
Google verwerkt dagelijks ruim —sommige schattingen komen zelfs uit op bijna —en dat aantal blijft oplopen. Al die zoekdata is een goudmijn voor SEO-teams, sales ops, e-commerce-analisten en steeds vaker ook AI-agents die live webbewijzen nodig hebben. Het probleem? In 2026 voelt het kiezen van een SERP API minder als een tool uitzoeken en meer als je weg vinden in een doolhof van prijspagina’s, creditsystemen en vage beloftes over "gestructureerde JSON."
Ik heb de afgelopen weken acht SERP API-aanbieders doorgespit—responsietijden getest, prijzen genormaliseerd over verwarrende factureringsmodellen en gekeken welke SERP-features elke aanbieder daadwerkelijk omzet naar gestructureerde velden. Het doel: je een eerlijke vergelijking geven, appelen met appelen, die je nergens anders vindt. We behandelen snelheid, werkelijke kosten op schaal, parse-dekking, AI-agent-fit en betrouwbaarheid in productie. Als je gefrustreerd bent door "je vergelijkt prijspagina’s, niet de werkelijke uitgaven" (een echt citaat uit een die ik vond), dan is dit artikel voor jou.
Waarom je in 2026 een SERP API nodig hebt (en waarom kiezen zo lastig is)
Een SERP API is een gehoste service die een zoekopdracht naar een zoekmachine stuurt en de resultatenpagina teruggeeft als machineleesbare output—meestal JSON. In plaats van zelf proxyrotatie, CAPTCHA-afhandeling, browser-rendering en parsers te bouwen, roep je één endpoint aan en krijg je gestructureerde data terug. Simpel idee, complexe markt.
De use-cases zijn inmiddels veel breder dan alleen rank tracking:
- SEO-teams hebben rankings nodig, snippet-eigenaarschap, People Also Ask-vragen en zichtbaarheid van concurrenten.
- Sales- en GTM-teams gebruiken SERP’s om bedrijven, reviewpagina’s, directories en signalen van koopintentie te vinden.
- E-commerce-teams monitoren Google Shopping, betaalde advertenties en concurrentieprijzen.
- AI-ontwikkelaars voeren SERP-data in in LLM-agents, RAG-pipelines en workflowtools zoals n8n en LangChain.
De groeit naar verwachting tot , met een CAGR van ongeveer 13,78%. SERP API’s nemen daarvan een flink deel voor hun rekening.
De kernfrustratie is dit: elke aanbieder zegt "gestructureerde JSON" te leveren, maar de SERP-elementen die daadwerkelijk worden geparsed—PAA, knowledge panels, local packs, shopping-advertenties, featured snippets—verschillen enorm. Ook de prijsmodellen zijn een rommeltje. Sommigen rekenen per zoekopdracht, anderen per credit, weer anderen per resultaat, en sommigen hanteren verschillende tarieven per snelheidsniveau of geolocatie. Een Reddit-gebruiker zei het mooi: "SerpApi rekent per geslaagde zoekopdracht, ScraperAPI verpakt alles in credits, en Serperdev lijkt goedkoop totdat je credits koppelt aan je echte workload."
Dit artikel vult de gaten op die ik nergens anders kon vinden: een parsing-matrix die laat zien wat elke API daadwerkelijk teruggeeft, genormaliseerde prijzen bij 1K/10K/100K queries, AI-agent-fit en data over productierijpheid.
Hoe we hebben getest: criteria voor het kiezen van de beste SERP API
Ik heb elke aanbieder beoordeeld op acht dimensies die direct aansluiten op waar productiegebruikers echt om geven. De meeste vergelijkingsartikelen behandelen er twee of drie oppervlakkig. Ik wilde ze alle acht, mét bewijs.
Snelheid en responstijd. Ik heb verwezen naar benchmarks van derden—met name —en naar documentatie van aanbieders. Snelheid is belangrijk als je realtime dashboards bouwt of tool-calling AI-agents die niet 30 seconden op een respons kunnen wachten.
Prijs op schaal (1K, 10K, 100K queries). Ik heb de prijzen van elke aanbieder genormaliseerd naar kosten per 1.000 geslaagde zoekopdrachten. Alleen zo kun je creditmodellen, abonnementen en pay-as-you-go eerlijk vergelijken.
Geparseerde SERP-features (meer dan organische resultaten). Ik heb documentatie en voorbeeldresponses gecontroleerd om te verifiëren welke SERP-elementen elke API als gestructureerde velden teruggeeft—not alleen ruwe HTML.
Gratis tier en pay-as-you-go-beschikbaarheid. Lage instapdrempels zijn belangrijk. Als je een aanbieder niet met je echte workload kunt testen voordat je honderden dollars vastlegt, is dat een rode vlag.
AI- en automatiseringsintegratie. In 2026 hebben meer teams SERP API’s nodig die AI-agents voeden dan dashboards. Schemastabiliteit, schone output en Markdown-conversie zijn belangrijk voor downstream LLM-consumptie.
Ondersteuning voor meerdere zoekmachines. De meeste artikelen richten zich alleen op Google. Ik heb bekeken welke aanbieders Bing, Yandex, DuckDuckGo, Baidu en anderen ondersteunen.
Rate limits en productierijpheid. Geen enkel concurrerend artikel vergelijkt systematisch rate limits, retry-beleid of SLA’s. Toch hebben teams die schalen naar duizenden queries per dag die informatie nodig.
Developer-vriendelijkheid. Kwaliteit van documentatie, beschikbaarheid van SDK’s en time-to-first-result.
1. Thunderbit
hanteert een fundamenteel andere aanpak dan traditionele SERP API’s. In plaats van vaste endpoints aan te bieden die vooraf bepaalde SERP-elementen parsen, laat Thunderbit’s Extract API je je eigen JSON Schema definiëren—en haalt AI exact de velden uit die jij specificeert op elke zoekresultatenpagina. De Distill API zet elke URL om in schone, LLM-klare Markdown.
Dat betekent dat Thunderbit werkt op Google, Bing, Yandex, DuckDuckGo of elke andere zoekmachine—de AI leest de pagina elke keer vers in plaats van te vertrouwen op hardcoded selectors. SERP-layouts veranderen voortdurend. Je hoeft niet te wachten tot een aanbieder een parser bijwerkt.
Belangrijkste functies
- Extract API: Definieer een aangepast JSON Schema (organische resultaten, PAA-vragen, bedrijven in local packs, shopping-producten—wat je ook nodig hebt) en krijg precies die velden terug als gestructureerde data.
- Distill API: Zet elke SERP-pagina om in schone Markdown—ideaal voor RAG-pipelines en LLM-samenvattingen.
- Meerdere zoekmachines by design: Werkt op elke toegankelijke zoekpagina, niet alleen Google.
- Batchverwerking: Verwerk meerdere URL’s parallel.
- Ingebouwde anti-botafhandeling: CAPTCHA-oplossing, JS-rendering en proxyrotatie zijn inbegrepen.
- Rate limits per tier: Free (10 req/min, 2 gelijktijdig), Pro (100 req/min, 10 gelijktijdig), Enterprise (1.000 req/min, 50 gelijktijdig).
Prijzen
Creditgebaseerd model. Distill kost 1 credit per pagina; Extract kost 20 credits per pagina. Gratis credits zijn beschikbaar om te testen. Op basis van jaarlijkse prijsberekeningen kan Distill’s marginale kost zo laag zijn als ~USD 0,80 per 1K pagina’s, terwijl Extract rond ~USD 16 per 1K pagina’s uitkomt bij volledig gebruik. De propositie van Extract is dat je exact het schema krijgt dat je downstreamsysteem nodig heeft—geen nabewerking nodig.
Bekijk voor de actuele pakketten.
Beste voor
AI-agent-workflows, RAG-pipelines, scraping over meerdere zoekmachines, teams die flexibele schema’s nodig hebben in plaats van vaste output, en iedereen die het zat is te wachten tot een aanbieder een nieuwe SERP-feature ondersteunt.
2. SerpApi
is de veteraan in deze ruimte—actief sinds 2016 met het breedste aanbod Google-specifieke endpoints. Het dekt Google Search, Maps, Shopping, Scholar, News, Jobs, Trends, Images, Videos en meer.
Belangrijkste functies
- Toegewijde endpoints voor verschillende Google-producten met volwassen geo-targeting (tot op stadsniveau).
- Parseert PAA, knowledge panels, local packs, advertenties, shoppingresultaten, featured snippets, answer boxes en gerelateerde zoekopdrachten als gestructureerde velden.
- Goed onderhouden documentatie en client libraries in meerdere talen.
Prijzen
. Starter-abonnement: USD 25/maand voor 1.000 zoekopdrachten (effectief USD 25 per 1K). Popular-abonnement: USD 130/maand voor 15.000 zoekopdrachten (~USD 8,67 per 1K). Big Data: USD 2.750/maand voor 500.000 zoekopdrachten (~USD 5,50 per 1K). Geen eenvoudige pay-as-you-go-optie—het zijn abonnementsbundels.
Snelheid en betrouwbaarheid
De benchmark van HasData rapporteert ~5,49 seconden gemiddelde responstijd—not de snelste, maar wel stabiel. SerpApi adverteert met een uptime-SLA van 99,95% op betaalde plannen, en limieten voor gelijktijdige verzoeken verschillen per plan.
Beste voor
Teams die de breedste Google-productdekking nodig hebben (Maps, Scholar, Shopping, Jobs) met hoge nauwkeurigheid en stabiele schema’s. Enterprise-projecten met budget voor premium prijzen.
3. Serper
is de keuze voor snelheid en lage kosten. Het is een nieuwere speler die zich richt op snelle Google SERP-scraping tegen zeer concurrerende prijzen, en het is populair geworden in de n8n- en LangChain-community’s voor AI-agentintegraties.
Belangrijkste functies
- Schone JSON-output voor Google Search, News, Scholar, Images, Shopping, Videos, Places, Patents en Autocomplete.
- Minimale setup—je kunt binnen een minuut resultaten ophalen.
- Eenvoudig genoeg dat AI-agentframeworks het native integreren.
Prijzen
2.500 gratis queries bij aanmelding. Instapprijs rond USD 0,001 per zoekopdracht, dalend naar ~USD 0,00075 bij hoog volume. Vriendelijk voor pay-as-you-go. Eén kanttekening: meer dan 10 resultaten per query opvragen kan 2 credits kosten (controleer het actuele gedrag in je dashboard).
Snelheid en betrouwbaarheid
Een van de snelste in benchmarks—HasData rapporteert rond 2,87 seconden gemiddeld. Support is alleen per e-mail, en het team houdt een relatief laag publiek profiel aan, wat sommige gebruikers voorzichtig maakt. Bij zeer hoge gelijktijdigheid melden enkele reviewers betrouwbaarheidszorgen. Voor de meeste workloads is het echter prima.
Beste voor
Budgetbewuste projecten, startups, AI-agentintegraties die snelle en goedkope Google SERP-data nodig hebben. High-volume rank tracking waar kosten per query de belangrijkste beperking zijn.
4. Scrapingdog
zit al 5+ jaar in de markt en staat consequent bovenaan als snelste in benchmarks van derden. HasData mat het op met een succesratio van 100%.
Belangrijkste functies
- Google SERP API levert organische resultaten, PAA, featured snippets, advertenties en lokale resultaten als gestructureerde JSON.
- Zowel ruwe HTML als geparseerde JSON-opties beschikbaar.
- Documentatie in meerdere talen met codevoorbeelden voor de meeste programmeertalen—aan de slag gaan kost minuten, geen uren.
- 24/7 support.
Prijzen
. Betaalde plannen starten rond USD 40/maand. Prijs per call begint bij ~USD 0,001 en daalt sterk bij hoog volume—sommige vergelijkingen noemen tarieven zo laag als USD 0,000058 in de hoogste tiers.
Snelheid en betrouwbaarheid
De snelheidscijfers zijn echt indrukwekkend. Als je workflow gevoelig is voor latency en je hoge volumes vaste-schema Google SERP-extractie doet, is Scrapingdog qua pure responstijd moeilijk te verslaan.
Beste voor
High-volume SEO-tools en rank trackers die lage latency en lage kosten nodig hebben. Teams die productiesystemen bouwen waarbij elke milliseconde API-responstijd telt.
5. DataForSEO
is niet alleen een SERP API—het is een complete API-suite voor bedrijven die SEO-producten bouwen. Het dekt SERP, keywords, backlinks, business data, Google Ads, Trends en meer.
Belangrijkste functies
- Extreem uitgebreide parsing van SERP-features—organisch, betaald, local pack, knowledge graph, PAA, featured snippets, shopping, images, videos, top stories en meer.
- Twee modi: Live (synchroon) voor realtime dashboards, en Standard (asynchroon) voor batch-workflows waarbij je taken in de wachtrij zet en later resultaten ophaalt.
- Meerdere zoekmachines: Google, Bing, Yahoo, Baidu, Naver, Seznam en anderen.
Prijzen
Pay-as-you-go-model, maar de kosten verschillen per endpoint, engine, apparaat, prioriteit en modus. SERP-prijzen liggen doorgaans tussen ~USD 0,0006 en USD 0,002 per taak voor Google organic, afhankelijk van standard versus live en prioriteitsinstellingen. De documentatie is dicht—reken erop dat je tijd in de prijscalculator moet steken. .
Snelheid en betrouwbaarheid
De standaard asynchrone modus kan trager zijn (~10 seconden) omdat taken in de wachtrij staan. Live/high-speed modi kosten meer, maar zijn geschikt voor realtime dashboards. Lange staat van dienst, bewezen stabiliteit en enterprise support beschikbaar.
Beste voor
SaaS-bedrijven die SEO-platforms, rank-tracking dashboards en keyword-researchtools bouwen. Teams die comfortabel zijn met complexe documentatie en infrastructuur op enterprise-niveau.
6. Bright Data
is de enterprise-zwaargewicht. De SERP API is één product tussen vele—proxies, datasets, Web Unlocker en scrapingtools. De propositie draait om schaal, betrouwbaarheid en infrastructuur.
Belangrijkste functies
- Toegewijde endpoints voor Google Maps, Shopping en algemene zoekopdrachten—plus ondersteuning voor meerdere zoekmachines via proxy-infrastructuur voor Bing, Yahoo, Yandex en DuckDuckGo.
- Claimt een succespercentage van 100% met ingebouwde unblocking-technologie.
- Waar Bright Data echt uitblinkt: geo-targeting, gelijktijdigheid en unblocking op enterprise-schaal.
Prijzen
Gericht op enterprise. Publieke prijzen tonen pay-as-you-go- en abonnementopties, met veel vergelijkingen die instapverplichtingen rond USD 499/maand noemen. Prijs per call begint rond ~USD 0,005, maar daalt met volume. . Proefcredits beschikbaar ($5 waard).
Snelheid en betrouwbaarheid
Benchmarks laten vaak 2 tot 5,58 seconden zien. De reden om Bright Data te kopen is niet de mediane latency—het is de enterprise-SLA, toegewijde support en infrastructuur die miljoenen gelijktijdige requests aankan zonder degradatie. raadt aan om geleidelijk op te schalen.
Beste voor
Enterprise-teams die miljoenen SERP’s per maand verzamelen. Organisaties die Google Maps/local business-data op schaal nodig hebben. Teams die al Bright Data-proxyproducten gebruiken.
7. ScraperAPI
is een algemene webscraping-API die ook gestructureerde Google SERP-endpoints aanbiedt. Het is de "één tool voor alles"-optie—makkelijk te integreren, met een proxy-pool van meer dan 40 miljoen IP’s.
Belangrijkste functies
- Gestructureerde data-endpoints voor Google Search, Shopping, News en Jobs.
- Anti-blocking op basis van machine learning en CAPTCHA-oplossing, met JavaScript-rendering inbegrepen zonder extra kosten.
- Geotargeting-ondersteuning voor gelokaliseerde resultaten.
Prijzen
7-daagse gratis proefperiode met 5.000 credits. Betaalde plannen starten rond USD 49/maand. De catch: SERP-calls kunnen andere credits verbruiken dan gewone scraping-requests, dus normaliseer altijd op basis van daadwerkelijk geleverde geslaagde SERP-queries. .
Snelheid en betrouwbaarheid
Hier komt het eerlijke deel: de benchmark van HasData rapporteert ~33,66 seconden gemiddelde responstijd voor SERP-queries. Dat is aanzienlijk trager dan gespecialiseerde SERP API’s. Wel een hoge succesratio (99,9%), maar de latency maakt het minder geschikt voor realtime toepassingen. Beter voor batchverwerking.
Beste voor
Teams die een algemene webscraping-oplossing nodig hebben met SERP als extra. Projecten waarbij snelheid minder belangrijk is dan betrouwbaarheid en eenvoudige setup. Ontwikkelaars die ScraperAPI al gebruiken voor andere scrapingtaken en leveranciers willen consolideren.
8. Apify
is geen pure SERP API. Het is een scraping- en automatiseringsplatform rond "Actors"—herbruikbare scripts voor taken zoals Google Search-scraping, Maps-extractie en workflowautomatisering. Zie het als een marktplaats waar je de scraper kiest (of bouwt) die precies bij je behoefte past.
Belangrijkste functies
- Marktplaats met vooraf gebouwde met uiteenlopende featuredekking.
- Zeer aanpasbaar—bouw custom scraping-workflows, koppel actors aan elkaar, plan runs in.
- Geeft JSON-output; flexibiliteit om specifieke SERP-features te parsen via actorconfiguratie.
- Sterk in het combineren van SERP-extractie met andere scraping- en automatiseringstaken.
Prijzen
Gratis tier met maandelijkse platformcredits (~$5 waard, ongeveer 1.400 resultaten). Betaalde plannen starten rond USD 49/maand. Kosten op actorniveau verschillen—sommige rekenen per resultaat, andere per compute unit. Vergelijkingen van derden zetten Apify vaak rond USD 0,003 per zoekopdracht op kleine schaal. .
Snelheid en betrouwbaarheid
HasData rapporteert ~8,2 seconden gemiddeld. De op actors gebaseerde architectuur voegt overhead toe vergeleken met gespecialiseerde SERP-endpoints. Beter voor geplande/batch-workflows dan voor realtime queries.
Beste voor
Teams die custom scraping + automatiseringsworkflows nodig hebben, verder dan alleen SERP-data. Projecten die SERP-extractie combineren met andere webscrapingtaken. Ontwikkelaars die maximale flexibiliteit willen boven vooraf gebouwde endpoints.
SERP-feature parsingmatrix: wat geeft elke API eigenlijk terug?
Dit is de vergelijking die ik nergens anders kon vinden. Elke aanbieder zegt "gestructureerde JSON", maar de echte SERP-elementen die als eersteklas velden worden geparseerd verschillen enorm. Ik heb voor elk product documentatie en voorbeeldresponses gecontroleerd.
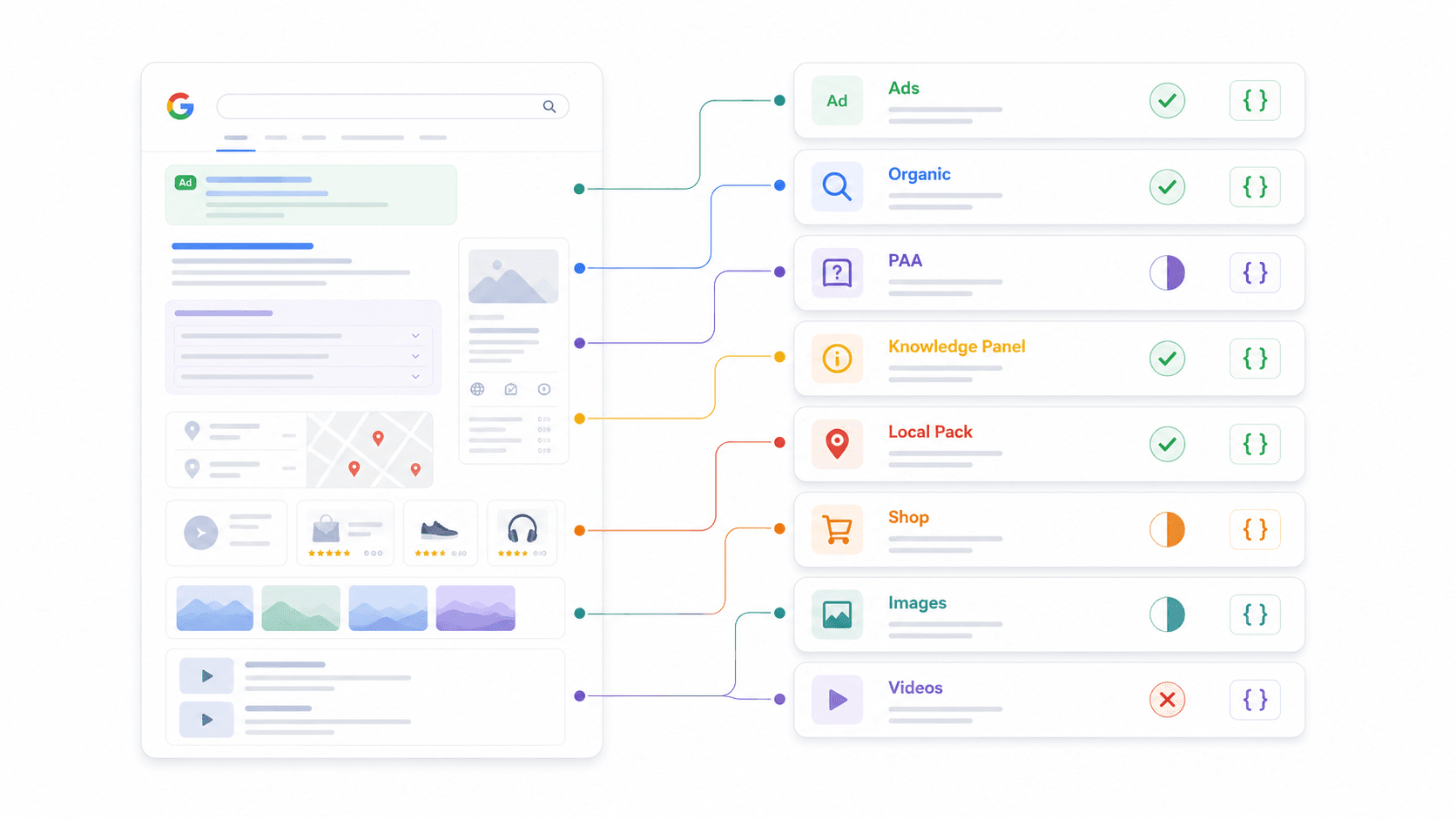
| SERP-feature | Thunderbit | SerpApi | Serper | Scrapingdog | DataForSEO | Bright Data | ScraperAPI | Apify |
|---|---|---|---|---|---|---|---|---|
| Organische resultaten | Aangepast schema | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | Afhankelijk van actor |
| People Also Ask | Aangepast schema | ✅ | ✅ | ✅ | ✅ | Gedeeltelijk | Gedeeltelijk | Afhankelijk van actor |
| Knowledge Panel | Aangepast schema | ✅ | Gedeeltelijk | Gedeeltelijk | ✅ | Gedeeltelijk | Gedeeltelijk | Afhankelijk van actor |
| Local Pack / Maps | Aangepast schema | ✅ | ✅ | Gedeeltelijk | ✅ | ✅ | Gedeeltelijk | Afhankelijk van actor |
| Shopping-resultaten | Aangepast schema | ✅ | ✅ | Gedeeltelijk | ✅ | ✅ | ✅ | Afhankelijk van actor |
| Featured Snippets | Aangepast schema | ✅ | Gedeeltelijk | ✅ | ✅ | Gedeeltelijk | Gedeeltelijk | Afhankelijk van actor |
| Advertenties (boven/onder) | Aangepast schema | ✅ | Gedeeltelijk | ✅ | ✅ | Gedeeltelijk | Gedeeltelijk | Afhankelijk van actor |
| Image Pack | Aangepast schema | ✅ | ✅ | ✅ | ✅ | Gedeeltelijk | Gedeeltelijk | Afhankelijk van actor |
| Videoresultaten | Aangepast schema | ✅ | ✅ | Gedeeltelijk | ✅ | Gedeeltelijk | Gedeeltelijk | Afhankelijk van actor |
Wat "Aangepast schema" betekent voor Thunderbit: In plaats van vooraf vast te leggen welke SERP-features het parseert, definieer je je eigen JSON Schema om exact de velden uit te halen die je nodig hebt. Wil je PAA-vragen plus antwoordsamenvattingen plus signalen voor commerciële intentie? Definieer dat schema en de AI levert het. Die flexibiliteit is waarom Thunderbit werkt op elke zoekmachine—not alleen Google.
Waarom dit belangrijk is voor je workflow: Als je PAA-data nodig hebt voor contentstrategie, verifieer dan dat je aanbieder het echt parseert. Als je shopping-advertenties volgt voor e-commerce, controleer dan of gestructureerde shoppingvelden bestaan. Ga er niet vanuit dat "gestructureerde JSON" gelijkstaat aan volledige dekking.
Werkelijke kosten op schaal: prijs-per-query vergelijking
De vermelde prijzen op websites vertellen niet het hele verhaal. Ik heb alles genormaliseerd naar kosten per 1.000 geslaagde queries bij drie volumetiers.
| Aanbieder | Kosten voor 1K queries | Kosten voor 10K queries | Kosten voor 100K queries | Pay-as-you-go? | Gratis tier |
|---|---|---|---|---|---|
| Thunderbit (Distill) | ~USD 0,80–3,20 | ~USD 8–32 | ~USD 80–320 | Creditpakket | Gratis credits |
| Thunderbit (Extract) | ~USD 16–64 | ~USD 160–640 | ~USD 1.600–6.400 | Creditpakket | Gratis credits |
| SerpApi | USD 25 (Starter) | ~USD 87 (Popular) | ~USD 550 (Big Data) | Nee (abonnement) | 250/maand |
| Serper | ~USD 1 | ~USD 10 | ~USD 75–100 | Ja | 2.500 queries |
| Scrapingdog | ~USD 1 | ~USD 10 of minder | Kan ver onder USD 10 zakken | Plan/credits | 1.000 credits |
| DataForSEO | ~USD 0,60–2 | ~USD 6–20 | ~USD 60–200 | Ja | Proefcredits |
| Bright Data | ~USD 0,50–5+ | Offerte-afhankelijk | Het best op enterprise-volume | Ja/plan | Proefcredits ($5) |
| ScraperAPI | Afhankelijk van credits | Afhankelijk van credits | Afhankelijk van credits | Plan/credits | 5.000 proefcredits |
| Apify | ~USD 3 (kleine schaal) | Afhankelijk van actor | Afhankelijk van actor | Platformcredits | Maandelijkse gratis credits |
Verborgen kosten om op te letten:
- Serper’s mogelijke kosten van 2 credits voor >10 resultaten per query.
- Het prijsverschil van DataForSEO tussen standard- en live/high-priority-modi.
- De creditvermenigvuldigers van ScraperAPI voor SERP versus gewone scraping.
- De enterprise-minimumverplichtingen van Bright Data.
Waarde per tier:
- Zijprojecten (USD 50/maand): Serper of Scrapingdog voor vaste Google SERP JSON.
- Groeiende teams (10K–50K queries/maand): Serper, Scrapingdog of DataForSEO, afhankelijk van parse-diepte.
- Enterprise (100K+ queries/maand): DataForSEO, Bright Data of SerpApi Big Data.
- AI-first extractie: Thunderbit, omdat het schema aansluit op wat je downstream-agent verwacht zonder nabewerking.
Beste SERP API voor AI-agents en LLM-workflows in 2026
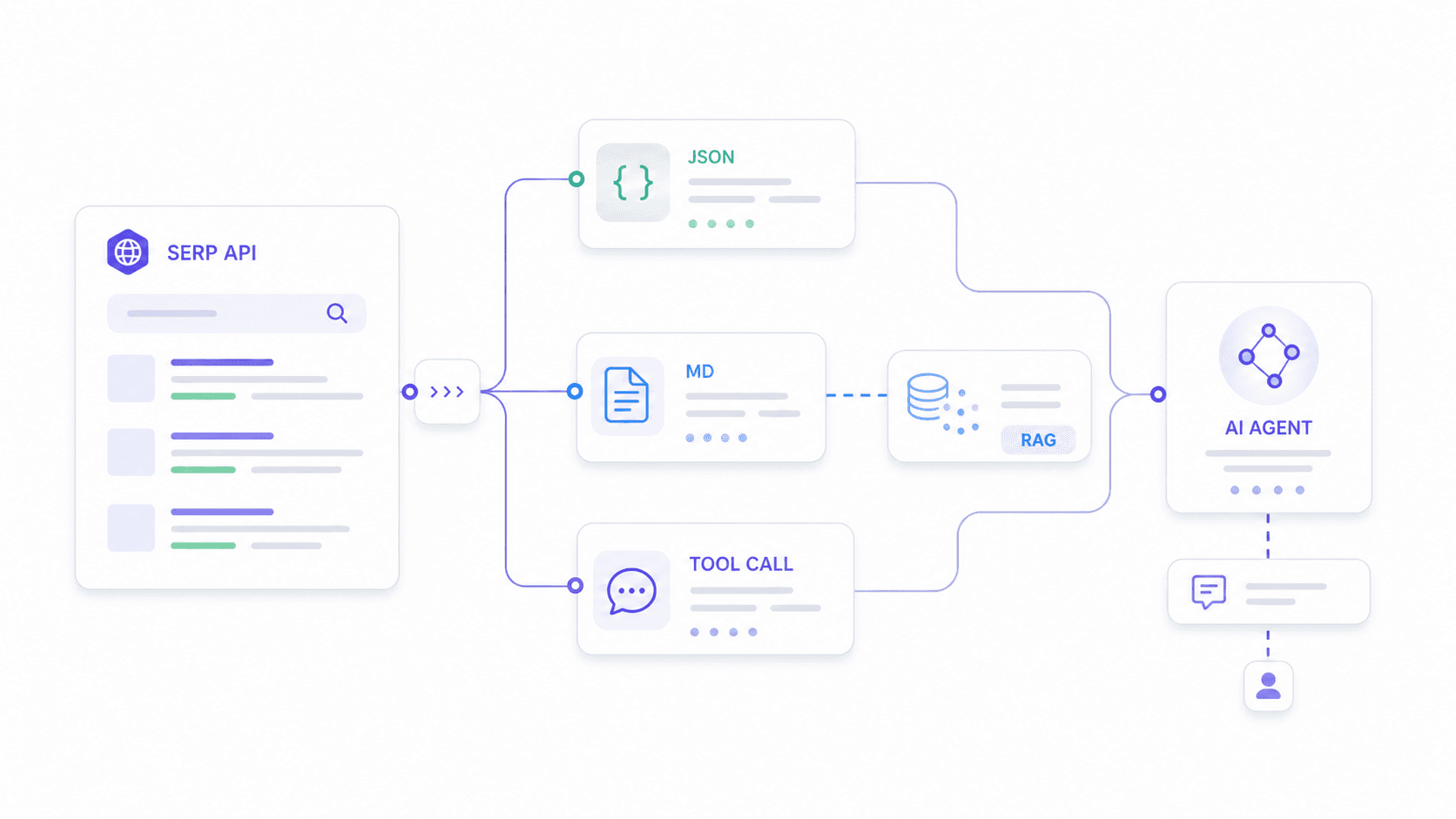
Dit is de use-case die niemand anders goed behandelt. Ik vond minstens drie waarin gebruikers beschrijven dat ze SERP API’s proberen te integreren met n8n-workflows en AI-agents, waarbij één gebruiker expliciet zei: "ik heb niet uitgevogeld hoe ik het goed werkend krijg met een AI-agent."
AI-agents hebben andere dingen nodig dan rank-tracking dashboards. Ze hebben nodig:
- Schema-stabiele JSON die hun parse-logica niet breekt wanneer een aanbieder zijn outputformaat bijwerkt.
- Aangepaste outputvelden die passen bij wat het downstream-model verwacht—not een generieke dump van alles.
- Schone Markdown of tekst voor RAG-embeddingpipelines.
- Lage genoeg latency voor realtime tool-calling.
Hoe elke aanbieder past in een AI-agent stack
| Aanbieder | Geschiktheid voor AI-agents | Waarom |
|---|---|---|
| Thunderbit | Uitstekend | Aangepast JSON Schema (Extract API) + Markdown voor RAG (Distill API). Het meest flexibel voor agent-specifieke extractie. |
| Serper | Zeer goed | Snelle, schone JSON, populair in n8n/LangChain-community’s. Simpel en goedkoop voor basis search-tool-calls. |
| SerpApi | Goed | Stabiel schema, uitstekende documentatie. Werkt goed wanneer agents Google-verticals nodig hebben (Maps, Scholar, Shopping). |
| DataForSEO | Goed | Het best wanneer de agent deel uitmaakt van een grotere SEO-datapipeline. |
| Scrapingdog | Goed | Snel en goedkoop; schema is stabiel voor Google SERP. |
| Bright Data | Goed | Dataverzameling op enterprise-schaal over zoekmachines/regio’s heen. |
| ScraperAPI | Matig | Beter wanneer de agent ook algemene webcrawling nodig heeft. |
| Apify | Matig tot goed | Flexibel maar trager; beter voor geplande batch-workflows. |
Praktisch voorbeeld met Thunderbit: Stel dat je AI-agent zoekintentie moet analyseren voor "beste CRM voor makelaars". Je definieert een schema dat organische resultaten opvraagt (titel, URL, snippet, positie), People Also Ask-vragen met antwoordsamenvattingen en een classificatie van commerciële intentie. Thunderbit’s Extract API levert precies die structuur—niet meer, niet minder. Je agent verspilt geen tokens aan het parsen van irrelevante velden of het opschonen van HTML-restanten.
Voor RAG-pipelines zet Thunderbit’s Distill API de SERP-pagina om in schone Markdown die klaar is voor embedding. De meeste gespecialiseerde SERP API’s geven vaste JSON-schema’s terug; Thunderbit’s aanpak laat ontwikkelaars de output aanpassen aan wat hun downstream-model verwacht.
Beslismatrix per use-case: als je X nodig hebt, gebruik Y
Gebruikers op forums blijven vragen om concrete aanbevelingen die aansluiten op hun echte workflows—not algemene "het hangt ervan af"-adviezen. Dus heb ik dit gemaakt.
| Jouw use-case | Beste keuze | Tweede keus | Waarom |
|---|---|---|---|
| SEO-ranktracking (hoog volume) | DataForSEO | Scrapingdog | SEO-native endpoints, bulkprijzen, uitgebreide parsing |
| Google Maps / lokale bedrijfsdata | SerpApi | Bright Data | Volwassen Maps-endpoint; Bright Data past bij local scraping op enterprise-schaal |
| AI-agent / n8n-automatisering | Thunderbit | Serper | Aangepast schema + Markdown voor RAG; Serper is snel en goedkoop voor simpele calls |
| Budget-MVP / zijproject (<USD 50/mnd) | Serper | Scrapingdog | Royale gratis tier, pay-as-you-go, minimale setup |
| Meerdere zoekmachines (Bing, Yandex, DuckDuckGo) | Thunderbit | DataForSEO | Thunderbit werkt via AI-extractie op elke zoekmachine; DataForSEO heeft multi-engine endpoints |
| Google Reviews-aggregatie | SerpApi | DataForSEO | Toegewijde review-parsing endpoints |
| E-commerce / shopping-monitoring | SerpApi | DataForSEO | Sterke dekking van Google Shopping en gestructureerde velden |
| Aangepaste scraping-workflows | Apify | ScraperAPI | Actor-flexibiliteit; ScraperAPI is makkelijk voor algemene scraping + SERP |
Snelle persona-gids:
- SEO-team: Begin met DataForSEO als je dashboards bouwt; gebruik SerpApi als Google-verticaldekking en documentatie belangrijker zijn dan prijs.
- Sales-team: Gebruik Thunderbit wanneer de workflow SERP’s, directorypagina’s en verrijking combineert; gebruik Serper voor eenvoudige lead discovery-query’s.
- AI-toolontwikkelaar: Thunderbit voor aangepaste schema’s/RAG, Serper voor goedkope snelle search, SerpApi voor robuuste Google-verticals.
- Solo-ondernemer: Begin met de gratis tiers van Serper, Scrapingdog, SerpApi en Thunderbit. Draai dezelfde 20 productie-achtige queries voordat je kiest.
Rate limits, betrouwbaarheid en productierijpheid vergeleken
Ik wou dat dit onderdeel bestond toen ik voor het eerst aanbieders voor productie-workflows beoordeelde. Teams die schalen naar duizenden queries per dag hebben voorspelbare rate limits, automatische retries en uptime-garanties nodig—and geen enkel ander vergelijkingsartikel behandelt dit systematisch.
| Aanbieder | Rate limit | Gelijktijdige requests | Retry bij fout | SLA / uptime |
|---|---|---|---|---|
| Thunderbit Free | 10 req/min | 2 | Ingebouwd (anti-bot, CAPTCHA) | — |
| Thunderbit Pro | 100 req/min | 10 | Ingebouwd | — |
| Thunderbit Enterprise | 1.000 req/min | 50 | Ingebouwd | Maatwerkvoorwaarden |
| SerpApi | Op planbasis (zoekopdrachten/uur) | Op planbasis | Aanbieder handelt proxies/CAPTCHA af | 99,95% SLA |
| Serper | Op account-/planbasis | Niet breed gepubliceerd | Handmatige client-retry aanbevolen | Geen publieke SLA |
| Scrapingdog | Op planbasis | Check de planvoorwaarden | Anti-blocking afgehandeld | Niet altijd publiek |
| DataForSEO | Gedocumenteerd per endpoint/mode | Verschilt per modus | Async ondersteunt polling/retry | Enterprise support |
| Bright Data | Gedocumenteerd, geleidelijk opschalen | Enterprise-schaal | Ingebouwde unblocking | Enterprise SLA |
| ScraperAPI | Plan-gebaseerde gelijktijdigheid | Afhankelijk van credits | Handelt retries/proxies af | Betaalde supportopties |
| Apify | Afhankelijk van actor/memory/compute | Platformlimieten | Configuratie op actorniveau | Platformbetrouwbaarheid |
Productie-checklist vóór je commit:
- Vraag of de aanbieder kosten rekent voor mislukte of geblokkeerde requests.
- Bevestig de exacte gelijktijdigheid, requests per minuut en burst-gedrag.
- Controleer of geotargeting, mobiel versus desktop en JS-rendering het creditverbruik veranderen.
- Bewaar voorbeeld-JSON-responses voor 20–50 echte queries en vergelijk veldnamen over meerdere dagen om schemastabiliteit te verifiëren.
- Voeg client-side retries en timeout-budgets toe als SERP-data bedrijfskritisch is.
Samenvatting in één oogopslag: alle 8 SERP API’s vergeleken
| Aanbieder | Gem. snelheid | Kosten per 1K | Gratis tier | Parsingdekking | AI-fit | Meerdere engines | Oordeel |
|---|---|---|---|---|---|---|---|
| Thunderbit | Middelmatig (AI-extractie) | Laag (Distill) tot premium (Extract) | Ja | Aangepast (elke feature) | Uitstekend | Uitstekend | Beste voor AI-native aangepaste SERP-extractie en RAG |
| SerpApi | ~5,5s | Premium | 250/maand | Uitstekend (vast) | Goed | Brede Google-verticals | Beste volwassen Google-dekking |
| Serper | ~2–3s | Zeer laag | 2.500 queries | Goed | Zeer goed | Vooral Google | Beste goedkope snelle API voor AI/MVP’s |
| Scrapingdog | ~1,25s | Zeer laag op schaal | 1.000 credits | Goed | Goed | Engines verifiëren | Beste snelheid/kosten-combinatie |
| DataForSEO | Middelmatig–traag (standard) | Laag–matig | Proefcredits | Uitstekend | Goed | Uitstekend | Beste infrastructuur voor SEO-platforms |
| Bright Data | ~2–5,5s | Enterprise | Proef ($5) | Goed (afhankelijk van product) | Goed | Uitstekend | Beste verzameling op enterprise-schaal |
| ScraperAPI | ~33s | Afhankelijk van credits | 5.000 proef | Matig | Matig | Google-endpoints | Beste als SERP één onderdeel is van bredere scraping |
| Apify | ~8s | Afhankelijk van actor | Maandelijkse credits | Afhankelijk van actor | Matig–goed | Afhankelijk van actor | Beste voor custom automatiseringsworkflows |
Hoe Thunderbit in jouw SERP-workflow past
Nog wat context over waarom ons team Thunderbit’s API zo heeft gebouwd. Het traditionele SERP API-model—vaste endpoints, vooraf bepaalde outputvelden, alleen Google—werkt prima voor simpele rank tracking. Maar zodra je iets net anders nodig hebt (PAA-antwoorden met sentiment, local pack-resultaten met review-aantallen, of shoppingdata in een specifiek databaseschema), zit je vast aan nabewerking of aan een andere aanbieder.
Thunderbit’s Extract API draait dat model om. Jij vertelt via een JSON Schema wat je wilt, en de AI zoekt uit hoe het uit welke zoekpagina dan ook gehaald moet worden. Vandaag Google, morgen Bing, volgende week een niche-zoekmachine—dezelfde API, dezelfde aanpak.
De Distill API lost een ander probleem op: rommelige SERP-pagina’s omzetten in schone Markdown die LLM’s echt kunnen consumeren zonder vast te lopen op HTML-restanten, navigatie-elementen en tracking scripts. Als je een RAG-pipeline bouwt die verse zoekbewijzen nodig heeft, is dit de snelste route van "live SERP" naar "geïndexeerde content."
Beide endpoints bevatten anti-botafhandeling, CAPTCHA-oplossing en JS-rendering standaard. Daar betaal je niet extra voor—het zit in de creditprijs verwerkt.
Probeer het zelf: voor browsergebaseerde extractie, of gebruik de API direct voor programmatische workflows. Ons heeft walkthroughs als je het eerst in actie wilt zien voordat je code schrijft.
Een opmerking over legaliteit
Dit komt in elke FAQ terug, dus hier is de korte versie: de legaliteit van SERP-scraping is feitelijk en jurisdictiegebonden. De stelde vast dat het scrapen van publiek toegankelijke data niet per se een computercriminaliteit is, maar dat geeft geen algemene toestemming. Google vanwege SERP-scraping, wat wijst op actieve commerciële druk rondom toegang.
Praktisch advies: gebruik vendor-API’s volgens hun voorwaarden, vermijd het verzamelen van persoonsgegevens tenzij dat echt nodig is, en vraag aanbieders hoe zij compliance afhandelen. Ga er niet vanuit dat SERP-scraping risicoloos is.
Conclusie
Geen enkele aanbieder wint op elk vlak—de juiste keuze hangt af van je use-case, budget en technische stack. Na het normaliseren van prijzen, het testen van snelheid, het in kaart brengen van parsingdekking en het beoordelen van AI-agent-geschiktheid, is dit mijn besliskader:
- Flexibiliteit + AI-agent-ready nodig? → Thunderbit
- Brede Google-productdekking nodig? → SerpApi
- Snelheid + laagste kosten nodig? → Serper of Scrapingdog
- Een SEO-platform bouwen? → DataForSEO
- Enterprise-schaal met SLA? → Bright Data of DataForSEO
- Algemene scraping + af en toe SERP? → ScraperAPI of Apify
Begin met de gratis tiers. Draai 20–50 echte queries die overeenkomen met je productie-workload. Vergelijk de JSON-responses. Controleer de werkelijke kosten na credits en multipliers. Beslis dan.
Prijzen veranderen in deze markt vaak—deze vergelijking is in mei 2026 genormaliseerd op basis van de huidige publieke pagina’s. Als je dit maanden later leest, controleer het dan opnieuw voordat je koopt.
Voor meer informatie over -aanpakken en hoe die zich verhouden tot traditionele methoden, hebben we daar uitgebreid over geschreven. En als je evalueert, kan Thunderbit’s Chrome-extensie ook die kant van het verhaal aan.
Veelgestelde vragen
1. Wat is een SERP API en wie heeft er een nodig?
Een SERP API is een service die zoekopdrachten naar zoekmachines zoals Google, Bing of Yandex stuurt en de resultaten teruggeeft als gestructureerde data (meestal JSON). SEO-professionals gebruiken ze voor rank tracking, sales-teams voor lead discovery, e-commerce-teams voor prijsmonitoring en AI-ontwikkelaars voor het voeden van live zoekdata in agents en RAG-pipelines.
2. Hoeveel kost het om 1.000 Google-zoekresultaten via een API te scrapen?
Dat varieert sterk—van ~USD 0,60 per 1K (DataForSEO in de standaardtier) tot ~USD 25 per 1K (SerpApi Starter-plan). Kortingen bij hoog volume verschillen enorm per aanbieder. Normaliseer altijd naar kosten per 1.000 geslaagde queries in plaats van alleen de headlineprijs te vergelijken.
3. Kan ik een SERP API gebruiken met AI-agents zoals LangChain of n8n?
Ja. Serper is populair in de n8n-community voor eenvoudige search-calls. Thunderbit is het sterkst wanneer je agent aangepaste JSON-schema’s of Markdown voor RAG nodig heeft. SerpApi werkt goed voor agents die stabiele Google-verticaldata nodig hebben (Maps, Scholar, Shopping).
4. Welke SERP API heeft de beste gratis tier om te testen?
Serper biedt 2.500 gratis queries bij aanmelding—het royaalst qua volume. SerpApi geeft 250 per maand, Scrapingdog biedt 1.000 credits, ScraperAPI levert 5.000 proefcredits (7 dagen) en Thunderbit bevat gratis credits voor prototyping. Apify heeft maandelijkse platformcredits ter waarde van ongeveer $5.
5. Welke SERP-features moet ik verifiëren voordat ik een aanbieder koop?
Ga er niet vanuit dat "gestructureerde JSON" volledige dekking betekent. Controleer of de API gestructureerde velden teruggeeft voor: People Also Ask, Knowledge Panel, Local Pack/Maps, Shopping-resultaten, Featured Snippets, Advertenties (boven en onder), Image Pack en Videoresultaten. Gebruik de parsingmatrix in dit artikel als start-checklist en test met echte queries voordat je je aan een plan commit.
Meer informatie