

Het web barst bijna uit zijn voegen van de data, en in 2026 is de race om die chaos om te zetten in inzichten feller dan ooit. Of je nu in sales, e-commerce of vastgoed werkt, of gewoon een datafanaat bent zoals ik, je hebt vast gemerkt dat die oude routine van “kopiëren en plakken” niet meer genoeg is. Hier is een opvallend cijfer: de wereldwijde markt voor webscraping bereikte volgens Mordor Intelligence $1,03 miljard in 2025 (genoemd in PromptCloud’s 2026 state-of-web-scraping report) en staat op koers om tegen 2030 ongeveer te verdubbelen.
En het zijn niet alleen techreuzen — 82% van de e-commercebedrijven en meer dan een derde van de beleggingsfirma’s gebruikt webscraping voor leads, prijsinformatie en marktonderzoek (Browsercat). De conclusie: als je geen webscrapingtool gebruikt, laat je waarschijnlijk geld — en inzichten — liggen.
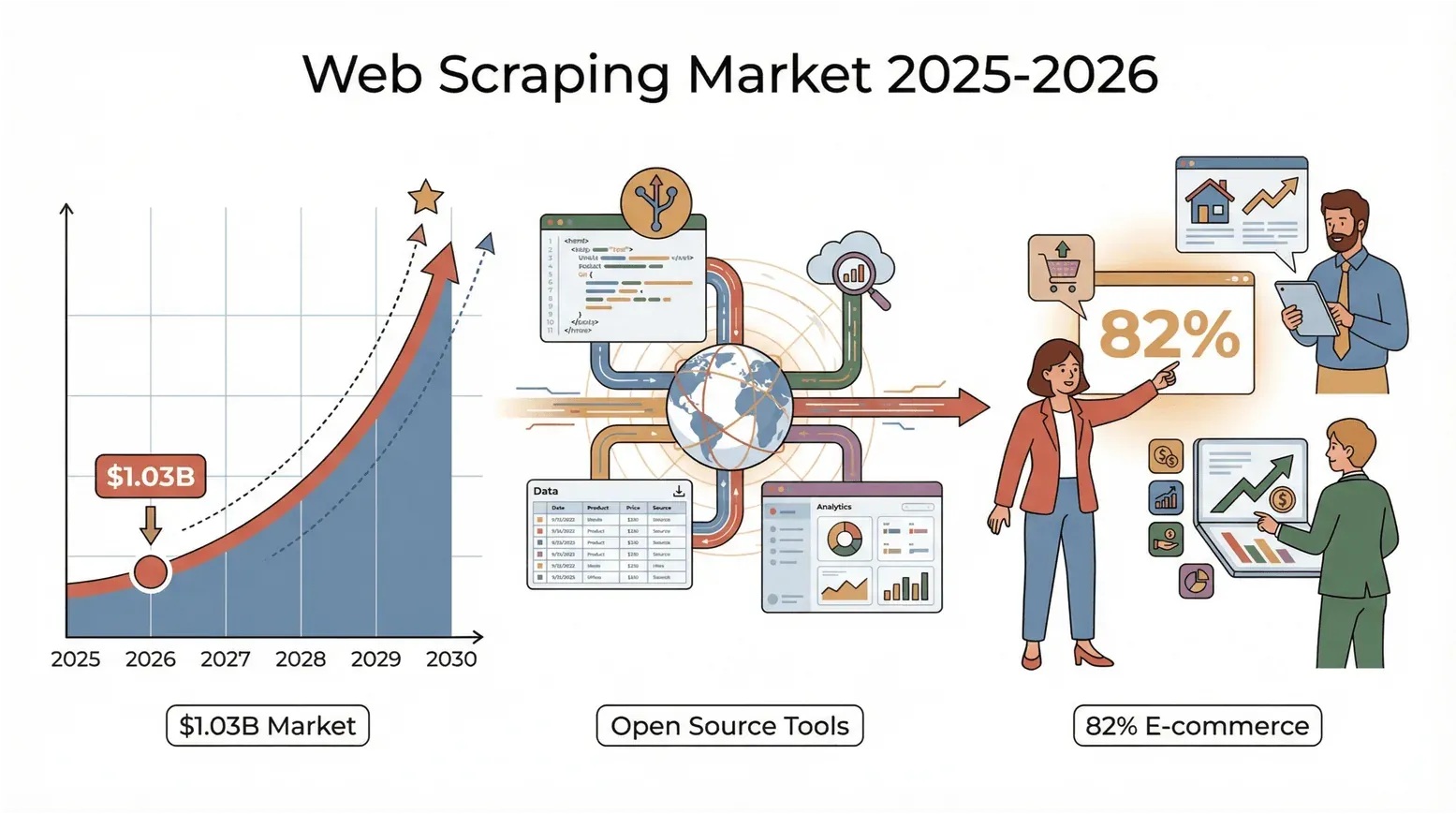
Maar er is ook goed nieuws: open-source webscrapingtools zijn krachtiger, toegankelijker en meer community-gedreven dan ooit. Of je nu een Python-pro bent, een JavaScript-nerd of een zakelijke gebruiker die gewoon data wil zonder gedoe, er is altijd wel een tool die bij je past. Ik heb jarenlang in SaaS en automatisering gewerkt en deze wereld zien evolueren. Laten we daarom duiken in de 5 beste open-source webscrapingtools die je in 2026 moet bekijken — plus hoe je de juiste kiest voor jouw situatie




