Laat me je meenemen naar mijn eerste stappen in de wereld van webscraping. Stel je voor: het is 2015, ik zit in een klein appartementje in New Jersey, al drie bakken koffie achter de kiezen, en ik ben aan het stoeien met een Python-script dat steeds crasht zodra de website die ik wil scrapen zijn opmaak verandert. Mijn favoriete tools toen? Beautiful Soup en Selenium. Fast forward naar 2025: de discussie over “Beautiful Soup vs Selenium” is nog steeds springlevend, maar het speelveld is compleet veranderd door AI. De tools van nu doen veel meer dan alleen HTML uitlezen – ze snappen de inhoud, volgen links alsof het mensen zijn, halen gestructureerde data op met gewone taal, en kunnen die zelfs direct opschonen, samenvatten of vertalen.
Webscraping is tegenwoordig allang niet meer alleen voor techneuten. Het is een onmisbare workflow geworden voor sales, marketing, e-commerce en operations teams die razendsnel actuele, gestructureerde data willen hebben. Met de webscrapingmarkt die inmiddels boven de uitkomt en nieuwe AI-gedreven tools zoals die alles op z’n kop zetten, is de vraag niet meer alleen “Welke Python webscraper moet ik kiezen?” maar vooral: “Hoe krijg ik de data die ik nodig heb, zonder gedoe, onderhoud of technische kopzorgen?” Laten we de strijd tussen Beautiful Soup en Selenium induiken – en ontdekken hoe AI de spelregels verandert.
Beautiful Soup vs Selenium: Wat is het verschil?
Als je ooit hebt gezocht op “python webscraper”, ben je ongetwijfeld zowel als tegengekomen. Maar wat maakt ze nu echt anders?
Zie Beautiful Soup als een supersnelle bibliothecaris. Het is een Python-bibliotheek die gemaakt is om data uit statische HTML- of XML-bestanden te vissen. Staat de info die je zoekt al in de broncode van de pagina? Dan vindt Beautiful Soup het vliegensvlug, ordent het netjes en levert het je op een presenteerblaadje aan. Het is licht, snel en hoeft de pagina niet “te zien” zoals een mens – het leest gewoon de ruwe HTML.
Selenium daarentegen is meer een robot-assistent die daadwerkelijk een browser kan bedienen. Het automatiseert echte browseracties: klikken, formulieren invullen, inloggen, scrollen en wachten tot JavaScript geladen is. Selenium is ideaal als de data pas zichtbaar wordt na interactie of als de pagina dynamisch opgebouwd wordt met JavaScript.
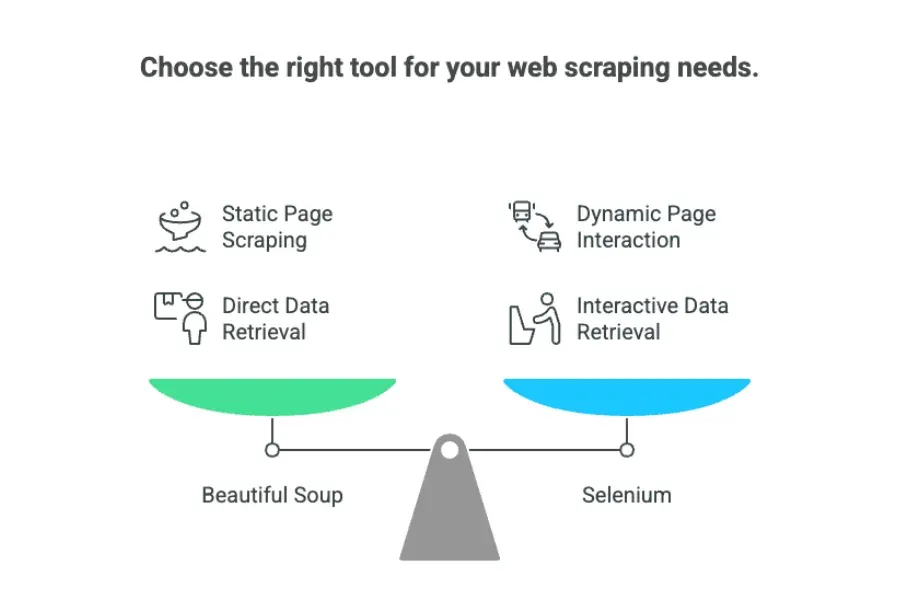
Kortom, in de discussie “beautiful soup vs selenium” komt het hierop neer:
- Beautiful Soup: Perfect voor statische pagina’s waar de data direct in de HTML staat.
- Selenium: Onmisbaar voor dynamische sites die interactie of laadtijd vereisen.
Voor niet-technische gebruikers een simpele vergelijking:
- Beautiful Soup is als informatie overnemen uit een papieren catalogus.
- Selenium is als iemand naar de winkel sturen om door de catalogus te bladeren, op knoppen te drukken en de nieuwste prijzen op te zoeken.
Veelvoorkomende uitdagingen: Beperkingen van Beautiful Soup en Selenium
Laten we eerlijk zijn over de valkuilen. Als iemand die meer uren dan me lief is heeft gespendeerd aan het debuggen van kapotte scrapers, zijn dit de grootste problemen met Beautiful Soup en Selenium:
1. Gevoeligheid voor websitewijzigingen
Beide tools zijn erg kwetsbaar voor veranderingen in de structuur van websites. Als de eigenaar een class-naam aanpast of een div verplaatst, kan je scraper van de ene op de andere dag stoppen met werken. Zoals : “de onderhoudskosten zijn soms tien keer zo hoog als de ontwikkelkosten.” Auw.
2. Snelheid (of het gebrek daaraan)
- Beautiful Soup is snel met parsen, maar als je duizenden pagina’s na elkaar moet scrapen, kost het alsnog veel tijd.
- Selenium is een stuk trager – elke pagina vereist het opstarten van een browser, wachten op scripts en interactie met de interface. Schalen met Selenium betekent veel browsers draaien, wat veel CPU en geheugen vraagt.
3. Beperkte herbruikbaarheid van code
Elke website is anders. Je moet dus voor elke site aparte parsing-logica schrijven, en als de site verandert, kun je weer opnieuw beginnen. Er is geen universeel script dat overal werkt.
4. Technische complexiteit
Beide tools vragen om Python-kennis, inzicht in HTML/CSS-selectors en (voor Selenium) kennis van browserdrivers. Voor niet-programmeurs is dit een flinke drempel.
5. Onderhoudsintensief
Scrapers draaiende houden is een doorlopende klus. Websites veranderen, anti-botmaatregelen worden strenger, en je moet je scripts continu bijhouden. Voor bedrijven betekent dit afhankelijk zijn van developers of het uitbesteden van scraping.
Verder dan traditionele Python webscraper tools: De opkomst van AI-gedreven oplossingen
Nu wordt het interessant. De afgelopen jaren zijn er AI-webscrapers opgekomen – tools die met grote taalmodellen (zoals GPT) websites kunnen “lezen” en data ophalen, zonder dat je hoeft te programmeren.
Maak kennis met Thunderbit: AI-webscraper voor zakelijke gebruikers
is een Chrome-extensie waarmee je elke website in slechts twee klikken kunt scrapen. Geen Python, geen code, geen gedoe met browserdrivers. Gewoon aanwijzen, klikken en de AI doet de rest.
Waarom AI-webscrapers zoals Thunderbit zo’n gamechanger zijn
- Echt no-code, geen moeite: Thunderbit is niet alleen “no code” – het is “geen moeite”. Je hoeft niets in te stellen. Installeer de , ga naar de gewenste pagina en laat de AI de velden voorstellen die je wilt ophalen.
- Kan overweg met dynamische content: Omdat het in de browser werkt, ziet Thunderbit alles wat jij ziet – ook data die door JavaScript wordt geladen, na klikken of achter een login.
- Snel en accuraat: Thunderbit’s AI kan meerdere pagina’s tegelijk scrapen en is ontworpen voor snelheid en precisie, vooral voor zakelijke toepassingen zoals leadgeneratie, e-commerce en vastgoed.
- Geen onderhoud: Zie Thunderbit als een AI-assistent die nooit moe wordt. Als de website verandert, past de AI zich aan. Nooit meer code herschrijven als een div verschuift.
- Data opschonen en verrijken: Thunderbit haalt niet alleen ruwe data op – het kan data labelen, formatteren, vertalen en zelfs samenvatten tijdens het scrapen. Het is alsof je 10.000 webpagina’s aan ChatGPT geeft en een gestructureerd, opgeschoond spreadsheet terugkrijgt.
Het resultaat? Zakelijke gebruikers kunnen eindelijk zelf de data ophalen die ze nodig hebben, zonder te wachten op IT of Python te leren.
Thunderbit vs Beautiful Soup vs Selenium: Snel overzicht
Hier een vergelijking van deze tools voor zakelijke gebruikers:
| Criteria | Beautiful Soup | Selenium | Thunderbit (AI-webscraper) |
|---|---|---|---|
| Installatie | Simpele Python-installatie | Complex (browserdrivers) | Chrome-extensie, geen setup |
| Gebruiksgemak | Makkelijk voor programmeurs | Lastiger, vereist code | No-code, gebruiksvriendelijk |
| Snelheid | Snel bij statische pagina’s | Traag (browser overhead) | Snel bij kleine/middelgrote jobs, niet voor miljoenen |
| Dynamische content | Kan geen JS aan | Kan alle dynamische content aan | Kan alle dynamische content aan |
| Onderhoud | Hoog (breekt bij wijzigingen) | Hoog (breekt, driver updates) | Laag (AI past zich aan) |
| Schaalbaarheid | Goed voor statisch, extra infra nodig | Moeilijk te schalen, zwaar | Beste voor kleine/middelgrote jobs, niet voor bulk |
| Data opschonen | Handmatig, achteraf | Handmatig, achteraf | Ingebouwd: labelen, formatteren, vertalen, samenvatten |
| Integraties | Eigen code | Eigen code | 1 klik naar Excel, Sheets, Airtable, Notion |
| Technische kennis | Python vereist | Python + browserkennis | Niet nodig |
Geavanceerde functies: Hoe Thunderbit webscraping voor bedrijven verandert
Wat maakt Thunderbit echt vernieuwend voor zakelijke gebruikers?
1. AI-gedreven data-extractie
Thunderbit gebruikt AI om webpagina’s te “lezen” en de beste velden voor te stellen. Je klikt op “AI Suggest Fields”, controleert de kolommen en drukt op “Scrape”. Geen selectors schrijven of HTML parsen.
2. Subpagina’s scrapen
Wil je data van een productlijst én van elke productpagina apart? Thunderbit bezoekt automatisch elke subpagina en verrijkt je datatabel – zonder extra instellingen.
3. Data opschonen, labelen en vertalen
Thunderbit’s AI kan:
- Data labelen: Voeg categorieën of tags toe tijdens het scrapen.
- Formatteren: Standaardiseer telefoonnummers, datums of prijzen.
- Vertalen: Vertaal direct de gescrapete inhoud naar je gewenste taal.
- Samenvatten: Maak samenvattingen of highlights van lange tekstvelden.
Het is alsof je een data-analist in je scraper hebt ingebouwd.
4. Naadloze integraties
Exporteer je data direct naar Excel, Google Sheets, Airtable of Notion met één klik. Geen gedoe meer met CSV’s.
5. No-code, geen onderhoud
Thunderbit is gemaakt voor zakelijke gebruikers, niet voor developers. Je hoeft geen Python te kennen en je hoeft je geen zorgen te maken over onderhoud. De AI past zich aan, zodat je workflows blijven draaien.
Meer weten over Thunderbit’s mogelijkheden? Bekijk .
De juiste tool kiezen: Praktische tips voor bedrijven
Hoe kies je nu tussen Beautiful Soup, Selenium en Thunderbit? Mijn advies, gebaseerd op jarenlange scraping-ervaring:
1. Hoeveel data heb je nodig?
- Kleine tot middelgrote projecten (enkele honderden tot duizenden pagina’s): Thunderbit is ideaal – snel, geen code, ingebouwde data cleaning.
- Grote bulk scraping (tienduizenden of miljoenen pagina’s): Beautiful Soup (eventueel met Scrapy) of enterprise-oplossingen. Thunderbit is (nog) niet bedoeld voor massale bulk scraping.
2. Heb je programmeurs beschikbaar?
- Wel developers: Beautiful Soup en Selenium geven je maximale controle.
- Geen developers, of je wilt snel schakelen: Thunderbit of een andere AI-tool.
3. Hoe vaak verandert de website?
- Regelmatige wijzigingen: Thunderbit’s AI past zich automatisch aan, dus minder onderhoud.
- Zelden wijzigingen: Beautiful Soup of Selenium kan prima, maar wees voorbereid op aanpassingen.
4. Heb je data cleaning of verrijking nodig?
- Ja: Thunderbit kan labelen, formatteren, vertalen en samenvatten tijdens het scrapen.
- Nee, alleen ruwe data: Beautiful Soup of Selenium.
Beslissingsmatrix
| Vraag | Beste tool |
|---|---|
| Geen developer, direct data nodig | Thunderbit |
| Data cleaning/vertaling tijdens scrapen nodig | Thunderbit |
| Massale schaal, eigen pipeline | Beautiful Soup/Scrapy |
| Regelmatige sitewijzigingen, weinig onderhoud | Thunderbit |
Conclusie: De toekomst van Python webscraper tools
Webscraping is enorm geëvolueerd sinds mijn eerste gevechten met kwetsbare Python-scripts. In 2025 is de discussie “beautiful soup vs selenium” nog steeds relevant, maar AI-tools zoals Thunderbit veranderen het speelveld voor bedrijven.
Beautiful Soup blijft de favoriet voor snel, lichtgewicht parsen van statische HTML – ideaal voor simpele klussen. Selenium is nog steeds de standaard voor het automatiseren van browsers en het scrapen van dynamische, interactieve sites, maar vraagt meer installatie en onderhoud.
Wil je echter geen code schrijven, geen onderhoudsproblemen en direct schone, gestructureerde data? AI-webscrapers zoals Thunderbit zijn de toekomst. Niet alleen “no code”, maar echt “geen moeite”. Voor sales-, e-commerce- en operationele teams die nú data nodig hebben (en niet na een week debuggen) is dat een enorme stap vooruit.
Mijn tip? Kijk kritisch naar je huidige scrapingprocessen. Ben je klaar met kapotte scripts, eindeloos onderhoud of wachten op developers? Probeer Thunderbit eens. De toekomst van webscraping is slimmer, sneller en toegankelijker dan ooit – en ik ben benieuwd waar het naartoe gaat.
Thunderbit zelf proberen? of lees meer tips op de . Benieuwd naar scraping van specifieke sites (Amazon, Twitter, PDF’s en meer)? Wij hebben de juiste gidsen:
Succes met scrapen – en moge je data altijd gestructureerd, actueel en zonder kopzorgen zijn.