Hier is een statistiek waar elk outboundteam van moet schrikken: . Het gemiddelde campagne-antwoordspercentage ligt op slechts 4,1%. Ondertussen kan goed onderzochte, diep gepersonaliseerde outreach oplopen tot dubbele cijfers. De formule lijkt dus duidelijk: gewoon meer personaliseren, toch?
Niet zo snel. Het probleem in 2026 is niet dat teams niet personaliseren. Het is dat kopers heel goed zijn geworden in het herkennen van neppe personalisatie. zegt minder snel te reageren als ze denken dat een e-mail door AI is gegenereerd, en geeft inmiddels de voorkeur aan merken die GenAI vermijden in content richting klanten.
De echte uitdaging is niet personalisatie versus schaal. Het is personalisatie versus geloofwaardigheid. Deze gids gaat over het bouwen van een systeem dat je beide geeft — zonder het alarm “dit is nep” te triggeren.
Wat is personalisatie in koude e-mails (en waarom doen de meeste teams het nog steeds verkeerd)?
 Personalisatie in koude e-mails betekent dat elk outreach-bericht voelt alsof het speciaal voor één persoon is geschreven — niet uit een massatemplate is getrokken. Maar hier gaat het bij de meeste teams mis: ze denken dat personalisatie gelijkstaat aan meer merge tags. Dat is niet zo. Personalisatie staat gelijk aan relevantie.
Personalisatie in koude e-mails betekent dat elk outreach-bericht voelt alsof het speciaal voor één persoon is geschreven — niet uit een massatemplate is getrokken. Maar hier gaat het bij de meeste teams mis: ze denken dat personalisatie gelijkstaat aan meer merge tags. Dat is niet zo. Personalisatie staat gelijk aan relevantie.
Het spectrum loopt van simpele tokenwissels (\{FirstName\}, \{CompanyName\}) helemaal door tot contextrijke verwijzingen naar de werkelijke situatie van een prospect — een recente aanwervingsgolf, een productlancering, een herziening van de prijspagina. Een e-mail die de vermoedelijke pijn van een prospect raakt zonder ook maar één naam te noemen, presteert beter dan eentje vol merge fields die niets wezenlijks zegt.
Klachten uit de community bevestigen dit. Een Reddit-reactie vergeleek de klassieke opener “Ik zag dat je in de [branche]-hoek zit” met zeggen “Ik zag dat je een gezicht hebt.” Een andere salesprofessional op LinkedIn noemde de regel “Ik kwam je bedrijf tegen en was onder de indruk van...” . Het patroon is duidelijk: ontvangers wijzen personalisatie niet af. Ze wijzen luie personalisatie af die op iedereen van toepassing had kunnen zijn.
Nog iets dat we meteen moeten benoemen: de kwaliteit van personalisatie hangt af van de kwaliteit van je onderzoek. Het schrijven komt daarna. Als de inputdata mager is, redt geen enkele template of AI-prompt de output.
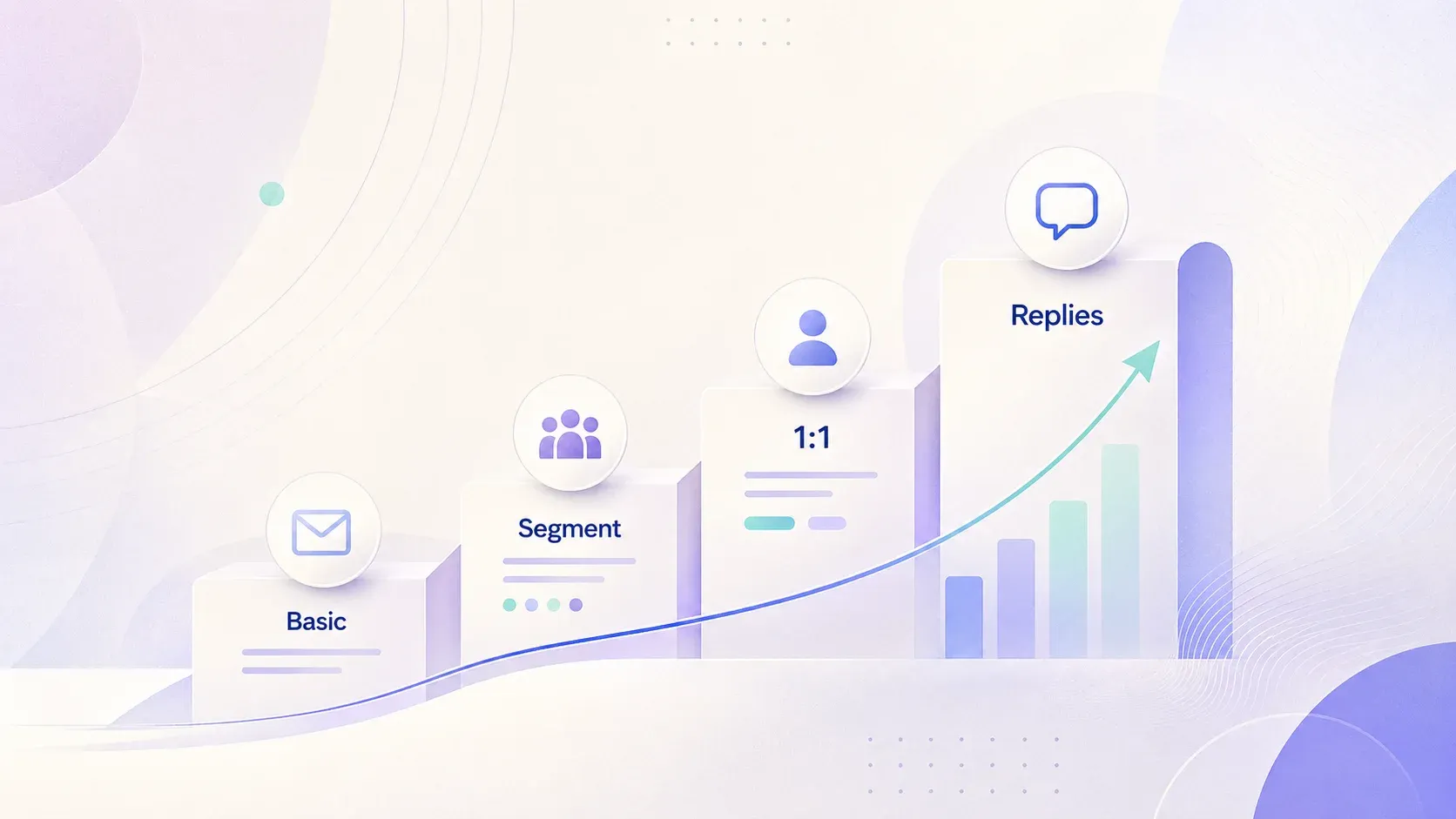
De cijfers liegen niet: antwoordspercentages bij koude e-mails per personalisatieniveau
Ik heb veel tijd besteed aan het naast elkaar leggen van vendor-benchmarks, door de community gerapporteerde cijfers en onze eigen observaties bij Thunderbit. De duidelijkste manier om de data te presenteren is in niveaus — omdat personalisatie niet binair is. Het is een spectrum, en elk niveau heeft een andere verhouding tussen inspanning en opbrengst.
| Personalisatieniveau | Inspanning per e-mail | Typische open rate | Typische reply rate | Beste voor |
|---|---|---|---|---|
| Geen (bulkblast) | ~0 sec | 20–30% | <1–3% | ❌ Niet aanbevolen |
| Basis (naam + bedrijf via merge) | ~5 sec | 35–45% | 3–6% | Lijsten met lage waarde, hoge omvang |
| Segmentgebaseerd (ICP + pijnpunt) | ~30 sec | 40–50% | 5–8% | Outbound op schaal voor mid-market |
| Diep 1-op-1 (onderzocht eerste zin) | 3–5 min | 50%+ | 8–15% | Enterprise / accounts met hoge ACV |
Bronnen: , , , .
Een paar eerlijke kanttekeningen: deze ranges verschuiven per sector, lijstkwaliteit en verzendreputatie. Open rates zijn vooral ruisgevoelig — dat afbeeldingsblokkering en privacyfuncties tracking vertekenen. En Hunter ontdekte dat campagnes met open tracking juist lagere reply rates kregen () dan campagnes zonder tracking.
Toch blijft het patroon in elke dataset die ik heb bekeken hetzelfde: relevantere personalisatie → meer reacties. De vraag is waar je de grens legt.
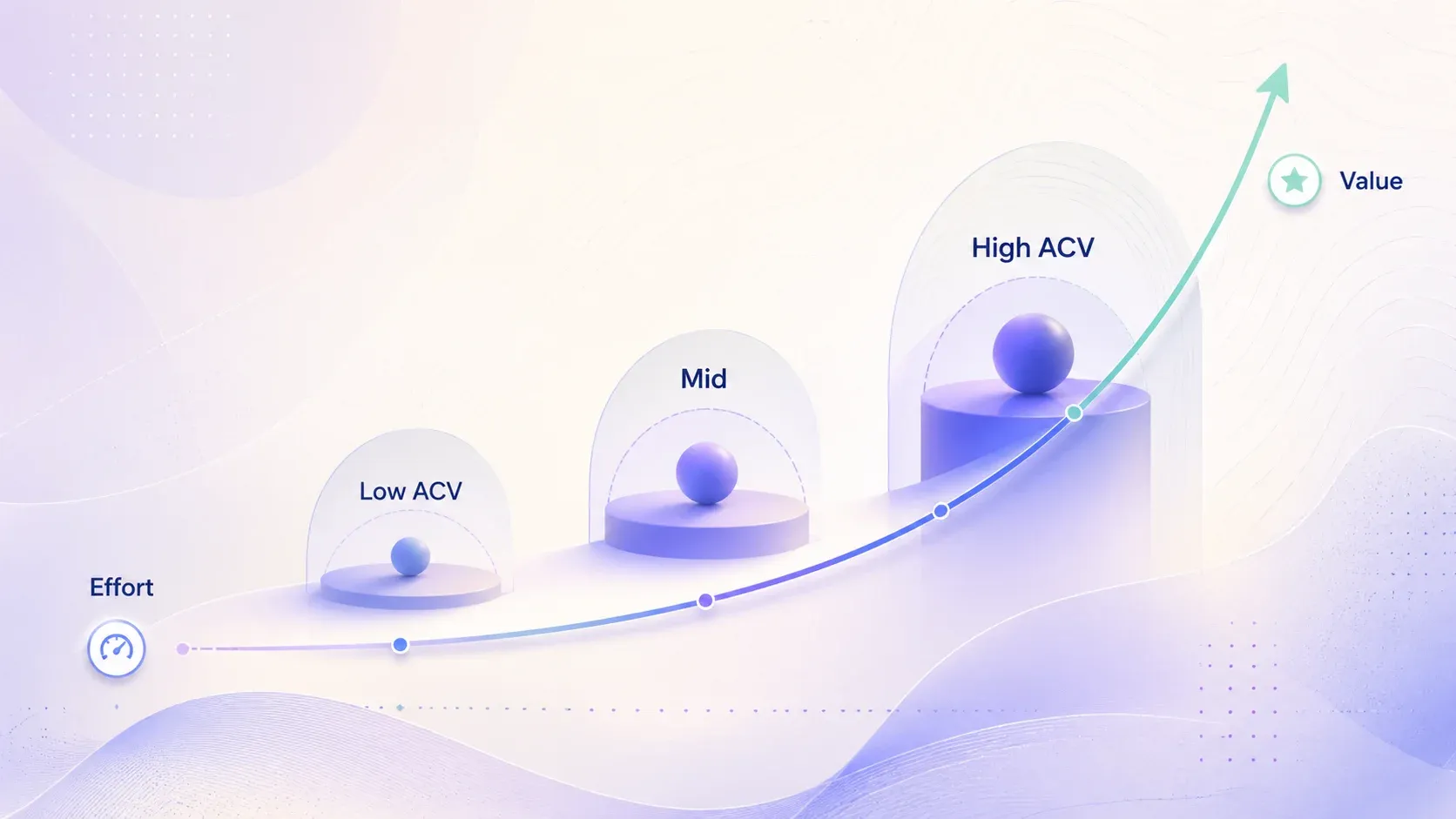
Wanneer diepere personalisatie de extra moeite niet meer waard is
Er is sprake van afnemend rendement, en dat hangt samen met de dealgrootte. Als je een product van $500 per maand verkoopt, is het waarschijnlijk niet rendabel om vijf minuten per prospect aan maatwerkonderzoek te besteden. Als je jaagt op een jaarlijks contract van $50K+, dan absoluut wel.
Een praktische vuistregel:
- ACV boven ongeveer $30K–50K: Diepe 1-op-1-personalisatie is gerechtvaardigd. De opbrengst per reactie is hoog genoeg om de onderzoekskosten op te vangen.
- ACV $5K–$30K: Segmentgebaseerde personalisatie is de sweet spot. Bouw 5–8 persona-specifieke templates rond echte pijnpunten.
- ACV onder $5K: Basis merge-personalisatie, maar alleen met een zeer schone, goed getargete lijst.
ondersteunen deze benadering: teams met een hogere ACV moeten zich benchmarken tegen strakkere verwachtingen voor reply rates en meer per prospect investeren.
Hoe je personalisatiesignalen verzamelt zonder gek te worden
De meeste gidsen over personalisatie springen meteen naar schrijven. Dat is omgekeerd gedacht. Het lastigste deel van personalisatie op schaal is niet zinnen genereren. Het is snel genoeg recente, bruikbare en rolrelevante signalen vinden om de moeite te rechtvaardigen.
Dat is de data-pijplijnstap die concurrenten overslaan — en precies waar de echte bottleneck zit.
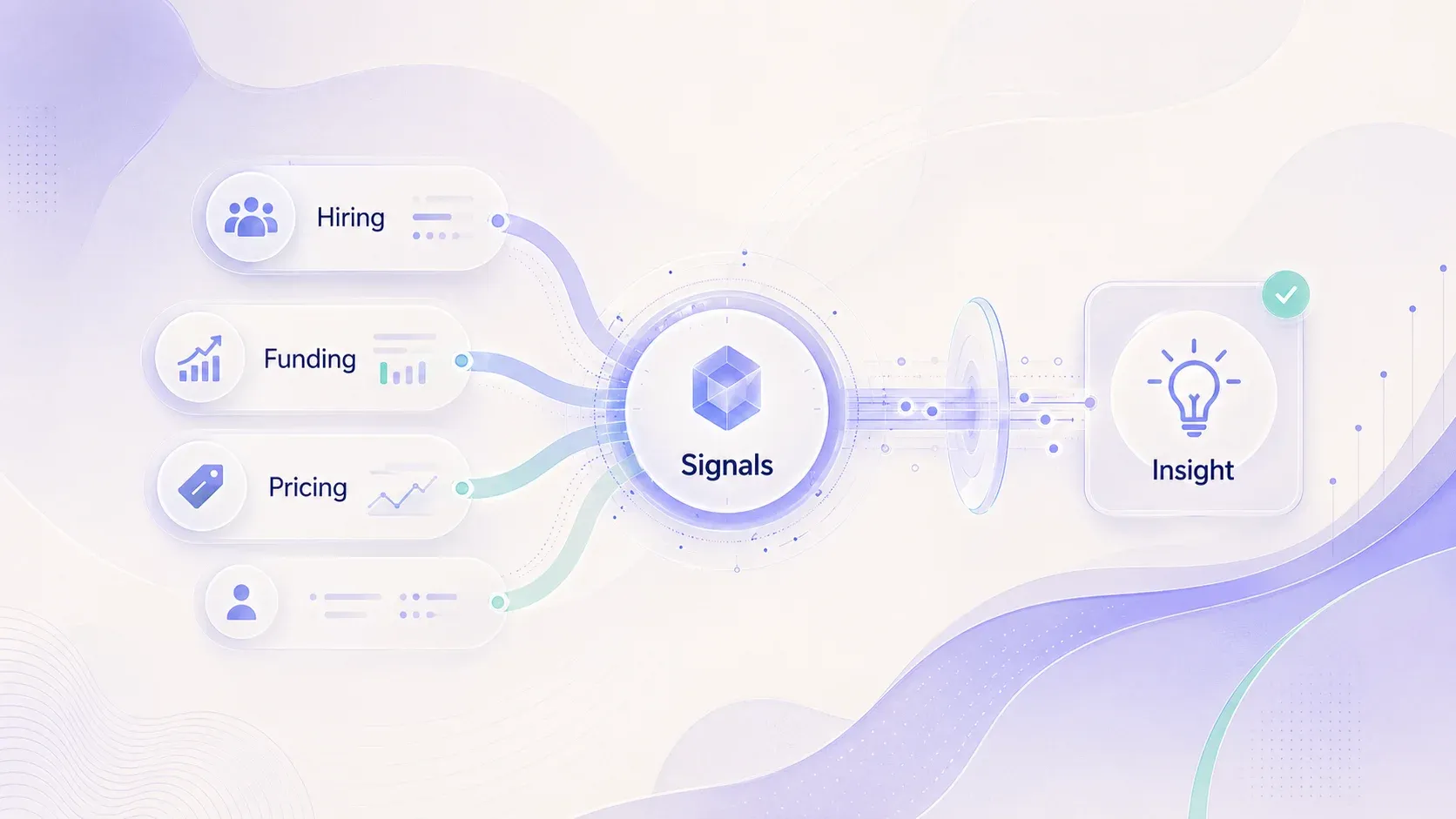
Welke signalen je moet zoeken (en waar je ze vindt)
Niet alle signalen zijn even sterk. De beste zijn recent en specifiek genoeg om niet te faken. “Jullie bedrijf groeit” is zwak. “Jullie hebben in twee weken drie DevOps-vacatures geplaatst” is sterk — omdat het wijst op een waarschijnlijk operationeel knelpunt.
Hier is waar je op moet letten en waar je het meestal vindt:
| Signaal | Waar te vinden |
|---|---|
| Recente financieringsrondes | Crunchbase, persberichten, investeerderspagina’s |
| Aanwervingspieken / functieclusters | Carrièrepagina’s, LinkedIn Jobs, vacaturebanken |
| Veranderingen in de tech stack | Engineeringblog, functiebeschrijvingen, productdocumentatie |
| Wijzigingen in prijs of packaging | Prijspagina, changelog, productmarketingpagina’s |
| Veranderingen in positionering | Homepage, oplossingspagina’s, bedrijfsblog |
| Prioriteiten van de directie | Earnings calls, podcasts, LinkedIn-posts |
De kern is dat elk signaal moet te koppelen zijn aan een plausibele zakelijke uitdaging. Een financieringsronde impliceert schaaldruk. Een cluster van DevOps-aanwervingen wijst op infrastructuurpijn. Een complete herziening van de prijspagina duidt op een nieuwe concurrentiepositie. Je verzamelt dus niet alleen feiten — je bouwt hypothesen over wat deze prospect op dit moment belangrijk vindt.
Versnel onderzoek met AI-webscraping zonder in te leveren op datakwaliteit
Handmatig onderzoek is grondig, maar traag. In mijn ervaring komt volledig handmatig prospectonderzoek uit op ongeveer 5–10 prospects per uur — en dat is met een gefocuste SDR die weet waar hij moet zoeken. Voor de meeste outboundteams is dat op schaal niet houdbaar.
Hier past AI-gedreven webscraping natuurlijk goed. Bij hebben we onze Chrome-extensie precies voor deze workflow gebouwd: bezoek de bedrijfswebsite van een prospect, laat de AI teampagina’s, productpagina’s, carrièresecties, Over ons-details en blogposts scannen, en exporteer daarna gestructureerde data naar Google Sheets of je CRM. De is hier vooral handig voor — je hoeft niet handmatig door elke sectie van een site te klikken. De scraper bezoekt automatisch relevante subpagina’s en verrijkt de dataset zonder die eindeloze tab-switch-marathon.
Zo verhouden de onderzoeksmethoden zich in de praktijk:
| Onderzoeksmethode | Prospects/uur | Datakwaliteit | Kosten |
|---|---|---|---|
| Volledig handmatig (Google + LinkedIn) | 5–10 | Hoog | Gratis (alleen tijd) |
| AI-webscraper (bijv. Thunderbit) + handmatige review | 40–80 | Hoog (met QC) | Laag |
| Alleen enrichment API (geen webcontext) | 100+ | Middelmatig (alleen gestructureerd) | Middelmatig–hoog |
De hybride aanpak — AI scrapen plus menselijke review — levert consequent de beste balans op. Enrichment API’s zijn snel, maar missen de genuanceerde, verhalende signalen (recente blogposts, prijswijzigingen, commentaar van leiderschap) die personalisatie echt maken. Handmatig onderzoek vangt alles, maar schaalt niet. De middenweg is waar de meeste teams uitkomen.
Voor een diepere uitleg over hoe je Thunderbit voor dit soort onderzoek inzet, bekijk onze of onze .
Hoe je elk onderdeel van een koude e-mail personaliseert (met voor- en na-voorbeelden)
Zodra je signalen hebt, is de volgende stap ze omzetten in e-mailcopy die specifiek aanvoelt — niet scriptmatig. Elk onderdeel van een koude e-mail heeft een eigen functie, en elk onderdeel vraagt om een andere vorm van personalisatie.
Onderwerpregels die geopend worden
De taak van de onderwerpregel is de open te verdienen. De data hier is genuanceerd: dat gepersonaliseerde onderwerpregels 46% opens opleverden tegenover 35% zonder personalisatie, maar Lavender’s onderzoek suggereert dat personalisatie met voornaam in onderwerpregels juist minder reacties kan opleveren: 12% daling. lieten zelfs zien dat niet-gepersonaliseerde onderwerpregels beter scoorden dan gepersonaliseerde op opens (41,87% vs. 35,78%).
De conclusie is simpel: contextuele specificiteit wint het van cosmetische naamsvermeldingen.
- Voor: “Snelle vraag voor je”
- Na: “Je nieuwe Kubernetes-migratie”
De tweede onderwerpregel laat zien dat de afzender iets specifieks weet. Een voornaam is niet nodig om persoonlijk te voelen.
Openingszinnen die specifiek aanvoelen, niet scriptmatig
De openingszin is het moment waarop alles staat of valt. Die moet verwijzen naar een specifiek, verifieerbaar signaal — niet naar een generiek compliment. Hier is een snelle checklist:
-
Is het specifiek voor DEZE persoon of dit bedrijf?
-
Kan het alleen voor hen waar zijn? (Als het op 100 andere bedrijven ook van toepassing is, herschrijf het.)
-
Verbindt het met een zakelijke uitdaging, en niet alleen met vleierij?
-
Voor: “Ik zag dat jullie bedrijf geweldige dingen doet in de SaaS-wereld.”
-
Na: “Ik zag dat jullie team deze maand drie DevOps-rollen heeft geplaatst — infrastructuur zo snel opschalen betekent meestal dat deployment-bottlenecks zich opstapelen.”
De eerste is het koude-e-mail-equivalent van “leuke trui.” De tweede laat zien dat de afzender huiswerk heeft gedaan en een hypothese heeft over de wereld van de prospect.
Bodycopy die laat zien dat je hun workflow begrijpt
De body moet de gepersonaliseerde opener verbinden met je waardepropositie. Herhaal de opener niet. Noem geen features op. Gebruik een “brugzin” die het signaal koppelt aan het probleem dat jij oplost, en voeg daarna een verwijzing naar een peer toe voor geloofwaardigheid.
Houd het bij 2–3 zinnen. laat zien dat de best presterende campagnes e-mails onder de 80 woorden houden. vond dat e-mails van 6–8 zinnen een gemiddelde reply rate van 6,9% haalden, maar korter en strakker werkt in koude outreach meestal beter.
- Voor: “Wij bieden een cloud-infrastructuurplatform met autoscaling, CI/CD-pipelines en 24/7 monitoring.”
- Na: “We hielpen het DevOps-team van [peer company] de deploytijd met 40% te verlagen na een vergelijkbare aanwervingsgolf — zonder extra headcount voor het operations-team.”
CTA’s die relevant voelen, niet generiek
Laat je vraag aansluiten op het vertrouwensniveau. Koude prospects willen niet meteen “een demo inplannen”. Ze willen een eerste stap met weinig verplichting.
- Voor: “Laat het me weten als je een demo wilt plannen.”
- Na: “Ik deel graag de aanpak die we bij [vergelijkbaar bedrijf] gebruikten — zal ik die sturen?”
De tweede CTA biedt eerst waarde, voordat er om tijd wordt gevraagd. Dat is voor een vreemde een veel lagere drempel.
Personalisatie in koude e-mails per buyer persona: wat werkt voor de CFO, de CTO en de VP Sales
Een van de meest onderschatte bevindingen uit recent onderzoek naar koude e-mails is dat dezelfde kwaliteit personalisatie heel anders presteert per rol. De benchmarkdata van Lavender laat zien:
- Financiële kopers zaten gemiddeld op 3,2% reply rate, maar hoogwaardige finance-e-mails stegen naar 5,7% — een stijging van 79%.
- Marketingkopers zaten gemiddeld op 3,2%, en stegen naar 4,2% — een stijging van 31%.
- Technische kopers zaten gemiddeld op 5,2%, maar sterkere e-mails brachten dat slechts naar 5,5% — ongeveer 6% stijging.
De implicatie is duidelijk: wat als “relevant” telt, hangt af van de persona. Een CFO kijkt naar margedruk en kostenefficiëntie. Een CTO kijkt naar technische fit en engineering-snelheid. Voor beide dezelfde invalshoek gebruiken is lui, en de data laat dat zien.
| Buyer persona | Signalen die aanspreken | Personalisatie-invalshoek | Voorbeeld van openingszin |
|---|---|---|---|
| CFO / Finance | Omzetmijlpalen, financiering, marges | ROI & kostenverlaging | “Ik zag dat jullie Q3-rapport margedruk in de logistiek benadrukte…” |
| CTO / Engineering | Tech stack, werving voor specifieke rollen, open-sourcebijdragen | Technische fit & efficiëntie | “Ik zag dat jullie team naar Kubernetes migreert — we hielpen [peer] de deploytijd met 40% te verlagen…” |
| VP Sales / CRO | Doelstellingen gehaald, teamgroei, toetreding tot nieuwe markten | Pipeline & conversie-impact | “Jullie sales-team is dit jaar 3x gegroeid — benieuwd of de outbound-infrastructuur hetzelfde tempo heeft gehouden…” |
| Marketing Lead | Campagnelanceringen, verschuivingen in contentstrategie, merkvermeldingen | Awareness & demand gen | “Jullie recente rebrand viel me op — de positioneringsverschuiving richting enterprise is slim…” |
De praktische les: bouw 5–8 sterke templates die zijn gekoppeld aan specifieke persona’s en pijnpunten. Deze segmentgebaseerde aanpak presteert vaak beter dan slordige 1-op-1 AI-regels — omdat een goed gemaakte template met de juiste invalshoek altijd wint van een slecht onderzocht “gepersonaliseerde” opener.
Voor meer informatie over het opbouwen van prospectlijsten per persona, zie onze .
Het onderdeel dat elke gids overslaat: hoe je personalisatie levend houdt in e-mails 2–5
Dit is momenteel het grootste gat in advies over koude e-mails. Ik heb tientallen gidsen gelezen, en bijna geen enkele gaat in op wat er gebeurt na e-mail 1. Toch lopen de meeste koude-e-mailcampagnes 3–5 touches, en laat zien dat follow-ups 42% van alle reacties opleveren. dat de eerste follow-up een 40% hogere reply rate kan hebben dan de opener.
Het probleem? Personalisatie zakt meestal naar nul na e-mail 1. Follow-ups worden generieke duwtjes: “Even checken”, “Zet ik dit nog even bovenaan je inbox”, “Heb je mijn laatste e-mail gezien?”
Dat is zonde. Elke follow-up is een kans om nieuw bewijs toe te voegen dat je aandachtig bent. Hier is een framework dat voor ons effectief werkt:
E-mail 1: de diep gepersonaliseerde opener
Gebruik het sterkste onderzochte signaal als haakje. Hier besteed je de meeste moeite aan — dit legt geloofwaardigheid vast voor de rest van de sequentie.
E-mail 2: verwijs naar een nieuw, ander signaal
Herhaal niet het signaal uit e-mail 1. Zoek een tweede signaal uit een andere bron — een recente LinkedIn-post, een nieuwe vacature, een update in de bedrijfsblog. Koppel terug naar de waardepropositie uit e-mail 1: “Ik kom even terug op mijn bericht over [X] — ik zag ook [nieuw signaal].”
E-mail 3: verander de invalshoek met peer proof of concurrentie-inzicht
Gebruik een case study of concurrentie-inzicht dat relevant is voor hun segment. “Teams zoals [peer company] in [hun sector] liepen tegen hetzelfde probleem aan en zagen [resultaat].” Dat verlaagt de ervaren risico’s en voegt social proof toe.
E-mail 4: gebruik een timingtrigger
Verwijs naar een realtime gebeurtenis: “Ik zag dat jullie team net een rol voor [X] heeft geplaatst — dat betekent meestal dat [Y-uitdaging] op de radar staat.” Zo blijft de reeks actueel aanvoelen, niet geautomatiseerd.
E-mail 5: de breakup-mail met een gepersonaliseerde samenvatting
Vat samen waarom je contact opnam, welke signalen je zag en welke waarde je bood. Houd het kort en respectvol: “Ik stop met mailen — maar ik wilde je nog [bron] meegeven voor het geval [pijnpunt] later toch speelt.”
Een belangrijke kanttekening: laat zien dat spamklachten stijgen van 0,5% op e-mail 1 naar 1,6% op e-mail 4, en dat unsubscribes rond ronde 4 de 2% aantikken. Elke follow-up moet dus echte waarde toevoegen. Als je alleen maar blijft porren, brand je vertrouwen op.
Voor meer over het structureren van outbound-sequenties, bekijk onze en .
Het vertrouwensprobleem bij AI-personalisatie: wat wordt afgekeurd en hoe los je het op?
AI kan helpen met personalisatie op schaal. Maar ongecontroleerde AI-personalisatie kan reply rates juist schaden. Het bewijs is behoorlijk vernietigend:
- in een Adobe Express-enquête uit 2025 zei minstens één merkmail te hebben ontvangen die door AI was geschreven.
- had zich uitgeschreven omdat ze vermoedden dat een e-mail door AI was geschreven.
- zegt het storend te vinden als AI is gebruikt — tenzij het resultaat nog steeds menselijk en relevant aanvoelt.
Het probleem is niet dat AI betrokken is. Het is dat robotachtige formuleringen, verzonnen feiten en neppe bewondering wantrouwen oproepen. Een Reddit-gebruiker in beschreef het patroon “Ik zag dat je…” als “een template die doet alsof het een persoon is.” Dat is de foutmodus.
Een QC-checklist voor door AI gegenereerde personalisatielijnen
Voordat een door AI geschreven e-mail de deur uitgaat, loop je deze vijf checks door:
- Is het aangehaalde feit verifieerbaar? Google het. Als AI een detail heeft verzonnen (hallucinaties zijn echt — communityrapporten suggereren ongeveer 1 op de 40 leads), verlies je meteen geloofwaardigheid.
- Kan dit compliment ook op 100 andere bedrijven slaan? Zo ja, herschrijf.
- Gebruikt het “Ik zag…” of “Ik was onder de indruk van…”? Dat zijn typische AI-startzinnen. Herschrijf ze.
- Klopt de bedrijfsnaam, rol en sector allemaal? Controleer op hallucinaties.
- Verbindt het met een echt zakelijk probleem, of is het alleen maar vleierij?
Tips voor prompt engineering voor betere AI-output
De kwaliteit van AI-personalisatie hangt af van de data die je erin stopt. Een vage prompt levert vage output op. Een afgebakende prompt met echte signalen levert iets bruikbaars op.
- Slechte prompt: “Schrijf een gepersonaliseerde eerste zin voor [bedrijf].”
- Betere prompt: “Gebruik deze data over [prospect]: [plak gescrapete data van Thunderbit of uit het CRM]. Schrijf een openingszin van 1 zin die verwijst naar hun [specifiek signaal] en dit koppelt aan [pijnpunt]. Schrijf in een informele, directe toon. Begin niet met ‘Ik zag’ of ‘Ik was onder de indruk.’”
Het verschil is dag en nacht. De eerste prompt geeft de AI niets om mee te werken. De tweede geeft beperkingen, context en een duidelijk outputformaat.
AI vs. handmatig vs. hybride: een eerlijke vergelijking
| Aanpak | Volume/dag | Kwaliteit | Risico op hallucinaties | Beste voor |
|---|---|---|---|---|
| Volledig door AI gegenereerd | 200+ | Laag–middelmatig | ⚠️ Hoog | Alleen met strikte QC-laag |
| AI-ontwerp + menselijke edit | 50–100 | Hoog | Laag (afgevangen in edit) | De meeste B2B-outboundteams |
| Volledig handmatig onderzoek + schrijven | 10–20 | Zeer hoog | Geen | Enterprise ABM-acties |
Voor de meeste teams is de hybride aanpak — AI-ontwerp plus menselijke edit — de sweet spot. Je krijgt de snelheid van automatisering, met het oordeel van een echt persoon die fouten opvangt, clichés verwijdert en de invalshoek aanscherpt. De boodschap van dit artikel is niet “personaliseer elke e-mail met AI.” Het is personaliseer strategisch, en verifieer meedogenloos.
Tools en aanpakken voor personalisatie van koude e-mails op schaal
Geen enkele tool dekt de hele personalisatie-workflow af. De beste stacks combineren lagen, waarbij elke laag één taak goed uitvoert.
| Type tool | Wat het doet | Sterktes | Beperkingen |
|---|---|---|---|
| AI-webscraper (bijv. Thunderbit) | Extraheert prospectdata uit websites op schaal | Pakt ongestructureerde signalen mee (blogs, teampagina’s, carrièrepagina’s); subpage scraping | Vereist menselijke review voor QC |
| Enrichment API (bijv. Apollo, Clearbit) | Voegt firmografische/technografische data toe aan leads | Snelle, gestructureerde data op schaal | Mist genuanceerde signalen (recente blogposts, prijswijzigingen) |
| AI-schrijfassistent (bijv. Lavender) | Scoort e-mailcopy en doet verbetersuggesties | Realtime feedback, toonanalyse | Heeft nog steeds kwalitatieve inputdata nodig |
| Platform voor koude e-mail (bijv. Saleshandy, Smartlead) | Verstuurt gepersonaliseerde sequenties met merge fields en planning | Automatiseert verzending, trackt opens/reacties | Personalisatiekwaliteit hangt af van wat je erin stopt |
De workflow die voor de meeste teams logisch is:
Scrapen → normaliseren → verrijken → opstellen → QC → verzenden → tracken
Thunderbit regelt de scrape-en-normalize-stap: haal gestructureerde data van bedrijfswebsites, exporteer naar of Excel, en voed dat vervolgens in je enrichment- en verzendtools. Apollo of iets vergelijkbaars verzorgt de firmografische verrijking. Lavender of ChatGPT helpt met opstellen. Saleshandy of Smartlead verzorgt levering en tracking.
Het punt is dat deze tools elkaar aanvullen, niet met elkaar concurreren. Een scraper zonder sender is gewoon een spreadsheet. Een sender zonder goede data is gewoon een spamkanon.
Stap voor stap: hoe je koude e-mails op schaal personaliseert (alles samenbrengen)
Hier is de geconsolideerde workflow, die alle eerdere secties samenbrengt tot een herhaalbaar systeem. Zie het als de playbook die we vandaag zouden volgen als we vanaf nul een personalisatie-engine voor koude e-mails zouden bouwen.
Stap 1: definieer je ICP en segmenteer je lijst
Voordat je iets personaliseert, segmenteer je prospectlijst op persona (CFO, CTO, VP Sales, enz.) en op accountniveau (enterprise = diep 1-op-1, mid-market = segmentgebaseerd). Dit bepaalt hoeveel onderzoek elke prospect krijgt.
Stap 2: scrape personalisatiesignalen op schaal
Gebruik Thunderbit of een vergelijkbare AI-webscrapingtool om prospectdata te halen uit bedrijfswebsites, LinkedIn, vacaturebanken en andere publieke bronnen. Gebruik Thunderbit’s “AI Suggest Fields” om de tool automatisch te laten bepalen welke data moet worden geëxtraheerd. Exporteer de gestructureerde output naar Google Sheets of je CRM.
Voor een stap-voor-stap uitleg van Thunderbit’s scrapingworkflow, bekijk de of onze .
Stap 3: bouw 5–8 persona-specifieke templates
Schrijf segmentgebaseerde templates voor elke persona, elk rond een specifiek pijnpunt. Laat placeholders open voor de gepersonaliseerde opener en brugzin. De template regelt body en CTA; de personalisatielaag regelt de eerste 1–2 zinnen.
Stap 4: schrijf (of laat AI draften) gepersonaliseerde openers
Gebruik de gescrapete data om handmatig of met AI openingszinnen voor elke prospect te schrijven. Pas de QC-checklist toe voordat iets de deur uitgaat. Als je AI gebruikt, geef dan de gescrapete signalen mee en beperk het outputformaat.
Stap 5: bouw een multi-touch-sequentie met verse signalen bij elke stap
Werk 3–5 e-mails per prospect uit, met bij elk contactmoment een ander personalisatiesignaal. E-mail 1 krijgt het diepste signaal. Elke follow-up introduceert nieuwe context — een ander datapunt, een peer proof, een timingtrigger.
Stap 6: verzend, track en iterer
Gebruik een platform voor koude e-mails om te plannen en te verzenden. Track open rates, reply rates en positieve reply rates per personalisatieniveau en persona. Itereer op welke signalen en invalshoeken de beste resultaten opleveren. Verdubbel op wat werkt; snijd weg wat niet werkt.
Het hele proces — van scrapen tot verzenden — is voor de meeste teams in een paar dagen op te zetten. Het onderhoud daarna draait vooral om het verversen van signalen en het finetunen van templates op basis van prestatiedata.
Belangrijkste inzichten
Personalisatie van koude e-mails op schaal draait niet om kiezen tussen kwaliteit en volume. Het draait om een systeem bouwen dat je beide geeft — zonder te faken.
- Relevantie wint het van vleierij. Een segmentgebaseerde template met de juiste invalshoek presteert beter dan een slordige AI-gegenereerde “Ik zag…”-opener.
- De kwaliteit van je onderzoek = de kwaliteit van je personalisatie. De bottleneck is niet schrijven — het is snel genoeg recente, specifieke en rolrelevante signalen vinden. AI-webscraping (zoals ) verkort die bottleneck enorm.
- Persona maakt uit. Wat een CFO beweegt, is anders dan wat een CTO beweegt. Koppel je templates aan buyer-rollen, niet alleen aan bedrijfsnamen.
- Follow-ups hebben verse signalen nodig. Personalisatie mag niet sterven na e-mail 1. Elk contactmoment in de sequentie moet nieuw bewijs geven dat je oplet.
- AI helpt, maar alleen met vangrails. De hybride aanpak — AI-ontwerp plus menselijke edit — is voor de meeste teams de betrouwbaarste methode. Verifieer feiten, verbied clichés en stuur nooit iets dat je zelf niet zou willen lezen.
Een praktische volgende stap: audit je huidige outreach. Op welk personalisatieniveau zit je nu? Wat zou nodig zijn om één niveau omhoog te gaan? Zelfs van “basis merge” naar “segmentgebaseerd” gaan kan je reply rates al merkbaar verbeteren — zonder enorme tijdsinvestering.
Als je wilt beginnen met het opbouwen van je research-pijplijn, op een kleine lijst en kijk hoe snel je een set prospect-URL’s kunt omzetten in gestructureerde, bruikbare signalen.

FAQ’s
Verbetert personalisatie in koude e-mails echt de reply rates?
Ja, en de data is consistent over meerdere benchmarks. Niet-gepersonaliseerde bulkblasts zitten meestal rond 1–3% reply rate, terwijl goed uitgevoerde diepe personalisatie 8–15% kan halen. De exacte cijfers verschillen per sector, lijstkwaliteit en verzendreputatie, maar de trend is echt. Bronnen zijn onder meer , en .
Hoeveel tijd moet ik besteden aan het onderzoeken van elke prospect?
Dat hangt af van de accountwaarde. Voor enterprise-deals ($50K+ ACV) zijn 3–5 minuten per prospect gerechtvaardigd. Voor mid-market op schaal kun je AI-webscrapingtools gebruiken om de onderzoekstijd terug te brengen naar 30–60 seconden per prospect, gevolgd door een menselijke QC-check. Het hybride model — AI scrapen plus handmatige review — levert consequent de beste verhouding tussen snelheid en kwaliteit op.
Kan AI gepersonaliseerde koude e-mails schrijven die niet nep klinken?
AI kan personalisatie opstellen, maar heeft kwalitatieve inputdata en menselijke review nodig. De grootste risico’s zijn verzonnen feiten, generieke complimenten en herkenbare formuleringen zoals “Ik zag…” of “Ik was onder de indruk van…” De meest betrouwbare aanpak voor de meeste B2B-teams is AI-ontwerp plus menselijke edit — fouten eruit halen en de invalshoek aanscherpen voordat iets de deur uitgaat.
Hoeveel follow-up e-mails moet ik sturen, en moet elk bericht gepersonaliseerd zijn?
De meest verdedigbare bandbreedte is 3–5 follow-ups (4–7 touches in totaal). Ja, elke follow-up moet minstens één vers, gepersonaliseerd signaal bevatten. laat zien dat follow-ups 42% van alle reacties opleveren, maar waarschuwt dat spamklachten en uitschrijvingen na de derde follow-up toenemen, tenzij elke touch nieuwe waarde toevoegt.
Is personalisatie van koude e-mails legaal?
Koude e-mailen is legaal als je het correct doet. In de VS is volledig van toepassing op B2B-commerciële e-mail — er is geen B2B-uitzondering. Belangrijke vereisten: nauwkeurige onderwerpregels, duidelijke afzenderidentificatie, een geldig postadres, een werkende opt-out-mogelijkheid en het honoreren van opt-outs binnen 10 werkdagen. In het VK/EU zijn strenger en moet je voorzichtiger omgaan met toestemming en gegevensverwerking.
Meer lezen