Je CRM is maar zo sterk als de data die je erin stopt. En eerlijk: de beste data ligt vaak gewoon voor het oprapen op openbare websites — niet verstopt achter peperdure databanken van derden.
Met webextractors zet je die rommelige webdata om naar strakke spreadsheets. De goede tools doen dat in een paar minuten, zonder dat je ook maar één regel code hoeft te schrijven.
Ik heb deze tools gebruikt in echte projecten — van leadlijsten bouwen tot concurrentieprijzen volgen en complete productcatalogi verzamelen. Dit zijn de 12 die zich echt hebben bewezen, gerangschikt op hoe goed ze werken voor concrete zakelijke taken.
Waarom webextractors onmisbaar zijn voor bedrijven
Laten we het beestje bij de naam noemen: het web is de grootste (en meest chaotische) database ter wereld. En in 2026 lopen de bedrijven voorop die die chaos kunnen omzetten in inzichten. Volgens zijn datagedreven organisaties 5% productiever en 6% winstgevender dan vergelijkbare bedrijven. Dat is geen nice-to-have — dat is een keihard meetbaar voordeel.
Webextractietools (ook wel webpagina-extractors of webextractie-oplossingen genoemd) zijn hierbij de stille versneller. Ze helpen salesteams om openbare directories, social media en bedrijfswebsites te scrapen en zo gerichte prospectlijsten op te bouwen — zonder verouderde leadlijsten in te kopen of te hopen dat een stagiair niet halverwege een copy-paste-marathon afhaakt (). Marketing- en e-commerceteams gebruiken webextractors om concurrentieprijzen te volgen, voorraadniveaus te monitoren en producten realtime te benchmarken — John Lewis schrijft web scraping bijvoorbeeld een 4% omzetstijging toe, puur door slimmer te prijzen ().
Maar het draait niet alleen om KPI’s. Webextractors besparen bizar veel tijd (een gebruiker meldde “honderden uren” winst door dataverzameling te automatiseren) en verminderen menselijke fouten (). Operationele teams zetten tegenwoordig scrapers op die continu data binnenhalen waar stagiairs anders weken mee bezig zouden zijn — uren terugpakken die vroeger wegvloeiden in eindeloos kopiëren en plakken (). En met AI-gedreven extractors kunnen zelfs niet-technische gebruikers websites omzetten naar gestructureerde data voor analyse ().
Kortom: als je in 2026 geen webextractor gebruikt, laat je waarschijnlijk inzichten (en omzet) op tafel liggen.
Hoe we de top 12 webextractors selecteerden
Er zijn belachelijk veel tools voor webextractie. Dus: hoe prik je daar de juiste uit? Ik heb tientallen opties bekeken, maar slechts 12 haalden deze lijst. Dit waren mijn belangrijkste criteria:
- Gebruiksgemak: Kan iemand zonder technische achtergrond snel starten zonder code te schrijven? Ik gaf voorrang aan no-code of low-code tools met een intuïtieve interface ().
- AI-mogelijkheden: Nieuwe generatie tools die AI inzetten om scraping simpeler te maken — zoals automatisch velden herkennen, navigatie op sites afhandelen of je in gewone taal laten beschrijven wat je nodig hebt ().
- Automatisering & planning: De beste webextractors draaien lekker op de automatische piloot. Ik koos tools die periodieke scrapes of website-monitoring ondersteunen ().
- Export & integraties: Kun je makkelijk exporteren naar Excel, Google Sheets, Airtable of Notion? Extra punten voor workflow-integraties ().
- Schaalbaarheid en betrouwbaarheid: Of je nu één pagina scrapt of duizenden: deze tools moeten het aankunnen. Ik nam ook reviews mee om betrouwbaarheid te beoordelen.
- Zakelijke use-cases: Ik legde de nadruk op tools die populair zijn bij sales, marketing, e-commerce en operations — niet alleen bij developers.
Sommige tools zijn AI-nieuwkomers, andere zijn gevestigde namen. Ze hebben één ding gemeen: ze helpen je het web om te vormen tot je eigen bedrijfsdatabase — zonder gedoe.
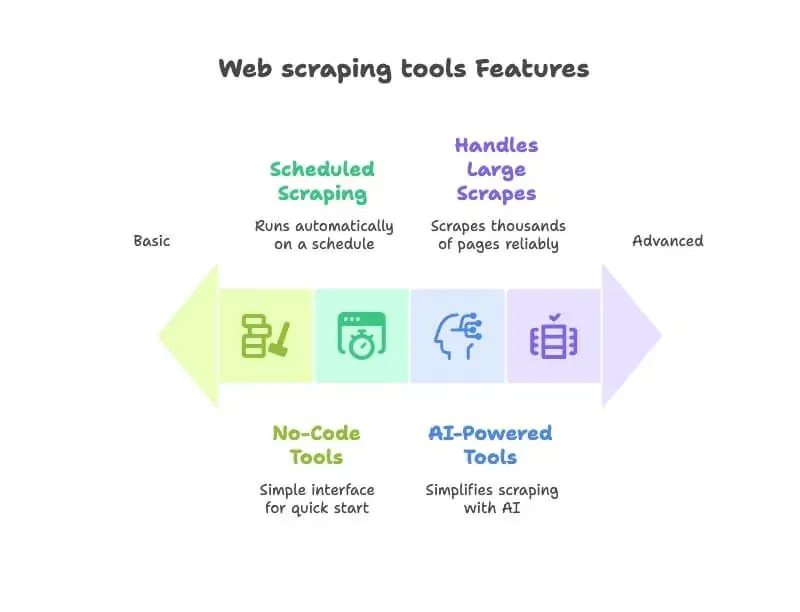
Snelle vergelijking: webextractor-tools in één oogopslag
Hier is een overzicht van de 12 webextractor-tools die ik bespreek, zodat je in één blik ziet hoe ze zich tot elkaar verhouden:
| Tool | AI-automatisering | Gebruiksgemak | Beste use-case |
|---|---|---|---|
| Thunderbit | Ja – AI stelt velden voor en verwerkt pagina’s automatisch | Zeer eenvoudig (Chrome-extensie, geen code) | Snel scrapen van leads, prijzen, enz. door niet-technische gebruikers die binnen minuten resultaat willen. |
| Octoparse | Beperkt (template-gedreven, geen AI) | Voor de meesten eenvoudig (visuele drag-and-drop) | Maatwerk scraping-workflows (met logins, paginering) voor analisten die controle willen zonder te programmeren. |
| Browse AI | Gedeeltelijk – point-and-click “robots” | Eenvoudig (no-code, cloud) | Geautomatiseerde monitoring van data (prijzen, listings, enz.) op schema, met alerts en integraties. |
| WebScraper.io | Nee (handmatige configuratie) | Gemiddeld (browserextensie met sitemap-instelling) | Visueel scrapen van websites met meerdere niveaus voor gebruikers die stappen willen configureren. |
| ScraperAPI | N.v.t. (API-service, regelt proxies via API) | Vereist code (API-integratie) | Webdata-extractie op grote schaal voor techteams — proxies & CAPTCHAs worden afgehandeld voor grootschalige scrapes. |
| Data Miner | Nee | Zeer eenvoudig (browserextensie met one-click templates) | Snelle eenmalige extractie van pagina’s (vooral tabellen of lijsten) direct naar CSV/Excel. |
| Simplescraper | Nee (wel enkele AI-ondersteunde functies) | Eenvoudig (point-and-click recipe builder) | No-code scraping met integraties — ideaal om webdata naar Google Sheets, Airtable of een API te sturen. |
| Instant Data Scraper | Ja – detecteert automatisch datatabellen | Zeer eenvoudig (klik en klaar, geen setup) | Direct gratis scrapen van HTML-tabellen en lijsten voor iedereen (perfect voor snelle datagrabs). |
| ScrapeStorm | Ja – AI herkent pagina-elementen | Eenvoudig (visuele interface; cross-platform app) | Grootschalige of complexe scrapingprojecten zonder code, inclusief geplande crawls. |
| Apify | Enigszins – kant-en-klare “actor”-bots beschikbaar | Gemiddeld (webinterface; code optioneel) | Schaalbare cloud scraping en automatisering via kant-en-klare of custom scripts. |
| ParseHub | Nee (zonder scripts, maar wel handmatige setup) | Eenvoudig voor basisgebruik (visuele editor; desktop app) | Scrapen van dynamische of complexe sites (AJAX-content) via een no-code interface. |
| OutWit Hub | Nee | Eenvoudig (desktop GUI-app) | Simpele, offline data-extractie en content-archivering voor kleinere projecten. |
De meeste tools bieden een gratis versie of proefperiode en werken met abonnementsniveaus. De focus ligt hier op mogelijkheden en use-cases, niet op prijs.
Thunderbit: de AI-webextractor voor iedereen

We trappen af met Thunderbit — ja, dat is mijn eigen product, maar blijf even hangen. De webextractie-wereld schuift op van “bouw je scraper zelf” naar “vertel de AI gewoon wat je wil hebben.” Thunderbit is de eerste tool die ik heb gezien (en mee heb gebouwd) die echt voelt als een AI-data-assistent in plaats van wéér een zoveelste “crawler”.
Met hoef je niet te hannesen met XPath, CSS-selectors of regex. Je zegt gewoon in normale mensentaal welke data je wilt — bijvoorbeeld “pak de titel, auteur en datum van deze pagina” — en Thunderbit’s AI fixt de rest (). Klik op “AI Suggest Fields” en Thunderbit leest de pagina, stelt kolommen voor en verwerkt zelfs subpagina’s en paginering automatisch ().
En het blijft niet bij “alleen ophalen”. Thunderbit kan tijdens het scrapen velden opschonen, transformeren, categoriseren en zelfs vertalen. Telefoonnummers normaliseren, beschrijvingen samenvatten of productnamen vertalen? Zet er een korte instructie bij en de AI doet het. Daarna exporteer je direct naar Excel, Google Sheets, Airtable of Notion ().
Wat Thunderbit echt anders maakt, is nul gedoe en bijna geen leercurve. Het is een Chrome-extensie, dus je bent binnen seconden onderweg. Geen plugins, geen ingewikkelde configuratie, geen technisch geneuzel. Daarom is het populair bij sales-, marketing- en operationele teams die snel output nodig hebben (). Met de gratis versie kun je de hele workflow testen, en de betaalde plannen zijn voor de meeste teams gewoon prima te doen.
Wil je voelen hoe AI-webextractie in het echt werkt? Download dan de en probeer het zelf. Grote kans dat je copy-paste-tijdperk dan echt voorbij is.
Octoparse: visuele webextractor voor maatwerk-workflows
Octoparse is een klassieker in de wereld van visueel webscrapen. Het is een desktopapp met een point-and-click interface: je klikt op de webpagina, selecteert de data die je wilt, en Octoparse bouwt achter de schermen je workflow (). Je kunt logins afhandelen, paginering instellen en zelfs formulieren automatisch laten invullen — zonder code.
Een groot pluspunt is de bibliotheek met 500+ kant-en-klare templates voor populaire sites (Amazon, Twitter, LinkedIn, enz.), waardoor je vaak meteen kunt starten (). Voor ingewikkeldere sites schakel je naar handmatige modus en zet je elke stap visueel neer. Octoparse kan content scrapen die pas na klikken of scrollen verschijnt, en ondersteunt proxies en CAPTCHA-oplossingen voor de taaie gevallen. Er is ook een cloudoptie voor planning en grotere runs.
De keerzijde: je hebt wel wat leercurve, vooral bij geavanceerde scenario’s. Maar voor niet-programmeurs en data-analisten die een maatwerk scraping-workflow willen zonder te coderen, is Octoparse een hele solide keuze ().
Browse AI: geautomatiseerde webextractie met kant-en-klare robots
Browse AI pakt het lekker laagdrempelig aan: je “traint” een robot door te klikken op de data die je wilt, en die leert vervolgens dezelfde data van vergelijkbare pagina’s te halen (). Alles draait in de cloud en is no-code, dus je hoeft geen scripts of servers te beheren.
Waar Browse AI echt in uitblinkt, is automatisering en monitoring. Je plant robots op vaste momenten en krijgt meldingen als data verandert (bijvoorbeeld wanneer een concurrent een prijs verlaagt of er een nieuwe vacature live gaat). Daarnaast is er een bibliotheek met vooraf gebouwde robots voor veelvoorkomende taken — vaak start je met iets kant-en-klaars en schaaf je het daarna bij ().
Browse AI integreert met duizenden apps via Zapier en Make, en exporteert direct naar Google Sheets of via API/webhooks (). Ideaal voor doorlopende monitoring en terugkerende dataverzameling, zeker als je hands-off alerts en integraties wilt.
WebScraper.io: browsergebaseerde webpagina-extractor

WebScraper.io (vaak gewoon “Web Scraper” genoemd) is een browserextensie waarmee je “sitemaps” bouwt: visuele routes die bepalen hoe je door een website navigeert en welke elementen je eruit trekt (). Je definieert selectors voor de data en de links die gevolgd moeten worden (zoals “klik op volgende pagina” of “open elke productpagina voor details”).
Er zit wat leercurve in, maar je schrijft geen code — je selecteert elementen en stelt acties in. Web Scraper ondersteunt navigatie over meerdere niveaus, paginering en zelfs infinite scroll (al moet je die stappen wel zelf uittekenen). Omdat het in je browser draait, kun je ook sites achter een login scrapen door zelf in te loggen.
WebScraper.io is ideaal voor ‘citizen data analysts’ die zich thuis voelen in webstructuren en een gratis, flexibele tool zoeken. Een betrouwbare werkpaard-optie, zolang je bereid bent je eigen sitemaps op te zetten.
ScraperAPI: API-first webextractor voor developers en teams
Niet elk team zit te wachten op point-and-click — soms wil je gewoon een backend-oplossing die webdata direct je apps of databases in duwt. ScraperAPI is een API-first webextractor: jij geeft een URL door en krijgt ruwe HTML of geëxtraheerde data terug, terwijl ScraperAPI de lastige stukken afhandelt zoals proxies, geografische IP-rotatie, headless browsers en CAPTCHAs ().
ScraperAPI beheert een pool van 40 miljoen+ proxies in 50+ landen en verwerkt 36 miljard requests per maand (). Het is vooral geschikt voor grootschalige, geautomatiseerde scraping waarbij betrouwbaarheid en anti-blocking cruciaal zijn. Je hebt wel programmeerkennis nodig, maar voor datapipelines of productintegraties is ScraperAPI een topkeuze.
Data Miner: Chrome-extensie voor snelle webpagina-extractie
Data Miner is een Chrome-extensie voor zakelijke gebruikers en onderzoekers die snel data willen binnenhalen. Je krijgt een point-and-click ervaring plus een bibliotheek met kant-en-klare scraping ‘recepten’ voor patronen zoals tabellen, lijsten of specifieke sites ().
Je installeert de extensie, gaat naar de pagina en klikt op het Data Miner-icoon. Kies een recept of maak er zelf één door elementen te selecteren. Perfect voor eenmalige taken of snelle databehoeften — denk aan sales die leads uit een directory trekt of e-commerce die concurrentieprijzen overneemt.
Data Miner is simpel, zit in je browser en is ideaal voor interactief, on-demand scrapen.
Simplescraper: no-code webextractor voor snelle resultaten
Simplescraper doet precies wat de naam belooft. Het is een no-code Chrome-extensie (en webapp) waarmee je visueel data selecteert en zo een “recept” bouwt voor extractie (). Je kunt links volgen om subpagina’s te scrapen, paginering afhandelen en je scrape met één klik omzetten naar een API-endpoint.
Waar Simplescraper echt punten scoort, zijn de integraties: stuur data direct naar Google Sheets, Airtable of tools zoals Zapier (). Er is ook cloud scraping en planning voor terugkerende jobs, plus “AI Enhance” om data met GPT op te schonen of te analyseren.
Als je snel resultaat en makkelijke koppelingen zoekt, is Simplescraper een soort Zwitsers zakmes voor lichte webscraping.
Instant Data Scraper: razendsnelle extractie voor tabellen en lijsten
Soms wil je data gewoon nu, zonder setup. Daar is Instant Data Scraper (IDS) voor. Het is een gratis Chrome-extensie die bekendstaat om one-click scraping van tabulaire data (). Je zet de extensie aan en IDS herkent automatisch tabellen of lijsten op de pagina. Het kan zelfs paginering en infinite scroll afhandelen door automatisch door te klikken.
IDS is 100% gratis, zonder account, zonder code, zonder wachttijd. Ideaal voor casuele of urgente scraping — zoals snel een leadlijstje voor sales of data uit Wikipedia-tabellen voor studie. Als IDS je data ziet, heb je die binnen seconden.
ScrapeStorm: cloudgebaseerde webextractor met AI-ondersteuning
ScrapeStorm is een AI-gedreven webscrapingtool die een visuele interface combineert met stevige AI-algoritmes (). Je voert een URL in en de AI herkent automatisch datavelden — lijsten, tabellen, knoppen voor volgende pagina’s en meer.
ScrapeStorm werkt cross-platform (Windows, Mac, Linux) en biedt zowel desktop- als cloud scraping. Je kunt taken plannen, meerdere jobs parallel draaien en exporteren naar Excel, CSV, JSON of zelfs uploaden naar een database (). Het is populair voor e-commerce en marktonderzoek, en kan met AI zelfs data uit afbeeldingen of PDF’s halen.
Voor grootschalige of complexe scrapingprojecten waarbij je een slimme assistent wilt, is ScrapeStorm zeker het bekijken waard.
Apify: webextractor-marktplaats en automatiseringsplatform

Apify is niet alleen een scraper — het is een platform voor webscraping en automatisering. Je draait er “actors”: scripts voor scraping of browserautomatisering. De echte kracht zit in Apify’s marktplaats met kant-en-klare actors voor veelvoorkomende taken (). Reviews van een webshop scrapen? Grote kans dat er al een actor voor bestaat.
Voor developers biedt Apify de mogelijkheid om eigen scrapers in Node.js of Python te schrijven en in de cloud te deployen. Het is schaalbaar, automatiseerbaar en via API te integreren. Apify past het best bij power users en organisaties die webdata als kernresource zien — denk aan doorlopende, grootschalige scraping of integratie in datapipelines.
ParseHub: visuele webpagina-extractor voor complexe sites

ParseHub is een desktopapp (met cloudopties) die bekendstaat om het scrapen van complexe, dynamische websites. Je navigeert door een site in een browserachtige omgeving, klikt op datapunten en ParseHub bouwt je scraper (). Het ondersteunt conditionele logica, geneste scraping, AJAX-content en meer.
ParseHub is vaak de tool die je pakt wanneer andere tools een site niet netjes te pakken krijgen. Het wordt gebruikt door onderzoekers, analisten en mkb’ers die lastige websites moeten aanpakken. Er is een leercurve, maar als je een complexe site wilt scrapen zonder te coderen, is ParseHub een sterke optie.
OutWit Hub: desktop webextractor voor content-archivering

OutWit Hub is wat old-school, maar het is een desktopapplicatie die heel sterk is in het verzamelen van allerlei soorten content (links, afbeeldingen, e-mailadressen, enz.) en het netjes organiseren ervan (). Het werkt als een mix van browser en spreadsheet: je bezoekt een pagina en OutWit Hub kan tabellen, lijsten, afbeeldingen en meer extraheren.
Handig voor onderzoek of content-archivering — bijvoorbeeld alle posts uit een forum trekken of een set bestanden downloaden. Omdat het lokaal draait, houd je je data in eigen beheer. OutWit Hub is het meest geschikt voor kleine tot middelgrote scrapingklussen waarbij je een duidelijke desktopinterface wilt.
Welke webextractor past het best bij jouw situatie?
Twaalf tools, eindeloos veel scenario’s. Welke moet je pakken? Dit is mijn spiekbriefje:
-
Voor absolute beginners of snelle eenmalige taken:
Probeer Instant Data Scraper voor simpele tabellen en lijsten (gratis en direct). Data Miner is ook laagdrempelig en heeft meer templates als je vaker vergelijkbare pagina’s scrapt.
-
Voor niet-technische teams met terugkerende scraping of integraties:
Thunderbit biedt de soepelste workflow dankzij de AI-aanpak — ideaal voor business users die vaak en snel resultaat willen. Browse AI is perfect voor doorlopende monitoring en alerts. Simplescraper is sterk als je data automatisch naar Google Sheets of een interne app wilt laten stromen via een API.
-
Voor complexe websites of maatwerk-workflows zonder code:
Ga voor een visuele scraper zoals Octoparse of ParseHub. Octoparse is toegankelijk en heeft veel templates. ParseHub kan extreem complexe dynamische sites aan en geeft veel controle. WebScraper.io is ook een goede optie als je je eigen sitemaps wilt configureren.
-
Voor developers of data engineers die schaal nodig hebben:
ScraperAPI is gemaakt om webscraping in software te embedden of grootschalige projecten te draaien. Apify is ideaal als je een schaalbaar platform wilt met een marktplaats voor kant-en-klare of custom scripts.
-
Voor content-zware extractie of offline gebruik:
OutWit Hub is een goede keuze om content systematisch te verzamelen en te archiveren, vooral als je een desktoptool wilt voor privacy of controle.
In de praktijk gebruiken veel teams meerdere tools, afhankelijk van de klus. Je begint misschien met Instant Data Scraper voor iets simpels, schakelt over naar Thunderbit of Octoparse voor een groter project, en gebruikt ScraperAPI of Apify wanneer je het proces echt wilt industrialiseren. Het mooie is: de meeste tools hebben een gratis versie of trial, dus je kunt rustig uitproberen wat bij je past.
Conclusie: de toekomst van webextractie voor business teams
Webextractietools hebben enorme sprongen gemaakt. In 2026 zijn ze volledig mainstream. De belangrijkste trend? Webscraping wordt makkelijker, meer geautomatiseerd en beter ingebed in dagelijkse workflows (). Dankzij AI-scrapers kun je zelfs complexe, dynamische websites aanpakken zonder specialistische kennis. Zoals een data engineer het verwoordde: “Toen AI-webscrapingtools op de markt kwamen, kon ik taken veel sneller en op grotere schaal afronden... met AI zit [data cleaning] automatisch in mijn workflow.”
Een tweede verschuiving: de grenzen tussen scrapen, monitoren en automatiseren vervagen. Tools zoals Browse AI en Thunderbit halen niet alleen data op, maar houden die ook actueel en kunnen zelfs acties uitvoeren (zoals formulieren invullen of alerts triggeren). De groei is duidelijk: een groot platform zag het aantal maandelijkse actieve gebruikers in één jaar met meer dan 140% stijgen (). Bedrijven van elke omvang snappen dat toegang tot openbare webdata (ethisch en legaal) essentieel is om competitief te blijven.
Voor business teams is de kernboodschap zelfredzaamheid. Je hoeft niet weken te wachten op een developer of beslissingen te nemen op onderbuikgevoel. De tools in deze lijst geven je directe toegang tot webdata, met interfaces en functies die passen bij echte use-cases in sales, marketing, operations en meer. En met hoe snel dit veld beweegt, verwacht ik binnenkort nog gebruiksvriendelijkere interfaces, slimmere AI en diepere integraties met BI- en analyticsplatformen.
Let wel: respecteer de gebruiksvoorwaarden van websites en de regels in robots.txt, en zorg dat je voldoet aan privacywetgeving. Ethisch scrapen is belangrijk als je dit duurzaam wilt blijven doen.
Of je nu start met een gratis extensie of een enterprise scraping-setup uitrolt: er is eigenlijk nooit een beter moment geweest om webinformatie om te zetten in actiegerichte inzichten. De webextractor-revolutie is begonnen — kies een tool, probeer het uit en haal waarde uit data die letterlijk voor het oprapen ligt. Je datagedreven toekomst is maar één klik weg.
Veelgestelde vragen
1. Wat is een webextractor en waarom is het belangrijk voor bedrijven?
Een webextractor is een tool die automatisch gestructureerde data van websites verzamelt. Het is belangrijk omdat je hiermee chaotische online informatie omzet in bruikbare inzichten — met hogere productiviteit, meer winst en zonder handmatige dataverzameling.
2. Wie kan webextractors gebruiken — heb ik technische kennis nodig?
Voor veel moderne webextractors heb je geen technische skills nodig. Tools zoals Thunderbit, Browse AI en Instant Data Scraper zijn gemaakt voor niet-technische gebruikers, met intuïtieve interfaces, AI-automatisering en no-code workflows.
3. Hoe profiteren sales-, marketing- en operationele teams van webextractors?
Sales kan leadlijsten opbouwen uit online directories, marketing kan concurrentieprijzen volgen en operations kan dataverzameling automatiseren. Dit bespaart tijd, vermindert fouten en levert actuele, betrouwbare inzichten voor betere beslissingen.
4. Waar moet ik op letten bij het kiezen van een webextractor?
Let op gebruiksgemak, AI-functies, automatisering/planning, integraties met tools zoals Google Sheets of Airtable, schaalbaarheid en of de tool past bij jouw use-case (bijv. sales leads, prijsmonitoring, content-archivering).
5. Bestaan er gratis of goedkope webextractors?
Ja. Veel webextractors hebben een gratis versie of betaalbare plannen. Instant Data Scraper is volledig gratis voor basisbehoeften, terwijl Thunderbit, Simplescraper en Data Miner ruime gratis plannen bieden met upgrade-opties.
Meer leren over webextractie, AI-scraping of hoe je websites omzet in een voordeel voor je team? Bekijk de voor extra gidsen, tips en praktijkverhalen uit de wereld van data-automatisering.