

Laten we eerlijk zijn: Amazon is eigenlijk het winkelcentrum, de supermarkt en de elektronicazaak van het hele internet. Werk je in sales, e-commerce of operations, dan weet je al dat wat er op Amazon gebeurt niet op Amazon blijft: het beïnvloedt je prijzen, je voorraad en zelfs je volgende grote productlancering. Maar hier zit het addertje onder het gras: al die smakelijke productdetails, prijzen, beoordelingen en reviews zitten verstopt achter een webinterface die gebouwd is voor shoppers, niet voor datagedreven teams. Dus hoe kom je aan die data zonder je weekenden te verprutsen met knip- en plakwerk alsof het 1999 is?
Daar komt webscraping om de hoek kijken. In deze gids laat ik je twee manieren zien om Amazon-productdata te extraheren: de klassieke aanpak waarbij je zelf de mouwen opstroopt en het in Python codeert, en de moderne route waarbij je AI het zware werk laat doen met een no-code webscraper zoals Thunderbit. Ik neem je mee door echte Python-code heen (met alle valkuilen en workarounds), en laat daarna zien hoe Thunderbit je in slechts een paar klikken dezelfde data laat ophalen—zonder coderen. Of je nu developer bent, businessanalist of gewoon iemand die genoeg heeft van handmatige data-invoer: je bent hier aan het juiste adres.
Waarom Amazon-productdata extraheren? (amazon scraper python, web scraping met python)
Amazon is niet alleen ’s werelds grootste online retailer—het is ook ’s werelds grootste openluchtmarkt voor competitieve intelligentie. Met meer dan 600 miljoen aangeboden producten en bijna 2 miljoen actieve verkopers is Amazon een goudmijn voor iedereen die wil:

- Prijzen monitoren (en die van jou in realtime aanpassen)
- Concurrenten analyseren (hun nieuwe lanceringen, beoordelingen en reviews volgen)
- Leads genereren (verkopers, leveranciers of zelfs potentiële partners vinden)
- Vraag voorspellen (door voorraadniveaus en verkoopranglijsten te volgen)
- Markttrends signaleren (door reviews en zoekresultaten te analyseren)
En dit is niet alleen theorie—bedrijven zien ook echt rendement. Zo gebruikte een elektronicaretailer ge-scrapete Amazon-prijsdata om de winstmarge met 15% te verhogen, terwijl een ander merk een stijging van 4% in verkoop en 30% minder analistentijd zag na automatisering van prijsmonitoring bij concurrenten.
Hier is een snelle tabel met use cases en de ROI die je ongeveer kunt verwachten:
| Use case | Wie gebruikt het | Typische ROI / voordeel |
|---|---|---|
| Prijsmonitoring | E-commerce, operations | 15%+ hogere winstmarge, 4% omzetstijging, 30% minder analistentijd |
| Concurrentieanalyse | Sales, product, operations | Snellere prijsaanpassingen, betere concurrentiepositie |
| Marktonderzoek (reviews) | Product, marketing | Snellere productiteratie, betere advertentieteksten, SEO-inzichten |
| Leadgeneratie | Sales | 3.000+ leads/maand, 8+ uur bespaard per accountmanager per week |
| Voorraad- en vraagvoorspelling | Operations, supply chain | 20% minder overvoorraad, minder out-of-stocks |
| Trenddetectie | Marketing, directie | Vroegtijdige signalering van populaire producten en categorieën |
En hier komt het belangrijkste: meer dan 90% van de organisaties rapporteert inmiddels meetbare waarde uit data-analyse. Scrape je Amazon niet, dan laat je inzichten (en geld) liggen.
Overzicht: Amazon Scraper Python vs. no-code webscraper-tools
Er zijn twee hoofdmanieren om Amazon-data uit de browser te halen en in je spreadsheets of dashboards te krijgen:
-
Amazon Scraper Python (web scraping met Python):
Schrijf je eigen script met Python-bibliotheken zoals Requests en BeautifulSoup. Dat geeft je volledige controle, maar je moet wel kunnen coderen, anti-botmaatregelen aankunnen en je script onderhouden wanneer Amazon zijn site aanpast.
-
No-code webscraper-tools (zoals Thunderbit):
Gebruik een tool waarmee je kunt aanwijzen, klikken en data extraheren—zonder programmeren. Moderne tools zoals Thunderbit gebruiken zelfs AI om te bepalen welke data je moet ophalen, omgaan met subpagina’s en paginering, en direct exporteren naar Excel of Google Sheets.
Zo verhouden ze zich tot elkaar:
| Criteria | Python-scraper | No-code (Thunderbit) |
|---|---|---|
| Installatietijd | Hoog (installeren, coderen, debuggen) | Laag (extensie installeren) |
| Benodigde vaardigheid | Coderen vereist | Geen (aanwijzen en klikken) |
| Flexibiliteit | Onbeperkt | Hoog voor veelvoorkomende use cases |
| Onderhoud | Jij fixt de code | De tool werkt zichzelf bij |
| Anti-botafhandeling | Jij regelt proxies en headers | Ingebouwd, wordt voor je afgehandeld |
| Schaalbaarheid | Handmatig (threads, proxies) | Cloudscraping, parallel verwerkt |
| Data-export | Maatwerk (CSV, Excel, DB) | Met één klik naar Excel en Sheets |
| Kosten | Gratis (je tijd + proxies) | Freemium, betalen voor schaal |
In de volgende secties neem ik je door beide aanpakken heen—eerst hoe je een Amazon-scraper in Python bouwt (met echte code), daarna hoe je hetzelfde doet met Thunderbit’s AI-webscraper.
Aan de slag met Amazon Scraper Python: vereisten en setup
Voordat we in de code duiken, zetten we je omgeving even goed neer.
Je hebt nodig:
- Python 3.x (download via python.org)
- Een code-editor (ik gebruik graag VS Code, maar alles werkt)
- De volgende bibliotheken:
requests(voor HTTP-verzoeken)beautifulsoup4(voor HTML-parsing)lxml(snelle HTML-parser)pandas(voor datatabellen/export)re(reguliere expressies, ingebouwd)
Installeer de bibliotheken:
pip install requests beautifulsoup4 lxml pandas
Projectsetup:
- Maak een nieuwe map voor je project.
- Open je editor, maak een nieuw Python-bestand aan (bijv.
amazon_scraper.py). - Je bent klaar om te beginnen!
Stap voor stap: webscraping met Python voor Amazon-productdata
Laten we een enkele Amazon-productpagina scrapen. (Geen zorgen, zo komen we ook nog bij het scrapen van meerdere producten en pagina’s.)
1. Requests sturen en HTML ophalen
Eerst halen we de HTML van een productpagina op. (Vervang de URL door een Amazon-product naar keuze.)
import requests
url = "<https://www.amazon.com/dp/B0ExampleASIN>"
response = requests.get(url)
html_content = response.text
print(response.status_code)
Let op: Deze basisrequest wordt waarschijnlijk door Amazon geblokkeerd. Je ziet dan een 503-fout of een CAPTCHA in plaats van de productpagina. Waarom? Omdat Amazon weet dat je geen echte browser bent.
Amazon’s anti-botmaatregelen omzeilen
Amazon is niet dol op bots. Om niet geblokkeerd te worden, moet je:
- Een User-Agent-header instellen (doen alsof je Chrome of Firefox bent)
- User-Agents roteren (niet steeds dezelfde gebruiken)
- Je requests afremmen (willekeurige vertragingen toevoegen)
- Proxies gebruiken (voor grootschalig scrapen)
Zo stel je headers in:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
response = requests.get(url, headers=headers)
Wil je wat verder gaan? Gebruik een lijst met User-Agents en roteer die per request. Voor grotere klussen wil je waarschijnlijk een proxyservice gebruiken (er zijn er genoeg), maar voor kleinschalig scrapen zijn headers en vertragingen meestal voldoende.
Belangrijke productvelden extraheren
Zodra je de HTML hebt, parse je die met BeautifulSoup.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, "lxml")
Nu halen we de belangrijkste gegevens eruit:
Producttitel
title_elem = soup.find(id="productTitle")
product_title = title_elem.get_text(strip=True) if title_elem else None
Prijs
Amazon’s prijs kan op een paar plekken staan. Probeer deze opties:
price = None
price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
if price_elem:
price = price_elem.get_text(strip=True)
else:
price_whole = soup.find("span", {"class": "a-price-whole"})
price_frac = soup.find("span", {"class": "a-price-fraction"})
if price_whole and price_frac:
price = price_whole.text + price_frac.text
Beoordeling en aantal reviews
rating_elem = soup.find("span", {"class": "a-icon-alt"})
rating = rating_elem.get_text(strip=True) if rating_elem else None
review_count_elem = soup.find(id="acrCustomerReviewText")
reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
reviews_count = reviews_text.split()[0] # bijvoorbeeld "1,554 ratings"
URL van de hoofdafbeelding
Amazon verstopt afbeeldingen met hoge resolutie soms in JSON in de HTML. Hier is een snelle regex-aanpak:
import re
match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
main_image_url = match.group(1) if match else None
Of pak gewoon de belangrijkste img-tag:
img_tag = soup.find("img", {"id": "landingImage"})
img_url = img_tag['src'] if img_tag else None
Productdetails
Specificaties zoals merk, gewicht en afmetingen staan meestal in een tabel:
details = {}
rows = soup.select("#productDetails_techSpec_section_1 tr")
for row in rows:
header = row.find("th").get_text(strip=True)
value = row.find("td").get_text(strip=True)
details[header] = value
Of, als Amazon de “detailBullets”-opmaak gebruikt:
bullets = soup.select("#detailBullets_feature_div li")
for li in bullets:
txt = li.get_text(" ", strip=True)
if ":" in txt:
key, val = txt.split(":", 1)
details[key.strip()] = val.strip()
Print je resultaten:
print("Titel:", product_title)
print("Prijs:", price)
print("Beoordeling:", rating, "op basis van", reviews_count, "reviews")
print("URL hoofdafbeelding:", main_image_url)
print("Details:", details)
Meerdere producten scrapen en paginering afhandelen
Eén product is leuk, maar waarschijnlijk wil je een hele lijst. Zo scrape je zoekresultaten en meerdere pagina’s.
Productlinks ophalen van een zoekpagina
search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
res = requests.get(search_url, headers=headers)
soup = BeautifulSoup(res.text, "lxml")
product_links = []
for a in soup.select("h2 a.a-link-normal"):
href = a['href']
full_url = "<https://www.amazon.com>" + href
product_links.append(full_url)
Paginering afhandelen
Amazon-zoek-URL’s gebruiken &page=2, &page=3, enzovoort.
for page in range(1, 6): # scrape de eerste 5 pagina's
search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
res = requests.get(search_url, headers=headers)
if res.status_code != 200:
break
soup = BeautifulSoup(res.text, "lxml")
# ... productlinks extraheren zoals hierboven ...
Door productpagina’s loopen en exporteren naar CSV
Verzamel je productdata in een lijst met dictionaries en gebruik dan pandas:
import pandas as pd
df = pd.DataFrame(product_data_list) # lijst met dicts
df.to_csv("amazon_products.csv", index=False)
Of naar Excel:
df.to_excel("amazon_products.xlsx", index=False)
Best practices voor Amazon Scraper Python-projecten
Laten we eerlijk zijn: Amazon verandert continu zijn site en bestrijdt scrapers actief. Zo houd je je project draaiende:
- Roteer headers en User-Agents (gebruik een bibliotheek zoals
fake-useragent) - Gebruik proxies voor grootschalig scrapen
- Throttle requests (willekeurige
time.sleep()tussen requests) - Ga netjes om met fouten (retry bij 503, back off als je geblokkeerd wordt)
- Schrijf flexibele parsinglogica (zoek per veld naar meerdere selectors)
- Let op HTML-wijzigingen (als je script ineens overal
Noneteruggeeft, controleer de pagina) - Respecteer robots.txt (Amazon staat scrapen van veel secties niet toe—scrape verantwoord)
- Ruim je data al tijdens het proces op (valutasymbolen, komma’s en witruimte verwijderen)
- Blijf verbonden met de community (forums, Stack Overflow, Reddit’s r/webscraping)
Checklist voor het onderhouden van je scraper:
- Roteer User-Agents en headers
- Gebruik proxies als je op schaal scrape’t
- Voeg willekeurige vertragingen toe
- Modulariseer je code voor makkelijke updates
- Houd bans of CAPTCHA’s in de gaten
- Exporteer data regelmatig
- Documenteer je selectors en logica
Voor een diepere duik, bekijk mijn gids voor webscraping met Python.
Het no-code alternatief: Amazon scrapen met Thunderbit AI-webscraper
Amazon-productdata scrapen met AI Get Started Free
Oké, je hebt nu de Python-aanpak gezien. Maar wat als je niet wilt coderen—of gewoon de data in twee klikken wilt ophalen en verder wilt met je leven? Daar komt Thunderbit van pas.
Thunderbit is een AI-webscraper Chrome-extensie waarmee je Amazon-productdata (en data van vrijwel elke website) kunt extraheren zonder te coderen. Dit is waarom ik het zo fijn vind:
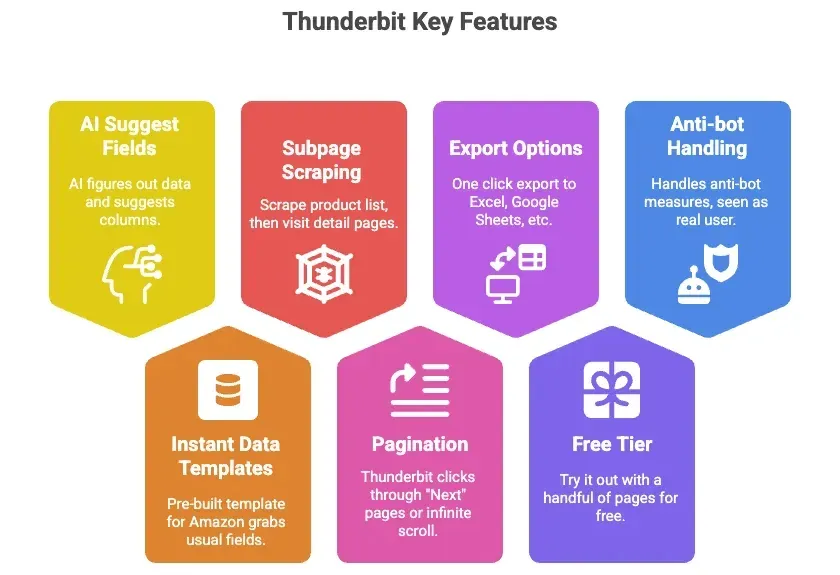
- AI veldsuggesties: Klik gewoon op een knop en Thunderbit’s AI bepaalt welke data op de pagina staat en stelt kolommen voor (zoals Titel, Prijs, Beoordeling, enzovoort).
- Directe datasjablonen: Voor Amazon is er een kant-en-klaar sjabloon dat alle gebruikelijke velden ophaalt—geen setup nodig.
- Subpagina-scraping: Scrape een productlijst en laat Thunderbit vervolgens automatisch elke productdetailpagina bezoeken om meer informatie op te halen.
- Paginering: Thunderbit kan voor je door “Volgende”-pagina’s klikken of infinite scroll afhandelen.
- Export naar Excel, Google Sheets, Airtable, Notion: Met één klik is je data klaar voor gebruik.
- Gratis laag: Probeer het gratis met een handvol pagina’s.
- Handelt anti-botgedoe voor je af: Omdat het in je browser draait (of in de cloud), ziet Amazon het als een echte gebruiker.
Stap voor stap: Thunderbit gebruiken om Amazon-productdata te scrapen
Zo eenvoudig is het:
-
Installeer Thunderbit:
Download de Thunderbit Chrome-extensie en meld je aan.
-
Open Amazon:
Ga naar de Amazon-pagina die je wilt scrapen (zoekresultaten, productdetail, wat dan ook).
-
Klik op “AI veldsuggesties” of gebruik een sjabloon:
Thunderbit stelt kolommen voor om te extraheren (of je kiest het Amazon Product-sjabloon).
-
Controleer de kolommen:
Pas de kolommen aan als je wilt (velden toevoegen/verwijderen, hernoemen, enzovoort).
-
Klik op “Scrape”:
Thunderbit haalt de data van de pagina en toont die in een tabel.
-
Subpagina’s en paginering afhandelen:
Als je een lijst hebt gescrapet, klik dan op “Subpagina’s scrapen” om elke productdetailpagina te bezoeken en meer informatie op te halen. Thunderbit kan ook automatisch door “Volgende”-pagina’s klikken.
-
Exporteer je data:
Klik op “Exporteren naar Excel” of “Exporteren naar Google Sheets.” Klaar.
-
(Optioneel) Scraping plannen:
Heb je deze data elke dag nodig? Gebruik Thunderbit’s planner om dit te automatiseren.
Dat is alles. Geen code, geen debuggen, geen proxies, geen hoofdpijn. Voor een visuele walkthrough kun je het Thunderbit YouTube-kanaal of de Amazon Product Scraper-sjabloonpagina bekijken.
Probeer het Amazon Product Scraper-sjabloon
Amazon Scraper Python vs. no-code webscraper: vergelijking naast elkaar
Laten we alles even op een rij zetten:
| Criteria | Python-scraper | Thunderbit (no-code) |
|---|---|---|
| Installatietijd | Hoog (installeren, coderen, debuggen) | Laag (extensie installeren) |
| Benodigde vaardigheid | Coderen vereist | Geen (aanwijzen en klikken) |
| Flexibiliteit | Onbeperkt | Hoog voor veelvoorkomende use cases |
| Onderhoud | Jij fixt de code | De tool werkt zichzelf bij |
| Anti-botafhandeling | Jij regelt proxies en headers | Ingebouwd, wordt voor je afgehandeld |
| Schaalbaarheid | Handmatig (threads, proxies) | Cloudscraping, parallel verwerkt |
| Data-export | Maatwerk (CSV, Excel, DB) | Met één klik naar Excel en Sheets |
| Kosten | Gratis (je tijd + proxies) | Freemium, betalen voor schaal |
| Beste voor | Developers, maatwerkbehoeften | Zakelijke gebruikers, snelle resultaten |
Ben je een developer die graag sleutelt en iets supermaatwerks nodig heeft, dan is Python je vriend. Wil je snelheid, eenvoud en geen code, dan is Thunderbit de juiste keuze.
Wanneer kies je Python, no-code of AI-webscraper voor Amazon-data?
Kies Python als:
- Je maatwerkl ogica nodig hebt of scraping wilt integreren in je backend-systemen
- Je op enorme schaal scrape’t (tienduizenden producten)
- Je wilt leren hoe scraping onder de motorkap werkt
Kies Thunderbit (no-code, AI-webscraper) als:
- Je snel data wilt, zonder te coderen
- Je een zakelijke gebruiker, analist of marketeer bent
- Je je team zelf data wilt laten ophalen
- Je het gedoe met proxies, anti-botmaatregelen en onderhoud wilt vermijden
Gebruik beide als:
- Je snel wilt prototypen met Thunderbit en daarna een custom Python-oplossing voor productie wilt bouwen
- Je Thunderbit wilt gebruiken voor dataverzameling en Python voor opschoning/analyse
Voor de meeste zakelijke gebruikers dekt Thunderbit 90% van je Amazon-scrapingbehoeften in een fractie van de tijd. Voor de overige 10%—het supermaatwerk, grootschalige of diep geïntegreerde werk—blijft Python koning.
Conclusie en belangrijkste inzichten
Hoe je Amazon-producten en reviews scrapt in 2025 met AI Get Started Free
Amazon-productdata scrapen is een superkracht voor elk sales-, e-commerce- of operations-team. Of je nu prijzen volgt, concurrenten analyseert of gewoon probeert je team te redden van eindeloos knippen en plakken, er is een oplossing voor je.
- Python-scraping geeft je volledige controle, maar brengt een leercurve en doorlopend onderhoud met zich mee.
- No-code webscrapers zoals Thunderbit maken Amazon-data-extractie toegankelijk voor iedereen—geen code, geen hoofdpijn, gewoon resultaat.
- De beste aanpak? Gebruik de tool die past bij je vaardigheden, je planning en je zakelijke doelen.
Ben je nieuwsgierig? Probeer Thunderbit eens—it’s free to start, en je zult versteld staan hoe snel je de data krijgt die je nodig hebt. En ben je developer, wees dan niet bang om te combineren: soms is de snelste manier om iets te bouwen om de AI het saaie werk voor je te laten doen.
Download de Thunderbit Chrome-extensie
FAQ’s
1. Waarom zou een bedrijf Amazon-productdata willen scrapen?
Door Amazon te scrapen kunnen bedrijven prijzen monitoren, concurrenten analyseren, reviews verzamelen voor productonderzoek, vraag voorspellen en salesleads genereren. Met meer dan 600 miljoen producten en bijna 2 miljoen verkopers op Amazon is het een rijke bron van competitieve intelligentie.
2. Wat zijn de belangrijkste verschillen tussen Python en no-code tools zoals Thunderbit voor het scrapen van Amazon?
Python-scrapers bieden maximale flexibiliteit, maar vereisen programmeervaardigheden, opstarttijd en doorlopend onderhoud. Thunderbit, een no-code AI-webscraper, laat gebruikers Amazon-data direct extraheren via een Chrome-extensie—geen code nodig, met ingebouwde anti-botafhandeling en exportopties naar Excel of Sheets.
3. Is het legaal om data van Amazon te scrapen?
Amazon’s servicevoorwaarden verbieden scraping doorgaans, en ze implementeren actief anti-botmaatregelen. Toch scrapen veel bedrijven nog steeds publiek beschikbare data, zolang ze verantwoord werken, zoals het respecteren van rate limits en het vermijden van buitensporige requests.
4. Wat voor data kan ik uit Amazon halen met webscraping-tools?
Veelvoorkomende datavelden zijn producttitels, prijzen, beoordelingen, aantallen reviews, afbeeldingen, productspecificaties, beschikbaarheid en zelfs verkopersinformatie. Thunderbit ondersteunt ook subpagina-scraping en paginering om data over meerdere listings en pagina’s te verzamelen.
5. Wanneer kies ik voor Python-scraping in plaats van een tool als Thunderbit, of andersom?
Gebruik Python als je volledige controle nodig hebt, maatwerkl ogica wilt of scraping wilt integreren in backend-systemen. Gebruik Thunderbit als je snel resultaat wilt zonder te coderen, makkelijk wilt opschalen of als zakelijke gebruiker een onderhoudsarme oplossing zoekt.
Wil je dieper gaan? Bekijk deze bronnen:
- Thunderbit Blog
- Wat is data scraping en hoe doe je het in 2025
- Hoe je Amazon-producten en reviews scrapt in 2025 met AI
- Gids voor webscraping met Python
Veel scrape-plezier—en moge je spreadsheets altijd up-to-date zijn.
Probeer Thunderbit AI-webscraper voor Amazon Get Started Free




