

Stel je voor: je zit naar een website te turen met duizenden producten en je baas (of je innerlijke data-nerd) wil al die prijzen, namen en reviews het liefst gisteren nog in een spreadsheet hebben. Je kunt natuurlijk uren gaan knippen en plakken, maar waarom zou je niet gewoon Python het werk laten doen? Hier komt webscraping om de hoek kijken – en geloof me, dat is allang niet meer alleen voor hackers in hoodies of Silicon Valley-techies. Webscraping is tegenwoordig een must-have skill voor iedereen, van sales tot makelaars en marktonderzoekers. De wereldwijde markt voor webscraping-software is nu al meer dan $1 miljard waard en zal naar verwachting meer dan verdubbelen tegen 2032. Kortom: bergen data en volop kansen.
Als medeoprichter van Thunderbit help ik bedrijven al jaren om hun dataverzameling te automatiseren. Maar voordat AI-webscrapers zoals Thunderbit het mogelijk maakten om met twee klikken webdata te verzamelen, heb ik het vak geleerd met de klassieke Python-tools: beautiful soup, requests en vooral veel trial-and-error. In deze gids leg ik uit wat beautiful soup is, hoe je het installeert en gebruikt, en waarom het nog steeds een favoriet is onder datafanaten. Daarna laat ik zien hoe AI-tools zoals Thunderbit webscraping voor iedereen toegankelijk maken (en je een hoop frustratie besparen). Of je nu net begint met Python, een zakelijke gebruiker bent of gewoon nieuwsgierig naar scraping: lees vooral verder.
Wat is BeautifulSoup? Een Introductie tot Python’s Webscraping-kracht
Laten we bij het begin beginnen. beautifulsoup (vaak afgekort tot BS4) is een Python-bibliotheek waarmee je makkelijk data uit HTML- en XML-bestanden haalt. Zie het als je persoonlijke HTML-speurneus: je voert een rommelige lap webcode in, en beautiful soup maakt er een overzichtelijke, doorzoekbare boomstructuur van. Plotseling is het ophalen van een productnaam, prijs of review net zo simpel als het opvragen van een tag of classnaam.
beautiful soup haalt zelf geen webpagina’s op (daarvoor gebruik je bijvoorbeeld requests), maar zodra je de HTML hebt, kun je razendsnel zoeken, filteren en precies de data eruit halen die je nodig hebt. Niet voor niets koos meer dan 43% van de ontwikkelaars in een recente enquête voor beautiful soup als hun favoriete webscraping-tool – meer dan welke andere bibliotheek dan ook.
beautiful soup wordt gebruikt voor van alles: van academisch onderzoek tot e-commerce-analyses en leadgeneratie. Marketingteams bouwen er influencer-lijsten mee, recruiters halen vacatures binnen en journalisten automatiseren hun research. Het is flexibel, vergevingsgezind en – als je een beetje Python kent – verrassend toegankelijk.
Waarom BeautifulSoup gebruiken? Zakelijke voordelen en praktijkvoorbeelden
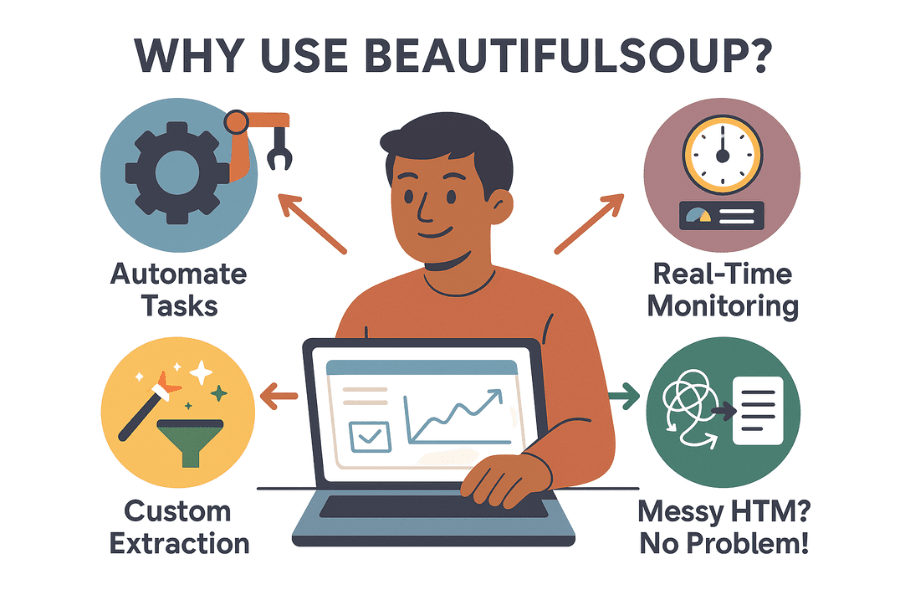
Waarom kiezen zoveel bedrijven en data-analisten voor beautiful soup? Dit zijn de belangrijkste redenen:
- Automatiseert saaie klusjes: Waarom handmatig kopiëren en plakken als een script het voor je doet? beautiful soup verzamelt in een paar minuten duizenden datapunten, zodat jij je op belangrijkere dingen kunt richten.
- Realtime monitoring: Stel scripts in om bijvoorbeeld prijzen van concurrenten, voorraad of nieuwsberichten automatisch te checken. Geen FOMO meer – als je concurrent zijn prijs verlaagt, weet jij het als eerste.
- Maatwerk data-extractie: Wil je de top 10 trending producten inclusief beoordelingen? beautiful soup geeft je volledige controle over wat je verzamelt en hoe je het verwerkt.
- Kan overweg met rommelige HTML: Zelfs als de code van een website een zooitje is, weet beautiful soup er meestal wel raad mee.
Hier een paar concrete toepassingen:
| Toepassing | Beschrijving | Voorbeeldresultaat |
|---|---|---|
| Leadgeneratie | Bedrijvengidsen of LinkedIn scrapen voor e-mails en telefoonnummers | Gerichte saleslijsten voor acquisitie |
| Prijsmonitoring | Prijzen van concurrenten op e-commerce sites volgen | Je eigen prijzen direct aanpassen |
| Marktonderzoek | Reviews, beoordelingen of productdetails verzamelen | Trends ontdekken en productontwikkeling sturen |
| Vastgoedgegevens | Woningen verzamelen van sites als Zillow of Realtor.com | Prijsontwikkelingen of investeringskansen analyseren |
| Contentaggregatie | Nieuwsartikelen, blogs of social media-berichten verzamelen | Nieuwsbrieven of sentimentanalyses voeden |
En het resultaat? Een Britse retailer gebruikte webscraping om concurrenten te monitoren en zag de omzet met 4% stijgen. ASOS verdubbelde de internationale verkoop door hun marketing aan te passen op basis van gescrapete lokale prijzen. Kortom: data uit webscraping leidt tot échte zakelijke beslissingen.
Aan de slag: BeautifulSoup installeren in Python
Klaar om te beginnen? Zo zet je beautiful soup op:
Stap 1: Installeer beautiful soup (op de juiste manier)
Zorg dat je de nieuwste versie installeert – beautiful soup 4 (bs4). Laat je niet foppen door de oude pakketnaam!
pip install beautifulsoup4
Gebruik je macOS of Linux, dan kan het zijn dat je pip3 of sudo moet gebruiken:
sudo pip3 install beautifulsoup4
Tip: Als je per ongeluk pip install beautifulsoup (zonder de “4”) gebruikt, krijg je een oude, niet-compatibele versie. Geloof me, dat wil je niet.
Stap 2: Installeer een parser (optioneel, maar slim)
beautiful soup werkt met de standaard HTML-parser van Python, maar voor snelheid en betrouwbaarheid kun je beter lxml en html5lib installeren:
pip install lxml html5lib
Stap 3: Installeer Requests (om webpagina’s op te halen)
beautiful soup verwerkt HTML, maar je moet het eerst ophalen. De requests bibliotheek is hiervoor de standaard:
pip install requests
Stap 4: Check je Python-omgeving
Zorg dat je Python 3 gebruikt. Werk je in een IDE (zoals PyCharm of VS Code), check dan even welke interpreter je gebruikt. Krijg je importfouten, dan installeer je de pakketten misschien in de verkeerde omgeving. Op Windows kun je met py -m pip install beautifulsoup4 het juiste Python-versie kiezen.
Stap 5: Test je installatie
Doe deze snelle check:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Zie je de <title>-tag verschijnen? Dan ben je klaar om te starten.
BeautifulSoup Basics: Belangrijke concepten en syntax uitgelegd
Dit zijn de kernbegrippen die je bij beautiful soup gebruikt:
- BeautifulSoup-object: Het startpunt van je geparste HTML-boom. Maak je aan met
BeautifulSoup(html, parser). - Tag: Staat voor een HTML- of XML-tag (zoals
<div>,<p>,<span>). Je kunt attributen, kinderen en tekst uitlezen. - NavigableString: De tekst die binnen een tag staat.
De parse tree begrijpen
Zie je HTML als een stamboom: de <html>-tag is de stam, <head> en <body> zijn de kinderen, enzovoort. Met beautiful soup navigeer je makkelijk door deze boomstructuur met Python.
Voorbeeld:
html = """
<html>
<head><title>Mijn testpagina</title></head>
<body>
<p class="story">Er was eens <b>drie kleine zusjes</b>...</p>
</body>
</html>
"""
soup = BeautifulSoup(html, "html.parser")
# Toegang tot de title-tag
print(soup.title) # <title>Mijn testpagina</title>
print(soup.title.string) # Mijn testpagina
# Eerste <p>-tag en class-attribuut uitlezen
p_tag = soup.find('p', class_='story')
print(p_tag['class']) # ['story']
# Alle tekst binnen de <p>-tag ophalen
print(p_tag.get_text()) # Er was eens drie kleine zusjes...
Navigeren en zoeken
- Element-accessors:
soup.head,soup.body,tag.parent,tag.children - find() / find_all(): Zoek tags op naam of attribuut.
- select(): Gebruik CSS-selectors voor complexe zoekopdrachten.
Voorbeeld:
# Alle links vinden
for link in soup.find_all('a'):
print(link.get('href'))
# CSS-selector voorbeeld
for item in soup.select('div.product > span.price'):
print(item.get_text())
Zelf aan de slag: Je eerste webscraper bouwen met BeautifulSoup
Tijd om praktisch te worden. Stel, je wilt producttitels en prijzen scrapen van een e-commerce zoekpagina (bijvoorbeeld Etsy). Zo pak je dat aan:
Stap 1: Haal de webpagina op
import requests
from bs4 import BeautifulSoup
url = "https://www.etsy.com/search?q=clothes"
headers = {"User-Agent": "Mozilla/5.0"} # Sommige sites vereisen een user-agent
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, 'html.parser')
Stap 2: Data parsen en extraheren
Stel dat elk product in een <li class="wt-list-unstyled"> staat, met de titel in <h3 class="v2-listing-card__title"> en de prijs in <span class="currency-value">.
items = []
for item in soup.find_all('li', class_='wt-list-unstyled'):
title_tag = item.find('h3', class_='v2-listing-card__title')
price_tag = item.find('span', class_='currency-value')
if title_tag and price_tag:
title = title_tag.get_text(strip=True)
price = price_tag.get_text(strip=True)
items.append((title, price))
Stap 3: Opslaan als CSV of Excel
Met de ingebouwde csv-module van Python:
import csv
with open("etsy_products.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["Producttitel", "Prijs"])
writer.writerows(items)
Of met pandas:
import pandas as pd
df = pd.DataFrame(items, columns=["Producttitel", "Prijs"])
df.to_csv("etsy_products.csv", index=False)
Nu heb je een spreadsheet klaar voor analyse, rapportage of gewoon om te laten zien.
Uitdagingen met BeautifulSoup: Onderhoud, anti-scraping en beperkingen
Tijd voor een reality check: hoe fijn beautiful soup ook is, het heeft zo zijn nadelen – zeker als je op grote schaal of langdurig wilt scrapen.
1. Gevoelig voor websitewijzigingen
Websites veranderen regelmatig hun lay-out, classnamen of de volgorde van elementen. Je beautiful soup-script werkt alleen zolang de selectors kloppen. Als een site zijn HTML aanpast, kan je script zomaar stukgaan – soms zonder dat je het merkt. Scrape je tientallen of honderden sites, dan is het bijhouden van al die scripts een flinke klus.
2. Anti-scrapingmaatregelen
Moderne websites zetten allerlei barrières op: CAPTCHAs, IP-blokkades, limieten op het aantal verzoeken, dynamische content via JavaScript, enzovoort. beautiful soup kan dit niet zelfstandig oplossen. Je zult proxies, headless browsers of zelfs externe CAPTCHA-oplossers moeten inzetten. Het is soms een kat-en-muisspel met websitebeheerders.
3. Schaalbaarheid en prestaties
beautiful soup is ideaal voor eenmalige scripts of kleine dataverzamelingen. Maar als je miljoenen pagina’s wilt scrapen of taken parallel wilt uitvoeren, moet je zelf extra code schrijven voor foutafhandeling, herstarten en infrastructuur. Het kan – maar het kost tijd en moeite.
4. Technische drempel
Eerlijk is eerlijk: als je niet vertrouwd bent met Python, HTML en debuggen, kan beautiful soup best overweldigend zijn. Zelfs voor ervaren ontwikkelaars is scrapen vaak een cyclus van inspecteren, coderen, testen, aanpassen en weer opnieuw.
5. Juridische en ethische aspecten
Webscraping zit soms in een juridisch grijs gebied, zeker als je robots.txt of de gebruiksvoorwaarden negeert. Met code ben je zelf verantwoordelijk voor netjes werken: beperk het aantal verzoeken, respecteer de regels van de site en ga ethisch om met data.
Verder dan BeautifulSoup: Hoe AI-tools zoals Thunderbit webscraping makkelijker maken
Gebruik AI om data van elke website te scrapen Get Started Free
Nu wordt het pas echt interessant. Dankzij AI zijn tools als Thunderbit er nu voor iedereen – niet alleen voor programmeurs.
Thunderbit is een AI-webscraper voor Chrome waarmee je met twee klikken data van elke website haalt. Geen Python, geen selectors, geen onderhoud. Je opent de pagina, klikt op “AI Suggest Fields” en Thunderbit’s AI herkent automatisch de relevante data (productnamen, prijzen, reviews, e-mails, telefoonnummers, enzovoort). Daarna klik je op “Scrape” en je bent klaar.
Thunderbit vs. BeautifulSoup: Vergelijking naast elkaar
| Functie | BeautifulSoup (coderen) | Thunderbit (No-Code AI) |
|---|---|---|
| Installatiegemak | Vereist Python, HTML-kennis en debuggen | Geen code – AI detecteert velden automatisch, klik-en-klaar |
| Snelheid van data ophalen | Uren (code schrijven en testen) | Minuten (2–3 klikken) |
| Aanpassingsvermogen bij wijzigingen | Breekt bij HTML-wijzigingen; handmatig bijwerken nodig | AI past zich aan veel wijzigingen aan; sjablonen voor populaire sites worden onderhouden |
| Paginering/subpagina’s | Handmatig lussen en verzoeken per pagina/subpagina | Ingebouwde paginering en subpagina-scraping – gewoon een instelling aanzetten |
| Anti-botmaatregelen | Zelf proxies, CAPTCHAs en browseremulatie toevoegen | Veel anti-botproblemen automatisch opgelost; browsercontext voorkomt blokkades |
| Dataverwerking | Volledige controle in code, maar je schrijft het zelf | Ingebouwde AI voor samenvatten, categoriseren, vertalen en opschonen |
| Exportmogelijkheden | Eigen code voor CSV, Excel, database, enz. | Eén klik export naar CSV, Excel, Google Sheets, Airtable, Notion |
| Schaalbaarheid | Onbeperkt als je zelf de infrastructuur bouwt; je beheert fouten, retries en schaal | Hoog – cloud/extensie regelt parallelle taken, planning en grote jobs (afhankelijk van plan/credits) |
| Kosten | Gratis (open source), maar kost tijd en onderhoud | Freemium (gratis voor kleine taken, betaald voor schaal), maar bespaart veel tijd en onderhoud |
| Flexibiliteit | Maximaal – code kan alles, als je het zelf bouwt | Dekking van de meeste standaardcases; voor uitzonderingen soms code nodig |
Meer weten? Check de Thunderbit blog en de feature documentatie.
Stapsgewijs: Data scrapen met Thunderbit versus BeautifulSoup
Laten we de workflows vergelijken door dezelfde soort productdata van een e-commerce site te scrapen.
Met BeautifulSoup
- Inspecteer de HTML-structuur van de website met de browser DevTools.
- Schrijf Python-code om de pagina op te halen (
requests), te parsen (beautiful soup) en de gewenste velden te extraheren. - Debug je selectors (classnamen, tagpaden) tot je de juiste data hebt.
- Regel paginering door lussen te schrijven voor “Volgende”-links.
- Exporteer de data naar CSV of Excel met extra code.
- Wijzigt de site? Begin weer bij stap 1.
Tijdsinvestering: 1–2 uur voor een nieuwe site (meer als je anti-botmaatregelen tegenkomt).
Met Thunderbit
- Open de gewenste website in Chrome.
- Klik op de Thunderbit-extensie.
- Klik op “AI Suggest Fields” – de AI stelt kolommen voor zoals productnaam, prijs, enz.
- Pas kolommen aan indien nodig en klik op “Scrape”.
- Zet paginering of subpagina-scraping aan met een schakelaar als dat nodig is.
- Bekijk de data in een tabel en exporteer naar je favoriete formaat.
Tijdsinvestering: 2–5 minuten. Geen code, geen debugging, geen onderhoud.
Extra: Thunderbit kan ook e-mails, telefoonnummers, afbeeldingen en zelfs formulieren automatisch invullen. Het is alsof je een razendsnelle stagiair hebt die nooit moppert over repeterend werk.
Probeer Thunderbit AI-webscraper gratis
Conclusie & Belangrijkste inzichten
Wat is data scraping en hoe doe je het in 2025 Get Started Free
Webscraping is uitgegroeid van een nichevaardigheid tot een onmisbare business-tool, van leadgeneratie tot marktonderzoek. beautifulsoup blijft een uitstekende instap voor iedereen met wat Python-kennis, dankzij de flexibiliteit en controle voor maatwerkprojecten. Maar nu websites steeds complexer worden – en zakelijke gebruikers sneller en eenvoudiger webdata willen – veranderen AI-tools zoals Thunderbit het speelveld.

Wil je graag zelf coderen en maatwerk bouwen, dan is beautiful soup nog steeds een uitstekende keuze. Maar wil je geen code schrijven, geen onderhoud en snel resultaat, dan is Thunderbit de toekomst. Waarom uren besteden aan bouwen als AI het in minuten voor je oplost?
Zelf proberen? Download de Thunderbit Chrome-extensie, of check meer tutorials op de Thunderbit Blog. En als je nog meer met Python wilt doen, blijf vooral experimenteren met beautiful soup – maar vergeet niet je polsen te strekken na al dat typen.
Veel succes met scrapen!
Probeer Thunderbit AI-webscraper Get Started Free
Verder lezen:
- Beautiful Soup Officiële Documentatie
- Wat is data scraping en hoe doe je het in 2025
- Hoe scrape je website-data naar Excel met AI
- Thunderbit YouTube-kanaal
Heb je vragen, ervaringen of wil je scraping-verhalen delen? Laat gerust een reactie achter of neem contact op. Waarschijnlijk heb ik meer scrapers gesloopt dan de meeste mensen ooit gebouwd hebben.




