Het internet staat bomvol waardevolle data, maar het grootste deel daarvan kun je niet zomaar downloaden. In 2025 is webscraping niet langer een hobby voor nerds, maar een must-have voor teams die prijzen, vacatures, vastgoed of concurrenten willen volgen. Alleen: Github puilt uit van de webscraping-projecten. Sommige zijn tot in de puntjes verzorgd, andere zijn een drama om te gebruiken, en veel zijn al tijden niet meer bijgewerkt. Hoe kies je dan de juiste—zeker als je geen programmeur bent?
In deze gids neem ik je mee langs de 15 beste webscraping Github-projecten voor 2025. Geen saaie lijst, maar een overzicht op basis van installatiegemak, waarvoor je het kunt gebruiken, of het met dynamische content overweg kan, hoe actief het wordt onderhouden, de exportmogelijkheden en voor wie het project eigenlijk bedoeld is. En als je geen zin hebt om te stoeien met code, laat ik je zien waarom no-code, AI-gedreven tools zoals het verschil maken voor zakelijke gebruikers en mensen zonder technische achtergrond.
Hoe hebben we de Top 15 Webscraping Github-projecten gekozen?
Laten we eerlijk zijn: niet elk Github-project is even goed. Sommige zijn door duizenden mensen getest, andere zijn nooit verder gekomen dan een hobbyprojectje. Voor deze lijst heb ik gekeken naar projecten die voldoen aan deze punten:
- Github-sterren & Community: Projecten met een flinke gebruikersgroep (van een paar duizend tot 90k+ sterren) en actieve bijdragers.
- Recente Activiteit: Tools die in 2025 nog steeds updates krijgen—geen digitale museumstukken.
- Documentatie & Gebruiksgemak: Duidelijke uitleg, voorbeeldcode en een redelijke leercurve.
- Echte Toepassing: Wordt gebruikt voor zakelijke of onderzoeksdoeleinden, niet alleen als “hello world”-voorbeeld.
Omdat webscraping voor iedereen iets anders betekent, vergelijk ik elk project op:
- Installatie & Opstartgemak: Kun je binnen een paar minuten aan de slag, of moet je eerst stoeien met drivers en afhankelijkheden?
- Toepassingsgebied: Is het gericht op e-commerce, nieuws, onderzoek of iets anders?
- Ondersteuning voor Dynamische Pagina’s: Kan het moderne, JavaScript-rijke sites aan?
- Projectgezondheid: Wordt het actief onderhouden, of is de laatste update uit de oertijd?
- Data-export: Krijg je direct bruikbare data, of alleen ruwe HTML?
- Doelgroep: Is het geschikt voor Python-beginners, data engineers of niet-technische teams?
Elk project krijgt een handige tag per criterium, zodat je snel ziet wat bij jouw situatie past—of je nu een codeheld bent of gewoon data in Google Sheets wilt.
Installatie & Opstartgemak: Hoe snel kun je aan de slag?
Voor de meeste mensen is het grootste struikelblok: hoe krijg je een scraper aan de praat? Daarom deel ik de installatiecomplexiteit zo in:
- Plug & Play (Geen Gedoe): Installeren en direct aan de slag. Perfect voor beginners.
- Gemiddeld (Command Line, Beetje Code): Je moet wat code schrijven of de CLI gebruiken, maar als je eerder gescript hebt, lukt het wel.
- Geavanceerd (Drivers, Anti-bot, Diepe Code): Vereist omgevingsinstellingen, browserdrivers of serieuze Python/JS-kennis.
Zo scoren de top-projecten:
- Plug & Play: MechanicalSoup (Python), Nokogiri (Ruby), Maxun (voor eindgebruikers, na installatie)
- Gemiddeld: Scrapy, Crawlee, Node Crawler, Selenium, Playwright, Colly, Puppeteer, Katana, Scrapling, WebMagic
- Geavanceerd: Heritrix, Apache Nutch (beide vereisen Java, config-bestanden of big data-stacks)
Ben je geen programmeur? Dan zijn de “Plug & Play” of no-code opties je beste vriend. Voor de rest geldt: “Gemiddeld” betekent dat je wat code moet schrijven, maar het blijft overzichtelijk—tenzij je allergisch bent voor accolades.
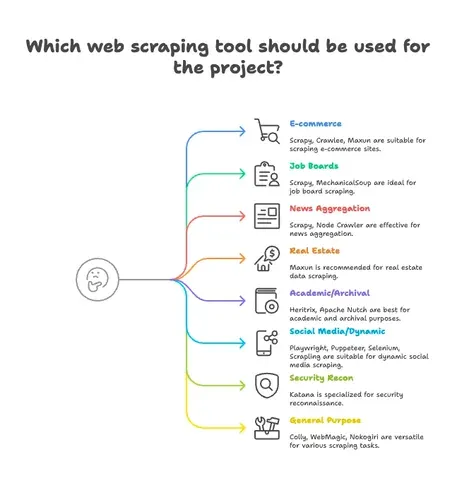
Toepassingsgericht Groeperen: Welke scraper past bij jouw sector?
Niet elke scraper is voor hetzelfde doel gemaakt. Daarom groepeer ik de top 15 op hun beste toepassingsgebied:
E-commerce & Prijsmonitoring
- Scrapy: Grootschalig, multi-pagina product scraping
- Crawlee: Flexibel, werkt voor zowel statische als dynamische e-commerce sites
- Maxun: No-code, ideaal voor snelle productlijsten
Vacaturebanken & Recruitment
- Scrapy: Kan paginering en gestructureerde lijsten aan
- MechanicalSoup: Geschikt voor jobboards met login
Nieuws & Contentaggregatie
- Scrapy: Ontworpen voor grootschalig nieuws scrapen
- Node Crawler: Snel voor statische nieuwsaggregatie
Vastgoed
- Thunderbit: AI-gestuurde scraping van lijsten én detailpagina’s
- Maxun: Visuele selectie van vastgoeddata
Academisch Onderzoek & Webarchivering
- Heritrix: Volledige site-archivering (WARC-bestanden)
- Apache Nutch: Gedistribueerd crawlen voor onderzoeksdata
Social Media & Dynamische Content
- Playwright, Puppeteer, Selenium: Scrapen van dynamische feeds, logins simuleren
- Scrapling: Onopvallend scrapen van sites met anti-botmaatregelen
Security & Reconnaissance
- Katana: Razendsnelle URL-detectie, security crawling
Algemeen Gebruik / Multipurpose
- Colly: Krachtige Go-scraper voor elke site
- WebMagic: Java-based, flexibel voor veel domeinen
- Nokogiri: Ruby-parser voor maatwerk
Ondersteuning voor Dynamische Pagina’s: Kunnen deze Github-projecten moderne sites aan?
Moderne websites draaien op JavaScript. React, Vue, infinite scroll, AJAX—als je ooit een pagina probeerde te scrapen en alleen “niets” kreeg, weet je hoe frustrerend dat is.
Zo pakken de projecten dynamische content aan:
- Volledige JS-ondersteuning (Headless Browser):
- Selenium: Stuurt echte browsers aan, voert alle JS uit
- Playwright: Multi-browser, multi-language, robuuste JS-ondersteuning
- Puppeteer: Headless Chrome/Firefox, volledige JS-rendering
- Crawlee: Wisselt tussen HTTP en browser (via Puppeteer/Playwright)
- Katana: Optionele headless-modus voor JS-parsing
- Scrapling: Integreert Playwright voor stealth JS-scraping
- Maxun: Gebruikt browser onder de motorkap voor dynamische content
- Geen native JS-ondersteuning (Alleen statische HTML):
- Scrapy: Heeft Selenium/Playwright-plugin nodig voor JS
- MechanicalSoup, Node Crawler, Colly, WebMagic, Nokogiri, Heritrix, Apache Nutch: Allemaal alleen HTML, geen JS out-of-the-box
Thunderbit’s AI steekt er met kop en schouders bovenuit: het herkent en scrapt automatisch dynamische content—geen handmatige instellingen, geen plugins, geen gezoek naar selectors. Klik gewoon op “AI Suggest Fields” en de tool doet het zware werk, zelfs op React-sites. Meer weten? Lees .
Projectgezondheid & Betrouwbaarheid: Werkt deze scraper volgend jaar nog?
Niets is zo vervelend als je workflow bouwen rond een tool die ineens niet meer wordt onderhouden. Zo scoren de top-projecten:
- Actief Onderhouden (Regelmatige updates):
- Scrapy:
- Crawlee:
- Playwright:
- Puppeteer:
- Katana:
- Colly:
- Maxun:
- Scrapling:
- Stabiel maar Minder Updates:
- MechanicalSoup:
- Node Crawler:
- WebMagic:
- Nokogiri:
- Onderhoudsmodus (Gespecialiseerd, traag):
- Heritrix:
- Apache Nutch:
Thunderbit is een beheerde dienst, dus je hoeft je nooit druk te maken over verouderde code. Het team houdt de AI, sjablonen en koppelingen up-to-date—en je krijgt onboarding, tutorials en support als je vastloopt.
Datahandling & Export: Van ruwe HTML naar bruikbare data
Data binnenhalen is pas het begin. Je wilt het in een formaat dat je team direct kan gebruiken—CSV, Excel, Google Sheets, Airtable, Notion of zelfs een live API.
- Ingebouwde gestructureerde export:
- Scrapy: CSV, JSON, XML export
- Crawlee: Flexibele datasets, opslag
- Maxun: CSV, Excel, Google Sheets, JSON API
- Thunderbit:
- Handmatige datahandling (zelf regelen):
- MechanicalSoup, Node Crawler, Selenium, Playwright, Puppeteer, Colly, WebMagic, Nokogiri, Scrapling: Je schrijft zelf code om data op te slaan/exporteren
- Gespecialiseerde export:
- Heritrix: WARC (webarchief-bestanden)
- Apache Nutch: Ruwe content naar opslag/index
Thunderbit’s gestructureerde export en integraties besparen zakelijke gebruikers veel tijd. Geen gedoe meer met CSV’s of zelf code schrijven—gewoon klikken en je data is direct bruikbaar.
Doelgroep: Voor wie is elk Webscraping Github-project bedoeld?
Niet elke tool is voor iedereen. Mijn aanbevelingen:
- Python-beginners: MechanicalSoup, Scrapling (voor de avontuurlijke beginner)
- Data engineers: Scrapy, Crawlee, Colly, WebMagic, Node Crawler
- QA & Automatisering: Selenium, Playwright, Puppeteer
- Security researchers: Katana
- Ruby-ontwikkelaars: Nokogiri
- Java-ontwikkelaars: WebMagic, Heritrix, Apache Nutch
- Niet-technische gebruikers / zakelijke teams: Maxun, Thunderbit
- Growth hackers, analisten: Maxun, Thunderbit
Geen zin in code, of wil je snel resultaat? Dan zijn Thunderbit en Maxun de beste keuze. Voor de rest: kies de tool die past bij jouw programmeertaal en toepassing.
De Top 15 Webscraping Github-projecten: Uitgebreide vergelijking
Hier volgt een overzicht per project, gegroepeerd op toepassing, met handige tags en highlights.
E-commerce, Prijsmonitoring en Algemeen Crawlen
— 57.1k sterren, update juni 2025

- Samenvatting: Krachtig, asynchroon Python-framework voor grootschalig crawlen en scrapen.
- Installatie: Gemiddeld (Python-code, async framework)
- Toepassing: E-commerce, nieuws, onderzoek, multi-pagina spiders
- JS-ondersteuning: Nee (plugin nodig)
- Projectgezondheid: Actief onderhouden
- Data-export: CSV, JSON, XML ingebouwd
- Doelgroep: Ontwikkelaars, data engineers
- Highlights: Schaalbaar, robuust, veel plugins. Steile leercurve voor beginners.
— 17.9k sterren, 2025

- Samenvatting: Volledig uitgeruste Node.js-bibliotheek voor statisch en dynamisch scrapen.
- Installatie: Gemiddeld (Node/TS-code)
- Toepassing: E-commerce, social media, automatisering
- JS-ondersteuning: Ja (Puppeteer/Playwright-integratie)
- Projectgezondheid: Zeer actief
- Data-export: Flexibel (datasets, opslag)
- Doelgroep: Dev-teams in JS/TS
- Highlights: Anti-blokkeringstools, eenvoudig schakelen tussen HTTP/browser.
— 13k sterren, juni 2025

- Samenvatting: Open-source, no-code webdata-extractieplatform met visuele interface.
- Installatie: Gemiddeld (serverinstallatie), eenvoudig (voor eindgebruikers)
- Toepassing: Algemeen, e-commerce, zakelijke scraping
- JS-ondersteuning: Ja (browser onder de motorkap)
- Projectgezondheid: Actief & groeiend
- Data-export: CSV, Excel, Google Sheets, JSON API
- Doelgroep: Niet-technische gebruikers, analisten, teams
- Highlights: Point-and-click scraping, multi-level navigatie, zelf te hosten.
Vacaturebanken, Recruitment en Simpele Interacties
— 4.8k sterren, 2024

- Samenvatting: Python-bibliotheek voor het automatiseren van formulieren en eenvoudige navigatie.
- Installatie: Plug & Play (Python, minimale code)
- Toepassing: Jobboards met login, statische sites
- JS-ondersteuning: Nee
- Projectgezondheid: Volwassen, licht onderhouden
- Data-export: Geen ingebouwd (handmatig)
- Doelgroep: Python-beginners, snelle scripts
- Highlights: Simuleert browsersessies in een paar regels. Niet voor dynamische sites.
Nieuwsaggregatie & Statische Content
— 6.8k sterren, 2024

- Samenvatting: Snelle, gelijktijdige server-side crawler met Cheerio-parsing.
- Installatie: Gemiddeld (Node callbacks/async)
- Toepassing: Nieuws, snelle statische scraping
- JS-ondersteuning: Nee (alleen HTML)
- Projectgezondheid: Matige activiteit (v2 beta)
- Data-export: Geen ingebouwd (zelf regelen)
- Doelgroep: Node.js-ontwikkelaars, hoge snelheid nodig
- Highlights: Async crawlen, rate limiting, jQuery-achtige API.
Vastgoed, Lijsten en Subpagina’s Scrapen

- Samenvatting: AI-gedreven, no-code webscraper voor zakelijke gebruikers.
- Installatie: Plug & Play (Chrome-extensie, 2 klikken)
- Toepassing: Vastgoed, e-commerce, sales, marketing, elke website
- JS-ondersteuning: Ja (AI detecteert dynamische content automatisch)
- Projectgezondheid: Continu bijgewerkt, beheerde dienst
- Data-export: Met één klik naar Sheets, Airtable, Notion, CSV, JSON
- Doelgroep: Niet-technische gebruikers, zakelijke teams, sales, marketing
- Highlights: AI “Suggest Fields”, subpagina’s scrapen, direct exporteren, onboarding, sjablonen, .
Academisch Onderzoek & Webarchivering
— 3k sterren, 2023

- Samenvatting: Webarchiver van Internet Archive op grote schaal.
- Installatie: Geavanceerd (Java-app, config-bestanden)
- Toepassing: Webarchivering, domeinbrede crawls
- JS-ondersteuning: Nee (alleen ophalen)
- Projectgezondheid: Onderhouden (traag maar stabiel)
- Data-export: WARC (webarchief-bestanden)
- Doelgroep: Archieven, bibliotheken, instellingen
- Highlights: Schaalbaar, robuust, standaard-compliant. Niet voor gerichte scraping.
— 3k sterren, 2024

- Samenvatting: Open-source crawler voor big data en zoekmachines.
- Installatie: Geavanceerd (Java+Hadoop voor schaal)
- Toepassing: Zoekmachine-crawling, big data
- JS-ondersteuning: Nee (alleen HTTP)
- Projectgezondheid: Actief (Apache)
- Data-export: Ruwe content naar opslag/index
- Doelgroep: Bedrijven, big data, academisch onderzoek
- Highlights: Plugin-architectuur, gedistribueerd crawlen.
Social Media, Dynamische Content en Automatisering
— ~30k sterren, 2025

- Samenvatting: Browserautomatisering voor scraping en testen, ondersteunt alle grote browsers.
- Installatie: Gemiddeld (drivers, multi-language)
- Toepassing: JS-rijke sites, testflows, social media
- JS-ondersteuning: Ja (volledige browserautomatisering)
- Projectgezondheid: Actief, volwassen
- Data-export: Geen (handmatig)
- Doelgroep: QA-engineers, ontwikkelaars
- Highlights: Multi-language, simuleert echt gebruikersgedrag.
— 73.5k sterren, 2025

- Samenvatting: Moderne browserautomatisering voor scraping en E2E-testen.
- Installatie: Gemiddeld (multi-language scripting)
- Toepassing: Moderne webapps, social media, automatisering
- JS-ondersteuning: Ja (headless of echte browser)
- Projectgezondheid: Zeer actief
- Data-export: Geen (zelf regelen)
- Doelgroep: Ontwikkelaars die robuuste browsercontrole nodig hebben
- Highlights: Cross-browser, auto-wait, netwerkinterceptie.
— 90.9k sterren, 2025

- Samenvatting: High-level API voor Chrome/Firefox-automatisering.
- Installatie: Gemiddeld (Node-scripting)
- Toepassing: Headless Chrome scraping, dynamische content
- JS-ondersteuning: Ja (Chrome/Firefox)
- Projectgezondheid: Actief (Chrome-team)
- Data-export: Geen (zelf in code)
- Doelgroep: Node.js-ontwikkelaars, front-end specialisten
- Highlights: Uitgebreide browsercontrole, screenshots, PDF, netwerkinterceptie.
— 5.4k sterren, juni 2025

- Samenvatting: Onopvallende, snelle scraper met anti-botfuncties.
- Installatie: Gemiddeld (Python-code)
- Toepassing: Stealth scraping, anti-bot, dynamische sites
- JS-ondersteuning: Ja (Playwright-integratie)
- Projectgezondheid: Actief, cutting edge
- Data-export: Geen ingebouwd (handmatig)
- Doelgroep: Python-ontwikkelaars, hackers, data engineers
- Highlights: Stealth, proxy, anti-blokkering, async.
Security Reconnaissance
— 13.8k sterren, 2025

- Samenvatting: Supersnelle webcrawler voor security, automatisering en linkdetectie.
- Installatie: Gemiddeld (CLI-tool of Go-lib)
- Toepassing: Security crawling, endpoint-detectie
- JS-ondersteuning: Ja (optionele headless-modus)
- Projectgezondheid: Actief (ProjectDiscovery)
- Data-export: Tekstoutput (URL-lijsten)
- Doelgroep: Security researchers, Go-ontwikkelaars
- Highlights: Snelheid, gelijktijdigheid, headless JS-parsing.
Algemeen Gebruik / Multipurpose Scraping
— 24.3k sterren, 2025

- Samenvatting: Snelle, elegante scraping-framework voor Go.
- Installatie: Gemiddeld (Go-code)
- Toepassing: High-performance, algemeen scrapen
- JS-ondersteuning: Nee (alleen HTML)
- Projectgezondheid: Actief, recente commits
- Data-export: Geen ingebouwd (zelf regelen)
- Doelgroep: Go-ontwikkelaars, prestatiegericht
- Highlights: Async, rate limiting, distributed scraping.
— 11.6k sterren, 2023

- Samenvatting: Flexibel Java-crawlerframework, Scrapy-stijl.
- Installatie: Gemiddeld (Java, eenvoudige API)
- Toepassing: Algemeen webscrapen in Java
- JS-ondersteuning: Nee (uit te breiden met Selenium)
- Projectgezondheid: Actieve community
- Data-export: Pluggable pipelines
- Doelgroep: Java-ontwikkelaars
- Highlights: Threadpool, schedulers, anti-blokkering.
— 6.2k sterren, 2025

- Samenvatting: Snelle, native HTML/XML-parser voor Ruby.
- Installatie: Plug & Play (Ruby-gem)
- Toepassing: HTML/XML-parsing in Ruby-apps
- JS-ondersteuning: Nee (alleen parsing)
- Projectgezondheid: Actief, volgt Ruby-updates
- Data-export: Geen (gebruik Ruby voor formatting)
- Doelgroep: Rubyists, Rails-ontwikkelaars
- Highlights: Snelheid, compliance, standaard veilig.
In één oogopslag: Vergelijkingstabel
Hier een snelle vergelijkingstabel—plus Thunderbit ter referentie:
| Project | Setup Complexity | Use Case | JS Support | Maintenance | Data Export | Audience | Github Stars |
|---|---|---|---|---|---|---|---|
| Scrapy | Gemiddeld | E-commerce, nieuws | Nee | Actief | CSV, JSON, XML | Devs, data engineers | 57.1k |
| Crawlee | Gemiddeld | Veelzijdig, automatisering | Ja | Zeer actief | Flexibele datasets | JS/TS dev teams | 17.9k |
| MechanicalSoup | Plug & Play | Statisch, formulieren | Nee | Volwassen | Geen (handmatig) | Python beginners | 4.8k |
| Node Crawler | Gemiddeld | Nieuws, statisch | Nee | Matig | Geen (handmatig) | Node.js devs | 6.8k |
| Selenium | Gemiddeld | JS-rijk, testen | Ja | Actief | Geen (handmatig) | QA engineers, devs | ~30k |
| Heritrix | Geavanceerd | Archivering, onderzoek | Nee | Onderhouden | WARC | Archieven, instellingen | 3k |
| Apache Nutch | Geavanceerd | Big data, search | Nee | Actief | Ruwe content | Enterprises, research | 3k |
| WebMagic | Gemiddeld | Java, algemeen | Nee | Actieve community | Pluggable pipelines | Java devs | 11.6k |
| Nokogiri | Plug & Play | Ruby parsing | Nee | Actief | Geen (handmatig) | Rubyists | 6.2k |
| Playwright | Gemiddeld | Dynamisch, automatisering | Ja | Zeer actief | Geen (handmatig) | Devs, QA | 73.5k |
| Katana | Gemiddeld | Security, discovery | Ja | Actief | Tekstoutput | Security, Go devs | 13.8k |
| Colly | Gemiddeld | High-perf, algemeen | Nee | Actief | Geen (handmatig) | Go devs | 24.3k |
| Puppeteer | Gemiddeld | Dynamisch, automatisering | Ja | Actief | Geen (handmatig) | Node.js devs | 90.9k |
| Maxun | Eenvoudig (gebruiker) | No-code, zakelijk | Ja | Actief | CSV, Excel, Sheets, API | Niet-tech, analisten | 13k |
| Scrapling | Gemiddeld | Stealth, anti-bot | Ja | Actief | Geen (handmatig) | Python devs, hackers | 5.4k |
| Thunderbit | Plug & Play | No-code, zakelijk | Ja | Beheerd, up-to-date | Sheets, Airtable, Notion | Niet-tech, zakelijke gebruikers | N/B |
Waarom Thunderbit de beste keuze is voor niet-technische en zakelijke gebruikers
Eerlijk is eerlijk: de meeste open-source Github-projecten zijn gemaakt door en voor programmeurs. Dat betekent dat je zelf moet installeren, onderhouden en troubleshooten. Ben je een zakelijke gebruiker, marketeer, sales of wil je gewoon snel resultaat—zonder gedoe met regex? Dan is Thunderbit voor jou gemaakt.
Waarom Thunderbit eruit springt:
- No-code, AI-gedreven gemak: Installeer de , klik op “AI Suggest Fields” en je bent aan het scrapen. Geen Python, geen selectors, geen “pip install”-gedoe.
- Dynamische pagina’s: Thunderbit’s AI leest en haalt data uit moderne, JavaScript-rijke sites (React, Vue, AJAX) zonder handmatige instellingen.
- Subpagina’s scrapen: Details van elk product of listing nodig? Thunderbit’s AI klikt automatisch door subpagina’s en voegt alles samen in één tabel—zonder maatwerkcode.
- Direct bruikbare export: Met één klik naar Google Sheets, Airtable, Notion, CSV of JSON. Ideaal voor leads, prijsmonitoring of contentverzameling.
- Altijd up-to-date & support: Thunderbit is een beheerde dienst—geen risico op “abandonware”. Je krijgt onboarding, tutorials en een groeiende sjabloonbibliotheek voor veelgebruikte sites.
- Doelgroep: Thunderbit is voor niet-technische gebruikers, zakelijke teams en iedereen die snelheid en betrouwbaarheid belangrijker vindt dan zelf sleutelen aan code.
Thunderbit wordt wereldwijd gebruikt door meer dan 30.000 gebruikers, waaronder teams van Accenture, Grammarly en Puma. En ja, we waren zelfs #1 Product van de Week op Product Hunt.
Zelf ervaren hoe makkelijk scrapen kan zijn? .
Conclusie: De juiste webscraping-oplossing kiezen voor 2025
Samengevat: Github biedt een schat aan krachtige scrapingtools, maar de meeste zijn voor programmeurs. Ben je gek op code, dan geven frameworks als Scrapy, Crawlee, Playwright en Colly je maximale controle. Werk je in onderzoek of security, dan zijn Heritrix, Nutch en Katana jouw tools.
Maar ben je een zakelijke gebruiker, analist of wil je gewoon snel, gestructureerde data—zonder gedoe? Dan is Thunderbit de beste keuze. Geen installatie, geen onderhoud, geen code. Gewoon resultaat.
Wat nu? Probeer een Github-project dat past bij jouw niveau en toepassing. Of sla de leercurve over en zie direct resultaat: en begin vandaag nog met scrapen.
Meer weten over webscraping? Check meer gidsen op de , zoals of .
Succes met scrapen—en moge je data altijd netjes, schoon en direct bruikbaar zijn. Loop je vast? Er is vast een Github-repo voor… of laat gewoon de AI van Thunderbit het werk doen.