Het web is een wilde, continu veranderende omgeving geworden—denk minder aan een “digitale bibliotheek” en meer aan een “datajungle”. In 2025 sta je, als je data van moderne websites wilt scrapen, niet alleen tegenover een muur van JavaScript—je staat tegenover een fort. Ik heb zelf gezien hoe traditionele scrapingtools vastlopen op dynamische content, eindeloos scrollen en anti-botbeveiliging. Daarom is de opkomst van de Python headless browser niet zomaar een trend—het is een echte omwenteling voor iedereen die betrouwbare, schaalbare webdata-extractie nodig heeft.
En het zijn niet alleen techneuten die hier oog voor hebben. Tegen 2025 vertrouwt , en meer dan . Of je nu in sales, e-commerce of operations werkt: de juiste Python headless browser maakt het verschil tussen “data binnen handbereik” en “data buiten bereik”. Dus laten we door de ruis heen snijden—ik heb deze tools getest, vergeleken en ermee gewerkt, en hier zet ik de 10 beste Python headless browsers voor moderne scraping op een rij (met extra aandacht voor hoe AI het spel verandert voor niet-programmeurs).
Waarom is een Python headless browser essentieel voor moderne scraping?
Laten we de vaktermen even ontleden: een Python headless browser is gewoon een webbrowser die je met Python-code aanstuurt, maar zonder dat logge venster op je scherm. Hij laadt pagina’s, voert JavaScript uit, klikt op knoppen, vult formulieren in—alles onzichtbaar, op de achtergrond. Zie het als een spookbrowser die onvermoeibaar doorwerkt terwijl jij van je koffie nipt.
Waarom is dat belangrijk? Omdat moderne websites voor gebruikers zijn gebouwd, niet voor bots. Ze verbergen data achter JavaScript, vereisen logins en verwachten dat je interacteert als een echt persoon. Traditionele scrapers die alleen HTML ophalen, kijken dan naar lege hulzen. Headless browsers daarentegen simuleren echt gebruikersgedrag—ze wachten op AJAX-aanroepen, scrollen door eindeloze feeds en halen de content binnen zoals jij die ziet in Chrome of Firefox ().
Maar er is meer:
- Snelheid en efficiëntie: Headless browsers slaan de visuele weergave over, waardoor ze sneller zijn en minder geheugen gebruiken—perfect voor scraping op schaal ().
- Ondersteuning voor dynamische content: Ze voeren JavaScript uit, dus je krijgt de echte, gerenderde data—niet alleen de ruwe HTML.
- Automatiseringssuperkrachten: Inloggen, pagineren of pop-ups afhandelen? Python headless browsers kunnen het allemaal automatiseren.
- Schaalbaarheid: Draai honderden instanties in de cloud, scrape duizenden pagina’s parallel en blijf ontspannen.
Voor zakelijke gebruikers betekent dit dat je eindelijk leads kunt verzamelen, concurrenten kunt monitoren of prijzen kunt volgen—zelfs als de website eruitziet als Fort Knox. En met de nieuwste AI-gestuurde tools hoef je geen codeur te zijn om mee te doen.
Hoe we de beste Python headless browsers hebben gekozen
Ik heb niet zomaar blind op een lijst met browsernamen geprikt. Hier heb ik op gelet:
- Prestaties en snelheid: Kan de tool moderne, JavaScript-zware sites snel en betrouwbaar verwerken?
- Browserondersteuning: Werkt het met Chrome, Firefox, WebKit of zelfs oudere engines zoals IE?
- Gebruiksgemak: Is het vriendelijk voor niet-programmeurs, of heb je er een PhD in Python voor nodig?
- AI- en no-codefuncties: Kunnen zakelijke gebruikers AI inzetten om scraping te automatiseren zonder scripts te schrijven?
- Community en support: Is er een actieve community, goede documentatie en doorlopende ontwikkeling?
- Unieke functies: Biedt het iets bijzonders—zoals directe templates, cloudscraping of navigatie naar subpagina’s?
Ik heb teams weken zien worstelen met de setup, om vervolgens vast te lopen zodra de paginalay-out veranderde. De beste tools werken niet alleen—ze passen zich aan, schalen mee en maken je leven makkelijker.
Top 10 beste Python headless browsers voor moderne scraping
Hier is mijn definitieve lijst, met een diepere blik op wat elke tool sterk maakt (of juist laat struikelen).
1. Thunderbit
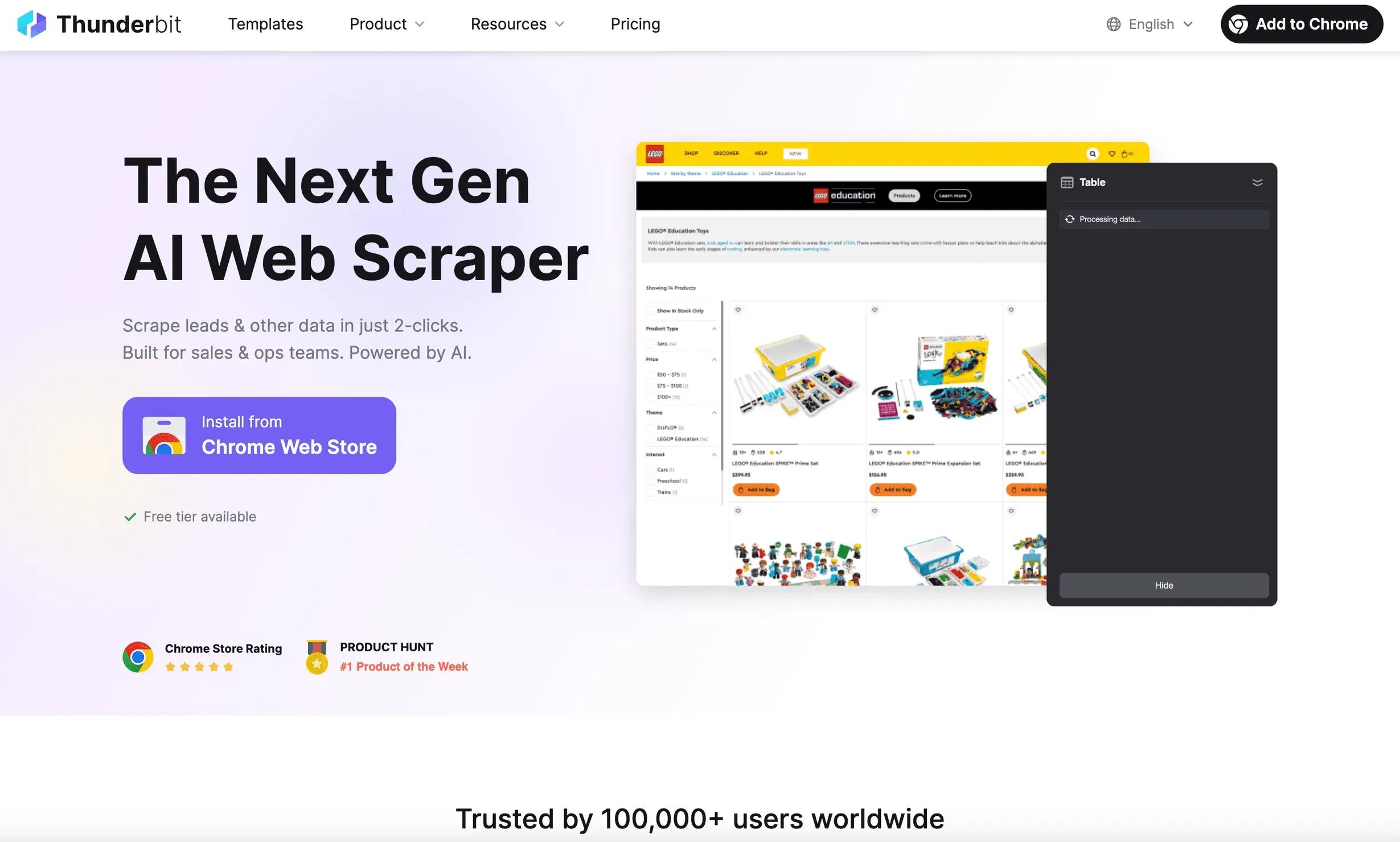 is de Python headless browser die ik jaren eerder had willen hebben. Het is niet zomaar een browserautomatiseringstool—het is een AI-webscraper Chrome-extensie gebouwd voor zakelijke gebruikers die resultaat willen, geen hoofdpijn.
is de Python headless browser die ik jaren eerder had willen hebben. Het is niet zomaar een browserautomatiseringstool—het is een AI-webscraper Chrome-extensie gebouwd voor zakelijke gebruikers die resultaat willen, geen hoofdpijn.
Waarom Thunderbit opvalt:
- AI velden voorstellen: Klik gewoon op “AI velden voorstellen”, en Thunderbit’s AI leest de pagina, adviseert welke data je moet extraheren en zet de scraper voor je op ().
- Directe datasjablonen: Voor populaire sites (Amazon, Zillow, LinkedIn, enz.) krijg je templates met één klik—geen setup nodig.
- Scraping van subpagina’s en paginering: Thunderbit kan door subpagina’s klikken, eindeloos scrollen afhandelen en alle data samenvoegen in één tabel.
- Natuurlijke-taakprompts: Beschrijf wat je wilt in gewoon Engels; Thunderbit’s AI doet de rest.
- Scrapen in de cloud of in de browser: Voer scrapes lokaal of in de cloud uit (tot 50 pagina’s tegelijk voor snelheid).
- Geen code nodig: Echt waar—als je een browser kunt gebruiken, kun je Thunderbit gebruiken.
- Gratis data-export: Exporteer met één klik naar Excel, Google Sheets, Notion of Airtable.
Ik heb Thunderbit uren zien besparen voor sales- en operationsteams—leads scrapen, prijzen volgen of productdata samenbrengen zonder ook maar één regel code. Het wordt wereldwijd vertrouwd door , en de feedback is steevast: “Ongelooflijk hoe makkelijk dit is.”
Het beste voor: niet-technische gebruikers, zakelijke teams, iedereen die AI het zware werk wil laten doen.
2. Selenium
 is de OG van browserautomatisering. Als je ooit hebt gegoogeld op “python headless browser”, ben je waarschijnlijk Selenium WebDriver tegengekomen.
is de OG van browserautomatisering. Als je ooit hebt gegoogeld op “python headless browser”, ben je waarschijnlijk Selenium WebDriver tegengekomen.
Voordelen:
- Ondersteunt alle grote browsers: Chrome, Firefox, Safari, Edge, zelfs Internet Explorer (voor de durfals).
- Enorme community: Talloze tutorials, plugins en Stack Overflow-antwoorden.
- Zeer flexibel: Automatiseer alles wat een gebruiker kan doen—klikken, formulieren, navigatie.
Nadelen:
- Setup kan pittig zijn: Je moet browserdrivers beheren en versies synchroon houden.
- Trager dan moderne tools: Het WebDriver-protocol voegt overhead toe, en opschalen naar honderden browsers is onhandig.
- Uitgebreide API: Je schrijft meer code dan met Playwright of Puppeteer.
Het beste voor: teams met bestaande Selenium-ervaring, cross-browser testen of oudere automatiseringsworkflows.
3. Puppeteer
 is Google’s high-level automatiseringsbibliotheek voor Chrome/Chromium. Hoewel het native in Node.js zit, kunnen Python-gebruikers via Pyppeteer toch meedoen.
is Google’s high-level automatiseringsbibliotheek voor Chrome/Chromium. Hoewel het native in Node.js zit, kunnen Python-gebruikers via Pyppeteer toch meedoen.
Voordelen:
- Gemaakt voor Chrome: Snel, efficiënt en strak geïntegreerd met Chrome DevTools.
- Async API: Geweldig voor moderne, JavaScript-zware sites.
- Rijke functies: Screenshots, PDF-export, netwerkinterceptie.
Nadelen:
- Alleen Chromium: Geen ondersteuning voor Firefox of Safari.
- Native voor Node.js: Python-gebruikers moeten Pyppeteer gebruiken (en die wordt inmiddels niet meer onderhouden—zie hieronder).
Het beste voor: ontwikkelaars die snelle, betrouwbare Chrome-automatisering willen en geen cross-browserondersteuning nodig hebben.
4. Playwright
 is de nieuwkomer, gebouwd door Microsoft—en het is razendsnel mijn standaardkeuze geworden voor geavanceerde scraping.
is de nieuwkomer, gebouwd door Microsoft—en het is razendsnel mijn standaardkeuze geworden voor geavanceerde scraping.
Voordelen:
- Ondersteuning voor meerdere browsers: Automatiseer Chromium, Firefox en WebKit met één API.
- Auto-waiting: Niet meer gokken wanneer een pagina klaar is—Playwright wacht automatisch.
- Gelijktijdigheid: Draai meerdere browser-contexten parallel voor bliksemsnelle snelheid.
- Python-first: Native Python-bindingen, zowel async als sync.
Nadelen:
- Grotere installatie: Bundelt meerdere browsers, dus de setup is wat zwaarder.
- Vereist nog steeds code: Minder gebruiksvriendelijk voor niet-technische gebruikers dan Thunderbit.
Het beste voor: ontwikkelaars die robuuste, moderne automatisering nodig hebben—vooral bij complexe, dynamische webapps.
5. Headless Chrome
 is de motor achter veel van de bovenstaande tools. Je kunt het direct aansturen via het Chrome DevTools Protocol (CDP) voor maximale flexibiliteit.
is de motor achter veel van de bovenstaande tools. Je kunt het direct aansturen via het Chrome DevTools Protocol (CDP) voor maximale flexibiliteit.
Voordelen:
- State-of-the-art webondersteuning: Werkt iets in Chrome, dan werkt het in headless Chrome.
- Fijngranulaire controle: Toegang tot elk hoekje en gaatje van de browser.
Nadelen:
- Steile leercurve: Je moet CDP spreken of een wrapperbibliotheek gebruiken.
- Alleen Chrome: Geen cross-browserondersteuning.
Het beste voor: experts die aangepaste automatiseringspipelines bouwen of Chrome op laag niveau integreren.
6. Pyppeteer
 is de niet-officiële Python-port van Puppeteer. Het bracht async Chrome-automatisering naar Python, maar… er zit een addertje onder het gras.
is de niet-officiële Python-port van Puppeteer. Het bracht async Chrome-automatisering naar Python, maar… er zit een addertje onder het gras.
Voordelen:
- Puppeteer-achtige API: Als je Puppeteer kent, voelt dit meteen vertrouwd.
- Snelle Chrome-automatisering: Geweldig voor dynamische sites.
Nadelen:
- Niet meer onderhouden: Het oorspronkelijke project wordt niet langer bijgewerkt (de ontwikkelaars raden aan over te stappen op Playwright).
- Alleen Chromium: Geen Firefox of Safari.
Het beste voor: oudere projecten die al Pyppeteer gebruiken. Voor nieuwe projecten: gebruik Playwright.
7. Splash
 is een lichte, scriptbare headless browser met een HTTP API, gebouwd door het Scrapinghub-team (nu Zyte).
is een lichte, scriptbare headless browser met een HTTP API, gebouwd door het Scrapinghub-team (nu Zyte).
Voordelen:
- Lichtgewicht: Gebruikt QtWebKit, dus minder zwaar dan Chrome.
- HTTP API: Te bedienen vanuit elke taal, niet alleen Python.
- Geweldig voor Scrapy: Integreert naadloos met Scrapy-spiders voor JavaScript-rendering.
Nadelen:
- Oudere WebKit-engine: Kan moeite hebben met hypermoderne JavaScript.
- Lua-scripting nodig: Voor geavanceerde interacties moet je wat Lua leren.
Het beste voor: Scrapy-gebruikers die af en toe JavaScript-rendering nodig hebben, of lichte server-side renderingtaken.
8. PhantomJS
 is de originele scriptbare headless browser, gebouwd op WebKit. Het was een pionier—maar inmiddels is het grotendeels achterhaald.
is de originele scriptbare headless browser, gebouwd op WebKit. Het was een pionier—maar inmiddels is het grotendeels achterhaald.
Voordelen:
- Eenvoudig te scripten: Makkelijk te automatiseren met JavaScript.
- Ondersteuning voor oude systemen: Werkt nog steeds voor oudere, statische sites.
Nadelen:
- Niet meer onderhouden: Sinds 2016 geen updates meer.
- Verouderde engine: Kan moderne, JavaScript-zware sites niet goed aan.
- Beveiligingsrisico’s: Geen recente patches.
Het beste voor: het onderhouden van oude scripts. Voor nieuwe projecten: migreer naar Playwright of Puppeteer.
9. HtmlUnit
 is een Java-gebaseerde headless browser die browsergedrag simuleert. Het is snel en lichtgewicht, maar geen echte browserengine.
is een Java-gebaseerde headless browser die browsergedrag simuleert. Het is snel en lichtgewicht, maar geen echte browserengine.
Voordelen:
- Volledig Java: Ideaal voor Java-zware omgevingen.
- Snel voor statische pagina’s: Geen volledige browser nodig.
Nadelen:
- Beperkte JavaScript-ondersteuning: Heeft moeite met moderne, dynamische sites.
- Niet native voor Python: Vereist integratielagen (bijv. Selenium’s HtmlUnitDriver).
Het beste voor: Java-gebaseerde workflows, testen van legacy-apps of het scrapen van eenvoudige, server-gerenderde pagina’s.
10. TrifleJS
 is een headless browser voor Internet Explorer (IE), bedoeld voor het automatiseren van verouderde webapps op Windows.
is een headless browser voor Internet Explorer (IE), bedoeld voor het automatiseren van verouderde webapps op Windows.
Voordelen:
- IE-automatisering: Handig voor oude intranetapps of systemen die alleen in IE werken.
- PhantomJS-achtige API: Weinig aanpassingen nodig voor PhantomJS-scripts.
Nadelen:
- Alleen Windows: Geen cross-platform ondersteuning.
- Verouderd: IE is met pensioen; TrifleJS is niche en wordt zelden onderhouden.
Het beste voor: gespecialiseerde legacy-workflows waarin IE-automatisering nog steeds vereist is.
Vergelijkingstabel met functies: Python headless browsers in één oogopslag
| Tool | Browserondersteuning | Prestaties & schaal | Gebruiksgemak | AI/no-codefuncties | Community & support | Het beste voor |
|---|---|---|---|---|---|---|
| Thunderbit | Chrome (extensie/cloud) | Hoog (cloudparallelisme) | Het makkelijkst—geen code | Ja (AI, templates) | Groeiend, actief | Niet-programmeurs, sales/ops, snelle data-extractie |
| Selenium | Alle grote browsers | Gemiddeld | Gemiddeld (setup) | Nee | Enorm, volwassen | Cross-browser, legacy, testautomatisering |
| Puppeteer | Chromium/Chrome | Zeer hoog | Hoog (voor devs) | Nee | Groot (Node.js) | Alleen Chrome, ontwikkelaars, snelle automatisering |
| Playwright | Chromium, Firefox, WebKit | Zeer hoog (meerdere contexten) | Hoog (voor devs) | Nee | Snel groeiend | Geavanceerde, multi-browser, moderne scraping |
| Headless Chrome | Chrome/Edge | Zeer hoog | Laag (handmatige CDP) | Nee | N.v.t. (basis) | Maatwerk, experts, controle op laag niveau |
| Pyppeteer | Chromium/Chrome | Hoog | Gemiddeld (async) | Nee | Klein, niet onderhouden | Oude Pyppeteer-scripts |
| Splash | QtWebKit | Gemiddeld | Gemiddeld (API/Lua) | Nee | Niche (Scrapy/Zyte) | Scrapy-gebruikers, lichte JavaScript-rendering |
| PhantomJS | WebKit (oud) | Laag (nu verouderd) | Gemiddeld (JS) | Nee | Beëindigd | Alleen legacy |
| HtmlUnit | Gesimuleerd (Java) | Gemiddeld/hoog (statisch) | Laag (Java) | Nee | Klein, Java-gericht | Java-workflows, eenvoudige/statische pagina’s |
| TrifleJS | Internet Explorer (Trident) | Laag/gemiddeld | Gemiddeld (JS, Win) | Nee | Minimaal, legacy | Legacy-automatisering alleen in IE |
Hoe kies je de juiste Python headless browser voor je bedrijf?
Hier is mijn spiekbriefje voor het kiezen van de juiste tool:
- Heb je snelle, no-code scraping met AI-hulp nodig? Kies dan voor . Het is de makkelijkste manier voor niet-programmeurs om betrouwbare data te krijgen—vooral voor sales-, e-commerce- of onderzoeksteams.
- Wil je maximale controle en cross-browserondersteuning? is dan je beste optie. Het is robuust, modern en gebouwd voor schaal.
- Heb je al in Selenium geïnvesteerd? Blijf bij —het blijft de koning van legacy- en multi-browserworkflows.
- Bouw je als ontwikkelaar Chrome-only automatisering? (of Playwright) is snel en krachtig.
- Scrape je eenvoudige, statische pagina’s in een Java-omgeving? is licht en makkelijk te integreren.
- Onderhoud je oude scripts of apps die alleen in IE werken? en zijn dan je vrienden in uiterste nood.
En onthoud: de beste tool is degene die past bij je workflow, de vaardigheden van je team en je zakelijke behoeften. Soms betekent dat combineren en afwisselen—Thunderbit voor snelle klusjes, Playwright voor zwaar werk en Selenium voor legacy-systemen.
Veelgestelde vragen
1. Wat is een Python headless browser en waarom heb ik er een nodig voor scraping?
Een Python headless browser is een webbrowser die je met Python-code aanstuurt, maar die onzichtbaar draait (zonder GUI). Hij is essentieel voor het scrapen van moderne, JavaScript-zware sites omdat hij scripts kan uitvoeren, gebruikersinteracties kan afhandelen en volledig gerenderde content kan extraheren—iets wat traditionele HTML-scrapers niet kunnen.
2. Welke Python headless browser is het beste voor niet-technische gebruikers?
is de beste keuze voor niet-programmeurs. Het gebruikt AI om de setup te automatiseren, biedt directe templates en laat je data scrapen in slechts een paar klikken—zonder programmeren.
3. Hoe verschillen Playwright en Puppeteer voor Python-gebruikers?
Playwright ondersteunt meerdere browsers (Chromium, Firefox, WebKit) en heeft robuuste Python-bindingen, waardoor het ideaal is voor geavanceerde automatisering. Puppeteer is alleen voor Chrome en native voor Node.js, maar Python-gebruikers kunnen Pyppeteer gebruiken (al wordt dat nu niet meer onderhouden). Voor nieuwe Python-projecten is Playwright de betere keuze.
4. Is Selenium nog steeds relevant voor moderne webscraping?
Ja—Selenium wordt nog steeds veel gebruikt, vooral voor cross-browser testen en legacy-automatisering. Maar het is trager en complexer in te stellen dan nieuwere tools zoals Playwright of Thunderbit, en het is minder efficiënt voor scraping op schaal.
5. Wanneer moet ik legacytools zoals PhantomJS, HtmlUnit of TrifleJS gebruiken?
Alleen voor het onderhouden of migreren van oude workflows. PhantomJS en TrifleJS zijn verouderd, en HtmlUnit is het meest geschikt voor Java-omgevingen met eenvoudige pagina’s. Voor nieuwe projecten kun je het best moderne, actief onderhouden tools gebruiken.
Als je klaar bent om te zien hoe moderne, AI-gestuurde scraping eruitziet, . En voor meer diepgaande artikelen over webautomatisering, bekijk de . Veel scrapeplezier—moge je data altijd vers zijn en je browsers eeuwig headless.
Meer lezen