Heb je ooit naar een spreadsheet zitten staren en gedacht: “Is deze ‘Acme Inc.’ nou gewoon dezelfde als ‘Acme Incorporated’?” Je bent echt niet de enige. In het bedrijfsleven zijn dubbele en inconsistente data niet alleen irritant, maar ook gewoon duur. Amerikaanse bedrijven verliezen jaarlijks naar schatting door slechte data, waarbij een gemiddeld bedrijf elk jaar zo’n $13 miljoen kwijtraakt aan dubbele records, foute contacten en onbetrouwbare analyses. Nu data uit steeds meer bronnen en systemen komt, wordt het probleem alleen maar groter—en is data matching onmisbaar voor iedereen die zijn bedrijf soepel wil laten draaien (en zijn hoofd koel wil houden).

Maar wat houdt data matching nu precies in, en waarom is het zo belangrijk voor sales, marketing en operations? In deze gids leg ik je de basics uit, deel ik praktijkvoorbeelden en laat ik zien hoe moderne tools zoals data matching voor iedereen toegankelijk maken—ook als je geen dataspecialist bent. Laten we samen orde scheppen in je data-chaos.
Wat is Data Matching? Simpel uitgelegd
Heel kort: data matching is het proces waarbij je records opspoort en aan elkaar koppelt die eigenlijk over dezelfde persoon, organisatie of product gaan, maar verspreid staan over verschillende databronnen (). Zie het als detectivewerk in je data: ontdekken dat “John Doe” in je sales-CRM dezelfde is als “Jonathan Doe” in je support-systeem, zelfs als de gegevens niet exact overeenkomen.
In de praktijk betekent dat bijvoorbeeld:
- Klantgegevens matchen tussen marketing-, sales- en supportdatabases.
- Productlijsten samenvoegen die onder verschillende namen of codes voorkomen.
- Leveranciers of partners koppelen die per ongeluk dubbel zijn ingevoerd met kleine verschillen.
Data matching draait niet alleen om exacte overeenkomsten. Het gaat juist om het herkennen van gelijkenissen—ook als er spelfouten, bijnamen of verschillende schrijfwijzen zijn. Zo worden “Jon Smith” en “Jonathan Smith” of “555-123-9988” en “(555) 123-9988” als dezelfde persoon of telefoonnummer herkend ().
Het doel? Eén compleet en overzichtelijk profiel per klant, product of leverancier—zonder losse, dubbele fragmenten.
Waarom Data Matching Belangrijk Is voor Bedrijven
Schone, eenduidige data is geen luxe, maar de basis voor een goed draaiend bedrijf en slimme keuzes. Daarom is data matching zo waardevol:
- Bespaar tijd en geld: Dubbele data zorgt voor verspilde marketingbudgetten, dubbele opvolging en veel handmatig werk. Uit onderzoek blijkt dat dubbele data de omzet met zo’n kan verlagen.
- Betere klantervaring: Klanten vinden het bloedirritant om twee keer dezelfde e-mail te krijgen of als twee verschillende mensen behandeld te worden. Meer dan als communicatie niet klopt.
- Betrouwbare analyses: Slechte data leidt tot verkeerde beslissingen. komt door dubbele of foutieve records.
- Minder risico op boetes: Inconsistente data maakt het lastig om te voldoen aan privacywetgeving zoals de AVG of HIPAA.
Hier zie je waar data matching direct waarde oplevert:
| Toepassing / Scenario | Hoe Data Matching Helpt |
|---|---|
| Lead-ontdubbeling (Sales) | Voegt dubbele leads samen zodat sales niet twee keer dezelfde persoon benadert en de pipeline zuiver blijft. |
| Klantprofielen samenvoegen | Koppelt klantgegevens uit verschillende systemen voor een 360°-beeld en betere service. |
| Product- en voorraaddata opschonen | Combineert dubbele productrecords voor consistente voorraad en prijzen. |
| Leveranciersmatching | Spoort dubbele leveranciers of facturen op, voorkomt dubbele betalingen en vereenvoudigt uitgavenanalyse. |
| Contactdata opschonen (Marketing) | Matcht en standaardiseert contactgegevens, verlaagt e-mailkosten en verbetert bezorging. |
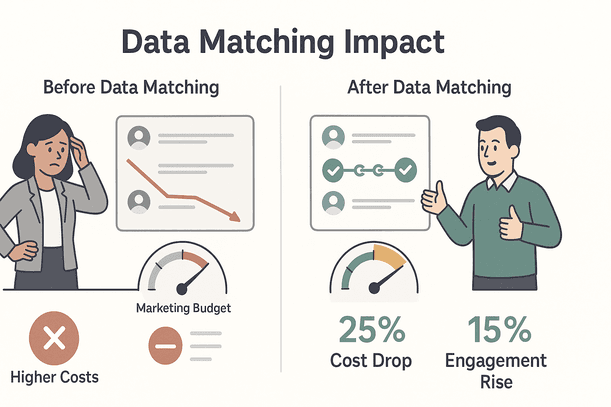
Bedrijven die investeren in data matching zien hun marketingkosten dalen met wel 25% en klantbetrokkenheid stijgen met zo’n 15% (). Dat is winst voor het hele bedrijf, niet alleen voor het datateam.
Hoe Werkt Data Matching? Belangrijke Principes en Technieken
Hoe werkt data matching nu eigenlijk? Hier de stappen in gewone mensentaal:
- Data voorbereiden: Maak je data schoon en standaardiseer deze. Denk aan het corrigeren van spelfouten, het gelijk maken van formaten (zoals datums en telefoonnummers) en zorgen dat velden vergelijkbaar zijn ().
- Matchcriteria bepalen: Kies welke velden je vergelijkt (zoals naam, e-mail of telefoon). Sommige velden zijn uniek (zoals e-mail), andere vragen om een ‘fuzzy’ vergelijking.
- Vergelijken en scoren: Gebruik algoritmes om records te vergelijken en een gelijkenisscore toe te kennen. Bijvoorbeeld, “Jonathan Smith” versus “Johnathan Smithe” kan een score van 0,92 op 1 krijgen.
- Beslisregels instellen: Stel drempels in—boven 90% is het een match, onder 50% niet, ertussenin vraagt om handmatige controle.
- Groeperen en samenvoegen: Koppel of voeg gematchte records samen tot één overzichtelijk record.
Fuzzy Matching en Andere Slimme Methoden
Data uit de praktijk is vaak rommelig, dus data matching gebruikt slimme technieken:
- Fuzzy matching: Vindt bijna-overeenkomsten, zoals spelfouten of variaties (“Jon Smyth” en “John Smith”) ().
- Fonematisch vergelijken: Herkent woorden die hetzelfde klinken (zoals “Katherine” en “Catherine”).
- Patroon/Regex matching: Herkent standaardpatronen, bijvoorbeeld telefoonnummers in verschillende notaties.
- Data fingerprinting: Maakt een digitale ‘vingerafdruk’ van elk record, zodat dubbele gegevens sneller worden herkend (“123 Main St. Apt 5” en “123 Main Street Apartment #5”).
- AI-ondersteunde matching: Machine learning leert van voorbeelden en wordt steeds slimmer, zodat ook lastige matches worden gevonden ().
De beste oplossingen combineren deze technieken voor maximale nauwkeurigheid.
Typische Businesscases voor Data Matching
Data matching is niet alleen iets voor IT—het levert direct resultaat op voor allerlei teams:
- Klantdata integreren: Combineer klantgegevens uit website, app en winkels tot één profiel. Een retailer verminderde dubbele profielen met 40% en zag e-mailengagement stijgen met 15% ().
- Leads ontdubbelen (Sales): Maak leads uit verschillende bronnen schoon zodat sales niet dubbel werk doet. Topteams houden het duplicaatpercentage onder de 1% ().
- Marketinglijsten opschonen: Verwijder dubbele e-mailadressen om dubbele mailings te voorkomen en campagnes te verbeteren.
- Productcatalogus beheren (E-commerce): Match en combineer productrecords om voorraadfouten en rapportageproblemen te voorkomen.
- Financiële data reconciliatie: Match leveranciers en facturen om dubbele betalingen te voorkomen—MKB’s lopen risico op meer dan $12.000 aan extra betalingen door dubbele facturen ().
- Patiëntendossiers koppelen (Zorg): Zorg voor patiëntveiligheid door dossiers over verschillende zorgverleners te matchen—ziekenhuizen zien gemiddeld een 10% duplicaatpercentage in patiëntendossiers ().
Welke sector je ook zit, als je data uit meerdere bronnen hebt, heb je data matching nodig.
Hoe Data Matching Beter Inzicht Geeft
Je kent vast de uitdrukking “garbage in, garbage out.” Als je rapporten gebaseerd zijn op rommelige, dubbele data, zijn je beslissingen onbetrouwbaar. Data matching verandert dat:
- Betrouwbare analyses: Geen dubbeltellingen meer—je rapporten kloppen. Je denkt niet langer dat je 100.000 klanten hebt als het er eigenlijk 80.000 zijn.
- Beter strategisch plannen: Eenduidige data laat echte trends zien, zodat je investeert in wat werkt.
- Sneller en flexibeler beslissen: Schone data betekent dat je snel kunt inspelen op veranderingen—zoals een populair product of een klant die dreigt af te haken.
- Dieper klantinzicht: Je ziet het volledige plaatje van elke klant, wat slimme segmentatie en cross-selling mogelijk maakt.
- Nauwkeurige KPI’s: Teams worden afgerekend op echte cijfers, niet op opgeblazen aantallen door dubbelen.
Bedrijven die data matching prioriteren, zien tot 15% hogere campagne-ROI en nemen met meer vertrouwen datagedreven beslissingen ().
De Beperkingen van Traditionele Data Matching Tools
Als data matching zo belangrijk is, waarom doet niet iedereen het perfect? Traditionele tools hebben flinke nadelen:
- Veel handwerk: Oude methodes (zoals Excel VLOOKUPs of eigen scripts) zijn traag en niet schaalbaar. Datateams besteden aan data opschonen en afstemmen.
- Ingewikkelde regels: Klassieke tools vragen veel technische kennis en onderhoud.
- Kwetsbaar en foutgevoelig: Ze raken snel in de war als data verandert of nieuwe bronnen worden toegevoegd.
- Niet geschikt voor grote of rommelige data: Excel loopt vast bij grote bestanden, oude tools kunnen niet goed overweg met ongestructureerde data.
- Alleen batchverwerking: Dubbelen stapelen zich op tussen de opschoonrondes—geen real-time matching.
- Niet gebruiksvriendelijk: De meeste tools zijn gemaakt voor IT, niet voor businessgebruikers.
Niet gek dat aangeeft moeite te hebben met dubbele data.
De Opkomst van AI in Data Matching: Slimmer, Sneller, Nauwkeuriger
AI verandert het spel. Moderne data matching tools gebruiken machine learning en natuurlijke taalverwerking om het zware werk te automatiseren:
- Automatiseert saaie taken: AI kan het aantal dubbele records in een paar maanden met 30–40% verminderen ().
- Kan omgaan met rommelige data: AI herkent patronen en context, en vindt matches die regels missen.
- Schaalt moeiteloos: AI verwerkt miljoenen records in enkele minuten.
- Leert en verbetert: AI-modellen worden steeds slimmer naarmate ze meer data en feedback krijgen.
- Werkt real-time: Veel AI-tools matchen data direct bij binnenkomst, niet alleen in batches.
Zo ontdekte dat AI-gebaseerde matching “John Smith” en “Jonathan S. Smith” in minuten kan koppelen, in plaats van dagen.
Thunderbit: Data Matching voor Iedereen Toegankelijk
Bij Thunderbit willen we data matching voor iedereen mogelijk maken—niet alleen voor data engineers. Zo helpt je om in een paar klikken schone, gematchte data te krijgen:
- AI Suggest Fields: Open een webpagina en klik op “AI Suggest Fields.” Thunderbit’s AI scant de pagina en stelt de beste kolommen voor (zoals Naam, Bedrijf, E-mail), zodat je alle belangrijke info in een consistent formaat vastlegt ().
- Subpagina’s en paginering scrapen: Thunderbit bezoekt automatisch subpagina’s (zoals detailprofielen) en voegt die info samen in je hoofdtafel—geen handmatig werk of ontbrekende details meer ().
- AI-herkenning en standaardisatie: Thunderbit herkent datatypes (zoals datums of telefoonnummers) en standaardiseert waarden direct—zelfs in verschillende talen ().
- Natuurlijke taalinterface: Beschrijf gewoon wat je wilt in normaal Nederlands, en Thunderbit regelt de rest ().
- Exporteren met één klik: Exporteer je schone, gematchte data direct naar Excel, Google Sheets, Airtable of Notion—zonder extra kosten of verborgen toeslagen ().
- Templates voor populaire sites: Thunderbit biedt kant-en-klare sjablonen voor sites als Amazon, Zillow en Shopify, zodat je altijd consistente, matchklare data krijgt.
- Geplande scraping: Stel terugkerende scrapes in om je data actueel en gematcht te houden ().
Mini-gids: Data matchen met Thunderbit
- Open de .
- Ga naar de gewenste webpagina.
- Klik op “AI Suggest Fields” om kolommen te laten voorstellen.
- Klik op “Scrape”—Thunderbit haalt de data op, standaardiseert en matcht deze (ook over subpagina’s).
- Exporteer je schone, ontdubbelde data naar je favoriete tool.
Zo makkelijk is het. Wil je Thunderbit in actie zien? Check dan ons .
De Juiste Data Matching Tool Kiezen voor Jouw Team
Let bij het kiezen van een data matching tool op deze punten:
| Criteria | Waarop letten? |
|---|---|
| Gebruiksgemak | Intuïtieve interface, natuurlijke taalcommando’s, geen zware code nodig. |
| Integratie | Exporteert/importeert naar Excel, Google Sheets, CRM’s en andere tools die je al gebruikt. |
| Schaalbaarheid | Werkt zowel met kleine lijsten als miljoenen records zonder vertraging. |
| AI-mogelijkheden | Fuzzy matching, AI-veldvoorstellen en leren van feedback. |
| Data opschonen | Standaardisatie, validatie en verrijking ingebouwd. |
| Aanpasbaarheid | Mogelijkheid om matchregels en drempels naar wens aan te passen. |
| Controleerbaarheid & compliance | Logboeken, ongedaan maken/herstellen en privacyvriendelijke functies. |
| Support & community | Goede documentatie, onboarding en snelle ondersteuning. |
Thunderbit voldoet aan al deze eisen—vooral voor niet-technische gebruikers die snel aan de slag willen.
Zelfs met goede tools kent data matching uitdagingen. Zo pak je ze aan:
- Inconsistente dataformaten: Standaardiseer velden (zoals datums en telefoonnummers) vooraf. Thunderbit doet dit automatisch.
- Ontbrekende data: Gebruik matching op meerdere velden en vul ontbrekende info aan waar mogelijk.
- Valse positieven/negatieven: Stel je matchdrempels goed af en gebruik handmatige controle bij twijfelgevallen.
- Meerdere bronsystemen: Gebruik master data management of tools die cross-systeem matching aankunnen.
- Privacyzorgen: Anonimiseer data tijdens matching, houd logboeken bij en volg privacyregels.
- Data actueel houden: Plan periodieke matching en stimuleer datakwaliteit binnen je team.
Samenvatting: Waarom Data Matching Onmisbaar Is voor Moderne Bedrijven
- Data matching zorgt voor één waarheid—geen dubbele of versnipperde records meer.
- Schone data levert betere bedrijfsresultaten op: hogere ROI, tevreden klanten en meer vertrouwen in je beslissingen.
- Handmatig matchen is niet meer bij te houden—AI-tools zoals Thunderbit zijn de toekomst.
- Thunderbit maakt data matching voor iedereen toegankelijk met AI-veldvoorstellen, subpagematching en eenvoudige export.
- Investeren in data matching geeft je een voorsprong—maak van je data een kracht in plaats van een last.
Benieuwd wat schone, gematchte data voor jouw bedrijf kan betekenen? of lees meer op de .
Veelgestelde vragen
1. Wat is data matching in gewone taal?
Data matching is het proces waarbij je gegevens aan elkaar koppelt die eigenlijk over dezelfde persoon, klant of product gaan, ook als de details niet exact overeenkomen.
2. Waarom is data matching belangrijk voor bedrijven?
Het helpt om dubbelen te verwijderen, klantprofielen te verenigen, analyses te verbeteren en verspilling te voorkomen—wat leidt tot betere beslissingen en tevreden klanten.
3. Hoe maakt AI data matching makkelijker?
AI automatiseert het saaie werk, kan omgaan met rommelige data en wordt steeds nauwkeuriger door te leren van voorbeelden—waardoor matching sneller en betrouwbaarder wordt.
4. Wat maakt Thunderbit anders dan andere data matching tools?
Thunderbit gebruikt AI om velden voor te stellen, data te standaardiseren en records te matchen—zelfs over subpagina’s. Het is ontworpen voor niet-technische gebruikers en werkt samen met populaire zakelijke tools.
5. Hoe kan ik starten met data matching in mijn team?
Begin met het in kaart brengen van je belangrijkste databronnen, gebruik een tool zoals Thunderbit om data te extraheren en standaardiseren, en plan regelmatige matching om je gegevens schoon en eenduidig te houden. Meer tips vind je op de .