
The web is overflowing with data, and let’s face it—no one’s got time to copy and paste their way through a thousand product listings or competitor price pages. If you’re running Linux (like I do for most of my automation and dev work), you already know the platform is a powerhouse for data-driven teams. In fact, , and . But here’s the catch: finding the right web scraper for Linux that actually fits your workflow—whether you’re a non-technical business user or a hardcore coder—can feel like searching for a needle in a haystack.
That’s why I’ve put together this deep dive into the top 18 Linux web scraping tools for 2026. From AI-powered, no-code solutions like (yes, the one my team and I built) to classic developer frameworks like Scrapy and Beautiful Soup, this list is your shortcut to picking the best Linux web scraper for your needs—without the trial-and-error headache.
Why Linux Web Scraping Tools Matter for Business Users
Let’s get real: manual data collection is a productivity killer. Studies show that teams relying on copy-paste methods waste hours every week and rack up error rates near 5%—that’s a recipe for costly mistakes and missed opportunities (). Linux, with its stability, security, and flexibility, is the go-to platform for running scrapers that need to work 24/7—whether you’re on a desktop, a server, or the cloud.
Common business use cases for Linux web scraping tools:
- Lead Generation: Sales teams scrape directories, social media, or review sites for fresh contacts, skipping the manual grind ().
- Price Monitoring: E-commerce teams pull competitor prices and stock data automatically, keeping their own pricing sharp and up-to-date.
- Competitor Research: Marketing and ops teams track product launches, reviews, and SEO keywords—no more “flying blind.”
- Market Intelligence: Analysts aggregate news, forums, and social data to spot trends in real time.
- Workflow Automation: Some tools (especially AI-powered ones) can even automate web workflows, like filling forms or navigating dashboards, right from your Linux machine.
The best part? The right Linux web scraping tool can empower non-technical users—not just coders—to access and leverage web data for smarter, faster business decisions.
How We Selected the Best Web Scraper for Linux
Not all scrapers are created equal, especially on Linux. Here’s what I looked for:
- Linux Compatibility: Every tool here runs natively on Linux, via browser, or with a simple workaround (like Wine or cloud access).
- Ease of Use: From natural language AI prompts to visual point-and-click interfaces, I prioritized tools that let non-coders get results fast—but I didn’t forget about the power users who want full control.
- Data Extraction Power: Can it handle dynamic content, pagination, subpages, and various data types? Does it survive anti-scraping tricks?
- Scalability & Automation: Scheduling, cloud scraping, distributed crawling—these are must-haves for serious data projects.
- Integration & Export: CSV, Excel, Google Sheets, APIs—if you can’t get your data out, what’s the point?
- Pricing & Licensing: Free, open-source, or paid—there’s something for every budget, from solo founders to enterprise teams.
- Community & Support: Active user bases, good docs, and responsive support make a huge difference when you hit a snag.
I’ve also woven in real user feedback, industry reviews, and my own hands-on experience with these tools. Let’s dive into the list.
1. Thunderbit
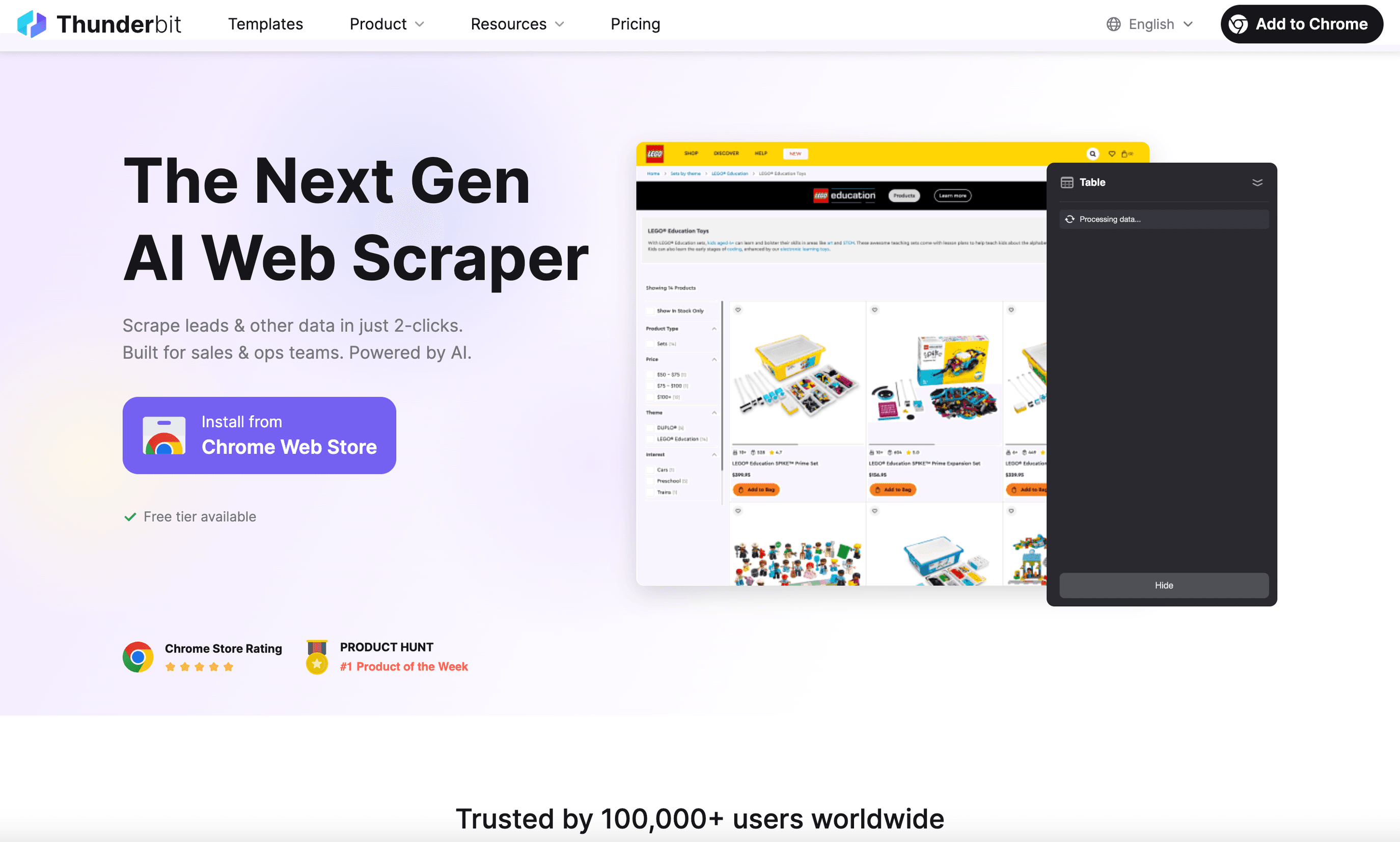 is my top pick for business users who want a web scraper for Linux that’s actually easy to use. As an , it runs perfectly on Linux (just open Chrome or Chromium) and lets you scrape data from any website in just two clicks.
is my top pick for business users who want a web scraper for Linux that’s actually easy to use. As an , it runs perfectly on Linux (just open Chrome or Chromium) and lets you scrape data from any website in just two clicks.
What makes Thunderbit stand out:
- Natural Language Prompts: Just describe what you want (“Extract all product names and prices from this page”) and Thunderbit’s AI figures out the rest.
- AI Suggest Fields: Click once, and Thunderbit scans the page, suggesting columns and data types—no manual field selection.
- Subpage & Pagination Scraping: Need more details? Thunderbit can visit each subpage (like product detail pages) and enrich your table automatically.
- Cloud or Local Scraping: Scrape up to 50 pages at once in the cloud, or use browser mode for sites that require login.
- Instant Export: One-click export to Excel, Google Sheets, Airtable, Notion, CSV, or JSON—always free.
- Bonus Tools: Extract emails, phone numbers, and images in a single click. AI autofill can even automate form input.
Pricing: Free tier (scrape 6–10 pages), paid plans start at $15/month for 500 rows (). Users love the “no learning curve” and how it “turns hours of work into minutes” (). For large jobs, you may need to split into smaller runs, but for most business use cases, it’s a huge time saver.
Linux compatibility: 100%. Just run Chrome/Chromium on your Linux desktop or server.
Best for: Non-technical business users (sales, marketing, ops) who want the fastest, easiest setup.
2. Scrapy
 is the gold standard for Python developers who want a flexible, scalable web scraper for Linux. It’s open-source, blazingly fast (asynchronous crawling), and can handle everything from simple scrapes to massive, distributed crawls.
is the gold standard for Python developers who want a flexible, scalable web scraper for Linux. It’s open-source, blazingly fast (asynchronous crawling), and can handle everything from simple scrapes to massive, distributed crawls.
Key features:
- Asynchronous, high-speed crawling—perfect for scraping thousands of pages.
- Highly extensible: Plugins for proxies, CAPTCHAs, and more.
- Integrates with Python data stack: Output to JSON, CSV, databases, or pandas.
- Handles cookies, sessions, and auto-throttling.
Pricing: 100% free and open-source.
Linux compatibility: Native (install via pip). Runs great on servers and containers.
Best for: Developers building custom, large-scale scrapers.
Heads up: There’s a learning curve for non-coders, but if you know Python, Scrapy is hard to beat.
3. Beautiful Soup
 is a lightweight Python library for parsing HTML and XML. It’s the go-to for quick-and-dirty scraping or cleaning up messy web pages.
is a lightweight Python library for parsing HTML and XML. It’s the go-to for quick-and-dirty scraping or cleaning up messy web pages.
Key features:
- Simple, human-friendly API—great for beginners.
- Pairs well with requests for fetching pages.
- Handles broken HTML gracefully.
Pricing: Free and open-source.
Linux compatibility: 100% (pure Python).
Best for: Developers and data scientists doing small-to-medium scraping or parsing tasks.
Limitations: Doesn’t handle JavaScript or dynamic content—combine with Selenium or Puppeteer if you need that.
4. Selenium
 is the classic browser automation framework. It lets you control Chrome, Firefox, or other browsers for scraping dynamic, JavaScript-heavy sites.
is the classic browser automation framework. It lets you control Chrome, Firefox, or other browsers for scraping dynamic, JavaScript-heavy sites.
Key features:
- Automates real browsers—can log in, click, scroll, and interact like a human.
- Supports Python, Java, C#, and more.
- Headless mode for running on Linux servers.
Pricing: Free and open-source.
Linux compatibility: Full support (just install the right browser driver).
Best for: QA engineers, scraping developers, and anyone who needs to simulate user behavior.
Heads up: Resource-intensive and slower than pure HTTP scrapers, but sometimes it’s the only way to get the data you need.
5. Puppeteer
 is a Node.js library from Google for controlling headless Chrome/Chromium. It’s like Selenium, but with a modern JavaScript API and tight integration with Chrome’s features.
is a Node.js library from Google for controlling headless Chrome/Chromium. It’s like Selenium, but with a modern JavaScript API and tight integration with Chrome’s features.
Key features:
- Executes JavaScript, handles dynamic content, and takes screenshots.
- Fast, stable, and easy to use for Node.js devs.
- Intercepts network requests and blocks unwanted resources.
Pricing: Free and open-source.
Linux compatibility: Installs Chromium automatically; works headless by default.
Best for: Developers scraping modern web apps or single-page sites.
6. Octoparse
 is a no-code web scraper with a drag-and-drop interface and tons of pre-built templates. While the desktop app is Windows/Mac only, Linux users can access Octoparse’s cloud platform via browser or run the Windows app with Wine.
is a no-code web scraper with a drag-and-drop interface and tons of pre-built templates. While the desktop app is Windows/Mac only, Linux users can access Octoparse’s cloud platform via browser or run the Windows app with Wine.
Key features:
- 100+ ready-made scraping templates for sites like Amazon, eBay, Zillow, etc.
- Visual workflow designer—point and click to build your scraper.
- Cloud scraping and scheduling—let Octoparse’s servers do the heavy lifting.
- Exports to Excel, CSV, JSON, and databases.
Pricing: Free tier (limited features), paid plans start at $75–$89/month.
Linux compatibility: Cloud/web access; desktop app via Wine.
Best for: Non-coders needing e-commerce or marketplace data quickly.
7. PhantomJS
 is a headless WebKit browser that was once the go-to for lightweight browser automation. It’s now deprecated, but still runs on Linux for legacy or simple tasks.
is a headless WebKit browser that was once the go-to for lightweight browser automation. It’s now deprecated, but still runs on Linux for legacy or simple tasks.
Key features:
- Scriptable in JavaScript.
- Handles moderate JavaScript and takes screenshots/PDFs.
- No GUI needed.
Pricing: Free and open-source.
Linux compatibility: Native binary.
Best for: Legacy projects or environments where installing Chrome isn’t possible.
Caveat: No longer maintained—modern sites may not work well.
8. ParseHub
 is a visual, cross-platform web scraper with a native Linux app. It’s great for non-coders who want to scrape complex, dynamic sites.
is a visual, cross-platform web scraper with a native Linux app. It’s great for non-coders who want to scrape complex, dynamic sites.
Key features:
- Point-and-click interface—select elements, build workflows visually.
- Handles dynamic content, maps, infinite scroll, and more.
- Cloud execution and scheduling.
- Exports to CSV, JSON, or via API.
Pricing: Free plan (5 projects), paid plans from $189/month.
Linux compatibility: Native app for Linux, Windows, Mac.
Best for: Analysts and semi-technical users who want control without coding.
9. Kimurai
 is a Ruby web scraping framework that supports Linux natively. It’s like Scrapy, but for Ruby devs.
is a Ruby web scraping framework that supports Linux natively. It’s like Scrapy, but for Ruby devs.
Key features:
- Multi-browser support: Headless Chrome, Firefox, PhantomJS, or plain HTTP.
- Asynchronous processing for high concurrency.
- Clean Ruby DSL for writing spiders.
Pricing: Free and open-source.
Linux compatibility: 100% (Ruby).
Best for: Ruby developers or Rails teams needing custom, high-concurrency scraping.
10. Apify
 is a cloud-based web scraping platform with open-source SDKs and a marketplace of ready-made “actors.” You can run scrapers on your Linux machine or in the cloud.
is a cloud-based web scraping platform with open-source SDKs and a marketplace of ready-made “actors.” You can run scrapers on your Linux machine or in the cloud.
Key features:
- SDKs for Node.js, Python, and more.
- Marketplace of pre-built scrapers.
- Cloud execution, scheduling, and API integration.
Pricing: Free tier, pay-as-you-go for cloud usage.
Linux compatibility: CLI/SDK runs on Linux; cloud platform accessible via browser.
Best for: Devs who want a mix of custom coding and a ready cloud infrastructure.
11. Colly
 is a Go-based web scraping framework built for speed and efficiency. If you’re a Go developer, this is your tool.
is a Go-based web scraping framework built for speed and efficiency. If you’re a Go developer, this is your tool.
Key features:
- Super-fast, concurrent scraping—over 1,000 requests/sec on a single core.
- Polite crawling (respects robots.txt), session/cookie management.
- Low memory footprint.
Pricing: Free and open-source.
Linux compatibility: Native Go binaries.
Best for: Go developers needing high-performance scraping.
12. PySpider
 is a Python web crawler system with a web UI. You can manage, schedule, and monitor crawls from your browser.
is a Python web crawler system with a web UI. You can manage, schedule, and monitor crawls from your browser.
Key features:
- Web-based interface for scripting and monitoring.
- Distributed crawling, scheduling, and retries.
- Integrates with databases and message queues.
Pricing: Free and open-source.
Linux compatibility: Designed for Linux deployment.
Best for: Teams managing multiple scraping projects via a web UI.
13. WebHarvy
 is a visual point-and-click scraper for Windows, but Linux users can run it via Wine. It’s known for its pattern detection and one-time purchase model.
is a visual point-and-click scraper for Windows, but Linux users can run it via Wine. It’s known for its pattern detection and one-time purchase model.
Key features:
- Browse and click to select data—no coding.
- Automatic pattern detection for lists.
- Exports to CSV, JSON, XML, SQL.
Pricing: ~$139 one-time license.
Linux compatibility: Runs under Wine or VM.
Best for: Beginners or solo professionals who want a quick, visual scraper.
14. OutWit Hub
 is a native Linux GUI application for web scraping. It auto-recognizes data patterns and offers powerful extraction and automation features.
is a native Linux GUI application for web scraping. It auto-recognizes data patterns and offers powerful extraction and automation features.
Key features:
- Auto-detects links, images, tables, emails, and more.
- Script editor for custom extraction.
- Macro automation and scheduling.
Pricing: Free version (limited), Pro license ~$50–$100.
Linux compatibility: Native app for Linux, Windows, Mac.
Best for: Non-coders with some technical inclination who want a desktop GUI scraper.
15. Portia
 is an open-source, visual web scraper from Scrapinghub. It runs in your browser and lets you annotate pages to train scrapers.
is an open-source, visual web scraper from Scrapinghub. It runs in your browser and lets you annotate pages to train scrapers.
Key features:
- Browser-based interface for visual extraction.
- Integrates with Scrapy for custom projects.
- Open-source and extensible.
Pricing: Free and open-source.
Linux compatibility: Browser-based; works on any OS.
Best for: Users who want open-source, visual scraping with Scrapy integration.
16. Content Grabber
 is an enterprise-grade visual scraper for Windows, but can be run on Linux via Wine or virtualization.
is an enterprise-grade visual scraper for Windows, but can be run on Linux via Wine or virtualization.
Key features:
- Visual editor plus C# scripting for advanced logic.
- Multi-agent management and scheduling.
- Integrates with databases, APIs, and more.
Pricing: Licenses in the thousands; server edition from $69/month.
Linux compatibility: Via Wine or VM.
Best for: Agencies and large teams managing many scraping projects.
17. Helium
 is a Python library that simplifies Selenium automation. It’s designed to make browser scripting more human-friendly.
is a Python library that simplifies Selenium automation. It’s designed to make browser scripting more human-friendly.
Key features:
- Intuitive commands like
click("Login")orwrite("email"). - Automates Chrome and Firefox.
- Great for quick scripting and automation tasks.
Pricing: Free and open-source.
Linux compatibility: Works on Linux (built on Selenium).
Best for: Python users who find Selenium too cumbersome.
18. Dexi.io
 is a cloud-based data extraction and automation platform. It’s accessible via browser, so Linux users can use it without any installs.
is a cloud-based data extraction and automation platform. It’s accessible via browser, so Linux users can use it without any installs.
Key features:
- Visual workflow designer for scraping and automation.
- Scheduling, data transformation, and API integration.
- Enterprise-grade scalability and support.
Pricing: Starts at $119/month (Standard); higher tiers for larger scale.
Linux compatibility: Web app—works on any OS.
Best for: Professionals and enterprises needing scalable, integrated web data extraction.
Quick Comparison Table: Linux Web Scraping Tools at a Glance
| Tool | Type / Key Features | Ideal For | Pricing | Linux Compatibility |
|---|---|---|---|---|
| Thunderbit | AI Chrome Extension, 2-click, subpage, cloud/local | Non-technical business users | Free, from $15/mo | ✔ Chrome on Linux |
| Scrapy | Python framework, async, CLI, highly extensible | Developers, large-scale custom scrapers | Free | ✔ Native |
| Beautiful Soup | Python library, simple HTML/XML parsing | Devs, data scientists, small tasks | Free | ✔ Native |
| Selenium | Browser automation, JS-heavy sites | QA, devs, dynamic content | Free | ✔ Native |
| Puppeteer | Node.js, headless Chrome, JS rendering | Node devs, modern web apps | Free | ✔ Native |
| Octoparse | No-code, drag-and-drop, cloud templates | Non-coders, e-commerce | Free, from $75/mo | ◐ Cloud/Wine |
| PhantomJS | Headless WebKit, scriptable JS | Legacy, lightweight, no Chrome | Free | ✔ Native |
| ParseHub | Visual, cross-platform, point-and-click | Analysts, semi-technical users | Free, from $189/mo | ✔ Native |
| Kimurai | Ruby framework, multi-browser, async | Ruby devs, high concurrency | Free | ✔ Native |
| Apify | Cloud platform, SDKs, marketplace | Devs, hybrid custom/cloud | Free tier, usage-based | ✔ Native/Cloud |
| Colly | Go framework, fast, concurrent | Go devs, high-performance | Free | ✔ Native |
| PySpider | Python, web UI, scheduling, distributed | Teams, multiple projects | Free | ✔ Native |
| WebHarvy | Visual, pattern detection, one-time license | Beginners, solo pros | ~$139 one-time | ◐ Wine/VM |
| OutWit Hub | Native GUI, auto-detects data, scripting | Non-coders, desktop GUI | Free, Pro $50–$100 | ✔ Native |
| Portia | Open-source, visual, browser-based | Open-source, Scrapy integration | Free | ✔ Browser |
| Content Grabber | Enterprise, visual, scripting, multi-agent | Agencies, large teams | $$$, from $69/mo | ◐ Wine/VM |
| Helium | Python, simplified Selenium, intuitive API | Python users, quick automation | Free | ✔ Native |
| Dexi.io | Cloud, visual workflow, scheduling, API | Enterprise, scalable automation | From $119/mo | ✔ Browser |
How to Choose the Right Web Scraper for Linux: Key Considerations
Picking the right tool is all about matching your needs and skills:
- Technical Skill Level: Non-coders should lean toward Thunderbit, ParseHub, Octoparse, or OutWit Hub. Developers can unlock more power with Scrapy, Puppeteer, Colly, or Kimurai.
- Data Complexity: For static pages, Beautiful Soup or Colly are fast and simple. For dynamic, JavaScript-heavy sites, you’ll want Selenium, Puppeteer, or a visual tool that supports JS.
- Scale & Frequency: For one-off jobs, no-code tools or cloud scrapers are fine. For scheduled, large-scale crawls, go with Scrapy, PySpider, or Apify.
- Integration Needs: Need to export to Excel, Sheets, or a database? Make sure your tool supports your workflow.
- Budget: Free and open-source options abound for coders. For business users, Thunderbit and ParseHub offer affordable entry points, while enterprise teams might invest in Dexi.io or Content Grabber.
- Support & Community: Open-source tools have big communities; commercial tools offer dedicated support.
Pro tip: Don’t be afraid to combine tools. Use Thunderbit to prototype and identify data patterns, then switch to Scrapy for production-scale crawls. Or use Selenium to log in and grab session cookies, then hand off to Colly or Scrapy for high-speed scraping.
Conclusion: Find Your Best Linux Web Scraping Tool for 2026
Linux users are spoiled for choice in 2026. Whether you want a no-code, AI-powered tool that gets you results in minutes (Thunderbit), a robust developer framework (Scrapy, Colly), or an enterprise-grade platform (Dexi.io), there’s a web scraper for Linux that fits your needs and your workflow.
Key takeaways:
- Linux is the backbone of modern data infrastructure—most top scrapers run natively or via browser.
- AI and no-code tools are democratizing web scraping for business users.
- Developer frameworks still rule for flexibility, speed, and scale.
- Try before you buy—most tools offer free tiers or trials.
Ready to get started? or check out the for more guides on web scraping, automation, and data-driven growth.
FAQs
1. What’s the easiest web scraper for Linux if I don’t know how to code?
is the top pick for non-technical users. It runs as a Chrome extension on Linux, uses AI to automate everything, and lets you scrape data in just two clicks.
2. Which Linux web scraper is best for large-scale, custom projects?
is the go-to for developers. It’s fast, scalable, and highly customizable—perfect for big, recurring crawls.
3. Can I scrape JavaScript-heavy or dynamic sites on Linux?
Yes! Use or to control real browsers and extract dynamic content. Visual tools like ParseHub and Thunderbit also support dynamic sites.
4. Are there free Linux web scraping tools for business use?
Absolutely. Scrapy, Beautiful Soup, Selenium, Colly, PySpider, and Kimurai are all free and open-source. Thunderbit and ParseHub offer free tiers for smaller jobs.
5. How do I choose between no-code and code-based Linux scrapers?
If you want speed and simplicity, go no-code (Thunderbit, ParseHub, Octoparse). If you need flexibility, automation, or integration with other systems, code-based tools (Scrapy, Puppeteer, Colly) are your best bet.
Happy scraping—and may your Linux-powered data projects run smoother than a fresh Ubuntu install. If you want to see more web scraping tips, check out the or subscribe to our for hands-on tutorials.
Learn More