
Het web is allang niet meer alleen een digitale speeltuin — het is ’s werelds grootste datawarehouse, en iedereen, van salesteams tot marktanalisten, probeert er zoveel mogelijk uit te halen. Maar laten we eerlijk zijn: webdata handmatig verzamelen is ongeveer net zo leuk als IKEA-meubels in elkaar zetten zonder handleiding, en dan met twee keer zoveel schroeven over.
Nu bedrijven steeds meer leunen op realtime marktinzichten, concurrentieprijzen en leadgeneratie, is de behoefte aan efficiënte, betrouwbare tools voor data crawlen groter dan ooit. Sterker nog, bijna voor besluitvorming, en de wereldwijde markt voor webscraping staat op het punt om .
Als je klaar bent met kopiëren en plakken, geen nieuwe leads meer wilt missen, of gewoon wilt zien wat er mogelijk is als je automatisering het zware werk laat doen, ben je hier aan het juiste adres. Ik heb jaren besteed aan het bouwen en testen van tools voor webextractie (en ja, ik leid het team bij ), dus ik weet uit eerste hand hoe de juiste tool uren handwerk kan terugbrengen tot een klus van twee klikken. Of je nu geen programmeur bent en snel resultaat wilt, of een developer die volledige controle zoekt, deze lijst met de top 10 beste tools voor data crawlen helpt je de juiste match te vinden.
Waarom de juiste tools voor data crawlen belangrijk zijn
Laten we eerlijk zijn: het verschil tussen een goede tool voor data crawlen en een middelmatige is niet alleen gemak — het is een directe route naar bedrijfsgroei. Als je webextractie automatiseert, bespaar je niet alleen tijd (een G2-recensent meldde zelfs ), maar verklein je ook de foutmarge, ontdek je nieuwe kansen en zorg je ervoor dat je team altijd werkt met de meest actuele en nauwkeurige data. Handmatig onderzoek is traag, foutgevoelig en vaak al verouderd tegen de tijd dat je klaar bent. Met de juiste tool kun je concurrenten volgen, prijzen monitoren of leadlijsten opbouwen in minuten — niet in dagen.
Een mooi voorbeeld: een beautyretailer gebruikte webscraping om de voorraad en prijzen van concurrenten te volgen, . Dát is het soort impact dat je simpelweg niet haalt met spreadsheets en handwerk.
Hoe we de beste tools voor data crawlen hebben beoordeeld
Met zoveel opties kan het kiezen van de juiste tool voor data crawlen voelen als speeddaten op een techconferentie. Dit zijn de criteria die ik heb gebruikt om de beste tools van de rest te onderscheiden:
- Gebruiksgemak: Kun je aan de slag zonder een PhD in Python? Is er een visuele interface of AI-hulp voor niet-programmeurs?
- Automatiseringsmogelijkheden: Ondersteunt de tool paginering, subpagina’s, dynamische content en planning? Kan hij voor grote taken in de cloud draaien?
- Prijs en schaalbaarheid: Is er een gratis versie of een betaalbaar instapplan? Hoe lopen de kosten op naarmate je databehoefte groeit?
- Functies en integraties: Kun je exporteren naar Excel, Google Sheets of via API? Zijn er sjablonen, planning of ingebouwde opschoonfuncties voor data?
- Het meest geschikt voor: Voor wie is de tool echt bedoeld — zakelijke gebruikers, developers of enterprise-teams?
Achteraan vind je ook een korte vergelijkingstabel, zodat je kunt zien hoe de tools zich tot elkaar verhouden.
Nu duiken we in de top 10 beste tools voor data crawlen voor efficiënte webextractie in 2026.
1. Thunderbit
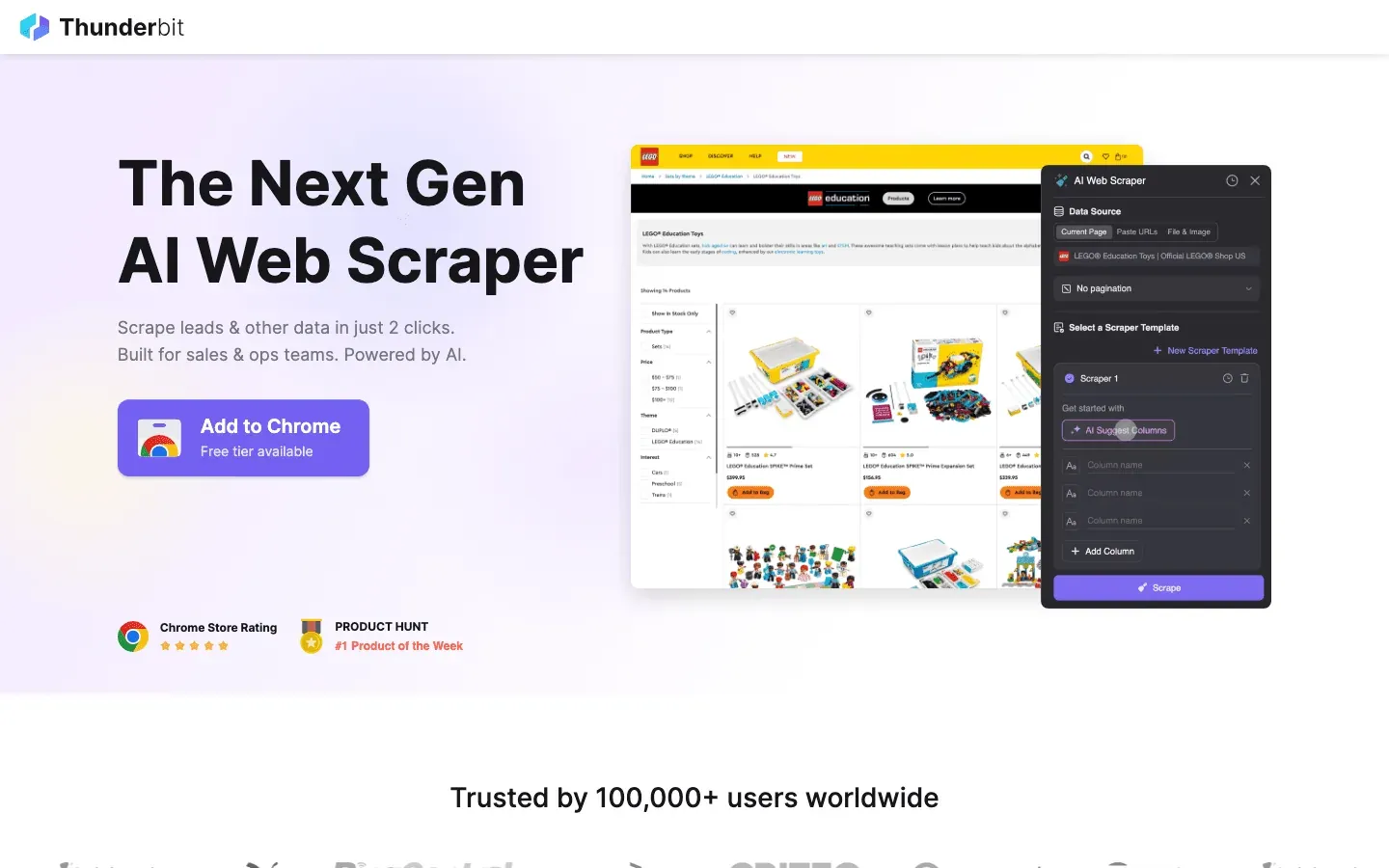 is mijn vaste aanbeveling voor iedereen die data crawlen net zo makkelijk wil maken als eten bestellen. Thunderbit is gebouwd als een AI-gestuurde Chrome-extensie en draait helemaal om scrapen in 2 klikken: klik op “AI Suggest Fields” en laat de AI bepalen wat er op de pagina staat, klik daarna op “Scrape” om de data op te halen. Geen code, geen gedoe met selectors — gewoon direct resultaat.
is mijn vaste aanbeveling voor iedereen die data crawlen net zo makkelijk wil maken als eten bestellen. Thunderbit is gebouwd als een AI-gestuurde Chrome-extensie en draait helemaal om scrapen in 2 klikken: klik op “AI Suggest Fields” en laat de AI bepalen wat er op de pagina staat, klik daarna op “Scrape” om de data op te halen. Geen code, geen gedoe met selectors — gewoon direct resultaat.
Waarom is Thunderbit zo geliefd bij salesteams, marketingteams en e-commerceteams? Omdat het is ontworpen voor echte bedrijfsworkflows:
- AI Suggest Fields: De AI leest de pagina en stelt de beste kolommen voor om uit te lezen — namen, prijzen, e-mails, noem maar op.
- Scraping van subpagina’s: Meer details nodig? Thunderbit kan automatisch elke subpagina bezoeken (zoals productpagina’s of LinkedIn-profielen) en je tabel verrijken.
- Direct exporteren: Zet je data rechtstreeks door naar Excel, Google Sheets, Airtable of Notion. Alle exports zijn gratis.
- Sjablonen met één klik: Voor populaire sites (Amazon, Zillow, Instagram) kun je direct sjablonen gebruiken voor nog sneller resultaat.
- Gratis data-export: Er zit geen betaalmuur op het exporteren van je data.
- Geplande scraping: Stel terugkerende taken in gewone taal in (“elke maandag om 9 uur”) — ideaal voor prijsmonitoring of wekelijkse lead-updates.
Thunderbit werkt met een creditsysteem (1 credit = 1 rij), met een voor maximaal 6 pagina’s (of 10 met een trial-boost). Betaalde abonnementen beginnen bij $15/maand voor 500 credits, waardoor het betaalbaar is voor teams van elke omvang.
Wil je zien hoe Thunderbit in de praktijk werkt, bekijk dan ons of . Dit is de tool die ik had willen hebben toen ik nog verdronk in handmatige data-invoer.
2. Octoparse
 is een zwaargewicht in de wereld van data crawlen, vooral voor enterprise-gebruikers die serieuze kracht nodig hebben. Het biedt een visuele desktopinterface (Windows en Mac) waarmee je point-and-click-extractieworkflows kunt bouwen — geen code nodig. Maar laat je niet misleiden door de vriendelijke UI: onder de motorkap verwerkt Octoparse inlogschermen, infinite scroll, roterende proxies en zelfs CAPTCHA-oplossing.
is een zwaargewicht in de wereld van data crawlen, vooral voor enterprise-gebruikers die serieuze kracht nodig hebben. Het biedt een visuele desktopinterface (Windows en Mac) waarmee je point-and-click-extractieworkflows kunt bouwen — geen code nodig. Maar laat je niet misleiden door de vriendelijke UI: onder de motorkap verwerkt Octoparse inlogschermen, infinite scroll, roterende proxies en zelfs CAPTCHA-oplossing.
- 500+ vooraf gebouwde sjablonen: Begin snel met sjablonen voor Amazon, Twitter, LinkedIn en meer.
- Cloudgebaseerde scraping: Laat taken draaien op de servers van Octoparse, plan processen in en schaal op voor grote projecten.
- API-toegang: Integreer gescrapete data rechtstreeks in je bedrijfsapps of databases.
- Geavanceerde automatisering: Ondersteunt dynamische content, paginering en workflows met meerdere stappen.
De gratis versie dekt 10 taken plus een royale maandelijkse exportlimiet van 50.000 rijen, dus het is een echt bruikbaar instapniveau — niet zomaar een lokkertje. Betaalde abonnementen beginnen bij $69/maand voor Standard (jaarlijks gefactureerd; ongeveer $82/maand bij maandelijkse betaling) en $249/maand voor Professional. De leercurve is steiler dan die van Thunderbit, maar als je duizenden pagina’s betrouwbaar wilt scrapen en clouduitvoering nodig hebt, blijft Octoparse een van de langst bestaande opties die het serieus waard zijn om te bekijken. Prijzen geverifieerd op op 2026-05-13.
3. Scrapy
 is de gouden standaard voor developers die volledige controle willen over hun data-crawlingprojecten. Het is een open-source Python-framework waarmee je aangepaste spiders (crawlers) voor elke website kunt coderen. Als je het kunt bedenken, kun je het bouwen met Scrapy.
is de gouden standaard voor developers die volledige controle willen over hun data-crawlingprojecten. Het is een open-source Python-framework waarmee je aangepaste spiders (crawlers) voor elke website kunt coderen. Als je het kunt bedenken, kun je het bouwen met Scrapy.
- Volledig programmeerbaar: Schrijf Python-code om precies vast te leggen hoe je een site moet crawlen en parseren.
- Asynchroon en snel: Verwerkt duizenden pagina’s parallel voor grootschalige projecten.
- Uitbreidbaar: Voeg middleware toe voor proxies, headless browsers of logica op maat.
- Sterke community: Veel tutorials, plugins en ondersteuning voor lastige scraping-scenario’s.
Scrapy is gratis en open-source, maar je hebt wel programmeervaardigheden nodig. Heb je een technisch team of wil je een aangepaste pipeline bouwen, dan is Scrapy moeilijk te overtreffen. Voor niet-programmeurs is het echter een flinke berg om te beklimmen.
4. ParseHub
 is een visuele, no-code webscrapingtool die perfect is voor niet-programmeurs die met complexe websites te maken hebben. Met de point-and-click interface kun je elementen selecteren, acties definiëren en scrapingworkflows bouwen — zelfs voor sites met dynamische content of lastige navigatie.
is een visuele, no-code webscrapingtool die perfect is voor niet-programmeurs die met complexe websites te maken hebben. Met de point-and-click interface kun je elementen selecteren, acties definiëren en scrapingworkflows bouwen — zelfs voor sites met dynamische content of lastige navigatie.
- Visuele workflowbouwer: Klik om data te selecteren, paginering in te stellen en pop-ups of dropdowns af te handelen.
- Ondersteunt dynamische content: Werkt met sites met veel JavaScript en interactieve pagina’s.
- Cloudruns en planning: Laat scrapes draaien in de cloud en plan terugkerende taken.
- Export naar CSV, Excel of via API: Eenvoudige integratie met je favoriete tools.
ParseHub biedt een gratis plan (5 projecten), met betaalde abonnementen vanaf . Het is wat duurder dan sommige concurrenten, maar de visuele aanpak maakt het toegankelijk voor analisten, marketeers en onderzoekers die meer nodig hebben dan een simpele Chrome-extensie.
5. Apify
 is zowel een platform als een marktplaats voor webcrawling. Het biedt een enorme bibliotheek met vooraf gebouwde “Actors” (kant-en-klare scrapers) voor populaire sites, plus de mogelijkheid om je eigen crawlers in de cloud te bouwen en uit te voeren.
is zowel een platform als een marktplaats voor webcrawling. Het biedt een enorme bibliotheek met vooraf gebouwde “Actors” (kant-en-klare scrapers) voor populaire sites, plus de mogelijkheid om je eigen crawlers in de cloud te bouwen en uit te voeren.
- 5.000+ kant-en-klare Actors: Scrape direct Google Maps, Amazon, Twitter en meer.
- Aangepaste scripting: Developers kunnen JavaScript of Python gebruiken om geavanceerde crawlers te bouwen.
- Schaalbaarheid in de cloud: Laat taken parallel draaien, plan processen in en beheer data in de cloud.
- API en integraties: Koppel resultaten aan je apps, workflows of datapijplijnen.
Apify geeft je $5 gratis platformtegoed om te starten, en schaalt daarna op naar Starter voor $29/maand, Scale voor $199/maand en Business voor $999/maand — elke laag werkt met “platformtegoed + pay-as-you-go voor compute units”, dus het gebruik bepaalt echt de rekening. Er is wat leercurve, maar als je zowel plug-and-play actors wilt als je eigen crawlers wilt schrijven in JS of Python, is Apify een van de sterkste opties op deze lijst. Prijzen geverifieerd op op 2026-05-13.
6. Data Miner
 is een Chrome-extensie die is gebouwd voor snel, sjabloongebaseerd data crawlen. Het is perfect voor zakelijke gebruikers die data uit tabellen of lijsten willen halen zonder enige setup.
is een Chrome-extensie die is gebouwd voor snel, sjabloongebaseerd data crawlen. Het is perfect voor zakelijke gebruikers die data uit tabellen of lijsten willen halen zonder enige setup.
- Enorme sjabloonbibliotheek: Meer dan duizend recepten voor veelgebruik