go als jouw webscraping-superkracht in te zetten? We nemen je mee in vijf praktische stappen—van installatie tot geavanceerde scraping—met duidelijke codevoorbeelden, handige tips en een blik op hoe AI-tools zoals je workflow kunnen versnellen.
Waarom Go kiezen voor webscraping? De zakelijke voordelen
Als je duizenden of zelfs miljoenen pagina’s wilt scrapen, telt elke seconde. Go is gemaakt voor dit soort zware klussen. Daarom stappen steeds meer bedrijven over op Go voor webscraping:
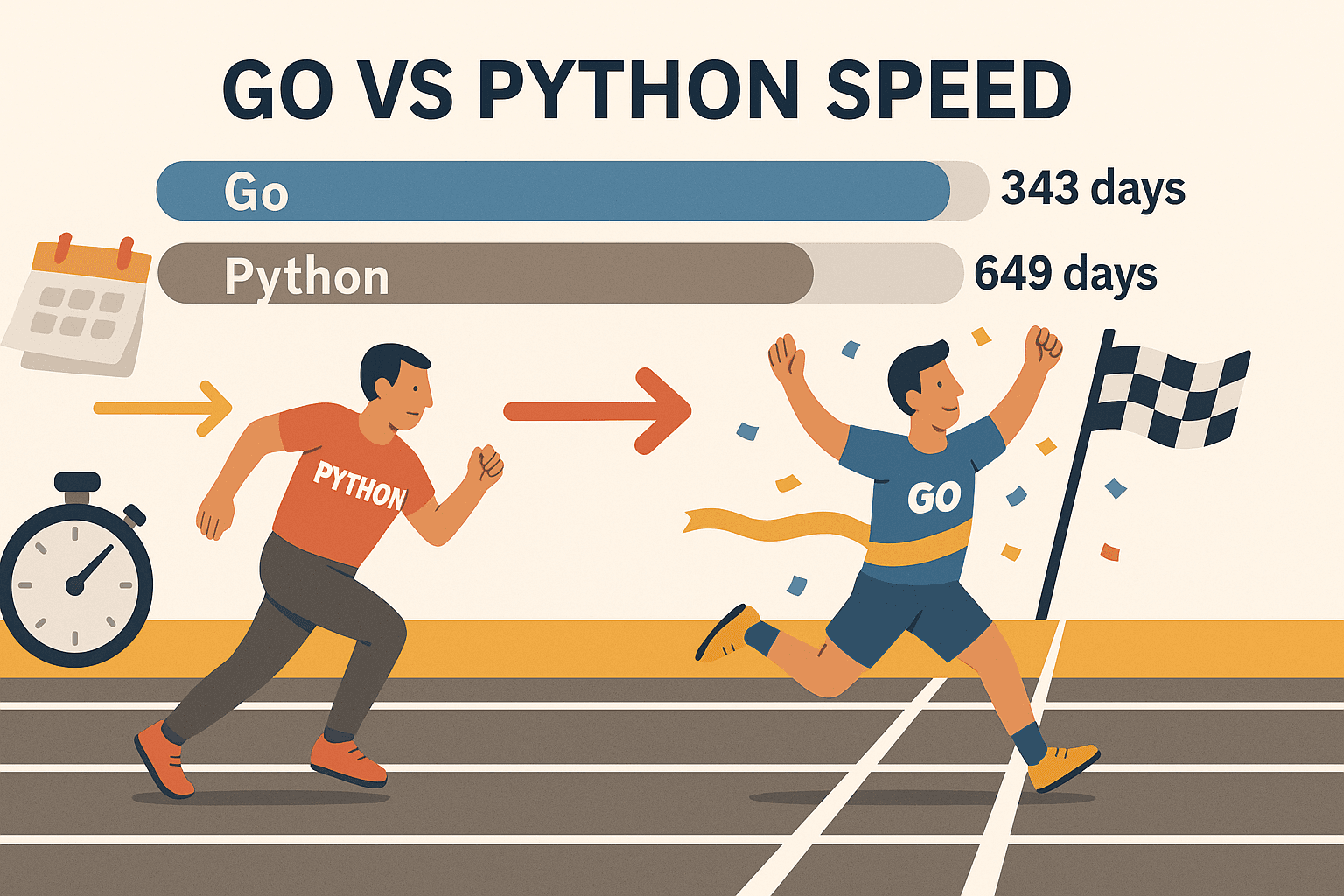
- Schaalbare gelijktijdigheid: Dankzij Go’s goroutines (lichte threads) kun je honderden pagina’s tegelijk scrapen—zonder dat je laptop in rook opgaat. In een benchmark wist Go te verwerken, terwijl Python er 649 dagen over deed. Dat is niet alleen sneller—dat is een compleet andere league.
- Stabiliteit en betrouwbaarheid: Go’s sterke typecontrole en efficiënt geheugenbeheer maken het ideaal voor langdurige, grootschalige crawlers. Geen scripts meer die ’s nachts crashen.
- Uitgebreide netwerkmogelijkheden: De standaardbibliotheek van Go heeft alles wat je nodig hebt voor HTTP-verzoeken, HTML-parsing en JSON—je hoeft niet eerst allerlei externe libraries te zoeken.
- Eenvoudige uitrol: Go compileert naar één enkel uitvoerbaar bestand, dus je scraper draait overal—geen gedoe met virtuele omgevingen of dependency-gedoe.
- Breed in gebruik: Go is inmiddels de (voorbij Node.js) en wordt vertrouwd door bedrijven als Google, Uber en Netflix.
Python blijft natuurlijk handig voor snelle scripts of als je machine learning nodig hebt. Maar als je snelheid, schaalbaarheid en betrouwbaarheid zoekt, is Go moeilijk te verslaan—zeker in combinatie met libraries als Colly en Goquery.
Stap 1: Je Go-omgeving klaarzetten voor webscraping
Voordat je kunt scrapen, moet Go geïnstalleerd zijn. Gelukkig is dat zo gepiept.
1. Installeer Go
- Ga naar de en kies de juiste installer voor jouw besturingssysteem (Windows, macOS of Linux).
- Volg de installatie-instructies. Op Linux kun je ook je pakketbeheerder gebruiken.
- Open een terminal en typ:
Zie je iets als1go versiongo version go1.21.0 darwin/amd64, dan zit je goed.
Problemen? Wordt go niet gevonden, check dan of je PATH goed staat. Op Linux/macOS kun je export PATH=$PATH:/usr/local/go/bin toevoegen aan je ~/.bash_profile of ~/.zshrc.
2. Start een nieuw Go-project
- Maak een nieuwe map voor je scraper:
1mkdir mijn-scraper && cd mijn-scraper - Initialiseer een Go-module:
Hiermee wordt een1go mod init github.com/jouwnaam/mijn-scrapergo.modbestand aangemaakt voor je dependencies.
3. Kies een editor
- met de Go-extensie is top (autocomplete, linting, debugging).
- JetBrains GoLand is populair bij Go-pro’s.
- Vim/Neovim met Go-plugins werkt ook prima als je old-school wilt gaan.
4. Test je installatie
Maak snel een main.go aan:
1package main
2import "fmt"
3func main() {
4 fmt.Println("Go is geïnstalleerd en werkt!")
5}Voer uit:
1go run main.goZie je je bericht verschijnen? Dan ben je klaar om te knallen.
Stap 2: Je eerste HTTP-verzoek doen in Go
Tijd om je eerste webpagina op te halen! Met Go’s net/http pakket is dat zo geregeld.
Voorbeeld van een simpele HTTP GET:
1package main
2import (
3 "fmt"
4 "io"
5 "net/http"
6)
7func main() {
8 resp, err := http.Get("https://example.com")
9 if err != nil {
10 fmt.Println("Fout bij ophalen van de URL:", err)
11 return
12 }
13 defer resp.Body.Close()
14 body, err := io.ReadAll(resp.Body)
15 if err != nil {
16 fmt.Println("Fout bij lezen van de response:", err)
17 return
18 }
19 fmt.Println(string(body))
20}Belangrijk:
- Check altijd op fouten na
http.Get. - Gebruik
defer resp.Body.Close()om geheugenlekken te voorkomen. - Met
io.ReadAlllees je de hele response in.
Tips:
- Wil je eigen headers (zoals een User-Agent) instellen? Gebruik
http.NewRequest:1req, _ := http.NewRequest("GET", "https://example.com", nil) 2req.Header.Set("User-Agent", "Mozilla/5.0") 3client := &http.Client{} 4resp, err := client.Do(req) - Check altijd
resp.StatusCode—200 is goed, 403 of 404 betekent geblokkeerd of niet gevonden.
Stap 3: HTML parsen en data extraheren met Go
HTML ophalen is pas het begin. Nu wil je de juiste data eruit vissen—zoals productnamen, prijzen of links.
Maak kennis met Goquery: Een Go-library waarmee je met jQuery-achtige selectors HTML kunt parsen.
Goquery installeren:
1go get github.com/PuerkitoBio/goqueryVoorbeeld: Productnamen en prijzen extraheren
1package main
2import (
3 "fmt"
4 "net/http"
5 "github.com/PuerkitoBio/goquery"
6)
7func main() {
8 resp, err := http.Get("https://example.com/products")
9 if err != nil {
10 panic(err)
11 }
12 defer resp.Body.Close()
13 doc, err := goquery.NewDocumentFromReader(resp.Body)
14 if err != nil {
15 panic(err)
16 }
17 doc.Find("div.product").Each(func(i int, s *goquery.Selection) {
18 name := s.Find("h2").Text()
19 price := s.Find(".price").Text()
20 fmt.Printf("Product %d: %s - %s\n", i+1, name, price)
21 })
22}Hoe werkt het?
doc.Find("div.product")selecteert alle productcontainers.- Binnen elk element haalt
s.Find("h2").Text()de productnaam op, ens.Find(".price").Text()de prijs.
Reguliere expressies: Voor simpele patronen (zoals e-mails) is Go’s regexp pakket snel en handig. Voor complexere HTML-structuren is Goquery je beste vriend.
Stap 4: Je scraper krachtiger maken met Go-libraries (Colly & Gocolly)
Klaar voor de volgende stap? is hét webscraping-framework voor Go. Het regelt crawling, gelijktijdigheid, cookies en meer—zodat jij je kunt focussen op de data.
Waarom Colly zo fijn werkt:
- Eenvoudige API: Registreer callbacks voor de elementen die je wilt scrapen.
- Gelijktijdigheid: Scrape honderden pagina’s tegelijk met
colly.Async(true). - Automatisch crawlen: Volg makkelijk links en paginering.
- Anti-bot functies: Stel headers in, roteer user agents en beheer cookies.
- Foutafhandeling: Ingebouwde hooks voor mislukte verzoeken.
Colly installeren:
1go get github.com/gocolly/colly/v2Voorbeeld van een simpele Colly-scraper:
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly/v2"
5)
6func main() {
7 c := colly.NewCollector(
8 colly.AllowedDomains("example.com"),
9 colly.Async(true),
10 )
11 c.OnHTML(".product-list-item", func(e *colly.HTMLElement) {
12 name := e.ChildText("h2")
13 price := e.ChildText(".price")
14 fmt.Printf("Product: %s - %s\n", name, price)
15 })
16 c.OnRequest(func(r *colly.Request) {
17 r.Headers.Set("User-Agent", "Mozilla/5.0")
18 })
19 c.OnError(func(r *colly.Response, err error) {
20 fmt.Println("Request mislukt:", r.Request.URL, "->", err)
21 })
22 c.Visit("https://example.com/products")
23 c.Wait()
24}Vergelijking: Goquery vs. Colly
| Functie | Goquery | Colly |
|---|---|---|
| HTML-parsing | Ja | Ja (gebruikt Goquery) |
| HTTP-verzoeken | Handmatig | Ingebouwd |
| Gelijktijdigheid | Handmatig (goroutines) | Eenvoudig (Async(true)) |
| Crawlen/links volgen | Handmatig | Automatisch |
| Anti-bot functies | Handmatig | Ingebouwd |
| Foutafhandeling | Handmatig | Ingebouwd |
Colly bespaart je enorm veel tijd zodra je scraper wat complexer wordt.
Stap 5: Omgaan met uitdagingen bij webscraping in Go
Webscraping in de praktijk is niet altijd een eitje. Zo tackle je de grootste obstakels:
1. IP-blokkades
- Gebruik proxies via Go’s
http.Transportof Colly’s proxy-ondersteuning. - Vertraag je verzoeken met random pauzes.
2. User-Agent en headers
- Stel altijd een realistische User-Agent in (zoals Chrome of Firefox).
- Imiteer echte browser-headers (zoals Accept-Language).
3. CAPTCHAs
- Krijg je een CAPTCHA? Dan scrape je waarschijnlijk te snel of te opvallend.
- Gebruik headless browsers (zoals ) voor sites die JavaScript of visuele interactie vereisen.
- Voor hardnekkige anti-botmaatregelen kun je een CAPTCHA-oplossingsdienst integreren.
4. Paginering
- Met Colly kun je automatisch “Volgende” links volgen:
1c.OnHTML("a.next", func(e *colly.HTMLElement) { 2 e.Request.Visit(e.Attr("href")) 3})
5. Dynamische content (JavaScript)
- Go’s HTTP-libraries voeren geen JavaScript uit. Gebruik een headless browser (Rod, chromedp) of probeer de onderliggende API te vinden.
6. Kom je er niet uit? Gebruik Thunderbit
Soms loop je vast—bijvoorbeeld als een site te dynamisch is, of als je snel data nodig hebt zonder te programmeren. Dan is ideaal. Thunderbit is een AI-webscraper Chrome-extensie die:
- Met AI automatisch velden herkent—klik gewoon op “AI Kolommen voorstellen”.
- Subpagina’s en paginering automatisch afhandelt.
- Draait in een echte browser (of in de cloud), dus werkt ook op JavaScript-rijke sites en omzeilt de meeste anti-botmaatregelen.
- Exporteert direct naar Excel, Google Sheets, Airtable of Notion—zonder code.
- Laat je scrapes plannen en data automatisch verzamelen voor je team.
Thunderbit is een uitkomst voor zakelijke gebruikers, sales-teams of iedereen die gestructureerde data wil zonder te programmeren. En ja, ik ben een beetje bevooroordeeld—mijn team en ik hebben het gebouwd om precies deze problemen op te lossen.
Go en Thunderbit combineren voor maximale productiviteit
Het mooie? Je hoeft niet te kiezen tussen Go en Thunderbit. De slimste teams gebruiken gewoon allebei.
Voorbeeldworkflow:
- Gebruik Go (met Colly) om een grote lijst URLs te crawlen of basisdata te verzamelen.
- Geef de URLs aan Thunderbit om gedetailleerde, gestructureerde info te extraheren—vooral handig bij subpagina’s, dynamische content of lastige anti-botmaatregelen.
- Exporteer de data uit Thunderbit naar Google Sheets of CSV.
- Gebruik Go opnieuw om de data te verwerken, samen te voegen of te analyseren.
Deze hybride aanpak geeft je de snelheid en controle van Go, plus de flexibiliteit en AI van Thunderbit. Het is alsof je een Zwitsers zakmes én een boormachine in je gereedschapskist hebt.
Go webscraping-oplossingen vergelijken: Core Go vs. Colly vs. Thunderbit
Hier een handig overzicht om het juiste gereedschap te kiezen:
| Aspect | Standaard Go (net/http + html) | Go + Colly (Library) | Thunderbit (AI No-Code) |
|---|---|---|---|
| Installatie & leercurve | Steil (veel code nodig) | Gemiddeld (makkelijkere API) | Zeer eenvoudig (geen code, AI) |
| Gelijktijdigheid | Handmatig (goroutines) | Ingebouwd (Async(true)) | Cloud/browser-parallelisme |
| Dynamische content (JS) | Vereist headless browser | Beperkte JS-ondersteuning | Volledige browser, native JS |
| Anti-bot afhandeling | Handmatig (proxies, headers) | Ingebouwde functies | Meestal automatisch, cloud IP’s |
| Data structureren | Eigen code | Callbacks, eigen structs | AI-voorstellen, automatisch |
| Exportopties | Eigen (CSV, DB, etc.) | Eigen | Excel, Sheets, Notion, Airtable |
| Onderhoud | Hoog (vaak code aanpassen) | Gemiddeld | Laag (AI past zich aan websites aan) |
| Beste voor | Devs, maatwerk pipelines | Devs, snelle prototypes | Niet-programmeurs, zakelijke gebruikers |
Tip: Gebruik Go/Colly voor maatwerk, grootschalige of backend-integraties. Gebruik Thunderbit als je snelheid, gemak of complexe front-end sites wilt aanpakken.
Samenvatting: Starten met webscraping in Go
- Go is een krachtpatser voor webscraping—vooral als je snelheid, gelijktijdigheid en betrouwbaarheid zoekt.
- Begin simpel: Zet je Go-omgeving op, doe HTTP-verzoeken en parse HTML met Goquery.
- Maak het krachtiger met Colly: Voor crawling, gelijktijdigheid en anti-bot trucs is Colly je beste maatje.
- Pak echte uitdagingen aan: Gebruik proxies, stel headers in en gebruik headless browsers of Thunderbit voor lastige sites.
- Combineer tools: Mix Go en Thunderbit voor het beste van beide werelden.
Webscraping is een enorme versneller voor sales, operations en research. Met Go en de juiste libraries (en een beetje AI) automatiseer je het saaie werk en kun je focussen op inzichten die je bedrijf vooruit helpen.
Meer bronnen over webscraping met Go
Wil je dieper duiken? Dit zijn mijn favoriete bronnen:
Veel succes met scrapen—moge je data altijd netjes gestructureerd zijn, je scrapers razendsnel en je koffie lekker sterk.
Veelgestelde vragen
1. Waarom zou ik Go gebruiken voor webscraping in plaats van Python of JavaScript?
Go biedt superieure gelijktijdigheid, snelheid en betrouwbaarheid—vooral bij grootschalige of langdurige scraping-projecten. Ideaal als je snel duizenden pagina’s wilt scrapen en een gecompileerd, draagbaar programma zoekt.
2. Wat is de makkelijkste manier om HTML te parsen in Go?
Gebruik de library. Hiermee kun je eenvoudig met jQuery-achtige selectors door de DOM navigeren en data extraheren.
3. Hoe ga ik om met sites die content via JavaScript laden in Go?
Je hebt een headless browser library nodig zoals of . Of gebruik voor een no-code, browser-gebaseerde aanpak die direct met JS overweg kan.
4. Hoe voorkom ik dat ik geblokkeerd word tijdens het scrapen?
Roteer je User-Agent, gebruik proxies, voeg vertragingen toe tussen verzoeken en boots echt browsergedrag na. Colly maakt dit eenvoudig, en Thunderbit regelt de meeste anti-botmaatregelen automatisch.
5. Kan ik Go en Thunderbit samen gebruiken in mijn workflow?
Zeker! Gebruik Go voor grootschalig crawlen of backend-integratie, en Thunderbit voor AI-gestuurde extractie, subpagina-scraping en export naar zakelijke tools. Het is een krachtige combinatie voor zowel ontwikkelaars als zakelijke gebruikers.
Wil je je webscraping-skills naar een hoger niveau tillen? Probeer of check de voor meer tips, tutorials en diepgaande artikelen over scraping, automatisering en AI.