
Vorige maand begon de Stripe-koppeling van een vriend stilletjes 503-fouten terug te geven om 23.00 uur op een vrijdag. Niemand merkte het tot zaterdagochtend — toen de supportinbox al meer dan 200 boze e-mails had van klanten bij wie het afrekenen was mislukt.
Dat verhaal is niet uitzonderlijk. Een schat de gemiddelde downtime op $5.600 per minuut, terwijl . Het echte bedrag hangt af van verkeer, conversieratio, orderwaarde, SLA-risico en herstelkosten — maar de richting is duidelijk: onbeheerde API’s zijn een bedrijfsrisico, niet alleen een technisch ongemak. En nu en , is monitoring niet langer optioneel. Wat ik met deze gids wilde doen, is iets wat ik elders nog niet had gezien: tools ordenen op jouw use case, de kwaliteit van waarschuwingen beoordelen (niet alleen of ze er zijn), echte prijzen voor 2026 laten zien en meten hoe snel je daadwerkelijk live kunt gaan. Niet zomaar weer een platte lijst met logo’s.
Nog iets: als je API-werk draait om webdata verzamelen, LLM’s voeden, RAG-systemen bouwen, pagina’s van concurrenten monitoren of prijs- en productdata uit websites halen, dan moet het gesprek over “API-tooling” niet stoppen bij uptime monitoring. Je hebt ook een betrouwbare manier nodig om rommelige webpagina’s om te zetten in gestructureerde data. Daar past in deze gids: het is geen uptime monitor, maar wel een van de snelste manieren om websites via een API om te zetten in schone Markdown of schema-gebaseerde JSON.
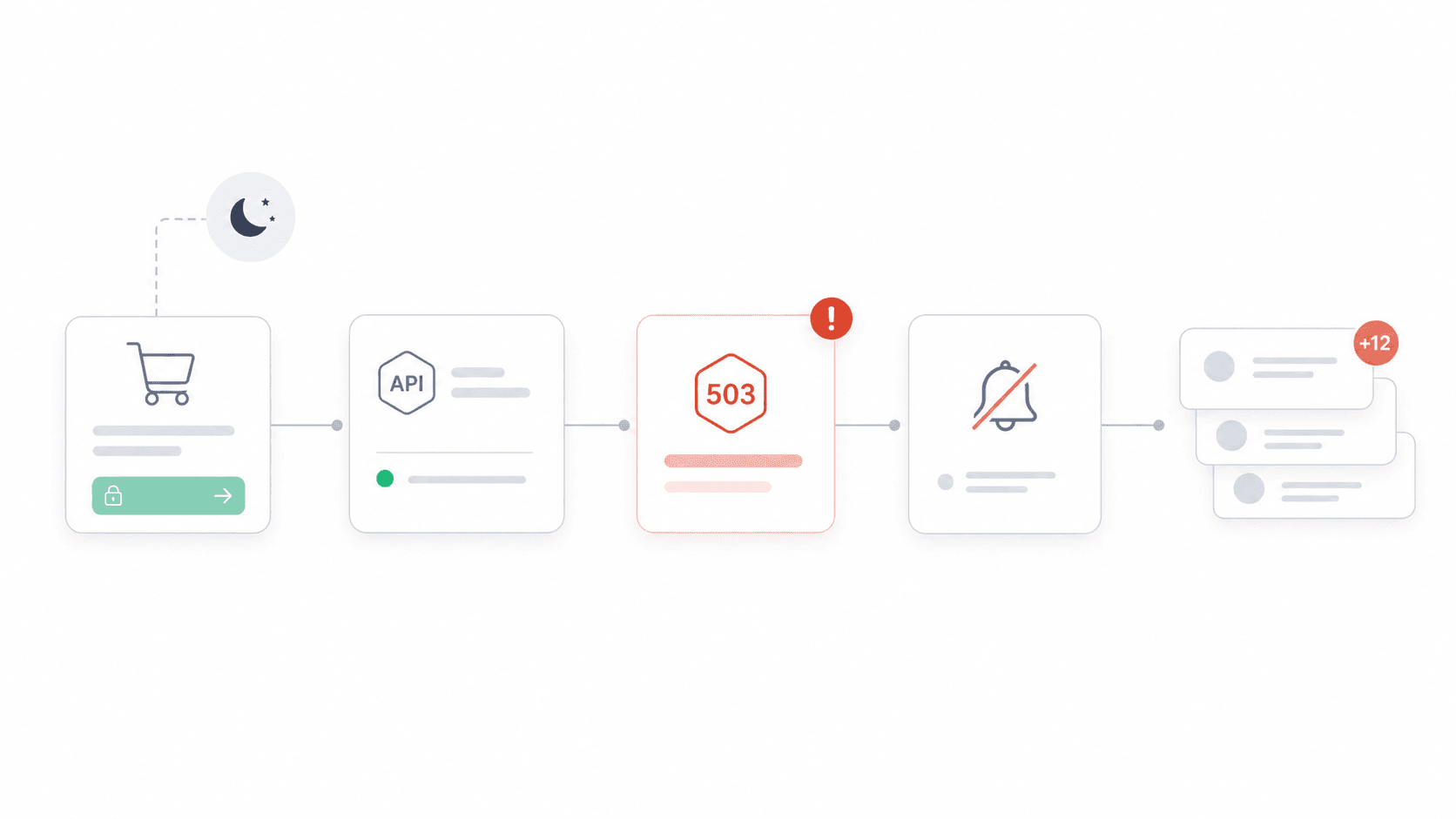
Wat is API-monitoring (en waarom zou jouw team zich erom moeten bekommeren)?
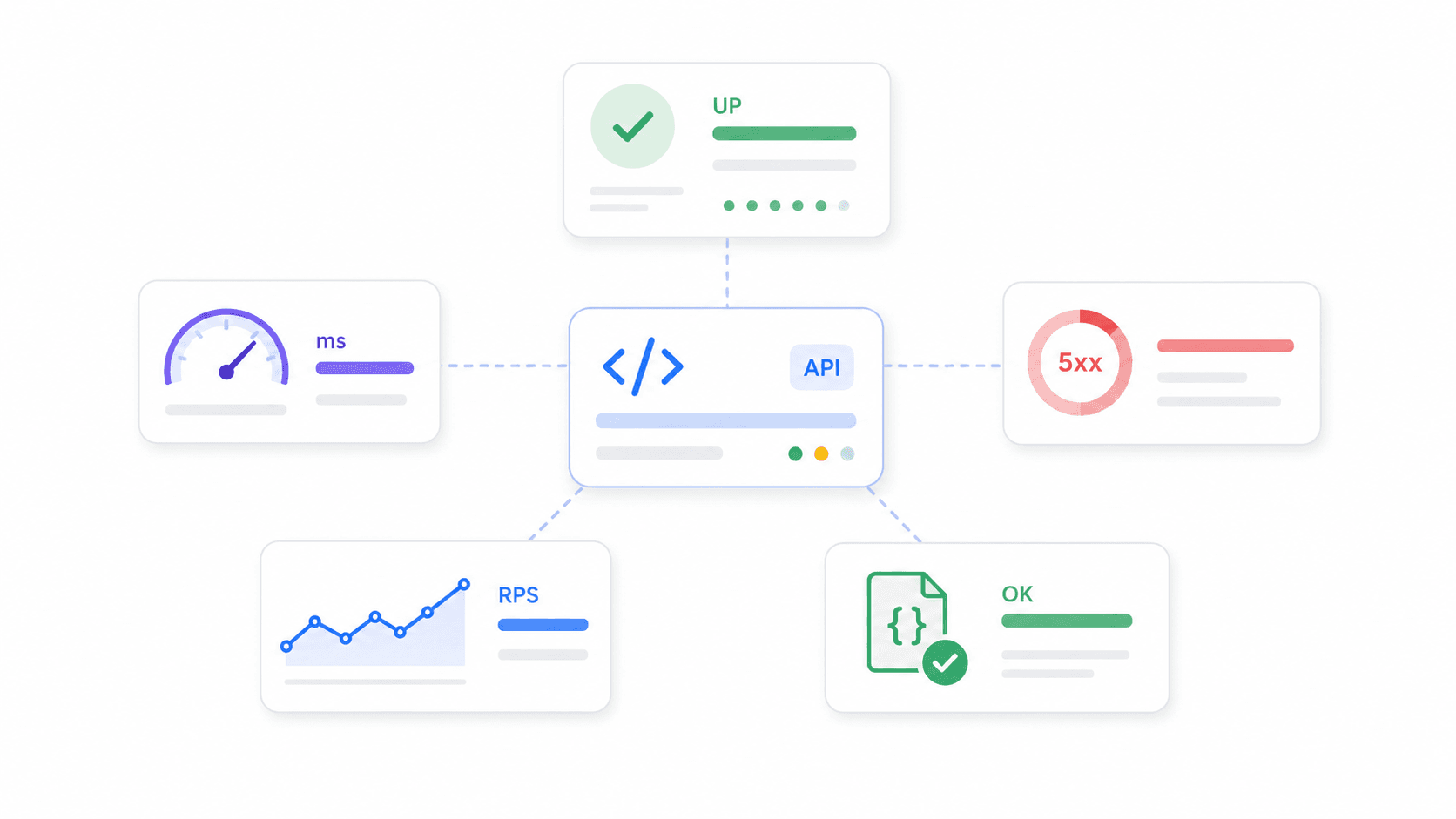
API-monitoring betekent dat je continu controleert of je API-endpoints beschikbaar zijn, snel reageren en de juiste data teruggeven. Dus niet alleen: “staat de server aan?” — een goede monitor valideert HTTP-statuscodes, response payloads, latency, SSL-certificaten, workflows met meerdere stappen (zoals inloggen → zoeken → afrekenen) en zelfs of het schema klopt.
Het verschilt van algemene website-monitoring (die checkt of een pagina laadt) en van APM (Application Performance Monitoring), dat dieper ingaat op code-level traces, databasequeries en interne runtime-details. API-monitoring zit precies op de grens: het test wat je gebruikers, partners en integraties daadwerkelijk ervaren wanneer ze je endpoints aanroepen.
Er is ook een verwante categorie die het noemen waard is: web data API’s. Die monitoren niet of je eigen API gezond is; ze helpen je product of workflow om op een betrouwbare manier externe webdata te verzamelen. Zo kan een webpagina omzetten in schone Markdown, gestructureerde velden als JSON extraheren en batchjobs draaien over veel URL’s. Als jouw “API”-project afhankelijk is van verse leveranciersdata, productpagina’s, openbare vermeldingen, documentatiepagina’s of onderzoeksbronnen, dan kan zo’n data-extractie-API net zo operationeel belangrijk zijn als uptime-checks.
Waarom zouden niet-technische collega’s zich hier iets van aantrekken? Omdat en . Wanneer een payment gateway, auth-service of shipping API uitvalt, is dat geen abstract infrastructuurprobleem — het betekent omzetverlies, kapotte partnercontracten, pieken in support en afnemend vertrouwen. Productmanagers, sales, operations en customer-success teams hebben hier allemaal direct belang bij.
Belangrijke metrics om te volgen:
- Uptimepercentage: aandeel van de tijd dat een endpoint beschikbaar is
- Responstijd / latency: hoe lang het endpoint nodig heeft om te reageren (gemiddelde, p95, p99)
- Foutpercentage: aandeel requests dat 5xx, time-outs of assertion-fouten teruggeeft
- Throughput: requests per seconde/minuut
- Correctheid: of de API verwachte data teruggeeft, niet alleen een 200 OK
Hoe we de beste API-monitoringtools voor 2026 hebben beoordeeld
De meeste artikelen over “de beste API-monitoringtools” stapelen alleen leveranciersnamen en features op elkaar. Ik wilde wat bewuster selecteren — deels omdat ik veel tijd heb besteed aan developerforums, en deels omdat het Thunderbit-team me hielp van leverancierssites om een echte vergelijking te maken (daarover later meer).
Hier is waar we op hebben gewogen:
| Criteria | Waarom het belangrijk is |
|---|---|
| Gebruiksgemak / tijd tot eerste waarschuwing | Kleine teams hebben vandaag dekking nodig, niet pas na een platformproject |
| Slimheid van alerts & minder ruis | Als alerts te luidruchtig zijn, negeren teams ze en missen ze echte incidenten |
| Ruimhartigheid van de free tier | Side projects en vroege startups beginnen vaak gratis |
| Prijstransparantie | Observability-kosten kunnen oplopen door hosts, seats, logs, synthetics en data-ingest |
| Breedte van integraties | Alerts moeten landen waar teams al werken (Slack, PagerDuty, enz.) |
| Schaalbaarheid & diepgang van data | Volwassen teams hebben traces, logs, APM, RBAC, SSO en retentie nodig |
| Kwaliteit van community & support | Open-source teams hebben releasefrequentie nodig; enterprise teams hebben SLA’s nodig |
| Mogelijkheid tot webdata-extractie | AI-apps, RAG-workflows en marktonderzoekstools hebben vaak schone externe data nodig, niet alleen endpoint-uptime |
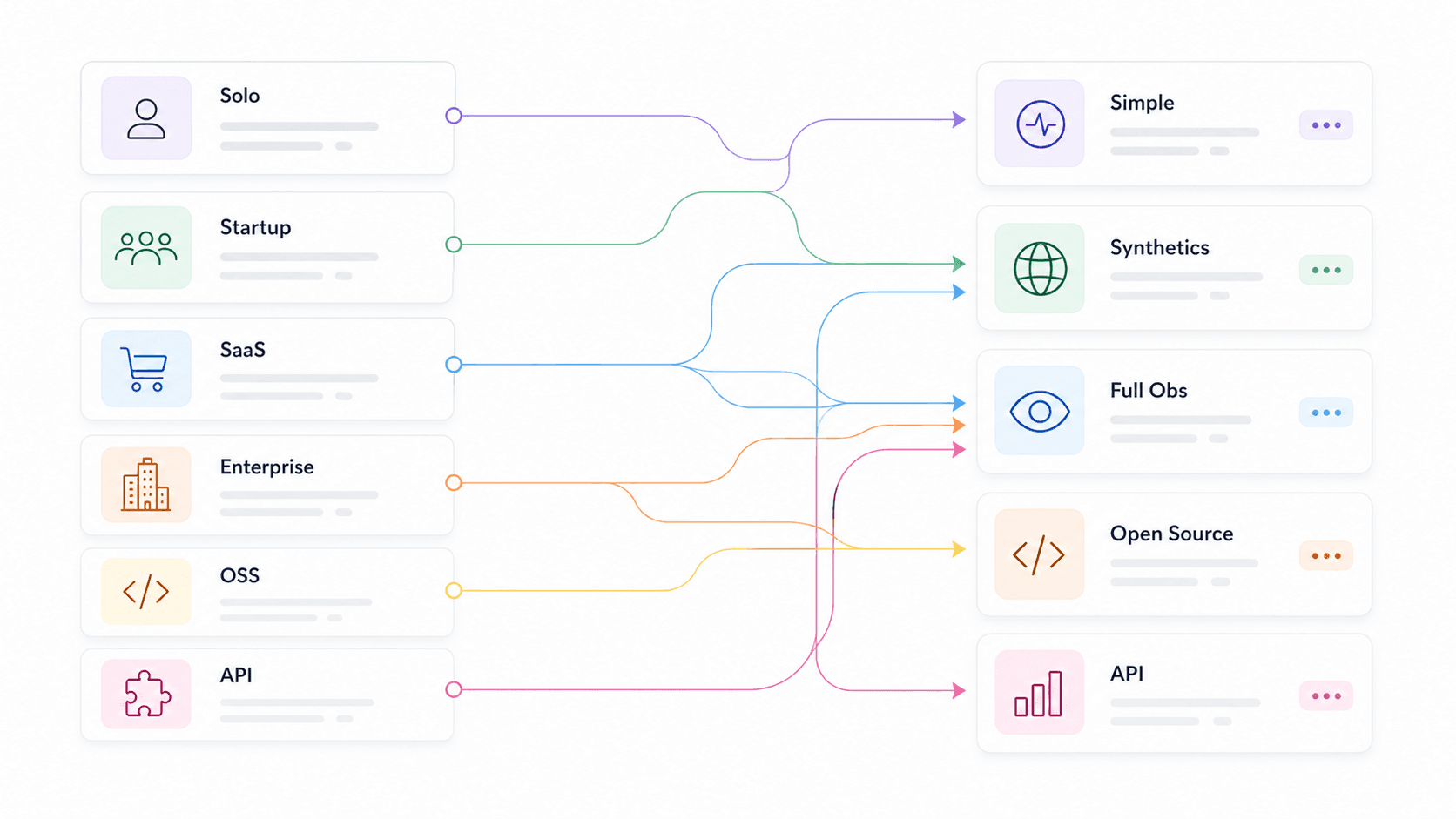
We hebben aanbevelingen ook uitgesplitst per use case — solo developer, startup, e-commerce/SaaS, enterprise, open-source purist, API-productteam en webdata/AI-app-team — zodat je direct naar jouw context kunt springen in plaats van 14 toolsamenvattingen te lezen in de hoop te raden welke relevant is. vond dat en als selectiecriteria, wat bevestigt dat dit geen nice-to-haves zijn.
Beste API-monitoringtools per use case: de snelle keuzetabel
Dit is de shortcut. Zoek je rij op en spring daarna naar de toolsecties hieronder voor de volledige uitwerking.
| Use case | Aanbevolen tools | Belangrijkste onderscheid |
|---|---|---|
| Webdata / AI-app-teams | Thunderbit Open API, Moesif, Apitally | Zet websites om in schone Markdown of gestructureerde JSON voor LLM’s, RAG-, prijs- en onderzoeksworkflows |
| Solo developer / side project | UptimeRobot, Uptime Kuma, Gatus | Gratis of self-hosted, minimale configuratie, snelle setup |
| Startup (team van 5–15 personen) | Checkly, Better Stack, Postman | Slimme alerts, snelle setup, betaalbaar, statuspagina’s |
| E-commerce / SaaS | Datadog, New Relic, Moesif, Checkly | Bedrijfsmetrics, APM/tracing, SDK-diepte, multi-step synthetics |
| Enterprise / multi-cloud | Datadog, New Relic, Splunk, Grafana Cloud | Distributed tracing, compliance, hybrid, RBAC/SSO |
| Open-source puristen | Prometheus + Grafana, Uptime Kuma, Gatus, Uptrace | Volledige controle, OTel-native, geen vendor lock-in |
| API-productteams | Moesif, Apitally, New Relic | Gebruik per klant, endpointtrends, anomaly alerts |
Het grootste patroon: tools die het snelst op te zetten zijn, leveren meestal minder analytics, terwijl de diepste platforms meer configuratie en kostenbeheersing vragen. Dat is geen fout — het is een trade-off om rekening mee te houden. Thunderbit zit in een iets andere lane: het is het snelst wanneer de taak is om webpagina’s om te zetten in API-klare data, niet om engineers te waarschuwen voor downtime.
Thunderbit Open API: het beste voor websites omzetten naar gestructureerde API-data
is de API die ik bovenaan zou zetten voor teams waarvan monitoring- of onderzoeksworkflow afhankelijk is van externe webdata. Het is geen traditionele uptime-monitor zoals Checkly of UptimeRobot. In plaats daarvan zet Thunderbit elke webpagina om in schone, gestructureerde data die je apps, agents, dashboards en LLM-pijplijnen echt kunnen gebruiken.
De API heeft drie kernworkflows. Distill zet een pagina om in schone, LLM-klare Markdown. Extract neemt een schema en geeft gestructureerde JSON-velden terug zoals productnaam, prijs, beschikbaarheid, bedrijfsgrootte, financieringsfase of beoordelingsscore. Batch laat je tot 100 URL’s asynchroon verwerken met webhooks, wat handig is als je prijspagina’s, concurrentencatalogi, leveranciersdocumentatie, nieuwsbronnen of grote onderzoekslijsten monitort.
De reden dat het thuishoort in een gids over API-tools is dat teams vaak onderschatten hoeveel infrastructuur “haal gewoon deze pagina op” eigenlijk kost. Sites met veel JavaScript hebben rendering nodig. Sommige pagina’s hebben georoute verkeer nodig. HTML moet worden ontdaan van navigatiebalken, advertenties, modals en boilerplate voordat het bruikbaar is voor een LLM. Selectors breken wanneer layouts veranderen. Proxy-rotatie, anti-botafhandeling, retries, queues en polling van resultaten kunnen van een kleine dataworkflow een onderhoudsproject maken. Thunderbit neemt veel van dat werk over achter één API.
Beste voor: bouwers van AI-apps, RAG-teams, e-commerce operations, sales ops, growth teams, marktonderzoekers en developers die websitegegevens via een API nodig hebben zonder een scrapingstack te bouwen en te babysitten.
Prijs: , inclusief maximaal 600 Distill-pagina’s of 30 Extract-pagina’s, met 2 gelijktijdige requests. Starter staat vermeld op $16/maand bij jaarlijkse facturering voor 60.000 API-eenheden/jaar en 30 gelijktijdige requests. Pro staat vermeld op $40/maand bij jaarlijkse facturering voor 600.000 API-eenheden/jaar en 50 gelijktijdige requests.
Instelsnelheid: ~5–15 minuten om een API-sleutel te krijgen en een eerste Distill- of Extract-request te draaien met cURL, SDK’s of de .
Nadelen: Thunderbit vervangt Datadog, New Relic, Better Stack of Checkly niet voor uptime-checks, incident-escalatie, traces, logs of on-call-routing. Zie het als de API die je gebruikt om webdata te verzamelen en te structureren — inclusief leveranciersprijzen, docs, concurrentenpagina’s, productvermeldingen of openbare datasets — niet als het systeem dat je on-call engineer wekt.
Datadog: het beste voor full-stack visibility
Datadog is de tool die ik het vaakst zie in enterprise- en mid-market SaaS-stacks, en met goede reden. Het is niet alleen API-monitoring — het is een volledig observabilityplatform dat synthetische API-tests koppelt aan distributed traces, logs, infrastructuurmetrics en real user monitoring in één overzicht.
Voor API-monitoring ondersteunt Datadog specifiek HTTP, SSL, DNS, WebSocket, TCP, UDP, ICMP, gRPC en . De leren verwachte patronen en waarschuwen bij afwijkingen in plaats van vaste drempels — een duidelijke stap vooruit ten opzichte van “waarschuw als latency > 500ms”. Het biedt ook die voorspellen wanneer een metric een drempel zal overschrijden, plus composite monitors die meerdere voorwaarden combineren.
Beste voor: e-commerce-, SaaS- en enterpriseteams die één overzicht willen over API’s, infrastructuur, logs en traces.
Prijs: Free tier verschilt per product. ; API-synthetische tests kosten $5 per 10.000 runs. 800+ integraties.
Instelsnelheid: ~15–30 minuten voor agent-installatie plus een basis-synthetische test.
Nadelen: Kan op schaal duur worden — “bill shock” is een terugkerend onderwerp op Hacker News en Reddit. Het enorme aantal SKU’s (hosts, logs, custom metrics, synthetics, users) betekent dat iemand de rekening moet bewaken, niet alleen de dashboards. De leercurve van het volledige platform is reëel.
Checkly: het beste voor developer-first synthetische checks
Checkly is de tool die ik zou geven aan een startup-engineeringteam dat API-checks dicht bij de code wil hebben. Het kernidee is “monitoring as code”: definieer API- en browserchecks programmatisch, draai ze vanaf wereldwijde locaties, integreer met CI/CD-pipelines en beheer alles via Git.
De kwaliteit van alerts is hier sterk. Checkly’s wordt expliciet neergezet als de “eerste verdedigingslinie” tegen false positives — je kunt vaste, lineaire of exponentiële retries instellen, retries vanaf dezelfde of een andere locatie, en maximale retryduur voordat een alert afgaat. Het maakt ook onderscheid tussen degraded, failed en recovered states, wat helpt om ruis in meldingen te verminderen.
Beste voor: startups en devteams die programmeerbare API-checks willen, , CI/CD-integratie en snelle setup.
Prijs: Recente publieke data laat een gratis plan zien met 10 uptime monitors, 1.000 browserchecks en 10.000 API-checks. Starter rond $24/maand bij jaarlijkse facturering — voordat je koopt.
Instelsnelheid: ~10–20 minuten voor een eerste API-check en alertkanaal.
Nadelen: Gericht op synthetische checks. Geen vervanging voor diepe APM, loganalytics of distributed tracing. Als je een API-fout wilt correleren met een database-bottleneck, heb je daar nog een ander hulpmiddel naast nodig.
UptimeRobot: het beste voor eenvoudige, betaalbare uptime-tracking
UptimeRobot is de Honda Civic van API-monitoring. Het doet één ding goed: je maakt een HTTP-, keyword-, ping-, port-, SSL- of heartbeat-monitor aan, kiest een interval en krijgt een melding als het fout gaat. Meer is het niet.
Beste voor: solo developers, kleine teams, bureaus of iedereen die basis uptime- en latency-tracking nodig heeft zonder complexiteit.
Prijs: . Betaalde Solo rond $7/maand bij jaarlijkse facturering. Geen creditcard nodig voor de gratis versie. Instelsnelheid: ~2–5 minuten — het snelst op deze lijst.
Nadelen: Beperkte alert-intelligentie. Basis drempelalerts, geen anomaly detection, geen distributed tracing, geen diepe analytics. Als je wilt weten waarom een endpoint traag is (niet alleen dat het traag is), helpt UptimeRobot je daar niet mee.
Uptime Kuma: de beste gratis, self-hosted API-monitoringtool
Uptime Kuma is de lieveling van de self-hostinggemeenschap, en de GitHub-cijfers bevestigen dat: , en release 2.3.2 per mei 2026. Het is MIT-licensed, ondersteunt HTTP(s), keywords, JSON-query’s, WebSocket, TCP, ping, DNS, push, Docker, meerdere statuspagina’s en 90+ notificatiediensten.
Beste voor: solo developers en teams die volledige controle, privacy en nul terugkerende SaaS-kosten willen — als je een server hebt.
Prijs: Gratis. De echte kosten zitten in je VM/container, backups, updates en ervoor zorgen dat de monitor zelf online blijft. Instelsnelheid: ~5–15 minuten met Docker voor een basischeck; 15–30 minuten met notificatie- en statuspaginaverfijning.
Nadelen: Je bent zelf verantwoordelijk voor onderhoud. En hier zit de belangrijke valkuil: als je Uptime Kuma host op dezelfde infrastructuur die het monitort, halen een cloud- of DNS-storing zowel je app als je monitor onderuit. Host het extern of combineer het met een SaaS-check.
Better Stack: het beste voor snelle incidentrespons
Better Stack (door gebruikers vaak nog Better Uptime genoemd) combineert uptime monitoring met incidentmanagement, on-call planning, escalatiebeleid en statuspagina’s in één platform. Het is vooral sterk niet als analytics-tool, maar als incident-workflow-tool rondom monitoring.
bepaalt wie in welke volgorde, met welke vertragingen, een melding krijgt totdat er bevestiging is. Routing op basis van metadata stuurt incidenten op ernst of ownership. Het integreert met Slack, Teams, webhooks en Zapier.
Beste voor: startups en middelgrote teams die monitoring + incidentrespons + statuspagina’s willen zonder drie losse tools aan elkaar te knopen.
Prijs: . Team rond $29/maand bij jaarlijkse facturering. Instelsnelheid: ~5–10 minuten via een GUI-wizard.
Nadelen: Minder diepgang in API-payload-analytics, distributed tracing of business-KPI-analyse dan Datadog, New Relic of Moesif.
Prometheus + Grafana: de beste open-source API-monitoringstack
Dit is de industriestandaard open-source combinatie. scraped en bewaart time-series metrics. (73.705 GitHub-sterren, 3.010 contributors) levert dashboards en alerting. regelt routing, grouping, deduplicatie, silencing en inhibition. Voor API-endpointchecks voegen teams toe voor HTTP-, HTTPS-, DNS-, TCP-, ICMP- en gRPC-probing.
Beste voor: open-source puristen, Kubernetes/SRE-teams en organisaties die al standaardiseren op Prometheus-metrics.
Prijs: Gratis self-hosted. heeft een gratis tier (100k API-testexecuties/maand) en usage-based betaalde plannen.
Instelsnelheid: 1–4 uur voor een basisopzet met Blackbox + Prometheus + Grafana + Alertmanager. Dagen voor productie-HA en alert-afstemming.
Nadelen: PromQL, YAML, relabeling, dashboardontwerp, retentie, opslag, HA en alert-tuning zijn serieus operationeel werk. De terugkerende trade-off is “minder UI, meer YAML.” Dit is de stack voor teams die al in metrics denken en één control plane willen — niet voor teams die monitoring “voor de lunch” live willen hebben.
New Relic: het beste voor SaaS application performance
New Relic combineert APM, infrastructuurmonitoring, logs, distributed tracing, synthetische monitoring, alerts, dashboards en AI-ondersteunde incidentanalyse. De free tier — — is echt royaal voor kleine teams.
De alert-intelligentie is waar New Relic uitblinkt in de discussie over alert fatigue. De bevat eventcorrelatie, anomaly detection, predictive alerts, root-cause analysis en suppressie van flapping. New Relic publiceerde een voorbeeld waarin — dat is een concreet cijfer voor ruisvermindering.
Beste voor: SaaS-teams en e-commerceplatforms die API-monitoring strak willen koppelen aan applicatietraces, errors, throughput en impact op gebruikers.
Prijs: Gratis: 100 GB/maand, 1 volledige gebruiker. Betaald gebruikt per-user- en data-gebaseerde prijsstelling.
Instelsnelheid: ~15–30 minuten voor agent-installatie en begeleide setup.
Nadelen: Prijsstelling kan op schaal complex worden. De alertconfiguratie heeft een leercurve — het platform is krachtig maar niet meteen vanzelfsprekend.
Moesif: het beste voor API-analytics en businessmetrics
Moesif is geen traditionele uptime monitor. Het is API-analytics en product intelligence: inzicht in API-gebruik per klant, endpoint, cohort, bedrijf, geografische regio, SDK, plan en gedrag. Als je vraag is “welke klant wordt geraakt?” in plaats van “staat het endpoint aan?”, dan is Moesif daarvoor gebouwd.
Het ondersteunt voor API-metrics zoals pieken/dalingen in verkeer, latency en gedragsveranderingen. De dynamische alerts hebben een paar dagen aan API-gedrag nodig om een model op te bouwen, maar zodra ze zijn getraind, vangen ze veranderingen op die statische regels missen.
Beste voor: API-productteams, SaaS-bedrijven en e-commerceplatforms die API-prestaties willen koppelen aan omzet, engagement en retentie.
Prijs: ; betaalde plannen schalen mee met het volume aan API-events. Zelfservicebedragen waren in mijn onderzoek niet volledig crawlbaar — controleer de huidige pagina.
Instelsnelheid: ~20–45 minuten (SDK/proxy/gateway-integratie is dieper dan een externe ping).
Nadelen: Meer analyticsgericht dan traditionele uptime monitoring. Je wilt Moesif waarschijnlijk combineren met Checkly, UptimeRobot of Datadog synthetics voor externe beschikbaarheidschecks.
Splunk: het beste voor enterprise loganalyse en compliance
Splunk is de tool die je pakt wanneer logaggregatie, zoeken, correlatie, compliance-klare auditbaarheid en hybrid/multi-cloud-ondersteuning niet onderhandelbaar zijn. dekt infrastructuur, APM, synthetics, real user monitoring, logs en incidentresponse. kan opvallende events clusteren tot episodes en ruis tussen monitoringsilo’s verminderen.
Splunks eigen is ontnuchterend: , , en .
Beste voor: enterprise- en multi-cloudteams met strikte eisen op het gebied van compliance, security, audit en log search.
Prijs: Usage-based en offertegedreven. Geen eenvoudige productie-free tier.
Instelsnelheid: Cloud-onboarding kan sneller zijn, maar enterprise-implementatie duurt vaak dagen tot weken.
Nadelen: Duur op schaal. Complexe setup. Overkill voor solo developers en kleine startups.
Postman: het beste voor teams die al API’s testen
Postman is vooral een platform voor API-ontwikkeling en testing, maar zijn laat teams Postman-collections plannen en vanaf cloudlocaties uitvoeren. Het sterkste argument is hergebruik: als je QA- of devteam al collections met assertions heeft, is daar monitors van maken een logische volgende stap.
Beste voor: dev- en QA-teams die al Postman-collections gebruiken en geplande checks willen zonder een aparte synthetische tool te kopen.
Prijs: Er is een free tier. ; extra blok van 50.000 calls voor $20/maand. Controleer de — de verpakking van Postman-plannen verandert geregeld.
Instelsnelheid: ~10 minuten als collections al bestaan.
Nadelen: Monitoringmogelijkheden zijn lichter dan bij gespecialiseerde tools zoals Checkly, Datadog of New Relic. Alertopties zijn basis.
Andere API-monitoringtools die het bekijken waard zijn
: Lichtgewicht, self-hosted, config-gedreven health dashboard. , ondersteunt HTTP, ICMP, TCP, DNS, Prometheus-vriendelijke metrics en uptime-badges. Geweldig voor solo developers die iets simpelers willen dan Prometheus, maar liever YAML/config-as-code hebben dan de UI van Uptime Kuma.
: Nieuwere tool gericht op API-verkeersanalytics en kwaliteitsbewaking voor startups. Claimt met aangepaste alerts over 14 metrics. Goed voor lichte API-analytics zonder een volledig observabilityplatform te adopteren.
: Full-stack monitoring met logs, synthetics en infrastructuurzichtbaarheid. . Een goedkoper alternatief voor Datadog voor mid-market teams.
: OpenTelemetry-native backend voor APM, tracing, metrics en logs. . Geen pure uptime checker, maar ideaal voor teams die op OTel standaardiseren en een open-sourcevriendelijke tracing-backend willen.
Build vs. buy: moet je je eigen API-monitoring bouwen?
“Moet ik gewoon zelf een script schrijven dat mijn endpoints pingt, of gebruik ik een gespecialiseerde tool?”
Die vraag komt continu terug in developerforums. Ik heb genoeg Reddit-threads gelezen om het patroon duidelijk te zien: teams beginnen met curl + cron, dat werkt een tijdje prima, en schakelen dan over zodra ze dashboards, historische data, checks in meerdere regio’s, betrouwbare alert-routing of zichtbaarheid over teams heen nodig hebben.
Een eerlijke beslismatrix:
| Factor | Eigen script | Gespecialiseerde tool |
|---|---|---|
| Insteltijd | 1–4 uur (basis); dagen (robuust) | 5–30 minuten |
| Onderhoud | Jij blijft er altijd verantwoordelijk voor | Provider verzorgt updates |
| Alertkwaliteit | Basis (up/down) | Slim (latencytrends, anomalieën, retries) |
| Kosten | Gratis (je tijd) | $0–$500+/maand |
| Dashboard | Vanaf nul bouwen | Vooraf gebouwd, aanpasbaar |
| Beste wanneer… | ≤3 endpoints, dev-zwaar team, hobbyproject | 5+ endpoints, ops/productteam, omzet op het spel |
Het belangrijkste inzicht uit forums: mensen die het zelf bouwen, krijgen er vaak spijt van zodra ze dashboards, historische data of zichtbaarheid over teams nodig hebben. En dan is er nog het meta-probleem — “je hebt monitoring op je monitoring nodig.” Ook een self-hosted monitor, database, backup, netwerkpad en alertprovider moeten betrouwbaar zijn.
Bouw het zelf als je 2 endpoints hebt en graag knutselt. Koop het als je een product moet shippen.
Dezelfde logica geldt voor webdata-extractie. Je kunt een scraper schrijven, headless browsers draaien, proxies roteren, selectors onderhouden, HTML opschonen en een queue bouwen. Maar als de taak is om webdata betrouwbaar aan een API-product, AI-agent of onderzoeksworkflow te leveren, is het meestal sneller om te gebruiken dan je eigen scrapinginfrastructuur te bouwen.
Alert fatigue: waarom alertkwaliteit belangrijker is dan alertkwantiteit
Dit is misschien wel het meest onderschatte criterium bij het kiezen van een API-monitoringtool. Alert fatigue ontstaat wanneer teams zoveel ruis, duplicaten of niet-acteerbare alerts ontvangen dat ze ze allemaal gaan negeren — en vervolgens echte incidenten missen.
De cijfers zijn indrukwekkend. vond dat de mediane organisatie en genereerde. De mediane incident-actionability was slechts — wat betekent dat minder dan één op de vijf incidenten uit alerts daadwerkelijk bruikbaar was. vond dat en .
De beste monitoringtool is de tool waarvan je alerts echt vertrouwt. Een vergelijking van hoe tools omgaan met alert-intelligentie:
| Tool | Alerttype | Methode om ruis te verminderen | Alertkanalen |
|---|---|---|---|
| Datadog | ML-anomaly, forecast, composite | Historische anomaly-banden, dynamische baselines, Watchdog AI | Slack, PagerDuty, Opsgenie, Teams, 20+ |
| Checkly | Drempel + degradatie-gebaseerd | Retry vóór firing, retries vanaf dezelfde/andere locatie | Slack, PagerDuty, Opsgenie, Teams, incident.io |
| New Relic | AI-issuegroepering, anomaly, predictive | Eventcorrelatie, flapping-suppressie, root-cause-context | Slack, PagerDuty, Teams, webhooks |
| Moesif | Gedragsanomaly | Dynamische modellen na meerdere dagen gedrag | Slack, PagerDuty, e-mail, sms |
| Better Stack | Uptime/incident/on-call | Escalatiebeleid, routing op ownership, vertragingen | Slack, Teams, webhooks, Zapier |
| Prometheus + Alertmanager | PromQL-regelalerts | Groepering, deduplicatie, silencing, inhibition | E-mail, PagerDuty, Opsgenie, webhooks |
| Splunk | Events, episodes, service health | ITSI Event Analytics, episodegroepering, ticketing | Splunk On-Call, ServiceNow, webhooks |
| Thunderbit Open API | Geen alertplatform | Gebruik samen met je eigen scheduler, workflowtool of monitoringstack | Webhooks voor batchjobs; alerts extern afgehandeld |
Praktisch advies: begin met minder alerts, maar met hogere betrouwbaarheid. Gebruik retry-before-firing, bevestiging vanuit meerdere regio’s, SLO burn-rate alerts, deduplicatie en routing op ownership. Waarschuw op user impact en businesskritieke flows (checkout failure, auth failure, payment 5xx), niet op elk intern symptoom.
Gratis tiers en prijzen in 2026: wat je echt betaalt
Prijspagina’s veranderen. Free tiers verschuiven. Verborgen kosten (hosts, seats, logs, synthetic runs, data-ingest) kunnen je verrassen. Dit is de sectie die ik op elk “beste tools”-artikel had willen zien. De snapshot voor 2026:
| Tool | Free tier | Betaald vanaf | Creditcard vereist? | Beste gratis use case |
|---|---|---|---|---|
| Thunderbit Open API | 600 eenmalige API-eenheden | ~$16/maand jaarlijks | Nee | Webdata-extractie voor LLM’s, RAG, pricing en research |
| Uptime Kuma | Onbeperkt (self-host) | — | Nee | Volledige monitoring, eigen server |
| UptimeRobot | 50 monitors, 5-minutenintervallen | ~$7/maand | Nee | Basis uptime-checks |
| Better Stack | 10 monitors, 1 statuspagina | ~$29/maand | Nee | Startup-uptime + statuspagina |
| Checkly | 10 uptime, 10k API-checks | ~$24/maand | Ja | Synthetische API-checks |
| Postman | Gratis account + monitoringtegoed | ~$14/gebruiker/maand | Nee | Hergebruik van bestaande collections |
| Prometheus + Grafana | Onbeperkt (self-host) | — | Nee | Metrics + visualisatie |
| Grafana Cloud | 100k API-testexecuties/maand | $29/maand platform + usage | Controleer | Beheerde synthetics-proef |
| New Relic | 100 GB/maand, 1 volledige gebruiker | Per gebruiker + data | Sommige plannen | APM + basisobservability |
| Datadog | Proefperiode/verschilt per product | $15/host/maand (Infra Pro) | Vaak wel | Evaluatie van full-stack |
| Moesif | Gratis/proefversie beschikbaar | Op volume gebaseerd | Controleer | Evaluatie van API-analytics |
| Splunk | Proefversies beschikbaar | Offertegebaseerd | Sales flow | Enterprise proof of concept |
| Gatus | Onbeperkt (self-host) | — | Nee | YAML-gestuurd statusdashboard |
| Apitally | Gratis/proefversie beschikbaar | Controleer | Controleer | Lichtgewicht API-analytics |
| Sematext | Proef/free verschilt | ~$2/HTTP-monitor | Controleer | Goedkopere synthetics/logs |
| Uptrace | Gratis self-hosted | Cloudtiers verschillen | Controleer | Evaluatie van OTel APM |
Opmerking over verborgen kosten: Self-hosted tools (Uptime Kuma, Prometheus, Gatus) zijn qua licentie “gratis”, maar een kleine VM, backups, onderhoudstijd en externe failover kunnen al snel de echte kosten worden. Bij webdata-API’s is de verborgen kost vaak anders: headless browsers onderhouden, kapotte selectors, proxy-pools, anti-bot-omwegen en HTML-opruiming.
Schatting voor kleine teams: Voor 10 API-endpoints en 3 teamleden is het goedkoopste SaaS-pad meestal UptimeRobot gratis of laag betaald, Better Stack gratis/Team, of Checkly als het uitvoervolume past. Datadog en New Relic kunnen betaalbaar zijn voor evaluatie, maar de echte rekening hangt af van hosts, users, logs, traces en volume aan synthetic runs. Als je project websitegegevens als API nodig heeft, zijn de gratis API-eenheden van Thunderbit genoeg om de workflow te testen voordat je een betaald plan neemt.
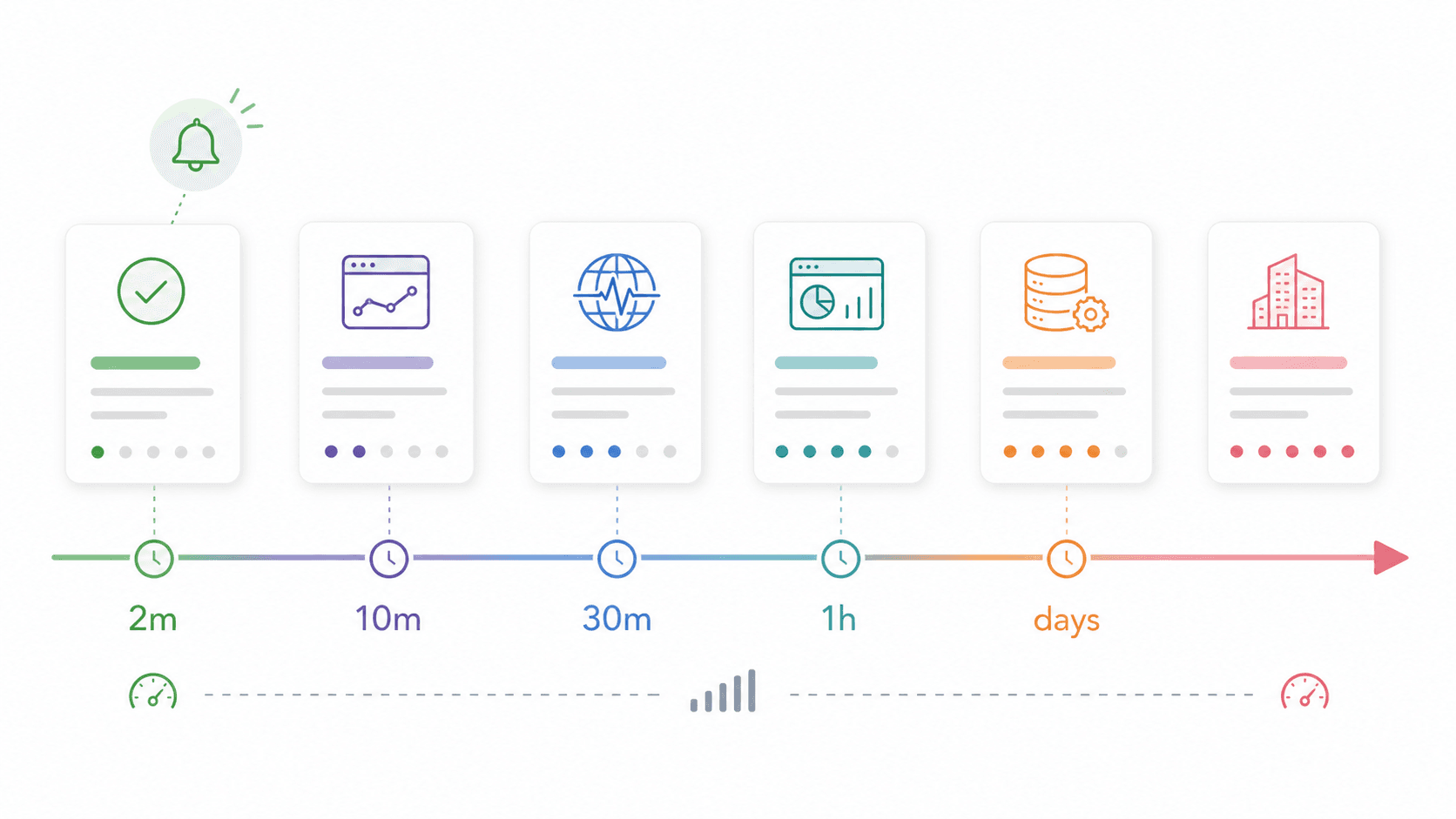
Scorecard voor setup-complexiteit: hoe snel tot je eerste alert?
Geen enkel concurrentenartikel dat ik vond, beoordeelt time-to-value — hoe lang het duurt vanaf aanmelding tot je eerste zinvolle alert. Voor kleinere teams is dat belangrijker dan feature-diepte.
| Tool | Tijd tot eerste alert | Benodigde technische vaardigheid | Configuratie-aanpak |
|---|---|---|---|
| Thunderbit Open API | ~5–15 minuten | Laag–middel | API-sleutel, cURL/SDK/CLI |
| UptimeRobot | ~2–5 minuten | Laag | GUI, klikken om toe te voegen |
| Better Stack | ~5–10 minuten | Laag | GUI-wizard |
| Checkly | ~10–20 minuten | Laag–middel | Code of GUI |
| Postman | ~10 minuten (met collections) | Laag–middel | Collection scheduler |
| Uptime Kuma | ~5–30 minuten | Middel | Docker + GUI |
| Gatus | ~15–45 minuten | Middel | YAML + Docker |
| Datadog | ~15–30 minuten | Middel | Agentinstallatie + GUI |
| New Relic | ~15–30 minuten | Middel | Agent + begeleide setup |
| Moesif | ~20–45 minuten | Middel | SDK/proxy-integratie |
| Grafana Cloud Synthetics | ~15–45 minuten | Middel | GUI, Terraform optioneel |
| Prometheus + Grafana | 1–4 uur | Middel–hoog | YAML, PromQL |
| Uptrace | 30–90 minuten | Middel–hoog | OTel SDK-integratie |
| Splunk | Uren tot weken | Hoog | Enterprise-onboarding |
Als monitoring aan het eind van de dag live moet zijn, begin dan in de bovenste helft van die tabel. Als het doel duurzame platformobservability is, plan dan een apart project voor de onderste helft. En als je eerste mijlpaal is: “haal schone data uit deze 100 webpagina’s in een app”, begin dan met Thunderbit voordat je custom scrapinginfrastructuur bouwt.
De beste API-monitoringtools naast elkaar vergeleken: het volledige overzicht
Eén tabel om te scannen voordat je beslist:
| Tool | Beste use case | Free tier | Alert-intelligentie | Insteltijd | Hosting | Opvallende feature |
|---|---|---|---|---|---|---|
| Thunderbit Open API | Webdata-extractie/API-datapijplijnen | 600 API-eenheden | Geen alerttool | 5–15 min | Cloud | Zet pagina’s om in Markdown of extraheer schema-gebaseerde JSON |
| Datadog | Full-stack enterprise/SaaS | Proef/verschilt | Anomaly, forecast, AI | 15–30 min | Cloud | Correlatie van synthetics met logs/traces/infra |
| Checkly | Dev-first synthetics | Ruim op checks gebaseerd | Retries, degradation | 10–20 min | Cloud | Monitoring as code + Playwright |
| UptimeRobot | Simpele uptime | 50 monitors | Basisdrempels | 2–5 min | Cloud | Snelste goedkope basismonitor |
| Uptime Kuma | Gratis self-hosted | Onbeperkt | Basis status/drempel | 5–30 min | Self-hosted | Schone UI, geen SaaS-kosten |
| Better Stack | Incidentrespons/statuspagina’s | 10 monitors | Escalaties, routing | 5–10 min | Cloud | Monitoring + on-call + statuspagina |
| Prometheus + Grafana | Open-source metrics-stack | Onbeperkt (self-host) | Groepering door Alertmanager | 1–4 uur | Self-hosted/cloud | Diepte van het PromQL-ecosysteem |
| New Relic | SaaS APM + API-checks | 100 GB/maand, 1 gebruiker | AI-groepering, suppressie van flapping | 15–30 min | Cloud | Sterke APM + synthetics samen |
| Moesif | API-analytics/businessmetrics | Gratis/proef | Gedragsanomalieën | 20–45 min | Cloud | API-gedragsanalytics per klant |
| Splunk | Enterprise logs/compliance | Proef | ITSI-episodes, AIOps | Dagen+ | Cloud/self-managed | Enterprise log search en governance |
| Postman | Teams die al API’s testen | Gratis account | Basis monitoralerts | 10 min | Cloud | Hergebruik van API-testcollections |
Hoe Thunderbit je evaluatie van API-tools kan versnellen
Volledige openheid: is geen API-monitoringtool — het is een AI webscraper en om webpagina’s om te zetten in schone Markdown of gestructureerde JSON. Dat maakt het nuttig in een ander deel van het besluitvormingsproces rond monitoringtools: het verzamelen van leveranciersprijzen, planlimieten, featureclaims, documentatiedetails en integratielijsten vóór je een platform kiest.
In plaats van handmatig 10+ prijspagina’s van leveranciers te openen en plannamen, monitorlimieten, check-intervals, integraties en creditcardvereisten in een spreadsheet te kopiëren, gebruikten we de om gestructureerde data uit de prijs- en featurepagina’s van elke tool te extraheren. Thunderbit’s AI leest elke pagina en stelt velden voor — plannaam, free-tier-details, betaalde prijs, ondersteunde integraties — en zet de output daarna om in een exporteerbare spreadsheet.
Voor developerworkflows geeft je hetzelfde idee programmatisch. Gebruik Distill wanneer je schone Markdown wilt voor LLM’s of RAG. Gebruik Extract wanneer je specifieke velden als JSON terug wilt. Gebruik Batch wanneer je een lijst met prijspagina’s, documentatie-URL’s, productpagina’s of concurrentenpagina’s wilt verwerken en de resultaten asynchroon wilt ontvangen.
De workflow:
- Open de prijspagina van een leverancier (Datadog, Checkly, UptimeRobot, enz.)
- Klik op “AI Suggest Fields” — Thunderbit stelt kolommen voor op basis van de inhoud van de pagina
- Klik op “Scrape” — de data vult zich in een gestructureerde tabel
- Gebruik subpage scraping om naar de prijs-, feature- en docspagina’s van elke leverancier te gaan
- Exporteer naar Google Sheets, Excel, Airtable, Notion of CSV
Voor API-first teams is de API-workflow net zo direct:
- Vraag een gratis API-sleutel aan bij Thunderbit
- Roep het Distill-endpoint aan voor schone Markdown van elke openbare pagina
- Roep het Extract-endpoint aan met schemabeschrijvingen voor gestructureerde JSON
- Gebruik Batch-endpoints en webhooks voor grotere URL-lijsten
- Stuur de output naar je app, spreadsheet, datawarehouse, vector database of monitoringworkflow
Voor een vergelijking van 10+ leveranciers kan handmatig copy-pasten al snel 2–3 uur kosten zodra je prijspagina’s, documentatie en integratiepagina’s meetelt. Thunderbit bracht onze eerste extractieronde terug tot ongeveer 15–30 minuten, waarbij de resterende tijd naar verificatie en beoordelingskeuzes ging. Als je ops-, procurement-, research- of AI-productteam onder tijdsdruk tools evalueert, is dat een praktische shortcut. Je kunt meer over dit soort workflow lezen in onze -gids, bekijken, of ons raadplegen voor walkthroughs.
Hoe kies je de beste API-monitoringtool voor jouw team?
De “beste” API-monitoringtool hangt af van je teamgrootte, technische diepgang, budget en wat falen betekent voor jouw product.
Een solo developer heeft geen Splunk nodig. Een gereguleerde enterprise mag niet leunen op een cronjob. Een API-productteam heeft misschien meer behoefte aan customer analytics zoals Moesif dan aan uptime-pings. Een e-commerce team moet kritieke checks prioriteren voor login, search, add-to-cart, checkout en payment authorization. Een AI- of dataproductteam heeft mogelijk eerst webdata-extractie van Thunderbit nodig voordat het volledige observability nodig heeft.
Drie principes die in al mijn onderzoek overeind bleven:
- Koppel de tool aan je use case. De snelle keuzetabel bestaat niet voor niets — begin daar.
- Geef prioriteit aan alertkwaliteit boven alertaantallen. Als je team alerts negeert, heb je geen monitoring. Dan heb je ruis.
- Onderschat de instelsnelheid niet. Een monitor die vandaag live gaat en betrouwbare alerts stuurt, is beter dan een perfect platformplan dat checkout nog een maand onbeheerd laat.
Als je meerdere tools tegelijk vergelijkt en het onderzoek wilt versnellen, probeer dan voor het in bulk extraheren van leveranciersdata naar één spreadsheet. Als je een API-product, RAG-pijplijn, AI-agent of market-intelligence-workflow bouwt die schone webdata nodig heeft, begin dan met . Het kiest de monitoringtool niet voor je — maar het brengt je wel sneller tot de beslissing, en het kan je eigen product een betrouwbare webdatalaag geven.
FAQ’s over de beste API-monitoringtools
Wat is in 2026 de beste gratis API-monitoringtool?
Voor SaaS-eenvoud biedt UptimeRobot 50 gratis monitors met 5-minutenintervallen zonder creditcard. Voor self-hosted controle is Uptime Kuma open-source, onbeperkt en heeft het een schone UI met 90+ notificatiediensten. Voor teams die metrics-diepte willen en al technische kennis hebben, is Prometheus + Grafana + Alertmanager de beste open-source stack — al kost de setup uren in plaats van minuten.
Als je doel niet uptime monitoring is maar webdata via een API extraheren, heeft Thunderbit Open API een free tier met 600 eenmalige API-eenheden, genoeg om page-to-Markdown-distillatie of schema-gebaseerde JSON-extractie te testen voordat je opschaalt.
Wat is het verschil tussen API-monitoring en APM?
API-monitoring controleert van buitenaf of endpoints beschikbaar zijn, snel reageren, fouten geven en correct zijn — het simuleert wat een gebruiker of integratie ervaart. APM (Application Performance Monitoring) gaat dieper de applicatie in: code-level traces, databasequeries, runtimefouten, queue-latency en service-afhankelijkheden. Tools zoals Datadog en New Relic bieden beide; UptimeRobot en Uptime Kuma richten zich op externe uptime-checks.
Thunderbit Open API is anders dan beide: het is een webdata-extractie-API. Het helpt je externe websites om te zetten in Markdown of gestructureerde JSON, wat nuttig is voor LLM-apps, onderzoeksworkflows, pricing intelligence en datapijplijnen.
Hoe vaak moet ik mijn API’s monitoren?
Productie-API’s die direct aan omzet zijn gekoppeld (checkout, auth, payments) moeten doorgaans elke 1 minuut worden gecontroleerd. Interne API’s of API’s met weinig verkeer kunnen vaak elke 5 minuten worden gecontroleerd. Maar frequentie alleen is niet het hele verhaal — gebruik retries, meerdere regio’s en betekenisvolle assertions zodat elke check snel én betrouwbaar is. Een 1-minuutcheck die valse alarmen geeft is slechter dan een 5-minutencheck die je kunt vertrouwen.
Voor webdata-extractieworkflows hangt de frequentie af van hoe snel de bron verandert. Prijspagina’s hebben misschien dagelijkse of wekelijkse extractie nodig. Snel bewegende inventory-, travel- of marketplace-data kan uurlijkse of nog frequentere vernieuwing vereisen. Thunderbit’s batch-API en webhooks zijn handig als je veel URL’s volgens schema moet verwerken.
Kan ik API’s monitoren zonder code te schrijven?
Ja. UptimeRobot, Better Stack en Uptime Kuma kun je volledig via GUI’s gebruiken. Checkly ondersteunt zowel GUI- als codegebaseerde setup. Postman gebruikt een collection-gebaseerde interface. Prometheus/Grafana vereist meestal YAML en PromQL. Datadog en New Relic kunnen starten via een begeleide setup, maar worden krachtiger met diepere instrumentatie.
Als je websitegegevens wilt extraheren zonder code te schrijven, is Thunderbit’s Chrome Extension de no-code route. Als je diezelfde workflow vanuit een applicatie wilt automatiseren, geeft developers Distill-, Extract- en Batch-endpoints.
Hoe verminder ik alert fatigue bij API-monitoring?
Kies tools met slimme alerting: anomaly detection (Datadog, New Relic), retry-before-firing (Checkly), gedragsanomalieën (Moesif) of groepering/silencing (Prometheus Alertmanager). Begin met minder alerts met hogere betrouwbaarheid, gericht op impact voor gebruikers. Gebruik SLO burn-rate alerts in plaats van vaste drempels, dedupliceer over services heen, routeer op ownership en meet actionability — als minder dan 20% van je alerts tot echte actie leidt, verminder dan eerst de ruis.
Meer lezen