YouTube heeft meer dan en . Het is ook een van de lastigste platforms om te scrapen zonder tegen een muur van CAPTCHA’s, 429-fouten of directe IP-blokkades aan te lopen.
Als je ooit hebt geprobeerd kanaalgegevens, reacties of transcripties op welke schaal dan ook binnen te halen, ken je de frustratie al. Je krijgt een paar honderd resultaten en dan trekt YouTube de stekker eruit. Ik heb veel tijd besteed aan het evalueren van hoe verschillende scraping-aanpakken standhouden tegenover de steeds veranderende anti-botbeveiliging van YouTube, en het verschil tussen tools die betrouwbaar werken en tools die je binnen enkele minuten blokkeren is enorm.
Deze gids behandelt de 6 beste YouTube-scrapers voor 2026—tools die echt zijn ontworpen om met de vijandigheid van YouTube om te gaan zonder je IP of je workflow op te blazen. Of je nu een marketeer bent die concurrentiekanalen volgt, een salesteam dat contactgegevens van creators zoekt, of een ontwikkelaar die een datapijplijn bouwt, hier zit een optie tussen die past.
Wat YouTube in 2026 daadwerkelijk blokkeert (en waarom de meeste scrapers falen)
De anti-botbeveiliging van YouTube is niet één enkele muur, maar een gelaagd systeem. Begrijpen waar je tegenop bokst is de eerste stap om niet geblokkeerd te worden.
Dit doet YouTube in 2026 om geautomatiseerde toegang te detecteren en af te remmen:

- IP-reputatie en snelheidscontroles: Herhaalde verzoeken vanaf datacenter-IP’s, VPN’s of gedeelde proxies worden snel gemarkeerd. Je ziet 403-fouten, 429 rate limits of schermen met „log in om te bevestigen dat je geen bot bent”.
- Browser- en JavaScript-fingerprinting: YouTube controleert of de client zich gedraagt als een echte browser—scripts uitvoeren, elementen renderen en de verwachte status behouden. Headless browsers en ruwe HTTP-clients falen deze controles vaak stilletjes (je krijgt gewoon lege of gedeeltelijke data).
- Vertrouwen in cookies en sessies: Als je verzoeken niet uit een herkende, langdurige browsersessie komen, voert YouTube de verificatie op. Ingelogde sessies met browsegeschiedenis krijgen meer vertrouwen dan nieuwe, anonieme sessies.
- Gedragsanalyse: Uniforme verzoekintervallen, te snel scrollen of herhaalde paginapatronen triggeren throttling. YouTube zoekt naar navigatie die geen mens zou uitvoeren.
- CAPTCHA-poorten: Bij een hoog risico dwingt YouTube menselijke verificatie af—vooral op zoekresultaten en in reactiesecties.
- Handhaving van API-quota: De officiële YouTube Data API hanteert dagelijkse quota op projectniveau (standaard 10.000 units/dag), en workflows met veel zoekopdrachten verbranden die in enkele minuten.
De typische gebruikerservaring: je begint met scrapen, haalt een paar honderd resultaten binnen en loopt dan vast op Error 429, een CAPTCHA-muur of stilletjes verminderde datakwaliteit. Cloud-scrapers die vanaf datacenter-IP’s draaien zijn extra kwetsbaar.
| Detectiemethode | Wat het doet | Symptoom voor de gebruiker | Tools die het risico verlagen |
|---|---|---|---|
| IP-reputatie/snelheid | Markeert datacenter-/VPN-/gedeelde IP’s | 403, 429, botbevestiging | Scrapen binnen browsersessie, residential proxies |
| JS-fingerprinting | Controleert op echte browseruitvoering | Stil ontbrekende data, CAPTCHA | Echte browserextensie, volledige rendering |
| Vertrouwen in cookies/sessie | Vergelijkt met ingelogde profielen | „Log in om te bevestigen” | Gebruikerscookies, geauthenticeerde sessie |
| Gedragsanalyse | Detecteert niet-menselijke patronen | Throttling na ~200 rijen | Menselijke vertragingen, randomisatie, kleine batches |
| API-quota-handhaving | Beperkt dagelijkse API-units | 403 quotaExceeded | Gebruik scrapers voor zoeken/reacties, API voor gerichte opvragingen |
| CAPTCHA-poorten | Dwingt menselijke verificatie af | Extractie stopt midden in de run | Browsersessie, proxy/unblocker, langzamer tempo |
De kern: tools die werken binnen een echte browsersessie (zoals Thunderbit) omzeilen veel van deze controles natuurlijk, omdat het verzoek er voor YouTube hetzelfde uitziet als normaal menselijk gebruik. Cloud-only scrapers hebben proxyrotatie, CAPTCHA-oplossing en zorgvuldig tempo nodig om overeind te blijven.
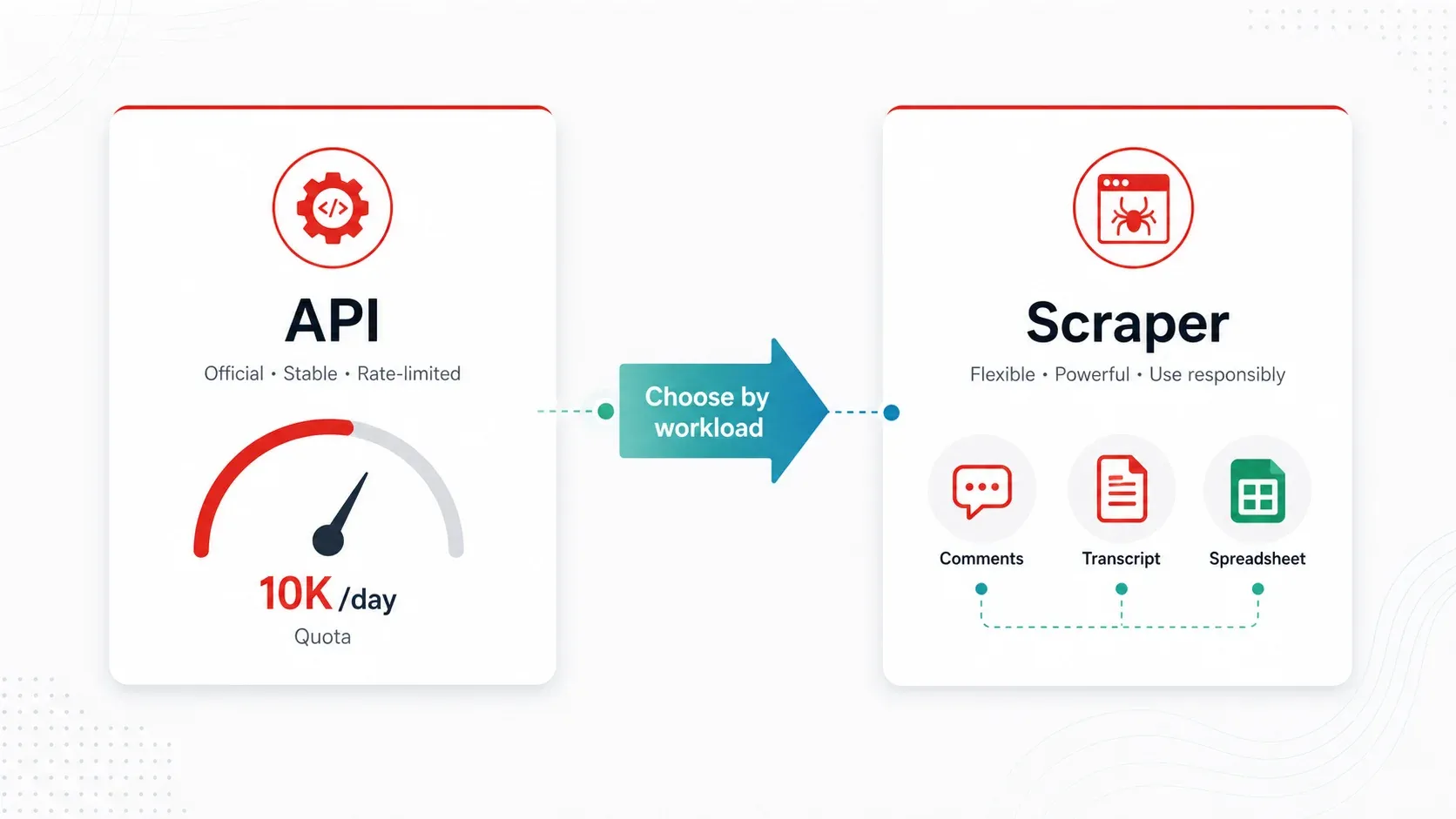
YouTube API versus de beste YouTube-scrapers: een praktisch besliskader
De YouTube Data API v3 is de „officiële” manier om programmatisch toegang te krijgen tot YouTube-data. Voor basismetadata bij laag volume is het betrouwbaar, maar het quota-model maakt het onpraktisch voor de meeste echte workflows rond concurrentieanalyse en onderzoek.
Hier is de rekensom. Elk API-project krijgt . Belangrijke endpoint-kosten:
search.list= 100 units per pagina (max. 50 resultaten per pagina)videos.list= 1 unit per oproep (tot 50 video-ID’s per oproep)commentThreads.list= 1 unit per oproep (tot 100 threads per oproep)
Dus als je 100 zoekopdrachten met keywords per dag uitvoert, is je volledige dagelijkse quota al op voordat je ook maar één video verrijkt hebt. Een workflow met veel reacties is per oproep goedkoper, maar echte paginering, uitgeschakelde reacties en het uitbreiden van antwoorden vreten de capaciteit snel op.
Wanneer de API genoeg is:
- Je hebt minder dan 100 video’s per dag nodig en alleen openbare metadata (titel, weergaven, likes, duur)
- Een ontwikkelaar kan OAuth opzetten en quota beheren
Wanneer een scraper beter is:
- Je hebt reacties op schaal nodig (de API werkt, maar quota-frictie is echt)
- Je hebt transcripties/ondertitels als tekst nodig (de API geeft ondertitelingstekst niet makkelijk op grote schaal bloot)
- Je monitort regelmatig 100+ kanalen (quota loopt op, planning is handmatig)
- Je hebt verrijkte of gelabelde data nodig (categorisering, vertaling of AI-gedreven veldherkenning)
- Je bent een niet-technische gebruiker die gewoon een spreadsheet wil
De API geeft ook niet alles bloot wat je op het web ziet: Shorts-shelf-data, publieke e-mails uit kanaalbeschrijvingen, community posts en sommige kanaalmetadata zijn alleen toegankelijk door de daadwerkelijke YouTube-pagina’s te scrapen.
Voor de meeste zakelijke gebruikers die concurrentieonderzoek doen, creators zoeken of contentstrategie opstellen, is een scraper-tool praktischer dan de API.
Hoe we de 6 beste YouTube-scrapers hebben gekozen
Elke tool op deze lijst is beoordeeld op dezelfde criteria—met extra gewicht voor wat er echt toe doet wanneer YouTube actief probeert je te blokkeren:
| Criteria | Waarom het belangrijk is |
|---|---|
| Betrouwbaarheid tegen blokkades | Het grootste pijnpunt voor gebruikers—rate limiting en IP-blokkades op schaal |
| Kosten per 1.000 resultaten | Gestandaardiseerde prijs maakt eerlijke vergelijking mogelijk |
| Ondersteunde datatypes | Metadata, reacties, transcripties, Shorts, thumbnails—sterk verschillend per tool |
| Schaalbaarheid | Kan het 100+ kanalen of 10K+ video’s aan zonder vast te lopen? |
| Gemak van setup | Eerste gebruikers hebben praktische, no-code-vriendelijke opties nodig |
| Exportformaten | CSV, JSON, Google Sheets, Airtable—verschillende workflows vragen om verschillende outputs |
| Onderhoudsbelasting | Wijzigingen bij YouTube breken tools; wie fixt het? |
Alle tools zijn beoordeeld op de huidige blokkadepatronen van YouTube die gebruikers in 2026 tegenkomen.
1. Thunderbit
is een AI-aangedreven Chrome-extensie die YouTube-pagina’s in ongeveer twee klikken omzet in gestructureerde data. In plaats van te draaien vanaf een cloudserver (die YouTube makkelijk markeert), werkt Thunderbit binnen je eigen browsersessie—voor YouTube lijk je dus gewoon normaal te browsen.
De kernworkflow voor YouTube: installeer de , ga naar een YouTube-kanaal, zoekresultatenpagina of videopagina en klik op „AI Suggest Fields”. De AI leest de pagina en stelt kolommen voor—videotitel, URL, weergaven, uploaddatum, beschrijving, thumbnail-URL, reactietekst, auteur, likes en meer. Je controleert, klikt op „Scrape” en exporteert direct naar Google Sheets, Excel, Airtable, Notion, CSV of JSON. Geen code, geen selectors, geen API-sleutels.
Belangrijkste functies voor YouTube-scraping:
- AI-veldherkenning: Thunderbit’s AI leest welke YouTube-pagina je ook open hebt en stelt automatisch relevante kolommen voor. Je hoeft geen CSS-selectors of XPath handmatig te mappen.
- Subpaginacrapping: Scrape een videolijst van een kanaal en klik vervolgens door naar elke videopagina om reacties, beschrijvingen, tags en transcripties te verrijken (als die zichtbaar zijn).
- Geplande scraping: Stel terugkerende taken in om kanalen wekelijks te volgen zonder handmatige tussenkomst.
- Browsermodus: Draait binnen je geauthenticeerde browsersessie en vermindert zo de „cloud datacenter IP”-vingerafdruk die de meeste YouTube-blokkades triggert.
- Gratis export: Data gaat naar Google Sheets, Excel, Airtable of Notion zonder export-paywall.
Aanpak tegen blokkades: Scraping binnen de browsersessie met de eigen geauthenticeerde sessie van de gebruiker. YouTube ziet een echte browser, echte cookies en echte sessiegeschiedenis. Voor jobs met hoog volume verkleinen kleinere geplande batches het risico verder.
Prijzen: Gratis laag (6 pagina’s), proefboost (10 pagina’s). Betaalde abonnementen zijn op credits gebaseerd. Bekijk de voor de actuele cijfers.
Het meest geschikt voor: Marketeers, salesteams, contentstrategen en operations-gebruikers die snel kanaal-/zoek-/reactieonderzoek willen doen zonder technische setup.
Hoe je YouTube scrape met Thunderbit (stap voor stap)
- Installeer de .
- Navigeer naar een YouTube-kanaalpagina, zoekresultaten, afspeellijst of videopagina.
- Klik op „AI Suggest Fields” — de AI leest de pagina en stelt kolommen voor (titel, URL, weergaven, datum, beschrijving, thumbnail, enz.).
- Controleer en pas aan indien nodig de voorgestelde velden aan.
- Klik op „Scrape” — de data wordt uitgelezen naar een gestructureerde tabel.
- Exporteer naar Google Sheets, Excel, Airtable, Notion, CSV of JSON.
Voor diepere extractie (bijvoorbeeld reacties van elke video in een kanaal ophalen), gebruik subpaginacrapping: scrape eerst de videolijst en laat Thunderbit daarna elke videopagina bezoeken om reactiedata, beschrijvingen of beschikbaarheid van transcripties uit te lezen.
Het hele proces duurt minder dan twee minuten voor een typische kanaalresearchtaak. Geen API-sleutels, geen proxy-instelling, geen code.
2. Apify
Apify is een cloudgebaseerd scrapingplatform met vooraf gebouwde YouTube „Actors”—gespecialiseerde scrapers voor video’s, reacties, kanalen, Shorts en transcripties. Het is ontworpen voor ontwikkelaars die geautomatiseerde datapijplijnen willen bouwen in plaats van eenmalig onderzoek te doen.
Het YouTube-ecosysteem van Apify bevat aparte Actors voor verschillende taken. Een goed onderhouden Actor met de titel „YouTube Scraper — Videos, Comments & Transcripts” accepteert kanalen, afspeellijsten, zoekopdrachten en directe video-URL’s. Hij ondersteunt filtering op Shorts, het scrapen van reacties en transcripties met tijdstempels.
Belangrijkste functies:
- Aparte Actors voor video’s, reacties, kanalen, Shorts en transcripties
- Accepteert zoektermen, kanaal-URL’s en afspeellijst-ID’s als invoer
- Cloudplanning en webhook-integraties
- Export naar JSON, CSV, Excel of push naar databases via API
- Rate control en proxyrotatie op Actor-niveau
Aanpak tegen blokkades: Tempo per Actor, Apify’s proxy-infrastructuur en waar van toepassing toegang via YouTube’s interne API (Innertube). Elke Actor implementeert zijn eigen retry- en rate-limitlogica.
Prijzen: De genoemde YouTube Scraper-Actor vermeldt ongeveer $15 per 1.000 video’s, $8 per 1.000 reacties en $5 per transcriptie. Platformplannen beginnen bij $49/maand.
Nadelen: Kosten lopen snel op bij grote jobs. De interface is gericht op ontwikkelaars—niet-technische gebruikers vinden het mogelijk complex. Output-schema’s verschillen per Actor, dus opschoning van data is vaak nodig. De kwaliteit van Actors verschilt op de marktplaats.
Het meest geschikt voor: Ontwikkelaars die geautomatiseerde datapijplijnen bouwen, teams die geplande extractie naar API’s of databases nodig hebben, en marketing-ops-teams die terugkerende workflows voor reactiesentiment draaien.
3. Bright Data
Bright Data is een enterprise datainfrastructuurplatform met het grootste residential proxy-netwerk in de sector en speciale YouTube-scrapers. Als je YouTube op enorme schaal en over meerdere regio’s wilt scrapen, is dit het zware geschut.
Bright Data biedt meerdere YouTube-scrapers (kanaalprofielen, video’s, reacties) plus kant-en-klare YouTube-datasets om te kopen. Hun managed scraping-dienst betekent dat zij de scraper voor je bouwen en onderhouden.
Belangrijkste functies:
- 150M+ residential IP’s in 195 landen
- YouTube-specifieke scrapers voor kanalen, video’s en reacties
- Volledige browser-rendering en CAPTCHA-oplossing
- Geo-gerichte scraping (YouTube-resultaten per land vergelijken)
- Optie voor managed service (zij doen het onderhoud)
- Batchverwerking tot 5K URL’s per verzoek
Aanpak tegen blokkades: Enorme pool residential proxies, automatische IP-rotatie, browser-fingerprint-emulatie en geïntegreerde CAPTCHA-oplossing. Dit is de sterkste anti-blocking-infrastructuur op de lijst.
Prijzen: Gratis proefperiode (1K verzoeken voor één week), pay-as-you-go vanaf $3,50 per 1K records, Scale-plan vanaf $499/maand met 384.000 records inbegrepen en $2,30 per 1K extra.
Nadelen: Overkill voor kleine projecten. Complexe prijsstelling (bandbreedte + verzoeken + IP’s kan voor een „bill shock” zorgen als limieten niet zijn ingesteld). Het platform vereist meer setup dan een Chrome-extensie.
Het meest geschikt voor: Grote bedrijven, bureaus die honderden kanalen monitoren en teams die geo-specifieke YouTube-data op enterprise-schaal nodig hebben.
4. Octoparse
Octoparse is een desktop- en cloud-scrapingtool met een visuele point-and-click-interface. Je bouwt YouTube-extractieworkflows door op elementen op de pagina te klikken—geen code nodig, maar wel met meer aanpassingsmogelijkheden dan een simpele extensie.
Octoparse heeft vooraf gebouwde YouTube-sjablonen, waaronder een YouTube Comments & Replies Scraper die in april 2026 is bijgewerkt. Hij extraheert gebruikersnamen, reactietekst, likes, publicatietijd en antwoordthreads uit video-URL’s.
Belangrijkste functies:
- No-code visuele workflowbouwer—klik elementen aan om scrapinglogica te definiëren
- Vooraf gebouwde YouTube-sjablonen voor reacties, zoekresultaten en videometadata
- Cloudplanning met automatische proxyrotatie
- Export naar Excel, CSV, JSON en databaseverbindingen
- Ingebouwde IP-rotatie en anti-detectie op cloudplannen
Aanpak tegen blokkades: Clouduitvoering met ingebouwde IP-rotatie en anti-detectiemaatregelen. Sjablonen handelen oneindig scrollen en dynamisch laden af voor veelvoorkomende YouTube-pagina’s.
Prijzen: YouTube-reactiesjabloon vermeld voor $0,20 per 1.000 regels. Platformplannen beginnen rond $75/maand (Standard, jaarlijks gefactureerd) met cloudservers, planning en proxy-opties.
Nadelen: Complexe YouTube-pagina’s (oneindig scrollen, lazy-loaded reacties, Shorts-tabs) kunnen afstelling van wachttijden en scrollgedrag vereisen. Transcript-/ondertitel-extractie is beperkt vergeleken met yt-dlp of speciale transcript-actors. Leercurve voor geavanceerde workflows.
Het meest geschikt voor: Marketinganalisten en business researchers die visuele workflowtools prefereren, maar meer maatwerk nodig hebben dan een Chrome-extensie biedt.
5. YT-DLP
YT-DLP (beschikbaar op GitHub) is een open-source command-line tool die videometadata, ondertitels, transcripties en meer uit YouTube (en meer dan 1.000 andere sites) haalt. Het is het Zwitserse zakmes voor technische gebruikers die maximale controle en nul abonnementskosten willen.
Voor scraping-achtig werk kan yt-dlp metadata extraheren zonder videobestanden te downloaden, met flags zoals --skip-download, --write-info-json, --dump-json en --flat-playlist. Het maakt onderscheid tussen automatisch gegenereerde en door mensen geschreven ondertitels—a detail dat de meeste andere tools missen.
Belangrijkste functies:
- Extraheert videometadata (titel, weergaven, likes, uploaddatum, beschrijving, tags) zonder de video te downloaden
- Downloadt complete afspeellijsten en kanalen in bulk
- Toegang tot ondertitels/transcripties (zowel automatisch gegenereerd ALS handgeschreven, apart)
- Batchverwerking met aangepaste outputsjablonen
- Cookie-/authenticatieondersteuning voor sessiegebaseerde toegang
- Volledig gratis, actieve open-source community
Aanpak tegen blokkades: Gebruikerscookies voor authenticatie (--cookies-from-browser), instelbare throttle-instellingen en door de community onderhouden extractor-updates die zich aanpassen aan wijzigingen bij YouTube.
Prijzen: Gratis.
Nadelen: Vereist vaardigheid met de command line. Geen visuele interface. Breekt wanneer YouTube wijzigt (de community fixt het snel, maar je moet nog steeds updaten en troubleshooten). Geen ingebouwde planning of export naar spreadsheets—je bouwt je eigen pijplijn.
Het meest geschikt voor: Ontwikkelaars, data scientists en technische teams die maximale controle nodig hebben over metadata- en transcriptie-extractie en geen moeite hebben met terminalcommando’s.
6. Phantombuster
Phantombuster is een cloud-automatiseringsplatform met YouTube-specifieke „Phantoms” die meer gericht zijn op growth marketing en leadgeneratie dan op pure data-opslag. Dit is de keuze als je doel is om creatorcontacten te vinden en outreach-lijsten op te bouwen.
Phantombuster’s YouTube Channel Video Extractor haalt kanaalinformatie, videolijsten en publieke e-mails uit kanaalbeschrijvingen. De officiële documentatie over rate limits zegt dat de YouTube Channel Video Extractor tot 100 video’s per launch ondersteunt en waarschuwt dat ongebruikelijke activiteit nog steeds YouTube-beperkingen kan uitlokken.
Belangrijkste functies:
- YouTube-kanaalscraper (aantal abonnees, videolijst, kanaalinformatie, publieke e-mails)
- Video- en reactiextractie voor concurrentieanalyse
- Integratie met CRM- en outreach-tools
- Planning en workflow-automatisering
- 14-daagse gratis proefperiode, Start-plan vanaf $56/maand (jaarlijks gefactureerd, 20u/maand uitvoering)
Aanpak tegen blokkades: Ingebouwde vertragingen tussen acties, phantom-browser-sessies, clouduitvoering met gecontroleerd tempo. Ontworpen voor workflows met veilig tempo, niet voor snelle bulkextractie.
Prijzen: Start-plan vanaf $56/maand (jaarlijks), Grow vanaf $128/maand, Scale vanaf $352/maand. Kosten per 1.000 resultaten variëren op basis van uitvoeringstijd in plaats van prijs per record.
Nadelen: Trager dan tools die op pijplijnen zijn gericht. Prijsstelling is gebaseerd op uitvoeringsuren en credits, niet op een nette kost per rij. Beperkte ondersteuning voor transcripties/ondertitels. De limiet van 100 video’s per launch betekent dat grote kanalen meerdere runs nodig hebben.
Het meest geschikt voor: Growth marketeers die influenceronderzoek doen, salesteams die contactinformatie van creators ophalen en bureaus die de YouTube-activiteiten van concurrenten monitoren.
Elk datatype dat je uit YouTube kunt extraheren (matrix per tool)
Verschillende tools ondersteunen verschillende YouTube-datatypes. Voordat je je vastlegt op een tool, moet je precies weten wat je krijgt. Hier is het overzicht:
| Datatype | Thunderbit | Apify | Bright Data | Octoparse | YT-DLP | Phantombuster |
|---|---|---|---|---|---|---|
| Videometadata (titel, weergaven, likes, duur, datum) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Reacties (bulk met auteur, tijdstempel, likes) | ✅ | ✅ | ✅ | ✅ | ❌ | ⚠️ |
| Reactie-antwoorden | ⚠️ | ✅ | ✅ | ✅ | ❌ | ⚠️ |
| Transcripties/ondertitels | ⚠️ (afhankelijk van de pagina) | ✅ | ⚠️ | ⚠️ | ✅ | ❌ |
| Automatische vs. handmatige ondertitels (onderscheiden) | ⚠️ | ✅ | ⚠️ | ❌ | ✅ | ❌ |
| Shorts-metrics | ✅ | ✅ | ✅ | ⚠️ | ✅ | ⚠️ |
| Kanaalanalyses (abonnees, totaal aantal weergaven, datum van lidmaatschap) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Thumbnails/afbeeldingen | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Publieke e-mails uit kanaalbeschrijvingen | ✅ (indien zichtbaar) | Afhankelijk van Actor | ⚠️ | ⚠️ | ❌ | ✅ |
Meest waardevolle data per zakelijke use case:
- Reacties → sentimentanalyse, bezwaarinventarisatie, klachten over concurrenten, publieksonderzoek
- Transcripties → LLM/RAG-pijplijnen, analyse van boodschap van concurrenten, content hergebruiken
- Kanaalmetadata → creator sourcing, concurrentietracking, sales-/influencerprospecting
- Videometadata → contentstrategie, analyse van titel/thumbnail, uploadfrequentie, SEO-ideeën
- Publieke e-mails → outreach naar creators (gebruik verantwoord en volgens e-mail-/privacyregels)
Beste YouTube-scrapers vergeleken: side-by-side tabel
| Tool | Type | Aanpak tegen blokkades | Kosten/1K resultaten | Het meest geschikt voor | Setup | Exportformaten | Schaal |
|---|---|---|---|---|---|---|---|
| Thunderbit | AI Chrome-extensie | Browsersessie, AI-veldherkenning | Gratis laag (6 pagina’s); betaald op credits | No-code kanaal-/zoekonderzoek | Zeer eenvoudig | Sheets, Excel, Airtable, Notion, CSV/JSON | Klein-middelgroot, gepland |
| Apify | Cloud actor-platform | Tempo per Actor, proxies, Innertube | ~$5–$15/1K (verschilt per actor) | Ontwikkelaarspijplijnen | Gemiddeld | JSON, CSV, Excel, API, webhooks | Middelgroot-hoog |
| Bright Data | Enterprise scraper/proxy | 150M+ residential IP’s, CAPTCHA-oplossing | $3,50/1K records (PAYG) | Enterprise-extractie | Gemiddeld-moeilijk | JSON, NDJSON, CSV, webhooks | Zeer hoog |
| Octoparse | Visuele workflowbouwer | Cloud IP-rotatie, anti-detectie | ~$0,20/1K regels (sjabloon) + plan | Visuele maatwerkworkflows | Gemiddeld | Excel, CSV, JSON, DB | Middelgroot |
| YT-DLP | Open-source CLI | Cookies, throttle-instellingen, community-updates | Gratis | Technische metadata-/transcriptie-extractie | Moeilijk (niet-technisch) | JSON, ondertitels, aangepaste output | Hangt af van setup |
| Phantombuster | Cloud growth automation | Ingebouwde vertragingen, sessies op tempo | Plan-gebaseerd ($56+/maand); ~100 video’s/launch | Creator lead gen, growth workflows | Eenvoudig-gemiddeld | CSV/JSON/API/CRM | Middelgroot, gecontroleerd tempo |
Categorie-winnaars:
- Beste voor niet-technische gebruikers: Thunderbit
- Beste voor ontwikkelaarspijplijnen: Apify
- Beste voor enterprise-schaal: Bright Data
- Beste visuele bouwer: Octoparse
- Beste gratis technische optie: YT-DLP
- Beste workflow voor growth marketing: Phantombuster
Gratis versus betaalde YouTube-scrapers: wanneer gratis tools genoeg zijn
Gratis tools werken wanneer je taak smal en infrequent is, en je je prettig voelt bij technisch onderhoud. Dit is wanneer je gratis kunt blijven en wanneer je beter kunt investeren:
| Scenario | Beste gratis optie | Wanneer upgraden naar betaald | Waarom |
|---|---|---|---|
| Eenmalige transcriptdownload | YT-DLP | Je hebt 500+ video’s nodig of niet-technische teamgenoten | CLI-setup en cookiebeheer geven extra frictie |
| Snelle check van een concurrentiekanaal | Thunderbit gratis laag (6 pagina’s) | Regelmatige monitoring of meer dan 10 pagina’s | Geplande scraping bespaart uren per week |
| Opbouwen van een LLM-trainingsdataset | YT-DLP + eigen scripts | Je wilt automatische/handmatige onderscheiding van ondertitels op schaal | Apify’s speciale Actors handelen randgevallen af |
| Wekelijkse monitoring van 10+ kanalen | — | Meteen | Planning en hergebruik van schema’s besparen echte tijd |
| Marketingteam dat creator leads verzamelt | Thunderbit gratis proefperiode | 10+ kanalen per week | Schaal op basis van credits is goedkoper dan de tijd die je kwijt bent aan scriptwerk |
De eerlijke conclusie: gratis tools zoals YT-DLP zijn krachtig, maar vragen doorlopend technisch onderhoud. Layoutwijzigingen bij YouTube, cookie-verloop, throttle-aanpassingen en outputformattering hebben allemaal handmatige aandacht nodig. Een script dat elke twee weken stukgaat, kan meer kosten aan engineer-tijd dan een betaald scraperabonnement.
AI-tools zoals Thunderbit lezen pagina’s elke keer vers in en passen zich automatisch aan lay-outwijzigingen aan. Die verborgen onderhoudskosten zijn precies waarom betaalde tools voor de meeste zakelijke teams de moeite waard zijn.
Hoe gescrapete YouTube-data er echt uitziet (echte outputvoorbeelden)
Een van de grootste gaten in scraperreviews is dat bijna niemand laat zien wat je daadwerkelijk krijgt. Hier zijn realistische voorbeelden van gescrapete YouTube-output:
Voorbeeld 1: Kanaalmetadata
| channel_name | handle | subscribers | total_views | video_count | join_date | description_snippet | public_email |
|---|---|---|---|---|---|---|---|
| Example SaaS Tutorials | @examplesaas | 184K | 22.4M | 412 | 2018-06-14 | Wekelijkse producttutorials en workflowgidsen | partnerships@example.com |
| Data Ops Weekly | @dataopsweekly | 92K | 8.7M | 215 | 2020-01-03 | Demo’s voor analytics, automatisering en AI-workflows | Niet zichtbaar |
Voorbeeld 2: Reactie-export
| video_url | timestamp | author | comment_text | likes | reply_count |
|---|---|---|---|---|---|
| youtube.com/watch?v=abc123 | 2026-04-18 | @workflowfan | Dit beantwoordde de vraag over de prijs beter dan de vendorpagina. | 28 | 3 |
| youtube.com/watch?v=abc123 | 2026-04-18 | @opslead | Ik zou graag een vervolg zien waarin dit met Apify wordt vergeleken. | 11 | 0 |
| youtube.com/watch?v=abc123 | 2026-04-19 | @examplesaas | Goed punt, dat testen we nu als volgende. | 4 | 0 |
Voorbeeld 3: Transcriptie-extractie
100:00:00.000 - 00:00:04.200 Vandaag vergelijken we zes YouTube-scraping-workflows voor marketeers.
200:00:04.200 - 00:00:09.800 Het belangrijkste verschil is of je metadata, reacties of transcripties nodig hebt.
300:00:09.800 - 00:00:15.300 Voor niet-technische gebruikers is een browsergebaseerde scraper meestal eenvoudiger te onderhouden.Veelvoorkomende opschoonproblemen om te verwachten:
- Aantallen weergaven kunnen gelokaliseerde suffixen bevatten (K, M) of niet-Engelse labels
- Uploaddata zijn soms relatief („3 jaar geleden”) in plaats van ISO-datums
- Reacties kunnen standaard gesorteerd zijn op Top in plaats van Nieuw
- Verborgen antwoorden en lazy-loaded reacties vereisen scrollen of paginering
- Publieke e-mailvelden kunnen verborgen zijn achter interactie- of accountbeperkingen
- Transcripties kunnen ontbreken, automatisch gegenereerd zijn of in een onverwachte taal staan
Voor Thunderbit is de workflow simpel: AI Suggest Fields → Scrape → Export to Google Sheets. De AI verzorgt de veldherkenning, dus je hoeft niet handmatig te definiëren hoe „weergaven” of „uploaddatum” eruitziet op de pagina.
Is het legaal om YouTube te scrapen in 2026?
De korte versie: het scrapen van publiek beschikbare YouTube-data is over het algemeen minder risicovol dan toegang krijgen tot privédata, maar het is zeker geen juridisch vrij spel.
YouTube’s verbieden expliciet geautomatiseerde toegang, behalve door openbare zoekmachines die robots.txt volgen of met voorafgaande schriftelijke toestemming van YouTube. Handhaving tegen legitiem zakelijk onderzoek is echter zeldzaam—YouTube richt zich vooral op grootschalig misbruik, contentpiraterij en privacy-schendingen.
Amerikaanse jurisprudentie biedt enige duidelijkheid. In de van het Ninth Circuit werd vastgesteld dat er serieuze vragen bestaan over de vraag of het scrapen van publiek beschikbare data de CFAA schendt. De dat het scrapen van publieke websites geen misdrijf is. Maar platformvoorwaarden, auteursrecht, privacy en anti-spamwetten blijven van kracht.
Praktische richtlijnen:
- Verzamel alleen openbare data die je account mag bekijken
- Scrape geen persoonsgegevens op onnodige schaal
- Omzeil geen toegangscontroles of paywalls
- Respecteer auteursrecht—publiceer transcripties of videoinhoud niet integraal opnieuw
- Beperk de snelheid van jobs en overbelast YouTube-servers niet
- Voldoe bij outreach aan CAN-SPAM, GDPR en lokale regels
- Raadpleeg een juridisch professional voor risicovolle use cases
De tools op deze lijst bevatten allemaal rate limiting en een respectvol tempo by design. Dat is niet alleen ethisch verstandig—het zorgt er ook voor dat je scraping op de lange termijn blijft werken.
Welke YouTube-scraper moet je kiezen?
Hier is de snelle beslisgids:
- Thunderbit → Het beste voor niet-technische gebruikers die snel, moeilijk te blokkeren YouTube-scraping naar spreadsheets willen. Begin hier als je marketeer, salesmedewerker of contentstrateeg bent.
- Apify → Het beste voor ontwikkelaars die geautomatiseerde pijplijnen bouwen met geplande taken, webhooks en API-levering.
- Bright Data → Het beste voor extractie op enterprise-schaal over meerdere regio’s met beheerde anti-blocking-infrastructuur.
- Octoparse → Het beste voor analisten die visuele workflowbouw willen met meer maatwerk dan een Chrome-extensie.
- YT-DLP → Beste gratis optie voor technische gebruikers die maximale controle over metadata en transcripties nodig hebben.
- Phantombuster → Het beste voor growth marketeers die creator sourcing en YouTube-gebaseerde leadgeneratie doen.
De sleutel om niet geblokkeerd te worden is niet één geheime truc—het gaat om het kiezen van een tool met slimme anti-detectie ingebouwd. Scraping binnen een echte browsersessie, proxyrotatie, gecontroleerd tempo en kleine geplande batches verlagen allemaal het risico. Met brute force duizenden verzoeken vanaf één cloud-IP versturen is wat je blokkeert.
Als je wilt zien hoe moderne YouTube-scraping eruitziet zonder code, probeer dan de gratis laag van . Twee klikken naar gestructureerde data. En als je behoeften technischer zijn of op enterprise-schaal liggen, dan hebben de andere tools op deze lijst je ook gedekt. Voor meer over webscraping-aanpakken kun je onze gidsen bekijken over en . Je kunt ook tutorials bekijken op het .
Veelgestelde vragen
Welke data kun je uit een YouTube-kanaal scrapen?
Publieke data die je kunt extraheren omvat videotitels, URL’s, thumbnails, weergaven, likes (waar zichtbaar), uploaddata, beschrijvingen, duur, reacties, antwoorden, namen/handles van reageerders, likes op reacties, transcripties/ondertitels (zowel automatisch gegenereerd als door mensen geschreven), Shorts-indicatoren, kanaalnaam, handle, aantal abonnees, aantal video’s, totaal aantal weergaven, beschrijving, links en publieke e-mails als die zichtbaar zijn op de kanaalpagina.
Hoeveel YouTube-video’s kan ik per dag scrapen zonder geblokkeerd te worden?
Er is geen universeel aantal. Browsergebaseerde tools zoals Thunderbit lopen minder risico bij gebruikersachtige workflows omdat ze binnen een echte sessie werken. Phantombuster’s YouTube Channel Video Extractor ondersteunt tot 100 video’s per launch. Cloudplatforms met proxyrotatie kunnen met de juiste pacing duizenden aan. Ruwe scripts vanaf cloudservers zonder rate limiting worden snel geblokkeerd. De veiligste aanpak is kleinere, geplande batches in plaats van één enorme run.
Kan ik YouTube-reacties scrapen voor sentimentanalyse?
Ja. Thunderbit, Apify, Bright Data en Octoparse ondersteunen allemaal bulk-extractie van reacties met auteur, tijdstempel, likes en aantallen antwoorden. Exporteer naar Google Sheets of CSV voor analyse. Apify’s YouTube-actor ondersteunt hiervoor expliciet instelbare maximale aantallen reacties per video.
Is er een gratis YouTube-scraper die in 2026 echt werkt?
YT-DLP is de beste gratis optie voor technische gebruikers—vooral voor metadata en transcripties. Thunderbit biedt een gratis laag voor niet-technische gebruikers (6 pagina’s, met een proefboost naar 10) die direct naar Google Sheets exporteert. Beide werken, maar YT-DLP vereist command-linevaardigheden terwijl Thunderbit alleen een browser nodig heeft.
Hoe voorkomen YouTube-scrapers dat ze worden geblokkeerd?
Verschillende tools gebruiken verschillende aanpakken: scraping binnen een browsersessie (Thunderbit) gebruikt de geauthenticeerde browsercontext van de gebruiker; residential proxyrotatie (Bright Data, Apify) verdeelt verzoeken over miljoenen IP’s; cookie-authenticatie (YT-DLP) behoudt sessievertrouwen; ingebouwde vertragingen en pacing (Phantombuster) vermijden gedragsdetectie. De meest betrouwbare aanpak combineert echte browsercontext met conservatief tempo en kleinere geplande jobs.
Meer weten