

Gebroken links. Verweesde pagina’s. Een “test”-pagina uit 2019 die Google op de een of andere manier heeft geïndexeerd. Als je een website beheert, dan ken je die frustratie vast wel.
Een goede crawler pikt dat allemaal op — en brengt je volledige site in kaart, zodat je echt kunt ingrijpen waar nodig. Maar veel mensen halen “web crawler” en “web scraper” door elkaar. Dat is niet hetzelfde.
Ik heb 10 gratis crawlers getest op echte websites. Sommige zijn ideaal voor SEO-audits. Andere zijn juist beter voor data-extractie. Dit werkte wel — en dit niet.
Wat is een website crawler? De basis uitgelegd
Laten we eerst een misverstand uit de weg ruimen: een website crawler is niet hetzelfde als een web scraper. Ik weet het, die termen worden vaak door elkaar gebruikt, maar in de kern zijn het verschillende tools. Zie een crawler als de kaartmaker van je website — hij verkent elk hoekje en gaatje, volgt alle links en maakt een kaart van al je pagina’s. De taak van een crawler is ontdekken: URL’s vinden, de sitestructuur in kaart brengen en content indexeren. Dat is precies wat zoekmachines zoals Google doen met hun bots, en wat SEO-tools gebruiken om de gezondheid van je site te controleren (Thunderbit Blog: Wat is een web crawler?).
Een web scraper daarentegen is de dataverzamelaar. Die geeft niets om de volledige kaart — hij wil gewoon de schat eruit halen: productprijzen, bedrijfsnamen, reviews, e-mails, noem maar op. Scrapers halen specifieke velden uit de pagina’s die crawlers vinden (Thunderbit Blog: Hoe crawl je een website?).
Een simpele vergelijking:
- Crawler: De persoon die elk gangpad in een supermarkt afloopt en alle producten inventariseert.
- Scraper: De persoon die rechtstreeks naar het koffieschap loopt en de prijs van elke biologische blend noteert.
Waarom is dit belangrijk? Omdat je, als je alleen alle pagina’s op je site wilt vinden voor bijvoorbeeld een SEO-audit, een crawler nodig hebt. Wil je alle productprijzen van de site van een concurrent ophalen, dan heb je een scraper nodig — of idealiter een tool die beide kan.
Waarom een online web crawler gebruiken? Belangrijkste zakelijke voordelen
Waarom zou je überhaupt een web crawler inzetten? Nou, het web wordt er niet kleiner op. Sterker nog, meer dan 54% van de enterprise-merken gebruikt speciale crawling-platforms om hun sites te optimaliseren, en sommige SEO-tools crawlen dagelijks 7 miljard pagina’s.
Dit is wat crawlers voor je kunnen doen:
- SEO-audits: Vind gebroken links, ontbrekende titels, dubbele content, verweesde pagina’s en meer (SEO.ai).
- Linkcontrole & QA: Pak 404’s en redirect-lussen op voordat je gebruikers dat doen (Screaming Frog).
- Sitemap-generatie: Maak automatisch XML-sitemaps voor zoekmachines en planning (PowerMapper).
- Contentinventaris: Bouw een overzicht van al je pagina’s, hun hiërarchie en metadata.
- Compliance & toegankelijkheid: Controleer elke pagina op WCAG-, SEO- en wettelijke vereisten (SiteOne Crawler).
- Prestaties & beveiliging: Signaleer trage pagina’s, te grote afbeeldingen of beveiligingsproblemen (SiteOne Crawler).
- Data voor AI & analyse: Voer gecrawlde data in analyse- of AI-tools in (Thunderbit Blog: Crawl4AI review).
Hier is een snelle tabel die gebruiksscenario’s koppelt aan zakelijke rollen:
| Gebruikssituatie | Ideaal voor | Voordeel / resultaat |
|---|---|---|
| SEO- & site-audits | Marketing, SEO, eigenaren van kleine bedrijven | Technische problemen vinden, structuur optimaliseren, rankings verbeteren |
| Contentinventaris & QA | Contentmanagers, webmasters | Content auditen of migreren, gebroken links/afbeeldingen opsporen |
| Leadgeneratie (scraping) | Sales, business development | Prospecting automatiseren, CRM vullen met verse leads |
| Concurrentie-inzicht | E-commerce, productmanagers | Prijzen, nieuwe producten en voorraadwijzigingen van concurrenten volgen |
| Sitemap- & structuurcloning | Developers, DevOps, consultants | Sitestructuur klonen voor redesigns of back-ups |
| Contentaggregatie | Onderzoekers, media, analisten | Gegevens uit meerdere sites verzamelen voor analyse of trendmonitoring |
| Marktonderzoek | Analisten, AI-trainings-teams | Grote datasets verzamelen voor analyse of AI-modeltraining |
(Thunderbit Blog: Hoe crawl je een website?)
Hoe we de beste gratis website crawler-tools hebben gekozen
Ik heb veel late avonden besteed (en meer koffie gedronken dan goed voor me is) aan het uitpluizen van crawler-tools, documentatie lezen en tests uitvoeren. Hierop lette ik:
- Technische mogelijkheden: Kan de tool moderne sites aan (JavaScript, logins, dynamische content)?
- Gebruiksgemak: Is hij toegankelijk voor niet-technische gebruikers, of heb je command-line tovenarij nodig?
- Beperkingen van het gratis plan: Is het echt gratis, of vooral een lokkertje?
- Online toegankelijkheid: Is het een cloudtool, desktop-app of codebibliotheek?
- Unieke functies: Doet de tool iets bijzonders — zoals AI-extractie, visuele sitemaps of event-gedreven crawling?
Ik heb elke tool getest, gebruikersfeedback bekeken en functies naast elkaar gelegd. Als een tool me de neiging gaf mijn laptop uit het raam te gooien, haalde hij de lijst niet.
Snelle vergelijkingstabel: 10 beste gratis website crawlers in één oogopslag
| Tool & type | Belangrijkste functies | Beste use case | Technische kennis nodig | Details gratis plan |
|---|---|---|---|---|
| BrightData (Cloud/API) | Enterprise crawling, proxies, JS-rendering, CAPTCHA-oplossing | Dataverzameling op grote schaal | Enige technische kennis is handig | Gratis proefperiode: 3 scrapers, 100 records per stuk (ongeveer 300 records totaal) |
| Crawlbase (Cloud/API) | API-crawling, anti-bot, proxies, JS-rendering | Developers die backend crawl-infrastructuur nodig hebben | API-integratie | Gratis: ~5.000 API-calls gedurende 7 dagen, daarna 1.000/maand |
| ScraperAPI (Cloud/API) | Proxy-rotatie, JS-rendering, asynchrone crawl, vooraf gebouwde endpoints | Developers, prijsmonitoring, SEO-data | Minimale setup | Gratis: 5.000 API-calls gedurende 7 dagen, daarna 1.000/maand |
| Diffbot Crawlbot (Cloud) | AI-crawl + extractie, knowledge graph, JS-rendering | Gestructureerde data op schaal, AI/ML | API-integratie | Gratis: 10.000 credits/maand (ongeveer 10k pagina’s) |
| Screaming Frog (Desktop) | SEO-audit, link/meta-analyse, sitemap, custom extractie | SEO-audits, sitebeheerders | Desktop-app, GUI | Gratis: 500 URL’s per crawl, alleen basisfuncties |
| SiteOne Crawler (Desktop) | SEO, performance, toegankelijkheid, beveiliging, offline export, Markdown | Developers, QA, migratie, documentatie | Desktop/CLI, GUI | Gratis & open source, 1.000 URL’s in GUI-rapport (instelbaar) |
| Crawljax (Java, OpenSrc) | Event-driven crawl voor JS-zware sites, statische export | Developers, QA voor dynamische webapps | Java, CLI/config | Gratis & open source, geen limieten |
| Apache Nutch (Java, OpenSrc) | Gedistribueerd, plugin-gebaseerd, Hadoop-integratie, custom search | Eigen zoekmachines, crawls op grote schaal | Java, command-line | Gratis & open source, alleen infrastructuurkosten |
| YaCy (Java, OpenSrc) | Peer-to-peer crawl & search, privacy, web/intranet-indexering | Privézoekfunctie, decentralisatie | Java, browser-UI | Gratis & open source, geen limieten |
| PowerMapper (Desktop/SaaS) | Visuele sitemaps, toegankelijkheid, QA, browsercompatibiliteit | Agencies, QA, visuele mapping | GUI, eenvoudig | Gratis proefperiode: 30 dagen, 100 pagina’s (desktop) of 10 pagina’s (online) per scan |
BrightData: cloud website crawler van enterprise-niveau

BrightData is de zwaargewicht onder de web crawlers. Het is een cloudplatform met een enorm proxy-netwerk, JavaScript-rendering, CAPTCHA-oplossing en een IDE voor custom crawls. Als je data op grote schaal verzamelt — bijvoorbeeld honderden e-commercesites volgt voor prijsvergelijking — dan is de infrastructuur van BrightData nauwelijks te verslaan (aimultiple.com).
Sterke punten:
- Kan moeilijke sites met anti-botmaatregelen aan
- Schaalbaar voor enterprise-behoeften
- Vooraf gebouwde templates voor veelvoorkomende sites
Beperkingen:
- Geen permanent gratis plan (alleen een proefperiode: 3 scrapers, 100 records per stuk)
- Kan overdreven zijn voor simpele audits
- Voor niet-technische gebruikers is er wel een leercurve
Als je webdata op schaal moet crawlen, is BrightData alsof je een Formule 1-auto huurt. Verwacht alleen niet dat hij na je proefrit gratis blijft rijden (BrightData Pricing).
Crawlbase: API-gedreven gratis web crawler voor developers

Crawlbase (voorheen ProxyCrawl) draait volledig om programmatisch crawlen. Je roept hun API aan met een URL en krijgt de HTML terug — terwijl proxies, geo-targeting en CAPTCHA’s op de achtergrond worden afgehandeld (Capterra).
Sterke punten:
- Hoge succespercentages (99%+)
- Kan JavaScript-zware sites verwerken
- Ideaal om in je eigen apps of workflows te integreren
Beperkingen:
- Vereist enige API- of SDK-integratie
- Gratis plan: ~5.000 API-calls gedurende 7 dagen, daarna 1.000/maand
Als je een developer bent die op schaal wil crawlen — en misschien ook wil scrapen — zonder proxies te beheren, is Crawlbase een solide keuze (Crawlbase Pricing).
ScraperAPI: dynamisch web crawlen eenvoudiger maken

ScraperAPI is de API van “haal het gewoon voor me op”. Jij geeft een URL door, de tool regelt proxies, headless browsers en anti-botmaatregelen, en levert de HTML terug (of voor sommige sites zelfs gestructureerde data). Vooral voor dynamische pagina’s is dit een sterke keuze, en het gratis plan is royaal (ScraperAPI Pricing).
Sterke punten:
- Super eenvoudig voor developers (gewoon een API-call)
- Ondersteunt CAPTCHA’s, IP-blokkades en JavaScript
- Gratis: 5.000 API-calls gedurende 7 dagen, daarna 1.000/maand
Beperkingen:
- Geen visuele crawl-rapporten
- Wil je links blijven volgen, dan moet je de crawl-logica zelf scripten
Als je web crawling binnen enkele minuten in je codebase wilt stoppen, is ScraperAPI een no-brainer.
Diffbot Crawlbot: geautomatiseerde ontdekking van sitestructuren

Diffbot Crawlbot wordt pas echt slim. Het crawlt niet alleen — het gebruikt AI om pagina’s te classificeren en gestructureerde data (artikelen, producten, evenementen, enz.) naar JSON om te zetten. Het is alsof je een robot-stagiair hebt die echt begrijpt wat hij leest (Diffbot Free Plan).
Sterke punten:
- AI-gedreven extractie, niet alleen crawling
- Kan overweg met JavaScript en dynamische content
- Gratis: 10.000 credits/maand (ongeveer 10k pagina’s)
Beperkingen:
- Gericht op developers (API-integratie)
- Geen visuele SEO-tool — meer voor dataprojecten
Heb je op schaal gestructureerde data nodig, zeker voor AI of analyse, dan is Diffbot een krachtpatser.
Screaming Frog: gratis desktop SEO crawler

Screaming Frog is de klassieke desktop crawler voor SEO-audits. De gratis versie crawlt tot 500 URL’s per scan en geeft je alles: gebroken links, meta-tags, dubbele content, sitemaps en meer (Screaming Frog User Guide).
Sterke punten:
- Snel, grondig en vertrouwd in de SEO-wereld
- Geen code nodig — gewoon URL invoeren en gaan
- Gratis voor maximaal 500 URL’s per crawl
Beperkingen:
- Alleen desktop (geen cloudversie)
- Geavanceerde functies (JS-rendering, planning) vereisen een betaalde licentie
Als SEO serieus voor je is, is Screaming Frog een must-have — verwacht alleen niet dat hij gratis je site van 10.000 pagina’s crawlt.
SiteOne Crawler: export en documentatie van statische sites

SiteOne Crawler is het Zwitsers zakmes voor technische audits. Het is open source, platformonafhankelijk en kan je site crawlen, auditen en zelfs exporteren naar Markdown voor documentatie of offline gebruik (SiteOne Crawler).
Sterke punten:
- Dekking voor SEO, performance, toegankelijkheid en beveiliging
- Exporteert sites voor archivering of migratie
- Gratis & open source, zonder gebruikslimieten
Beperkingen:
- Technischer dan sommige GUI-tools
- Auditrapport in de GUI is standaard beperkt tot 1.000 URL’s (instelbaar)
Ben je developer, QA’er of consultant en wil je diepgaand inzicht — en houd je van open source — dan is SiteOne een verborgen parel.
Crawljax: open-source Java web crawler voor dynamische pagina’s
Crawljax is een specialist: ontworpen om moderne, JavaScript-zware webapps te crawlen door gebruikersinteracties na te bootsen (kliks, formulierinvoer, enz.). Het is event-driven en kan zelfs een statische versie van een dynamische site uitspugen (Wikipedia: Crawljax).
Sterke punten:
- Uitstekend voor SPAs en sites met veel AJAX
- Open source en uitbreidbaar
- Geen gebruikslimieten
Beperkingen:
- Vereist Java en wat programmeer- of configuratiekennis
- Niet geschikt voor niet-technische gebruikers
Als je een React- of Angular-app wilt crawlen alsof je een echte gebruiker bent, dan is Crawljax je vriend.
Apache Nutch: schaalbare gedistribueerde website crawler

Apache Nutch is de oerklassieker onder open-source crawlers. Het is gebouwd voor enorme, gedistribueerde crawls — denk aan je eigen zoekmachine bouwen of miljoenen pagina’s indexeren (Martechvibe).
Sterke punten:
- Schaalt naar miljarden pagina’s met Hadoop
- Zeer configureerbaar en uitbreidbaar
- Gratis & open source
Beperkingen:
- Steile leercurve (Java, command-line, configuratie)
- Niet voor kleine sites of casual gebruikers
Wil je web op grote schaal crawlen en schrik je niet van wat command-line werk, dan is Nutch jouw tool.
YaCy: peer-to-peer web crawler en zoekmachine
YaCy is een unieke, gedecentraliseerde crawler en zoekmachine. Elke instantie crawlt en indexeert sites, en je kunt deelnemen aan een peer-to-peer netwerk om indexen te delen met anderen (TechRadar: YaCy).
Sterke punten:
- Privacygericht, geen centrale server
- Ideaal voor privézoekfuncties of intranetsearch
- Gratis & open source
Beperkingen:
- Resultaten hangen af van de dekking van het netwerk
- Enige setup nodig (Java, browser-UI)
Ben je fan van decentralisatie of wil je je eigen zoekmachine bouwen, dan is YaCy een fascinerende optie.
PowerMapper: visuele sitemapgenerator voor UX en QA

PowerMapper draait helemaal om het visualiseren van de structuur van je site. Het crawlt je site en genereert interactieve sitemaps, en controleert daarnaast toegankelijkheid, browsercompatibiliteit en basis-SEO (Slickplan Review).
Sterke punten:
- Visuele sitemaps zijn ideaal voor bureaus en designers
- Controleert toegankelijkheid en compliance
- Makkelijke GUI, geen technische skills nodig
Beperkingen:
- Alleen proefperiode (30 dagen, 100 pagina’s desktop / 10 pagina’s online per scan)
- Volledige versie is betaald
Als je een sitemap aan klanten wilt laten zien of compliance wilt checken, is PowerMapper een handige tool.
De juiste gratis web crawler kiezen voor jouw situatie
Met zoveel opties: hoe kies je? Hier is mijn korte leidraad:
- Voor SEO-audits: Screaming Frog (kleine sites), PowerMapper (visueel), SiteOne (diepe audits)
- Voor dynamische webapps: Crawljax
- Voor grootschalige of custom search: Apache Nutch, YaCy
- Voor developers die API-toegang nodig hebben: Crawlbase, ScraperAPI, Diffbot
- Voor documentatie of archivering: SiteOne Crawler
- Voor enterprise-schaal met een proefperiode: BrightData, Diffbot
Belangrijke factoren om mee te nemen:
- Schaalbaarheid: Hoe groot is je site of crawltaak?
- Gebruiksgemak: Ben je comfortabel met code, of wil je vooral point-and-click?
- Data-export: Heb je CSV, JSON of integratie met andere tools nodig?
- Support: Is er een community of documentatie als je vastloopt?
Wanneer web crawling en web scraping samenkomen: waarom Thunderbit slimmer is
Scrape data van elke website met AI Get Started Free
De realiteit is: de meeste mensen crawlen websites niet alleen om mooie kaartjes te maken. Het echte doel is meestal om gestructureerde data te krijgen — of het nu om productlijsten, contactgegevens of contentinventarissen gaat. Daar komt Thunderbit om de hoek kijken.
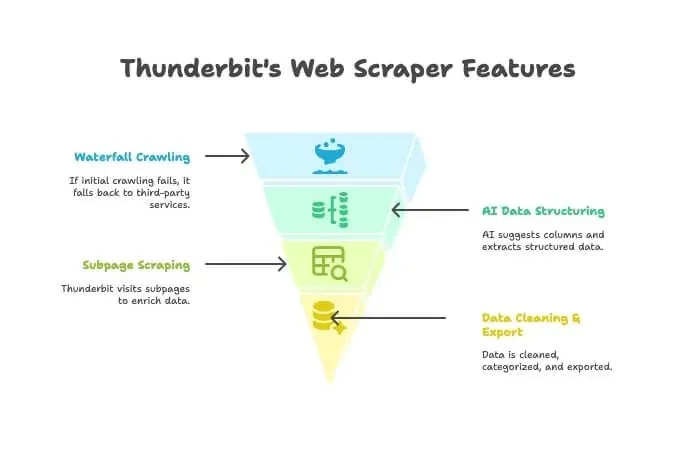
Thunderbit is niet zomaar een crawler of scraper — het is een AI-aangedreven Chrome-extensie die beide combineert. Zo werkt het:
- AI-crawler: Thunderbit verkent de site, net als een crawler.
- Waterfall crawling: Als Thunderbit’s eigen engine een pagina niet kan laden (bijvoorbeeld door een stevige anti-botbarrière), valt het automatisch terug op externe crawldiensten — zonder handmatige setup.
- AI-data-structurering: Zodra de HTML binnen is, stelt Thunderbit’s AI de juiste kolommen voor en haalt het gestructureerde data eruit (namen, prijzen, e-mails, enz.) zonder dat jij één selector hoeft te schrijven.
- Subpage scraping: Moet je details van elke productpagina halen? Thunderbit kan automatisch elke subpagina bezoeken en je tabel verrijken.
- Datacleaning & export: Het kan data samenvatten, categoriseren, vertalen en met één klik exporteren naar Excel, Google Sheets, Airtable of Notion.
- No-code eenvoud: Als je een browser kunt gebruiken, kun je Thunderbit gebruiken. Geen code, geen proxies, geen gedoe.
Wanneer kies je Thunderbit boven een traditionele crawler?
- Als je einddoel een nette, bruikbare spreadsheet is — niet alleen een lijst met URL’s.
- Als je het hele proces wilt automatiseren (crawl, extract, opschonen, exporteren) op één plek.
- Als je je tijd en gemoedsrust waardeert.
Je kunt Thunderbit’s Chrome-extensie hier downloaden en zelf zien waarom zoveel zakelijke gebruikers overstappen.
Probeer Thunderbit gratis – AI Web Scraper
Conclusie: haal meer uit gratis website crawlers
Wat is data scraping en hoe doe je het Get Started Free
Website crawlers zijn enorm geëvolueerd. Of je nu marketeer, developer of gewoon iemand bent die zijn site gezond wil houden: er is een gratis tool — of in elk geval een tool met gratis proefperiode — voor jou. Van enterprise-platforms zoals BrightData en Diffbot, tot open-source parels zoals SiteOne en Crawljax, tot visuele mappers zoals PowerMapper: de keuze is groter dan ooit.
Maar als je op zoek bent naar een slimmere, geïntegreerde manier om van “ik heb deze data nodig” naar “hier is mijn spreadsheet” te gaan, probeer dan Thunderbit. Het is gebouwd voor zakelijke gebruikers die resultaat willen, niet alleen rapporten.
Klaar om te beginnen met crawlen? Download een tool, draai een scan en ontdek wat je hebt gemist. En als je van crawlen naar bruikbare data wilt in twee klikken, bekijk Thunderbit.
Voor meer diepgaande analyses en praktische handleidingen, bezoek de Thunderbit Blog.
Website-data scrapen met AI in 2 klikken
Probeer AI Web Scraper Get Started Free
FAQ
Wat is het verschil tussen een website crawler en een web scraper?
Een crawler ontdekt en brengt alle pagina’s op een site in kaart (denk: een inhoudsopgave maken). Een scraper haalt specifieke datavelden op (zoals prijzen, e-mails of reviews) uit die pagina’s. Crawlers vinden, scrapers halen eruit (Thunderbit Blog: Wat is een web crawler?).
Welke gratis web crawler is het beste voor niet-technische gebruikers?
Voor kleine sites en SEO-audits is Screaming Frog gebruiksvriendelijk. Voor visuele mapping is PowerMapper sterk (tijdens de proefperiode). Thunderbit is het makkelijkst als je gestructureerde data wilt en een no-code ervaring in de browser zoekt.
Zijn er websites die web crawlers blokkeren?
Ja — sommige sites gebruiken robots.txt-bestanden of anti-botmaatregelen (zoals CAPTCHA’s of IP-blokkades) om crawlers te weren. Tools zoals ScraperAPI, Crawlbase en Thunderbit (met waterfall crawling) kunnen hier vaak omheen werken, maar crawl altijd verantwoord en respecteer de regels van de site (BrightData Pricing).
Hebben gratis website crawlers limieten op pagina’s of functies?
Meestal wel. Bijvoorbeeld: de gratis versie van Screaming Frog is beperkt tot 500 URL’s per crawl; de proefperiode van PowerMapper is 100 pagina’s. API-gebaseerde tools hebben vaak maandelijkse creditlimieten. Open-source tools zoals SiteOne of Crawljax hebben meestal geen harde limieten, maar je bent dan wel gebonden aan je eigen hardware.
Is het gebruik van een web crawler legaal en privacyconform?
In het algemeen is het crawlen van publieke webpagina’s legaal, maar controleer altijd de gebruiksvoorwaarden en robots.txt van een site. Crawl nooit privé- of met een wachtwoord beveiligde data zonder toestemming, en houd rekening met privacywetgeving als je persoonsgegevens verzamelt (Crawlbase Guide).




