

Laat me je meenemen in een herkenbaar verhaal. Een paar jaar terug hielp ik een salesteam met de voorbereiding van een grote campagne. Alles leek tot in de puntjes geregeld: de mails stonden klaar, de aanbiedingen waren scherp en het CRM puilde uit van de leads. Maar zodra de campagne live ging, kwam bijna een derde van onze e-mails retour. Wat bleek? Onze data zat vol slordigheden: tikfouten, lege velden en dubbele contacten. Het team was dagen bezig met het opschonen en we misten flink wat kansen. Toen besefte ik: zelfs kleine slordigheden bij gegevensinvoer kunnen uitgroeien tot flinke bedrijfsproblemen.
Nu, jaren later, zie ik dat bedrijven – groot én klein – nog steeds tegen dezelfde issues aanlopen. Maar er is goed nieuws: we leven in een tijd waarin AI-tools de meeste van deze fouten kunnen opsporen (en zelfs oplossen) voordat ze schade aanrichten. Als medeoprichter van Thunderbit heb ik van dichtbij gezien hoe de juiste technologie gegevensinvoer kan veranderen van een tijdrovende, foutgevoelige klus naar een soepel en betrouwbaar proces. Laten we daarom eens kijken naar de meest voorkomende fouten bij gegevensinvoer, waarom ze ontstaan en hoe AI het verschil maakt voor iedereen die met data werkt.
Waarom nauwkeurige gegevensinvoer onmisbaar is voor elk bedrijf
Wat is data scraping en hoe doe je het in 2025 Get Started Free
Gegevensinvoer is de stille motor achter je bedrijfsvoering. Of je nu in sales, marketing, e-commerce of vastgoed werkt: je beslissingen zijn zo goed als de data waarop je vertrouwt. Eén tikfout of een leeg veld kan je analyses in de war schoppen, klantcontacten mislopen of zelfs voor gedoe met de wet zorgen.
En de impact is niet mals. Volgens Gartner kost slechte datakwaliteit bedrijven gemiddeld $12,9 miljoen per jaar. Op landelijk niveau schat IBM dat slechte data jaarlijks $3 biljoen uit de Amerikaanse economie trekt. En het meest opvallende: slechts 3% van de bedrijfsdata voldoet aan de minimale kwaliteitsnormen.
Als gegevensinvoer misgaat, merk je dat direct: gemiste leads, weggegooid marketingbudget, kans op boetes en slechte beslissingen. Gelukkig zijn er nu AI-tools die deze fouten kunnen onderscheppen voordat ze echt pijn doen.
De meest voorkomende fouten bij gegevensinvoer (en hoe ze ontstaan)
Laten we eerlijk zijn: gegevensinvoer is zelden iemands droombaan. Het is saai, vraagt veel concentratie en wordt vaak afgeraffeld. Dat is vragen om fouten. Dit zijn de missers die ik het vaakst tegenkom (en ja, ik heb ze zelf ook gemaakt):
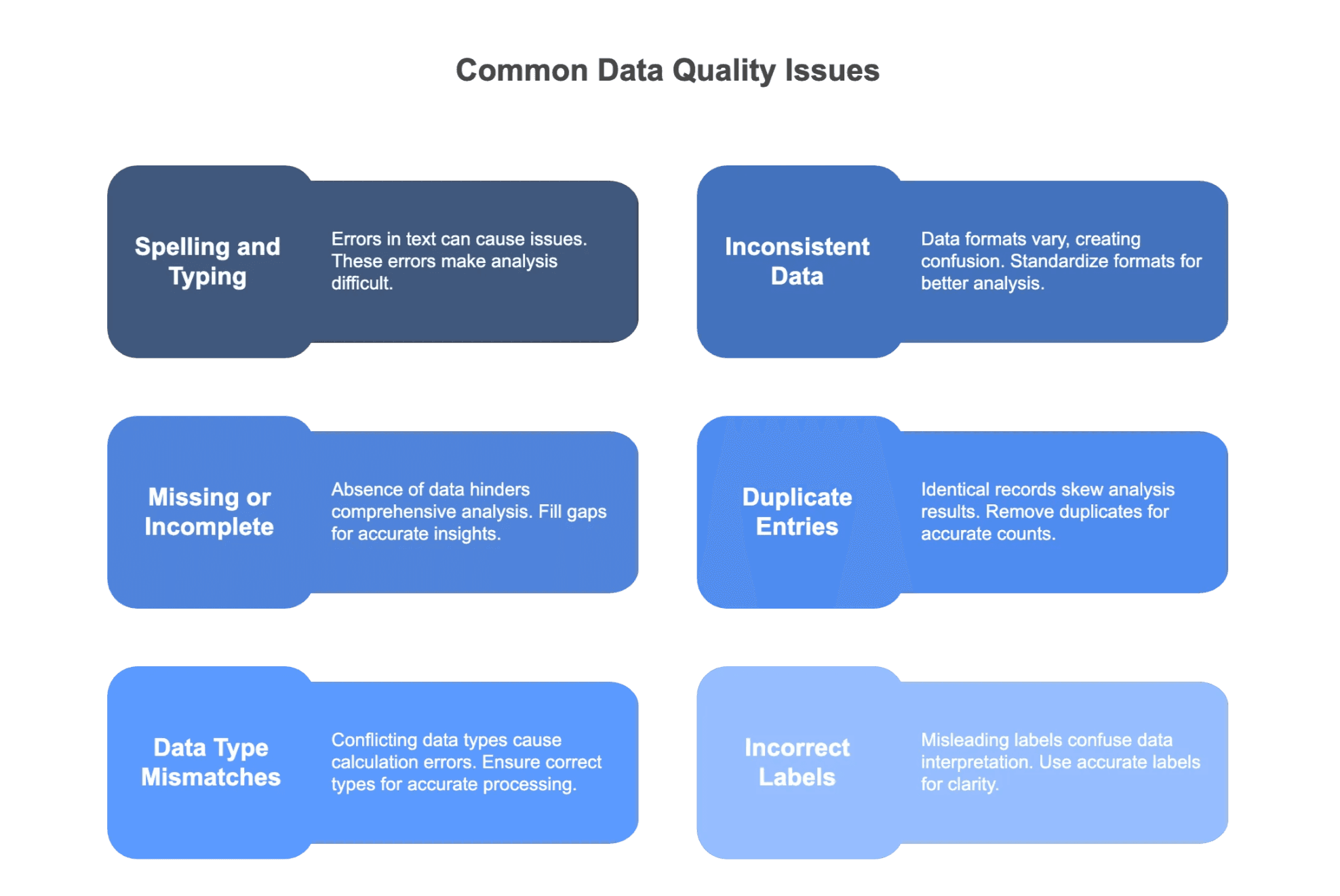
- Spelfouten en typfouten
- Inconsistente dataformaten
- Ontbrekende of onvolledige gegevens
- Dubbele invoer
- Verkeerde gegevenstypen
- Foutieve labels of categorieën
Hoe ontstaan deze fouten? Vaak is het een mix van menselijke factoren (moeheid, afleiding, te weinig uitleg) en gebrekkige processen (vage formulieren, geen controles, data uit verschillende bronnen samenvoegen). Zelfs met digitale tools sluipen deze fouten er nog in – vooral als teams nog steeds handmatig data opschonen en dedupliceren in Excel (iets wat 65% van de bedrijven nog steeds doet).
Laten we elk type fout even onder de loep nemen.
Spelfouten en typfouten
De klassieker. Of het nu gaat om een verkeerd gespelde naam (“Jonh” in plaats van “John”) of een verkeerd getal (“10000” in plaats van “1000”), deze kleine missers kunnen grote gevolgen hebben. In sales betekent een fout in een e-mailadres een gemiste lead. In de financiële sector kan een verkeerd getal miljoenen kosten (vraag maar aan Samsung Securities).
Inconsistente dataformaten
Heb je ooit geprobeerd een lijst met datums te sorteren, terwijl de helft in “DD/MM/JJJJ” staat en de rest in “JJJJ-MM-DD”? Of telefoonnummers die soms als “(123) 456-7890” en soms als “1234567890” zijn ingevoerd? Zulke verschillen zorgen voor vastlopende automatiseringen, onbetrouwbare rapportages en lastige data-integratie.
Ontbrekende of onvolledige gegevens
Lege velden zijn de sluipmoordenaars van je bedrijfsprocessen. Een ontbrekende postcode betekent een pakket dat niet aankomt. Onvolledige klantdata zorgt voor gemiste opvolging. Soms komt het doordat de info niet beschikbaar was, of omdat het systeem het niet verplicht stelde. Hoe dan ook: je proces loopt vast.
Dubbele invoer
Wie heeft er niet ooit “Acme Inc.” en “Acme Incorporated” als twee aparte klanten in het CRM gezien? Dubbelen zorgen voor opgeblazen statistieken, verwarring in het team en verspilling van tijd en geld. In sommige gevallen bestaat 10–20% van de data uit dubbele records.
Verkeerde gegevenstypen
Heb je ooit “ABC” in een telefoonnummer-veld gezien? Of een beoordeling van “999” op een schaal van 1–5? Zulke fouten kunnen systemen laten crashen, analyses verstoren en zelfs tot compliance-issues leiden (stel je voor: $100.000 invullen in plaats van $10.000 bij een leningaanvraag).
Foutieve labels of categorieën
Verkeerd labelen is verraderlijk. Een klant die als “Groothandel” wordt gemarkeerd terwijl het eigenlijk “Retail” is, of een uitgave die aan de verkeerde afdeling wordt toegewezen. Zulke fouten verstoren analyses en kunnen leiden tot dure fouten in de administratie.
Hoe AI het werk rondom gegevensinvoer verandert
Hier wordt het interessant. AI is allang niet meer alleen voor zelfrijdende auto’s of chatbots – het verandert stilletjes ook de wereld van gegevensinvoer. In plaats van te vertrouwen op mensen om elke fout te vinden, kunnen AI-tools nu:
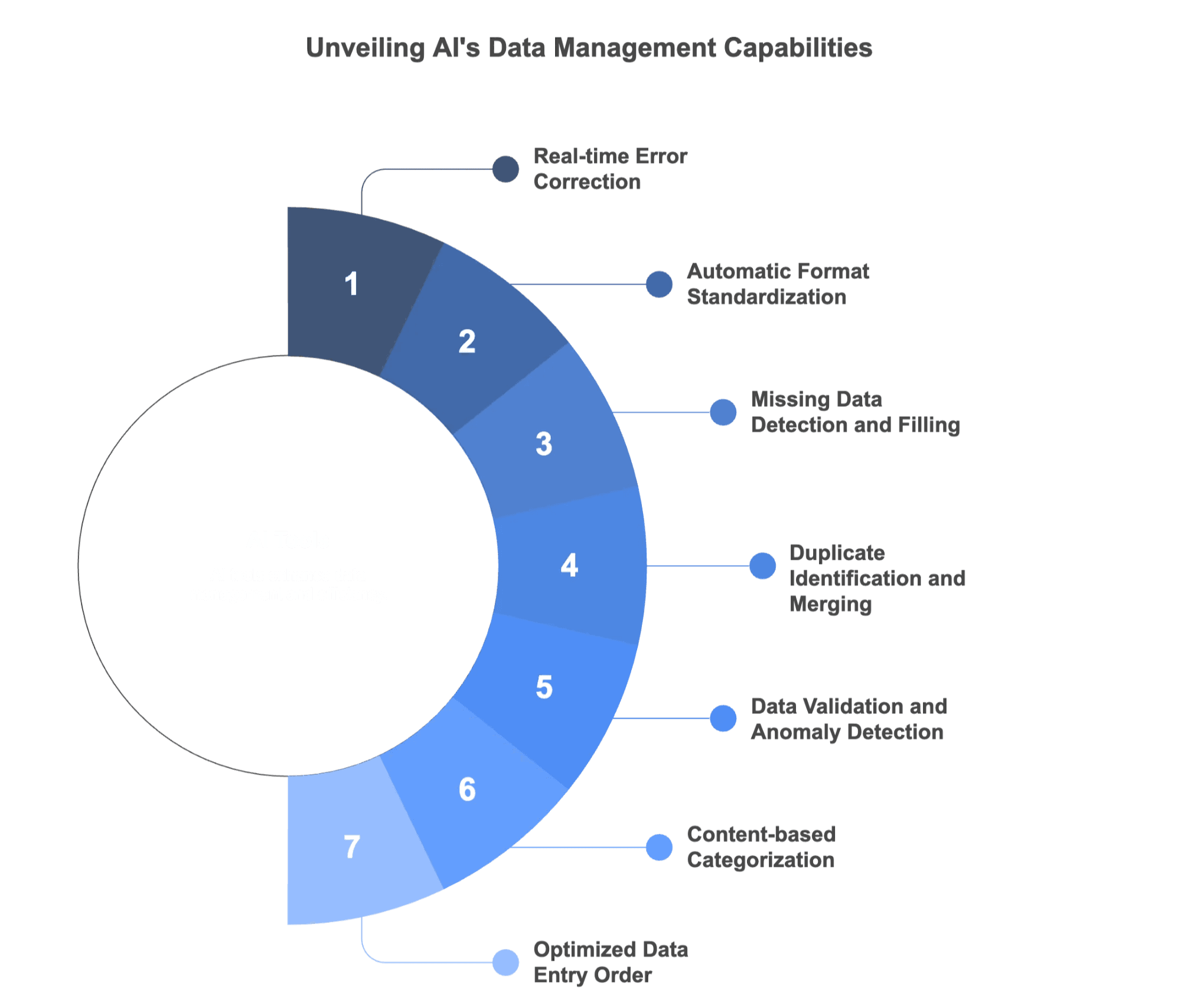
- Typfouten direct signaleren en correcties voorstellen
- Automatisch formaten standaardiseren
- Ontbrekende gegevens opsporen en aanvullen
- Dubbelen herkennen en samenvoegen
- Gegevenstypen controleren en afwijkingen markeren
- Invoer automatisch categoriseren op basis van inhoud
- De volgorde van gegevensinvoer optimaliseren om fouten te voorkomen
Deze verschuiving van handmatig naar AI-ondersteunde gegevensinvoer zorgt ervoor dat teams zich kunnen richten op belangrijker werk – en dat “vervuilde data” tot het verleden behoort.
AI-oplossingen voor elke fout bij gegevensinvoer
Tijd voor de praktijk. Zo pakt AI de meest voorkomende fouten bij gegevensinvoer aan:
AI-gestuurde spellingcontrole en correctie
Moderne AI gebruikt natural language processing (NLP) om typfouten te herkennen – zelfs als een woord technisch gezien “correct” is, maar niet past in de context (denk aan “john Smyth” in plaats van “John Smith”). Deze systemen gaan veel verder dan de klassieke spellingscontrole en leren van veelvoorkomende naamvariaties en zakelijke termen.
Formaatstandaardisatie met AI
AI herkent patronen in je data en kan automatisch alles omzetten naar een uniform formaat. Heb je een kolom met datums in allerlei verschillende notaties? AI zet ze allemaal om naar bijvoorbeeld “JJJJ-MM-DD”. Hetzelfde geldt voor telefoonnummers, adressen en meer. Sommige tools vragen zelfs: “Wil je deze invoer omzetten naar het standaardformaat?”
Ontbrekende gegevens opsporen en aanvullen
Machine learning-modellen kunnen onvolledige records signaleren en zelfs waarschijnlijke waarden voorstellen. Ontbreekt er een postcode? AI kan deze voorspellen op basis van stad en provincie. Soms kan AI zelfs externe databases raadplegen om ontbrekende info aan te vullen (uiteraard alleen met jouw toestemming).
Dubbelen opsporen met AI
Traditionele deduplicatie werkt op exacte overeenkomsten. AI gebruikt echter fuzzy matching en clustering-algoritmen om records te vinden die op elkaar lijken, maar niet identiek zijn (“IBM Corp.” versus “International Business Machines”). Zo houd je één betrouwbare bron van waarheid en voorkom je verwarring.
Gegevenstype-validatie
AI leert hoe “normale” data eruitziet en markeert alles wat daarbuiten valt. Voert iemand “999” in bij een beoordeling van 1–5, of een letter in een numeriek veld? Het systeem vraagt dan om correctie. Ook kan AI velden onderling controleren (bijvoorbeeld: als “Land” Nederland is, verwacht een postcode van vier cijfers).
Automatische categorisatie en labeling
NLP-modellen kunnen invoer automatisch classificeren op basis van de inhoud. Bijvoorbeeld: als een supportticket “account werkt niet, inloggen mislukt” bevat, kan AI het label “Inlogprobleem” toekennen. Dit betekent minder handmatig labelen en meer consistente categorieën.
Gegevensinvoer optimaliseren met AI
AI kan de beste volgorde voor gegevensinvoer voorstellen en formulieren aanpassen op basis van eerdere antwoorden. Kies je bijvoorbeeld “Internationaal”, dan vraagt het formulier om een paspoortnummer in plaats van een burgerservicenummer. Dit voorkomt verwarring en zorgt dat alle verplichte velden worden ingevuld.
Praktische AI-tools voor slimmere gegevensinvoer
Er zijn steeds meer AI-tools die zijn ontwikkeld om uitdagingen bij gegevensinvoer aan te pakken. Dit zijn enkele tools waar ik zelf mee heb gewerkt of die ik heb onderzocht:
Thunderbit: AI-webscraper & data-entry assistent
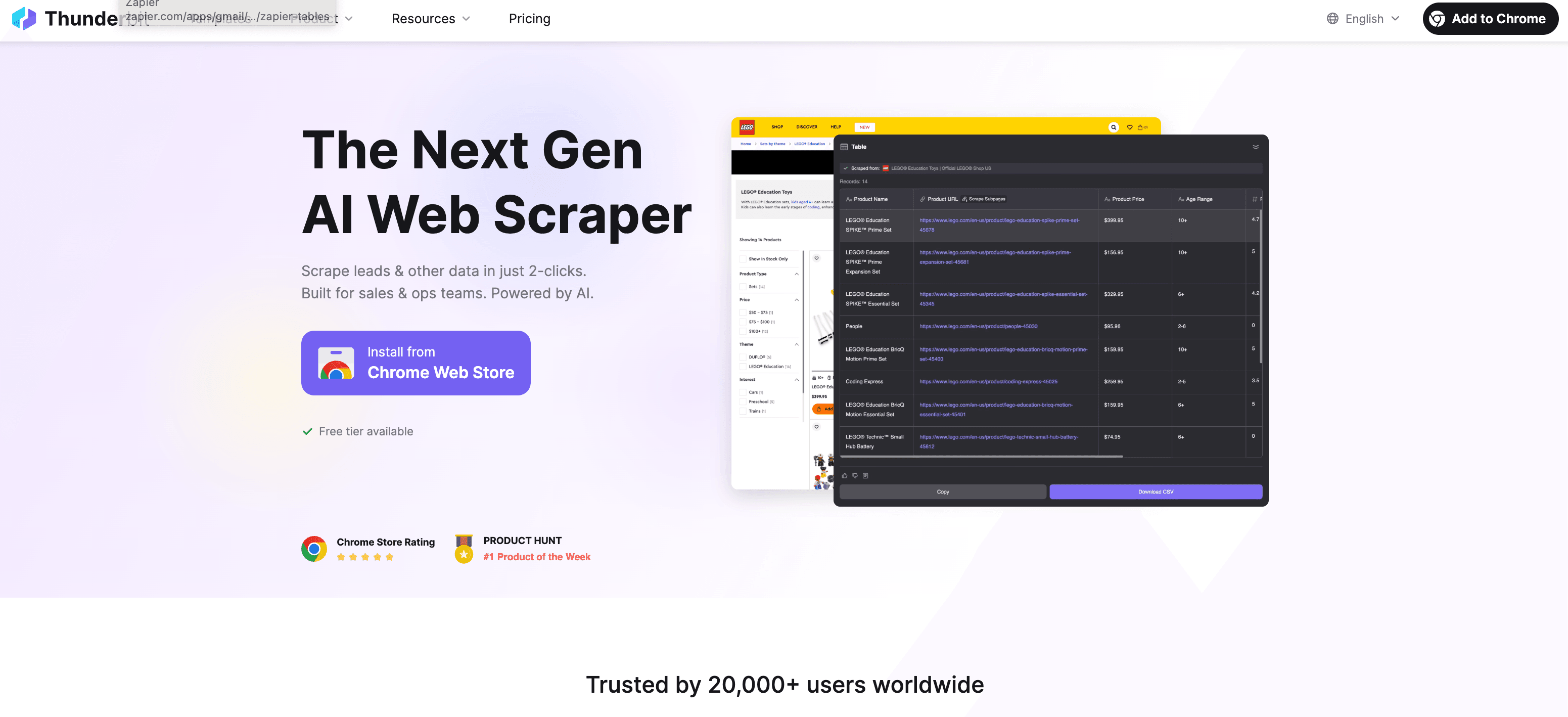
Thunderbit is een AI-gestuurde Chrome-extensie waarmee je gestructureerde data van elke website kunt halen in slechts een paar klikken. De functie “AI Suggest Fields” leest de pagina, adviseert welke velden je het beste kunt scrapen en structureert de data automatisch. Ook subpagina’s en paginering worden meegenomen, ideaal voor salesteams die leadlijsten bouwen, e-commerce teams die prijzen monitoren of onderzoekers die marktdata verzamelen. En ja, het is veel sneller (en nauwkeuriger) dan handmatig kopiëren en plakken. Je kunt het direct proberen via de Thunderbit Chrome Extension Download Page.
Probeer Thunderbit voor AI-gestuurde gegevensinvoer
OpenRefine: Open-source data opschonen
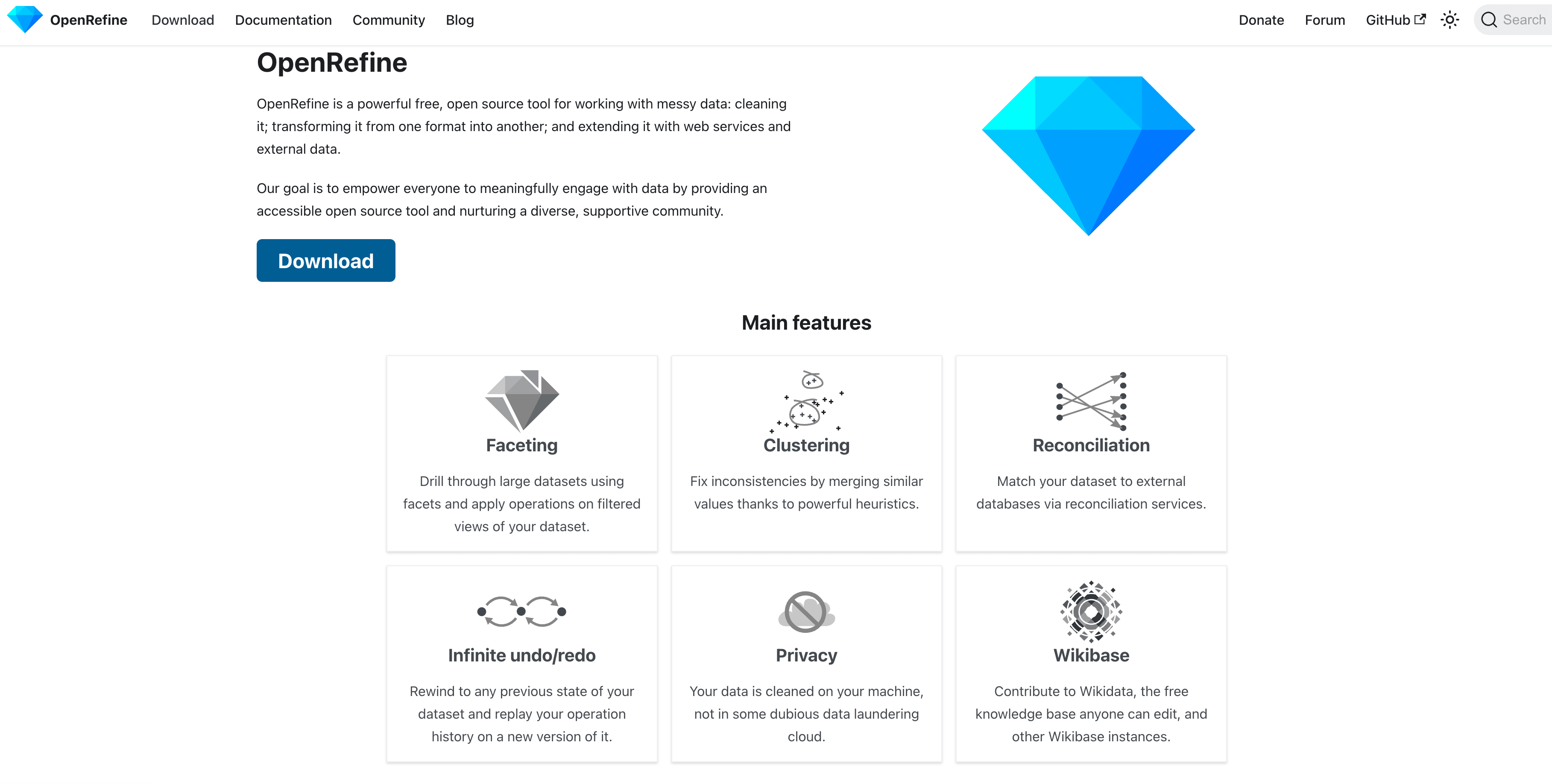
OpenRefine is favoriet bij data-analisten om “rommelige” datasets op te schonen. Het gebruikt clustering-algoritmen om vergelijkbare invoer te groeperen (zoals “Acme Inc.” en “ACME, Inc.”), zodat je eenvoudig dubbelen kunt samenvoegen en formaten kunt standaardiseren. Ideaal voor eenmalige opschoonprojecten en bovendien gratis te gebruiken.
Trifacta (nu onderdeel van Alteryx): AI-gestuurde data-wrangling

Trifacta Pricing gebruikt machine learning om suggesties te doen voor het opschonen van data – zoals het standaardiseren van datums of het extraheren van domeinen uit URL’s. Het is gemaakt voor big data en biedt visuele profielen en samenwerkingsmogelijkheden voor teams die met miljoenen rijen werken.
OCR en slimme documentverwerking
Tools zoals ABBYY FlexiCapture Pricing, Microsoft Form Recognizer Pricing, en Google Document AI Pricing gebruiken AI-gestuurde OCR om gestructureerde data uit gescande documenten, facturen en bonnetjes te halen. Deze platforms kunnen belangrijke velden herkennen, valideren en het aantal handmatige invoerfouten tot wel 80% verminderen.
NLP-gebaseerde data-oplossingen
Platforms zoals IBM Watson NLU Pricing en Amazon Comprehend Pricing gebruiken NLP om tekstuele data te analyseren en structureren. Ze kunnen bijvoorbeeld datums en acties uit ongestructureerde notities halen, supporttickets automatisch labelen of adresformaten standaardiseren.
Best practices voor foutloze gegevensinvoer in het AI-tijdperk
AI is krachtig, maar geen wondermiddel. De beste resultaten bereik je door slimme tools te combineren met slimme processen.
Hier zijn een paar tips die ik in de praktijk heb geleerd:
- Menselijke controle blijft belangrijk: Laat AI mogelijke fouten signaleren, maar laat een mens twijfelgevallen beoordelen – zeker bij kritische data.
- Automatiseer kwaliteitscontroles: Behandel data als software – voer automatische checks uit bij elke import of transformatie.
- Blijf monitoren: Gebruik dashboards om fouten, volledigheid en dubbelen te volgen. Stel AI-gestuurde waarschuwingen in om problemen snel te signaleren.
- Integreer AI in je workflow: Voeg AI-validatie en suggesties direct toe aan je invoerschermen.
- Feedbackloops: Laat gebruikers feedback geven op AI-voorstellen, zodat het systeem steeds slimmer wordt.
- Combineer AI met traditionele controles: Gebruik dubbele invoer of audits voor gevoelige velden, en laat AI de rest doen.
- Maak datakwaliteit een gedeelde verantwoordelijkheid: Zorg dat iedereen zich verantwoordelijk voelt voor schone data, niet alleen de IT-afdeling.
Een cultuur van datakwaliteit opbouwen: wat teams kunnen doen
Technologie is maar de helft van het verhaal. De meest succesvolle organisaties zorgen ervoor dat datakwaliteit een gedeelde prioriteit is. Zo pak je dat aan:
- Draagvlak vanuit het management: Leidinggevenden moeten duidelijke doelen stellen voor datakwaliteit en deze koppelen aan bedrijfsresultaten.
- Opleiding en training: Train medewerkers regelmatig over het belang van goede data en het gebruik van nieuwe tools.
- Duidelijke richtlijnen: Leg standaarden voor gegevensinvoer vast en wijs data stewards aan die de kwaliteit bewaken.
- Open communicatie: Bespreek datakwaliteit in teamoverleggen, deel successen en leerpunten, en moedig feedback aan.
- Waardering en beloning: Zet teams of medewerkers die de datakwaliteit verbeteren in het zonnetje.
- Toegankelijke tools: Zorg dat iedereen de juiste AI-tools en bronnen kan gebruiken.
- Blijf verbeteren: Zie elke fout als een kans om te leren en pas processen aan waar nodig.
Een mooi voorbeeld komt van een productiebedrijf dat zijn Six Sigma-programma uitbreidde naar data. Medewerkers werden getraind in datakwaliteit, fouten werden zichtbaar gemaakt op dashboards en operators kregen AI-validatietools. Het resultaat? Niet alleen schonere data, maar ook snellere productieaanpassingen en meer vertrouwen in analyses door het hele bedrijf.
Belangrijkste inzichten: Slimmere gegevensinvoer met AI
- Fouten bij gegevensinvoer zijn duur en komen vaak voor – van typfouten en dubbelen tot lege velden en verkeerde labels.
- AI-tools veranderen het werk rondom gegevensinvoer, door fouten direct te signaleren, formaten te standaardiseren en zelfs ontbrekende info aan te vullen.
- De beste resultaten bereik je door AI te combineren met slimme processen en een cultuur van kwaliteit – waarbij iedereen, van directie tot nieuwe medewerker, zich verantwoordelijk voelt voor schone data.
Ben je het zat om steeds weer data op te schonen (of lig je wakker van wat er allemaal mis kan gaan in je CRM)? Dan is het tijd om te ontdekken wat AI voor jou kan betekenen. Tools als Thunderbit, OpenRefine en moderne OCR-platforms maken het makkelijker dan ooit om je data accuraat, betrouwbaar en direct bruikbaar te houden.
En onthoud: in de zakenwereld is schone data geen luxe, maar een concurrentievoordeel. Laten we samen “vervuilde data” verleden tijd maken – met slimme tools én goede gewoontes.
Meer weten over AI-gedreven dataworkflows? Bekijk de Thunderbit Blog voor meer tips, handleidingen en praktijkverhalen over hoe AI je werk makkelijker én efficiënter maakt.
Ontdek Thunderbit AI Data Tools
Veelgestelde vragen
1. Wat zijn de meest voorkomende fouten bij gegevensinvoer?
Typfouten, inconsistente formaten, lege velden, dubbelen en verkeerd gelabelde categorieën komen het vaakst voor. Deze problemen verstoren processen, analyses en besluitvorming.
2. Hoe helpt AI om de nauwkeurigheid van data te verbeteren?
AI-tools signaleren typfouten, doen correctievoorstellen, standaardiseren formaten, herkennen dubbelen en vullen lege velden automatisch aan – waardoor menselijke fouten worden geminimaliseerd.
3. Kan AI handmatige gegevensinvoer volledig vervangen?
Niet helemaal. AI vermindert fouten en versnelt het werk, maar menselijke controle blijft nodig voor uitzonderingen en validatie.
4. Welke bedrijven profiteren het meest van AI-tools voor gegevensinvoer?
Sales-, marketing-, e-commerce-, vastgoed- en operationele teams – vooral als ze werken met CRM’s, leadlijsten of grote hoeveelheden webdata.
Meer lezen
1. Enterprises Whose Bad Data Cost Them Millions: Lessons from Samsung & Uber
Praktijkvoorbeelden van dure datafouten – en wat bedrijven daarvan leerden.
2. Bad Data: A $3T Per Year Problem (VentureBeat)
Een blik op de impact van slechte data op de economie en hoe AI kan helpen.
3. Poor Data Quality Is a Full-Blown Crisis (Eckerson Group)
Interessant rapport uit 2024 over hoe bedrijven nog steeds handmatig rommelige data moeten opschonen.
4. Thunderbit Blog: AI Tools for Sales, Ops & Web Data
Handleidingen, producttips en praktijkvoorbeelden over hoe AI handmatige gegevensinvoer overbodig maakt.
Probeer AI Webscraper Get Started Free




