
Samenvatting
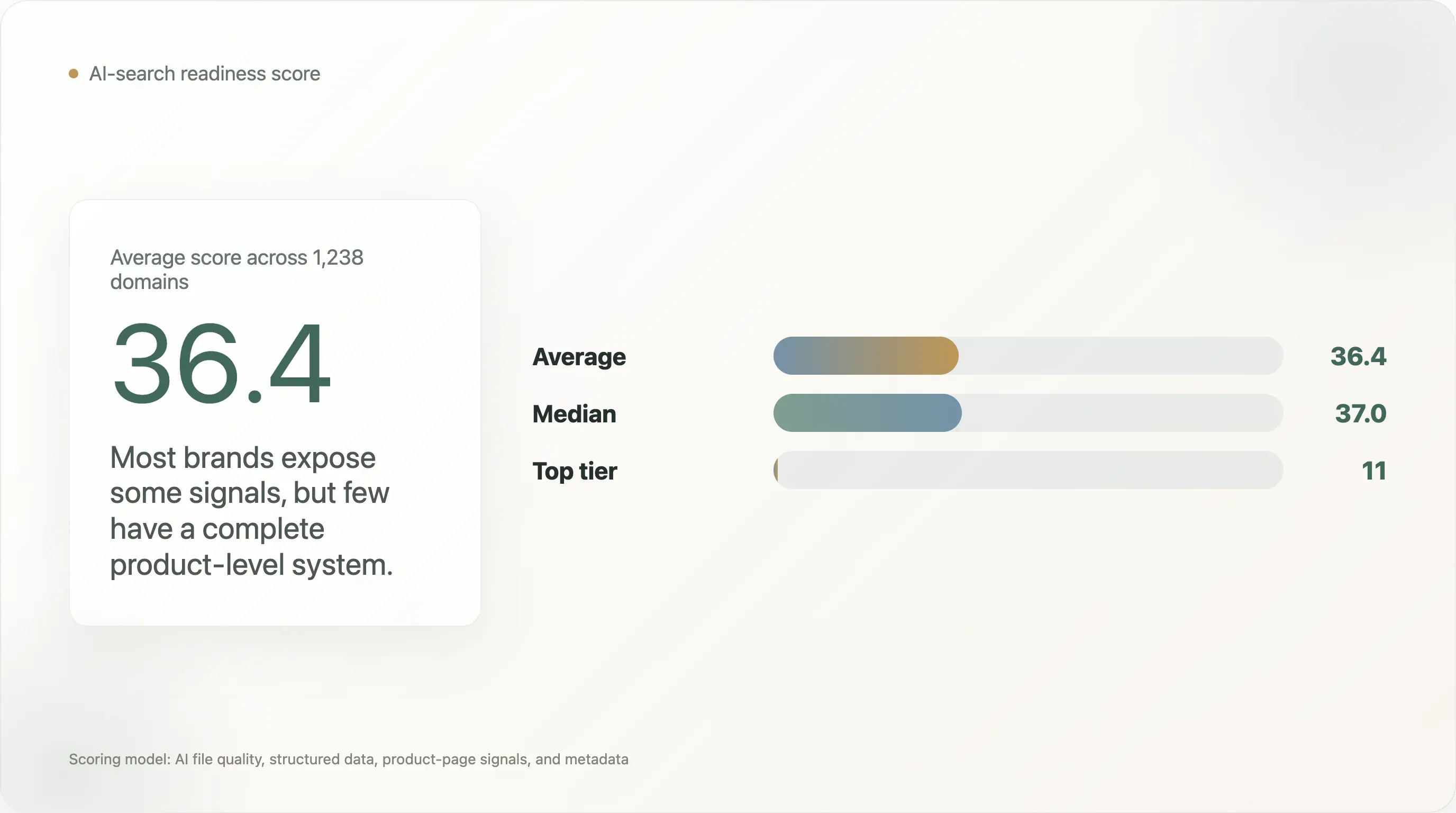
Dit onderzoek beoordeelt 1.238 DTC-domeinen op AI-zoekgereedheid aan de hand van vier lagen: kwaliteit van AI-bestanden, algemene gestructureerde data, gestructureerde signalen op productpagina’s en metadata. De gemiddelde score is 36,4 van 100, en de mediaan is 37,0. Slechts 11 domeinen haalden de ai_ready-categorie binnen dit scoringsmodel.
De grootste bevinding is de kloof tussen zichtbaarheid op oppervlakteniveau en begrip op productniveau. De grootste bucket voor llms.txt-kwaliteit is platform_default, met 629 domeinen. Dat betekent dat veel merken wel een basisbestand dat door AI kan worden gelezen hebben, omdat hun platform het automatisch heeft aangemaakt. Maar Product-schema op de homepage komt slechts voor op 0,9% van de beoordeelde domeinen, en Product-schema op productpagina’s komt voor op 39,2% van de beoordeelde domeinen waar productpagina’s zijn getest. Prijssignalen op productpagina’s komen voor bij 48,1%, en review- of beoordelingssignalen bij 43,5%.
De verdeling per tier laat zien hoe vroeg de markt nog is:
| AI-gereedheidstier | Domeinen |
|---|---|
| Niet gereed | 435 |
| Gedeeltelijk gereed | 425 |
| Basisvindbaarheid | 367 |
| AI-gereed | 11 |
Die verdeling is nuttig, omdat ze drie ideeën uit elkaar trekt die vaak door elkaar lopen. Een merk kan vindbaar zijn. Een merk kan metadata hebben. Een merk kan llms.txt hebben. Maar vindbaarheid is niet hetzelfde als productniveau-begrip.
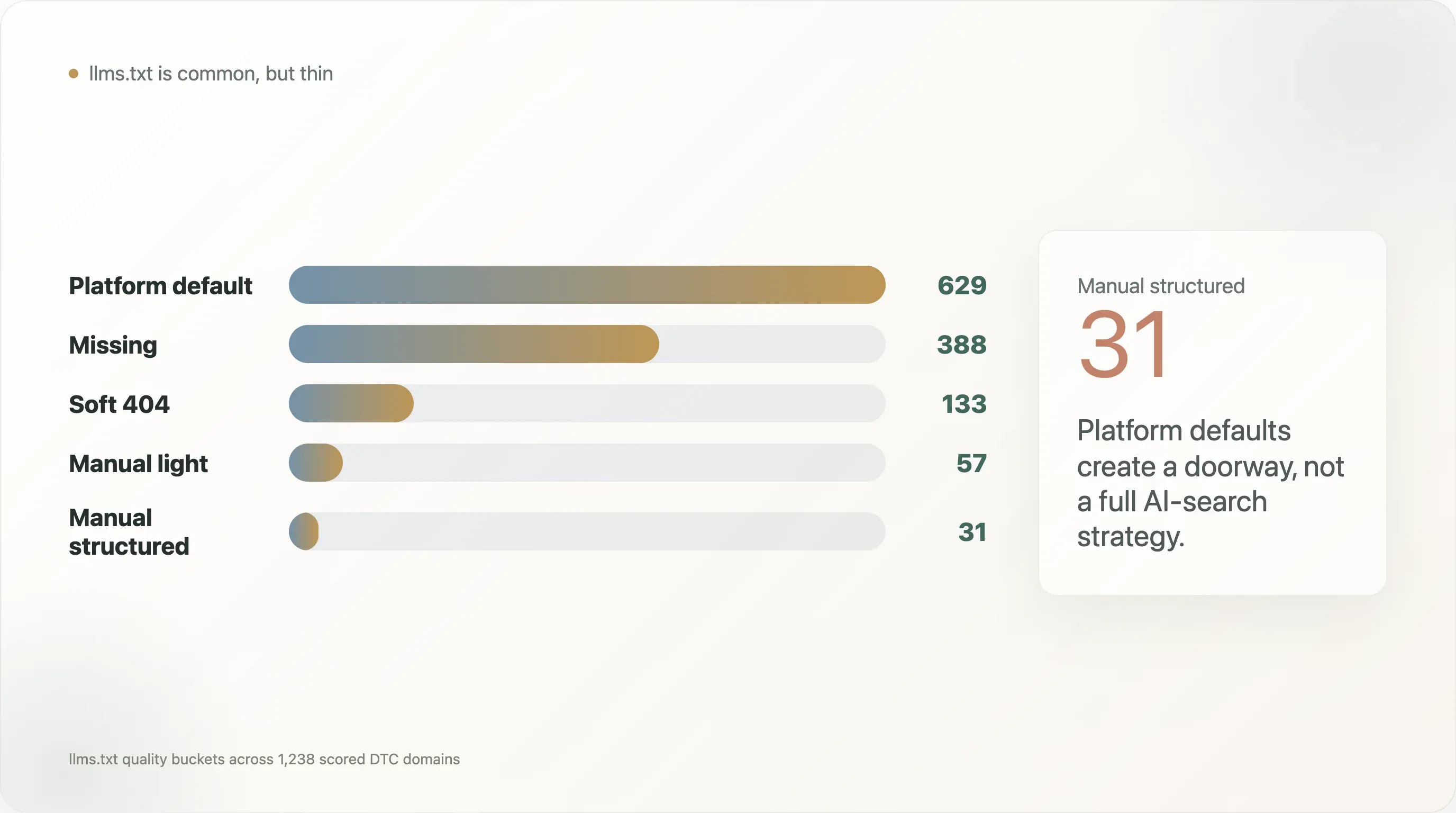
De verdeling van de llms.txt-kwaliteit maakt dit nog duidelijker:
| Bucket voor llms.txt-kwaliteit | Domeinen |
|---|---|
| Platform default | 629 |
| Ontbrekend | 388 |
| Soft 404 | 133 |
| Handmatig licht | 57 |
| Handmatig gestructureerd | 31 |
De sterkste conclusie voor dit rapport is dus niet: "DTC-merken hebben llms.txt." Die kop is te oppervlakkig. Beter is: platform-defaults hebben een dunne eerste laag AI-vindbaarheid gecreëerd, maar de meeste DTC-merken hebben nog niet de laag met gestructureerde productdata opgebouwd die nodig is voor AI-shopping en antwoordsystemen.
Positieve voorbeelden laten zien hoe betere gereedheid eruit kan zien. De ai_ready-categorie omvat merken zoals Mokobara, Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods, La Maison Convertible, Unbloat, NuRange Coffee, Three Ships Beauty en Manukora. Deze voorbeelden zijn relevant, omdat ze laten zien dat AI-gereedheid niet is voorbehouden aan één categorie of één type merk. Food, beauty, wellness, meubels, kleding en specialty commerce kunnen allemaal hun machineleesbare productlaag verbeteren.
De meest deelbare bevindingen
-
De gemiddelde AI-gereedheidsscore voor DTC is slechts 36,4/100.
-
Slechts 11 van de 1.238 beoordeelde domeinen haalden de
ai_ready-tier. -
llms.txt komt vaak voor, maar is meestal door het platform gegenereerd. De grootste kwaliteitsbucket is platform default, met 629 domeinen.
-
Handmatig gestructureerde llms.txt is zeldzaam. Slechts 31 domeinen vallen in de bucket handmatig gestructureerd.
-
Product-schema op de homepage is bijna afwezig. Het komt slechts voor op 0,9% van de beoordeelde domeinen.
-
Product-schema op productpagina’s komt vaker voor, maar is nog steeds onvolledig. Het komt voor op 39,2% van de beoordeelde domeinen waar productpagina’s zijn getest.
-
AI-shopping-gereedheid vereist productfeiten, niet alleen crawler-toegang. Prijs-, aanbod-, review-, beschikbaarheids- en Productschema-signalen zijn belangrijker dan alleen een dun bestand.
1. Waarom AI-zoekgereedheid anders is dan de basis van SEO
Traditionele SEO vraagt of een pagina kan worden gecrawld, geïndexeerd, gerankt en aangeklikt. AI-zoekopdrachten voegen daar een andere laag aan toe: kan het systeem het merk, het product, het aanbod, de prijs, reviews, beschikbaarheid, beleid en entiteitsrelaties goed genoeg begrijpen om vragen te beantwoorden of producten aan te bevelen?
Dat verschil is belangrijk voor DTC, omdat e-commercepagina’s vol zitten met details die voor mensen makkelijk zijn, maar voor machines rommelig kunnen zijn. Een shopper kan een productpagina bekijken en de productnaam, prijs, maat, abonnementsoptie, korting, reviews, voorraadstatus en retourbeleid begrijpen. Een crawler of AI-agent moet die feiten consequent uitgedrukt zien.
Metadata helpt. Open Graph helpt. Canonical-tags helpen. llms.txt kan crawlers helpen belangrijke content te vinden. Maar productniveau-structuur is de echte test. Als een AI-shoppingassistent vijf eiwitpoeders, huidverzorgingsproducten, kaarsen, jurken of koffie-abonnementen vergelijkt, heeft die gestructureerde feiten nodig. Zonder die feiten kan het merk wel zichtbaar zijn, maar niet betrouwbaar worden begrepen.
Dit rapport scheidt vier gereedheidslagen:
- AI-bestandslaag: of llms.txt bestaat en of het ontbreekt, een soft 404 is, platform-default, handmatig licht of handmatig gestructureerd is.
- Laag met algemene gestructureerde data: JSON-LD, Organization, WebSite, BreadcrumbList en Product-schema.
- Productpaginalaag: Product-schema, aanbod- of prijssignalen, review- of beoordelingssignalen en beschikbaarheidssignalen.
- Metadatalaag: canonical, meta description, Open Graph-afbeelding, Twitter-kaart, hreflang en vergelijkbare machineleesbare context.
Het gelaagde model is belangrijk, omdat het voorkomt dat je een oppervlakkige conclusie trekt. Een merk met llms.txt maar zonder productfeiten is minder klaar dan het lijkt. Een merk zonder llms.txt maar met rijke productpagina-schema’s kan beter begrijpelijk zijn dan de bestandslaag doet vermoeden.
2. Het llms.txt-verhaal: een dunne laag, grotendeels gemaakt door platforms
De llms.txt-audit leverde vijf kwaliteitsbuckets op:
| Kwaliteitsbucket | Domeinen | Interpretatie |
|---|---|---|
| Platform default | 629 | Een standaard door het platform gegenereerd bestand, meestal dun maar geldig |
| Ontbrekend | 388 | Geen bruikbaar bestand gevonden |
| Soft 404 | 133 | Een misleidende of niet-nuttige respons |
| Handmatig licht | 57 | Door mensen gemaakt of aangepast bestand, maar beperkt van structuur |
| Handmatig gestructureerd | 31 | Substantieel handmatig bestand met koppen, links, product- of beleidsbegrippen |
Dit is de belangrijkste nuance in het rapport. Op het eerste gezicht lijkt de adoptie van llms.txt sterk, omdat platform-default-bestanden vaak voorkomen. Maar platform default is niet hetzelfde als een doordachte AI-zoekstrategie. Het is vaak slechts een basislaag voor verwijzing.
Dat maakt platform-default-bestanden niet waardeloos. Ze kunnen crawlers helpen belangrijke paden te vinden. Ze laten ook zien hoe snel beslissingen op platformniveau de markt kunnen bewegen. Een platform kan honderden winkels een nieuw machineleesbaar bestand geven voordat de meeste merkteams überhaupt over AI-zoekoperaties hebben nagedacht.
Maar de bucket handmatig gestructureerd is veel kleiner: 31 domeinen. Voorbeelden in de audit zijn handmatig gestructureerde bestanden van merken zoals Dermalogica, Ad Hoc Atelier, DKNY en verschillende ai_ready-voorbeelden zoals Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods en Three Ships Beauty. Dit zijn nuttige positieve voorbeelden, omdat ze laten zien wat het betekent om verder te gaan dan een standaardbestand: meer links, meer koppen, meer producttermen, meer beleidsbegrippen en meer doordachte structuur.
Ook de soft-404-bucket is belangrijk. Een soft 404 betekent dat het verzoek iets teruggeeft, maar geen bruikbaar llms.txt-bestand. Dat kan eenvoudige audits misleiden. Voor AI-zoekgereedheid is alleen aanwezigheid niet genoeg. Kwaliteitscontroles zijn belangrijk.
3. Productniveau-structuur is de echte kloof
De sterkste kloof in de data zit in Product-schema.
Product-schema op de homepage komt slechts voor op 0,9% van de beoordeelde domeinen. Product-schema op productpagina’s komt voor op 39,2% van de beoordeelde domeinen waar productpagina’s zijn getest. Prijssignalen op productpagina’s komen voor bij 48,1%, en review- of beoordelingssignalen bij 43,5%.
Deze cijfers vertellen een duidelijk verhaal. Basis productfeiten zijn niet consistent machineleesbaar, zelfs wanneer het merk een e-commercewinkel heeft.
Dat is belangrijk, omdat AI-search en AI-shopping waarschijnlijk helderheid belonen. Als een productpagina Product-schema, aanbiedingen, prijs, beschikbaarheid, reviewsignalen en beleidslinks bevat, geeft dat machines betrouwbaardere feiten. Als die feiten verstopt zitten in JavaScript, inconsistente templates, afbeeldingen of dynamische widgets, kunnen machines ze verkeerd begrijpen of negeren.
De kloof in gereedheid gaat niet alleen over ranking. Het gaat over representatie. Wanneer AI-systemen een productcategorie samenvatten, opties vergelijken, vragen beantwoorden als "het beste voor" of shoppingaanbevelingen genereren, zijn merken met schonere productfeiten makkelijker nauwkeurig op te nemen.
Positieve voorbeelden uit de ai_ready-groep maken dat duidelijk:
- Mokobara haalde in de output de hoogste score met 83.
- Magic Mind, Le Petit Ballon en Maine Lobster Now scoorden elk 81.
- Yo Mama's Foods scoorde 80.
- La Maison Convertible, Unbloat, Vinocheepo en NuRange Coffee scoorden 79.
- Three Ships Beauty scoorde 77.
- Manukora scoorde 75.
Deze voorbeelden bestrijken meerdere categorieën. AI-gereedheid is niet alleen een beautykwestie of alleen een techkwestie. Het is relevant voor food, wellness, meubels, kleding, specialty producten en elke categorie waarin een shopper een AI-systeem om aanbevelingen, vergelijkingen of uitleg kan vragen.
4. AI-gereedheidstiers: de meeste merken zitten nog onder de streep
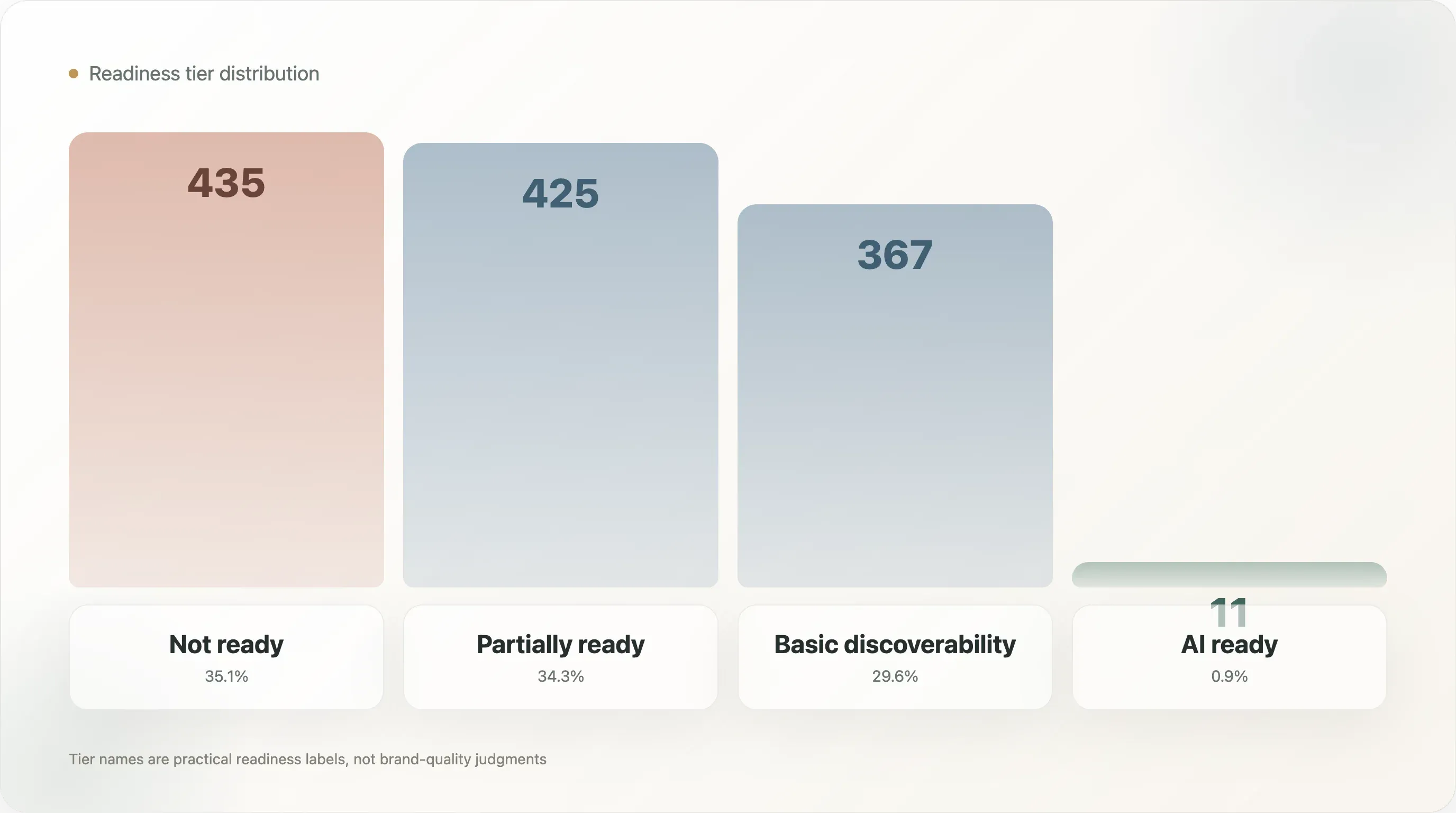
De verdeling per tier is:
| Tier | Domeinen | Aandeel van de steekproef |
|---|---|---|
| Niet gereed | 435 | 35,1% |
| Gedeeltelijk gereed | 425 | 34,3% |
| Basisvindbaarheid | 367 | 29,6% |
| AI-gereed | 11 | 0,9% |
De namen zijn bewust praktisch gekozen. Niet gereed betekent niet dat het merk slecht is. Het betekent dat de publieke signalen die dit model gebruikt onvoldoende AI-zoekgereedheid laten zien. Gedeeltelijk gereed betekent dat sommige onderdelen aanwezig zijn, maar belangrijke lagen ontbreken. Basisvindbaarheid betekent dat het merk beter zichtbaar is voor machines, maar nog steeds productniveau-volledigheid kan missen. AI-gereed betekent dat het domein een sterkere combinatie laat zien van bestandskwaliteit, gestructureerde data, productfeiten en metadata.
Slechts 11 domeinen haalden de hoogste tier. Dat is de kop, maar het nuttigere inzicht is de vorm van het midden. De steekproef is bijna gelijk verdeeld over niet gereed, gedeeltelijk gereed en basisvindbaarheid. De markt is niet leeg. Ze is in transitie. Veel merken hebben wel signalen, maar weinig hebben een compleet systeem.
Dat creëert een kans op korte termijn. AI-zoekgereedheid is nog vroeg genoeg dat een merk van gemiddeld naar sterk kan bewegen met relatief praktisch werk: llms.txt verbeteren, schema valideren, productfeiten blootleggen, metadata opschonen en productpagina’s makkelijker machineleesbaar maken.
5. Patroon per categorie: beauty en apparel lopen voorop, maar geen enkele categorie is klaar
Categorieclassificatie is richtinggevend, niet exact. Toch laat de categorietabel bruikbare patronen zien:
| Categorie | Steekproef | Gem. AI-gereedheid | Handmatig of gestructureerd llms | Schema op productpagina’s | Schema-rate op productpagina’s |
|---|---|---|---|---|---|
| Beauty & Skincare | 98 | 46,2 | 3 | 56 | 57,1% |
| Apparel & Footwear | 149 | 45,7 | 6 | 79 | 53,0% |
| Jewelry & Accessories | 34 | 44,5 | 0 | 20 | 58,8% |
| Pet | 15 | 43,5 | 0 | 8 | 53,3% |
| Baby & Kids | 27 | 42,6 | 1 | 15 | 55,6% |
| Food & Beverage | 118 | 42,5 | 5 | 58 | 49,2% |
| Home & Furniture | 48 | 42,3 | 0 | 23 | 47,9% |
| Health & Wellness | 58 | 40,7 | 6 | 27 | 46,6% |
| Outdoor & Sports | 49 | 39,8 | 1 | 23 | 46,9% |
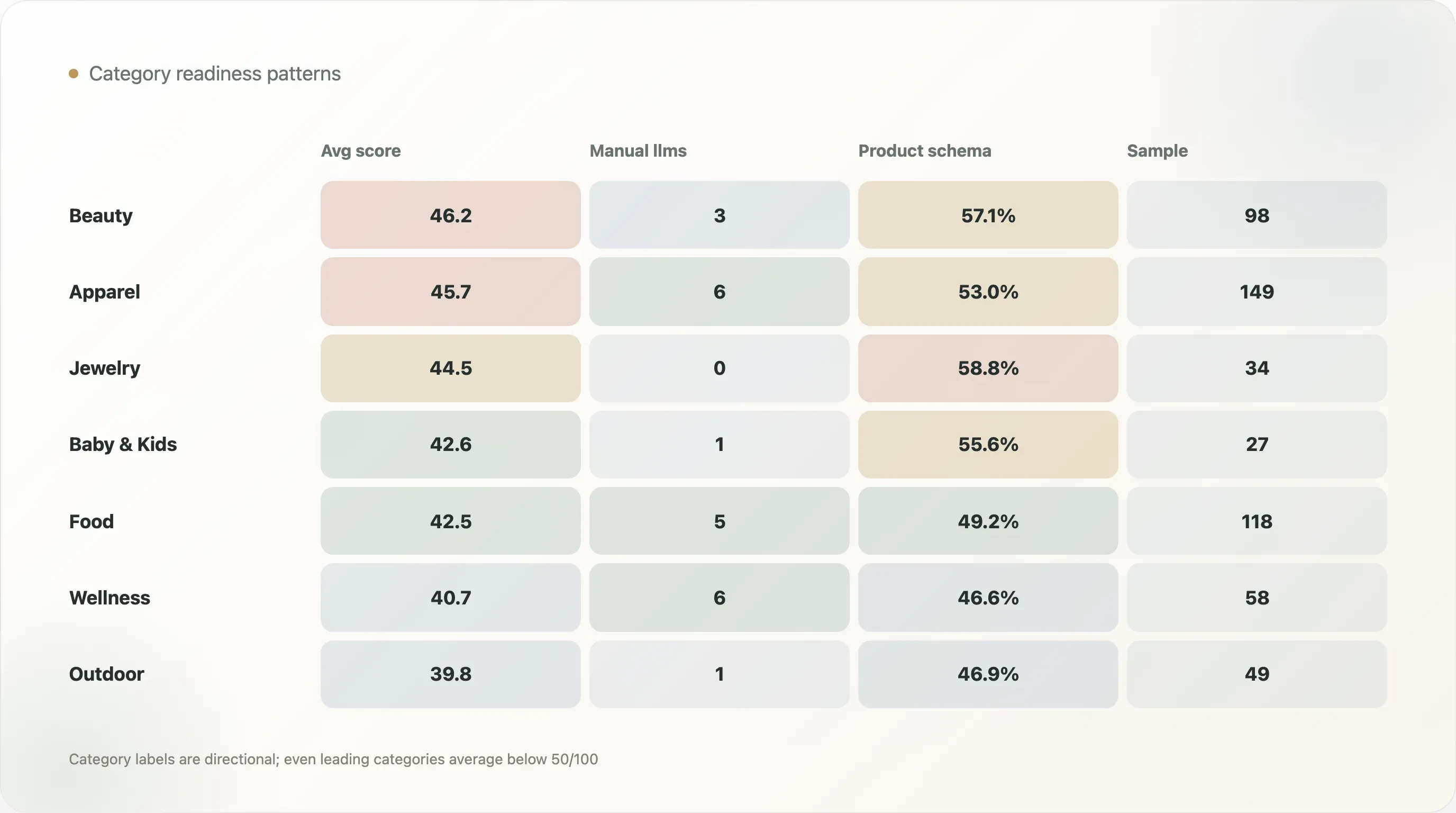
Beauty & Skincare heeft de hoogste gemiddelde AI-gereedheidsscore met 46,2. Apparel & Footwear volgt met 45,7. Deze categorieën hebben vaak sterke e-commerce-templates, rijke productcatalogi, reviews, varianten, visuele assets en contentbehoeften. Ze kunnen sneller profiteren van gestructureerd productwerk.
Jewelry & Accessories heeft een hoge schema-rate op productpagina’s van 58,8%, maar in de categorietabel geen detecties van handmatig of gestructureerd llms.txt. Dat laat zien waarom gereedheid gelaagd moet worden bekeken. Een categorie kan sterk zijn in productschema en zwak in AI-bestandskwaliteit.
Food & Beverage bevat verschillende sterke positieve voorbeelden, waaronder Maine Lobster Now, Yo Mama's Foods, NuRange Coffee en Manukora. Dat is belangrijk, omdat food- en beverage-producten vaak duidelijke feiten vereisen: ingrediënten, voedingswaarden, portiegrootte, abonnement, herkomst, verzending, opslag, reviews en beschikbaarheid. AI-systemen kunnen die details alleen nauwkeurig weergeven als de site ze netjes aanbiedt.
Health & Wellness heeft een rate voor handmatig of gestructureerd llms van 10,3%, de hoogste onder de grote categorieën in de tabel, maar een gemiddelde score van 40,7. Dat suggereert dat sommige merken in deze categorie actief experimenteren met AI-leesbare bestanden, terwijl de productpaginastructuur nog veel ruimte heeft voor verbetering. Gezien de vertrouwens- en educatielast in wellness zou deze categorie een van de meest actieve moeten zijn in gestructureerde feiten.
Geen enkele categorie is klaar. Zelfs de leidende categorieën scoren gemiddeld onder de 50/100. Dat maakt content over AI-gereedheid per categorie een sterke kans voor SEO-schrijvers en consultants.
6. Hoe goed eruitziet: positieve patronen van AI-gereed gemaakte merken
De ai_ready-groep is klein, maar nuttig omdat hij patronen laat zien die het waard zijn om te kopiëren.
Mokobara scoorde 83, de hoogste in de output. Het is een voorbeeld van sterke gecombineerde gereedheid in plaats van een overwinning op slechts één signaal.
Magic Mind, Le Petit Ballon en Maine Lobster Now scoorden elk 81 en vallen in de bucket handmatig gestructureerd llms. Dat is belangrijk, omdat het laat zien dat er bewust aan de bestandslaag is gewerkt, niet alleen aan platform-defaults.
Yo Mama's Foods scoorde 80, eveneens met handmatig gestructureerd llms. Foodmerken kunnen profiteren van een AI-leesbare structuur, omdat AI-systemen vragen kunnen krijgen over ingrediënten, smaak, gebruikssituaties, recepten, dieetgeschiktheid en vergelijkingen.
Three Ships Beauty scoorde 77 met handmatig gestructureerd llms. Beauty is een ideale categorie voor gestructureerde AI-gereedheid, omdat shoppers vragen stellen over huidtype, ingrediënten, routines, textuur, reviews en alternatieven.
Manukora scoorde 75. Honing en aan wellness verwante foodproducten vereisen vaak uitleg over herkomst, kwaliteit, voordelen, certificeringen en gebruik, waardoor gestructureerde product- en beleidsignalen waardevol zijn.
De les is niet dat elk merk er hetzelfde uit moet zien. De les is dat AI-gereedheid een systeem is:
- Een nuttig llms.txt-bestand
- Schone metadata
- Gestructureerde organisatie- en websitegegevens
- Schema op productpagina’s
- Prijs- en aanbodsignalen
- Review- of beoordelingssignalen
- Beschikbaarheidsignalen
- Duidelijkheid over beleid en support
Elke laag helpt. De combinatie zorgt voor gereedheid.
7. Waarom llms.txt alleen niet genoeg is
llms.txt is een handig shorthand geworden voor AI-gereedheid. Dat is begrijpelijk, omdat het zichtbaar, makkelijk te controleren en nieuw genoeg is om strategisch te voelen. Maar dit onderzoek laat zien waarom het niet als het hele verhaal moet worden gezien.
Een platform-default llms.txt-bestand kan een basisdeur creëren. Het kan crawlers naar belangrijke pagina’s wijzen. Het kan machines vertellen dat de site een AI-leesbaar ingangspunt heeft. Maar als de productpagina’s productfeiten niet duidelijk blootleggen, leidt die deur naar een rommelige kamer.
Het AI-zoekprobleem is niet alleen: "kan de crawler de site vinden?" Het is:
- Kan de crawler het product identificeren?
- Kan hij het merk identificeren?
- Kan hij de prijs parseren?
- Kan hij de beschikbaarheid parseren?
- Kan hij reviews of beoordelingen identificeren?
- Kan hij productcontent onderscheiden van marketingcontent?
- Kan hij beleid begrijpen?
- Kan hij varianten vergelijken?
- Kan hij de juiste canonieke pagina citeren?
llms.txt helpt met navigatie en prioritering. Gestructureerde productdata helpt met begrip. AI-gereedheid heeft beide nodig.
8. Het operator-handboek: hoe je AI-zoekgereedheid verbetert
Voor DTC- en e-commerce teams is de praktische workflow eenvoudig.
Stap 1: Controleer de AI-bestandslaag. Heeft het domein llms.txt? Is het echt, of is het een soft 404? Is het platform-default, handmatig licht of gestructureerd? Verwijst het naar nuttige pagina’s?
Stap 2: Audit metadata. Controleer canonical-tags, meta descriptions, Open Graph-afbeeldingen, Twitter Cards, hreflang waar relevant en de mobiele viewport. Niet glamoureus, wel belangrijk voor contextopbouw door machines.
Stap 3: Valideer JSON-LD. Controleer Organization-, WebSite-, BreadcrumbList- en Productschema. Productschema is de belangrijkste e-commercekloof.
Stap 4: Audit productpagina’s, niet alleen de homepage. AI-shopping zal productpagina’s belangrijk vinden. Controleer productnaam, beschrijving, afbeelding, prijs, aanbod, beschikbaarheid, SKU, reviews, beoordelingen, varianten en retourbeleid.
Stap 5: Maak productfeiten stabiel. Verstop kritieke productfeiten niet alleen in afbeeldingen, tabs die niet netjes renderen of JavaScript-widgets die crawlers mogelijk niet parseren.
Stap 6: Verbeter de duidelijkheid van beleid. Verzending, retouren, abonnementsvoorwaarden, garanties, certificeringen en veiligheidsclaims moeten makkelijk te vinden en makkelijk te parseren zijn.
Stap 7: Test opnieuw na templatewijzigingen. Schema breekt vaak bij redesigns, themawijzigingen, app-wijzigingen en headless migraties. Behandel gestructureerde data als onderdeel van QA.
Stap 8: Eigenaarschap van het systeem. AI-gereedheid mag niet alleen bij SEO liggen. Het raakt e-commerce, product, content, engineering, legal en customer support.
9. Waar SEO- en contentteams naar kunnen verwijzen
Dit onderzoek levert meerdere sterke insteekpunten op voor citaten:
"Slechts 11 van de 1.238 beoordeelde DTC-domeinen haalden de AI-gereed-tier." Dit is de breedste haak voor gereedheid.
"llms.txt komt vaak voor, maar is meestal door het platform gegenereerd." De bucket platform default bevat 629 domeinen, terwijl handmatig gestructureerde bestanden slechts op 31 voorkomen.
"Product-schema op de homepage komt slechts voor op 0,9% van de beoordeelde domeinen." Dit is de scherpste kloof in gestructureerde data.
"Product-schema op productpagina’s komt voor bij 39,2% waar productpagina’s zijn getest." Dit voegt nuance toe: productpagina’s doen het beter dan homepages, maar zijn nog steeds onvolledig.
"Beauty en Apparel lopen voorop in de categorietabel, maar scoren nog steeds gemiddeld onder 50/100." Dit creëert een categorie-specifieke invalshoek.
"AI-gereedheid is gelaagd." Dit is het belangrijkste educatieve punt voor lezers die llms.txt anders gelijkstellen aan gereedheid.
De kanttekening is essentieel: de data weerspiegelt publieke websitesignalen in deze steekproef, niet de totale adoptie in de sector en niet de interne zoekprestaties.
10. Wat AI-shopping verandert voor DTC-teams
Traditionele e-commerce-ontdekking was gebouwd rond pagina’s, rankings, advertenties en klikken. Een shopper zocht, vergeleek resultaten, opende pagina’s, las reviews en nam beslissingen. AI-shopping en antwoordsystemen comprimeren dat traject. Een shopper kan vragen om "de beste saus met weinig suiker voor doordeweekse pasta", "een carry-on rugzak onder de €200 met goede reviews" of "een milde cleanser voor de gevoelige huid zonder parfum". Het AI-systeem kan opties samenvatten voordat de shopper ooit een merkpagina ziet.
Dat verandert de taak van de productpagina. De pagina moet mensen nog steeds overtuigen, maar moet het product ook duidelijk genoeg beschrijven voor machines om het te vergelijken. Merktoon is niet genoeg. Mooie beelden zijn niet genoeg. Een slimme productnaam is niet genoeg. De machine heeft feiten nodig: wat het is, voor wie het is, wat het kost, of het beschikbaar is, welke varianten er zijn, wat reviews zeggen, welke claims worden ondersteund, welke ingrediënten of materialen belangrijk zijn en welk beleid van toepassing is.
Daarom is productniveau-structuur belangrijker dan een generiek AI-bestand. llms.txt kan een crawler helpen begrijpen waar die moet kijken. Productschema en schone productfeiten helpen hem begrijpen wat hij heeft gevonden.
Het risico voor DTC-merken is niet alleen buitengesloten worden. Het is verkeerd worden weergegeven. Als een productpagina onduidelijk is, kan een AI-antwoord het verkeerde kenmerk samenvatten, een belangrijk onderscheid missen, een belangrijk beleidsdetail weglaten of het product oneerlijk vergelijken met concurrenten die beter gestructureerd zijn. In die zin is AI-gereedheid deels een kwestie van merkbescherming.
Voor categorieën met complexe afwegingspaden liggen de belangen hoger. Beauty-shoppers vragen naar huidtype, ingrediënten, routines, gevoeligheid en resultaten. Food-shoppers vragen naar voedingswaarden, allergenen, herkomst, smaak, recepten en dieetgeschiktheid. Apparel-shoppers vragen naar pasvorm, maat, materialen, retouren en styling. Wellness-shoppers vragen naar bewijs, gebruik, veiligheid en vertrouwen. Home-shoppers vragen naar afmetingen, materialen, levering, montage en duurzaamheid. Dit zijn net zo goed machineleesbare-contentproblemen als marketingproblemen.
De kans is dat de meeste merken nog vroeg zijn. De gemiddelde gereedheidsscore is slechts 36,4/100, en slechts 11 domeinen haalden de ai_ready-tier. Een merk hoeft niet te wachten op een complete site-rebuild. Het kan beginnen met templates, schema, duidelijker beleid en productfeiten.
11. Een AI-gereedheidsplan per afdeling
AI-gereedheid hoort niet alleen bij SEO. Het raakt meerdere teams.
SEO is eigenaar van vindbaarheid en schema-validatie. SEO-teams moeten canonical-tags, metadata, gestructureerde data, Productschema, breadcrumbs, hreflang en crawlbaarheid auditen. Ze moeten ook monitoren of Productschema overeind blijft na themawijzigingen en app-updates.
E-commerce is eigenaar van productpaginafeiten. Productnamen, prijzen, varianten, beschikbaarheid, bundels, abonnementen, reviews, verzendvoorwaarden en retourdetails moeten helder en consistent zijn. Als die feiten verspreid zijn over widgets, tabs, afbeeldingen en scripts, kunnen machines moeite hebben.
Content is eigenaar van uitlegdiepte. AI-systemen belonen pagina’s die vragen duidelijk beantwoorden. Koopgidsen, vergelijkingstabellen, uitleg over ingrediënten, pagina’s voor gebruikssituaties, maatadvies en FAQ-secties helpen zowel mensen als machines.
Engineering is eigenaar van implementatiekwaliteit. Schema moet geldig, stabiel en template-gedreven zijn. Productfeiten mogen niet volledig afhangen van kwetsbare client-side rendering. Productpaginatemplates moeten na releases worden getest.
Legal en compliance zijn eigenaar van claims. Als een product gezondheids-, duurzaamheids-, veiligheids-, ingrediënt- of prestatieclaims maakt, moeten die accuraat, onderbouwbaar en eenvoudig te interpreteren zijn. AI-systemen kunnen onduidelijke claims versterken.
Customer support is eigenaar van terugkerende vragen. Supporttickets laten zien wat shoppers en AI-systemen kunnen vragen: levertijd, pasvorm, ingrediënten, compatibiliteit, retouren, opzeggen van abonnementen, onderhoudsinstructies en productvergelijkingen. Die vragen moeten input geven voor productpaginacontent.
Leadership is eigenaar van prioritering. AI-gereedheid concurreert met veel andere projecten. De businesscase is eenvoudig: gestructureerde productfeiten ondersteunen SEO, AI-search, productfeeds, betaalde shopping, onsite search, support en conversie. Dit is niet alleen een AI-project.
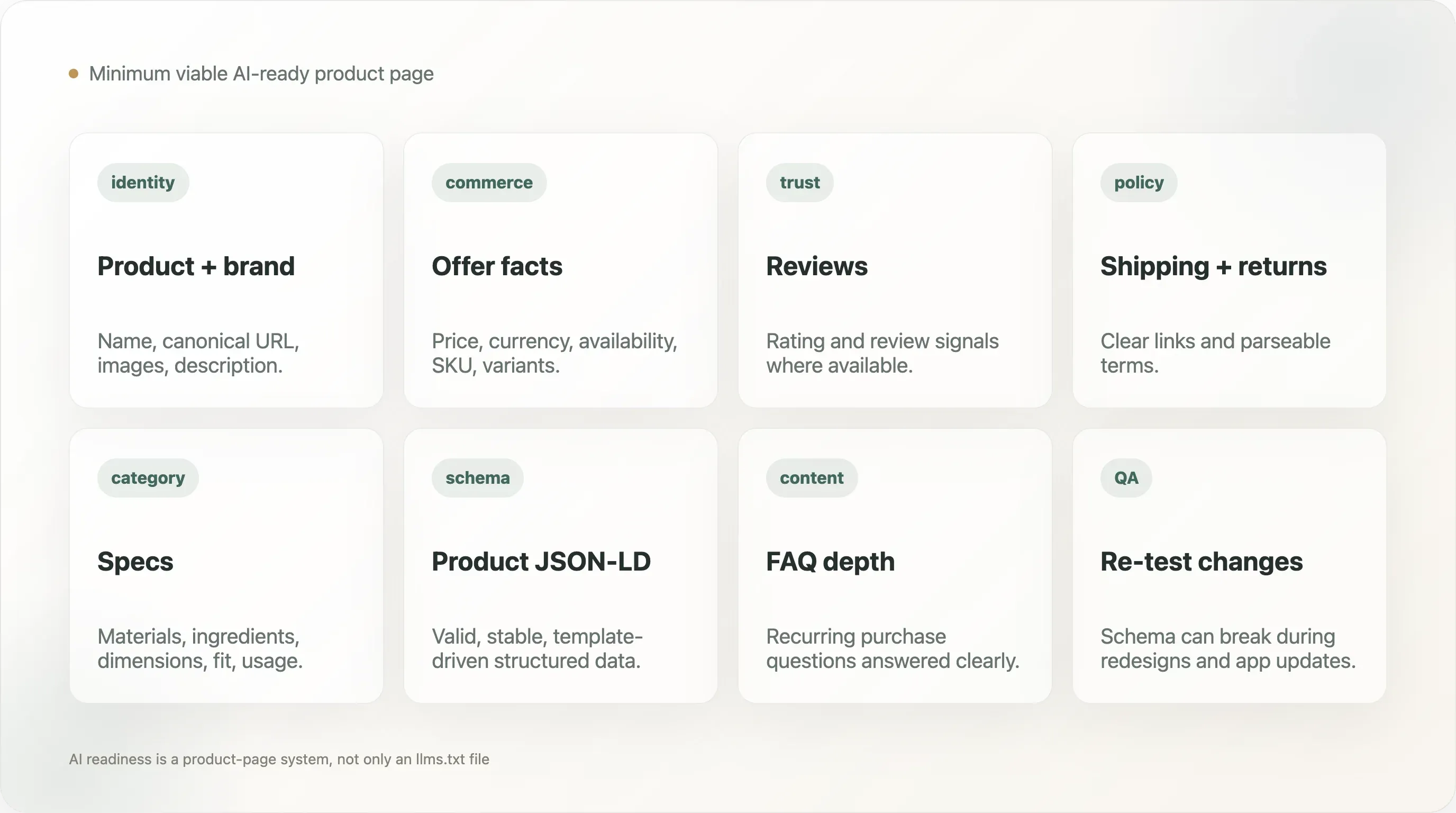
12. De minimaal haalbare AI-ready productpagina
Een praktische DTC-productpagina moet het volgende blootleggen:
- Productnaam
- Merknaam
- Canonieke URL
- Productbeschrijving
- Productafbeeldingen
- Prijs
- Valuta
- Beschikbaarheid
- Variantinformatie
- SKU of product-ID waar relevant
- Review- of beoordelingssignalen waar beschikbaar
- Aanbiedingsdetails
- Links naar verzend- en retourbeleid
- Feiten over materiaal, ingrediënten of specificaties waar relevant voor de categorie
- FAQ- of supportcontent voor terugkerende koopvragen
De pagina moet ook geldig Product-schema bevatten en voorkomen dat kritieke feiten alleen verborgen zitten in afbeeldingen of scripts die crawlers mogelijk niet parseren. Dit vereist geen saaie productpagina’s. Het vereist een scheiding tussen overtuigend design en betrouwbare gestructureerde feiten.
Voor veel merken is de snelste winst niet het schrijven van een lang AI-strategiedocument. Het is het valideren van tien belangrijke productpagina’s, schema repareren en ervoor zorgen dat de belangrijkste productfeiten zichtbaar zijn in HTML en gestructureerde data.
Methode
Dit onderzoek gebruikt de DTC dual-report-dataset die is verzameld op 11 mei 2026. Het beoordeelt 1.238 domeinen met behulp van master.csv, detection.csv, seo_signals.csv, ruwe llms.txt-bestanden en ruwe HTML van productpagina’s waar beschikbaar.
Het scoringsmodel scheidt vier lagen:
- AI-bestandslaag: bestaan en kwaliteit van llms.txt.
- Laag met algemene gestructureerde data: JSON-LD, Organization, WebSite, BreadcrumbList, Product en gerelateerde gestructureerde signalen.
- Productpaginalaag: Product-schema, aanbod- of prijssignalen, review- of beoordelingssignalen en beschikbaarheidssignalen.
- Metadatalaag: canonical, meta description, Open Graph-afbeelding, Twitter Card, hreflang en gerelateerde paginacontext.
Het model produceert een AI-gereedheidsscore van 0 tot 100 en deelt domeinen in een van vier tiers in: niet gereed, gedeeltelijk gereed, basisvindbaarheid en ai_ready.
Kanttekeningen
-
AI-gereedheid is niet hetzelfde als AI-verkeer. De score meet geen daadwerkelijke referrals vanuit AI-zoeksystemen of shopping agents.
-
Publieke signalen vormen een ondergrens. Sommige gestructureerde data kan dynamisch laden of op een manier verschijnen die de crawl niet heeft vastgelegd.
-
De kwaliteit van llms.txt is heuristisch. Handmatig gestructureerde bestanden worden geïdentificeerd aan de hand van observeerbare bestandskenmerken zoals koppen, links, producttermen en beleidsbegrippen.
-
Productpaginadetectie is afhankelijk van uitgevoerde productpagina-fetches. Percentages voor Productschema op productpagina’s gelden waar productpagina’s zijn getest en beschikbaar waren.
-
De steekproef is geen volledige DTC-telling. Ze is scheef richting merken die zichtbaar zijn in ecosystemen van e-commerce-tools en publieke DTC-lijsten.
-
Categorielabels zijn richtinggevend. Ze zijn nuttig voor brede vergelijking, maar geen exacte taxonomie.
-
AI-zoekstandaarden zijn nog in ontwikkeling. Het scoringsmodel is ontworpen als een praktische benchmark voor 2026, niet als een permanente definitie.
Opmerkingen voor reproduceerbaarheid
De oplevermap bevat:
analyze_ai_search_readiness.py— scoringsscript dat werd gebruikt om DTC-domeinen te evalueren op basis vanllms.txt, gestructureerde data, signalen op productpagina’s en metadatasignalen.ai_search_readiness_scores.csv— AI-gereedheidsscores op domeinniveau, tiers en component-signalen.llms_quality_audit.csv— kwaliteitsaudit vanllms.txtop domeinniveau, inclusief classificaties als platform-default, soft-404, ontbrekend, handmatig licht en handmatig gestructureerd.category_ai_readiness.csv— vergelijking van AI-gereedheid per categorie.top_ai_ready_brands.csv— domeinen met de hoogste scores voor redactionele beoordeling en voorbeeldselectie.lowest_ai_ready_brands.csv— domeinen met de laagste scores voor kloofanalyse en redactionele beoordeling.summary.json— kernstatistieken uit dit rapport, waaronder steekproefgrootte, tier-aantallen, gemiddelde score, mediaanscore en percentages van productpaginassignalen.
Correcties op de methode, datasetproblemen en vervolganalyses zijn welkom via support@thunderbit.com. Dit rapport is gepubliceerd onafhankelijk van elke commerciële positie die Thunderbit inneemt; wij bouwen een AI-aangedreven webscraper en hebben een structureel belang bij het feit dat openbare e-commercewebsites makkelijker en nauwkeuriger te begrijpen zijn voor mensen, zoekmachines en AI-agents. De benchmark is gebaseerd op 1.238 beoordeelde DTC-domeinen op basis van publieke websitedata die op 11 mei 2026 zijn verzameld. De data in dit rapport staat op zichzelf. — Het Thunderbit-onderzoeksteam, mei 2026.