
In 2015 betekende scrapen nog dat je een ontwikkelaar moest vragen een Python-script te schrijven, of dat je zelf een heel weekend XPath zat te leren. In 2026 typ je gewoon “haal alle productnamen en prijzen op” en laat je AI de rest doen.
Die omslag ging razendsnel. Meer dan 2 miljoen bedrijven vertrouwen inmiddels op webscraping. De markt ging in 2024 de grens van 1 miljard dollar voorbij en staat op koers om tegen 2030 te verdubbelen.
De grootste aanjager? AI-webcrawlers. Die passen zich aan als een lay-out verandert. Ze snappen de inhoud van een pagina, niet alleen HTML-tags. En ze werken ook voor mensen die nog nooit een regel code hebben geschreven.
Ik heb maandenlang 15 van deze tools getest. Dit is wat ik heb ontdekt — inclusief waarom Thunderbit (ja, het bedrijf dat ik mede heb opgericht) op nummer 1 eindigde.
Waarom AI webpagina’s scrapen transformeert: het nieuwe tijdperk van webscraper-tools
Haal data van elke website op met AI Get Started Free
Laten we eerlijk zijn: traditioneel webscrapen was nooit echt gemaakt voor de gemiddelde zakelijke gebruiker. Alles draaide om code, selectors en hopen dat je script niet stukging zodra een website iets aan de lay-out veranderde. AI en LLM's hebben dat compleet omgegooid.
Zo werkt het:
- Instructies in natuurlijke taal: In plaats van te prutsen met code, vertel je de AI gewoon wat je wilt. Tools zoals Thunderbit begrijpen je instructies in gewoon Engels en zetten het extractieproces voor je op (bron).
- Adaptief leren: AI-scrapers kunnen zich aan lay-outwijzigingen aanpassen op websites, waardoor onderhoud een stuk minder gedoe is.
- Omgaan met dynamische content: Moderne sites zitten vol JavaScript en oneindig scrollen. AI-tools werken daar gewoon mee en vangen data die ouderwetse scrapers zouden missen.
- Gestructureerde output met AI-parsing: LLM-gebaseerde scrapers begrijpen de pagina-inhoud echt en leveren schone, gestructureerde data op.
- Automatische anti-bot-omzeiling: AI-scrapers kunnen anti-scrapingmaatregelen omzeilen en proxies/headless browsers gebruiken om IP-blokkades te vermijden.
- Geïntegreerde datastromen: De beste tools halen niet alleen data op — ze zetten die ook direct neer waar je ze nodig hebt, met éénkliksexport naar Google Sheets, Airtable, Notion en meer (bron).
Het resultaat? Webscraping voelt nu meer als point-and-click — of zelfs als chatten — waardoor niet alleen ontwikkelaars, maar ook sales-, marketing- en operationele teams webdata direct kunnen gebruiken.
15 AI-webcrawlers die in 2026 de moeite waard zijn
Laten we de top 15 AI-webcrawlers doornemen, te beginnen met Thunderbit. Ik geef per tool de kernfuncties, doelgroep, prijs en wat hem onderscheidt. En ja, ik ben ook eerlijk over waar elke tool uitblinkt — en waar niet.
1. Thunderbit: de AI-webscraper voor iedereen
Ik ben hier natuurlijk niet helemaal neutraal in, maar Thunderbit is de AI-webscraper die ik jaren geleden zelf had willen hebben. Dit is waarom hij op nummer 1 staat:
- Extractie in natuurlijke taal: Je “chat” met Thunderbit. Beschrijf gewoon welke data je wilt — “haal alle productnamen en prijzen van deze pagina op” — en de AI doet de rest (bron). Geen code, geen selectors, geen gedoe.
- Crawlen van subpagina's en meerdere niveaus: Thunderbit kan links volgen en subpagina's scrapen. Scrape bijvoorbeeld eerst een productoverzicht en klik daarna automatisch door naar elke productpagina voor details — in één keer.
- Direct gestructureerde output: De AI formatteert en schonk data direct on the fly, stelt relevante velden voor, normaliseert formaten en vat tekst zelfs samen of categoriseert die.
- Brede bronondersteuning: Thunderbit werkt niet alleen met HTML — het kan ook uit PDF's en afbeeldingen extraheren met ingebouwde OCR en vision AI (bron).
- Zakelijke integraties: Eénkliksexport naar Google Sheets, Airtable, Notion of Excel (bron). Plan scrapes in en stuur data rechtstreeks naar je teamworkflow.
- Vooraf gebouwde sjablonen: Voor sites zoals Amazon, LinkedIn, Zillow enz. biedt Thunderbit kant-en-klare scrapingrecepten voor dataverzameling met één klik.
- Gebruiksvriendelijk en toegankelijk: De interface werkt met point-and-click en heeft een intuïtieve assistent. Gebruikers zeggen dat ze binnen enkele minuten aan de slag zijn.

Thunderbit wordt vertrouwd door meer dan 30.000 gebruikers wereldwijd, waaronder teams bij Accenture, Grammarly en Puma. Salesteams gebruiken het om leaddlijsten op te bouwen, makelaars bundelen woningaanbod en marketeers volgen concurrenten — allemaal zonder ook maar één regel code te schrijven.
Prijzen: Er is een gratis versie (scrape tot 100 stappen per maand), met betaalde abonnementen vanaf $14,99 per maand. Zelfs de pro-abonnementen zijn betaalbaar voor individuen en kleine teams.
Thunderbit komt het dichtst in de buurt van “het web in een database veranderen” dat ik ooit heb gezien — en het is gebouwd voor iedereen, niet alleen voor engineers.
Probeer de Thunderbit Chrome-extensie
2. Crawl4AI
Voor wie: Ontwikkelaars en technische teams die aangepaste pipelines bouwen.
Crawl4AI is een open-source, op Python gebaseerd framework dat is geoptimaliseerd voor snelheid en grootschalig crawlen, met LLM-integratie in gedachten. Het is razendsnel, ondersteunt headless browsers voor dynamische content en kan gescrapete data structureren zodat die makkelijk in AI-workflows kan worden gevoed.
- Beste voor: Ontwikkelaars die een krachtige, aanpasbare crawl-engine nodig hebben.
- Prijzen: Gratis (MIT-licentie). Je moet het zelf hosten en draaien.
3. ScrapeGraphAI
Voor wie: Ontwikkelaars en analisten die AI-agents of complexe datapijplijnen bouwen.
ScrapeGraphAI is een promptgestuurde, open-source Python-bibliotheek die websites omzet in gestructureerde datagrafen met behulp van LLM's. Je kunt prompts schrijven als: “Haal alle productnamen, prijzen en beoordelingen van de eerste 5 pagina's op”, en de tool bouwt de scrapingworkflow voor je (bron).
- Beste voor: Technisch vaardige gebruikers die flexibele, promptgebaseerde scraping willen.
- Prijzen: Gratis voor de open-source bibliotheek; cloud-API vanaf $20 per maand.
4. Firecrawl
Voor wie: Ontwikkelaars die AI-agents of grootschalige datapijplijnen bouwen.
Firecrawl is een AI-gericht crawlplatform en API die complete websites omzet in “LLM-ready” data (bron). Het levert Markdown of JSON, verwerkt dynamische content en integreert met frameworks zoals LangChain en LlamaIndex.
- Beste voor: Ontwikkelaars die live webdata in AI-modellen willen voeden.
- Prijzen: De open-source kern is gratis; cloudabonnementen starten bij $19 per maand.
5. Browse AI
Voor wie: Zakelijke gebruikers, growth hackers en analisten.
Browse AI is een no-code platform met een point-and-click-interface. Je “traint” een robot door op de gewenste data te klikken, waarna de AI dat patroon generaliseert voor toekomstige scrapes. Het kan inloggen, oneindig scrollen en sites bewaken op wijzigingen.
- Beste voor: Niet-technische gebruikers die dataverzameling en monitoring willen automatiseren.
- Prijzen: Gratis plan (50 credits per maand); betaalde plannen vanaf $19 per maand.
6. LLM Scraper
Voor wie: Ontwikkelaars die AI het parsewerk willen laten doen.
LLM Scraper is een open-source JavaScript/TypeScript-bibliotheek waarmee je een dataschema definieert en een LLM die data van elke webpagina laat extraheren. Het is gebouwd op Playwright, ondersteunt meerdere LLM-providers en kan zelfs herbruikbare code genereren.
- Beste voor: Ontwikkelaars die met LLM's elke webpagina willen omzetten in gestructureerde data.
- Prijzen: Gratis (MIT-licentie).
7. Reader (Jina Reader)
Voor wie: Ontwikkelaars die LLM-applicaties, chatbots of samenvatters bouwen.
Jina Reader is een API die schone tekst en gestructureerde data uit webpagina's haalt, en zelfs uit PDF's/afbeeldingen, en Markdown of JSON levert dat direct geschikt is voor LLM's. Het wordt aangedreven door een aangepast AI-model en kan zelfs afbeeldingen van bijschriften voorzien.
- Beste voor: Schone, leesbare content ophalen voor LLM's of vraag-antwoordsystemen.
- Prijzen: Gratis API (voor basisgebruik is geen sleutel nodig).
8. Bright Data
Voor wie: Enterprises en professionele gebruikers die schaal, compliance en betrouwbaarheid nodig hebben.
Bright Data is een zwaargewicht in de webdata-industrie, met een enorm proxynetwerk en AI-gestuurde scrapingtools. Het biedt kant-en-klare scrapers, een algemene Web Scraper API en “LLM-ready” datastreams.
- Beste voor: Organisaties die betrouwbare webdata op schaal nodig hebben.
- Prijzen: Gebaseerd op gebruik, premium. Gratis proefversies beschikbaar.
9. Octoparse
Voor wie: Niet-technische tot licht-technische gebruikers.
Octoparse is een gevestigde no-code tool met een visuele workflowdesigner en AI-gestuurde auto-detectie. Het verwerkt logins, oneindig scrollen en kan data in verschillende formaten exporteren.
- Beste voor: Analisten, eigenaren van kleine bedrijven of onderzoekers.
- Prijzen: Gratis versie beschikbaar; betaalde plannen vanaf $119 per maand.
10. Apify
Voor wie: Ontwikkelaars en technische teams die aangepaste scraping/automatisering nodig hebben.
Apify is een cloudplatform voor het draaien van scraping-scripts (“actors”) en biedt een winkel met vooraf gebouwde actors. Het schaalt goed, integreert met AI en ondersteunt proxybeheer.
- Beste voor: Ontwikkelaars die eigen scripts in de cloud willen draaien.
- Prijzen: Gratis versie; betaalde plannen op basis van gebruik vanaf $49 per maand.
11. Zyte (Scrapy Cloud)
Voor wie: Ontwikkelaars en bedrijven die enterprise-grade scraping nodig hebben.
Zyte is het bedrijf achter Scrapy en biedt een cloudplatform en AI-gestuurde automatische extractie. Het ondersteunt planning, proxies en grootschalige projecten.
- Beste voor: Dev-teams die langlopende scrapingprojecten draaien.
- Prijzen: Van gratis proefversies tot maatwerk enterprise-abonnementen.
12. Webscraper.io
Voor wie: Beginners, journalisten en onderzoekers.
Webscraper.io is een populaire Chrome-extensie voor point-and-click dataverzameling. Het is eenvoudig, gratis voor lokaal gebruik en biedt een cloudservice voor grotere taken.
- Beste voor: Snelle, eenmalige scrapingtaken.
- Prijzen: Gratis extensie; cloudabonnementen vanaf ongeveer $50 per maand.
13. ParseHub
Voor wie: Niet-technische gebruikers die meer kracht nodig hebben dan basistools bieden.
ParseHub is een desktopapp met een visuele workflow voor het scrapen van dynamische content, waaronder kaarten en formulieren. Je kunt projecten in de cloud uitvoeren en er is een API beschikbaar.
- Beste voor: Digitale marketeers, analisten en journalisten.
- Prijzen: Gratis versie (200 pagina's per run); betaalde plannen vanaf $189 per maand.
14. Diffbot
Voor wie: Enterprises en AI-bedrijven die grootschalige, gestructureerde webdata nodig hebben.
Diffbot gebruikt computer vision en NLP om automatisch data te extraheren van elke webpagina, met API's voor artikelen, producten en een enorm knowledge graph.
- Beste voor: Marktintelligentie, finance en trainingsdata voor AI.
- Prijzen: Premium, vanaf ongeveer $299 per maand.
15. DataMiner
Voor wie: Niet-technische gebruikers, vooral in sales, marketing en journalistiek.
DataMiner is een Chrome-extensie voor snelle, point-and-click webdata-extractie. Het heeft een bibliotheek met kant-en-klare “recepten” en kan direct naar Google Sheets exporteren.
- Beste voor: Snelle taken zoals tabellen of lijsten exporteren naar spreadsheets.
- Prijzen: Gratis versie (500 pagina's per dag); Pro vanaf ongeveer $19 per maand.
De beste AI-webscraper-tools vergelijken: welke past bij jouw behoeften?
Hier is een vergelijking op hoofdlijnen om je te helpen kiezen:
| Tool | AI/LLM-gebruik | Gebruiksgemak | Output/integratie | Ideaal voor | Prijzen |
|---|---|---|---|---|---|
| Thunderbit | Natuurlijke-taalinterface; AI stelt velden voor | Het makkelijkst (no-code chat) | Export naar Sheets, Airtable, Notion | Niet-technische teams | Gratis versie; Pro vanaf ~$30/maand |
| Crawl4AI | AI-ready crawlen; LLM's integreren | Moeilijk (Python-coding) | Bibliotheek/CLI; integratie via code | Devs die snelle AI-datapijplijnen nodig hebben | Gratis |
| ScrapeGraphAI | LLM-promptpipelines voor scraping | Gemiddeld (wat code of API) | API/SDK; JSON-output | Devs/analisten die AI-agents bouwen | Gratis OSS; API vanaf $20/maand |
| Firecrawl | Crawlt naar LLM-ready Markdown/JSON | Gemiddeld (API/SDK-gebruik) | SDK's (Py, Node, enz.); LangChain-integratie | Devs die live webdata aan AI koppelen | Gratis + betaalde cloud |
| Browse AI | AI-ondersteund point & click | Makkelijk (no-code) | 7000+ app-integraties (Zapier) | Niet-technische gebruikers die webmonitoring automatiseren | Gratis 50 runs; Betaald vanaf $19/maand |
| LLM Scraper | Gebruikt LLM's om pagina's naar schema te parsen | Moeilijk (TS/JS-coding) | Codebibliotheek; JSON-output | Devs die AI het parsewerk willen laten doen | Gratis (gebruik je eigen LLM-API) |
| Reader (Jina) | AI-model extraheert tekst/JSON | Makkelijk (simpele API-call) | REST-API levert Markdown/JSON | Devs die webzoek-/contentdata aan LLM's toevoegen | Gratis API |
| Bright Data | AI-verrijkte scraping-API's; groot proxynetwerk | Moeilijk (API, technisch) | API's/SDK's; datastreams of datasets | Enterprise-schaal | Gebaseerd op gebruik |
| Octoparse | AI herkent lijsten automatisch | Gemiddeld (no-code app) | CSV/Excel, API voor resultaten | Licht-technische gebruikers | Gratis beperkt; $59–$166/maand |
| Apify | Enkele AI-functies (Actors, AI-tutorials) | Moeilijk (codescripts) | Uitgebreide API; integreert met LangChain | Devs die aangepaste scraping in de cloud willen | Gratis versie; pay-as-you-go |
| Zyte (Scrapy) | ML-gebaseerde auto-extractie; Scrapy-framework | Moeilijk (Python-coding) | API, Scrapy Cloud UI; JSON/CSV | Dev-teams, langlopende projecten | Maatwerkprijzen |
| Webscraper.io | Geen AI (handmatige sjablonen) | Makkelijk (browserextensie) | CSV-download, Cloud API | Beginners, snelle eenmalige scrapes | Gratis extensie; Cloud vanaf ~$50/maand |
| ParseHub | Geen expliciete LLM; visuele builder | Gemiddeld (no-code app) | JSON/CSV; API voor cloudruns | Niet-ontwikkelaars die complexe sites scrapen | Gratis 200 pagina's; Betaald vanaf $189/maand |
| Diffbot | AI vision/NLP voor elke pagina; knowledge graph | Makkelijk (alleen API-calls) | API's (Article/Prod/...) + Knowledge Graph-query | Enterprise, gestructureerde webdata | Vanaf ~$299/maand |
| DataMiner | Geen LLM; community-recepten | Het makkelijkst (browser-UI) | Export naar Excel/CSV; Google Sheets | Niet-technische gebruikers die naar spreadsheets scrapen | Gratis beperkt; Pro vanaf ~$19/maand |
Toolcategorieën: van ontwikkelaarspowerhouses tot gebruiksvriendelijke webscrapers voor bedrijven
Om deze lijst beter te begrijpen, kunnen we de tools opdelen in een paar categorieën:
1. Powerhouses voor ontwikkelaars en open source
- Voorbeelden: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Sterktes: Veel flexibiliteit, schaal en maatwerk. Ideaal voor het bouwen van aangepaste pipelines of integratie met AI-modellen.
- Nadelen: Vereisen programmeerkennis en meer configuratie.
- Toepassingen: Een aangepaste datapijplijn bouwen, complexe sites scrapen of integreren met interne systemen.
2. AI-geïntegreerde scraping-agents
- Voorbeelden: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Sterktes: Verkleinen de kloof tussen scrapen en data begrijpen. Natuurlijke-taalinterfaces maken ze toegankelijk.
- Nadelen: Sommige zijn nog in ontwikkeling; ze bieden mogelijk minder fijnmazige controle.
- Toepassingen: Snelle antwoorden of datasets, autonome agents bouwen of live data aan LLM's voeden.
3. No-code/low-code webscrapers voor bedrijven
- Voorbeelden: Thunderbit, Browse AI, Octoparse, ParseHub, Webscraper.io, DataMiner
- Sterktes: Gebruiksvriendelijk, weinig tot geen codering nodig, geschikt voor terugkerende zakelijke taken.
- Nadelen: Kunnen moeite hebben met erg complexe websites of enorme schaal.
- Toepassingen: Leadgeneratie, concurrentiemonitoring, onderzoeksprojecten en eenmalige data-extracties.
4. Enterprise-dataplatforms en -diensten
- Voorbeelden: Bright Data, Diffbot, Zyte
- Sterktes: Full-stack oplossingen, beheerde diensten, compliance en betrouwbaarheid op schaal.
- Nadelen: Hogere kosten, meer onboarding nodig.
- Toepassingen: Grootschalige, altijd actieve datapijplijnen, marktinformatie en trainingsdata voor AI.
Hoe kies je de juiste AI-webcrawler voor jouw webscrapingbehoeften?
Wat is data scraping en hoe doe je het Get Started Free
De juiste tool kiezen kan overweldigend voelen, dus hier is mijn stapsgewijze aanpak:
- Bepaal je doelen en databehoeften: Welke sites en data heb je nodig? Hoe vaak? Hoeveel? Wat ga je ermee doen?
- Beoordeel je technische niveau: Geen code? Probeer Thunderbit, Browse AI of Octoparse. Wel wat scripting? LLM Scraper of DataMiner. Sterke dev-skills? Crawl4AI, Apify of Zyte.
- Denk aan frequentie en schaal: Eenmalig? Gebruik gratis tools. Terugkerend? Zoek naar planningsfuncties. Grootschalig? Enterprise-tools of open source op schaal.
- Budget en prijsmodel: Gratis abonnementen zijn ideaal om te testen. Abonnement versus gebruiksgebaseerd hangt af van je behoeften.
- Proef en proof of concept: Test een paar tools op je echte data. De meeste hebben een gratis versie.
- Onderhoud en support: Wie lost het op als de site verandert? No-code-tools met AI kunnen kleine wijzigingen automatisch herstellen; open source leunt op jou of de community.
- Koppel tools aan scenario's: Salesteam dat leads scrapt? Thunderbit of Browse AI. Onderzoeker die tweets verzamelt? DataMiner of Webscraper.io. AI-model dat nieuwsartikelen nodig heeft? Jina Reader of Zyte. Een vergelijkingssite bouwen? Apify of Zyte.
- Zorg voor een back-up: Soms werkt één tool niet voor een specifieke site. Heb een alternatief achter de hand.
De “juiste” tool is degene die je de data geeft die je nodig hebt, met zo min mogelijk frictie en binnen je budget. Soms is dat een combinatie van tools.
Thunderbit versus traditionele webscraper-tools: wat maakt het anders?
Laten we concreet maken waarom Thunderbit anders is:
- Interface in natuurlijke taal: Geen code, geen point-and-click-circus. Beschrijf gewoon wat je wilt (bron).
- Geen configuratie en sjabloonsuggesties: Thunderbit detecteert automatisch paginering, subpagina's en stelt zelfs sjablonen voor veelvoorkomende sites voor (bron).
- AI-gestuurde datacleaning en verrijking: Vat samen, categoriseer, vertaal en verrijk data terwijl je scrapt (bron).
- Minder onderhoudsproblemen: Thunderbit's AI is bestand tegen kleine sitewijzigingen, waardoor er minder snel iets stukgaat.
- Integratie met zakelijke tools: Direct exporteren naar Google Sheets, Airtable en Notion — geen gedoe meer met CSV's (bron).
- Snelle time-to-value: Van idee naar data in minuten, niet in dagen.
- Leercurve: Als je kunt browsen en kunt beschrijven wat je nodig hebt, kun je Thunderbit gebruiken.
- Aanpasbaarheid: Scrape websites, PDF's, afbeeldingen en meer — allemaal met dezelfde tool.
Thunderbit is niet zomaar een scraper — het is een data-assistent die in je workflow past, of je nu in sales, marketing, ecommerce of vastgoed werkt.
Probeer Thunderbit AI Web Scraper
Best practices voor webscraping met AI-webscraper-tools
Om het maximale uit AI-webscrapers te halen, zijn hier mijn belangrijkste tips:
- Definieer je databehoefte duidelijk: Weet welke velden je wilt, hoeveel pagina's je nodig hebt en in welk formaat.
- Gebruik AI-suggesties: Gebruik veldherkenning en AI-suggesties van tools om belangrijke data op te vangen die je anders zou missen (bron).
- Begin klein en valideer: Test op een kleine steekproef, controleer de output en pas aan waar nodig.
- Ga om met dynamische content: Zorg dat je tool dynamische content en interacties ondersteunt (paginering, oneindig scrollen, enz.).
- Respecteer websitebeleid: Controleer robots.txt, scrape geen gevoelige data en houd je aan rate limits.
- Integreer voor automatisering: Gebruik exportfuncties en webhooks om gescrapete data direct in je workflow te zetten.
- Bewaar de datakwaliteit: Doe een sanity check op je data, gebruik nabewerking en monitor op fouten.
- Wees beknopt met prompts: Bij AI-gestuurde tools leveren duidelijke en specifieke instructies betere resultaten op.
- Leer van de community: Sluit je aan bij forums en communities voor tips en troubleshooting.
- Blijf up-to-date: AI-tools ontwikkelen zich snel — houd nieuwe functies en verbeteringen in de gaten.
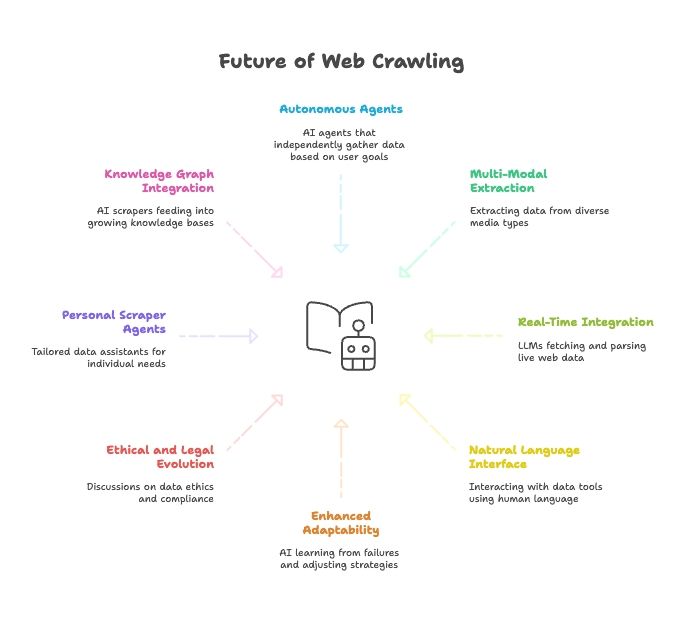
De toekomst van webscraping: AI, LLM's en de opkomst van webscraper-agents in natuurlijke taal
Vooruitkijkend gaat de combinatie van AI en webscraping alleen maar sneller.
- Volledig autonome scraper-agents: Straks vertel je een AI-agent gewoon je einddoel, en bedenkt die zelf hoe de data opgehaald moet worden.
- Multimodale data-extractie: Scrapers halen data uit tekst, afbeeldingen, PDF's en zelfs video's.
- Realtime-integratie met AI-modellen: LLM's krijgen ingebouwde modules om live webdata op te halen en te parsen.
- Alles in natuurlijke taal: We praten met onze datatools zoals we met mensen praten, waardoor dataverzameling en -transformatie voor iedereen toegankelijk worden.
- Grotere aanpasbaarheid: AI-scrapers leren van fouten en passen strategieën automatisch aan.
- Ethische en juridische ontwikkeling: Verwacht meer discussie over data-ethiek, compliance en fair use.
- Persoonlijke scraper-agents: Stel je een persoonlijke data-assistent voor die nieuws, vacatures en meer verzamelt, afgestemd op jouw behoeften.
- Integratie met knowledge graphs: AI-scrapers voeden voortdurend steeds grotere kennisbanken, waardoor slimmere AI mogelijk wordt.
Kortom? De toekomst van webscraping is nauw verweven met de toekomst van AI. De tools worden elke dag slimmer, autonomer en toegankelijker.
Conclusie: zakelijke waarde ontsluiten met de juiste AI-webcrawler
Webscraping is dankzij AI van een niche, technische vaardigheid uitgegroeid tot een kerncompetentie voor bedrijven. De 15 tools die ik hier heb besproken laten zien wat er in 2026 mogelijk is — van ontwikkelaarspowerhouses tot gebruiksvriendelijke assistenten voor bedrijven.
Het echte geheim? De juiste tool kiezen kan de waarde die je uit webdata haalt enorm vergroten. Voor niet-technische teams is Thunderbit de makkelijkste manier om van het web een gestructureerde, analyseklare database te maken — geen code, geen gedoe, gewoon resultaat.
Dus of je nu leads verzamelt, concurrenten monitort of je volgende AI-model voedt: neem de tijd om je behoeften te beoordelen, probeer een paar tools uit en kijk wat voor jou werkt. En als je de toekomst van webscraping vandaag al wilt ervaren, probeer Thunderbit dan eens. De inzichten die je nodig hebt, zitten maar één prompt van je vandaan.
Meer weten? Bekijk de Thunderbit-blog voor verdiepende artikelen, tutorials en het nieuwste op het gebied van AI-gestuurde data-extractie.
Verder lezen:
- Wat is data scraping en hoe doe je het in 2026
- Hoe je website-data naar Excel scrapt met AI
- De beste webscraping-tools & software in 2026
Probeer AI Web Scraper Get Started Free
FAQ's
1. Wat is een AI-webcrawler en hoe verschilt die van traditionele webscrapers?
Een AI-webcrawler gebruikt natuurlijke taalverwerking en machine learning om webdata te begrijpen, extraheren en structureren. In tegenstelling tot traditionele scrapers die handmatige codering en XPath-selectors vereisen, kunnen AI-tools dynamische content verwerken, zich aanpassen aan lay-outwijzigingen en gebruikersinstructies in gewoon Engels interpreteren.
2. Wie zou AI-webscrapingtools zoals Thunderbit moeten gebruiken?
Thunderbit is gebouwd voor zowel niet-technische als technische gebruikers. Het is ideaal voor professionals in sales, marketing, operations, research en ecommerce die gestructureerde data uit websites, PDF's of afbeeldingen willen halen — zonder code te schrijven.
3. Welke functies maken Thunderbit anders dan andere AI-webcrawlers?
Thunderbit biedt een interface in natuurlijke taal, crawlen op meerdere niveaus, automatische datastructurering, OCR-ondersteuning en naadloze export naar platforms zoals Google Sheets en Airtable. Daarnaast zijn er AI-gestuurde veldsuggesties en vooraf gebouwde sjablonen voor populaire sites.
4. Zijn er in 2026 gratis opties voor AI-webscraping?
Ja. Veel tools zoals Thunderbit, Browse AI en DataMiner bieden gratis abonnementen met beperkt gebruik. Voor ontwikkelaars bieden open-source opties zoals Crawl4AI en ScrapeGraphAI volledige functionaliteit zonder kosten, al vragen ze wel technische setup.
5. Hoe kies ik de juiste AI-webcrawler voor mijn behoeften?
Begin met het bepalen van je datadoelen, technische niveau, budget en schaalvereisten. Wil je een no-code, gebruiksvriendelijke oplossing, dan zijn Thunderbit of Browse AI goede keuzes. Voor grootschalige of maatwerkbehoeften zijn tools zoals Apify of Bright Data beter geschikt.




