
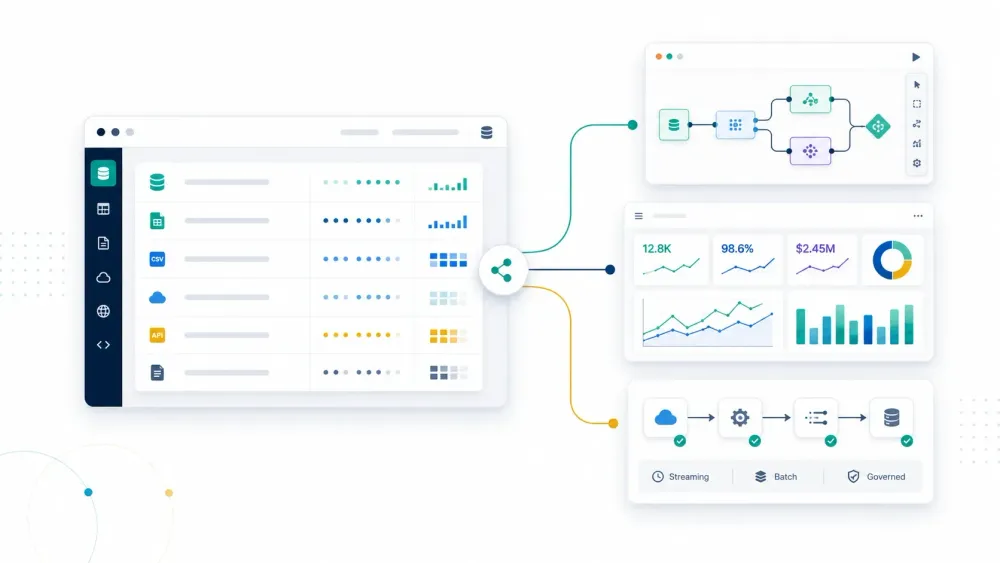
Bedrijven hebben in 2026 geen tekort aan data. Ze hebben een tekort aan workflow-fit. Het World Economic Forum merkte op dat de wereldwijde dataproductie in 2025 naar verwachting 181 zettabyte zou bereiken, terwijl IBM zegt dat naar schatting 68% van de bedrijfsdata ongebruikt blijft. Precies die kloof maakt software voor datamining nog steeds relevant: niet als buzzword, maar als de praktische laag die ruwe records, documenten, websitegegevens en eventstreams omzet in patronen waar je echt iets aan hebt.
IBM’s definitie blijft de duidelijkste: datamining gebruikt machine learning en statistische analyse om bruikbare informatie uit grote datasets te halen. In de praktijk betekent dat dat kopers nu naar een bredere stack kijken dan de oude lesboekdefinitie doet vermoeden. Sommige teams hebben visuele modelleertools nodig. Andere teams hebben gereguleerde enterprise analytics nodig. Weer andere teams hebben cloud-schaal machine learning en streaming-infrastructuur nodig. En sommige teams moeten gewoon eerst rommelige webdata vastleggen voordat analyse überhaupt kan beginnen.
Snelle keuzes per workflow
- Wil je websitegegevens snel verzamelen voordat je ze analyseert? Begin met Thunderbit.
- Wil je een visueel no-code data science-platform? Zet Altair AI Studio en KNIME op je shortlist.
- Wil je het makkelijkste open-source startpunt om te leren of te prototypen? Kijk naar Orange en Weka.
- Wil je enterprise predictive analytics met governance? Vergelijk IBM SPSS Modeler, SAS Enterprise Miner en Spotfire Statistica.
- Wil je cloud-native ML en deployment? Bekijk Microsoft Azure Machine Learning, Dataiku en H2O.ai.
- Wil je grootschalige pipelines of in-database analytics? Richt je dan op Teradata en Google Cloud Dataflow.
Bekijk of Thunderbit bij je dataworkflow past
Wat telt in 2026 als software voor datamining?
Deze zoekterm dekt inmiddels vier verschillende aankoopbehoeften:
- Tools voor data-acquisitie: producten die je helpen ruwe data te verzamelen of te structureren voordat analyse begint.
- Visuele workflowtools: platforms waarmee analisten data kunnen opschonen, modellen kunnen bouwen en resultaten kunnen scoren zonder zwaar te coderen.
- Enterprise-suites voor statistiek en predictieve analyse: beheerde systemen voor grotere organisaties en gereguleerde teams.
- Cloud- en infrastructuurlagen: platforms die grootschalige training, deployment of realtimeverwerking ondersteunen.
Daarom is deze lijst bewust gemengd. Als je team nog steeds uren kwijt is aan het kopiëren van velden uit websites, kan een browser-first tool voor datavastlegging meer zakelijke waarde opleveren dan een geavanceerde modelleersuite die je nooit volledig gaat gebruiken. Andersom geldt hetzelfde: als je knelpunt zit in gecontroleerde modeluitrol of verwerking op datawarehouse-schaal, dan is juist een andere aanpak logisch.
Als je eerst één korte oriëntatievideo wilt zien voordat je tools vergelijkt, dan is dit IBM-overzicht nog steeds de beste compacte introductie, omdat het laat zien waar datamining past ten opzichte van analytics, machine learning en procesverbetering:
Snelle vergelijkingstabel: beste software voor datamining in 2026
| Tool | Beste voor | Wat eruit springt | Prijsindicatie |
|---|---|---|---|
| Thunderbit | Zakelijke teams die eerst ruwe webdata nodig hebben voordat ze analyseren | AI-veldvoorstellen, subpagina’s, paginering, export naar Sheets / Excel / Airtable / Notion | Gratis plan; betaalde self-service niveaus; zakelijke abonnementen |
| Altair AI Studio | Visuele ML-workflows zonder zwaar coderen | Drag-and-drop ontwerp, AutoML, interactieve datavoorbereiding; voorheen RapidMiner Studio | Gratis proefperiode; commerciële edities |
| KNIME | Open-source workflow-analytics en automatisering | Op knooppunten gebaseerde pipelines, sterke community, brede uitbreidingen | Gratis platform; betaalde zakelijke producten |
| Orange | Beginners en visuele datamining met focus op onderwijs | Zeer toegankelijke visuele widgets en verkenningsworkflows | Gratis en open source |
| Weka | Experimenteren met algoritmen en onderwijs | Grote bibliotheek met klassieke ML-methoden in een lichte GUI | Gratis en open source |
| IBM SPSS Modeler | Teams voor enterprise predictive analytics | Visuele streams, tekstanalyse, deployment met aandacht voor governance | Offertebasis / enterprise |
| SAS Enterprise Miner | Gereguleerde sectoren en SAS-centrische teams | Volwassen modeldiepgang, verwerking van grote datasets, SAS-integratie | Offertebasis / enterprise |
| Azure Machine Learning | Cloud-analytics en ML voor Microsoft-first teams | AutoML, MLOps, Azure-integratie, beheerde deployment | Cloudprijs op basis van gebruik |
| Alteryx | Analisten die prep en self-service analytics automatiseren | Drag-and-drop prep, herhaalbare workflows, brede zakelijke adoptie | Proefperiode plus enterprise-prijzen |
| Spotfire Statistica | Statistische diepgang plus enterprise-controles | Geavanceerde analytics, herbruikbare workflows, compliancegerichte monitoring | Offertebasis / enterprise |
| Teradata | In-database analytics op enorme schaal | Sterke prestaties op grote enterprise datasets en beheerde data-omgevingen | Enterprise / contract |
| Rattle | Leren op basis van R en goedkoop prototypen | GUI boven R-workflows met zicht op de code | Gratis en open source |
| Dataiku | Cross-functionele data science-teams | No-code plus code-samenwerking, automatisering, governance | Gratis editie; enterprise-prijzen |
| H2O.ai | AutoML en schaalbare modelbouw | Snelle modellering, verklaarbaarheid, sterk ML-ecosysteem | Open source + enterprise-aanbod |
| Google Cloud Dataflow | Realtime en grootschalige batchverwerking van data | Beheerde Apache Beam-pipelines, autoscaling, streamingondersteuning | Cloudprijs op basis van gebruik |
De 15 beste softwaretools voor datamining voor bedrijven in 2026
Beste voor snelle dataverzameling en visuele workflow-datamining
1. Thunderbit
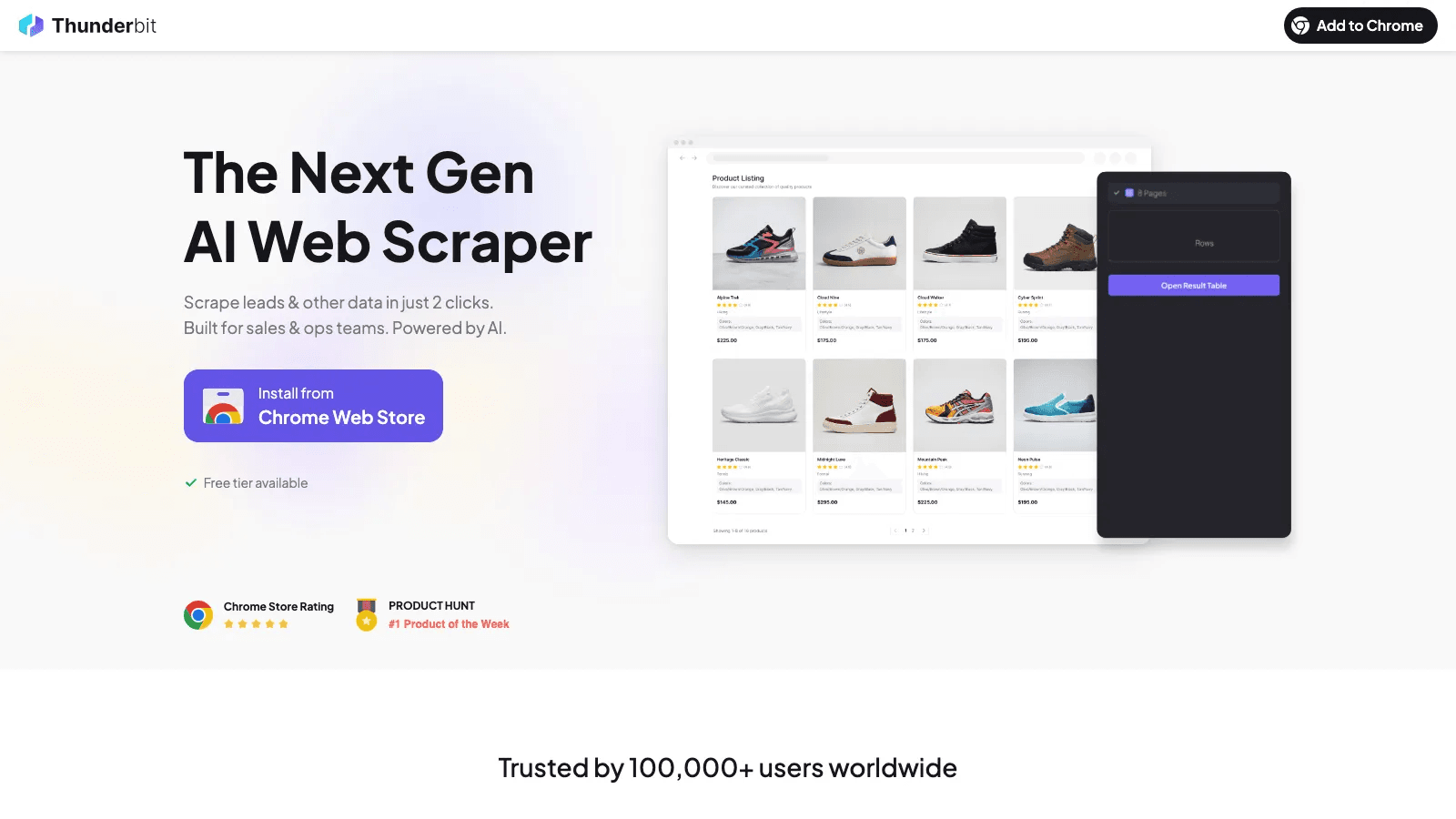
Thunderbit verdient een plek op deze lijst omdat veel zakelijke dataminingprojecten al mislukken voordat modellering überhaupt begint. De data staat op websites, in pdf’s, op interne onderzoekspagina’s, in portalen of in lijsten met veel afbeeldingen. Als je die data niet netjes kunt verzamelen, doet je analytics-stack er eigenlijk niet meer toe.
Thunderbit is op z’n sterkst wanneer het werk in de browser begint en het team snel gestructureerde output wil. Met AI-veldvoorstellen, subpagina-scraping, verwerking van paginering en directe exports is het een goede keuze voor sales-, ecommerce-, operations-, recruitment- en marktonderzoeksteams die niet eerst een scrapingpipeline willen bouwen.
- Beste voor: web-first data-acquisitie voor zakelijke gebruikers.
- Wat eruit springt: AI Suggest Fields, verrijking met subpagina’s, uitvoering in browser of cloud, export naar Sheets / Excel / Airtable / Notion.
- Waarom het op de lijst staat: het haalt het verzamelknelpunt weg dat downstream analyse blokkeert.
- Prijsindicatie: gratis plan, betaalde self-service plannen en zakelijke opties zijn beschikbaar.
Probeer Thunderbit AI Web Scraper gratis
2. Altair AI Studio
Altair AI Studio is een van de belangrijkste veranderingen om scherp te hebben als je deze categorie kent van oudere overzichten: het is de huidige productnaam voor wat veel kopers nog kennen als RapidMiner Studio. Altair omschrijft het als een visuele data science-tool met drag-and-drop, AutoML, interactieve datavoorbereiding en ondersteuning voor zowel nieuwere AI-workflows als klassieke machine learning.
Het blijft een sterke keuze voor teams die serieuze modelleercapaciteit willen zonder elke workflow in notebooks te bouwen. Vergeleken met puur educatieve tools biedt het een betere brug naar herhaalbaar zakelijk gebruik.
- Beste voor: analisten en domeinexperts die begeleide visuele ML-workflows willen.
- Wat eruit springt: drag-and-drop-canvas, AutoML, interactieve voorbereiding, brede dataverbindingen.
- Let op: de commerciële positionering is sterker dan bij open-source opties, dus inkoop speelt een grotere rol.
3. KNIME Analytics Platform

KNIME is nog steeds de meest veelzijdige open-source workflowtool op deze lijst. De interface met nodes is toegankelijk genoeg voor analisten, maar diep genoeg voor teams die datavoorbereiding, statistische analyse, machine learning, automatisering en uitbreidingen in één herhaalbare pipeline willen combineren.
KNIME werkt vooral goed wanneer transparantie belangrijk is. Gebruikers kunnen elke stap van een workflow inspecteren, delen en uitbreiden met integraties voor Python, R, databases en andere tooling.
- Beste voor: open-source-first teams en analisten met veel workflowbehoefte.
- Wat eruit springt: herbruikbare pipelines, groot ecosysteem van uitbreidingen, sterke community-adoptie.
- Let op: de flexibiliteit is uitstekend, maar de interface voelt meer technisch dan lichte tools voor beginners.
4. Orange
Orange blijft de meest toegankelijke omgeving voor datamining voor gebruikers die willen leren door te kijken. De widgetgebaseerde interface maakt classificatie, clustering, visualisatie en tekstdatamining veel eenvoudiger te begrijpen dan tools die vooral op de commandoregel leunen.
Voor zakelijke teams is Orange vooral nuttig als snelle prototype- of onderwijstool, niet als zwaar gereguleerd enterpriseplatform.
- Beste voor: beginners, docenten, workshops en verkenning in een vroege fase.
- Wat eruit springt: toegankelijke visuele interface en sterke exploratieve visualisatie.
- Let op: het is geen ideale keuze voor enterprise-deployment of zware operationalisering.
5. Weka
Weka is nog steeds een klassieker, en terecht. Het biedt een grote set machine-learningalgoritmen in een compacte interface die prettig werkt voor experimenten, benchmarking en onderwijs.
De zakelijke relevantie is kleiner dan vroeger, maar het blijft waardevol voor snelle tests, leren en kleine datasets waarbij je brede algoritmekeuze wilt zonder een groter platform op te zetten.
- Beste voor: algoritmevergelijking, onderwijs en kleinschalig experimenteren.
- Wat eruit springt: brede dekking van klassieke ML en een lichte GUI.
- Let op: het voelt verouderd vergeleken met nieuwere workflowproducten en is niet gebouwd voor moderne MLOps.
Als je eerst wilt zien hoe een modern visueel workflowproduct eruitziet voordat je iets op je shortlist zet, is deze officiële walkthrough van de GUI van Altair AI Studio een handig tussenmoment:
Beste voor enterprise predictive analytics en gecontroleerde modellering
6. IBM SPSS Modeler
IBM SPSS Modeler is nog steeds de veiligste shortlist-optie voor organisaties die enterprise predictive analytics willen zonder elke analist in codezware tooling te duwen. De visuele stream-interface heeft standgehouden omdat modelbouw, voorbereiding en scoring daardoor begrijpelijk blijven voor zakelijke stakeholders.
- Beste voor: grote organisaties die toegankelijke predictive analytics met governance willen.
- Wat eruit springt: visuele streams, ondersteuning voor tekstanalyse, enterprise-deploymentopties.
- Let op: dit is een platformaankoop, geen los hulpmiddel voor een informeel team.
7. SAS Enterprise Miner
SAS Enterprise Miner blijft vooral relevant in gereguleerde en SAS-centrische omgevingen. Het is niet de meest hippe tool in deze categorie, maar wel geloofwaardig waar auditbaarheid, institutioneel vertrouwen en bestaande SAS-infrastructuur belangrijker zijn dan trends.
- Beste voor: financiële dienstverlening, zorg, verzekeringen en andere gereguleerde workflows.
- Wat eruit springt: volwassen modeldiepgang, aansluiting op het SAS-ecosysteem, verwerking van grote datasets.
- Let op: teams zonder bestaande SAS-investering vinden nieuwere platforms vaak makkelijker om in te stappen.
8. Microsoft Azure Machine Learning
Azure Machine Learning is hier de sterkste optie voor teams die al leven binnen de cloudstack van Microsoft en één omgeving willen voor experimenteren, AutoML, deployment en monitoring.
- Beste voor: Azure-first organisaties die cloud-ML en operations willen combineren.
- Wat eruit springt: AutoML, modelbeheer, deploymenttools, integratie met het Microsoft-ecosysteem.
- Let op: cloudflexibiliteit is een kracht, maar kostenbeheer wordt belangrijk zodra het gebruik groeit.
9. Alteryx

Alteryx verdient zijn plek omdat veel zakelijke datamining in de praktijk nog steeds neerkomt op het opschonen, combineren en operationaliseren van dataverwerking die vroeger in spreadsheets zat. Alteryx is al jaren de tool die analisten kopen wanneer ze af willen van steeds dezelfde pijnlijke transformatiestappen die ze elke week handmatig uitvoeren.
- Beste voor: businessanalisten die prep-intensieve workflows automatiseren.
- Wat eruit springt: drag-and-drop voorbereiding, herhaalbare analytics-workflows, brede adoptie door zakelijke gebruikers.
- Let op: krachtig, maar meestal niet de goedkoopste optie voor lichtere teams.
10. Spotfire Statistica
Spotfire Statistica blijft een van de betere opties voor organisaties die diepgaande statistische methoden en gecontroleerd operationeel gebruik nodig hebben. De huidige positionering van Spotfire legt de nadruk op geavanceerde analytics, herbruikbare workflows en governance die geschikt is voor compliance.
- Beste voor: productie, zorg, kwaliteit en compliancegerichte analytics-teams.
- Wat eruit springt: volwassen statistische diepgang, herbruikbare modelworkflows, monitoring en governance.
- Let op: beter geschikt voor gestructureerde enterpriseprogramma’s dan voor lichte experimenten.
Beste voor geavanceerde dataplatforms, samenwerking en schaal
11. Teradata
Teradata staat hier om één reden: wanneer je dataminingprobleem zich afspeelt binnen een enorme, beheerde data-omgeving, zijn prestaties en architectuur net zo belangrijk als algoritmen. Teradata blijft relevant voor in-database analytics, grootschalige datawarehousing en enterprise workloads die kleinere puntoplossingen niet comfortabel aankunnen.
- Beste voor: enorme enterprise datasets en in-database analytics.
- Wat eruit springt: schaal, prestaties en aansluiting op enterprise data-omgevingen.
- Let op: voor de meeste mkb- en midmarketteams is dit overkill.
12. Rattle
Rattle is nog steeds een bruikbare brug voor teams of lerenden die het modelleerecosysteem van R willen zonder veel vooraf te hoeven scripten. Het werkt het best als een goedkope leer- en prototypinglaag, niet als een modern samenwerkingsplatform.
- Beste voor: R-lerenden en licht prototypen.
- Wat eruit springt: GUI boven R-workflows plus zicht op de code.
- Let op: verouderd vergeleken met nieuwere visuele samenwerkingstools.
13. Dataiku
Dataiku is een van de meest uitgebalanceerde producten op deze lijst als je zowel samenwerking als schaal nodig hebt. Het werkt goed omdat het je niet dwingt te kiezen tussen no-code gebruikers en gevorderde practitioners. Zakelijke gebruikers kunnen werken met recipes en dashboards, terwijl technische gebruikers waar nodig code-niveau controle houden.
- Beste voor: cross-functionele analytics- en data science-teams.
- Wat eruit springt: no-code plus codesamenwerking, sterke governance, automatisering en ondersteuning voor deployment.
- Let op: meer platform dan veel kleinere teams nodig hebben als hun use case smal is.
14. H2O.ai
H2O.ai blijft hoog op de lijst staan voor organisaties die geven om schaalbare modellering, AutoML en verklaarbaarheid. Het is vooral aantrekkelijk wanneer snelheid en modeliteratie belangrijker zijn dan elk onderdeel van de workflow vanaf nul opbouwen.
- Beste voor: ML-teams die snelle iteratie en schaalbare automatisering willen.
- Wat eruit springt: AutoML, modelsnelheid, verklaarbaarheid, sterk ecosysteem.
- Let op: het is meer ML-gericht dan sommige zakelijke teams echt nodig hebben.
15. Google Cloud Dataflow
Google Cloud Dataflow is geen klassieke desktoptool voor datamining, maar verdient de laatste plek omdat veel moderne dataminingprojecten afhankelijk zijn van realtime- of grootschalige batchpipelines voordat analyse überhaupt begint. Als je use case streaming data, eventverwerking of grootschalige featurevoorbereiding omvat, dan maakt Dataflow deel uit van de echte dataminingstack.
- Beste voor: streaming pipelines en grootschalige batchvoorbereiding.
- Wat eruit springt: beheerde Apache Beam, autoscaling, sterke integratie met GCP.
- Let op: het is infrastructuurgedreven en geen analytics-tool die primair voor zakelijke gebruikers is gemaakt.
Hoe je kiest zonder te veel in te kopen
De meest voorkomende fout bij aankoop is dat je de bron van de frictie verwart:
- Als het probleem datatoegang is, begin dan met een verzamelt tool zoals Thunderbit.
- Als het probleem productiviteit van analisten is, vergelijk dan eerst Altair AI Studio, KNIME, Alteryx en Orange.
- Als het probleem enterprise governance is, zet SPSS Modeler, SAS Enterprise Miner, Spotfire Statistica of Dataiku op je shortlist.
- Als het probleem cloud-ML-operaties is, begin dan met Azure Machine Learning, H2O.ai of Dataiku.
- Als het probleem streaming of architectuur op enorme schaal is, beweeg dan richting Teradata of Dataflow.

Een simpele vuistregel helpt: koop de minst complexe tool die je bottleneck echt oplost. Veel teams hebben geen enorm data science-platform nodig. Ze hebben betere dataverzameling, schonere voorbereiding en één herhaalbare workflow nodig die analisten ook echt gaan gebruiken.
Als web-first datavastlegging deel uitmaakt van je stack, dan is deze Thunderbit-quickstartvideo het nuttigste praktische voorbeeld, omdat hij laat zien hoe je van een rommelige pagina naar een gestructureerde tabel gaat zonder onnodige technische omwegen:
Eindselectie per teamtype

- Sales-, ecommerce- en browser-intensieve operationele teams: Thunderbit, Alteryx, KNIME.
- Analisten die visuele workflows willen zonder zware codeafhankelijkheid: Altair AI Studio, KNIME, Alteryx, Orange.
- Teams voor enterprise predictive analytics: IBM SPSS Modeler, SAS Enterprise Miner, Spotfire Statistica.
- Cross-functionele data science-organisaties: Dataiku, Azure Machine Learning, H2O.ai.
- Data engineering- en platformteams: Teradata, Google Cloud Dataflow, Azure Machine Learning.
- Budgetbewuste lerenden of prototypebouwers: Orange, Weka, Rattle, KNIME.
Als ik deze lijst voor de meeste zakelijke kopers in 2026 zou moeten terugbrengen tot de kortste praktische shortlist, dan zou die zijn:
- Thunderbit voor snelle website- en documentdatavastlegging vóór analyse.
- Altair AI Studio voor visuele data science en AutoML zonder een notebook-first workflow.
- KNIME voor de flexibiliteit van open-source workflows.
- IBM SPSS Modeler voor enterprise predictive analytics met een zakelijke interface.
- Dataiku voor teams die samenwerking, governance en schaal tegelijk nodig hebben.
Conclusie
De echte vraag is niet welk product de langste featurelijst heeft. De echte vraag is welke tool je team met de minste frictie van ruwe data naar een verdedigbare beslissing brengt. In 2026 betekent dat meestal dat je verzamel-, voorbereidings-, modelleer- en deploymentproblemen uit elkaar trekt in plaats van te doen alsof één aankoop al die lagen even goed oplost.
Als je werk begint met publieke websites, pdf’s en ongestructureerde pagina’s, begin dan met Thunderbit. Als het begint met gereguleerde enterprise-modellering, begin dan hoger in de stack met tools zoals SPSS Modeler, Dataiku of Azure Machine Learning. En als je nog uitzoekt welk type platform je überhaupt nodig hebt, dan zijn KNIME, Orange en Altair AI Studio nog altijd de beste plekken om snel duidelijkheid te krijgen.
Gerelateerd om te lezen
- Wat is data scraping en hoe doe je het in 2025
- Hoe je met AI elke website kunt scrapen
- Beste tools voor webscraping in 2026
Veelgestelde vragen
1. Wat is software voor datamining, in simpele zakelijke termen?
Software voor datamining helpt teams patronen, segmenten, afwijkingen, trends en voorspellende signalen in ruwe data te vinden. In een echte zakelijke workflow betekent dat meestal een combinatie van dataverzameling, opschoning, modelbouw, scoring en rapportage.
2. Is software voor datamining alleen voor data scientists?
Nee. De markt is inmiddels verdeeld tussen technische en niet-technische kopers. Thunderbit, Altair AI Studio, KNIME, Orange en Alteryx verlagen allemaal de drempel voor analisten en zakelijke teams, terwijl platforms zoals Dataiku, Azure ML en H2O.ai ook meer gevorderde gebruikers bedienen.
3. Wat is de beste software voor datamining voor een niet-technisch team?
Als je data op internet begint, is Thunderbit de snelste eerste stap. Als je bredere visuele analytics en workflowmodellering nodig hebt, zijn Altair AI Studio, KNIME, Orange en Alteryx de sterkste no-code- of low-code-opties op deze lijst.
4. Moet ik kiezen voor een open-source tool of een enterpriseplatform?
Kies open source als je flexibiliteit, lagere instapkosten en ruimte om te experimenteren nodig hebt. Kies enterpriseplatforms wanneer governance, support, deployment-controles, compliance en standaardisatie tussen teams belangrijker zijn dan eenvoud in licenties.
5. Kan ik meer dan één van deze tools samen gebruiken?
Ja, en veel teams zouden dat ook moeten doen. Een veelvoorkomende stack is om data te verzamelen met Thunderbit, die vervolgens voor te bereiden of te modelleren in KNIME of Alteryx, en het daarna te operationaliseren of te monitoren in een cloud- of enterpriseplatform. De beste stack lost meestal verschillende lagen van de workflow op in plaats van één tool alles te laten doen.




