Een GitHub-zoekopdracht op "amazon scraper" levert ongeveer op. Beperk dat tot repos die in de afgelopen zes maanden zijn gepusht, en je komt uit op ongeveer — amper 20%. De rest? Verlaten tutorials, verouderde wrappers en scripts die stopten met werken zodra Amazon zijn verdediging aanscherpte.
Ik heb heel wat tijd besteed aan het doorspitten van Amazon-scraperrepos, het lezen van GitHub-issues en het volgen van discussies op Reddit en Stack Overflow. Het patroon is steeds hetzelfde: iemand vindt een populaire repo, is een uur bezig met opzetten, draait hem één keer en loopt vast op een muur van CAPTCHA’s of 503-fouten. Amazon’s anti-botaanpak in 2026 is niet meer wat die zelfs twee jaar geleden was — TLS-fingerprinting, gedragsanalyse en agressieve CAPTCHA-uitrol hebben het oude draaiboek van "rotate user agents en hopen op het beste" vrijwel waardeloos gemaakt. Deze gids behandelt de best practices die echt uitmaken als je betrouwbare Amazon-data uit een GitHub-repo wilt halen, en wat je moet doen wanneer (niet als) je scraper breekt.
Wat is een Amazon Scraper op GitHub (en waarom falen er zoveel)?
Een Amazon-scraper GitHub-repo is meestal een open-source script — vaak in Python, Node.js of op basis van Scrapy — dat gestructureerde data van Amazon-pagina’s haalt. De datadoelen zijn herkenbaar: producttitel, prijs, ASIN, beoordelingen, aantal reviews, beschikbaarheid, verkopersinformatie, zoekresultaatkaarten en reviewtekst.
De opzet is meestal vrij eenvoudig:
- Een HTTP-client of headless browser haalt de pagina op.
- Een HTML- of JSON-parser extraheert de velden.
- De data wordt opgeslagen in CSV, JSON of een database.
Repos vallen doorgaans in vier categorieën:
- Lichtgewicht Python-bibliotheken (bijv. )
- Scrapy-spiders (bijv. )
- Browser-automatisering met Selenium of Playwright
- API-wrapperprojecten die in feite front-ends zijn voor een commerciële scrapingdienst (bijv. )
Het faalpatroon is voorspelbaar. De meeste repos breken omdat:
- Amazon zijn paginalay-out of HTML-fragmenten wijzigt
- Amazon een 503 of CAPTCHA serveert in plaats van echte content
- De TLS- en HTTP-fingerprint van de scraper niet meer op een browser lijkt
- Locale, taal- of headerverschillen argwaan wekken
- De maintainer verdergaat nadat het oorspronkelijke, smalle use case is opgelost
Veel sterren en "momenteel bruikbaar" zijn twee heel verschillende dingen. In de audit die ik voor dit artikel uitvoerde, leken slechts ongeveer drie van de acht breed zichtbare repos in 2026 duidelijk actief.
Doe in 2026 eerst een versheidsaudit vóór je een Amazon Scraper GitHub-repo kloont
Deze stap is belangrijker voor Amazon dan voor de meeste andere doelen. Amazon’s verdedigingsmechanismen veranderen sneller dan die van een doorsnee e-commercewebsite, dus een repo die prima werkt op een brochurewebsite kan binnen een paar weken waardeloos worden op Amazon. Toch raden de meeste "best amazon scraper github"-lijsten repos aan zonder te checken of ze nog werken. Gebruikers verspillen uren aan het opzetten van kapotte tools.
Hoe je checkt of een GitHub-repo nog leeft
Voordat je ook maar iets git clonet, loop je deze controles na:
- Datum van de laatste commit: Alles ouder dan 6 maanden is op Amazon een duidelijk waarschuwingssignaal.
- Open issues vs. reactiesnelheid: Zoek in het Issues-tabblad op "captcha", "503", "blocked" en "not working". Als die meldingen zich opstapelen zonder reacties van de maintainer, loop dan weg.
- Gezondheid van dependencies: Open
requirements.txtofpackage.json. Verouderde libraries (bijv. ouderequestszonder moderne TLS-afhandeling) zijn een rode vlag. - Dekking van Amazon-paginatypes: Kan de repo productpagina’s, zoekresultaten én reviews aan? Of maar één van de drie?
- Anti-botaanpak: Hardcoded headers zonder proxy-ondersteuning is een aanpak uit 2023 die 2026 niet overleeft.
Amazon Scraper GitHub-versheidschecklist

| Versheidssignaal | Wat te controleren | Rode vlag 🚩 |
|---|---|---|
| Datum van laatste commit | Commit-feed of datum van repo-push | Ouder dan 6 maanden |
| Open issues | Issues-tab — filter op "captcha", "503", "blocked" | Herhaaldelijk kapot zonder reacties van de maintainer |
| Gezondheid van dependencies | requirements.txt / package.json | Verouderde libraries, geen moderne TLS-strategie |
| Dekking van Amazon-pagina’s | README + codevoorbeelden | Ondersteunt maar één paginatype (bijv. productpagina’s maar niet zoeken of reviews) |
| Anti-botaanpak | Broncode, proxyconfiguratie | Alleen hardcoded headers en UA-strings |
| Onderhoudsmodel | Is het een echte scraper, tutorial of commerciële API-wrapper? | De repo is in feite alleen een front-end voor een betaalde dienst |
Wat de audit daadwerkelijk vond
Ik heb acht breed zichtbare Amazon-scraperrepos langs deze criteria gelegd. De resultaten zijn nuchter stemmend:
| Repo / Tool | Sterren | Signaal laatste commit | Scope | Status in 2026 | Opmerkingen |
|---|---|---|---|---|---|
| oxylabs/amazon-scraper | ~2.872 | 2026-04-02 | Beheerde scraper-API-wrapper | Actief, maar niet DIY | Vers, maar dit is eigenlijk een front-end op een beheerde dienst |
| omkarcloud/amazon-scraper | ~214 | 2026-02-25 | Beheerde API voor zoeken, details, reviews | Actief, maar niet DIY | Goede dekking, maar het is een API-product, geen ruwe scraper |
| theonlyanil/amzpy | ~110 | 2026-02-26 | Lichtgewicht Python-bibliotheek | Actief | De duidelijkste directe GitHub-scraper met curl_cffi |
| philipperemy/amazon-reviews-scraper | ~134 | 2024-11-21 | Alleen reviews | Smal maar bruikbaar | Oud en erg review-specifiek |
| python-scrapy-playbook/amazon-python-scrapy-scraper | ~74 | Laatste commit 2023; repo gepusht op 2024-08-20 | Scrapy-spiders + proxy-middleware | Tutorial-niveau, verouderend | Nuttig om te leren, niet als kant-en-klare stack voor 2026 |
| drawrowfly/amazon-product-api | ~744 | 2022-11-13 | Node CLI voor zoeken, details, reviews | Hoog risico | Brede dekking, maar onderhoud is te oud |
| tducret/amazon-scraper-python | ~881 | 2020-10-13 | Zoeken naar CSV | Dood voor 2026 | Historisch populair, duidelijk verouderd |
| scrapehero-code/amazon-scraper | ~432 | 2020-06-21 | Zoek-/producttutorial | Dood voor 2026 | Feitelijk archiefmateriaal |
De openbare issues vertellen hetzelfde verhaal. heeft een issue met de titel "All requests receive captcha response." heeft "Doesn't seem to be working." heeft "Bypass Amazon protection." Dit zijn geen obscure randgevallen — dit zijn de eerste problemen waar gebruikers tegenaan lopen.
Het anti-ban draaiboek: hoe je geblokkeerd worden met een Amazon Scraper van GitHub voorkomt
Geblokkeerd worden is het grootste pijnpunt voor iedereen die een amazon scraper github-project gebruikt. Algemene tips als "gebruik proxies en roteer user agents" zijn niet langer genoeg. Amazon’s anti-botstack van 2025-2026 omvat TLS-fingerprinting, gedragsanalyse en agressieve CAPTCHA-uitrol. Je hebt een gelaagde aanpak nodig.
TLS-fingerprintmatching: waarom vanilla requests je een ban oplevert
Dit is een van de meest onderschatte anti-ban-technieken. TLS-fingerprinting werkt als volgt: wanneer je script een beveiligde verbinding met Amazon opent, kan de server veel afleiden over de client aan de manier waarop die "handshaket" — de aangeboden cipher suites, de volgorde van extensies, de HTTP/2-instellingen. Browsers gebruiken relatief vaste TLS- en HTTP/2-instellingen, en die combinaties zijn via technieken als te herkennen.
Gewone requests- en standaard httpx-opstellingen kunnen headers kopiëren, maar niet het Chrome-achtige TLS- en HTTP/2-gedrag. Amazon ziet het verschil.
pakt dit direct aan. Het biedt browser-impersonatie — ondersteunde doelwitten zijn onder andere chrome136, safari184 en firefox133 — zodat de TLS-fingerprint van je HTTP-client overeenkomt met die van een echte browser. De docs waarschuwen expliciet tegen het genereren van willekeurige JA3-strings: browser-fingerprints zijn per versie grotendeels vast, en willekeurige onzin is makkelijker te detecteren dan een gekopieerde echte fingerprint.
De communitydata sluit daarop aan. Een bevestigt dat de impersonate-parameter nuttig is omdat die browserprofielen roteert en headers op elkaar afgestemd houdt. Een andere meldt dat Amazon clients op basis van TLS-fingerprint blokkeert "na ongeveer een maand of twee." Een vraagt specifiek of Amazon python-requests fingerprint (spoiler: ja).
Als je nog steeds gewone requests gebruikt als eerste Amazon-client, pas dan eerst die aanname aan vóór je iets anders upgrade.
Proxyrotatie goed gedaan (niet alleen "gebruik proxies")
Het doel van proxies is niet om zo vaak mogelijk te roteren. Het doel is om sessies geloofwaardig te laten lijken.
Residential vs. datacenter: Datacenter-proxies zijn goedkoper maar makkelijker te detecteren. Residential-proxies kosten meer, maar zijn veel moeilijker voor Amazon om te flaggen. begint bij $4,00/GB pay-as-you-go, en daalt naar $3,50/GB bij grotere plannen. begint bij $6/GB. Amazon hoort in de categorie "geavanceerd doelwit" waar residential proxies de premie waard zijn.
Rotatie per verzoek vs. per sessie: Hier gaat het in de meeste tutorials mis. Bij elk verzoek van proxy wisselen terwijl cookies en headers constant blijven, kan juist minder menselijk ogen, niet meer. Het veiligere patroon:
- Houd zoeken → product → review zoveel mogelijk op dezelfde sticky sessie
- Wissel sessies als je een nieuwe zoekreis begint, niet bij elk verzoek
- Roteer tussen sessies, niet willekeurig binnen één browsingsessie
Een merkte op dat standaard ISP-IP’s het lang niet zo goed deden als mobiele IP’s op populaire e-commercewebsites. Een andere meldde geblokkeerd te worden zelfs met roterende user agents en residential proxies — een goede herinnering dat proxies alleen niet genoeg zijn.
Requestsnelheid, backoff en rate limiting
Amazon’s 503-pagina’s zijn geen willekeurig ongeluk. Het is feedback.
Een over het scrapen van meer dan 500 ASIN’s meldde een 503 op exact hetzelfde punt, rond ASIN 101, zelfs met pauzes. Het patroon is oud, maar de les is actueel: ruwe hoeveelheid vanaf één IP of fingerprint triggert uiteindelijk de verdediging.
Beste pacing-praktijken voor DIY GitHub-scrapers:
- Willekeurige vertragingen tussen verzoeken (geen vaste intervallen, want die zijn detecteerbaar)
- 2 tot 5 seconden tussen openbare productverzoeken voor simpele HTTP-clients
- Exponentiële backoff na een 503 of CAPTCHA — stap voor stap terugschalen in plaats van meteen opnieuw proberen
- Lagere concurrency dan je denkt nodig te hebben
- Fail-open logging in plaats van strakke retry-lussen
De meeste amazon scraper github-repos hebben geen ingebouwde rate limiting. Die zul je zelf moeten toevoegen.
Header-orchestratie: meer dan alleen User-Agent-strings
Amazon controleert de volledige header-set, niet alleen de User-Agent.
Een realistische browser-header-set hoort onder andere te bevatten:
User-AgentAcceptAccept-LanguageAccept-EncodingSec-CH-*hints wanneer relevant- Connectiegedrag dat past bij het gekozen browserprofiel
Headers moeten overeenkomen met de locale van de marketplace. Een ontdekte dat dezelfde botopstelling alleen in sommige locales werd gedetecteerd, waarbij een andere reageerder wees op regio-gerelateerde headers zoals Accept-Language.
De regel: headers, TLS/browserprofiel en proxygeografie mogen elkaar niet tegenspreken. Stuur geen Chrome-headers met een Firefox UA. Gebruik geen Amerikaanse proxy met Accept-Language: de-DE.
CAPTCHA-afhandeling: wanneer oplossen en wanneer terugschakelen
Een CAPTCHA tegenkomen betekent dat Amazon al argwaan heeft. Oplossen reset je trustscore niet.
Bij afzonderlijke, weinig frequente CAPTCHA-gebeurtenissen:
- Het PyPI-pakket is een pure-Python Amazon-tekst-CAPTCHA-oplosser, al is de laatste release van mei 2023 — zie het als een tactisch hulpmiddel, niet als een duurzame strategie
- noemt Amazon Captcha voor $0,45 per 1.000 oplossingen
Bij herhaalde CAPTCHA-lussen:
- Stop met oplossen en begin met terugschakelen
- Herhaalde CAPTCHA’s betekenen dat de sessie verbrand is — oplossen herstelt het vertrouwen in de fingerprint, sessiegeschiedenis of IP-reputatie niet
- Als CAPTCHA’s clusteren per proxy-subnet, zit het probleem in de netwerklayer en niet in de parser
Wanneer je echt een headless browser nodig hebt (en wanneer het overkill is)
De verkeerde reflex is om overal Playwright voor te draaien.
Goede use cases voor een browser:
- Zoekresultaten die afhankelijk zijn van JavaScript-rendering of locale-afhankelijke state
- Reviewflows die doorsturen naar login- of aanmeldpagina’s
- Workflows waarin cookies en browsercontext belangrijker zijn dan brute snelheid
Slechte use cases voor een browser:
- Gewone openbare productpagina’s
- Statische extractie van productdetails waarbij een browser-achtige HTTP-client volstaat
- Bulkophaalwerk op grote schaal waarbij rekenefficiëntie belangrijk is
Begin met de lichtste client die werkt. Een over scrapen op schaal beschreef de progressie: begin met requests, stap dan over naar curl_cffi, en ga alleen naar een volledige browser als de lichtere opties falen. Headless browsers zijn aantoonbaar trager en meer resource-intensief dan HTTP-clients voor het scrapen van Amazon-productpagina’s.
Anti-ban beslismatrix voor Amazon Scraper GitHub-projecten
| Scenario | Aanbevolen aanpak | Waarom |
|---|---|---|
| Openbare productpagina’s (kleine schaal) | curl_cffi + sticky residential sessie | Goedkoopste route die nog steeds op een browser lijkt |
| Zoekresultaatpagina’s | Eerst curl_cffi, Playwright alleen als rendering of state HTTP breekt | Zoeken is meer stateful en locale-gevoelig |
| Reviews (login vereist) | Browsermodus met echte cookies/sessie | Login en dynamische reviewflows zijn moeilijker na te bootsen met kale HTTP |
| Grote schaal (5k+ per dag) | Beheerde scraper-API, unlocker of no-code platform | DIY GitHub-code wordt dan een infrastructuurprobleem |
Als je Amazon Scraper GitHub-project breekt: zorg voor een no-code back-upplan
Elke ervaren scraper houdt een Plan B achter de hand.
Amazon-updates breken uiteindelijk elke GitHub-repo op het slechtst mogelijke moment. Voor e-commerceteams betekent een kapotte scraper gemiste prijswijzigingen, verouderde concurrentiedata en gaten in dashboards.
Veel mensen die zoeken op "amazon scraper github" zijn in feite zakelijke gebruikers — e-commerce operations, marketeers, FBA-onderzoekers — die coding-oplossingen probeerden omdat ze geen betere opties konden vinden. Forumdata laat ook echte frustratie zien met Amazon’s officiële : strikte toegang, beperkte data en die veel verkopers niet kunnen halen.
Waarom GitHub Amazon-scrapers voortdurend onderhoud nodig hebben
De audit hierboven maakt het concreet:
- Verouderde repos stapelen breukmeldingen op zonder fixes
- "Werkende" repos bespreken tegenwoordig openlijk anti-botmaatregelen in de README
- Communitythreads draaien steeds vaker om TLS-fingerprints, CAPTCHA-lussen en proxykwaliteit — niet om CSS-selectors
Voor zakelijke gebruikers is die onderhoudslast de echte verborgen kost. De repo is gratis. Jouw tijd om hem om 2 uur ’s nachts te debuggen niet.
Thunderbit als praktisch alternatief voor een Amazon Scraper
biedt een die titel, prijs, ASIN, beoordelingen, merk, beschikbaarheid, verzendherkomst en originele URL extraheert — zonder code te schrijven.
Hoe dat er in de praktijk uitziet:
- 2-click scraping in plaats van Python-omgevingen, dependencies en proxyconfiguraties opzetten
- Instant Amazon-template — geen AI-overhead, gewoon 1-click extractie
- Browser scraping mode voor pagina’s waarvoor login nodig is (zoals reviewpagina’s die GitHub-scrapergebruikers frustreren)
- Cloud scraping voor openbare productpagina’s op snelheid (50 pagina’s tegelijk)
- Gratis export naar Google Sheets, Airtable, Notion, Excel — niet alleen CSV/JSON
- Scheduled scraper voor doorlopende prijsmonitoring
- AI past zich aan layoutwijzigingen aan — jij hebt geen onderhoudslast
GitHub Amazon Scraper vs. Thunderbit: eerlijke vergelijking

| Factor | GitHub-scraper (bijv. AmzPy) | Thunderbit |
|---|---|---|
| Installatietijd | 15–60 min (Python, dependencies, proxies) | ~2 min (installeer Chrome-extensie) |
| Onderhoud | Jij fixt breuken | AI past zich aan layoutwijzigingen aan |
| Anti-botafhandeling | Zelf doen (proxies, headers, TLS) | Ingebouwd (cloud + browsermodi) |
| Reviews scrapen (ingelogd) | Complex sessiebeheer | Browser scraping mode |
| Data-export | Alleen CSV/JSON | Sheets, Airtable, Notion, Excel, CSV, JSON |
| Planning | Zelf doen (cron, Airflow, enz.) | Ingebouwde scheduled scraper |
| Aanpasbaarheid | Hoger | Lager |
| Kosten | Gratis (plus proxykosten) | Gratis niveau beschikbaar; op credits gebaseerd |
De eerlijke afruil: GitHub-repos bieden meer aanpasbaarheid; Thunderbit biedt meer betrouwbaarheid. Als je team meer waarde hecht aan uptime dan aan flexibiliteit, is de no-code route meestal de rationelere keuze.
Best practices voor gepland en terugkerend Amazon-scrapen
De meeste amazon scraper github-projecten zijn gebouwd voor eenmalige runs, maar echte business use cases — prijsmonitoring, voorraadtracking, concurrentieanalyse — vereisen terugkerende scrapes. GitHub-repos bevatten vrijwel nooit ingebouwde planning, waardoor gebruikers cronjobs, Airflow of n8n-workflows aan elkaar moeten knopen.
DIY-planning voor GitHub Amazon-scrapers
De minimale haalbare setup voor terugkerende runs:
- Cronjob op Linux of macOS om het script volgens schema uit te voeren
- Append-only logs zodat je achteraf fouten kunt debuggen
- Deduplicatie op basis van ASIN + timestamp zodat je geen dubbele data opslaat
- Foutmeldingen (zelfs een simpele e-mail bij een niet-nul exitcode) zodat je weet wanneer een run om 3 uur ’s nachts breekt
Voor complexere teams:
- n8n voor lichte workflowautomatisering (vaak genoemd in communitythreads)
- Airflow voor zwaardere geplande pipelines
- Database-gestuurde state als je verschillen en historie nodig hebt
De kernbest practice is niet de scheduler zelf — het is state management. Houd de laatste succesvolle run, de laatste ASIN-set, gewijzigde prijzen en mislukte URL’s bij.
Plannen eenvoudiger gemaakt met Thunderbit
Thunderbit’s laat je het interval in gewoon Nederlands beschrijven, URL’s invoeren en op "Schedule" klikken. De AI zet natuurlijke taal om in een cron-schema — geen technische setup. Voor e-commerceteams zonder engineers die prijzen of lanceringen van concurrenten monitoren, levert dat een duidelijke vermindering van operationele last op.
Best practices voor terugkerende Amazon-scrapes
Deze gelden ongeacht welke tool je gebruikt:
- Dedupliceer op ASIN + tijdvenster — sla niet twee keer per run hetzelfde product op
- Sla prijzen op als getallen, niet als ruwe strings — scheelt opschoning stroomafwaarts
- Voeg scrape-timestamps toe aan elke rij — die heb je nodig voor trendanalyse
- Volg delta’s, niet alleen de huidige status — "prijs daalde 12% sinds vorige week" is nuttiger dan "prijs is $24,99"
- Stuur meldingen bij betekenisvolle veranderingen — een concurrent die 15% zakt in prijs is een notificatie waard; een fluctuatie van 0,5% is ruis
- Denk na over dataopslag — platte bestanden werken voor kleine runs; voor 5k+ ASIN’s per dag kun je beter aan een database of cloud spreadsheet denken
Outputkwaliteit naast elkaar: wat elke Amazon Scraper GitHub-aanpak daadwerkelijk teruggeeft
Niemand vergelijkt de werkelijke outputkwaliteit tussen amazon scraper github-repos. Gebruikers hechten enorm aan datakwaliteit — "welke tool levert de schoonste, meest complete data" — maar moeten elke repo zelf klonen en testen. Deze sectie vult dat gat.
Wat populaire GitHub-repos echt extraheren (en missen)
Gebaseerd op README-voorbeelden, openbare voorbeelden en gedocumenteerde outputformaten:
| Aanpak | Wat het duidelijk extraheert | Veelvoorkomende hiaten / afruilen |
|---|---|---|
| amzpy | Titel, prijs, valuta, afbeeldings-URL, beoordelingen, reviews, varianten, ASIN | Gericht op productpagina’s; minder rijk in volledige reviews/specs-secties |
| tducret/amazon-scraper-python | CSV met titel, beoordeling, aantal reviews, product-URL, afbeeldings-URL, ASIN | Verouderd, gericht op listings, zwak anti-botverhaal |
| python-scrapy-playbook scraper | Zoekresultaten, productpagina’s, reviews, CSV/JSON-pipelines | Tutorial-niveau; leunt op externe proxy-middleware; extra opschoning waarschijnlijk nodig |
| omkarcloud/amazon-scraper | Zoeken, categorie, details, topreviews, veel afbeeldingen/video’s/specs | Geen ruwe scraper — het is een beheerde API-dienst |
| Thunderbit Amazon template | Titel, prijs, ASIN, merk, beoordeling, reviews, beschikbaarheid, verzendherkomst, verrijking van subpagina’s | Minder code-level controle dan maatwerk scripts |
Tabel voor vergelijking van outputkwaliteit
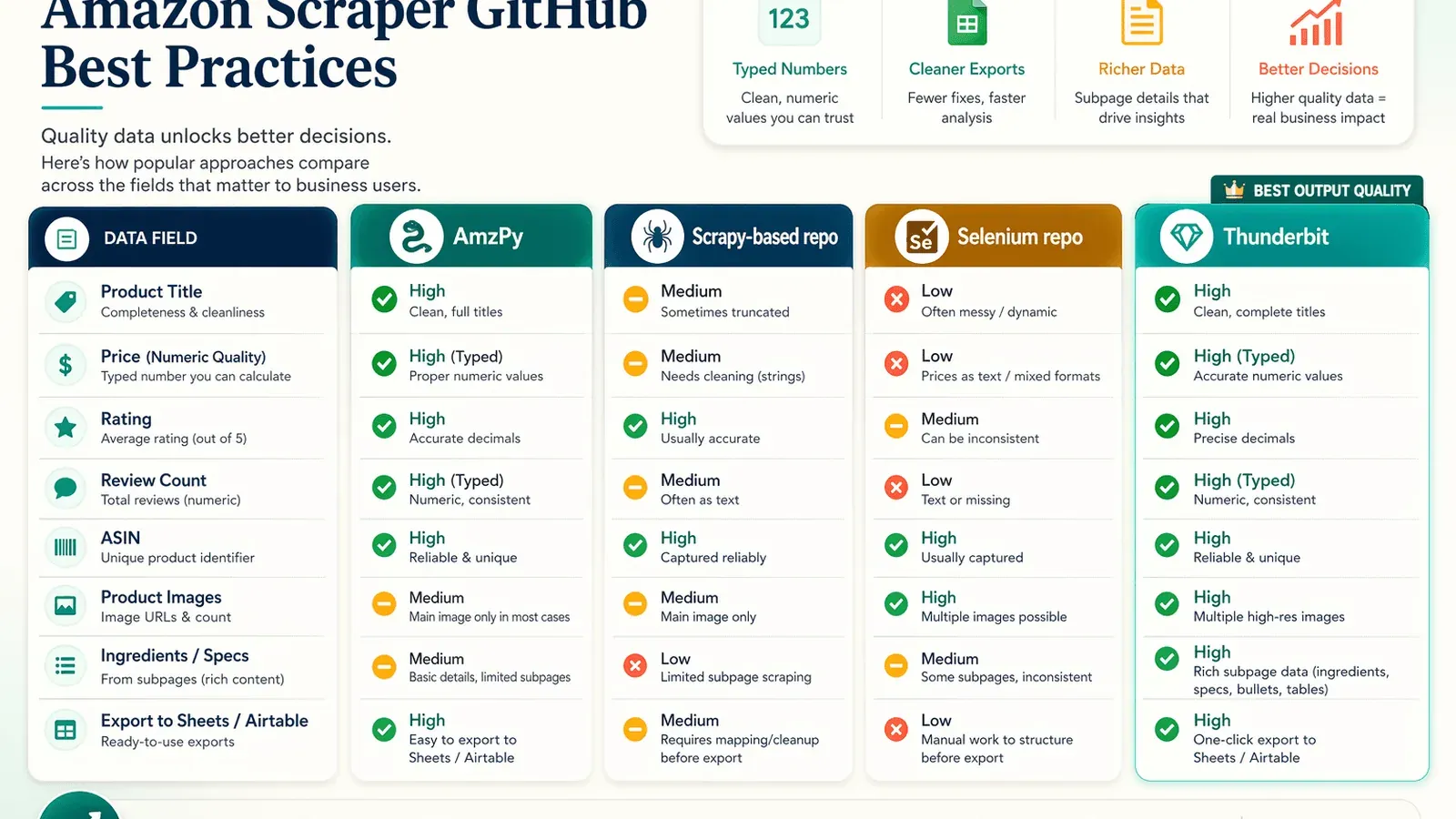
| Gegevensveld | AmzPy | Repo op basis van Scrapy | Selenium-repo | Thunderbit |
|---|---|---|---|---|
| Producttitel | ✅ | ✅ | ✅ | ✅ |
| Prijs (numeriek) | ⚠️ string | ✅ | ⚠️ string | ✅ (getaltype) |
| Beoordeling | ✅ | ✅ | ✅ | ✅ |
| Aantal reviews | ❌ | ✅ | ✅ | ✅ |
| ASIN | ✅ | ✅ | ✅ | ✅ |
| Productafbeeldingen | ❌ | ⚠️ alleen thumbnail | ✅ | ✅ (hoge resolutie, exporteerbaar) |
| Ingrediënten/specs | ❌ | ❌ | ❌ | ✅ (via subpage scraping + AI) |
| Export naar Sheets/Airtable | ❌ | ❌ | ❌ | ✅ gratis |
Waarom dataopmaak belangrijk is voor zakelijke gebruikers
Rommelige data creëert verborgen arbeid. Zelfs een succesvolle scraper kan operationeel falen als:
- Prijzen strings zijn met valutasymbolen in plaats van schone getallen
- Ontbrekende waarden inconsistent zijn (lege string vs. null vs. "N/A")
- Afbeeldingen alleen thumbnails in lage resolutie zijn
- Reviewvelden of specs nog nabewerking nodig hebben vóór analyse
Voor e-commerce operation-teams heeft schone data direct invloed op analysesnelheid en besluitvorming. Thunderbit’s AI formatteert data op type — getallen als getallen, datums als datums, URL’s als URL’s — zodat je er meteen mee aan de slag kunt. GitHub-repos verschillen daar sterk in, en de schoonmaaktijd loopt snel op.
Snelle referentie: checklist met best practices voor Amazon Scraper GitHub
- Controleer de datum van de laatste commit vóór je kloont. Ouder dan zes maanden is op Amazon een sterk waarschuwingssignaal.
- Doorzoek issues op "captcha", "503", "blocked" en "not working" vóór de setup.
- Geef voorkeur aan
curl_cffiof een andere browser-imiterende HTTP-client boven gewonerequests. - Houd headers, TLS-profiel, taal en proxygeografie consistent — geen tegenstrijdigheden.
- Gebruik sticky sessies voor browseflows; roteer niet blind bij elk verzoek.
- Voeg willekeurige pacing en exponentiële backoff toe.
- Zie herhaalde CAPTCHA’s als een verbrande sessie, niet als een puzzel om brute-forcen.
- Gebruik headless browsers alleen wanneer HTTP-clients de pagina niet betrouwbaar kunnen reproduceren.
- Sla checkpoints en state op zodat mislukte runs veilig kunnen hervatten.
- Heb een fallbackplan — of dat nu een beheerde API is of een no-code tool zoals .
Juridische en ethische overwegingen voor Amazon-scraping in 2026
Kort even een paar dingen om te weten.
Amazon’s houding is restrictief en wordt steeds restrictiever. De sterkste signalen:
- Amazon’s eigen hulppagina’s geven nu een terug met de tekst: "To discuss automated access to Amazon data please contact api-services-support@amazon.com."
- Amazon’s blokkeert een brede reeks dynamische, review-, profiel-, verlanglijst- en offer-listingpaden.
- Amazon’s maakt expliciet bezwaar tegen verborgen of verhulde agenttoegang, omzeiling van beveiligingsmaatregelen en het verkeerd identificeren van een agent als Google Chrome. Amazon over het incident.
- Amazon heeft in eind 2025 de tegen OpenAI-crawlers.
Het praktische risico is duidelijk hoger wanneer je van openbare productpagina’s naar geauthenticeerde flows, verhulde automatisering of commerciële extractie op grote schaal gaat. Dit is geen juridisch advies — raadpleeg je eigen juridische team voor jouw specifieke situatie.
Belangrijkste lessen: betrouwbare Amazon-data krijgen zonder geblokkeerd te worden
In volgorde van belangrijkheid:
- Audit vóór je kloont. Ga ervan uit dat de meeste GitHub-resultaten verouderd zijn, tutorials zijn of wrappers rond commerciële API’s.
- Upgrade eerst je netwerklayer. TLS-fingerprinting en sessiecoherentie zijn belangrijker dan HTML-selectors.
- Gebruik sticky residential sessies, geen willekeurige proxy-chaos. Roteer tussen sessies, niet erin.
- Tem requests alsof je een gebruiker bent, niet alsof je een stresstest draait. Willekeurige vertragingen en exponentiële backoff zijn niet-onderhandelbaar.
- Los geïsoleerde CAPTCHA’s op; beëindig sessies die herhaaldelijk worden uitgedaagd. Forceer geen verbrande fingerprint.
- Heb een fallback. Amazon verandert halverwege de week iets en je GitHub-scraper breekt. Een onderhouden no-code tool zoals of een beheerde API kan je datapijplijn overeind houden terwijl jij debugt.
- Geef prioriteit aan outputkwaliteit. Schone, getypeerde data bespaart downstream meer tijd dan een snelle maar rommelige scraper.
Als je betrouwbaarheid boven aanpasbaarheid verkiest, biedt Thunderbit een onderhouden alternatief — bekijk de of bekijk tutorials op het . Developers die volledige controle willen, kunnen GitHub-repos absoluut gebruiken — maar alleen met de anti-ban- en onderhoudspraktijken uit deze gids.
Veelgestelde vragen
Is het legaal om Amazon-productdata te scrapen met een GitHub-scraper?
Amazon’s voorwaarden beperken geautomatiseerde dataverzameling, en Amazon handhaaft dit actief via cease-and-desist-brieven en technische tegenmaatregelen (vooral in 2025-2026). Het scrapen van publiek toegankelijke productdata zit in een grijs gebied; scrapen achter een login of je bot verhullen als een echte browser brengt meer risico met zich mee. Dit is geen juridisch advies — raadpleeg je juridische team voor je specifieke use case.
Hoe vaak breken Amazon-scraper GitHub-repos?
Vaak. Amazon verandert paginalay-outs, voegt nieuwe anti-botlagen toe en deprecieert endpoints regelmatig. In de audit voor dit artikel waren slechts ongeveer 3 van de 8 breed zichtbare repos in 2026 duidelijk functioneel. Zelfs "werkende" repos hebben vaak open issues over CAPTCHA’s en 503-fouten. Reken erop dat je je setup elke paar weken tot maanden moet troubleshooten of bijwerken.
Wat is de beste Amazon-scraper op GitHub in 2026?
Er is geen absolute winnaar — het hangt af van je use case en je technische comfort. Voor een lichtgewicht, directe Python-scraper is een van de actuelere opties. Voor bredere dekking via een beheerde API werkt , maar het is niet echt DIY. Gebruik de versheidschecklist uit dit artikel om elke repo zelf te beoordelen vóór je je eraan verbindt.
Kan Thunderbit Amazon scrapen zonder code?
Ja. Thunderbit’s extraheert producttitel, prijs, ASIN, beoordelingen, merk, beschikbaarheid en meer met één klik. Het ondersteunt browser scraping mode voor pagina’s waarvoor login nodig is, cloud scraping voor openbare pagina’s op snelheid, scheduled scraping voor terugkerende taken en gratis export naar Google Sheets, Airtable, Notion en Excel. Je kunt starten door de te installeren.
Hoe voorkom ik dat mijn IP wordt geblokkeerd bij het scrapen van Amazon?
Gebruik een gelaagde aanpak: (1) stap over van gewone requests naar een TLS-imiterende client zoals curl_cffi, (2) gebruik residential proxies met sticky sessies in plaats van willekeurige datacenterrotatie, (3) voeg willekeurige pacing en exponentiële backoff toe, (4) houd je volledige header-set consistent met je browserprofiel en marketplace-locale, en (5) zie herhaalde CAPTCHA’s als een signaal om de sessie te beëindigen, niet als een puzzel die je eindeloos moet oplossen. Zie voor meer detail de anti-ban-beslismatrix eerder in dit artikel.