Laat ik je een geheimpje vertellen: het internet is eigenlijk de grootste bibliotheek ter wereld, maar de meeste boeken zitten stevig op slot. Elke dag spreek ik ondernemers, marketeers en salesmensen die weten dat er goud aan informatie op websites te vinden is—denk aan productspecificaties, prijzen van concurrenten, klantreviews, contactgegevens—maar hoe krijg je die tekst eruit? Daar gaat het vaak mis. Na jaren in de SaaS- en automatiseringshoek heb ik alle ‘copy-paste marathons’ en ‘zelf Python-scripts bouwen’ wel voorbij zien komen. Gelukkig is tekst uit een website halen tegenwoordig een stuk simpeler (en minder frustrerend) dankzij slimme AI-webscraper tools en handige browserextensies.
In deze gids laat ik je alle praktische manieren zien—van ouderwets kopiëren en plakken tot geavanceerde AI-oplossingen zoals (ja, dat is ons eigen product, maar ik ben eerlijk over de plus- en minpunten). Of je nu een Excel-wizard bent, een developer, of gewoon klaar bent met eindeloos naar webpagina’s staren: je vindt hier een aanpak die bij je past. Tijd om die digitale boeken open te breken en de tekst te pakken die je nodig hebt.
Wat bedoelen we met tekst uit een website halen?
Met ‘tekst uit een website halen’ bedoelen we het verzamelen van de info die je op een webpagina ziet (en soms niet ziet) en die omzetten naar een bruikbaar formaat—zoals een spreadsheet, database of een net Word-bestand. Maar niet alle webtekst is hetzelfde:
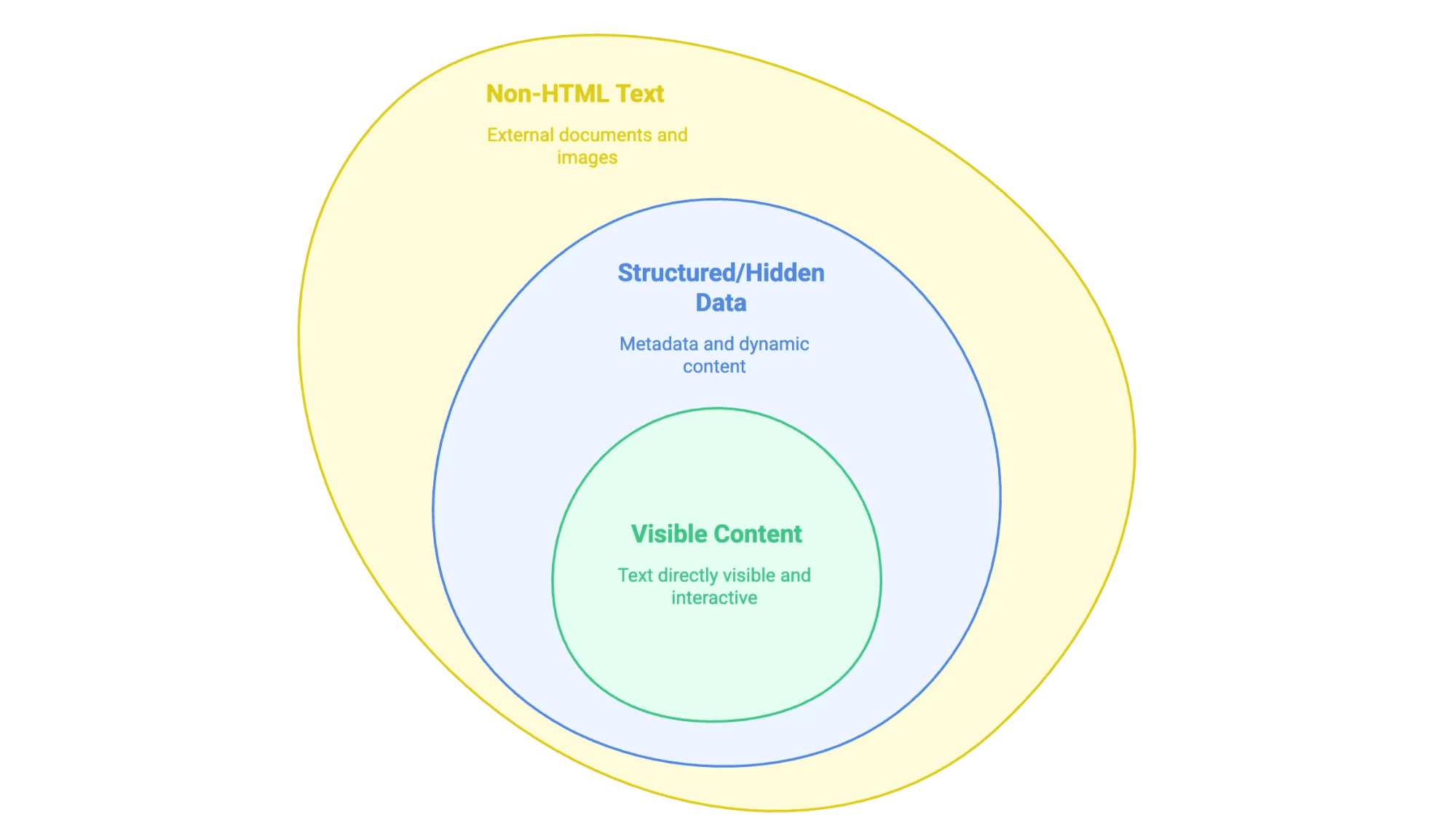
- Zichtbare content: Dit is de tekst die je gewoon met je muis kunt selecteren—zoals bodytekst, koppen, lijstjes, tabellen, productomschrijvingen, blogs, enzovoort.
- Gestructureerde of verborgen data: Denk aan metadata in
<meta>-tags, JSON-LD scripts, of info die pas zichtbaar wordt na klikken of scrollen (JavaScript). - Niet-HTML tekst: PDF’s, Word-bestanden en zelfs afbeeldingen met tekst (zoals gescande contracten of infographics) die op de site staan of zijn ingesloten.
Het is handig om te weten welk type tekst je zoekt, want elke soort vraagt om een andere aanpak.
Waarom zou je tekst uit een website halen? Zakelijke voordelen en toepassingen
Laten we eerlijk zijn: niemand haalt voor de lol tekst van websites (tenzij je een heel aparte hobby hebt). Bedrijven doen het omdat het echt iets oplevert. De markt voor webscraping-software was in , en groeit nog steeds. Waarom? Hierom:
| Team | Voorbeeldtoepassing | Voordeel |
|---|---|---|
| Sales | Adreslijsten en contactinfo verzamelen | Sneller en rijker prospecteren |
| Marketing | Blogposts en SEO-data van concurrenten halen | Inzicht in contentgaten, trends spotten |
| Operations | Prijzen monitoren op e-commerce sites | Dynamische prijsstelling, voorraadbeheer |
| Vastgoed | Woningen en details verzamelen | Marktanalyse, leads genereren |
| Support | Klantreviews en forumvragen verzamelen | Sentimentanalyse, issues vroeg signaleren |
Wat voorbeelden uit de praktijk:

- Leadgeneratie: Een horecaleverancier in minuten in plaats van dagen.
- Concurrentieanalyse: Winkels als John Lewis door prijsdata te scrapen.
- SEO-analyse: Teams halen meta-tags en zoekwoorden op om hun .
En met AI-tools besparen bedrijven vergeleken met handmatig werk.
Handmatig: De basis van kopiëren en plakken
We beginnen bij het begin. Soms wil je gewoon snel een stukje tekst pakken—zonder extra poespas.
Hoe doe je dat handmatig?
- Kopiëren en plakken: Open de pagina, selecteer de tekst, druk op Ctrl+C (of rechtermuisknop > Kopiëren). Plak het in je document of spreadsheet.
- Pagina opslaan als: In je browser: Bestand > Pagina opslaan als. Kies ‘Webpagina, alleen HTML’ voor de broncode, of soms als .txt voor alleen de tekst.
- Printen naar PDF: Gebruik de printoptie van je browser om op te slaan als PDF. Open de PDF en kopieer de tekst, of gebruik ‘Opslaan als tekst’ in je PDF-lezer.
- Ontwikkelaarstools: Rechtermuisknop > Inspecteren of F12. Bekijk de HTML-bron, zoek meta-tags of verborgen JSON, en kopieer wat je nodig hebt.
Beperkingen
Handmatig werkt prima voor kleine klusjes, maar is een ramp als je veel data nodig hebt. Het is . Ik heb stagiairs dagenlang rijen uit tabellen zien overtypen—dat gun je niemand.
Tekst uit websites halen met browserextensies en online tools
Wil je het jezelf makkelijker maken? Browserextensies en online tools zijn ideaal voor de meeste zakelijke gebruikers: geen code, geen gedoe, gewoon aanklikken en klaar.
Waarom deze tools gebruiken?

- Veel sneller dan handmatig kopiëren
- Geen technische kennis nodig
- Kan tabellen, lijsten en soms zelfs bestanden aan
- Exporteer naar Excel, Google Sheets, CSV, enz.
Hier zijn de populairste opties op een rij.
Thunderbit: AI-webscraper voor snelle en nauwkeurige tekstopslag
Eerlijk is eerlijk, ik ben niet helemaal objectief, maar is echt gemaakt om tekst van websites halen net zo makkelijk te maken als een pizza bestellen. Zo werkt het:
Stappenplan: Tekst halen met Thunderbit
- Installeer de Chrome-extensie: uit de Chrome Web Store.
- Open de gewenste website: Ga naar de pagina waarvan je tekst wilt halen.
- Klik op “AI Suggest Fields”: Thunderbit’s AI scant de pagina en stelt voor welke velden (kolommen) je kunt halen—zoals productnaam, prijs, omschrijving, enz.
- Controleer & pas aan: Je kunt de suggesties aanpassen of eigen velden toevoegen.
- Klik op “Scrape”: Thunderbit verzamelt de data, ook van subpagina’s of pagineringen als dat nodig is.
- Exporteer: Download je data naar Excel, Google Sheets, Airtable, Notion of als CSV/JSON. Geen extra kosten voor exporteren.
Wat maakt Thunderbit uniek?
- AI-gestuurde veldsuggesties: Geen gedoe met selectors of code. De AI bepaalt wat belangrijk is op de pagina.
- Automatisch subpagina’s & paginering: Wil je details van elke productpagina in een categorie? Thunderbit klikt automatisch door.
- Tekst uit PDF’s, afbeeldingen en documenten: Heb je een PDF-handleiding of een productspecificatie als afbeelding? Thunderbit’s ingebouwde OCR haalt daar ook tekst uit.
- Meertalige ondersteuning: Werkt in 34 talen (Klingon staat nog op de wensenlijst).
- Gratis data-export: Je betaalt niet extra om je data te downloaden.
- Toepassingen: Productomschrijvingen, contactgegevens, blogcontent, leadlijsten, noem maar op.
Wil je het in actie zien? Check onze voor handleidingen zoals .
Andere browserextensies en online tools
Een kort overzicht van andere tools die je kunt tegenkomen:
- Webscraper (): Gratis, point-and-click, maar je moet wel even leren werken met ‘sitemaps’ en selectors. Ideaal voor wie technisch is aangelegd. Kan paginering aan, maar geen PDF’s of afbeeldingen. .
- CopyTables: Super simpel—kopieert HTML-tabellen direct naar je klembord of Excel. Perfect voor snel een enkele tabel, maar werkt alleen per pagina en alleen voor tabellen. .
- ScraperAPI (): Voor developers. Je stuurt een URL, krijgt de HTML terug (regelt proxies, blokkades, enz.), maar je moet zelf de tekst nog parseren. .
Wanneer gebruik je welke tool?
- Thunderbit: Als je snelheid, AI-hulp en ondersteuning voor meerdere formaten (inclusief PDF’s/afbeeldingen) wilt.
- Webscraper: Als je graag zelf sleutelt en meer controle wilt.
- CopyTables: Als je snel een tabel nodig hebt.
- ScraperAPI: Als je zelf een scraper bouwt in code.
Geautomatiseerd webscrapen: Programmeren voor tekstextractie
Ben je developer (of heb je er eentje in je team), dan geeft zelf coderen maximale controle. Zo werkt het in grote lijnen:
- HTTP-verzoek sturen: Gebruik bijvoorbeeld Python’s
requestsom de pagina op te halen. - HTML parseren: Gebruik
BeautifulSoup,lxmlofScrapyom de gewenste tekst te vinden. - Extract & export: Haal de tekst eruit, maak het schoon en sla op als CSV, JSON of in een database.
Voorbeeld: Python + Beautiful Soup
1import requests
2from bs4 import BeautifulSoup
3url = "<http://quotes.toscrape.com>"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
7for qt in quotes:
8 print(qt)Voordelen & nadelen
- Voordelen: Maximale flexibiliteit, geschikt voor elke site of datatype, integreert met je eigen systemen.
- Nadelen: Vereist programmeerkennis, onderhoud, en je moet omgaan met anti-botmaatregelen.
Wanneer kies je hiervoor?
- Je wilt duizenden (of miljoenen) pagina’s scrapen.
- De site is complex (logins, meerstapsformulieren).
- Je wilt scraping direct in je eigen app of workflow integreren.
Tekst halen uit niet-HTML-bestanden: PDF’s, Word-documenten en afbeeldingen
Websites bevatten niet alleen HTML, maar ook PDF’s, Word-bestanden en afbeeldingen met waardevolle tekst. Zo pak je dat aan:
PDF’s
- Tekstgebaseerde PDF’s: Gebruik tools als Adobe Acrobat, of libraries als
PDFMinerofPyPDF2om tekst te halen. - Gescande PDF’s: Gebruik OCR (Optical Character Recognition) tools zoals Tesseract, , of .
Word/Excel-bestanden
- Word: Gebruik
python-docxom .docx-bestanden te lezen. - Excel: Gebruik
openpyxlofpandasvoor .xlsx-bestanden.
Afbeeldingen
- OCR-tools: Tesseract (open source) of cloudservices voor hogere nauwkeurigheid. Beste resultaat met scherpe afbeeldingen (150–300 DPI).
Thunderbit’s aanpak
Met de “Image/Document Parser” kun je een PDF, afbeelding of document uploaden of linken, waarna de AI de tekst eruit haalt (en zelfs kolommen voorstelt als er een tabel wordt gevonden). Je hoeft dus niet te wisselen tussen verschillende tools—behandel bestanden gewoon als een webpagina.
Alle methodes vergeleken: Welke tekstextractie past bij jou?
Hier een handig overzicht om te kiezen:
| Methode | Gebruiksgemak | Schaalbaarheid | Technische kennis nodig | Ondersteunde datatypes | Ideaal voor |
|---|---|---|---|---|---|
| Handmatig (kopiëren-plakken) | Zeer makkelijk | Laag | Geen | Alleen zichtbare tekst | Kleine, eenmalige klusjes |
| Browserextensies/tools | Makkelijk–gemiddeld | Gemiddeld | Weinig–gemiddeld | HTML, sommige tabellen | Niet-technische gebruikers, kleine–middelgrote taken |
| AI-tools (Thunderbit) | Zeer makkelijk | Hoog | Geen | HTML, PDF’s, afbeeldingen, meer | Zakelijke gebruikers, gemengde content |
| Programmeren (code) | Moeilijk | Zeer hoog | Hoog | Alles (met juiste libraries) | Developers, grootschalige projecten |
| Niet-HTML extractie (OCR) | Gemiddeld | Laag–gemiddeld | Gemiddeld | PDF’s, afbeeldingen, documenten | Als bestanden/afbeeldingen belangrijk zijn |
Wil je snel, flexibel en zonder stress aan de slag—vooral zakelijk—dan zijn AI-tools zoals Thunderbit bijna niet te overtreffen. Maar als je volledige controle wilt of op grote schaal werkt, is zelf coderen een goede optie.
Samenvatting: Begin vandaag nog met tekst halen uit websites
- Het web staat vol waardevolle tekstdata, maar het is niet altijd makkelijk te pakken.
- Handmatig werkt alleen voor kleine klusjes, maar is niet schaalbaar.
- Browserextensies en AI-webscrapers zoals maken tekst halen snel, nauwkeurig en toegankelijk voor iedereen—zonder code.
- Voor niet-HTML content (PDF’s, afbeeldingen) heb je tools nodig met ingebouwde OCR en documentherkenning.
- Kies de methode die past bij de vaardigheden van je team, de omvang van je project en het soort data dat je zoekt.
Veel succes met scrapen—en hopelijk zijn je Ctrl+C-dagen snel voorbij. Met de juiste tools wordt webdata verzamelen een geautomatiseerd proces dat je tijd bespaart voor belangrijker werk. Geen eindeloos kopiëren en plakken meer, maar slimme, efficiënte oplossingen binnen handbereik. Op naar een productievere toekomst zonder handmatig gedoe!
Veelgestelde vragen
Vraag 1: Kan ik van elke website data scrapen?
Antwoord: Niet altijd. Sommige websites blokkeren scrapers of verbieden het in hun voorwaarden. Check altijd eerst het beleid van de site.
Vraag 2: Hoe nauwkeurig zijn AI-webscrapers?
Antwoord: AI-gestuurde scrapers zoals Thunderbit zijn erg nauwkeurig, maar soms moet je bij complexe of dynamische pagina’s wat bijstellen.
Vraag 3: Heb ik programmeerkennis nodig voor webscraping-tools?
Antwoord: Nee, tools zoals Thunderbit en andere browserextensies zijn juist gemaakt voor niet-technische gebruikers en vereisen geen programmeerkennis.
Vraag 4: Welke data kan ik uit PDF’s of afbeeldingen halen?
Antwoord: OCR-tools kunnen tekst, tabellen en zelfs verborgen data uit gescande PDF’s en afbeeldingen halen, waardoor je veel flexibeler data kunt verzamelen.
Meer lezen