
Als je AI-gestuurde webscrapingtools aan het verkennen bent, ben je waarschijnlijk Crawl4AI al tegengekomen. Het is een populair open-sourceproject dat onder ontwikkelaars veel aandacht krijgt vanwege de snelheid en flexibiliteit. Maar wat als je geen programmeur bent — of gewoon snel data wilt ophalen zonder te stoeien met Python-scripts? Of je Crawl4AI nu overweegt voor je volgende project, of juist op zoek bent naar een gebruiksvriendelijker alternatief, vooral als je werkt in sales, marketing, e-commerce of vastgoed: dan zit je hier goed. In deze review leg ik uit wat Crawl4AI biedt, waar het uitblinkt en waar je misschien meer van verwacht. Ik laat je ook zien hoe Thunderbit zich verhoudt als een moderne no-code-oplossing voor zakelijke gebruikers die het web willen scrapen met slechts een paar klikken.
Wat is Crawl4AI?
Crawl4AI is een open-source Python-bibliotheek voor webcrawling en gegevensextractie, met een sterke focus op AI en use-cases rond grote taalmodellen (LLM’s). Op GitHub wint het snel aan populariteit dankzij de hoge snelheid, parallelle crawls en de mogelijkheid om data uit te voeren in AI-vriendelijke formaten zoals JSON en Markdown. Kort gezegd is het een toolkit voor ontwikkelaars om websites op schaal te scrapen en die data vervolgens te voeden aan AI-modellen, analytics-dashboards of eigen databases.
![]()
Belangrijkste producten en functies:
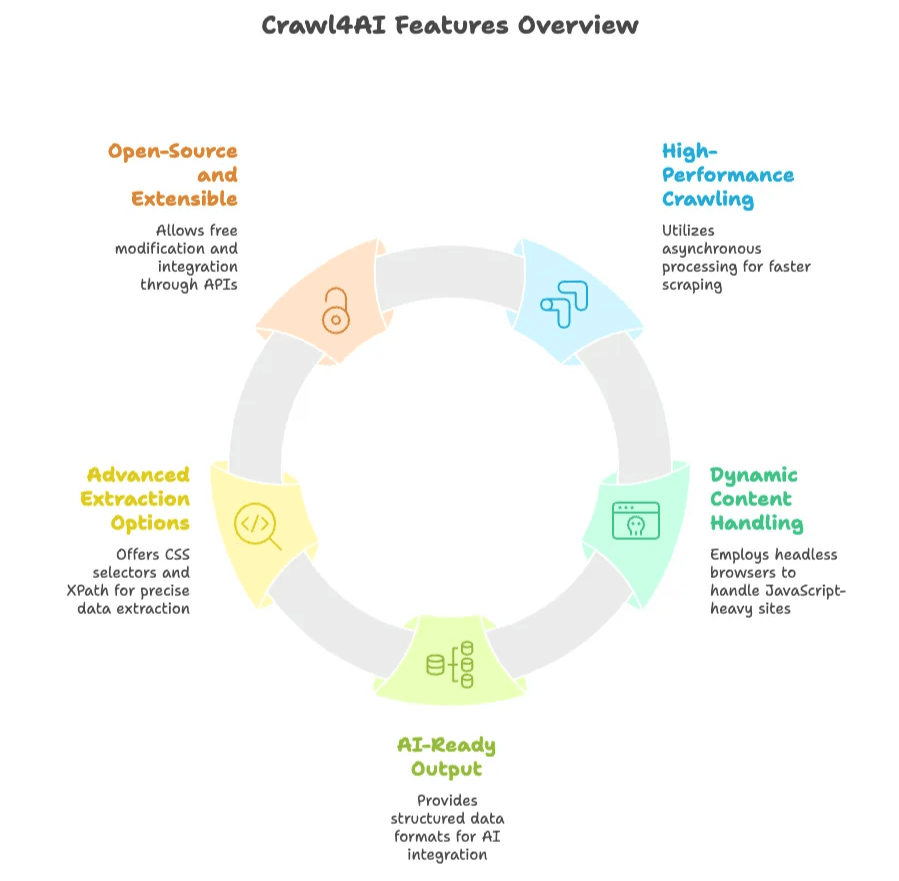
- Hoge prestaties bij crawlen: Gebruikt asynchrone, parallelle verwerking om meerdere pagina’s tegelijk te crawlen, waardoor het vaak veel sneller is dan traditionele scrapers.
- Omgaan met dynamische content: Stuurt een headless browser aan (zoals Chromium via Playwright) om JavaScript uit te voeren en moderne, dynamische websites te scrapen.
- AI-klaar uitvoerformaat: Zet data om naar gestructureerde tekst (JSON, Markdown of opgeschoonde HTML) die direct geschikt is voor AI of data-analyse.
- Geavanceerde extractieopties: Laat gebruikers extractieregels instellen met CSS-selectors of XPath, en zelfs LLM’s integreren voor samenvatting of extractie van content.
- Open source en uitbreidbaar: Gratis te gebruiken, aan te passen en uit te breiden. Biedt een Python API, command-line interface en REST API voor flexibele integratie.
De filosofie van Crawl4AI is om “data te democratiseren” door ontwikkelaars een snelle, code-gedreven scraper te geven zonder betaalmuren of beperkingen van commerciële tools. Als je prettig met Python werkt, is het een krachtige manier om snel grote hoeveelheden webdata te verzamelen.
Voor wie is Crawl4AI bedoeld?
Crawl4AI is in de eerste plaats gebouwd voor technische gebruikers — denk aan ontwikkelaars, data scientists, AI-onderzoekers en iedereen die comfortabel Python-scripts schrijft. Typische use-cases zijn onder andere:
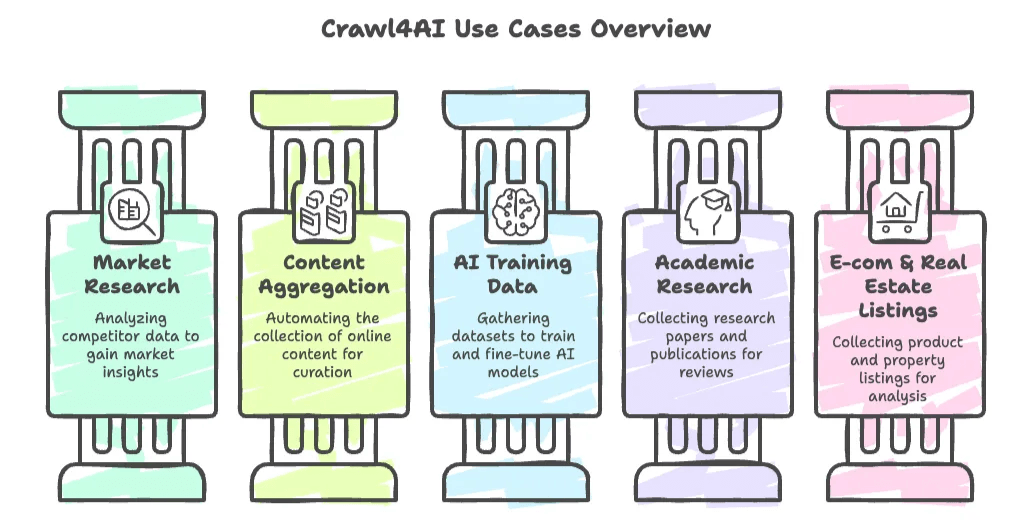
- Marktonderzoek en concurrentieanalyse: Scrape websites van concurrenten, nieuwsartikelen of sociale media voor inzichten.
- Content-aggregatie: Automatiseer het verzamelen van nieuws, blogs of forumberichten voor curatie of trendmonitoring.
- Verzameling van trainingsdata voor AI: Verzamel grote datasets (zoals documentatie, vragen en antwoorden of artikelen) om taalmodellen te trainen of bij te stellen.
- Academisch onderzoek: Verzamel automatisch wetenschappelijke artikelen, jurisprudentie of online publicaties voor literatuuronderzoek.
- E-commerce- en vastgoedvermeldingen: Ontwikkelaars kunnen eigen crawlers bouwen om product- of woningaanbod te verzamelen voor analyse.
Maar hier zit de crux: Crawl4AI is niet ontworpen voor niet-technische gebruikers. Ben je salesmanager, marketeer of makelaar zonder programmeerervaring, dan zul je de installatie en het gebruik waarschijnlijk als intimiderend ervaren. De tool gaat ervan uit dat je Python beheerst en weet hoe je extractieregels instelt en problemen oplost.
Prijsplan van Crawl4AI
Een van de grootste pluspunten van Crawl4AI is de prijs: het is helemaal gratis. Als open-sourceproject zijn er geen licentiekosten, abonnementsniveaus of betaalmuren. Je kunt het via pip installeren en direct aan de slag.
Toch heeft “gratis” ook kanttekeningen:
- Installatie en onderhoud: Je moet tijd investeren in het opzetten van je omgeving, het schrijven van scripts en het onderhouden van je scraping-workflows.
- Indirecte kosten: Als je grote crawls uitvoert, moet je mogelijk betalen voor proxies, servers of cloudresources.
- Ondersteuning: Er is geen officiële klantenservice — alleen communityforums en GitHub-issues.
Voor bedrijven met eigen technische expertise kan dit een kosteneffectieve oplossing zijn. Maar voor niet-technische teams kunnen de tijd en moeite die nodig zijn om op gang te komen al snel zwaarder wegen dan het prijskaartje van nul euro.
Gebruikersfeedback over Crawl4AI
Om echt te begrijpen hoe Crawl4AI presteert, heb ik gebruikersreviews bekeken op techblogs, AI-toolgidsen en communityforums. Dit viel op:
Wat gebruikers waarderen
- Snelheid en kostenefficiëntie: Ontwikkelaars zijn enthousiast over hoe snel Crawl4AI grote websites kan scrapen, vaak sneller dan betaalde tools. Dat het gratis is, is een enorm pluspunt.
- Flexibiliteit van open source: Gebruikers vinden het prettig dat ze volledige controle over de code hebben, zonder vendor lock-in of functionele beperkingen.
- AI-klaar uitvoerformaat: De gestructureerde, schone uitvoer van data — vooral in JSON of Markdown — bespaart tijd voor iedereen die data in AI-modellen of analysetools stopt.
Waar gebruikers tegenaan lopen
Maar bij die lof komen ook flinke kanttekeningen kijken — vooral voor beginners of mensen zonder programmeerervaring.
1. Steile leercurve
Een terugkerend thema is dat Crawl4AI niet beginnersvriendelijk is. Ben je nieuw in webscraping of niet vertrouwd met Python, dan krijg je te maken met een steile leercurve. Er is geen point-and-click-interface; alles gebeurt via scripts en configuratiebestanden. Het instellen van de omgeving, het schrijven van extractieregels en het omgaan met asynchroon crawlen vereisen technische kennis. Een reviewer zei het onomwonden: “Als je niet kunt coderen, raak je de weg kwijt.”
2. Niet vriendelijk voor absolute beginners
Zelfs met enige technische achtergrond kan Crawl4AI lastig zijn. De documentatie wordt beter, maar de community is nog klein, waardoor hulp vinden soms traag gaat. Gebruikers melden bugs of crashes op complexe sites, en problemen oplossen betekent vaak graven in GitHub-issues of Stack Overflow. Ook ontbreken ingebouwde functies voor veelvoorkomende zakelijke behoeften — zoals inloggen op websites, CAPTCHAs oplossen of terugkerende crawls plannen. Wil je data volgens een schema scrapen of authenticatie afhandelen, dan moet je die functies zelf bouwen.
Praktijkvoorbeeld:
- Een marketingmanager bij een middelgroot e-commercebedrijf probeerde Crawl4AI te gebruiken om prijzen van concurrenten te monitoren. Na dagenlang worstelen met Python-scripts en browserdrivers gaf die het op en stapte over op een no-code tool. De technische drempels en het gebrek aan ondersteuning maakten het voor het team onpraktisch.
- Een makelaar wilde woningaanbod van meerdere sites scrapen. De installatie van Crawl4AI bleek overweldigend en de eerste configuratie lukte niet. Zonder ontwikkelaar in de buurt kwam het project stil te liggen.
Kortom: hoewel Crawl4AI voor ontwikkelaars een krachtig hulpmiddel is, is het voor zakelijke gebruikers die gewoon data willen zonder gedoe een lastige keuze.
Belangrijkste conclusies uit de Crawl4AI-review
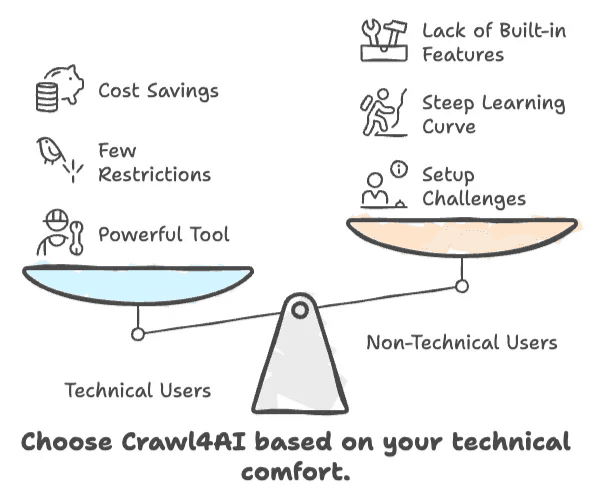
- Crawl4AI is snel, flexibel en gratis — maar alleen als je met code overweg kunt.
- Niet-technische gebruikers zullen moeite hebben met de installatie, leercurve en het gebrek aan ingebouwde zakelijke functies.
- Heb je een point-and-click no-code-oplossing nodig, dan is Crawl4AI waarschijnlijk niet voor jou.
- Voor ontwikkelaars en AI-practitioners is het een krachtige tool met weinig beperkingen.
- Voor zakelijke gebruikers kunnen de tijd en moeite zwaarder wegen dan de besparing op kosten.
Maak kennis met Thunderbit: de no-code AI-webscraper voor zakelijke gebruikers
Nu we hebben gezien waar Crawl4AI tekortschiet voor niet-technische gebruikers, is het tijd voor een beter alternatief: Thunderbit.
Thunderbit is een AI-gestuurde webscraper Chrome-extensie die speciaal is gebouwd voor zakelijke gebruikers — sales-, marketing-, e-commerce- en vastgoedprofessionals die snel data van elke website willen halen, zonder ook maar één regel code. Ik heb veel scrapingtools getest, en Thunderbit springt eruit door zijn eenvoud én kracht.
Wat maakt Thunderbit anders?
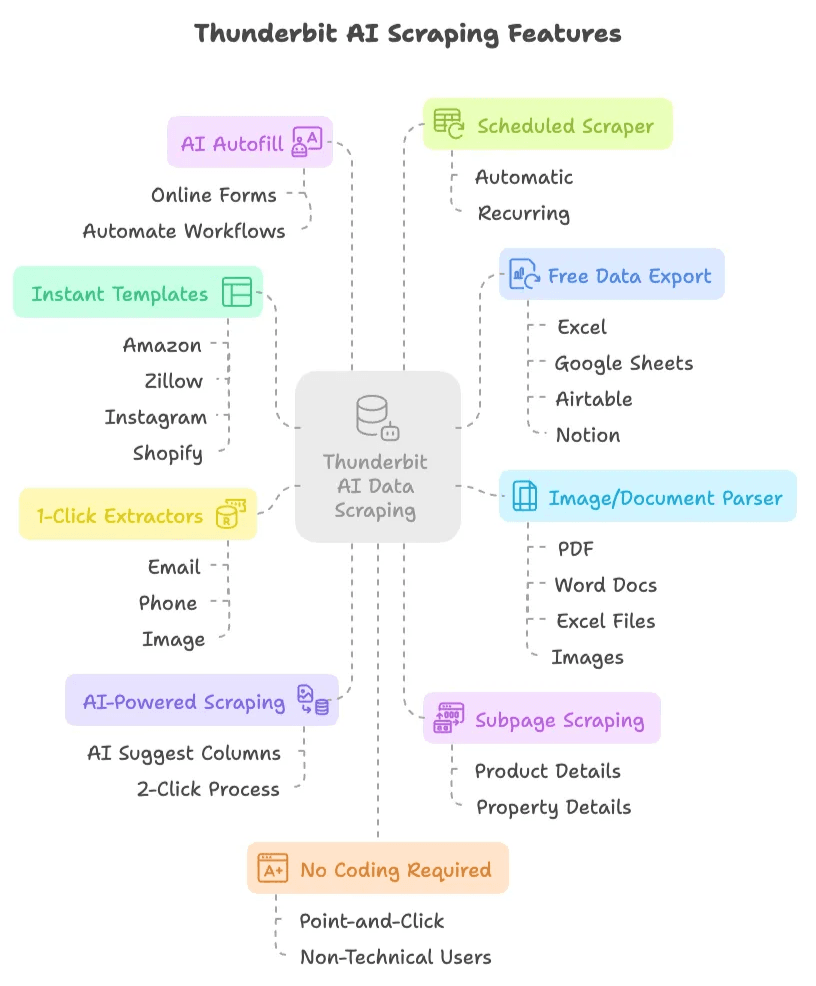
- AI-gestuurde scraping in 2 klikken: Klik op “AI Suggest Columns”, laat de AI voorstellen wat je moet extraheren en druk vervolgens op “Scrape”. Klaar. Geen scripts, geen selectors, geen hoofdpijn.
- Subpagina-scraping: De AI van Thunderbit kan automatisch subpagina’s bezoeken, zoals product- of woningdetails, en je datatabel verrijken — zonder handmatige instellingen.
- Directe datascraper-sjablonen: Voor populaire sites zoals Amazon, Zillow, Instagram en Shopify kun je data met één klik exporteren via kant-en-klare sjablonen.
- Gratis data-export: Exporteer je gescrapete data naar Excel, Google Sheets, Airtable of Notion — zonder extra te betalen.
- AI-autovullen (volledig gratis): Gebruik AI om online formulieren in te vullen en workflows te automatiseren. Selecteer gewoon de context en laat Thunderbit de rest doen.
- Geplande scraper: Stel automatische, terugkerende scrapes in met een simpel schema — geen cronjobs of serverconfiguratie nodig.
- 1-klik e-mail-, telefoon- en afbeeldings-extractors: Haal direct e-mailadressen, telefoonnummers of afbeeldingen van elke website.
- Afbeelding/document-parser: Extraheer tabellen uit PDF’s, Word-documenten, Excel-bestanden of afbeeldingen. Upload je bestand, laat AI de data structureren en klik op “Scrape”.
- Geen code nodig: Alles werkt via point-and-click en is ontworpen voor niet-technische gebruikers.
Data van elke website scrapen met AI Get Started Free
Thunderbit draait om het toegankelijk maken van webdata voor iedereen — niet alleen voor ontwikkelaars. Wil je zien hoe het werkt, bekijk dan de downloadpagina van de Thunderbit Chrome-extensie of lees de Thunderbit Blog voor praktijkvoorbeelden.
Probeer Thunderbit AI Web Scraper gratis
Prijsplannen van Thunderbit
Thunderbit gebruikt een eenvoudig creditsysteem: 1 credit = 1 uitvoerrij. Zo zien de plannen eruit:
| Niveau | Maandprijs | Jaarprijs (per maand) | Credits (maandelijks) |
|---|---|---|---|
| Gratis | Gratis | Gratis | 6 pagina’s |
| Starter | $15 | $9 | 500 |
| Pro 1 | $38 | $16.5 | 3.000 |
| Pro 2 | $75 | $33.8 | 6.000 |
| Pro 3 | $125 | $68.4 | 10.000 |
| Pro 4 | $249 | $137.5 | 20.000 |
Je kunt gratis beginnen en tot 6 pagina’s scrapen (of 10 met een gratis proefperiode). Betaalde abonnementen geven meer credits en geavanceerde functies, maar zelfs het gratis plan is ruim genoeg voor lichte gebruikers. Meer details vind je op de pagina Thunderbit-prijzen.
Thunderbit vs Crawl4AI: vergelijking naast elkaar
Laten we Thunderbit en Crawl4AI eens rechtstreeks vergelijken, zodat je ziet waar elke tool uitblinkt — en waar Thunderbit het leven voor zakelijke gebruikers makkelijker maakt.
| Functie / criterium | Thunderbit | Crawl4AI |
|---|---|---|
| No-code, point-and-click-interface | ✅ | ❌ |
| AI Suggest Columns (automatische detectie) | ✅ | ❌ |
| Subpagina-scraping (automatisch) | ✅ | ❌ |
| Directe sjablonen (Amazon, enz.) | ✅ | ❌ |
| Gratis data-export (Excel, Sheets) | ✅ | ❌ |
| AI-autovullen (formulieren invullen) | ✅ | ❌ |
| Geplande scraping (zonder code) | ✅ | ❌ |
| 1-klik e-mail/telefoon/afbeelding-extractie | ✅ | ❌ |
| Tabel-extractie uit afbeelding/document | ✅ | ❌ |
| Kan omgaan met dynamische content | ✅ | ✅ |
| Open source | ❌ | ✅ |
| Vereist coderen | ❌ | ✅ |
| Gratis versie beschikbaar | ✅ | ✅ |
| Community-ondersteuning | ✅ | ⚠️ (beperkt) |
| Gemaakt voor zakelijke gebruikers | ✅ | ❌ |
| Gemaakt voor ontwikkelaars | ⚠️ | ✅ |
| Prijs | $ (gratis en betaald) | Gratis |
| Klantenondersteuning | ✅ | ❌ |
Legenda:
✅ = Ja
❌ = Nee
⚠️ = Beperkt/deels
$ = Betaalde abonnementen beschikbaar
Conclusie
Ben je een ontwikkelaar die graag met code sleutelt en volledige controle wil, dan is Crawl4AI een krachtige, gratis tool voor grootschalige webscraping. Maar ben je een zakelijke gebruiker — vooral in sales, marketing, e-commerce of vastgoed — die gewoon data wil ophalen zonder gedoe, dan is Thunderbit de duidelijke winnaar. Het is gebouwd voor niet-technische gebruikers, met AI-automatisering, directe sjablonen en een gebruiksvriendelijke interface waarmee je in seconden van website naar spreadsheet gaat.
Scrape elke website met Thunderbit
Veelgestelde vragen
1. Hoe verhoudt Thunderbit zich tot andere AI-webscrapers zoals Crawl4AI?
Thunderbit is ontworpen voor niet-technische gebruikers en biedt een no-code, point-and-click-interface, terwijl Crawl4AI een op ontwikkelaars gerichte, open-source Python-bibliotheek is. Thunderbit automatiseert complexe taken met AI, waardoor webscraping voor iedereen toegankelijk wordt.
2. Welke unieke functies biedt Thunderbit voor zakelijke gebruikers?
Thunderbit biedt AI-gestuurde kolomsuggesties, subpagina-scraping, directe sjablonen voor populaire sites en gratis data-export naar Excel of Google Sheets — allemaal zonder code. Daarnaast bevat het geplande scraping en 1-klik-extractors voor e-mailadressen, telefoonnummers en afbeeldingen.
3. Kan Thunderbit complexe data-extractie aan, zoals PDF’s of afbeeldingen?
Zeker weten! De AI van Thunderbit kan tabellen uit PDF’s, Word-documenten, Excel-bestanden en afbeeldingen halen. Upload gewoon je bestand, laat de AI de data structureren en klik op “Scrape” voor directe resultaten. Lees meer op de Thunderbit Blog.
Meer informatie
- Wat is data scraping en hoe doe je het in 2025 – Thunderbit Blog
- De beste webscrapingtools en software in 2025 – Thunderbit Blog
- De beste AI-tools voor gegevensverzameling voor modelklare datasets – Medium
- Hoe AI-webscrapers kunnen helpen bij data-extractie en analyse - Forbes
Probeer AI-webscraper Get Started Free




