
Elke AI-webscraper ziet er fantastisch uit in een productdemo. Tot je hem loslaat op een echte site met Cloudflare-beveiliging, en hij een challenge-pagina teruggeeft terwijl hij doodleuk zegt dat hij 47 productvermeldingen heeft gevonden.
Ik heb de afgelopen maanden scrapers voor ons team bij Thunderbit geëvalueerd. In communities zie ik keer op keer hetzelfde terugkomen: het verschil tussen demo-prestaties en betrouwbaarheid in productie is de grootste frustratie. Een Reddit-gebruiker vatte het perfect samen: Met in alleen al de categorie web scraping, plus tientallen Chrome-extensies, API-aanbieders en actor-marktplaatsen, is de keuzeparadox echt. Dus testte ik er 12.
Dit artikel vergelijkt 12 AI-webscraper-tools op basis van criteria die ertoe doen in productie: anti-botafhandeling, schaalbaarheid, kwaliteit van gestructureerde output, kostenefficiëntie, ondersteuning voor dynamische sites en flexibiliteit voor ontwikkelaars. Geen functielijstjes. Geen marketingscreenshots. Alleen wat echt werkt zodra de demo voorbij is.
Waarom de meeste AI-webscrapers na de demo falen
Het patroon is voorspelbaar. De marketingsite van een tool laat zien hoe hij schone kolommen extraheert uit een eenvoudige productoverzichtspagina. Je installeert hem, probeert hem op een beveiligde e-commercesite, en krijgt een van deze uitkomsten:
- Een
200 OK-reactie met een Cloudflare-challenge-pagina in plaats van echte data - Schone resultaten voor de eerste 5 pagina’s, daarna stille fouten of verzonnen rijen
- Vandaag perfecte extractie, volgende week kapotte selectors na een kleine lay-outwijziging
Dit zijn geen uitzonderingen. Dit is de norm.
Zoals een gebruiker : "The scraper returns a 200 with a Cloudflare challenge page, your agent tries to reason over it, hallucinates, and you have no idea why."
Het kernprobleem is architectonisch. De meeste demo’s laten de parslaag zien op schone openbare pagina’s, terwijl het echte werk stukloopt in de fetchlaag. Productiesites voegen botbeveiliging, dynamische rendering, geneste detailpagina’s, infinite scroll, inlogstatus, localeverschillen en veranderende lay-outs toe.
Een tool kan er in een producttour geweldig uitzien en alsnog binnen de eerste serieuze workflow van een klant onderuitgaan.
Daarom beoordeelt dit artikel elke tool vanuit het perspectief van productiegeschiktheid in plaats van een functielijst. De zes criteria die ik gebruikte:
| Criteria | Waarom het telt |
|---|---|
| Anti-bot/CAPTCHA-afhandeling | Beveiligde sites vallen al uit vóór extractiekwaliteit relevant wordt |
| Schaalbaarheid voorbij de demo | Batchtaken en parallelle runs onthullen operationele grenzen |
| Kwaliteit van gestructureerde output | Gebruikers hebben schone JSON/CSV nodig, geen ruwe HTML die handmatige opschoning vereist |
| Token-/kostenefficiëntie | AI-extractie kan duurder worden dan het scrapen zelf |
| Ondersteuning voor dynamische/JS-zware sites | Moderne pagina’s vereisen gerenderde DOM’s, geen statische HTML |
| No-code vs. API-flexibiliteit | Sales-teams en data-engineers hebben verschillende behoeften |
Als je snel wilt zien hoe web scraping de afgelopen twee jaar is veranderd, is deze Browserless-talk een goede opmaat voordat je de tools één voor één vergelijkt.
Waar AI echt helpt in een scraping-pipeline (en waar niet)
Een hardnekkige mythe in deze markt is dat "AI web scraper" betekent dat AI alles end-to-end doet. De community is daar opvallend duidelijk over: . De botte samenvatting van een gebruiker: "Je gebruikt AI om een screenshot van een webpagina te lezen. Je gebruikt AI niet om de scraper zelf te coderen."
De scraping-pipeline heeft drie verschillende lagen, en de waarde van AI verschilt per laag enorm:
Crawlen en ophalen: de infrastructuurlaag
Hier gebeuren de requests: proxies, headless browsers, sessiebeheer, CAPTCHA-oplossing, retries. AI doet hier bijna niets nuttigs. Je hebt nog steeds proxy pools, browser fingerprinting en unblocking-infrastructuur nodig. Dit is waar de meeste tools in productie als eerste falen.
Parsen en extraheren: waar AI uitblinkt
Zodra je schone pagina-inhoud hebt, is AI uitstekend in het omzetten van ongestructureerde HTML naar gestructureerde velden. Schema-gebaseerde extractie, adaptieve veldherkenning en het omgaan met lay-outvariaties zonder kwetsbare XPath-selectors zijn precies het sterke punt van AI in scraping.
Naverwerking: labelen, vertalen, categoriseren
Na extractie voegt AI waarde toe door producten te categoriseren, tekst te vertalen, telefoonnummers te normaliseren of beschrijvingen samen te vatten. Dat werkt sterk, maar alleen als de geëxtraheerde data al klopt.
Zo verhouden de 12 tools zich tot deze lagen:
| Tool | Crawlen/ophalen | Parsen/extractie | Naverwerking | Beste omschrijving |
|---|---|---|---|---|
| Thunderbit | Sterk | Sterk | Sterk | Full-stack no-code AI-webscraper |
| Octoparse | Sterk | Midden | Laag | Op regels gebaseerde visuele scraper met cloudinfrastructuur |
| Browse AI | Midden | Midden | Midden | Cloudrobotplatform gericht op monitoring |
| Firecrawl | Midden | Sterk | Laag-Midden | Extractie-API voor ontwikkelaars |
| Apify | Sterk | Midden-Sterk | Midden | Actor-marktplaats en orkestratie |
| Gumloop | Midden | Midden | Sterk | Workflow-automatisering met scraper-nodes |
| Bright Data | Zeer sterk | Midden | Laag-Midden | Enterprise-infrastructuurstack |
| Bardeen | Midden | Midden | Sterk | Browserautomatisering voor GTM-workflows |
| Diffbot | Laag-Midden | Zeer sterk | Midden | Voorgetrainde extractie plus knowledge graph |
| ScrapingBee | Sterk | Laag-Midden | Laag | Fetching- en unblocking-API |
| Instant Data Scraper | Laag | Midden (eenvoudige pagina’s) | Laag | Heuristische snelle scraper in de browser |
| ParseHub | Midden | Midden | Laag | Desktop-visual scraper voor complexe interacties |
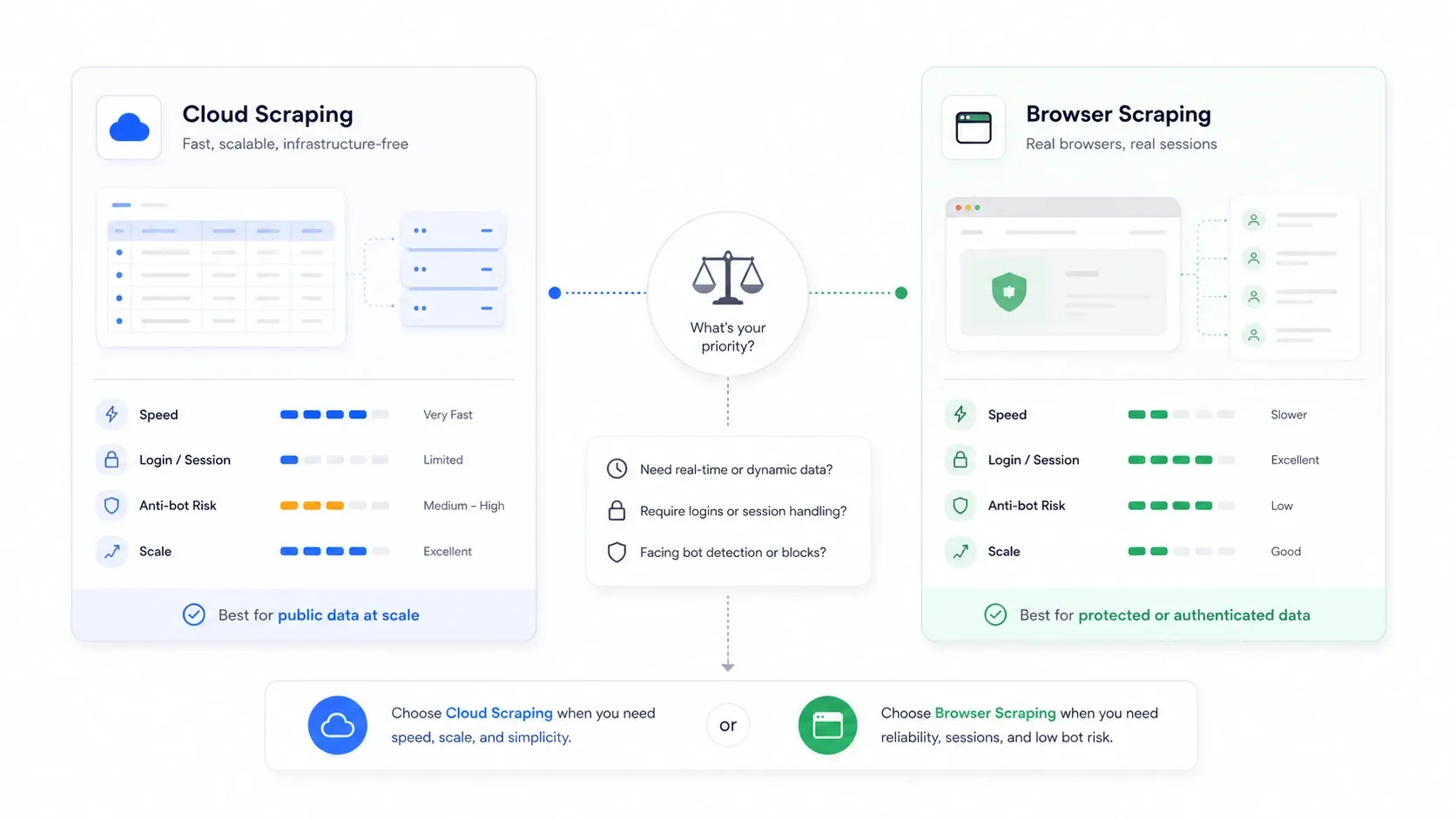
Cloud scraping versus browser scraping: de keuze die niemand uitlegt
Dit is de architectonische beslissing die de meeste overzichtsartikelen volledig overslaan, en vaak is die belangrijker dan welke tool je kiest.
Cloud scraping betekent dat externe servers pagina’s voor je ophalen. Browser scraping betekent dat de extractie gebeurt in je eigen browsersessie, met jouw cookies, jouw IP en jouw geauthenticeerde status.
| Scenario | Beter mode | Waarom |
|---|---|---|
| Openbare e-commerce- en overzichtssites op grote schaal | Cloud | Snellere parallelisatie en geen bottleneck van je lokale machine |
| Sites waarvoor je moet inloggen of authenticeren | Browser | Hergebruikt je echte sessiecookies |
| Sites die datacenter-IP’s afstraffen | Browser | Lijkt op normaal gebruikersverkeer |
| Grote terugkerende monitoringtaken | Cloud | Eenvoudiger plannen en continuïteit |
| Eenmalige, fragiele taken die gevoelig zijn voor anti-botmaatregelen | Browser | Makkelijker te inspecteren wat de site echt heeft gerenderd |
Dit is economisch ook relevant. Apify’s State of Web Scraping-report van 2026 laat zien dat van jaar tot jaar, en dat hogere infrastructuurkosten rapporteert. Anti-bot is dus niet alleen een technisch probleem, maar ook een budgetkwestie.
De meeste tools bieden maar één mode. Dit is het overzicht:
| Tool | Cloud | Browser | Beide |
|---|---|---|---|
| Thunderbit | ✅ | ✅ | ✅ |
| Octoparse | ✅ | ✅ (lokaal) | ✅ |
| Browse AI | ✅ | Alleen setup | — |
| Firecrawl | ✅ | API voor interactief gebruik | — |
| Apify | ✅ | ✅ (via actors) | ✅ |
| Gumloop | ✅ | ✅ (Web Agent) | ✅ |
| Bright Data | ✅ | ✅ | ✅ |
| Bardeen | Beperkt (openbare pagina’s) | ✅ | Gedeeltelijk |
| Diffbot | ✅ | — | — |
| ScrapingBee | ✅ | — | — |
| Instant Data Scraper | — | ✅ | — |
| ParseHub | ✅ (betaald) | ✅ (desktop) | ✅ |
De 12 AI-webscrapers in één oogopslag
Hier is de hoofdvergelijking van alle 12 tools:
| Tool | Het beste voor | Gratis tier | Cloud/browser | API-toegang | Geplande scraping | Anti-botafhandeling |
|---|---|---|---|---|---|---|
| Thunderbit | Niet-technische teams | ✅ (6 pagina’s) | Beide | ✅ | ✅ | Sterk |
| Octoparse | Template-zware scraping | ✅ (beperkt) | Beide | ✅ | ✅ | Gemiddeld-sterk |
| Browse AI | Wijzigingen monitoren | ✅ (beperkt) | Vooral cloud | ✅ | ✅ | Gemiddeld |
| Firecrawl | Dev-extractiepijplijnen | ✅ (1.000 credits/maand) | Cloud plus browser-API | ✅ | Nee | Gemiddeld |
| Apify | Dev-teams plus marktplaats | ✅ ($5 gratis gebruik) | Beide | ✅ | ✅ | Sterk met add-ons |
| Gumloop | Workflowautomatisering | ✅ (5.000 credits/maand) | Beide | ✅ | ✅ | Midden |
| Bright Data | Enterprise data-toegang | Proefperiode / credits | Beide | ✅ | Extern | Zeer sterk |
| Bardeen | Browserautomatisering voor sales en ops | ✅ (100 credits) | Browser-first | Beperkt | ✅ | Midden-laag |
| Diffbot | Gestructureerde extractie-API’s | ✅ (10.000 credits) | Cloud | ✅ | Nee | Laag bij fetching / hoog bij extractie |
| ScrapingBee | Dev-fetching en unblocking | ✅ (1.000 credits) | Cloud | ✅ | Nee | Sterk |
| Instant Data Scraper | Gratis eenmalige scrapes | ✅ (helemaal gratis) | Alleen browser | Nee | Nee | Laag |
| ParseHub | Complexe visuele workflows | ✅ (5 projecten) | Desktop plus cloud | ✅ | ✅ (betaald) | Midden |
1. Thunderbit
is de AI-webscraper die we speciaal hebben gebouwd voor niet-technische teams die productiedata nodig hebben zonder code te schrijven of infrastructuur te beheren. De kernworkflow is echt twee klikken: AI Suggest Fields leest de pagina en stelt kolommen voor, waarna Scrape de extractie uitvoert in cloud- of browsermode.
Wat Thunderbit anders maakt dan andere no-code scrapers is de architectuur. Thunderbit scheidt crawl-onderdelen zoals cloudinfrastructuur, proxyrotatie, anti-botafhandeling en JavaScript-rendering van AI-extractie die HTML leest en gestructureerde kolommen oplevert. Dat sluit aan bij het door experts aanbevolen patroon van "scraper first, LLM second", maar dan verpakt in een Chrome-extensieworkflow die salesmedewerkers en operations-managers echt kunnen gebruiken.
Belangrijkste sterke punten
- Zowel cloud- als browserscraping in één interface. Wissel van mode afhankelijk van of de doelsite openbaar is of je geauthenticeerde sessie vereist. Cloudmode verwerkt tot 50 pagina’s parallel.
- AI leest de paginastructuur elke keer opnieuw. Geen XPath-onderhoud. Als een site zijn lay-out aanpast, past Thunderbit zich automatisch aan bij de volgende run.
- Subpage scraping. AI bezoekt gekoppelde detailpagina’s en verrijkt de hoofd-datatabel zonder handmatige configuratie.
- Field AI Prompts. Aangepast labelen, vertalen en categoriseren tijdens de extractie in plaats van als aparte naverwerkingsstap.
- Gratis exports naar Google Sheets, Excel, Airtable en Notion.
- Directe scraper-sjablonen voor populaire sites zoals Amazon, Zillow en LinkedIn.
- Plannen in natuurlijke taal. Zeg “scrape elke maandag om 9 uur” en het wordt omgezet naar een terugkerend schema.
- Open API met Distill- en Extract-endpoints, batchverwerking tot 100 URL’s en openbare gelijktijdigheid van 2 op Free tot 50 op Pro 1.
Waar het beter kan
- De gratis tier is bewust klein.
- Voor de no-code-ervaring draait veel om de Chrome-extensie. Ontwikkelaars die alleen API-workflows willen, moeten de Open API apart gebruiken.
- Niet de juiste tool als je primaire behoefte ruwe proxy-infrastructuur is zonder extractie.
Prijs
Gratis tier beschikbaar. No-code-abonnementen starten vanaf $9/maand bij jaarlijkse facturering of $15/maand per maand voor Starter. API-prijzen zijn apart: eenmalig gratis 600 units, daarna $16/maand jaarlijks voor Starter API en $40/maand jaarlijks voor Pro 1 API. Zie en .
Het beste voor: Sales-, e-commerce- en operationsteams die gestructureerde webdata nodig hebben zonder ondersteuning van engineers.
2. Octoparse
is een visuele workflowbouwer voor web scraping met een grote bibliotheek aan kant-en-klare sjablonen. Het bestaat al lang genoeg om volwassen cloudinfrastructuur te hebben, en het gaat goed om met paginering op gestructureerde, voorspelbare websites.
Belangrijkste sterke punten
- Uitgebreide set vooraf gebouwde scraping-sjablonen voor populaire sites
- Cloud-extractie met geplande runs
- IP-rotatie en CAPTCHA-oplossing als betaalde add-ons
- API-toegang op hogere abonnementen
Waar het beter kan
- AI-mogelijkheden zijn lichter dan bij LLM-native tools. Veldsuggesties leunen nog steeds meer op sjablonen dan op adaptief lezen.
- Complexe of ongebruikelijke lay-outs vereisen veel handmatige finetuning in de visuele editor.
- De leercurve wordt steiler zodra je conditionele logica of anti-blocking workarounds nodig hebt.
Prijs
Er is een gratis forever-abonnement beschikbaar. De officiële helpcenter-prijzen verwijzen momenteel naar Standard vanaf $75/maand bij jaarlijkse facturering en Professional vanaf $208/maand bij jaarlijkse facturering, terwijl sommige gelokaliseerde pagina’s en upgradepaden hogere maandelijkse equivalenten tonen. Het belangrijkste is dat de prijsstructuur van Octoparse nu abonnementsniveaus combineert met betaalde add-ons zoals residential proxies en CAPTCHA-oplossing.
Het beste voor: Analisten en operationsteams die gestructureerde, templatevriendelijke sites op middelgrote schaal scrapen.
3. Browse AI
is een cloudgebaseerd no-codeplatform dat vooral is gebouwd voor het monitoren van websitewijzigingen door de tijd heen, zoals prijswijzigingen van concurrenten, voorraadbeschikbaarheid en contentupdates. Scraping maakt deel uit van het product, maar de echte onderscheidende factor is het terugkerende monitorings- en waarschuwingssysteem.
Belangrijkste sterke punten
- Ingebouwde wijzigingsdetectie en meldingen
- No-code robotrecorder met point-and-click-instelling
- Vooraf gebouwde robots voor populaire sites
- Premium proxy-ondersteuning op hogere abonnementen
Waar het beter kan
- Creditgebaseerde prijsstelling wordt snel duur wanneer je detailpagina’s op schaal monitort
- Minder aantrekkelijk voor eenmalige grootschalige extractie dan API-first tools
- Gemiddelde anti-botafhandeling; sommige sites hebben nog steeds premium proxies of workarounds nodig
Prijs
Gratis account beschikbaar. Betaalde abonnementen beginnen rond $19/maand bij jaarlijkse facturering voor Starter, met hogere credits- en monitoringtier daarboven.
Het beste voor: Teams die voortdurend concurrentieprijzen, contentwijzigingen of voorraadniveaus willen volgen in plaats van eenmalige bulkextractie.
4. Firecrawl
is een developer-first API die webpagina’s omzet in schone Markdown of gestructureerde JSON. Het zit vooral in de extractielaag en is uitstekend voor teams die RAG-pijplijnen bouwen of webcontent in LLM’s willen voeden.
Belangrijkste sterke punten
- Uitstekende kwaliteit van Markdown-output voor downstream LLM-workflows
- Schone API met scrape-, crawl-, map-, search-, extract- en browseracties
- Ondersteuning voor batchverwerking
- Gelijktijdigheid van 2 op Free tot 100 op Growth
Waar het beter kan
- Geen no-code interface en vereist ontwikkelaarsvaardigheden
- Ingebouwde proxy- en anti-bot-hulp bestaat, maar Firecrawl positioneert zich niet als dedicated unblocking-aanbieder
- Geen eigen planner voor terugkerende taken
- Niet kostenefficiënt voor niet-ontwikkelaars die gewoon een spreadsheet met data willen
Prijs
Het gratis plan bevat 1.000 credits per maand. Betaalde plannen beginnen jaarlijks bij $16/maand voor Hobby en schalen op met meer credits, gelijktijdigheid en browsergebruik. Browsersessies worden apart in credits afgerekend.
Het beste voor: Ontwikkelaars die LLM-pijplijnen, RAG-systemen of aangepaste extractieworkflows bouwen en schone Markdown of JSON van webpagina’s nodig hebben.
5. Apify
is een platform met een marktplaats van vooraf gebouwde scraping-actors plus tools om eigen actors te bouwen. Zie het als een orkestratielaag waar je gespecialiseerde scrapers voor specifieke sites kiest of bouwt, en ze vervolgens plant en beheert via één uniforme API.
Belangrijkste sterke punten
- Gigantische actor-marktplaats met door de community gebouwde scrapers voor honderden sites
- Sterke API en SDK voor ontwikkelaars
- Ingebouwd proxybeheer en planning
- Integreert met veel downstream tools
Waar het beter kan
- "No-code" is maar deels waar zodra je de marktplaats verlaat en aangepaste logica nodig hebt
- De betrouwbaarheid van actors hangt af van onderhoud door de community
- Prijzen kunnen snel oplopen omdat compute, actor-kosten en proxies zich opstapelen
Prijs
De gratis tier bevat $5 aan maandelijkse platformcredits. Betaalde plannen beginnen bij $39/maand voor Starter, met hogere tiers voor schaalgebruik daarboven.
Het beste voor: Dev-teams die herbruikbare, planbare scraping-workflows willen met een groot ecosysteem van kant-en-klare oplossingen.
6. Gumloop
is een no-code workflowautomatiseringsplatform met een webscraping-node. De echte waarde zit niet alleen in scraping. Het gaat erom extractie te koppelen aan LLM’s, Google Sheets, CRM’s en andere tools in één visueel canvas.
Belangrijkste sterke punten
- Visuele drag-and-drop workflowbouwer
- Integreert scraping met LLM’s en downstream business tools in één flow
- Gratis plan wordt momenteel geadverteerd met 5.000 credits/maand
- Tijdgebaseerde planning voor terugkerende workflows
- Basis scraping en interactieve Web Agent-modi dekken zowel eenvoudige als rijkere flows
Waar het beter kan
- De scraping-engine is minder robuust dan dedicated AI-webscraper-tools
- Beperkte anti-bot- en proxydiepte vergeleken met specialistische aanbieders
- Limieten voor gelijktijdigheid en triggers zijn strakker op gratis plannen
- Niet ideaal voor grootschalig, hoog-volume scrapen als primair gebruiksdoel
Prijs
Gratis plan beschikbaar. Gumloop combineerde eind 2025 zijn oude Solo- en Team-structuur in een Pro-plan, en de publieke communicatie sindsdien richt zich meer op ruimere gratis credits en geconsolideerde betaalde tiers dan op scraper-first-prijzen.
Het beste voor: Teams die scraping als één stap willen in een bredere geautomatiseerde workflow: scrapen, analyseren en doorzetten naar business tools.
Als je eerst wilt zien hoe een AI-native extractieworkflow in de praktijk voelt voordat je de rest van de lijst leest, is deze Thunderbit-walkthrough de meest relevante productdemo voor niet-technische teams.
7. Bright Data
is de enterprise-grade infrastructuurstack op deze lijst. Als jouw probleem is: "Ik kom hoe dan ook niet voorbij de botbeveiliging op deze site," dan is Bright Data waarschijnlijk het antwoord, maar het komt wel met enterprise-complexiteit en bijbehorende prijzen.
Belangrijkste sterke punten
- Toonaangevend proxy-netwerk over residential, datacenter- en mobiele IP’s
- Web Unlocker voor anti-bot- en CAPTCHA-bypassing
- Scraping Browser met ingebouwde unblocking
- Vooraf verzamelde datasets beschikbaar voor aankoop
- Volledige programmatische controle via API en SDK
Waar het beter kan
- Niet ontworpen voor niet-technische gebruikers
- Prijzen weerspiegelen de enterprise-positionering
- AI-extractie is niet de belangrijkste reden om het platform te kopen
Prijs
Browser API start bij $8/GB pay-as-you-go, met lagere prijzen per GB bij grotere maandelijkse afnames. Andere Bright Data-producten zoals Unlocker, Scraper APIs, datasets en proxy pools gebruiken andere prijseenheden.
Het beste voor: Enterprise-datateams die zwaar beveiligde sites op schaal moeten scrapen en de technische mensen hebben om de infrastructuur te beheren.
8. Bardeen
is een browserautomatiseringstool die zich richt op klikken, formulierinvullingen en scraping, met AI-gestuurde data-extractie erbovenop. Je kunt het het best zien als een GTM-workflowtool die toevallig ook scrapt, niet als een scrapingtool die toevallig GTM doet.
Belangrijkste sterke punten
- Intuïtieve playbook-stijl automatisering waarbij scraping één stap is
- Officiële scrapers onderhouden door het Bardeen-team voor populaire sites
- Sterke integraties met CRM, Google Sheets, Slack en andere business tools
- Goed voor lead scraping, verrijking en CRM-exportworkflows
Waar het beter kan
- Browser-first architectuur beperkt scrapen met hoog volume zonder toezicht
- Cloud scraping werkt alleen op openbare pagina’s, niet op afgeschermde
- Anti-botafhandeling is vooral wat je browsersessie al biedt
- AI-extractie kan moeite hebben met complexe of niet-standaard lay-outs
Prijs
Gratis plan bevat 100 maandelijkse credits. Openbare supportdocumentatie verwijst naar oude $15/maand Pro-prijzen voor bestaande gebruikers, terwijl de huidige commerciële verpakking van Bardeen meer enterprise- en workflowgericht is dan klassieke low-end scraper-prijzen.
Het beste voor: Sales- en operationsteams die scraping nodig hebben als onderdeel van een bredere browserautomatiseringsworkflow.
9. Diffbot
gebruikt computer vision en NLP om webpagina’s te lezen als een mens, en levert gestructureerde data voor artikelen, producten, discussies en organisaties. Het is een van de extractie-API’s van de hoogste kwaliteit die beschikbaar zijn als je pagina’s passen bij de voorgetrainde modellen.
Belangrijkste sterke punten
- Voorgetrainde extractiemodellen voor artikelen, producten, discussies en meer
- Knowledge Graph met miljarden entiteiten voor dataverrijking
- Sterke kwaliteit van gestructureerde output op ondersteunde paginatypes
- Duidelijke developer-API met gepubliceerde rate limits
Waar het beter kan
- Geen no-code interface
- Geen ingebouwde crawling, proxybeheer of anti-botafhandeling
- Duur voor kleine teams
- Minder flexibel op niet-standaard paginatypes dan schema-prompt extractors
Prijs
Het gratis plan bevat 10.000 credits. Startup is $299/maand voor 250.000 credits, en Plus is $899/maand voor 1.000.000 credits.
Het beste voor: Dev-teams die zeer nauwkeurige gestructureerde extractie nodig hebben van standaard paginatypes en fetching apart willen afhandelen.
10. ScrapingBee
is een webscraping-API die zich richt op de fetch- en unblocking-laag. Je stuurt een URL, het handelt proxies, headless-browser-rendering en anti-botverdediging af, en geeft HTML terug of optioneel geëxtraheerde data.
Belangrijkste sterke punten
- Ingebouwde proxyrotatie en anti-botafhandeling
- Ondersteuning voor JavaScript-rendering
- Simpele REST API
- Endpoint voor Google Search scraping
- Gepubliceerde gelijktijdigheid per plan
Waar het beter kan
- AI-extractiefuncties zijn beperkt
- Geen no-code interface
- Geen ingebouwde planning of monitoring
- Een
200-reactie met een blokpagina kan nog steeds als geslaagde request tellen
Prijs
Gratis plan bevat 1.000 API-credits. Betaalde plannen beginnen bij $49/maand en schalen op met hogere gelijktijdigheid en requestvolumes.
Het beste voor: Ontwikkelaars die vooral betrouwbare page fetching voorbij anti-botverdediging nodig hebben en de extractie met eigen code of een aparte tool afhandelen.
11. Instant Data Scraper
is een gratis Chrome-extensie met meer dan 1.000.000 gebruikers die automatisch datapatronen op een pagina detecteert en export naar CSV of Excel mogelijk maakt. Er is geen AI-veldvoorstel in de LLM-zin. Het gebruikt heuristische patroonherkenning.
Belangrijkste sterke punten
- Volledig gratis, geen account nodig
- Detectie van data met één klik op veel overzichts- en tabelpagina’s
- Kan op sommige sites paginering verwerken
- Extreem lage drempel om te starten
- Nog steeds in onderhoud, met updates in de Chrome Web Store in 2026
Waar het beter kan
- Geen AI-gestuurde veldsuggesties of datalabeling
- Geen cloud scraping, planning of API
- Heeft moeite met complexe lay-outs, dynamische content en JS-zware sites
- Geen anti-botafhandeling buiten wat je browser al kan laden
- Export beperkt tot CSV en Excel
Prijs
Gratis. Voor altijd.
Het beste voor: Iedereen die een snelle, eenmalige scrape nodig heeft van een eenvoudige overzichtspagina en geen account wil maken of iets wil betalen.
12. ParseHub
is een desktopapplicatie met een visuele point-and-click-interface voor het bouwen van scrapingprojecten. Het kan complexe geneste data, AJAX-content, infinite scroll en dropdown-interacties aan die eenvoudigere extensies vaak missen.
Belangrijkste sterke punten
- Visuele selectorinterface voor het definiëren van extractieregels
- Verwerkt geneste data, dropdowns, infinite scroll en AJAX-content
- Gratis tier met tot 5 projecten
- Exports naar JSON, CSV en Excel
- Cloudplanning en IP-rotatie op betaalde plannen
Waar het beter kan
- Alleen-desktop workflow, geen gemak van een browserextensie
- Langzamere uitvoering dan cloud-native tools
- Projecten breken wanneer site-lay-outs veranderen, omdat er geen AI-herleeslaag is
- Beperkte AI-mogelijkheden en een meer legacy visuele scraper-ervaring
Prijs
Gratis plan beschikbaar met 5 projecten en 200 pagina’s per run. Betaalde plannen beginnen bij $189/maand met planning, IP-rotatie en hogere limieten.
Het beste voor: Niet-technische gebruikers die complexe interactieve sites willen scrapen en bereid zijn tijd te investeren in het opzetten van een visuele workflow.
Hoe je in 5 stappen start met een AI-webscraper
Elke tool in deze lijst heeft een andere onboardingflow. Ik gebruik Thunderbit als concreet voorbeeld, omdat die het best past bij de zoekintentie: "ik wil dat dit gewoon werkt op een echte pagina".
Stap 1: Installeer en navigeer
Installeer de en open de pagina die je wilt scrapen: een productlijst, een directory of een vastgoedportaal.
Stap 2: Laat AI je datavelden voorstellen
Klik op AI Suggest Fields. De AI leest de huidige pagina en stelt kolomnamen en gegevenstypes voor. Op een productpagina kan dat bijvoorbeeld Productnaam, Prijs, Beoordeling, Afbeeldings-URL en Beschrijving zijn.
Stap 3: Pas velden aan met AI Prompts
Pas kolommen aan als de standaardinstellingen niet helemaal kloppen. Voeg Field AI Prompts toe voor aangepaste transformaties zoals "vertaal de beschrijving naar Spaans", "categoriseer als Elektronica, Wonen of Mode", of "extraheer alleen de numerieke prijs".
Stap 4: Kies cloud- of browsermode en scrape
Selecteer cloud scraping voor openbare sites of browser scraping voor geauthenticeerde of zwaar beveiligde targets. Klik daarna op Scrape.
Stap 5: Exporteer je data waar je maar wilt
Exporteer resultaten naar Google Sheets, Excel, Airtable of Notion. Exporteren is gratis.
Wat als de lay-out van de site verandert?
Dit is het belangrijkste productievoordeel van AI-native extractors boven op regels gebaseerde tools. Traditionele scrapers zoals ParseHub en oudere Octoparse-workflows vertrouwen op XPath-selectors of CSS-paden. Wanneer een site zijn HTML-structuur bijwerkt, breken die selectors en ben je terug bij handmatige herconfiguratie.
AI-gestuurde extractors zoals Thunderbit lezen de paginastructuur elke keer opnieuw. Dat betekent geen XPath-onderhoud en geen kwetsbare selectors. De AI past zich automatisch aan lay-outwijzigingen aan bij de volgende run.
Geplande scraping en API-toegang: de power-userfuncties waar niemand over schrijft
Eenmalige scrapes zijn prima voor onderzoek. Productietoepassingen zoals prijsmonitoring, leadlijstverversing en voorraadtracking vereisen terugkerende extractie en programmatische toegang. Deze functies scheiden speeltjes van tools.
Ondersteuning voor planning
| Tool | Natieve planning | Opmerkingen |
|---|---|---|
| Thunderbit | ✅ | Instelling in natuurlijke taal |
| Octoparse | ✅ | Geplande cloud-runs |
| Browse AI | ✅ | Kernproductfunctie |
| Firecrawl | ❌ | Gebruik externe cron |
| Apify | ✅ | Volledige cron-expressies |
| Gumloop | ✅ | Tijdgebaseerde workflow-triggers |
| Bright Data | Extern | Meestal georkestreerd via klantsystemen |
| Bardeen | ✅ | Planning van playbooks |
| Diffbot | ❌ | API-first, externe orkestratie |
| ScrapingBee | ❌ | Alleen API |
| Instant Data Scraper | ❌ | Handmatige browsertool |
| ParseHub | ✅ (betaald) | Premiumfunctie |
Vergelijking van developer-API’s
| Tool | Gelijktijdigheid of rate-indicatie | Prijsmodel |
|---|---|---|
| Thunderbit | 2 → 50 gelijktijdig | Creditgebaseerd |
| Firecrawl | 2 → 100 gelijktijdig | Creditgebaseerd |
| Apify | Afhankelijk van plan | Compute units |
| Gumloop | Workflow-gelijktijdigheid beperkt per plan | Creditgebaseerd |
| Diffbot | 5 calls/min → 25 calls/sec | Creditgebaseerd |
| ScrapingBee | 10 → 200 gelijktijdig | API-creditgebaseerd |
| Bright Data | Browser API adverteert onbeperkte gelijktijdige requests | GB-gebaseerd |
Als je use case technischer is en je wilt weten hoeveel infrastructuur je zelf wilt beheren, is deze Firecrawl-walkthrough een nuttige, op uitvoering gerichte aanvulling op de productvergelijkingen hierboven.
Hoe je de juiste AI-webscraper kiest
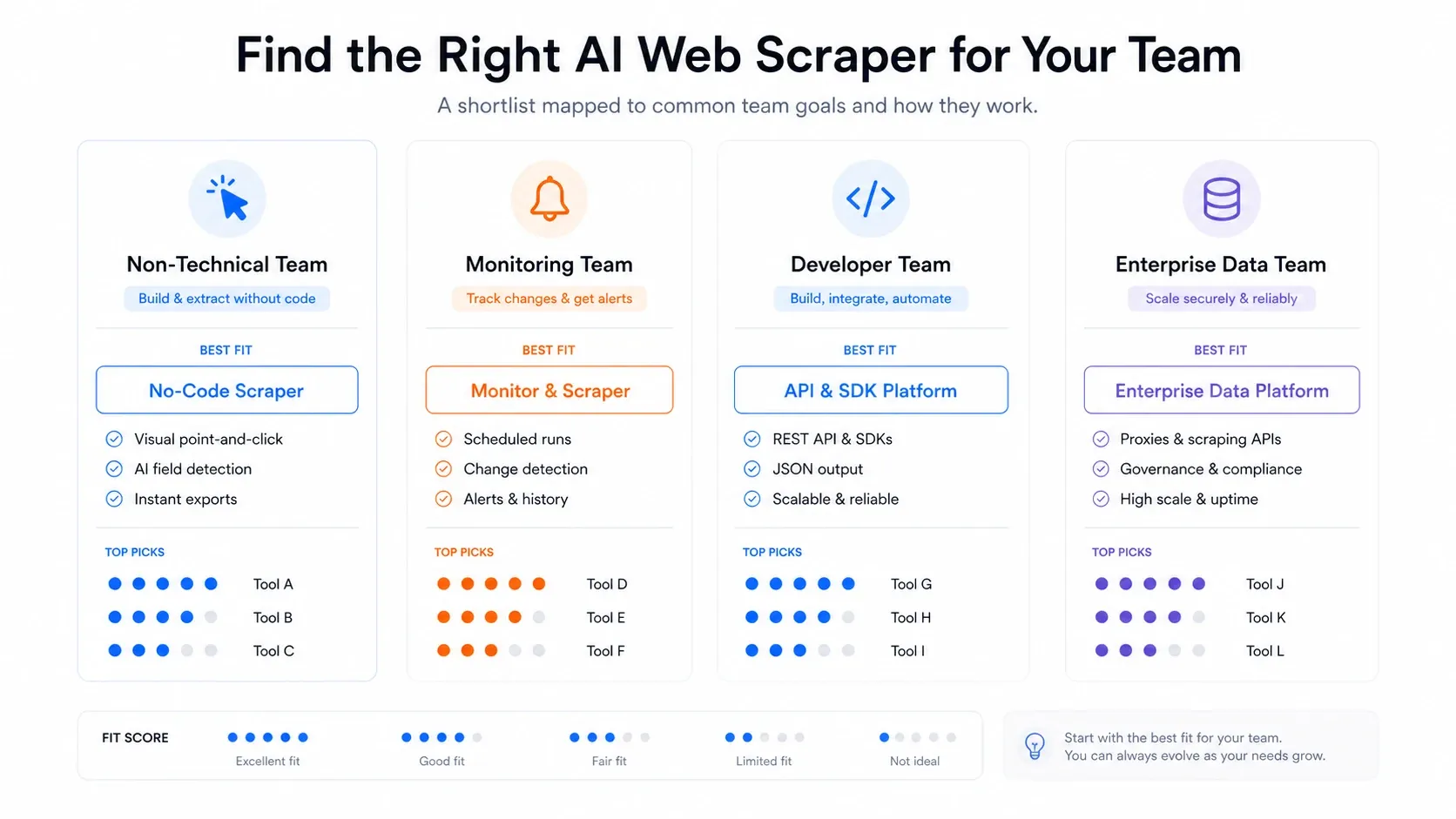
Na het testen van alle 12 tools zou ik het zo aanpakken:
- Niet-technisch team dat snel data nodig heeft: Begin met Thunderbit. De workflow in twee klikken, gratis exports en de browser-cloudschakelaar dekken de meeste zakelijke scrapingbehoeften zonder engineering-ondersteuning.
- Doorlopende monitoring en alerts nodig: Browse AI is hier speciaal voor gemaakt. Het is niet de sterkste eenmalige extractor, maar wijzigingsdetectie is een eersteklas functie.
- Ontwikkelaar die een LLM-pijplijn bouwt: Firecrawl voor Markdown- of JSON-extractie, of Diffbot voor voorgetrainde gestructureerde extractie. Combineer een van beide met ScrapingBee of Bright Data als je serieuze anti-botafhandeling nodig hebt in de fetchlaag.
- Marktplaats met kant-en-klare scrapers nodig: Apify heeft het grootste actor-ecosysteem. Houd er wel rekening mee dat onderhoud nodig is wanneer actors breken.
- Enterprise-schaal, zwaar beveiligde targets: Bright Data. Niets anders komt in de buurt van de proxy-infrastructuur, maar budget en technische bezetting moeten dan ook passend zijn.
- Scraping als onderdeel van grotere automatisering: Gumloop of Bardeen, afhankelijk van of je workflows automatiseert of browsergebaseerde GTM-taken.
- Gewoon een snelle gratis scrape nodig: Instant Data Scraper. Geen setup, geen kosten, geen complexiteit, maar ook geen planning, geen AI en geen cloud.
- Complexe interactieve sites met dropdowns en AJAX: ParseHub doet dit nog steeds beter dan de meeste extensies, al is de onderhoudslast reëel.
Conclusie
De markt voor AI-webscrapers in 2026 zit vol tools die in demo’s indrukwekkend lijken en in productie teleurstellen. De kloof tussen "werkt in een marketing-screenshot" en "werkt om 3 uur ’s nachts volgens schema op een beveiligde e-commercesite" is waar de meeste kopers tijd en geld verliezen.
De belangrijkste conclusie uit de evaluatie van alle 12 tools is simpel: de fetchlaag blijft nog steeds het moeilijke deel. AI blinkt uit in extractie en naverwerking, maar vervangt geen proxy-infrastructuur, anti-botafhandeling of sessiebeheer. De beste tools lossen beide lagen op, zoals Thunderbit en Bright Data, of zijn eerlijk over welke laag ze afdekken, zoals Firecrawl voor extractie en ScrapingBee voor fetching.
Als je wilt zien hoe een productieklare AI-webscraper eruitziet zonder code te schrijven, . De gratis tier is genoeg om de volledige workflow op echte pagina’s te testen. Als je behoeften meer developergericht zijn, combineer dan een extractie-API met een dedicated fetching-service en bespaar jezelf de frustratie van verwachten dat één tool alles doet.
FAQ’s
Waarom falen de meeste AI-webscrapers op echte websites terwijl ze in demo’s prima werken?
Demo’s laten meestal extractie zien op schone, onbeveiligde pagina’s. Echte sites voegen Cloudflare-beveiliging, dynamische JavaScript-rendering, paginering, inlogvereisten en vaak veranderende lay-outs toe. De meeste tools doen het parsen en extraheren goed, maar missen robuuste infrastructuur voor de fetchlaag.
Wat is het verschil tussen cloud scraping en browser scraping, en wanneer gebruik ik welke?
Cloud scraping gebruikt externe servers om pagina’s op te halen, wat sneller, parallel en schaalbaar is. Browser scraping draait in je eigen browsersessie en is beter voor geauthenticeerde sites of sites met agressieve botdetectie. Thunderbit is een van de weinige tools die beide modi in dezelfde interface aanbiedt.
Kan ik een AI-webscraper gebruiken voor terugkerende taken zoals prijsmonitoring?
Ja, maar alleen als de tool geplande scraping ondersteunt. Thunderbit, Octoparse, Browse AI, Apify, Gumloop, Bardeen en ParseHub op betaalde plannen bieden allemaal planning.
Welke AI-webscraper is het beste als ik niet kan coderen?
Thunderbit biedt voor niet-technische gebruikers de snelste weg naar bruikbare data. Instant Data Scraper is volledig gratis maar beperkt tot eenvoudige pagina’s. Browse AI en Octoparse bieden visuele interfaces met meer instellingen. ParseHub is krachtig voor complexe interactieve sites, maar heeft een steilere leercurve.
Hoeveel kost AI-webscraping op productieniveau eigenlijk?
De bandbreedte is groot. Instant Data Scraper is gratis. Thunderbit, Firecrawl en Browse AI bieden gratis instapopties met goedkope betaalde plannen. Middensegment-tools zoals Octoparse, ParseHub en ScrapingBee lopen uiteen van ongeveer $49 tot $189 per maand. Enterprise-oplossingen zoals Bright Data en Diffbot beginnen veel hoger.