

Temu bereikt inmiddels meer dan 416 miljoen maandelijks actieve gebruikers verspreid over ruim 50 markten. De productcatalogus loopt uiteen van keukenhulpjes en accessoires voor huisdieren tot ledstrips. Als je actief bent in ecommerce, dropshipping of competitive intelligence, heb je waarschijnlijk al eens Temu-data in een spreadsheet willen zetten — en daarna ontdekt dat Temu daar liever geen medewerking aan verleent.
Ik heb veel tijd gestoken in het onderzoeken en testen van scrapingtools voor beveiligde ecommerce-sites. Temu is echt een van de lastigste targets. De meeste online gidsen geven je óf een Python-tutorial die binnen een week stukgaat, óf verwijzen je door naar enterprise-API’s die duurder zijn dan je maandelijkse advertentiebudget.
De realiteit is dat de meeste zakelijke gebruikers — dropshippers, solopreneurs, marketingteams — gewoon een nette spreadsheet willen met productnamen, prijzen, afbeeldingen, reviews en verkopersinformatie. Ze hebben geen behoefte aan het debuggen van Playwright-scripts om 2 uur ’s nachts.
Deze gids vult precies dat gat: een praktische, op vaardigheidsniveau ingedeelde analyse van de beste Temu-scrapers die in 2026 echt werken, plus de best practices die van een losse scrape doorlopende competitive intelligence maken. Of je nu helemaal nieuw bent of een ontwikkelaar die een datapipeline bouwt, hier vind je iets bruikbaars.
Probeer Thunderbit voor Temu-scraping
Waarom Temu scrapen? Topgebruikssituaties voor zakelijke teams
Temu-data is niet alleen interessant — ze is strategisch waardevol.
Het platform is een prijsbepalende factor geworden in productcategorieën met lage en middelhoge ticketprijzen. Ook als je niet op Temu verkoopt, vergelijken klanten jouw prijzen met wat ze daar zien. Zo gebruiken verschillende teams Temu-data:
| Gebruikssituatie | Benodigde gegevens | Waarom het belangrijk is |
|---|---|---|
| Productonderzoek voor dropshipping | Titel, prijs, afbeelding, beoordeling, aantal reviews, aantal verkochte items, varianten | Vindt goedkope producten met vraagsignalen voor vergelijking over Amazon, Shopify, AliExpress en TikTok Shop heen |
| Concurrerende prijsstrategie | Huidige prijs, originele prijs, korting %, valuta, verzending, tijdstempel | Bouwt een basislijn voor prijsstrategie en promotieplanning |
| Product sourcing | Specificaties, afbeeldingen, varianten, verkoper/winkel, item-ID, categorie | Brengt producttypen en supplier-achtige listings in kaart die extra verificatie waard zijn |
| Analyse van markttrends | Zoekwoord, categorie, aantal verkochte items, aantal reviews, beoordeling | Laat zien welke producten in verschillende categorieën terrein winnen |
| Marketing- en creatieonderzoek | Titel, afbeelding, aantal reviews, beoordeling, beschrijvingen, categorielabels | Onthult messaging, visuele haakjes, bundels en claims die worden gebruikt door listings met veel volume |
| Voorraad- en beschikbaarheidsmonitoring | Product-URL, beschikbaarheid, geschatte verzendtijd, prijs, tijdstempel | Legt voorraadtekorten, wijzigingen in lokale magazijnen en prijsbewegingen vast in de tijd |
Het publiek dat zoekt op “beste Temu-scrapers” valt meestal uiteen in drie groepen. Niet-technische gebruikers willen een Chrome-extensie die een spreadsheet oplevert. Half-technische operators willen een visuele tool met sjablonen en planning. Ontwikkelaars willen een API, een Playwright-script en een proxystrategie.
Dit artikel behandelt ze alle drie — maar begint bij de grootste groep: mensen die data nodig hebben, geen code.
Wat de beste Temu-scrapers in 2026 onderscheidt
Een scraper die Amazon of Shopify aankan, overleeft Temu niet per se. De evaluatiecriteria voor dit artikel zijn:
- Betrouwbaarheid op Temu — Levert de tool echt schone data op, of wordt hij geblokkeerd, geeft hij lege rijen terug of valt hij uit na een layoutwijziging?
- Gebruiksgemak — Kan een niet-technische zakelijke gebruiker beginnen zonder code te schrijven?
- Volledigheid van data — Ondersteunt de tool subpage-enrichment (elke productdetailpagina bezoeken voor specificaties, varianten en verkopersinformatie)?
- Onderhoudslast — Past de tool zich aan wanneer Temu de pagina-opbouw wijzigt?
- Planning en monitoring — Kan hij terugkerende scrapes uitvoeren en exporteren naar een live datadoel?
- Exportbestemmingen — CSV, Excel, Google Sheets, Airtable, Notion, JSON?
- Kosteninzicht — Wat kost een realistische Temu-scrapingworkflow nu eigenlijk per maand?
Communitymeldingen op Reddit's r/webscraping beschrijven Temu consequent als een van de moeilijkste ecommerce-sites om te scrapen. Een gebruiker schreef dat hij “zelfs als koper geen prijs kan ophalen”, terwijl een ander opmerkte dat Temu en Shopee teams inzetten die anti-botmechanismen voortdurend versterken. Er zijn geen publieke benchmarkgegevens specifiek voor Temu-failures, maar het Imperva Bad Bot Report 2025 liet zien dat geautomatiseerd verkeer menselijk verkeer voorbijstreefde, waarbij bots goed waren voor 51% van al het internetverkeer. Dat is de omgeving waar Temu zich tegen verdedigt.
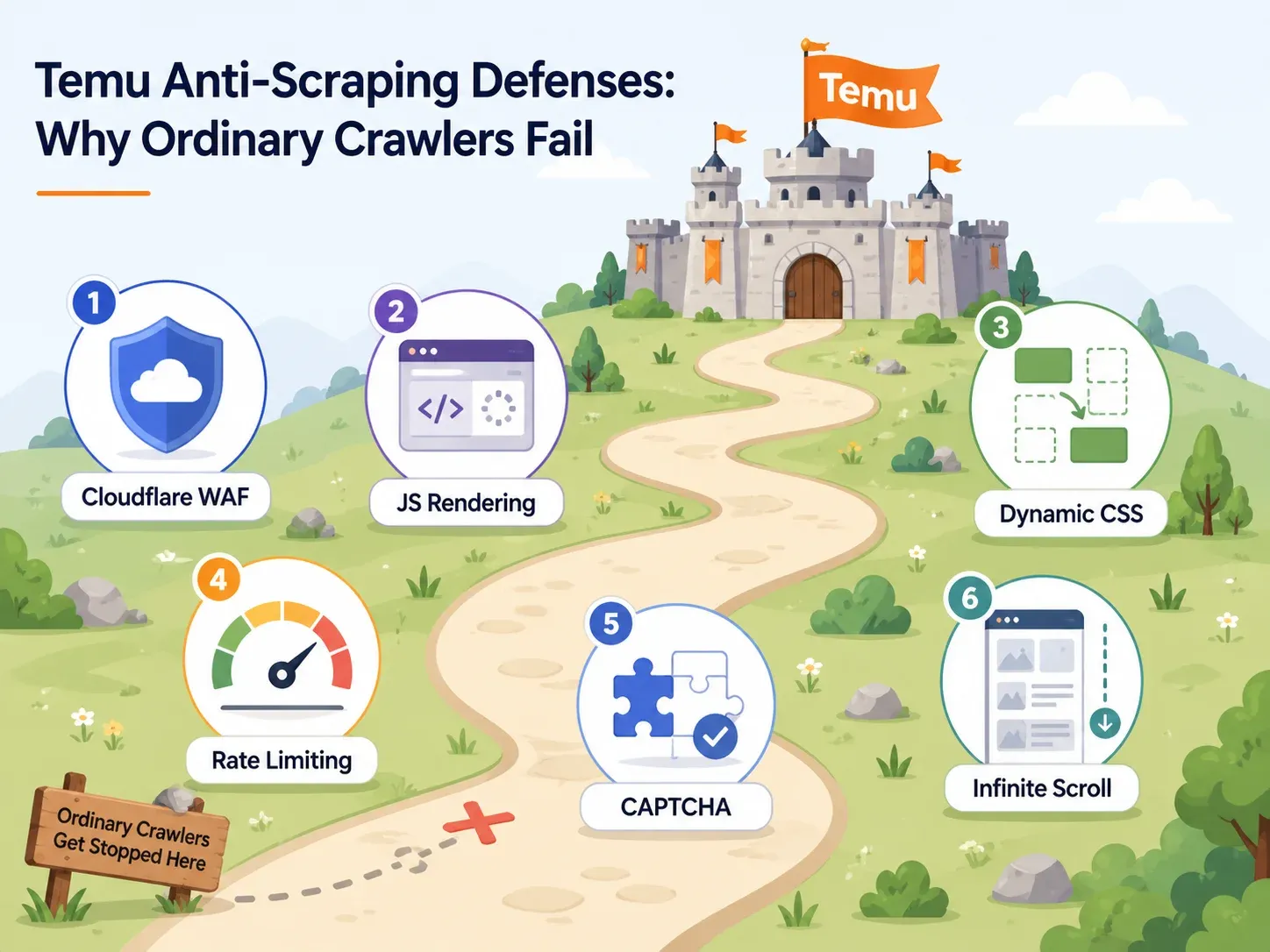
Temu’s anti-botverdediging: waarom de meeste scrapers falen
De meeste artikelen over Temu-scraping besteden één zin aan anti-botmaatregelen: “Temu gebruikt anti-bot.” Daar heb je niet veel aan.
Als je een tool kiest, moet je weten welke verdedigingen Temu gebruikt en welke mogelijkheden van een tool daartegen werken. Dit is de praktische kaart:
| Temu-verdediging | Wat het doet | Benodigde toolcapaciteit | Voorbeeldtools |
|---|---|---|---|
| Cloudflare WAF / browserchecks | Blokkeert geautomatiseerde user-agents, herkent bot-fingerprints, geeft challenge-pagina’s terug | Cloudinfrastructuur met roterende residential IP’s en echte browser-fingerprints | Thunderbit (cloudscraping), Bright Data, Oxylabs, ScraperAPI |
| Zware JavaScript-rendering | Productdata wordt via JS geladen; ruwe HTML is leeg | Headless browser of volledige browser-rendering | Thunderbit (browser scrape-modus), Playwright, Selenium, ParseHub, Apify browser actors |
| Dynamische CSS-selectors | Class-namen veranderen tussen deployments, waardoor CSS-gebaseerde scrapers stukgaan | AI-gebaseerde veldherkenning (niet afhankelijk van vaste selectors) | Thunderbit (AI leest de pagina elke keer vers), Bright Data AI scraper builder |
| Rate limiting | Tempert snelle opeenvolgende verzoeken | Gelijktijdige cloudverzoeken met slimme throttling | Thunderbit (tot 50 pagina’s tegelijk via cloud), ScraperAPI, Bright Data |
| CAPTCHA-uitdagingen | Onderbreekt sessies na verdacht gedrag | Ingebouwde CAPTCHA-oplossing of een strategie met minder triggers | Bright Data, Oxylabs, ScraperAPI premium/ultra-premium |
| Oneindig scrollen / lazy loading | Alleen de eerste producten verschijnen zonder interactie | Slim scrollen, detectie van paginering, automatisering van interacties | Thunderbit-paginering, Apify smart scrolling, Octoparse workflow builder |
Cloudflare WAF en IP-blokkering
De voordeur van Temu wordt bewaakt door browser-integriteitschecks in de stijl van Cloudflare. Basis-HTTP-verzoeken — het soort dat een simpele Python requests.get()-aanroep doet — krijgen een challenge, worden 403’en of leveren onvolledige data op.
Tools die hier werken, hebben roterende residential- of mobiele IP’s en echte browser-fingerprints nodig. Cloudflare’s Radar review van 2025 meldde dat niet-AI-bots begin 2025 verantwoordelijk waren voor ongeveer de helft van de HTML-paginaverzoeken. Dat is de schaal van automatisering waar platforms zoals Temu zich tegen wapenen.
JavaScript-rendering en dynamische selectors
Hier gaan de meeste beginnende scrapers stilletjes onderuit.
Als je de broncode van Temu bekijkt, zie je vaak een lege huls — de echte productkaarten, prijzen en afbeeldingen worden na het laden van de pagina via JavaScript ingeladen. Een scraper die alleen ruwe HTML leest, levert dan niets bruikbaars op. Daarbovenop veranderen Temu’s CSS-classnamen en DOM-structuren tussen deployments. Een scraper die vertrouwt op een vaste CSS-selector zoals .product-card__price werkt vandaag en geeft morgen lege kolommen terug.
AI-gebaseerde scrapers (zoals Thunderbit) lezen de pagina elke keer semantisch, dus ze zijn niet afhankelijk van het feit dat specifieke class-namen hetzelfde blijven.
Rate limiting en CAPTCHA-uitdagingen
Ga je Temu te snel of te vaak vanaf één IP aanspreken, dan activeer je rate limits of CAPTCHA-uitdagingen. Sommige tools pakken dit aan met slimme throttling en ingebouwde CAPTCHA-oplossing. Andere laten het aan jou over — wat voor een niet-technische gebruiker in feite een doodlopende weg is.
Bij cloudscraping is de sleutel: gelijktijdige verzoeken verspreid over schone IP’s, met automatische retry-logica.
Beste Temu-scrapers per vaardigheidsniveau: een complete uitsplitsing
Vind je rij en ga direct naar het passende onderdeel:
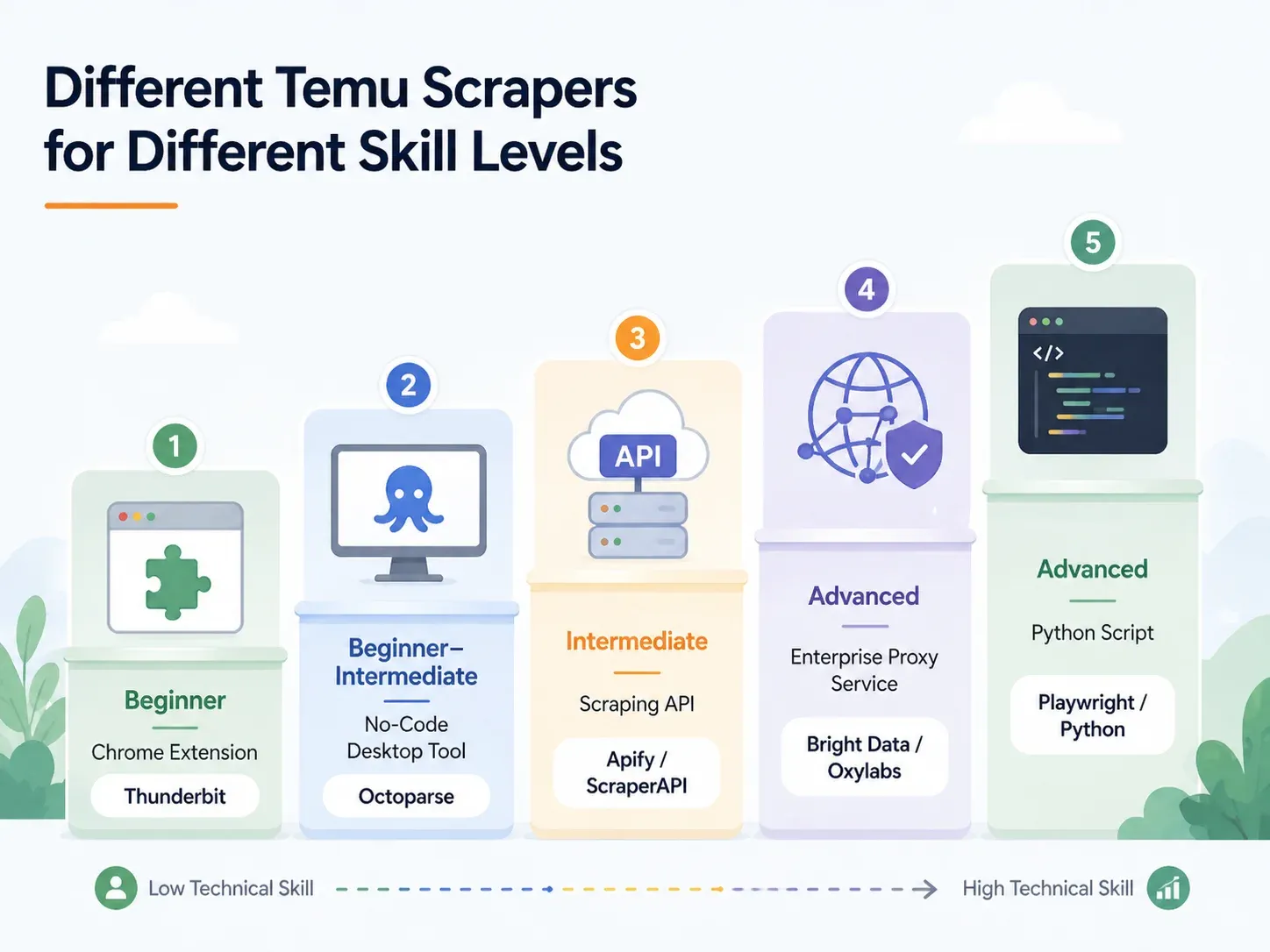
| Aanpak | Vaardigheidsniveau | Insteltijd | Anti-botafhandeling | Het beste voor |
|---|---|---|---|---|
| AI Chrome-extensie (bijv. Thunderbit) | Beginner | < 2 min | Afgehandeld (cloud of browser) | Dropshippers, marketeers, ecommerce-operations |
| No-code desktoptool (bijv. Octoparse, ParseHub) | Beginner–Gemiddeld | 10–60 min | Gedeeltelijk (proxyconfiguratie nodig) | Regelmatige scraping met sjablonen |
| Scraping-API/-service (bijv. ScraperAPI, Apify) | Gemiddeld | 15–45 min | Ingebouwd | Ontwikkelaars die integreren in pipelines |
| Managed proxy/enterprise (bijv. Bright Data, Oxylabs) | Gevorderd/Enterprise | Uren–dagen | Volledige infrastructuur | Hoge volumes, levering naar warehouse |
| Aangepast Python-script (Playwright/Selenium) | Gevorderd | 1–4 uur+ | Handmatig (proxy + CAPTCHA-instelling) | Volledige controle, maatwerk voor uitzonderingsgevallen |
Thunderbit: beste Temu-scraper voor niet-technische gebruikers
Thunderbit is een AI-gedreven Chrome-extensie, gebouwd voor zakelijke gebruikers — salesteams, ecommerce-operators, dropshippers, marketeers — die gestructureerde data van websites nodig hebben zonder code te schrijven. Ik werk bij het Thunderbit-team, dus ik ken het product goed. Ik ben eerlijk over wat het doet en waar het past.
De kernworkflow bestaat uit twee klikken: open een Temu-pagina, klik op AI Suggest Fields, bekijk de voorgestelde kolommen (productnaam, prijs, afbeelding, beoordeling, enz.), en klik daarna op Scrape.
Thunderbit’s AI leest de paginastructuur en stelt automatisch kolomnamen en gegevenstypen voor. Het vertrouwt niet op vaste CSS-selectors, dus wanneer Temu de class-namen of de indeling van kaarten wijzigt, past de scraper zich aan.
Belangrijkste functies voor Temu:
- Cloudscrape-modus: Sneller voor openbare pagina’s, verwerkt tot 50 pagina’s tegelijk. Het beste voor categoriepagina’s, zoekresultaten en productoverzichten waarvoor geen login nodig is.
- Browser-scrape-modus: Gebruikt je huidige Chrome-sessie, inclusief cookies, landinstellingen en inlogstatus. Het beste wanneer regio, pop-ups of ingelogde content bepalen wat de pagina toont.
- Scrape Subpages: Na het scrapen van een overzichtspagina klik je op “Scrape Subpages” om elke productdetailpagina te bezoeken en kolommen toe te voegen zoals volledige beschrijving, varianten, verkopersinformatie, geschatte verzending en specificaties — zonder extra configuratie.
- Field AI Prompts: Categoriseer, vertaal of herformatteer data tijdens het scrapen. Bijvoorbeeld: “Categoriseer dit product als Kitchen Utensils, Small Appliances, Storage of Other.”
- Geplande scraping: Stel een planning in in natuurlijke taal (“elke maandag om 9:00”), voer URL’s in, en Thunderbit voert de scrape uit in de cloud en exporteert naar Google Sheets, Airtable of een andere bestemming.
- Gratis export: Excel, CSV, Google Sheets, Airtable, Notion, JSON — geen betaalmuur op export. Afbeeldingen exporteren als echte bijlagen in Airtable en Notion.
Prijzen: gratis tier met tot 6 pagina’s (of 10 met een trial-boost); betaalde abonnementen beginnen rond $15/maand (maandelijks) of $9/maand (jaarlijks) voor 500 credits, waarbij 1 credit = 1 outputrij.
Temu-data scrapen met AI Get Started Free
Side-by-side: Thunderbit vs. Python-script op dezelfde Temu-pagina
Het contrast is groot:
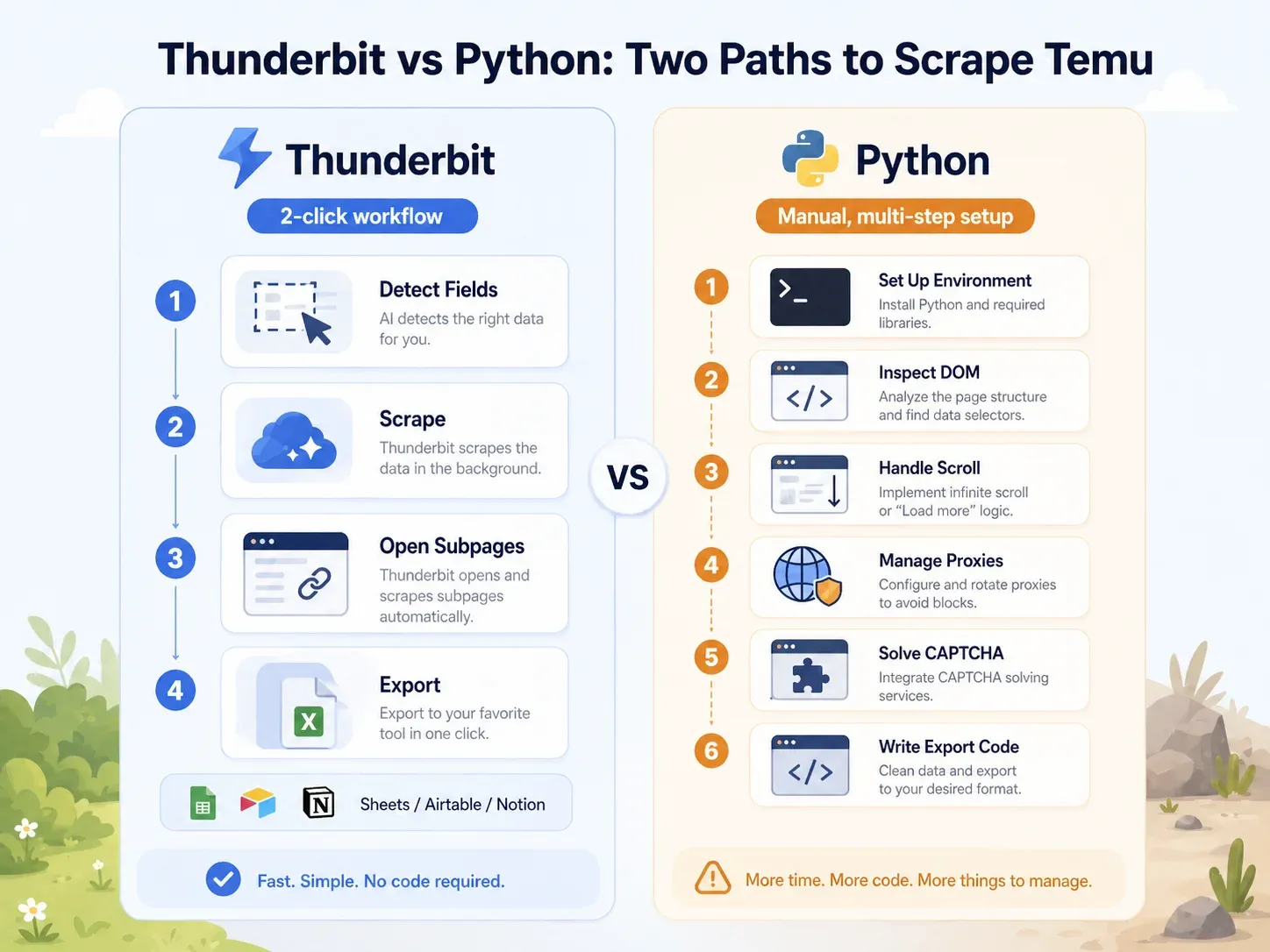
| Taak | Thunderbit | Python (Playwright) |
|---|---|---|
| Temu-categoriepagina openen | Open pagina in Chrome | Python-omgeving opzetten, Playwright installeren, browsers installeren |
| Velden identificeren | Klik op “AI Suggest Fields” | DOM inspecteren, netwerkcalls bekijken, JSON-payloads analyseren |
| Dynamisch laden afhandelen | Browser/cloud-modus + paginering | Scroll-/wait-logica schrijven, verzoeken onderscheppen |
| Blokkades afhandelen | Probeer cloud-modus of browser-modus | Proxies, headers, fingerprinting, retries, CAPTCHA toevoegen |
| Listingvelden extraheren | Klik op “Scrape” | Selectors of API-parseringslogica schrijven |
| Productpagina’s verrijken | Klik op “Scrape Subpages” | Een aparte PDP-crawler bouwen |
| Exporteren | Klik op Sheets/Airtable/Notion/Excel | CSV/JSON/Sheets-integratiecode schrijven |
| Typische setup voor een zakelijke gebruiker | Binnen 2 minuten | Minstens 1–4 uur; doorlopend onderhoud |
Een minimale Playwright-prototype voor Temu kan er zo uitzien (pseudocode — niet productieklaar):
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.temu.com/search_result.html?search_key=kitchen+organizer")
page.wait_for_load_state("networkidle")
for _ in range(8):
page.mouse.wheel(0, 2000)
page.wait_for_timeout(1200)
cards = page.locator("[data-product-id], a[href*='goods.html']")
# Productiecode heeft nog steeds selectors, proxies, retries,
# CAPTCHA-afhandeling, PDP-crawling en exportlogica nodig.
print(cards.count())
Dat zijn al 10+ regels vóór je één enkel veld hebt geëxtraheerd, en dan heb je proxies, CAPTCHA, PDP-enrichment of export nog niet eens aangeraakt. Voor een niet-technische gebruiker comprimeert Thunderbit die hele workflow tot een paar klikken. Voor een ontwikkelaar biedt de Python-route meer controle — maar wel tegen een veel hogere onderhoudskost.
Octoparse en ParseHub: no-code desktop-Temu-scrapers
Als je meer controle wilt dan een Chrome-extensie, maar geen code wilt schrijven, dan zijn Octoparse en ParseHub de belangrijkste opties.
Octoparse heeft een publiek Temu Details Scraper-sjabloon. De voorbeeldoutput bevat product-ID’s, titels, prijzen, verkoper-/winkelgegevens, afbeeldings-URL’s, kortingen, winkel-URL’s en gedetailleerde specificaties. Dat is een echt voordeel — je kunt starten met een sjabloon in plaats van een workflow vanaf nul op te bouwen. Octoparse ondersteunt ook cloud-extractie, planning en visuele workflowopbouw.
De kanttekeningen voor Temu:
- Anti-bot-add-ons (residential proxies vanaf $3/GB, CAPTCHA-oplossing voor $1–$1,50 per duizend) kunnen snel oplopen.
- Sjablonen kunnen stukgaan wanneer Temu de layout wijzigt. Je moet mogelijk selectors bijwerken of wachten tot Octoparse het sjabloon onderhoudt.
- De setup duurt 10–60 minuten, afhankelijk van de complexiteit van de pagina.
Octoparse-prijzen: gratis plan met 10 taken en 50K maandelijkse data-export; Standard rond $75/maand per jaar; Professional rond $108/maand per jaar. Add-ons voor proxies, CAPTCHA en managed services komen daar bovenop.
ParseHub is een visuele desktop/webscraper die goed overweg kan met dynamische pagina’s (hij draait een volledige Chromium-browser). De betaalde abonnementen beginnen echter bij $189/maand, wat stevig is voor een solopreneur. In mijn onderzoek vond ik geen sterk publiek Temu-specifiek sjabloon. ParseHub past beter bij teams die al vertrouwd zijn met het bouwen van visuele scrapingprojecten.
| Tool | Sterktes voor Temu | Zwaktes op Temu | Prijs |
|---|---|---|---|
| Octoparse | Publiek Temu-sjabloon, visuele workflow, cloud-extractie, planning | Sjabloononderhoud, anti-bot-add-ons verhogen de kosten | Gratis; ~$75/maand jaarlijks Standard; ~$108/maand jaarlijks Pro; add-ons extra |
| ParseHub | Afhandeling van dynamische pagina’s, projectworkflow-builder, IP-rotatie op betaalde plannen | Hogere instapprijs, geen publiek Temu-sjabloon gevonden | Betaalde plannen vanaf $189/maand |
Scraping-API’s: ScraperAPI, Apify en Bright Data voor Temu
API-gebaseerde scrapingdiensten handelen proxies, rendering en anti-botlogica af, zodat ontwikkelaars zich kunnen richten op het parsen en opslaan van data. Ze passen goed wanneer je een pipeline bouwt, niet wanneer je een eenmalige spreadsheet-export draait.
ScraperAPI is een ontwikkelaars-API voor proxy-rotatie en rendering. Op de prijspagina staat een proefperiode van 7 dagen met 5.000 credits, Hobby voor $49/maand voor 100.000 credits, en hogere tiers daarboven. De adder onder het gras voor Temu: JavaScript-rendering en premium proxy-pools kosten 10–75 credits per verzoek, afhankelijk van de tier. Door die creditvermenigvuldiging kan je effectieve kost per rij veel hoger uitvallen dan de headlineprijs.
Apify is een platform met een marktplaats van vooraf gebouwde “actors” (scrapers). Er bestaan meerdere Temu-actors. Eén door de community onderhouden Temu Scraper noemt pay-per-event-prijzen van ongeveer $5 per 1.000 producten op de gratis tier. Een andere Temu Products Scraper noemt $4 per 1.000 resultaten. Het risico: de kwaliteit van actors varieert, onderhoud hangt af van de community, en sommige actors kunnen verouderd zijn of stukgaan wanneer Temu updates uitrolt. Controleer altijd de datum van de laatste wijziging en gebruikersbeoordelingen voordat je je vastlegt.
Bright Data is de enterprise-optie. Op de Temu-scraperpagina staat dat jobs draaien op Bright Data-infrastructuur met proxy-rotatie, geo-targeting, CAPTCHA-/unblockinglogica en autoscaling. Outputformaten zijn onder meer JSON, CSV, Parquet, en directe levering naar S3, GCS, Azure Blob, BigQuery en Snowflake. Branchebeoordelingen melden dat Web Scraper API pay-as-you-go rond $2,5 per 1.000 records kost, met contractplannen vanaf ongeveer $499/maand. Krachtig, maar geprijsd voor teams met serieuze budgetten.
Oxylabs heeft ook een speciale Temu Scraper API-pagina. Plannen beginnen bij $49/maand, met een gratis proefperiode tot 2.000 resultaten. Het is een sterk alternatief voor Bright Data voor ontwikkelteams die gestructureerde Temu-data via API willen.
| API/Platform | Temu-specifiek bewijs | Sterkte | Zwakte | Het beste voor |
|---|---|---|---|---|
| ScraperAPI | Geen Temu-specifieke pagina gevonden, maar ecommerce anti-botfuncties zijn gedocumenteerd | Eenvoudig endpoint, JS-rendering, premium proxies | Creditvermenigvuldigers voor premium functies; ontwikkelaars moeten zelf de data parsen | Developer pipelines |
| Apify | Meerdere Temu-actors in de marktplaats | Snelste ontwikkelroute als de actor past en onderhouden wordt | Actor-kwaliteit varieert; sommige verouderd | Ontwikkelaars die een actor-marktplaats + planning willen |
| Bright Data | Speciale Temu-scraperpagina | Enterprise-infrastructuur, unblocking, levering naar warehouse | Duur; webscrapingconcepten blijven vereist | Datateams op enterprise-schaal |
| Oxylabs | Speciale Temu Scraper API-pagina | Duidelijke prijs per resultaat, JS-afhandeling, claims rond IP/CAPTCHA | Developer-API-workflow | Ontwikkelteams die Temu-API-toegang nodig hebben |
Aangepaste Python-scripts (Playwright/Selenium): volledige controle, veel werk
Aangepaste Python-scrapers bieden maximale flexibiliteit — dat is de winst. Playwright is over het algemeen een betere start dan Selenium voor Temu, dankzij het auto-waiting-model en betere omgang met JavaScript-zware pagina’s.
Maar de afweging is pittig.
Een prototype kost 1–4 uur. Een productiescraper heeft proxy-rotatie, realistische browser-fingerprints, een CAPTCHA-strategie, retries, schema-validatie, outputopslag, monitoring, alerting en juridische review nodig.
En hij breekt. Reddit-scrapinggemeenschappen beschrijven moderne ecommerce-scraping herhaaldelijk als instabiel wanneer sites Cloudflare, JavaScript-rendering en anti-bot-fingerprints gebruiken.
| Faalmodus | Typische oorzaak | Mitigatie | |---|---|---|---| | Lege HTML / ontbrekende producten | JS laadt productkaarten na de eerste HTML | Gebruik Playwright, wacht op network en DOM | | Alleen de eerste paar producten | Oneindig scrollen / lazy loading | Scroll-loop, network-idle waits, drempels op aantal kaarten | | Prijzen ontbreken of zijn inconsistent | Regio-/sessie-/valutastatus of anti-botrespons | Locale instellen, cookies, geotargeted proxy | | 403 / challenge / CAPTCHA | IP-reputatie, headless fingerprint, verzoeksnelheid | Residential proxies, stealth browser, lagere snelheid | | Selectorbreuk | DOM-/class-wijzigingen, A/B-tests | Semantische extractie of API-parsing indien beschikbaar |
Aangepaste scripts zijn niet de “gratis” optie. Ze verschuiven kosten van abonnementskosten naar ontwikkeltijd, proxykosten, CAPTCHA-kosten en onderhoudsrisico. Als je een scraping engineer in huis hebt en bijzondere logica nodig hebt, is dit de juiste route. Voor alle anderen is dit in de praktijk de duurste optie.
Best practice: subpage-scraping voor volledige Temu-productdata
Dit is dé best practice met de meeste impact in dit artikel — en bijna geen enkele andere gids behandelt het.
Een Temu-categorie- of zoekpagina laat je de basis zien: titel, thumbnail, prijs, ruwe beoordeling. Maar de velden die een rij echt bruikbaar maken — gedetailleerde beschrijvingen, variantenlijsten, volledige aantallen reviews, geschatte verzendtijden, verkopersnamen, specificatietabellen — staan op de productdetailpagina (PDP).
Als je alleen de listingpagina scrapt, werk je met een gedeeltelijke dataset.
De tweestapsworkflow:
- Stap 1 — Scrape de listingpagina (PLP): Extraheer productnaam, prijs, thumbnail en beoordeling van een Temu-zoek- of categoriepagina.
- Stap 2 — Verrijk via subpage-scraping: Bezoek elke PDP van het product en voeg kolommen toe zoals volledige beschrijving, aantal reviews, variantopties, verzendtijd en verkopersinformatie.
Zo ziet de data er vóór en na uit:
| Veld | Uit PLP (Stap 1) | Toegevoegd vanuit PDP (Stap 2) |
|---|---|---|
| Producttitel | ✅ | — |
| Prijs | ✅ | ✅ (geverifieerd / korting %) |
| Thumbnail | ✅ | — |
| Sterrenbeoordeling | ✅ | ✅ (met aantal reviews) |
| Volledige beschrijving | ❌ | ✅ |
| Variants (maten, kleuren) | ❌ | ✅ |
| Verkopernaam | ❌ | ✅ |
| Geschatte verzending | ❌ | ✅ |
| Gedetailleerde specificaties | ❌ | ✅ |
In Thunderbit is dit één klik: na je eerste scrape klik je op “Scrape Subpages.” De AI bezoekt elke product-URL en voegt de extra kolommen toe — geen extra configuratie, geen aparte spider, geen selectoronderhoud. Octoparse’s Temu Details-sjabloon en Apify’s Temu-actor ondersteunen ook velden op PDP-niveau, maar met meer setup en onderhoud. In Python moet je een aparte PDP-crawler bouwen, de selectors onderhouden en paginering binnen detailpagina’s afhandelen — een flinke extra investering.
Best practice: geplande Temu-scraping voor doorlopende prijs- en voorraadmonitoring
Eenmalige scrapes zijn nuttig voor productontdekking. Competitive intelligence vraagt om herhaalde observatie.
Prijzen veranderen, producten raken uitverkocht, nieuwe items verschijnen dagelijks, en kortingsniveaus verschuiven met promoties. Een wekelijkse of dagelijkse scrape creëert een historietabel waar je team echt iets mee kan.
Drie use-cases die de moeite waard zijn om te automatiseren:
- Prijmonitoring: Volg wekelijks de top 50 Temu-SKU’s van een concurrent. Laat geüpdatete prijzen automatisch exporteren naar Google Sheets voor een snelle vergelijking met je eigen prijzen.
- Voorraad- en beschikbaarheidsmonitoring: Detecteer wanneer een trending product uitverkocht raakt, een nieuwe variant verschijnt of de geschatte verzendtijd verandert.
- Detectie van nieuwe producten/trends: Plan dagelijks een scrape van Temu’s “New Arrivals” of een prioriteitscategoriepagina. Sorteer op aantal verkochte items of aantal reviews om stijgende producten vroeg te signaleren.
In Thunderbit stel je dit in door het interval in natuurlijke taal te beschrijven (“elke maandag om 9:00”), je doel-URL’s in te voeren en op “Schedule” te klikken. De scrape draait in de cloud en exporteert naar de bestemming van jouw keuze. Omdat de AI de pagina elke keer vers leest, passen geplande scrapes zich automatisch aan Temu’s layoutwijzigingen aan — je hoeft selectors niet bij te werken wanneer Temu een productkaart herontwerpt.
Het alternatief: een cronjob opzetten, een Python-script onderhouden, proxy-rotatie configureren, een outputpipeline bouwen en selectors repareren telkens wanneer Temu de layout wijzigt. Voor een niet-technisch team is dat onhaalbaar. Voor een ontwikkelaar is het doorlopende overhead. Apify en Bright Data ondersteunen ook geplande runs, maar met meer technische setup en hogere kosten.
Best practice: de end-to-end Temu-dataworkflow (scrape → schoonmaken → exporteren → handelen)
De meeste scrapinggidsen stoppen bij “CSV downloaden.”
Maar zakelijke gebruikers hebben data nodig in de tools waar ze echt mee werken — Google Sheets voor samenwerking, Airtable voor productdatabases, Notion voor teamdashboards. De echte best practice is een end-to-end workflow:
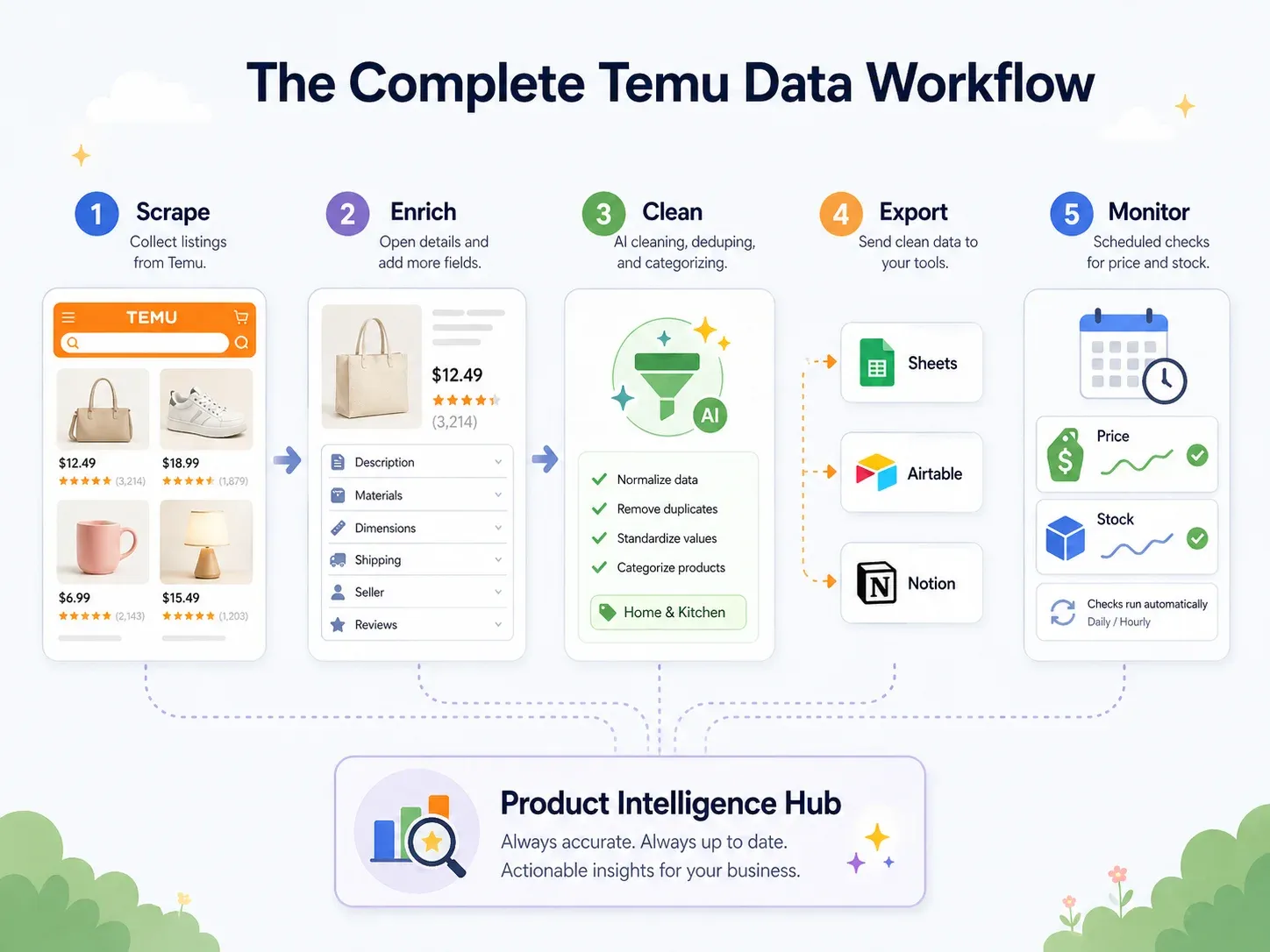
| Workflowstap | Wat er gebeurt | Thunderbit-capaciteit |
|---|---|---|
| Scrape | Data extraheren van Temu-pagina’s | AI Suggest Fields → Scrape (2 klikken) |
| Verrijken | Elke productdetailpagina bezoeken | Scrape Subpages (1 klik) |
| Opschonen & labelen | Producten categoriseren, prijzen normaliseren, titels vertalen | Field AI Prompt — labelen, formatteren, vertalen tijdens het scrapen |
| Exporteren | Data naar bedrijfstools sturen | Gratis export naar Excel, Google Sheets, Airtable, Notion; CSV/JSON downloaden |
| Monitoren | Wijzigingen in de tijd volgen | Scheduled Scraper met natuurlijke-taalintervallen |
Hier is een concreet voorbeeld: je scrape 200 Temu-keukenproducten. Tijdens het scrapen categoriseert een Field AI Prompt elk product automatisch in “Utensils / Small Appliances / Storage / Cleaning / Decor.” Prijzen worden genormaliseerd naar numerieke USD-waarden. Chinese producttitels worden naar het Engels vertaald. De data wordt rechtstreeks geëxporteerd naar een Airtable-base, met productafbeeldingen intact (niet alleen URL’s — echte afbeeldingsbijlagen, zoals beschreven in Thunderbit’s gids over image scraping). Een geplande scrape ververst de data wekelijks.
Enkele handige Field AI Prompt-instructies voor Temu-data:
- “Categoriseer dit product in een van: Kitchen Utensils, Small Appliances, Storage, Cleaning, Decor, Other. Geef alleen de categorie terug.”
- “Vertaal de producttitel naar beknopt Engels, met behoud van merknamen, aantallen, maten en modelnummers.”
- “Normaliseer de prijs als een getal zonder valutasymbolen.”
- “Label de vraag als High, Medium of Low op basis van beoordeling, aantal reviews en aantal verkochte items. Als data ontbreekt, geef Unknown terug.”
Deze workflow verandert een ruwe scrape in een levende product intelligence-database — zonder dat een ontwikkelaar een aparte ETL-pipeline hoeft te bouwen.
Vergelijking van de beste Temu-scrapers: side-by-side tabel
| Tool | Vaardigheidsniveau | Insteltijd | Anti-botafhandeling | Subpage-scraping | Planning | Exportopties | Prijstier | Het beste voor |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | Beginner | Minuten | Browser-modus, cloud-modus, AI-veldherkenning | Ja (Scrape Subpages) | Ja (natuurlijke-taalplanning) | Excel, CSV, Google Sheets, Airtable, Notion, JSON | Gratis 6 pagina’s; betaald vanaf ~$9–15/maand voor 500 credits | Niet-technische ecommerce-teams, dropshippers |
| Octoparse | Beginner–Gemiddeld | 10–60 min | Cloud-extractie, proxy/CAPTCHA-add-ons | Ja (template-workflows) | Ja (betaalde/cloud-plannen) | Excel, CSV, JSON, HTML, XML, database, Google Sheets | Gratis; ~$75/maand jaarlijks Standard; add-ons extra | Operators die visuele workflows + Temu-sjabloon willen |
| ParseHub | Beginner–Gemiddeld | 30–60 min | Dynamische rendering, betaalde IP-rotatie | Ja (projectflows) | Betaalde plannen | CSV/JSON, Dropbox/S3 op betaald | Betaald vanaf $189/maand | Teams die visuele projecten voor dynamische sites bouwen |
| ScraperAPI | Ontwikkelaar | Uren | Proxy-rotatie, JS-rendering, premium pools | Aangepast gecodeerd | DataPipeline/scheduler | HTML/JSON/CSV | Proef 5K credits; Hobby $49/maand; hogere tiers beschikbaar | Ontwikkelaars die aangepaste Temu-pipelines bouwen |
| Apify | Gemiddeld | 10–30 min als de actor past | Actor-specifieke browser/proxylogica | Afhankelijk van actor | Ja | JSON, CSV, Excel, API/datasets | Gratis platform; Temu-actors ~$4–5/1K producten | Ontwikkelaars/operators die actor-kwaliteit kunnen beoordelen |
| Bright Data | Gevorderd/Enterprise | Uren–dagen | Volledige proxy-, CAPTCHA-, unblocking- en autoscalinglaag | Aangepast via scraper/API | Ja | JSON, CSV, Parquet, S3, GCS, Azure, BigQuery, Snowflake | ~$2,5/1K records PAYG; contracten vanaf ~$499/maand | Enterprise-datateams, extractie op hoog volume |
| Oxylabs | Gevorderd | Uren | JS-afhandeling, IP/CAPTCHA-claims | Aangepast via API | Ja | JSON/API-output | Vanaf $49/maand; proef tot 2K resultaten | Ontwikkelteams die Temu-API-toegang nodig hebben |
| Aangepaste Python (Playwright) | Gevorderd | 1–4 uur+; doorlopend onderhoud | Handmatige proxies, CAPTCHA, fingerprints | Volledig aangepast | Cron/queue/manual | Aangepast | Ontwikkeltijd + proxy/CAPTCHA/hostingkosten | Randgevallen, teams met scraping engineers |
Welke Temu-scraper moet je kiezen? Korte aanbevelingen
- Dropshipper die snel productonderzoek nodig heeft? Begin met Thunderbit’s gratis tier. Het is de snelste route van “ik wil Temu-data” naar “ik heb een spreadsheet.” Als het werkt op jouw doelpagina’s (en dat zou het moeten doen voor de meeste openbare categorie- en productpagina’s), ben je klaar.
- Operator die visuele controle en herbruikbare sjablonen wil? Octoparse heeft een publiek Temu Details-sjabloon en een visuele workflowbuilder. Reken op 10–30 minuten setup en wat proxy-/CAPTCHA-configuratie.
- Ontwikkelaar die een datapipeline of interne tool bouwt? ScraperAPI of Apify geven je API-/actor-workflows die goed integreren met code en geplande jobs. Beoordeel Apify-actors zorgvuldig — controleer onderhoudsstatus en gebruikersbeoordelingen.
- Enterprise-team dat Temu-data op hoog volume en levering naar warehouse nodig heeft? Bright Data is de infrastructuuroptie. Duur, maar het verwerkt schaal, unblocking en levering naar S3/BigQuery/Snowflake.
- Scraping engineer die ongebruikelijke logica nodig heeft? Aangepaste Playwright/Selenium geeft je volledige controle. Reserveer wel budget voor doorlopend onderhoud, proxykosten en CAPTCHA-afhandeling.
Voor de meeste niet-technische zakelijke gebruikers raad ik aan eerst Thunderbit’s gratis tier te testen. De directe vraag is altijd: “Kan ik de rijen krijgen die ik nodig heb van déze exacte Temu-pagina?” — en dat kun je binnen twee minuten beantwoorden zonder iets uit te geven. Voor ontwikkelaars: voer een benchmark uit van kosten per succesvol geëxtraheerde rij over Apify, ScraperAPI en een klein Playwright-prototype voordat je budget vastlegt.
Probeer Thunderbit gratis voor Temu-scraping
Veelgestelde vragen over Temu scrapen
Is het legaal om Temu te scrapen?
Dat hangt af van het rechtsgebied, de data die je verzamelt, je toegangsmetode en hoe je de data gebruikt. Temu’s Gebruiksvoorwaarden beperken expliciet geautomatiseerde toegang, inclusief crawlen, scrapen of spideren van pagina’s of data. Amerikaanse rechtbanken hebben enige gunstige precedentwerking geboden voor toegang tot publiek beschikbare data (het Ninth Circuit-arrest hiQ v. LinkedIn), maar latere uitspraken hebben ook contractbreuk- en trespass-claims bevestigd. Het korte antwoord: het scrapen van publiek beschikbare productdata voor onderzoek kan in sommige contexten verdedigbaar zijn, maar de gebruiksvoorwaarden, privacywetgeving, auteursrecht en de manier waarop je de data gebruikt zijn allemaal van belang. Dit is geen juridisch advies — raadpleeg een jurist voor commercieel gebruik.
Hoe vaak wijzigt Temu de lay-out van zijn website?
Er is geen publieke frequentie gedocumenteerd. Communitymeldingen en het tool-ecosysteem behandelen Temu als een dynamisch, vaak bijgewerkt doel. Ga ervan uit dat CSS-selectors op elk moment kunnen breken, en geef de voorkeur aan AI-/semantische extractie of actief onderhouden sjablonen boven hardcoded selectors.
Kan ik Temu scrapen zonder geblokkeerd te worden?
Voor beperkte openbare pagina’s met een verantwoord tempo, ja — vooral met tools die echte browser-rendering, sessieondersteuning en throttling hebben. Geen enkele tool mag worden gezien als een universele garantie. Cloudscraping met roterende IP’s werkt goed voor openbare cataloguspagina’s; browser-scraping met je huidige sessie werkt beter wanneer regio, login of pop-ups de data beïnvloeden.
Welke data kan ik uit Temu-productpagina’s halen?
Veelvoorkomende openbare velden zijn producttitel, URL, huidige prijs, originele prijs, kortingspercentage, afbeeldings-URL’s, sterrenbeoordeling, aantal reviews, aantal verkochte items, naam van verkoper/winkel, verzendinformatie, categorie, productspecificaties, varianten (kleuren, maten) en het tijdstip van scraping. De exacte beschikbare velden hangen af van het paginatype (listing versus detail) en de regio.
Heb ik proxies nodig om Temu te scrapen?
Voor kleine, handmatige browser-modus-extractie (een paar pagina’s tegelijk) misschien niet. Voor cloud-, geplande of grootschalige verzameling zijn proxies of managed anti-blocking-infrastructuur meestal noodzakelijk. Tools zoals Thunderbit, Bright Data en ScraperAPI bundelen proxybeheer in hun platform, zodat je het niet apart hoeft te configureren.
Als je dieper wilt gaan op verwante onderwerpen, bekijk dan onze gidsen over webscraping voor prijsvergelijking, beste ecommerce-webscrapers, data van websites naar Excel scrapen en hoe je naar Google Sheets scrapt. Je kunt ook walkthroughs bekijken op het Thunderbit YouTube-kanaal.
Probeer Thunderbit voor Temu-scraping Get Started Free
Meer leren




