
De vraag naar goed gelabelde data voor machine learning is nog nooit zo groot geweest. Elke keer dat ik met teams praat die bezig zijn met nieuwe AI-modellen—of het nu gaat om verkoopprognoses, productaanbevelingen of sentimentanalyse—komen steeds dezelfde problemen naar voren: handmatig data labeling is traag, duur en eerlijk gezegd behoorlijk frustrerend. Ik heb projecten weken, soms zelfs maanden, zien stilvallen omdat er simpelweg niet genoeg gelabelde voorbeelden waren om een model te trainen. En als de labels niet consequent zijn? Dan kun je net zo goed een gokje wagen met je model.
Gelukkig is er goed nieuws: geautomatiseerde data labeling met machine learning verandert het hele spel. Door AI het zware werk te laten doen, versnellen bedrijven niet alleen het labelingproces, maar verbeteren ze ook de nauwkeurigheid en consistentie—twee dingen die het succes van je ML-project bepalen. In deze gids leg ik uit hoe geautomatiseerde data labeling werkt, waarom het zo belangrijk is voor sterke modellen, en hoe je met tools als zelf een geautomatiseerde labeling workflow opzet—zonder dat je hoeft te programmeren.
Wat is geautomatiseerde data labeling met machine learning?
Laten we het simpel houden. Geautomatiseerde data labeling met machine learning betekent dat je algoritmes en AI-tools inzet om labels (zoals “spam” of “geen spam”, “kat” of “hond”, “positief” of “negatief”) toe te wijzen aan ruwe data—zonder dat een mens elk voorbeeld hoeft te beoordelen. Zie het als het verschil tussen duizenden vakantiefoto’s handmatig taggen of gezichtsherkenning gebruiken om ze automatisch te sorteren op persoon, locatie of stemming.
Vroeger werd data labeling vooral met de hand gedaan: mensen bekeken elk datapunt en gaven het juiste label. Dat kan best nauwkeurig zijn, maar het is traag, duur en lastig op te schalen. Geautomatiseerd labelen gebruikt juist machine learning modellen—getraind op een kleinere set handmatig gelabelde data—om de rest van je dataset te voorzien van labels. Het resultaat? Sneller, consistenter en schaalbaar labelen ().
Voor bedrijven betekent dit: betere modellen, sneller gebouwd, en minder handmatig werk. In een wereld waar data centraal staat, is dat een flinke voorsprong.
Waarom geautomatiseerde data labeling essentieel is voor sterke machine learning modellen
Het is simpel: de kwaliteit van je gelabelde data bepaalt hoe goed je machine learning model presteert. Zoals het gezegde gaat: “rommel erin, rommel eruit.” Als je labels niet kloppen of niet consequent zijn, leert je model de verkeerde dingen en worden je voorspellingen onbetrouwbaar ().
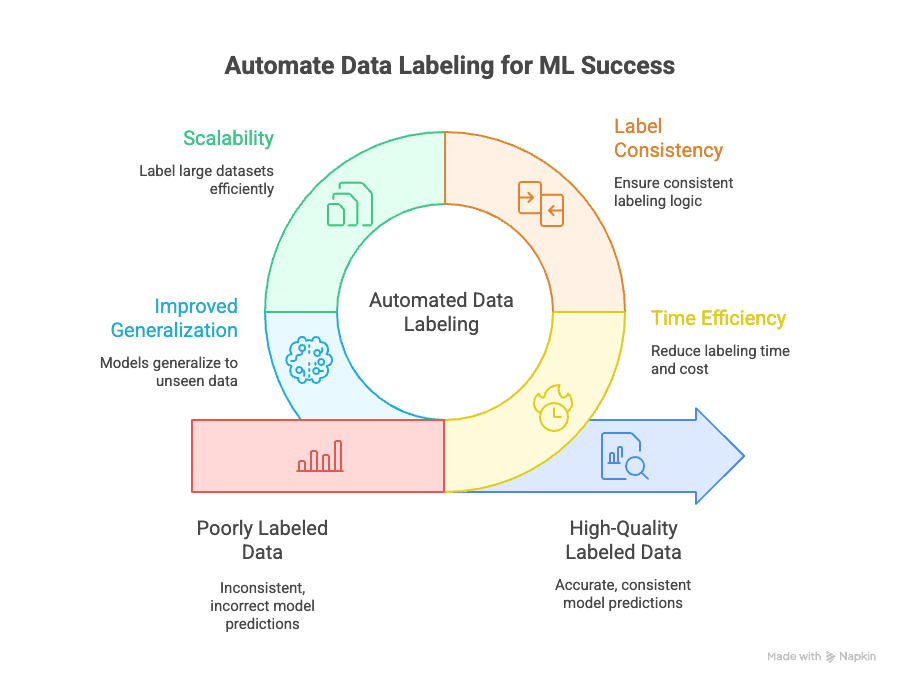
Geautomatiseerde data labeling pakt meerdere uitdagingen aan:
- Tijdbesparing: Handmatig labelen kan van een ML-project opslokken. Automatisering brengt dit terug tot een fractie, zodat je sneller kunt itereren en modellen kunt lanceren.
- Consistente labels: Machines raken niet moe of afgeleid. Automatisch labelen zorgt ervoor dat elk datapunt volgens dezelfde logica wordt gelabeld, waardoor menselijke fouten en bias afnemen ().
- Schaalbaarheid: Moet je 10.000, 100.000 of zelfs een miljoen datapunten labelen? Met automatisering is dat haalbaar—zonder dat je een heel team hoeft in te huren ().
- Betere generalisatie: Consequente, hoogwaardige labels zorgen ervoor dat je modellen beter presteren op nieuwe, onbekende data—het uiteindelijke doel van machine learning ().
En de impact op je business is groot: slecht gelabelde data kan de nauwkeurigheid van je model tot wel verlagen, terwijl goede, geautomatiseerde labeling zorgt voor snellere ontwikkeling en implementatie van modellen.
Handmatig vs. geautomatiseerd data labelen: een vergelijking
Laten we het naast elkaar zetten:
| Factor | Handmatig labelen | Geautomatiseerd labelen met ML |
|---|---|---|
| Snelheid | Traag (weken/maanden bij grote datasets) | Snel (minuten/uren bij grote datasets) |
| Nauwkeurigheid | Hoog, maar gevoelig voor menselijke fouten/inconsistentie | Hoog, met consequente logica en minder fouten |
| Schaalbaarheid | Beperkt door menselijke capaciteit | Schakelt moeiteloos op naar miljoenen datapunten |
| Kosten | Duur (arbeidsintensief) | Lagere kosten op de lange termijn (Keylabs) |
| Beste keuze voor | Kleine, complexe of onduidelijke datasets | Grote, repetitieve of duidelijk gedefinieerde datasets |
Handmatig labelen blijft nuttig—voor uitzonderingen of onduidelijke data—maar voor de meeste zakelijke toepassingen is automatisering de beste keuze.
De basisstappen van geautomatiseerde data labeling met machine learning
Hoe werkt geautomatiseerde data labeling nu precies? Dit is de workflow die ik zelf gebruik (en aanraad):
- Data verzamelen en voorbereiden
- Kenmerken (features) extraheren en voorbereiden
- Automatisch labelen met machine learning
- Kwaliteitscontrole en menselijke review
Laten we elke stap kort toelichten.
Stap 1: Data verzamelen en voorbereiden
Voordat je kunt labelen, moet je data verzamelen en opschonen. Denk aan het scrapen van productinformatie van websites, het exporteren van klantreviews of het verzamelen van afbeeldingen uit interne systemen. Kwaliteit is hier superbelangrijk: slechte data leidt tot slechte labels en dus slechte modellen ().
Best practices:
- Verwijder dubbele en irrelevante data
- Standaardiseer formaten (zoals datums, valuta, etc.)
- Vul ontbrekende of onvolledige data aan
Stap 2: Kenmerken extraheren en voorbereiden
Bepaal welke kenmerken belangrijk zijn voor je labeling. Label je bijvoorbeeld productinformatie, dan kun je prijs, merk, categorie en omschrijving als features gebruiken. In sales of marketing kun je bedrijfsnamen, contactgegevens of sentiment uit e-mails halen.
Zakelijk voorbeeld: Met kun je gestructureerde data van webpagina’s scrapen—zoals productspecificaties, reviews of contactgegevens—zonder te programmeren.
Stap 3: Automatisch labelen met machine learning
Hier gebeurt het echte werk. Je gebruikt machine learning modellen (getraind op een kleinere, handmatig gelabelde dataset) om de rest van je data te labelen. Veelgebruikte technieken zijn:
- Supervised modellen: Train een classifier op gelabelde voorbeelden en label daarna nieuwe data.
- Regelgebaseerd labelen: Gebruik vaste regels (bijv. “als prijs > €1000, label als ‘premium’”) voor eenvoudige gevallen.
- Active learning: Het model vraagt om menselijke input bij twijfelgevallen en verbetert zo continu ().
- Transfer learning: Gebruik voorgetrainde modellen om sneller te starten in nieuwe domeinen ().
Het resultaat? Consequente, hoogwaardige labels—op grote schaal.
Stap 4: Kwaliteitscontrole en menselijke review
Zelfs de beste modellen hebben controle nodig. Regelmatige menselijke review helpt om uitzonderingen, onduidelijke data of modelafwijkingen te signaleren. Praktische QA-stappen zijn:
- Neem willekeurige steekproeven voor handmatige controle
- Vergelijk automatische labels met een “gouden standaard”
- Gebruik metrics zoals inter-annotator agreement om consistentie te meten ()
Zo gebruik je Thunderbit voor geautomatiseerde data labeling met machine learning
Tijd om praktisch te worden. is een AI-webscraper en data labeling tool speciaal voor zakelijke gebruikers—geen programmeerkennis nodig. Zo automatiseer je je data labeling workflow:
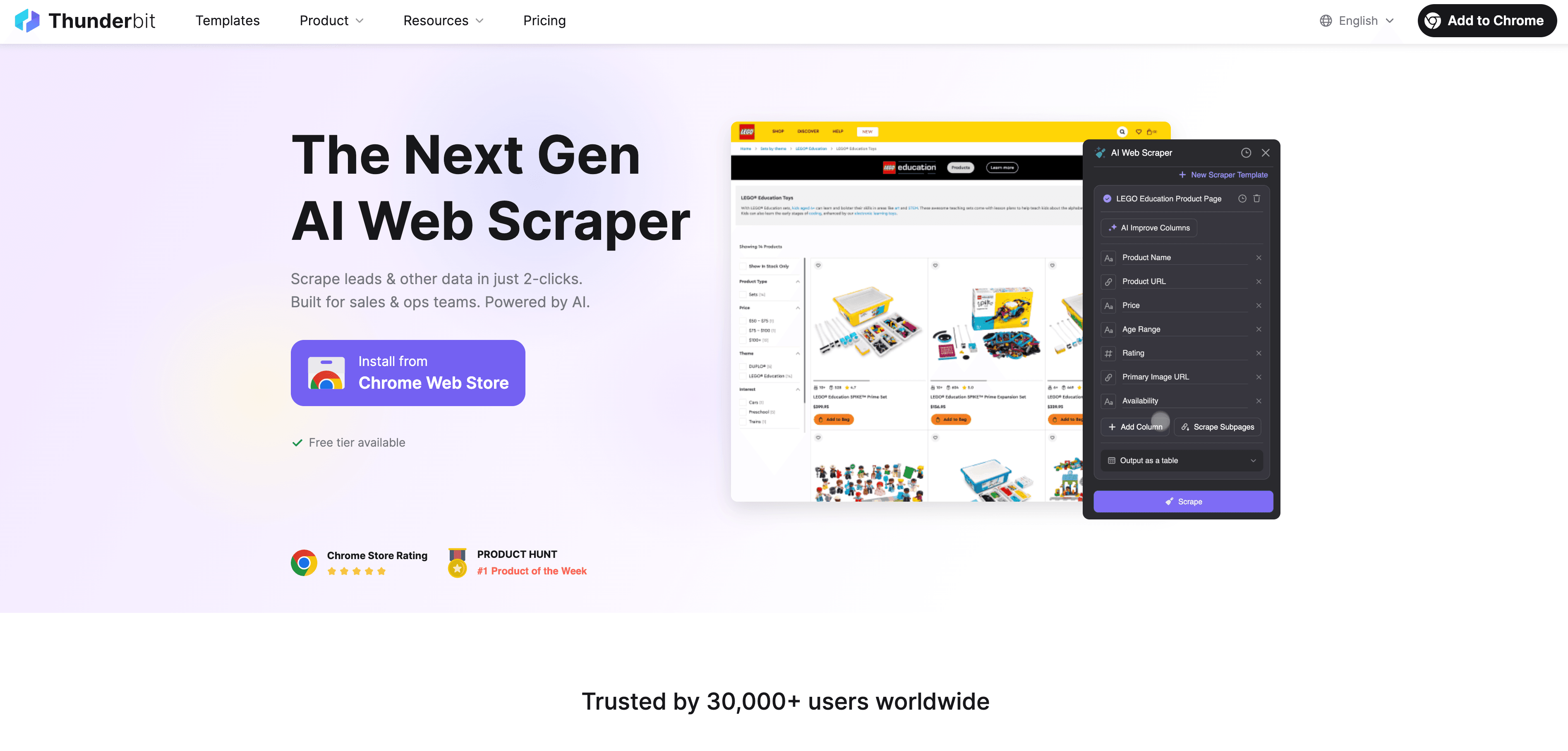
Stapsgewijze handleiding
- Scrape website data: Gebruik de om gestructureerde data van elke website te verzamelen. Open de extensie, kies je bron en laat Thunderbit’s AI de beste velden voor je selecteren.
- Definieer labelinstructies: Geef met gewone taal aan hoe de AI je data moet labelen. Bijvoorbeeld: “Label alle producten boven €500 als ‘premium’” of “Tag reviews met positieve toon.”
- Automatisch labelen toepassen: Met Thunderbit’s Field AI Prompt kun je precies instellen hoe labels worden toegekend—ideaal voor complexe of meer-veldige labeling.
- Exporteer gelabelde data: Exporteer je gelabelde data direct naar Excel, Google Sheets, Airtable of Notion—klaar voor modeltraining of analyse.
Het mooiste? Thunderbit is gemaakt voor niet-technische gebruikers in sales, marketing, operations en meer. Je hoeft geen code te schrijven of te stoeien met ingewikkelde templates.
Thunderbit’s natuurlijke taal prompts en Field AI functies
Een van mijn favoriete functies is dat je label-logica gewoon in het Nederlands kunt omschrijven. Wil je leads indelen op regio, producten taggen op categorie of e-mails markeren met spoed? Beschrijf simpelweg wat je wilt, en Thunderbit’s AI regelt de rest.
Voorbeelden van prompts:
- “Label alle contacten met een ‘.edu’ e-mailadres als ‘Onderwijs’.”
- “Als de review ‘snelle levering’ noemt, tag als ‘Positieve verzendervaring’.”
- “Groepeer producten op merk en prijsklasse.”
Met de Field AI Prompt kun je nog verder gaan—label-logica per kolom instellen, regels combineren of labels automatisch vertalen naar meerdere talen.
Subpagina scraping en multi-veld labeling
Complexe datastructuren? Geen probleem. Met Thunderbit’s subpagina scraping kun je data en labels uit onderliggende pagina’s halen (zoals productspecificaties of auteursprofielen) en alles samenvoegen in één overzichtelijke tabel. Je kunt meerdere velden tegelijk labelen—dat scheelt enorm veel tijd.
Praktijkvoorbeeld: Productinformatie scrapen van een webshop, vervolgens per product doorklikken om specificaties, reviews en verkopersinformatie te verzamelen en labelen—alles in één workflow.
Meerdere data labeling tools combineren voor meer nauwkeurigheid en efficiëntie
Thunderbit dekt veel, maar soms heb je gespecialiseerde tools nodig voor bijvoorbeeld beeld- of videolabeling. Daarvoor zijn platforms als of ideaal.
Tip: Gebruik Thunderbit voor het scrapen en eerste labeling van webdata, en exporteer daarna naar Label Studio of Supervisely voor geavanceerde annotatie (zoals objecten markeren in afbeeldingen of video’s frame-voor-frame labelen). Zo haal je het beste uit elke tool en verhoog je zowel de nauwkeurigheid als de efficiëntie ().
Wanneer gespecialiseerde tools combineren met Thunderbit?
- Beeldannotatie: Voor taken als objectherkenning of segmentatie, gebruik Supervisely of Label Studio.
- Video labeling: Gespecialiseerde videotools zijn geschikt voor frame-voor-frame annotatie en tracking.
- Complexe multi-label taken: Combineer Thunderbit’s gestructureerde data-extractie met geavanceerde annotatietools voor het beste resultaat.
Best practice: Start met Thunderbit voor snelle, schaalbare labeling van (semi-)gestructureerde data, en schakel gespecialiseerde tools in voor diepgaande annotatie waar nodig.
Best practices voor geautomatiseerde data labeling met machine learning
Wil je het maximale uit je geautomatiseerde labeling halen? Dit zijn mijn belangrijkste tips:
- Stel duidelijke labelrichtlijnen op: Onduidelijke labels zorgen voor inconsistente data—maak duidelijk wat elk label betekent.
- Begin met een kwalitatieve startset: Label handmatig een kleine, representatieve steekproef om je eerste model te trainen.
- Blijf verbeteren: Gebruik active learning om je model steeds slimmer te maken en focus menselijke review op de lastigste gevallen.
- Regelmatig valideren: Controleer periodiek een willekeurige steekproef van gelabelde data om fouten of afwijkingen te ontdekken.
- Integreer en automatiseer: Gebruik tools als Thunderbit om data verzamelen, labelen en exporteren in één workflow te combineren.
Veelvoorkomende uitdagingen en hoe je ze oplost
Geautomatiseerde data labeling kent ook valkuilen. Zo pak je de meest voorkomende aan:
- Onduidelijke data: Gebruik heldere, gedetailleerde labeldefinities en geef voorbeelden voor randgevallen.
- Modelafwijking: Train je labelingmodel regelmatig opnieuw met nieuwe, handmatig gecontroleerde data.
- Randgevallen: Zorg voor een proces waarbij mensen twijfelgevallen of nieuwe situaties beoordelen.
- Integratieproblemen: Kies tools (zoals Thunderbit) die eenvoudig exporteren naar je favoriete platformen mogelijk maken.
Samenvatting & belangrijkste inzichten
Geautomatiseerde data labeling met machine learning is de geheime kracht achter de beste AI-modellen van nu. Het bespaart tijd, verlaagt kosten en—het belangrijkste—zorgt voor consistente, hoogwaardige labels die je modellen nodig hebben om optimaal te presteren. Door tools als te combineren met gespecialiseerde annotatieplatforms, bouw je een workflow die snel, nauwkeurig en schaalbaar is—ongeacht je technische kennis.
Zelf ervaren hoe groot het verschil is? , probeer geautomatiseerd labelen bij je volgende project en zie je machine learning modellen sneller en slimmer worden. Meer tips en praktijkvoorbeelden? Bekijk de voor verdiepende artikelen en tutorials.
Veelgestelde vragen
1. Wat is geautomatiseerde data labeling met machine learning?
Dit is het proces waarbij AI en ML-modellen automatisch labels aan data toekennen, in plaats van dat mensen dit handmatig doen. Het versnelt het labelproces, zorgt voor meer consistentie en is geschikt voor grote datasets.
2. Waarom is de kwaliteit van labeling belangrijk voor machine learning?
Goede, consistente labels zijn essentieel voor het trainen van nauwkeurige modellen. Slechte labeling kan de nauwkeurigheid tot wel 80% verlagen en leidt tot onbetrouwbare voorspellingen.
3. Hoe helpt Thunderbit bij geautomatiseerde data labeling?
Met Thunderbit kun je webdata scrapen en labelen met AI, via natuurlijke taal prompts en aanpasbare veldlogica—zonder te programmeren. Ideaal voor zakelijke gebruikers in sales, marketing en operations.
4. Kan ik Thunderbit combineren met andere labeling tools?
Zeker. Gebruik Thunderbit voor het verzamelen en eerste labeling van gestructureerde data, en exporteer daarna naar tools als Label Studio of Supervisely voor geavanceerde beeld- of video-annotatie.
5. Wat zijn de best practices voor geautomatiseerde data labeling?
Stel duidelijke labelrichtlijnen op, begin met een kwalitatieve startset, verbeter je model met active learning, valideer regelmatig en gebruik geïntegreerde tools om je workflow te stroomlijnen.
Klaar om je data labeling te automatiseren en je machine learning projecten te versnellen? Probeer Thunderbit en ontdek hoeveel tijd—en frustratie—je bespaart.
Meer weten: