Het web groeit tegenwoordig sneller dan je met je ogen kunt knipperen—en geloof me, ik ben een snelle koffiedrinker. In 2026 is webdata-extractie niet meer alleen voor de techneuten; het is de stille kracht achter sales, prijsvergelijkingen in e-commerce, marktonderzoek en zelfs vastgoedanalyses. , dus de juiste webscraping-bibliotheek kiezen kan het verschil maken tussen urenlang handmatig werk of een kant-en-klare spreadsheet vol inzichten—nog voordat je concurrent aan de lunch zit.
Het mooie is: webscraping-bibliotheken in 2026 zijn er in alle soorten en maten, van codevrije AI Chrome-extensies tot krachtige frameworks voor developers. Of je nu in sales werkt en leads in Excel wilt, als operations manager 500 producten volgt, of als Python-fanaat je eigen crawler bouwt—er is altijd een oplossing die bij je past. Na jaren in SaaS en automatisering (en meer nachten doorhalen dan me lief is) heb ik de beste opties voor je uitgezocht. Hier vind je de 10 webscraping-bibliotheken die je dit jaar niet mag missen, plus handige tips om de juiste keuze te maken.
Wat Maakt een Webscraping-bibliotheek Sterk in 2026?
Voordat we de lijst induiken, eerst even: waar moet je nu echt op letten bij het kiezen van een webscraping-bibliotheek? Uit mijn ervaring hebben de beste tools in 2026 deze eigenschappen:
- Gebruiksgemak: Kan iemand zonder programmeerkennis snel resultaat halen? Of heb je een Python-diploma nodig?
- Omgaan met Dynamische Content: Kan de tool moderne, JavaScript-rijke sites aan? Of loopt hij vast bij alles wat meer is dan simpele HTML?
- Taal- & Platformondersteuning: Werkt het in jouw favoriete taal—Python, JavaScript, Java—of zelfs direct in je browser?
- Schaalbaarheid: Kan het honderden of duizenden pagina’s verwerken zonder problemen?
- Integratie & Export: Kan je makkelijk exporteren naar Excel, Google Sheets, Notion of je datastroom?
- AI & Automatisering: In 2026 zijn AI-gedreven tools die werken met natuurlijke taal een enorme plus—vooral voor zakelijke gebruikers die niet willen coderen.
De realiteit: zakelijke teams willen snelheid, nauwkeurigheid en zo min mogelijk gedoe. Hoe minder tijd je kwijt bent aan het fixen van kapotte scrapers of code, hoe meer tijd je hebt om met de data aan de slag te gaan. Dankzij AI en browserautomatisering kunnen nu zelfs niet-technische gebruikers data verzamelen waar vroeger een ontwikkelaar voor nodig was ().
Tijd voor het echte werk.
Top 10 Krachtige Webscraping-bibliotheken voor 2026
- voor no-code, AI-gestuurde webscraping direct in je browser
- voor simpele HTML-parsing en datacleaning in Python
- voor grootschalig, razendsnel crawlen en dataverwerking
- voor browserautomatisering en scraping van dynamische, JavaScript-rijke sites
- voor supersnelle XML/HTML-parsing in Python
- voor jQuery-achtige HTML-selectie in Python
- voor alles-in-één HTTP, HTML-parsing en JS-rendering in Python
- voor het automatiseren van formulieren en eenvoudige browseracties in Python
- voor headless Chrome-automatisering in Node.js
- voor krachtige HTML-parsing in Java
1. Thunderbit
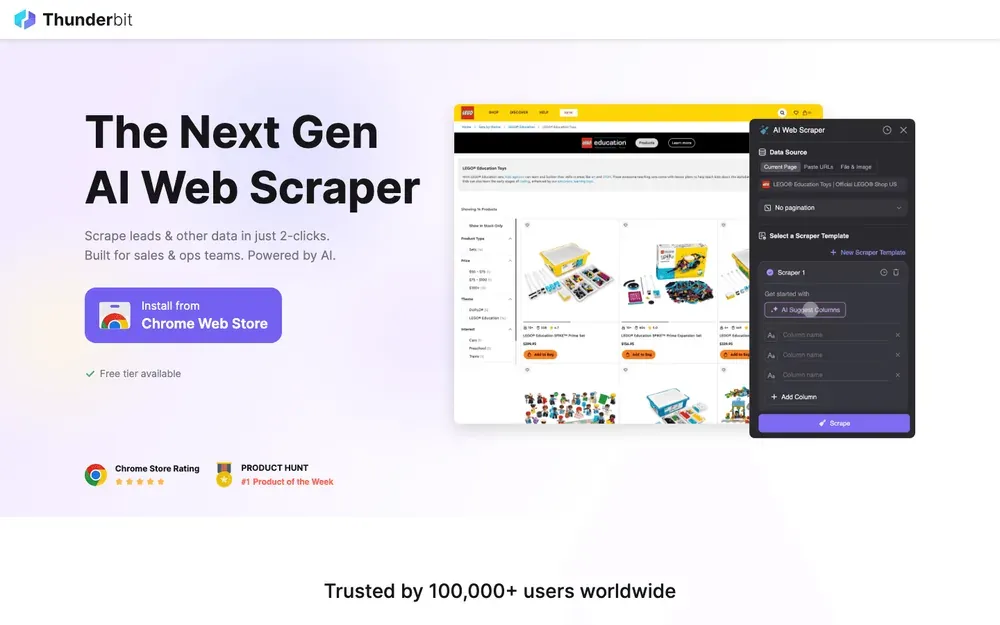
is mijn absolute favoriet voor iedereen die webdata wil verzamelen zonder te programmeren. Deze laat je gewoon in je eigen woorden beschrijven wat je zoekt (“Haal alle productnamen, prijzen en afbeeldingen van deze pagina”), en de AI regelt de rest. Geen sjablonen, geen gedoe—klik op “AI Suggest Fields”, pas eventueel aan, en je kunt direct beginnen.
Waarom Thunderbit in 2026 zo sterk is:
- No-code, natuurlijke taal: Iedereen kan ermee werken—sales, operations, marketing, vastgoed. Geen Python nodig.
- AI Suggest Fields: De AI leest de pagina en stelt automatisch de beste kolommen voor.
- Subpagina-scraping: Meer details nodig? Thunderbit bezoekt automatisch subpagina’s (zoals product- of profielpagina’s) en verrijkt je tabel ().
- Directe sjablonen voor populaire sites: Amazon, Zillow, Shopify en meer—scrapen met één klik.
- Export naar Excel, Google Sheets, Notion, Airtable: Je data komt direct waar je team het nodig heeft.
- Ondersteunt 34 talen: Ideaal voor internationale teams.
- Cloud- of browserscraping: Kies wat bij je workflow past—cloud is supersnel voor openbare sites, browsermodus werkt met logins.
Thunderbit wordt wereldwijd door meer dan 30.000 gebruikers vertrouwd. Met het gratis pakket kun je tot 6 pagina’s scrapen (of 10 met een proefboost). Wil je ervaren hoe moderne webscraping werkt? Begin hier.
2. Beautiful Soup
is een klassieker onder de Python-bibliotheken, geliefd bij data-analisten vanwege de eenvoud en kracht bij het parsen van rommelige HTML. Als je ooit data moest halen uit een pagina met kapotte tags of rare opmaak, is Beautiful Soup je redder.
Waarom Beautiful Soup zo prettig werkt:
- Kan overweg met onregelmatige HTML: Ideaal voor het opschonen en extraheren van data uit ‘lelijke’ webpagina’s ().
- Makkelijk te leren: Ook voor Python-beginners snel op te pakken.
- Flexibel: Werkt goed samen met HTTP-clients zoals Requests, en kan gecombineerd worden met lxml voor extra snelheid.
- Typische toepassingen: Snel data extraheren, webdata opschonen, kleine scripts.
Werk je met statische pagina’s of rommelige HTML? Dan is Beautiful Soup een uitstekende keuze.
3. Scrapy
is de krachtpatser onder de Python-webscrapers. Het is een compleet framework voor het bouwen van schaalbare crawlers en dataverwerkingspijplijnen. Moet je duizenden pagina’s scrapen, links volgen en data op grote schaal verwerken? Dan is Scrapy gemaakt voor jou.
Waarom Scrapy een topkeuze is:
- Sterk modulair: Bouw complexe spiders, pipelines en middlewares ().
- Geschikt voor grote projecten: Ideaal voor marktonderzoek, concurrentieanalyse of elke klus waarbij je veel sites moet crawlen.
- Asynchroon en snel: Ontworpen voor snelheid en efficiëntie.
- Grote community: Veel plugins, tutorials en ondersteuning.
Scrapy heeft een leercurve, maar voor grote projecten is het een echte krachtpatser.
4. Selenium
is dé tool voor browserautomatisering. Het wordt gebruikt voor alles van het testen van webapps tot het scrapen van sites die logins, klikken of pop-ups vereisen. Moet je interactie hebben met JavaScript-rijke of zeer dynamische sites? Selenium kan een echte gebruiker nabootsen ().
Sterke punten van Selenium:
- Automatiseert echte browsers: Chrome, Firefox, Safari, Edge—alles is mogelijk.
- Kan omgaan met logins, pop-ups en gebruikersacties: Ideaal voor scraping na inloggen of bij meerstapsprocessen.
- Meerdere programmeertalen: Python, Java, C# en meer.
- Beste keuze voor: Sites die simpele scrapers blokkeren, of als je echt gebruikersgedrag moet nabootsen.
Het is wat zwaarder dan HTTP-bibliotheken, maar soms heb je gewoon een echte browser nodig.
5. lxml
is een razendsnelle XML- en HTML-parser voor Python. Is snelheid je hoogste prioriteit (denk: duizenden grote documenten parsen), dan is lxml bijna niet te verslaan ().
Waarom lxml favoriet is:
- Supersnel: Sneller dan de meeste andere Python-parsers, vooral bij grote bestanden.
- Robuust: Kan zowel XML als HTML aan, en werkt goed samen met andere tools.
- Ideaal voor: Grote datasets verwerken, combineren met Beautiful Soup of Scrapy voor extra kracht.
Scrapen op grote schaal of enorme bestanden verwerken? Dan is lxml onmisbaar.
6. PyQuery
brengt de kracht van jQuery-selectors naar Python. Ben je fan van het gemak van $('.class') in jQuery? Met PyQuery kun je datzelfde doen in je scraping-scripts ().
PyQuery in het kort:
- jQuery-achtige selectors: Intuïtief voor iedereen met front-end ervaring.
- Korte, leesbare code: Maakt complexe selecties eenvoudig.
- Werkt samen met lxml: Snel en efficiënt onder de motorkap.
- Ideaal voor: Projecten waar je snel, jQuery-achtig HTML wilt manipuleren in Python.
Perfect voor webontwikkelaars die overstappen naar data-extractie.
7. Requests-HTML
is een Python-bibliotheek die het gemak van Requests (voor HTTP) combineert met ingebouwde HTML-parsing en zelfs JavaScript-rendering.
Wat Requests-HTML uniek maakt:
- Alles-in-één: Haal pagina’s op, parse HTML en render JavaScript in één pakket.
- Gebruiksvriendelijk: Ideaal voor kleine tot middelgrote scraping-projecten.
- Perfect voor: Snel scripts maken, sites met wat dynamische content, gebruikers die eenvoud zoeken.
Net begonnen of een flexibele tool nodig voor kleinere klussen? Requests-HTML is een aanrader.
8. MechanicalSoup

is een Python-bibliotheek die webformulieren en eenvoudige browserinteracties automatiseert. Gebouwd op Beautiful Soup en Requests, dus ideaal voor inloggen, formulieren invullen en simpele workflows ().
Waarom MechanicalSoup handig is:
- Automatiseert formulieren en logins: Ideaal voor data achter een login.
- Eenvoudige API: Snel op te pakken voor beginners.
- Perfect voor: Herhalende browseracties, simpele workflows, sites waar volledige browserautomatisering te veel is.
Niet zo krachtig als Selenium voor complexe sites, maar veel lichter en eenvoudiger voor basisbehoeften.
9. Puppeteer
is een Node.js-bibliotheek voor het aansturen van headless Chrome of Chromium. Dé favoriet voor het scrapen van JavaScript-rijke, interactieve websites ().
De kracht van Puppeteer:
- Volledige browserautomatisering: Klikken, scrollen, formulieren invullen—net als een echte gebruiker.
- Kan dynamische content aan: Ideaal voor sites die data via JavaScript laden.
- Perfect voor: E-commerce, social media, of elke site waar traditionele scrapers falen.
Ben je JavaScript-ontwikkelaar of moet je de ‘moderne web’ scrapen? Dan is Puppeteer onmisbaar.
10. Jsoup
is dé standaard voor HTML-parsing in Java. Zie het als Beautiful Soup, maar dan voor Java-ontwikkelaars ().
Waarom Java-teams dol zijn op Jsoup:
- Eenvoudige, krachtige API: Data extraheren en manipuleren met een paar regels code.
- Kan rommelige HTML aan: Maakt zelfs slecht opgemaakte pagina’s netjes.
- Perfect voor: Scraping integreren in Java-apps of backend-processen.
Werk je met Java? Dan is Jsoup de logische keuze.
Vergelijkingstabel Webscraping-bibliotheken
Hier een snel overzicht van alle 10 bibliotheken:
| Bibliotheek | Taal | Gebruiksgemak | Dynamische Content | AI/No-Code | Typische Toepassingen | Beste Voor |
|---|---|---|---|---|---|---|
| Thunderbit | Chrome Ext. | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Ja | Sales, operations, research, vastgoed | Niet-coders, zakelijke gebruikers |
| Beautiful Soup | Python | ⭐⭐⭐⭐ | ⭐ | Nee | HTML-parsing, datacleaning | Python-beginners, analisten |
| Scrapy | Python | ⭐⭐⭐ | ⭐⭐ | Nee | Grootschalig crawlen, pipelines | Developers, big data projecten |
| Selenium | Multi | ⭐⭐ | ⭐⭐⭐⭐⭐ | Nee | Browserautomatisering, logins | QA, scraping dynamische sites |
| lxml | Python | ⭐⭐⭐ | ⭐ | Nee | Snel parsen, grote bestanden | Power users, grote datasets |
| PyQuery | Python | ⭐⭐⭐⭐ | ⭐ | Nee | jQuery-achtige selectie | Webdevs, compacte scripts |
| Requests-HTML | Python | ⭐⭐⭐⭐ | ⭐⭐ | Nee | Snel scripts, JS-rendering | Beginners, kleine projecten |
| MechanicalSoup | Python | ⭐⭐⭐⭐ | ⭐⭐ | Nee | Formulieren automatiseren, logins | Simpele browseracties |
| Puppeteer | Node.js | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Nee | JS-rijke sites, automatisering | JS devs, dynamische webscraping |
| Jsoup | Java | ⭐⭐⭐⭐ | ⭐ | Nee | HTML-parsing in Java | Java-teams, backend workflows |
Hoe Kies je de Juiste Webscraping-bibliotheek voor Jouw Bedrijf?
Welke bibliotheek past nu het beste bij jou? Mijn advies, gebaseerd op jaren praktijkervaring (en heel wat nachtelijk debuggen):
- Niet-coders of zakelijke gebruikers: Begin met Thunderbit. Dankzij AI/no-code heb je in minuten resultaat. Wil je gewoon data in Excel of Sheets? Maak het niet moeilijker dan nodig.
- Python-ontwikkelaars: Beautiful Soup en Requests-HTML zijn top voor kleine klussen. Scrapy is je vriend voor grote projecten. Combineer met lxml of PyQuery voor extra kracht.
- Moet je inloggen of met dynamische content werken? Selenium (multi-language) of Puppeteer (Node.js) zijn dan de beste opties.
- Java-teams: Jsoup is dé keuze voor integratie in Java-apps.
- Formulieren of simpele workflows automatiseren? MechanicalSoup is lichtgewicht en eenvoudig.
Belangrijke factoren om te overwegen:
- Technische kennis: No-code tools zoals Thunderbit zijn ideaal voor niet-technische teams. Ontwikkelaars kiezen vaak liever voor code-gebaseerde bibliotheken.
- Datacomplexiteit: Voor simpele, statische pagina’s zijn Beautiful Soup of Jsoup perfect. Voor dynamische, JavaScript-rijke sites kies je Selenium of Puppeteer.
- Schaal: Scrapy en lxml zijn ideaal voor grootschalige, snelle klussen.
- Integratie: Thunderbit’s directe export naar Sheets, Notion en Airtable bespaart veel tijd in zakelijke workflows.
Meer weten over de juiste keuze? Bekijk .
Conclusie: Ontgrendel Webdata met de Juiste Tools
Webscraping in 2026 is allang niet meer alleen voor programmeurs of data scientists. Dankzij de opkomst van AI-gedreven en no-code tools kan elk team—van sales tot research—profiteren van de data die het web te bieden heeft. De juiste bibliotheek kan je honderden uren per jaar besparen (), je nauwkeurigheid verhogen en je bedrijf een voorsprong geven.
Mijn tip? Begin bij je eigen behoeften—snelheid, schaal, technische kennis—en probeer een paar opties uit. is ideaal om kennis te maken, en open source-bibliotheken als Beautiful Soup of Scrapy zijn er altijd als je zelf wilt programmeren.
Meer weten? Bekijk de voor meer handleidingen, of abonneer je op ons voor praktische tutorials.
Veel succes met scrapen—en moge je data altijd schoon, gestructureerd en direct bruikbaar zijn.
Veelgestelde Vragen
1. Wat is de makkelijkste webscraping-bibliotheek voor niet-programmeurs in 2026?
is de beste keuze voor niet-coders. De AI Chrome-extensie laat je data scrapen met natuurlijke taal, zonder enige programmeerkennis.
2. Welke bibliotheek is het beste voor JavaScript-rijke of dynamische websites?
(Node.js) en (multi-language) zijn het meest geschikt voor dynamische, JavaScript-gedreven sites. Ze automatiseren echte browsers en kunnen complexe interacties aan.
3. Wat is het verschil tussen Beautiful Soup en Scrapy?
is ideaal voor het parsen en extraheren van data uit enkele pagina’s of kleine projecten, vooral bij rommelige HTML. is een compleet framework voor het bouwen van schaalbare crawlers en het verwerken van grote datasets.
4. Kan ik gescrapete data direct exporteren naar Google Sheets of Notion?
Ja— biedt directe export naar Google Sheets, Notion, Airtable en Excel. Bij de meeste codebibliotheken moet je zelf exportfunctionaliteit toevoegen.
5. Hoe kies ik de juiste webscraping-bibliotheek voor mijn bedrijf?
Kijk naar je technische vaardigheden, de complexiteit van de sites die je wilt scrapen, de hoeveelheid data en je integratiebehoeften. No-code tools zoals Thunderbit zijn ideaal voor zakelijke teams, terwijl ontwikkelaars vaak kiezen voor Scrapy, Beautiful Soup of Puppeteer voor meer controle.
Meer weten