Samenvatting voor executives
We hebben het robots.txt-bestand opgehaald van elk domein in de Tranco top 10.000-lijst van ’s werelds websites met het hoogste verkeer. Vervolgens hebben we elk bestand geparseerd met een parser die RFC 9309 volgt, het bestand geclassificeerd op basis van het AI-botbeleid dat de site al dan niet heeft ingevoerd, en geteld hoeveel van ’s werelds meest bezochte sites daadwerkelijk proberen ChatGPT, Claude, Perplexity, Gemini, Common Crawl, Bytespider, Apple Intelligence en de andere crawlers te blokkeren die in 2026 grote taalmodellen trainen en ondersteunen.
De belangrijkste cijfers, op een steekproef van 7.248 sites waarvan we robots.txt netjes konden lezen:
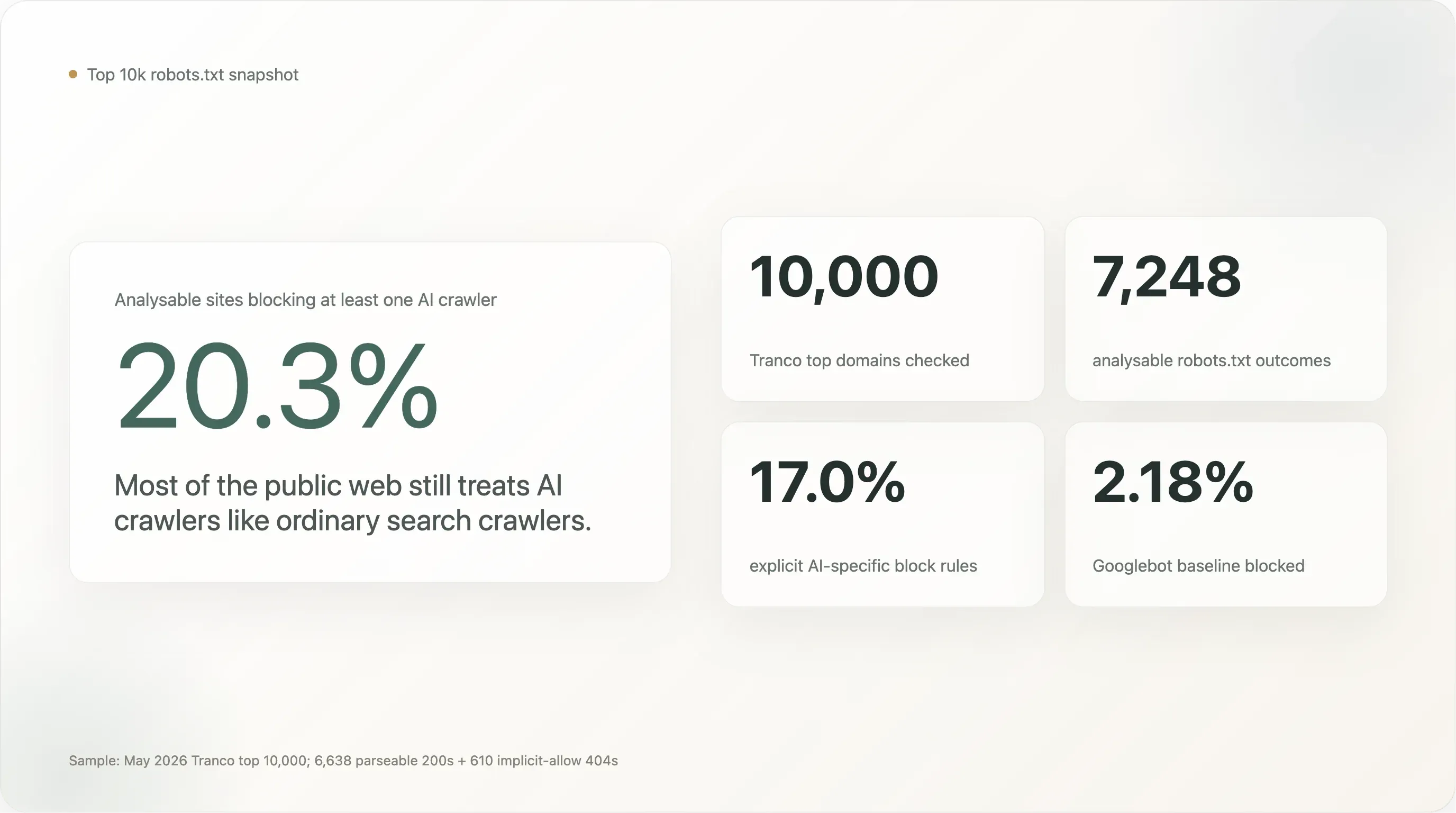
20,3% van de top 10.000 sites ter wereld blokkeert minstens één AI-crawler. 17,0% heeft bewust een expliciete AI-specifieke regel geschreven. De overige 80% laat AI-crawlers net zo welkom zijn als Googlebot.
Zes bevindingen die het verhaal kantelen:
- Nieuwsorganisaties blokkeren in 47% van de gevallen — het hoogste percentage van alle sectoren. Duitse nieuwsmedia leiden met 88%, Franse met 80%, Russische met 0%. De juridische context, niet technologie of sector-economie, is de belangrijkste drijfveer.
CCBot(Common Crawl) is de meest geblokkeerde bot met 16,3% — vóórGPTBot(15,8%) enBytespider(14,9%). Uitgevers richten zich op het trainingscorpus, niet op het modelmerk. De meest gebruikte selectieve regel is "blokkeerCCBot, staGooglebottoe" (14,1% van de sites).- Frankrijk loopt voorop met 50,6% AI-blokkering op
.fr-sites; de EU-cluster ligt 16 punten boven het wereldwijde basisniveau. 275robots.txt-bestanden verwijzen expliciet naar EU-richtlijn 2019/790. Artikel 4 is de enige juridische context die zichtbaar de cijfers beweegt. - 17,8% schreef eigen AI-regels; 4,5% gebruikt Cloudflare’s vendorsjabloon; 75,7% zegt niets. Grote sites schrijven zelf; de lange staart gebruikt de schakelaar. The Atlantic en
cloudflare.comzelf staan op de Cloudflare Managed-lijst. - 108 sites staan
GPTBotexpliciet toe — WordPress.org, Kaspersky, Norton, Avast, Sophos, The Verge, The Atlantic, NBA.com, The Sun, Branch.io. Security en ontwikkeltools zijn oververtegenwoordigd. - AI-beleid wordt niet strenger aan de kop van de curve. Top 100, 101–1000, 1001–5000 en 5001–10000 zitten allemaal tussen 19% en 23%. Het headline-percentage is een eigenschap van het openbare web in 2026, niet van de grootte van een individuele site.
Het verhaal gaat niet langer over de vraag of het web "terugslaat." Het gaat over welke sectoren, welke landen, welke juridische kaders en welke AI-vendors het doelwit zijn van actief beleid — en welke niet.
I. Achtergrond: hoe robots.txt een AI-beleidsdocument werd
Drie krachten hebben sinds OpenAI GPTBot in augustus 2023 uitbracht de betekenis van robots.txt veranderd.
AI-vendors werden talrijker. Google’s Google-Extended, Anthropic’s ClaudeBot, ByteDance’s Bytespider, Apple’s Applebot-Extended, Amazon’s Amazonbot, Meta’s Meta-ExternalAgent volgden allemaal. De bestaande CCBot van Common Crawl werd het blokkeerdoel met de grootste impact, omdat het archief de voedingsbron is voor de meeste open-weight modellen. Ook niet-vendor bots doken op: AI2Bot, cohere-ai, PerplexityBot, YouBot, DuckAssistBot, Diffbot, Omgili. Een volledige blokkeerlijst voor 2026 telt ongeveer 25 namen.
Artikel 4 van de EU-auteursrechtrichtlijn 2019/790 creëerde een wettelijke uitzondering voor tekst- en datamining die niet van toepassing is als de rechthebbende zijn rechten “uitdrukkelijk heeft voorbehouden” op een “machineleesbare” manier. In heel 2024–2025 zijn EU-uitgevers en hun juristen robots.txt gaan gebruiken als de standaardmanier om dat voorbehoud te uiten. Onze dataset laat zien dat 275 sites Richtlijn 2019/790 expliciet noemen en 87 “TDM” vermelden — vooral op Europese nieuwssites, waar het als een juridische inleiding van 4–8 regels staat.
Cloudflare productiseerde de schakelaar. In 2024–2025 lanceerde Cloudflare een dashboard voor “AI Audit”, een schakelaar “Block AI Bots”, en een Managed robots.txt-sjabloon met de taal Content-Signal: search=yes,ai-train=no plus standaardtekst over EU 2019/790. In mei 2026 draait dat sjabloon op 4,5% van de parseerbare top 10k. Cloudflare’s roadmap bespreekt openbaar om de schakelaar standaard aan te zetten voor nieuwe accounts — wat de wereldwijde blokkeergrens met 5–8 punten zou verschuiven zonder dat een individuele uitgever een beslissing neemt.
robots.txt is in 2026 niet langer het kleurloze configuratiebestand dat het in 2022 was. Het is een mechanisme om auteursrechten voor te behouden, met verdragssteun in de EU, een door vendors vormgegeven beleidsdocument in de lange staart, en de frontlinie van een langzaam onderhandelingsproces tussen de mensen die websites beheren en de mensen die modellen trainen.
II. Methodologie
We hebben geprobeerd dit zo saai en reproduceerbaar mogelijk te maken. De volledige pipeline (Python-scripts, geparste CSV’s, ruwe robots.txt-archieven, grafieken) is samen met dit rapport gepubliceerd.
Steekproef
We zijn begonnen met de Tranco-lijst van mei 2026, gedownload als top-1m.csv.zip, en hebben de eerste 10.000 rijen geselecteerd. Tranco aggregeert vier upstream-rankings (Cisco Umbrella, Majestic, Farsight en Cloudflare Radar), filtert op stabiliteit over een periode van 30 dagen en verwijdert duidelijke crawler/CDN-ruis. De lijst die daaruit komt, is het dichtst bij een canonieke “wereldwijde top-10k voor webverkeer” dat publiek beschikbaar is, en is de standaardsteekproef voor academisch webonderzoek (gebruikt in 600+ peer-reviewed papers sinds KU Leuven het in 2018 lanceerde).
De lijst bevat een mix van (a) primaire websites die mensen bezoeken, (b) infrastructuur-/API-/DNS-/CDN-apexdomeinen die geen / bedienen, en (c) domeinen die intern door grote platforms worden gebruikt (bijv. gvt1.com, apple-dns.net, googleusercontent.com). In plaats van deze vooraf weg te filteren, hebben we ze allemaal behouden en in de analysetlaag als categorie infrastructure gelabeld. Ze vallen vanzelf weg wanneer we ons beperken tot “sites die een parseerbaar robots.txt teruggaven.”
Ophalen
Voor elk van de 10.000 domeinen hebben we asynchroon een GET /robots.txt via HTTPS uitgevoerd, met een fallback naar HTTP, redirects tot vier sprongen gevolgd, een totale timeout van 12 seconden, een bodemplafond van 500 KB, en een echte browser User-Agent-string met Accept-Language: en-US. De gelijktijdigheid werd begrensd op 80 verzoeken tegelijk. De taak liep vanaf één residentieel IP in San Francisco.
De fetch-uitkomst:
| Status | Aantal | Interpretatie |
|---|---|---|
200 OK | 6.638 | robots.txt-inhoud ontvangen en te parsen. |
404 Not Found | 610 | Er bestaat geen robots.txt. RFC 9309 definieert dit als impliciet "alles toestaan." |
403 Forbidden | 563 | De origin weigert actief robots.txt-verzoeken. Uit de analyse verwijderd. |
429 Too Many Requests | 7 | Bij deze rangklasse vrijwel geen throttling op CDN-niveau. |
fetch_failed (TLS / DNS / TCP-fout) | 2.065 | Vooral CDN-apexpunten (akamai.net, cloudfront.net, fastly.net, gtld-servers.net, apple-dns.net) die geen webserver op / draaien. Niet "geblokkeerd" — er is gewoon geen robots.txt om te serveren. |
| Overige 4xx/5xx | 117 | Gemengd — serverfouten, geofencing, ongeldige antwoorden. |
Hiermee komen we uit op 7.248 sites in de analyseerbare steekproef (6.638 200 + 610 404). De 2.065 fetch_failed zijn echte domeinen, maar het zijn CDN/DNS-apexpunten, geen sites die mensen bezoeken, en ze als een “AI-beleid” behandelen heeft geen zin. Ze staan in de dataset als een aparte toegankelijkheidsstatistiek.
Parsing
Elke 200-body is geparset met protego, een Python-implementatie van RFC 9309 die in productie door Scrapy wordt gebruikt. Voor elk (site, bot)-paar hebben we drie dingen berekend:
can_fetch_root— of de bot/mag ophalen, met de groeps-/recordssemantiek van de standaard, prioriteit voor de langste overeenkomst, en de override vanUser-agent: *door een specifieke bot-blokkade wanneer beide bestaan.has_specific_rule— of het bestand eenUser-agent:-regel bevat die deze exacte bot noemt (hoofdletterongevoelig).disallow_count— hoeveelDisallow:-instructies er in het overeenkomende blok staan, gebruikt om volledige sitebrede verboden te onderscheiden van padbeperkingen.
Die combinatie is belangrijk, omdat een top-line “blokkeerpercentage” twee totaal verschillende fenomenen verhult: merken die bewust User-agent: GPTBot \n Disallow: / schreven omdat ze terug wilden duwen, en merken waarvan een generieke User-agent: * \n Disallow: /-blokkade (jaren geleden opgezet voor staging of onderhoud) toevallig ook elke AI-bot verbiedt die nog niet bestond toen de regel werd geschreven. In dit rapport omvat het cijfer “any AI block” beide soorten; het cijfer “explicit AI block” is de bewuste subset.
Bots binnen scope
We volgden 25 bots, gegroepeerd in drie categorieën:
- AI-trainingscrawlers (16):
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Meta-ExternalAgent,Bytespider,Applebot-Extended,Diffbot,Amazonbot,ImagesiftBot,FacebookBot,cohere-ai,AI2Bot,Omgili,Omgilibot. - AI-inferentie / live retrieval bots (7):
PerplexityBot,Perplexity-User,ChatGPT-User,OAI-SearchBot,ClaudeBot(dat zowel training als inferentie bedient),YouBot,DuckAssistBot. - Zoekbasis (6):
Googlebot,Bingbot,DuckDuckBot,Slurp(Yahoo),Baiduspider,YandexBot.
Een paar bots zitten op de grens tussen training en inferentie. ClaudeBot is de opvallendste — Anthropic heeft de oudere anthropic-ai-UA in 2024 uitgefaseerd en gebruikt nu ClaudeBot voor zowel training als live retrieval, dus een regel Disallow: ClaudeBot betekent niet langer netjes “blokkeer training maar behoud zichtbaarheid.” We hebben de toewijzing laten staan en het gevolg later benoemd.
Sectorclassificatie
We hebben elk domein geclassificeerd in 16 sectorcategorieën (news, social, streaming, ecommerce, search, finance, infrastructure, saas, academia, dev, gov, adult, gambling, travel, telecom, unknown) met een gelaagde aanpak:
- Bekende-domeinwoordenboek — een handmatig samengestelde map van ~500 drukbezochte domeinen naar sectoren.
- TLD-/suffixpatronen —
.gov→gov,.eduen.ac.*→academia, herkende CDN-suffixen →infrastructure. - Trefwoorden in domeinnamen — news, post, shop, bank, porn, casino enz. als fallbacksignalen.
- Homepage-scrape — voor sites die de eerste drie lagen niet konden classificeren en die een
robots.txt200teruggaven, hebben we de HTML van de homepage opgehaald,<title>,<meta name="description">,<meta property="og:type">geëxtraheerd, en een keyword scoring gedraaid tegen categorie-signalen in de stijl van taalmodellen.
Dit leverde 3.407 sites (34%) op met een zekere sectorlabeling en 6.593 sites die unknown bleven. De unknown-bucket wordt gedomineerd door niet-Engelse regionale portalen, corporate .com-merkensites die niet in één categorie passen, en traditionele uitgevers in kleinere taalmarkten waarvoor we geen woordenboekinvoer hadden. Waar dit rapport een sectoraal percentage noemt, is de noemer de geclassificeerde steekproef voor die sector, niet de volledige 10.000.
III. Bevindingen
Bevinding 1 — Eén op de vijf sites met veel verkeer blokkeert minstens één AI-bot
Over de 7.248 analyseerbare sites blokkeren 1.472 (20,31%) minstens één AI-bot. 1.230 (16,97%) hebben een bewuste AI-specifieke regel. De Googlebot-baseline is 2,18% (158 sites — de meeste blokkeren ofwel alles als standaard voor onderhoud, of zijn in drie gevallen zoekmachines die concurrenten blokkeren).
De headline van 20% is 9× de Googlebot-baseline. Dat is een echt signaal — sites met veel verkeer blokkeren veel vaker een AI-crawler dan een zoekcrawler — maar het is ook een stuk lager dan het “AI-blokkeren wordt universeel” narratief dat sinds 2024 in de pers rondgaat. Zelfs op de 10.000 meest bezochte sites van het web blijft de grote meerderheid stil over AI.
Het verschil tussen “any AI block” (20,3%) en “explicit AI block” (17,0%) is in absolute zin klein, maar conceptueel belangrijk. Het verschil van 3,3 punten is het aandeel sites dat AI-bots alleen blokkeert omdat hun bestaande User-agent: * \n Disallow: /-regel alles vangt wat langskomt, inclusief bots die niet bestonden toen de regel werd geschreven. Het cijfer 17,0% geeft een schoner beeld van “hoeveel van ’s werelds grootste websites een AI-specifieke beslissing hebben genomen.”
Afgezet tegen eerdere literatuur:
| Bron | Datum | Steekproef | Blokkeerpercentage |
|---|---|---|---|
| Originality.ai | mrt. 2025 | 1.000 populairste nieuwsbronnen (Engels) | 35,7% blokkeert GPTBot |
| Palewire | aug. 2024 | 1.500 nieuwsorganisaties | 36,0% enige AI-crawler |
| Reuters Institute | voorjaar 2025 | 50 toonaangevende nieuwsmerken, 10 landen | 78% enige AI-crawler |
| WIRED / NYT | eind 2023 | Top 50 Amerikaanse nieuwsbronnen | 26% blokkeert GPTBot |
| Dit rapport (Thunderbit) | mei 2026 | Tranco top 10.000 (alle sectoren) | 20,3% / 17,0% expliciet |
Onze 17,0% expliciet is lager dan elke nieuws-only studie, omdat tweederde van onze steekproef geen nieuws is. Beperkt tot de 650 nieuwssites komen we op 47% — binnen dezelfde band als de eerdere studies, zodra je de samenstelling van de steekproef meeneemt. Het structurele beeld blijft hetzelfde: de nieuwscohort blokkeert AI tegen 3–4× het tempo van de rest van het web.
Bevinding 2 — Diep in de sectoren: een spreiding van 12× van nieuws naar telecom
De meest geciteerde bevinding in twee jaar “AI scraping”-verslaggeving is het 80% van de nieuwsmedia blokkeert GPTBot-cijfer van Originality.ai en Palewire. Onze uitsnede levert een kleiner maar nog steeds onderscheidend cijfer op: 47,2% van de nieuws-sites in de top 10.000 blokkeert minstens één AI-bot, en 45,2% schrijft een expliciete AI-regel.
Maar “nieuws versus alles anders” is te grof. De volledige uitsplitsing (sectoren met n ≥ 10 in de steekproef) vertelt een veel rijker verhaal:
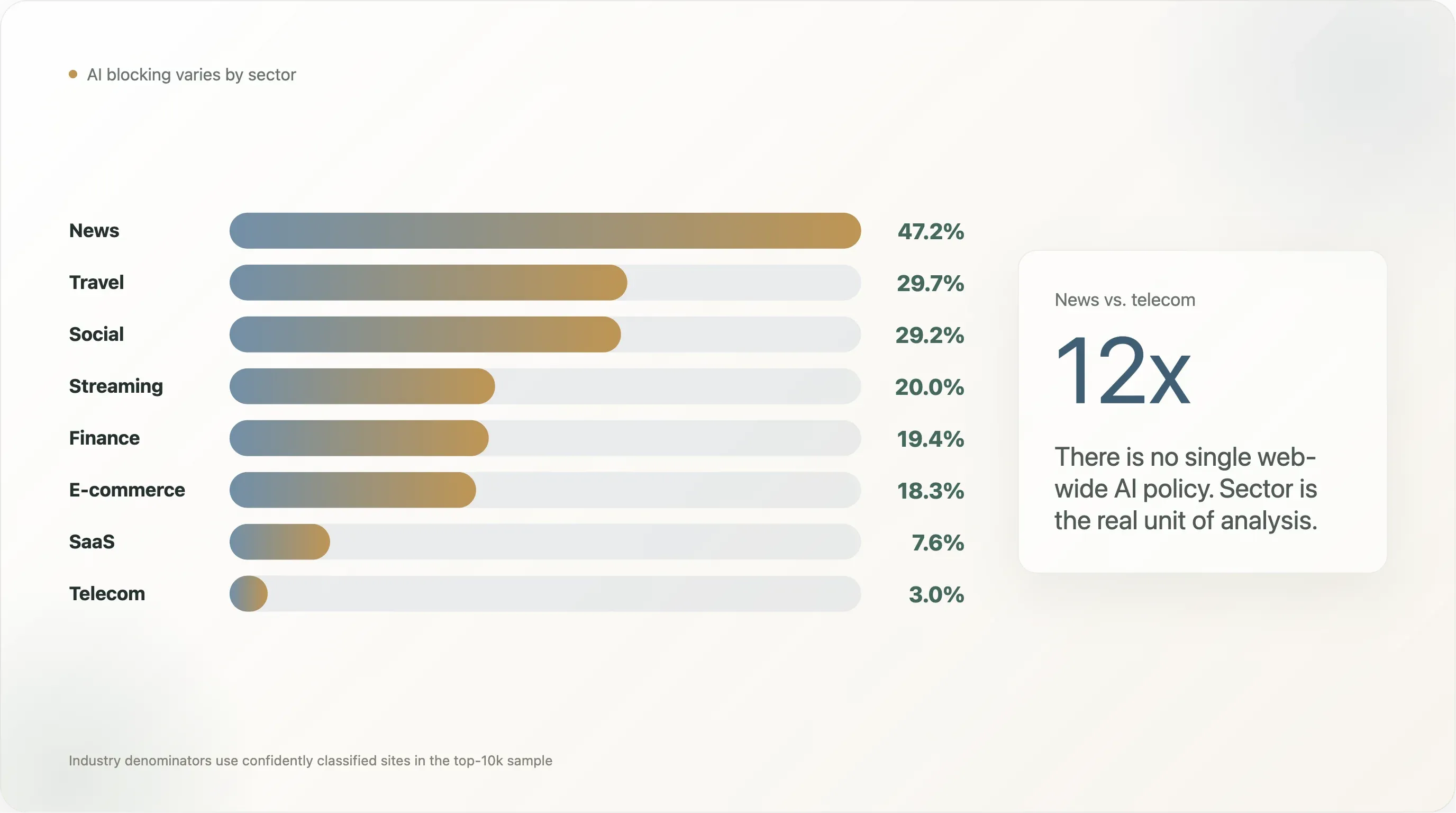
| Sector | n | Any AI block | Expliciet | Googlebot geblokkeerd | Eigen regels | Cloudflare Managed | Stil |
|---|---|---|---|---|---|---|---|
| Nieuws | 650 | 47,2% | 45,2% | 1,5% | 46,9% | 1,5% | 48,5% |
| Reizen | 64 | 29,7% | 29,7% | 0,0% | 35,9% | 3,1% | 54,7% |
| Sociaal | 65 | 29,2% | 23,1% | 4,6% | 23,1% | 6,2% | 66,2% |
| Streaming | 440 | 20,0% | 17,7% | 0,7% | 16,8% | 3,6% | 75,5% |
| Finance | 129 | 19,4% | 12,4% | 0,8% | 14,7% | 2,3% | 75,2% |
| E-commerce | 224 | 18,3% | 17,4% | 0,4% | 24,1% | 1,3% | 66,1% |
| Adult | 254 | 17,3% | 14,6% | 0,4% | 10,2% | 7,9% | 79,5% |
| Search | 12 | 16,7% | 0,0% | 0,0% | 0,0% | 0,0% | 100,0% |
| Academia | 268 | 14,6% | 13,8% | 0,4% | 13,4% | 3,4% | 77,2% |
| Gambling | 100 | 14,0% | 13,0% | 0,0% | 18,0% | 4,0% | 77,0% |
| Ontwikkeltools | 129 | 10,1% | 7,8% | 0,0% | 8,5% | 5,4% | 77,5% |
| SaaS | 369 | 7,6% | 6,2% | 0,3% | 9,5% | 0,8% | 87,5% |
| Overheid | 172 | 5,2% | 3,5% | 0,0% | 4,1% | 0,6% | 83,1% |
| Infrastructuur | 47 | 4,3% | 0,0% | 0,0% | 4,3% | 2,1% | 72,3% |
| Telecom | 33 | 3,0% | 3,0% | 0,0% | 12,1% | 0,0% | 78,8% |
De spreiding van 12× tussen nieuws en telecom is precies waarom “het AI-beleid van het web” de verkeerde analyseeenheid is. Er is niet één getal; er zijn sectorspecifieke getallen die een orde van grootte uit elkaar lopen. Hieronder lopen we de vier meest onderscheidende bevindingen door.
Nieuws: 47% blokkade, 47% DIY. Nieuws is de cohort die het draaiboek schreef. Cloudflare Managed komt in nieuws slechts op 1,5% uit — deze uitgevers besteden de regel niet uit. De tekst is opvallend rijk: de NYT opent met een juridische inleiding van 14 regels die verwijst naar “Art. 4 of the EU Directive”; de BBC met “Please use our site like a human, not a robot... TL;DR: Browse, read, watch, enjoy — like a human.”; The Sun met “The Sun does not permit the unlicensed use of our content for large language models.” Dit is robots.txt als beleidsverklaring, niet als configuratie.
Reizen op 30% — de verrassing. Booking, Expedia, TripAdvisor, Kayak en de grote luchtvaartmaatschappijen blokkeren tegen ongeveer tweederde van het nieuwspercentage. Het selectieve patroon is consistent: de gemiddelde reiscrawler blokkeert 5–7 trainings-UA’s, maar laat inferentie-UA’s (PerplexityBot, ChatGPT-User, OAI-SearchBot) ongemoeid. Geaggregeerde prijs- en reviewdata is de moat; citaties terug naar de site zijn de upside. Dit is het zuiverste “training eruit, inferentie erin”-patroon in één sector.
Adult op 17% — ook een verrassing. Eerdere kleinere steekproeven lieten 0% zien. De full-sample data laat zien dat 1 op de 6 adult-sites minstens één AI-bot verbiedt, met het hoogste Cloudflare Managed-percentage van alle sectoren (7,9%). Meer dan de helft van de AI-blokkades in de adultsector komt van de Cloudflare-schakelaar, niet van een uitgeversbeslissing. Training voor beeldgeneratie is de impliciete dreiging — modellen in de StableDiffusion-klasse leren visuele stijl sneller dan taalmodellen schrijfstijl leren.
SaaS op 7,6% is contra-intuïtief. Softwareleveranciers zijn het luidst in het AI-beleidsgesprek, maar hun robots.txt staat vaak wijd open. De juiste lezing: SaaS-marketingteams hebben AI-zoekopdrachten correct herkend als distributiekanaal. De leveranciers die er wél over hebben nagedacht, kiezen eerder voor opt-in dan voor opt-out — de expliciete Allow-GPTBot-lijst (Bevinding 12) wordt gedomineerd door security- en devtooling-SaaS.
Overheid 5,2%, telecom 3,0%, infrastructuur 4,3%, dev 10,1%. Wetgeving voor openbare registers maakt Disallow: / juridisch precair voor .gov. Telecommarketing wil vindbaarheid. CDN-apexdomeinen hebben niets te beschermen. Ontwikkeltools kiezen expliciet voor opt-in (hun content wordt waardevoller als LLM’s ernaar verwijzen).
De conclusie: er bestaat geen enkel getal voor “het web blokkeert AI wel/niet” dat niet meer verliest dan het zegt. Rapportage per sector is de enige eerlijke manier om deze data te bespreken.
Bevinding 3 — Per AI-vendor: wie wordt het meest geblokkeerd?
Een andere natuurlijke uitsnede van de data is per AI-bedrijf in plaats van per bot. Meerdere vendors draaien meerdere bots (OpenAI draait er drie: GPTBot, ChatGPT-User, OAI-SearchBot; Anthropic draait er twee: ClaudeBot, anthropic-ai; Meta draait er twee: Meta-ExternalAgent, FacebookBot). Samenvoegen op vendorniveau is het dichtst bij de vraag “wat vindt het openbare web van elk AI-bedrijf?”
| AI-vendor | Bots samengevoegd | Sites die ≥ 1 bot blokkeren | % van analyseerbaar |
|---|---|---|---|
| Common Crawl | CCBot | 1.178 | 16,25% |
| OpenAI | GPTBot, ChatGPT-User, OAI-SearchBot | 1.172 | 16,17% |
| Anthropic | ClaudeBot, anthropic-ai | 1.111 | 15,33% |
| ByteDance | Bytespider | 1.082 | 14,93% |
| Meta | Meta-ExternalAgent, FacebookBot | 989 | 13,65% |
Google-Extended | 970 | 13,38% | |
| Amazon | Amazonbot | 877 | 12,10% |
| Apple | Applebot-Extended | 859 | 11,85% |
| Webz.io (Omgili) | Omgili, Omgilibot | 731 | 10,09% |
| Cohere | cohere-ai | 717 | 9,89% |
| Perplexity | PerplexityBot, Perplexity-User | 715 | 9,86% |
| Diffbot | Diffbot | 684 | 9,44% |
| You.com | YouBot | 563 | 7,77% |
| AI2 (Allen AI) | AI2Bot | 487 | 6,72% |
| DuckDuckGo | DuckAssistBot | 482 | 6,65% |
Common Crawl is de meest doelwitgerichte partij ondanks dat het een non-profit webarchief is en geen LLM-uitbater. De reden is hefboomwerking: CCBot voedt bijna elk open-weight model en een substantieel deel van de gesloten modellen. CCBot eerst blokkeren is de regel met de hoogste dekking die een uitgever kan schrijven.
OpenAI, Anthropic en ByteDance clusteren rond 14–16%. OpenAI’s voorsprong is deels een telartefact (drie OpenAI-bots versus één bot voor ByteDance). Bytespider’s 14,9% is het “Bytespider-gedrag”-effect — het is sinds 2024 gedocumenteerd dat het robots.txt negeert, en uitgevers blokkeren het als publiek signaal, niet omdat ze bang zijn voor TikTok.
Meta, Google, Amazon, Apple op 12–14% vormen de tweede laag — defensief geschreven in plaats van als positieverklaring. Kleinere vendors (Webz.io, Cohere, Perplexity, Diffbot, You.com, AI2, DuckDuckGo) op 6–10% worden vooral omhoog getrokken door de algemene vloer van 3,8%; expliciete regels voor hen zitten in de 1–4%-range.
xAI (Grok), Mistral en de meeste Europese/Chinese modellabs ontbreken in de tabel — ze hebben geen gedocumenteerde UA’s voor trainingscrawlers gepubliceerd. Het huidige robots.txt-ecosysteem is een dialoog tussen Amerikaanse/Chinese vendors die UA’s uitbrachten en Amerikaanse/Europese uitgevers die regels schreven; vendors die niets uitbrachten zijn onzichtbaar in de onderhandeling.
Bevinding 4 — CCBot is de nieuwe bliksemafleider, niet GPTBot
De volgorde van bots in de top-10k ziet er zo uit:
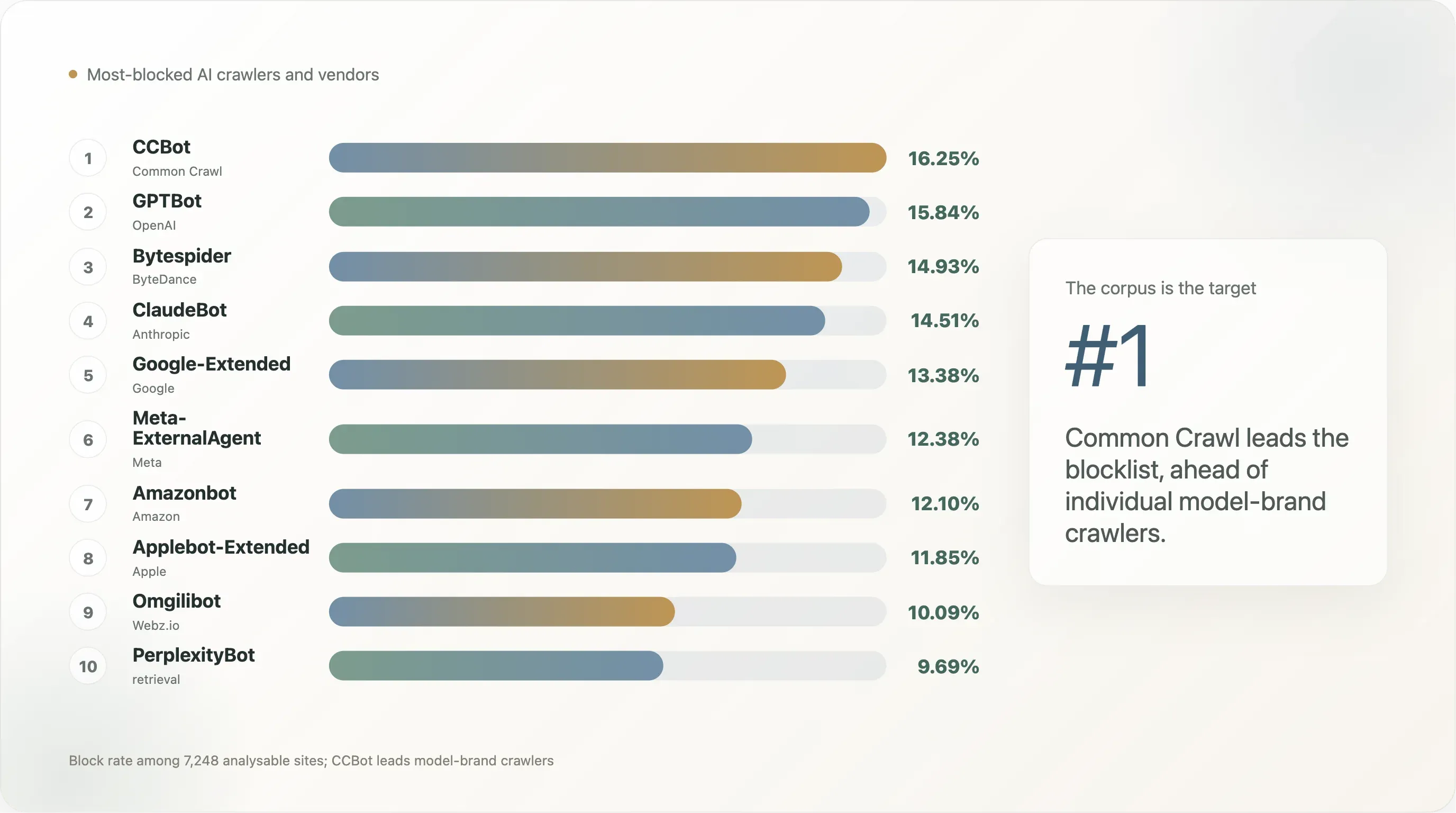
| Rang | Bot | Blokkeerpercentage | Expliciete-regel-rate |
|---|---|---|---|
| 1 | CCBot (Common Crawl) | 16,25% | 12,90% |
| 2 | GPTBot (OpenAI) | 15,84% | 12,72% |
| 3 | Bytespider (ByteDance) | 14,93% | 11,35% |
| 4 | ClaudeBot (Anthropic) | 14,51% | 11,13% |
| 5 | Google-Extended | 13,38% | 10,18% |
| 6 | Meta-ExternalAgent | 12,38% | 8,95% |
| 7 | Amazonbot | 12,10% | 8,66% |
| 8 | Applebot-Extended | 11,85% | 8,72% |
| 9 | Omgilibot | 10,09% | 5,31% |
| 10 | anthropic-ai (verouderd) | 9,99% | 6,55% |
| 11 | cohere-ai | 9,89% | 6,42% |
| 12 | PerplexityBot | 9,69% | 6,40% |
| 13 | Diffbot | 9,44% | 5,95% |
| 14 | ChatGPT-User (inferentie) | 8,90% | 5,73% |
| 15 | YouBot (inferentie) | 7,77% | 4,29% |
| 16 | OAI-SearchBot (inferentie) | 6,83% | 3,66% |
| basislijn | Googlebot | 2,18% | — |
| basislijn | Bingbot | 2,27% | — |
Het verhaal van deze tabel is dat de bot die het openbare web als eerste blokkeert niet het modelmerk is — het is het corpus. Common Crawl’s archief van 250 miljard pagina’s is de grootste trainingsinput geweest voor GPT-3, GPT-4, Llama 1 / 2 / 3, Falcon, Mistral, BLOOM en de meeste open-weight modellen die sinds 2020 zijn uitgebracht. Een site die wil opt-outen van “in het volgende frontiermodel zitten” optimaliseert door eerst CCBot te blokkeren — zodra je niet in Common Crawl zit, ben je in de praktijk gratis uitgesloten van de open-source trainingspijplijn. GPTBot en ClaudeBot komen tweede en derde omdat ze de zichtbare voorkant zijn van twee specifieke commerciële producten; de corpus-UА is het structurele doelwit.
De lager geplaatste AI-bots in de tabel zijn ook informatief. Omgilibot op 10% is opvallend hoog voor een bot waar de meeste lezers nog nooit van hebben gehoord — het wordt geëxploiteerd door Webz.io, een content-data broker die webarchieven verkoopt aan LLM-vendors, en een aanzienlijke groep nieuwsorganisaties noemt het inmiddels expliciet in hun bestanden. AI2Bot op 6,7% (en een bijbehorende Ai2Bot-Dolma-regel op Squarespace-sites) suggereert dat ook de academische LLM-gemeenschap wordt geflagd door uitgevers die niet per se onderscheid maken tussen “non-profit onderzoekscrawler” en “commerciële crawler.”
De inferentiecluster — ChatGPT-User, OAI-SearchBot, YouBot, Perplexity-User — zit 4–8 procentpunten onder de trainingscluster. Dat verschil is het antwoord op een langlopende beleidsvraag: ja, sites met veel verkeer maken onderscheid tussen een bot die data verzamelt voor toekomstige modeltraining en een bot die live retrieval doet om nu een vraag van een gebruiker te beantwoorden. Ze maken het onderscheid niet altijd (de algemene regels doen dat niet), maar een betekenisvol deel schrijft regels die specifiek op de trainingskant mikken.
Bevinding 5 — 14% blokkeert CCBot maar laat Googlebot welkom: het patroon “blokkeer het corpus, behoud de zoekmachine”
De selectieve regel met de meeste adoptie in de top-10k:
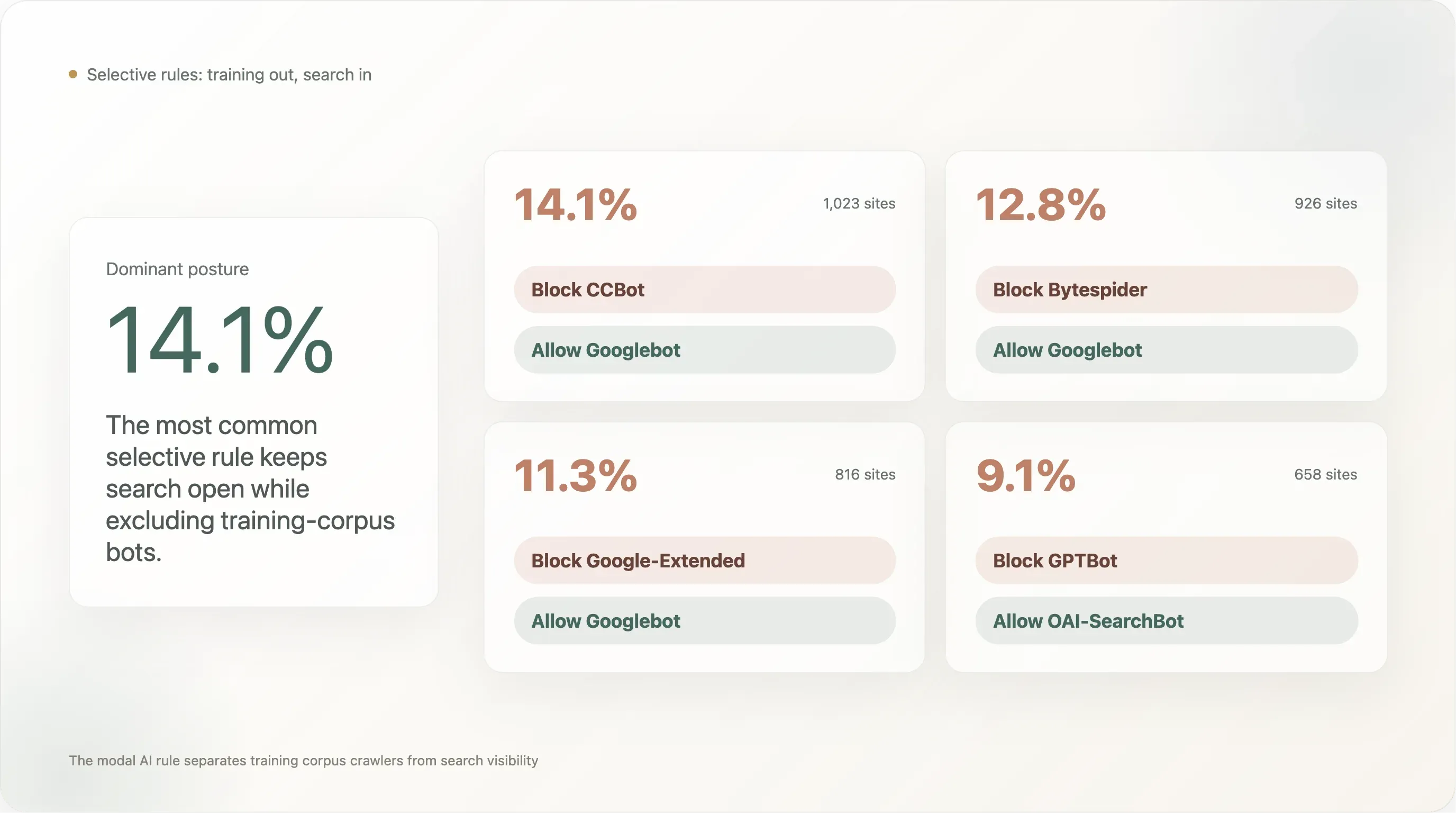
| Regelpatroon | Sites | % van analyseerbaar |
|---|---|---|
Blokkeer CCBot, sta Googlebot toe | 1.023 | 14,11% |
Blokkeer Bytespider, sta Googlebot toe | 926 | 12,78% |
Blokkeer Google-Extended, sta Googlebot toe | 816 | 11,26% |
Blokkeer GPTBot, sta OAI-SearchBot toe | 658 | 9,08% |
Blokkeer GPTBot, sta ChatGPT-User toe | 525 | 7,24% |
Blokkeer CCBot, sta PerplexityBot toe | 519 | 7,16% |
Blokkeer anthropic-ai, sta ClaudeBot toe | 59 | 0,81% |
Het meest gebruikte patroon (14,1%) is “blokkeer Common Crawl, behoud Google-zoekzichtbaarheid.” De nummer twee (12,8%) is “blokkeer Bytespider, behoud Google-zoekzichtbaarheid” — dus: blokkeer ByteDance’s crawler met een reputatieprobleem, terwijl de legitieme zoekbaseline intact blijft. De derde (11,3%) is “blokkeer Google’s eigen AI-trainings-UA terwijl Google’s zoek-UA wel blijft toestaan,” precies de scheiding waarvoor Google Google-Extended heeft ontworpen: de uitgever kiest uit voor Bard / Gemini-training zonder zoekranking te verliezen.
Samen beschrijven deze drie cijfers de dominante beleidslijn op het top-10k-web: blokkeer de trainingscorpus-bots, laat de zoek- en inferentiebots ongemoeid. Het minderheidspatroon “blokkeer training maar laat deze specifieke live-retrieval-UA van het LLM toe” — GPTBot ✗ / ChatGPT-User ✓ op 7,2% — bestaat, maar is kleiner dan de corpusniveau-snoei.
De rij anthropic-ai / ClaudeBot op 0,81% weerspiegelt Anthropic’s UA-uitfasering in 2024: ClaudeBot bedient nu zowel training als inferentie, waardoor de duidelijke uitdrukking “blokkeer training, sta citatie toe” die de oude anthropic-ai-UA wel mogelijk maakte, verdwijnt. Dit is misschien wel de meest onderbesproken UA-ontwerpbeslissing van 2024–2025 — ze heeft een hele klasse beleidsuitingen uit robots.txt verwijderd.
Bevinding 6 — Nieuws in detail: per land en taal
Als we de nieuwscategorie uitsplitsen op landcode-TLD — waarbij belangrijk is dat dit .de voor Duits nieuws betekent, .fr voor Frans nieuws enz., niet de taal van de content — is de variatie binnen nieuws groter dan de variatie tussen nieuws en de rest:
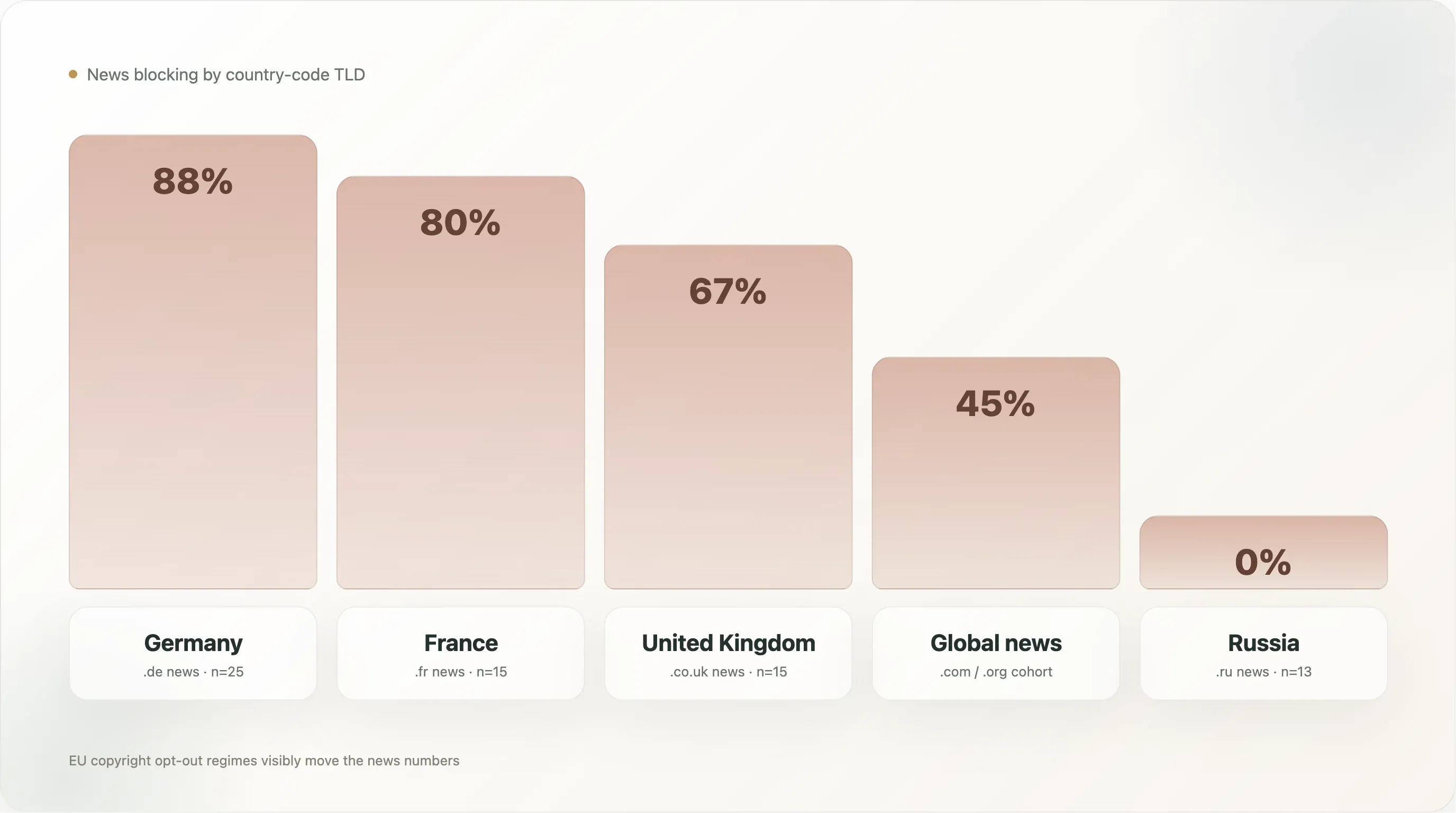
| Land (alleen nieuws) | n | Any AI block | Expliciet |
|---|---|---|---|
🇩🇪 Duitsland (.de) | 25 | 88,0% | 88,0% |
🇫🇷 Frankrijk (.fr) | 15 | 80,0% | 80,0% |
🇬🇧 Verenigd Koninkrijk (.co.uk) | 15 | 66,7% | 53,3% |
🇪🇸 Spanje (.es) | 5 | 60,0% | 60,0% |
🇮🇹 Italië (.it) | 13 | 53,8% | 53,8% |
Wereldwijd nieuws (.com/.org/enz.) | 500 | 45,0% | 42,8% |
🇵🇱 Polen (.pl) | 7 | 42,9% | 42,9% |
🇯🇵 Japan (.jp) | 12 | 25,0% | 25,0% |
🇷🇺 Rusland (.ru) | 13 | 0,0% | 0,0% |
🇬🇷 Griekenland (.gr) | 6 | 0,0% | 0,0% |
Duitse nieuwsmedia zijn met 88% de meest blokkerende subsegment in de hele dataset, en het is 88% expliciet — er is vrijwel geen Duitse nieuwssite in de top 10k die AI-trainingscrawlers toegang geeft tot zijn archief. De cohort wordt aangevoerd door Spiegel, Bild, Welt, Zeit, FAZ, Süddeutsche, Heise, Golem, Stern, Focus — de hele Duitse gevestigde journalistiek, plus techuitgevers die afzonderlijk regels hebben geschreven. De politieke infrastructuur eronder is dicht: VG Media, de collectieve auteursrechtenorganisatie van Duitse uitgevers, is de meest agressieve klager in EU-geschillen over AI-auteursrecht geweest, en Artikel 4 van de EU-richtlijn is in Duits recht geïmplementeerd als §44b UrhG met expliciete machineleesbare opt-out-taal. Tegen de tijd dat AI-vendors arriveerden, waren Duitse uitgevers van alle nationale cohorten het best voorbereid om die juridische houding om te zetten in robots.txt-regels.
Franse nieuwsmedia op 80% zitten daar net onder. De Franse juridische omgeving lijkt op die van Duitsland (Richtlijn 2019/790 omgezet in Franse wet), en het gedrag van de cohort lijkt ook op elkaar — lemonde.fr, lefigaro.fr, liberation.fr, lequipe.fr, 20minutes.fr, ouest-france.fr blokkeren allemaal, waarbij het bestand van Le Monde bovendien verwijst naar het Franse droit du producteur de base de données (Artikel L 342-1 van de Code de la propriété intellectuelle) als parallelle binnenlandse juridische basis. Frankrijk heeft daar bovenop nog een uitspraak uit 2024 van de commerciële rechtbank in Parijs, waarin werd geoordeeld dat opt-outs op basis van robots.txt voldoende kennisgeving vormen onder Artikel 4; dat biedt directe jurisprudentiële steun die geen andere jurisdictie nog evenaart.
Het VK op 67% is lager, en dat komt doordat meerdere grote Britse uitgevers (thesun.co.uk, dailymail.co.uk, mirror.co.uk) User-agent: *-deny-all-blokkades gebruiken in plaats van AI-specifieke regels, waardoor het expliciete percentage daalt naar 53%. Het totale effect is hetzelfde — deze sites staan AI-crawling niet toe — maar het beleid wordt geformuleerd als “geen robots behalve deze specifieke allowlist van zoekmachines” in plaats van als named-AI-bot-disallows. De juridische basis is ook zwakker: na Brexit nam het VK de logica van Artikel 4 over, maar de bijbehorende nationale jurisprudentie is dunner.
Russisch nieuws op 0% is de meest verrassende rij. Dertien nieuwswebsites met Russische domeinen in de steekproef (dzen.ru, rbc.ru, ria.ru, kommersant.ru, tass.ru, lenta.ru, gazeta.ru, interfax.ru, kp.ru, tass.com, enz.) — geen daarvan blokkeert een AI-crawler. De waarschijnlijke verklaring: training van Russische LLM’s wordt gedomineerd door Yandex’ eigen GPT-achtige modellen (die Yandex-internal crawlers gebruiken, niet Common Crawl), de Russische auteursrechtcontext heeft geen equivalent van Artikel 4 opgepikt, en grote Russische uitgevers zien westerse LLM’s als geen echt probleem (Amerikaanse exportbeperkingen beperken OpenAI/Anthropic-diensten in Rusland al) en Yandex als een binnenlandse stakeholder in plaats van een tegenstander. De beleidspositie is simpelweg anders.
Japans nieuws op 25% is een derde patroon. Japan heeft expliciete uitzonderingen voor tekst- en datamining in het nationale auteursrecht (Artikel 30-4 van de Japanse Auteurswet, gewijzigd in 2018) die ruimer zijn dan Artikel 4 van de EU-richtlijn — ze staan TDM toe voor “niet-genot”-doeleinden, inclusief AI-training, zonder toestemming van de rechthebbende. Japanse uitgevers hebben minder juridische basis om uit te sluiten, en de bijbehorende robots.txt-percentages zijn lager. De 25% die wel blokkeert, bestaat vooral uit de grootste, meest kosmopolitische uitgevers (asahi.com, nikkei.com) die zich internationaal eerder dan nationaal positioneren.
De nieuwsdata per land is het helderste bewijs in het rapport dat de juridische context, niet technologie of sector-economie, de belangrijkste drijfveer is achter AI-blokkering. EU-nieuwscohorten clusteren tussen 54% en 88%; niet-EU-nieuwscohorten (Rusland, Japan, de wereldwijde .com-cohort) variëren van 0% tot 45%. De piek van 88% zit in het land met de meest ontwikkelde implementatie van Artikel 4; de vloer van 0% zit in het land met feitelijk geen AI-beleidswetgeving.
Bevinding 7 — EU versus de rest: een kloof van 16 punten
Als we de landenbril een niveau hoger zetten, is het brede EU-versus-rest-verschil scherp:
| Regio | n | Any AI block | Expliciet |
|---|---|---|---|
EU ccTLD’s (.fr, .de, .es, .it, .nl, .pl, .se, .dk, .fi, .be, .at, .cz, .hu, .ro, .gr, .pt, .ie, .sk, .bg) | 617 | 35,2% | 33,9% |
Niet-EU nationale ccTLD’s (.uk, .jp, .kr, .cn, .ru, .br, .in, .au, .mx, .ca, .tr, .ar, .cl, .co, .pe) | 897 | 17,2% | 13,6% |
Globaal (.com, .net, .org, enz.) | 5.734 | 19,2% | 15,7% |
EU-ccTLD-sites blokkeren AI tegen twee keer het tempo van de niet-EU-nationale cohort en bijna twee keer het tempo van de wereldwijde .com-basislijn. Het verschil is consistent over de EU-lidstaten heen (geen enkel land bepaalt het gemiddelde) en consistent over sectoren heen (.de nieuws op 88%, .de SaaS op ~12%, .de e-commerce op ~25% — allemaal hoger dan hun wereldwijde tegenhangers).
We vonden 275 robots.txt-bestanden in de top-10k die Richtlijn 2019/790 expliciet in hun comments noemen — ongeveer 3,8% van de parseerbare steekproef. De cohort wordt gedomineerd door EU-uitgevers, maar reikt verder: meerdere Amerikaanse nieuwsmerken (met name NYT, dat direct “Art. 4 of the EU Directive” citeert), enkele Britse sites en een handvol grotere Europese e-commercebestemmingen nemen de juridische taal over. 87 bestanden noemen “TDM” of “text and data mining” expliciet. 460 bestanden bevatten een vorm van taal om auteursrechten voor te behouden (“expressly opts out,” “all rights reserved,” “no commercial use,” “no machine learning”), ook waar geen specifieke wet wordt genoemd.
Twee verdere, meer fijnmazige observaties uit deze uitsnede:
Het EU-effect is niet alleen nieuws. Als we nieuws constant houden, blokkeren niet-nieuwe EU-sites AI nog steeds vaker dan niet-nieuwe niet-EU-sites (ongeveer 28% versus 14%). Een kleine maar reële groep EU-SaaS, e-commerce en academia heeft het Artikel 4-raamwerk ook in hun eigen sector geïnternaliseerd.
De EU-achtige taal wordt buiten de EU steeds meer een de facto sjabloon. Het Cloudflare Managed robots.txt-sjabloon — wereldwijd gebruikt — verwijst expliciet naar “ARTICLE 4 OF THE EUROPEAN UNION DIRECTIVE 2019/790” in de standaardtekst. Een Amerikaanse site die Cloudflare’s instelling “Block AI Bots” inschakelt, claimt zonder dat misschien te beseffen een EU-wettelijk voorbehoud van rechten. Dit is een van de interessantste policy-drift-artifacts die we vonden: een Europees juridisch concept wordt geglobaliseerd via de productinterface van een Amerikaanse infrastructuurprovider.
Bevinding 8 — Sjablonen en oorsprong van sjablonen
De uitsplitsing naar sjabloonoorsprong van de 6.638 sites die een parseerbaar robots.txt teruggaven:
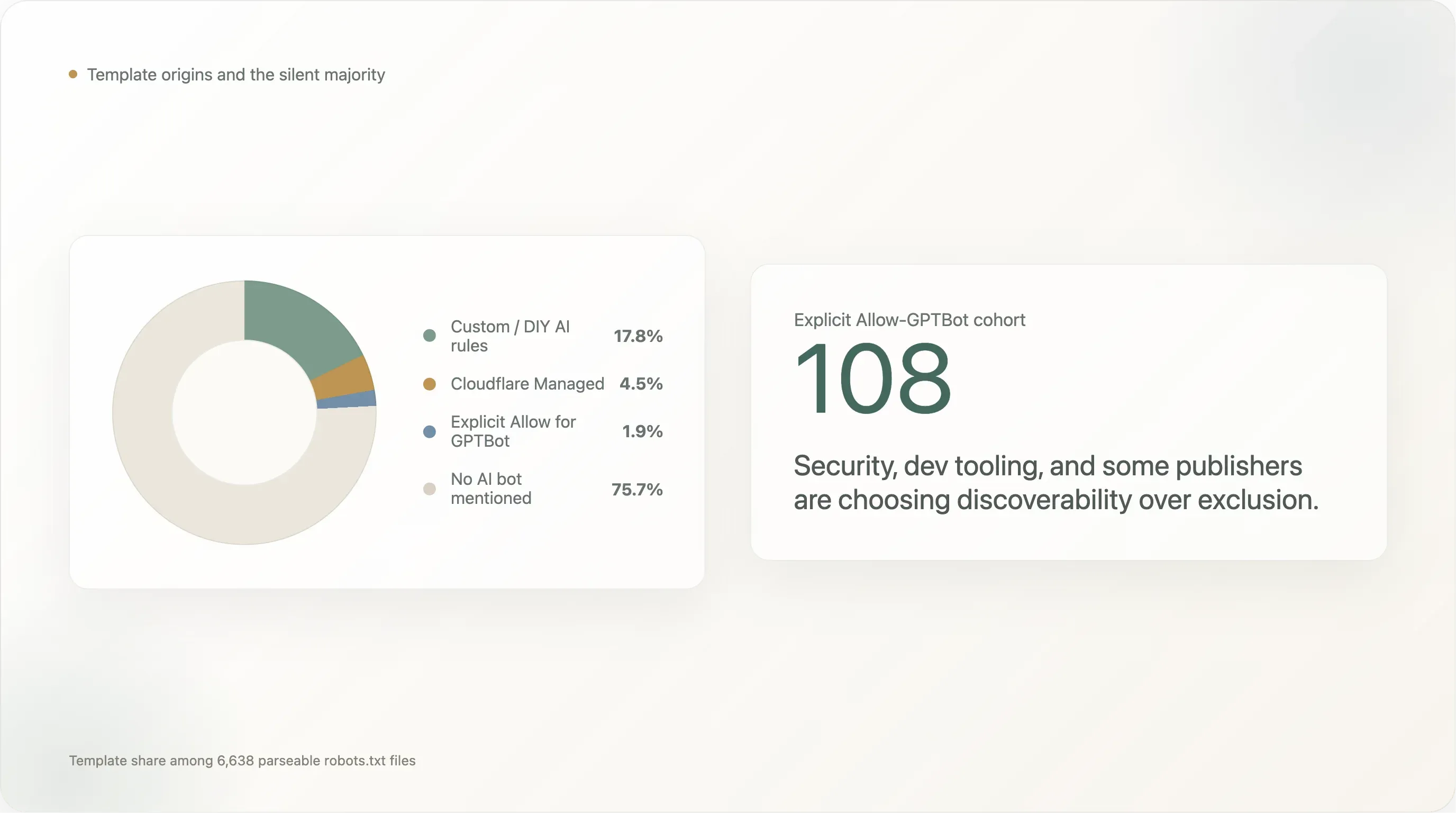
| Sjabloon | Sites | Aandeel |
|---|---|---|
| Geen AI-bot genoemd (standaard Shopify-achtig, Yoast, handgeschreven zonder rekening te houden met AI) | 5.024 | 75,7% |
| Aangepaste / DIY AI-regels | 1.183 | 17,8% |
Cloudflare Managed (Content-Signal: search=yes,ai-train=no) | 302 | 4,5% |
Expliciete Allow: / voor GPTBot | 124 | 1,9% |
| Squarespace-standaard (28 AI-UA’s in de padbeperkte blokkade) | 5 | 0,1% |
DIY-regels domineren met 17,8%. De groep zelfgeschreven blokkeerders wordt aangevoerd door elk socialmediaplatform (facebook.com, twitter.com, linkedin.com, whatsapp.com, tiktok.com, snapchat.com, pinterest.com, x.com, chatgpt.com zelf), de grootste e-commercebestemmingen (amazon.com, amazonvideo.com), de grootste nieuwsmerken (nytimes.com, cnn.com, bbc.com, theguardian.com, forbes.com, reuters.com, bbc.co.uk, t-online.de, weather.com), sleutelspelers in streaming/media (netflix.com, vimeo.com, soundcloud.com, imdb.com), en een lange staart van professionele-dienstenwebsites (canva.com, medium.com).
Cloudflare Managed zit op 4,5% — veel hoger dan dezelfde templatepenetratie aan de absolute top van de curve en lager dan de penetratie in de lange staart buiten het bereik van dit rapport. Het sjabloon wordt vooral gebruikt in het segment rang 1001–10.000 (4–5%) en is vrijwel afwezig aan de top van de curve (Top 100: 1 site gebruikt het; Top 101–1000: 5 sites). De grote mondiale properties schrijven hun eigen regels; de lange staart gebruikt de schakelaar.
Een paar specifieke Cloudflare Managed-sites zijn het noemen waard. cloudflare.com zelf gebruikt het sjabloon, wat logisch is (Cloudflare gebruikt zijn eigen product op het eigen domein). theatlantic.com gebruikt het sjabloon — het enige grote Amerikaanse nieuwsmerk dat we vonden zonder aangepaste regel. spankbang.com gebruikt het sjabloon — de hoogst gerankte adult-site die een Cloudflare-ingespoten AI-blokkade adopteert. linktr.ee gebruikt het sjabloon, waardoor AI-training over de hele creator economy van Linktree in één vendorbeslissing wordt geblokkeerd. launchpad.net, nexusmods.com, vinted.fr, cookielaw.org, rustdesk.com en een lange lijst van kleinere mediaproperties maken de zichtbare Cloudflare Managed-cohort compleet.
Het adoptiepatroon van Cloudflare is het concreetste bewijs dat een groot deel van “het AI-beleid van het web” door infrastructuurproviders wordt bepaald. Het absolute aandeel is klein (4,5%), maar structureel belangrijk: het sjabloon is de standaard die Cloudflare levert, en de default-on-lijn voor de komende 12 maanden is opwaarts. Als Cloudflare de schakelaar voor nieuwe accounts standaard aanzet, verschuift het wereldwijde blokkeercijfer aanzienlijk zonder dat een individuele uitgever een beslissing neemt.
De Squarespace-standaard (5 sites in de top-10k, maar een veel grotere cohort buiten onze steekproef) is een ander patroon: Squarespace levert een robots.txt waarin 28 AI-bots in één blokkade worden genoemd, maar die bots erven de padbeperkingen van User-agent: * in plaats van een sitebrede ban te krijgen. AI-crawlers kunnen / ophalen, de homepage, productpagina’s, de blog. Ze kunnen alleen /config of /account niet ophalen. We hebben dit eerder al aangemerkt als de bron van fout-positieve “AI block”-lezingen in scans van Squarespace-sites door derden; diezelfde waarschuwing geldt hier.
Bevinding 9 — AI-beleid is uniform over de rangverdeling
De gebruikelijke intuïtie voor dit soort onderzoek is dat de meest bezochte sites het strengste AI-beleid zouden hebben — zij hebben het meeste te verliezen door trainingsverplaatsing, de meeste juridische capaciteit en de meeste publieke aandacht. De data ondersteunt die intuïtie niet.
| Rangbucket | n | Any AI block | Expliciet | Cloudflare Managed |
|---|---|---|---|---|
| Top 100 | 67 | 22,4% | 17,9% | 1 site |
| Top 101–1.000 | 598 | 22,9% | 19,2% | 5 sites |
| Top 1.001–5.000 | 2.810 | 19,0% | 15,3% | 99 sites |
| Top 5.001–10.000 | 3.773 | 20,8% | 17,8% | 197 sites |
De vier buckets zitten tussen 19% en 23%. De Top 100 is niet agressiever dan de staart van rang 5.001–10.000. Het headline-percentage lijkt een eigenschap van het openbare web in 2026, niet een signaal van hoe groot of prominent een individuele site is.
Twee factoren spelen mee. Ten eerste wordt de kop van de curve gedomineerd door infrastructuur-/SaaS-/zoek-/portaldomeinen (Microsoft, Apple, Google, enz.) die zelf relatief weinig AI blokkeren. Ten tweede bevat de lange staart een groot aandeel regionale nieuwsuitgevers en EU-jurisdictiesites die — zoals Bevinding 6 en 7 lieten zien — AI agressiever blokkeren dan het wereldgemiddelde. De twee effecten heffen elkaar ongeveer op, en het nettoresultaat is een uniforme headline.
De kolom Cloudflare Managed verschuift wel over de curve. De Top 1000 heeft 6 Cloudflare-managed sites (1,0%); de Top 1001–10000 heeft er 296 (5,7%). De grote sites schrijven zelf; de lange staart gebruikt de vendorschakelaar. Dit is het enige betekenisvolle rangafhankelijke signaal in de dataset, en het suggereert dat naarmate je van de top van het web naar de lange staart afdaalt, het aandeel AI-beleid dat door de vendor in plaats van door de uitgever wordt bepaald gestaag stijgt. We verwachten dat deze gradiënt verder doorzet voorbij de top 10k en tot ver in de top 100k.
Bevinding 10 — Vijf anatomieën: hoe robots.txt eruitziet wanneer het echt beleid is
Cijfers beschrijven de vorm van de dataset; het echte karakter van “AI-beleid op het openbare web” zie je het best door concrete bestanden te lezen. Hier zijn vijf die het waard zijn om uit te lichten, geselecteerd om het beleidspectrum te bestrijken.
Anatomie 1 — The New York Times (nytimes.com)
De eerste 14 regels van nytimes.com/robots.txt:
1# New York Times content is made available for your personal, non-commercial
2# use subject to our Terms of Service here:
3# https://help.nytimes.com/hc/en-us/articles/115014893428-Terms-of-Service.
4# Use of any device, tool, or process designed to data mine or scrape the content
5# using automated means is prohibited without prior written permission from
6# The New York Times Company. Prohibited uses include but are not limited to:
7# (1) text and data mining activities under Art. 4 of the EU Directive on Copyright in
8# the Digital Single Market;
9# (2) the development of any software, machine learning, artificial intelligence (AI),
10# and/or large language models (LLMs);
11# (3) creating or providing archived or cached data sets containing our content to others; and/or
12# (4) any commercial purposes.
13# Contact https://nytlicensing.com/contact/ for assistance.Dit is robots.txt als juridisch bewijsstuk. Het bestand is zo opgebouwd dat het als bewijs kan worden ingebracht in de NYT v. OpenAI-zaak waar het deel van uitmaakt. De verwijzingen naar “Art. 4 of the EU Directive” — door een Amerikaanse uitgever — illustreren de observatie uit Bevinding 7 dat EU-juridische kaders doorsijpelen in het mondiale debat. Het expliciete verbod op “creating or providing archived or cached data sets” is rechtstreeks gericht op Common Crawl. Het bestand is 60+ regels lang met benoemde User-agent-blokken voor GPTBot, OAI-SearchBot, ChatGPT-User, anthropic-ai, ClaudeBot, CCBot, Google-Extended, Applebot-Extended, Bytespider, Diffbot, Meta-ExternalAgent, Amazonbot, Omgili, Omgilibot en nog een half dozijn anderen — elke genoemde bot krijgt zijn eigen Disallow: /.
Anatomie 2 — Der Spiegel (spiegel.de) — AI-permissie per sectie
Der Spiegel heeft het meest operationeel geavanceerde robots.txt dat we in de hele dataset vonden. Het relevante blok:
1# TLP-6507: Testweise Freischaltung der OpenAI-Suchcrawler fuer ausgewaehlte Bereiche
2User-agent: OAI-SearchBot
3Allow: /ausland/
4Allow: /partnerschaft/
5Allow: /gesundheit/
6Allow: /familie/
7Allow: /reise/
8Allow: /psychologie/
9Allow: /stil/
10Disallow: /
11User-agent: ChatGPT-User
12Allow: /ausland/
13Allow: /partnerschaft/
14Allow: /gesundheit/
15Allow: /familie/
16Allow: /reise/
17Allow: /psychologie/
18Allow: /stil/
19Disallow: /De commentaarregel betekent: “Testmatige openstelling van OpenAI-zoekcrawlers voor geselecteerde secties.” Spiegel heeft zeven specifieke contentcategorieën op de allowlist gezet — internationaal nieuws, partnerschappen, gezondheid, familie, reizen, psychologie en lifestyle — voor OpenAI’s inferentie-UA’s, terwijl de rest wordt geblokkeerd. De politieke secties, het Duitse nationale nieuws en de onderzoeksjournalistiek zijn expliciet uitgesloten. Common Crawl, Bytespider, Cohere, Webzio-Extended en de andere trainings-UA’s krijgen verderop in het bestand een volledige Disallow: /.
Dit is robots.txt als sectiegebonden redactioneel beleid. De impliciete theorie is dat lifestylecontent een lager risico op trainingsverplaatsing heeft en een hogere kans op inferentie-citaties oplevert, dus laat Spiegel AI die secties tonen; politieke en onderzoekscontent zijn de moat, dus AI wordt uitgesloten. We hebben dit patroon nergens anders gezien. Het wijst op een niveau van interne afstemming tussen redactie, juridisch en infrastructuur dat de meeste redacties nog niet hebben bereikt. We verwachten dat dit soort fijnmazige, sectiegebonden beleidsuitingen zich in 2026–2027 zal verspreiden — het bestand van Spiegel is in feite een vroege indicator.
Anatomie 3 — BBC (bbc.com) — de vorm van de beleidsverklaring
De BBC robots.txt begint met:
1# version: ec59bd036e5138eb4831a9ed44447b1ff310e235
2# The BBC's Terms of Use: https://www.bbc.co.uk/terms
3# - Explain the rules for using our services
4# - Tell you what you can do with our content
5#
6# In short: Please use our site like a human, not a robot.
7# That means:
8# - No scraping, crawling, or systematic extraction of content
9# - No use of BBC content for training or fine-tuning AI models, including LLMs
10# - No retrieval-augmented generation (RAG), AI-powered search, agentic AI or
11# grounding using BBC content
12# - No creating datasets from BBC content
13# - No text and data mining (TDM) under Article 4 of the EU Directive on Copyright
14# - No using BBC content to create summaries for your own use
15# - No business use without permission
16# - The BBC reserves all rights in its content and expressly opts out of any
17# statutory exceptions in any jurisdiction for text and data mining,
18# as permitted by law
19#
20# TL;DR: Browse, read, watch, enjoy - like a human.De BBC geeft versies aan zijn robots.txt (# version: ec59bd... is een git-commit-hash), verbiedt de acht specifieke vormen van AI-gebruik die de juristen van de BBC volgen, en sluit af met een samenvatting in de proza-stem waarop het merk van de BBC is gebouwd. De uitdrukking “expressly opts out of any statutory exceptions in any jurisdiction” is een bewuste wereldwijde voorbehoudsverklaring — het zegt: we vertrouwen geen enkel afzonderlijk juridisch kader om ons de bescherming te geven die we willen, dus we beroepen ons overal tegelijk op opt-out. Dit is het meest uitgewerkte robots.txt in de dataset, en leest meer als een persbericht dan als een configuratiebestand.
Anatomie 4 — WordPress.org — expliciete welkomstverklaring
Vergelijk al het bovenstaande met wordpress.org:
1User-agent: GPTBot
2Allow: /
3User-agent: ClaudeBot
4Allow: /
5User-agent: anthropic-ai
6Allow: /
7User-agent: Google-Extended
8Allow: /
9User-agent: Applebot-Extended
10Allow: /
11User-agent: PerplexityBot
12Allow: /
13User-agent: Bytespider
14Allow: /
15User-agent: CCBot
16Allow: /
17User-agent: Copilot
18Allow: /WordPress.org kiest expliciet voor negen AI-trainingscrawlers, waaronder de drie (Bytespider, CCBot, anthropic-ai) die elders het vaakst worden geblokkeerd. De impliciete theorie is dat de documentatie en plugin-ecosystemen van WordPress een publiek goed zijn waarvan de waarde stijgt wanneer AI-assistenten er vragen over kunnen beantwoorden. Elke keer dat iemand Claude vraagt “hoe stel ik permalinks in WordPress in?” en Claude is getraind op wordpress.org/documentation/, is de missie van WordPress gediend. De Foundation lijkt te hebben besloten dat in elke model-trainingscorpus zitten strategisch positief is, en ze hebben de uitdrukkingsgrammatica van het bestand gebruikt om dat te zeggen.
Anatomie 5 — The Verge (theverge.com) — het gesponsorde hybride model
Nog een patroon dat het waard is om te tonen. The Verge structureert hun AI-regels als Disallow: / \ Allow: /sp/:
1User-agent: GPTBot
2Allow: /
3User-agent: Applebot
4Allow: /
5User-agent: Google-Extended
6Disallow: /
7Allow: /sp/
8User-agent: anthropic-ai
9Disallow: /
10Allow: /sp/
11User-agent: Bytespider
12Disallow: /
13Allow: /sp/
14User-agent: CCBot
15Disallow: /
16Allow: /sp/
17User-agent: ChatGPT-User
18Disallow: /
19Allow: /sp/
20User-agent: ClaudeBot
21Disallow: /
22Allow: /sp/Het pad /sp/ is The Verge’s sectie voor gesponsorde / partnercontent. Redactionele content is geblokkeerd voor AI-training; gesponsorde content is toegestaan. De economische logica is helder: sponsors betalen om vindbaar te zijn, ook via AI; het redactionele vlaggenschip is de moat. GPTBot staat volledig open (vermoedelijk via een directe OpenAI-relatie), Applebot staat volledig open als zoekbaseline, en de rest krijgt het hybride regime. Dit is de enige vorm van “tiered AI access” in zijn soort die we vonden.
Deze vijf bestanden beschrijven het huidige bereik van robots.txt-AI-beleid. De meeste bestanden in de top 10k lijken op geen van deze vijf — ze zijn stil of gebruiken een vendorsjabloon. De bestanden die wél op een van deze lijken, zijn geschreven door mensen die hebben besloten dat het bestand de moeite waard is om zorgvuldig te lezen.
Een noot over de grootte van bestanden: de mediane robots.txt-body in onze steekproef is 858 bytes — te klein om een betekenisvol AI-beleid in te coderen. De rechterstaart bevat de regels: 1.005 sites (15,3%) hebben een bestand groter dan 5 KB, 273 groter dan 20 KB, en het maximum was 248 KB. 460 bestanden bevatten taal om rechten voor te behouden; 275 noemen EU 2019/790 bij naam. Een robots.txt in 2026 is steeds vaker een versiebeheerd, door juristen beoordeeld document, niet een losse configuratieregel.
Bevinding 11 — 108 sites heten GPTBot expliciet welkom
Een kleine maar zichtbare groep schrijft een regel User-agent: GPTBot \n Allow: / — het omgekeerde van het vaker besproken “Disallow GPTBot.” Het totaal in onze steekproef is 108 sites met een expliciete Allow voor GPTBot op het rootpad. De eerste 25 op Tranco-rang:
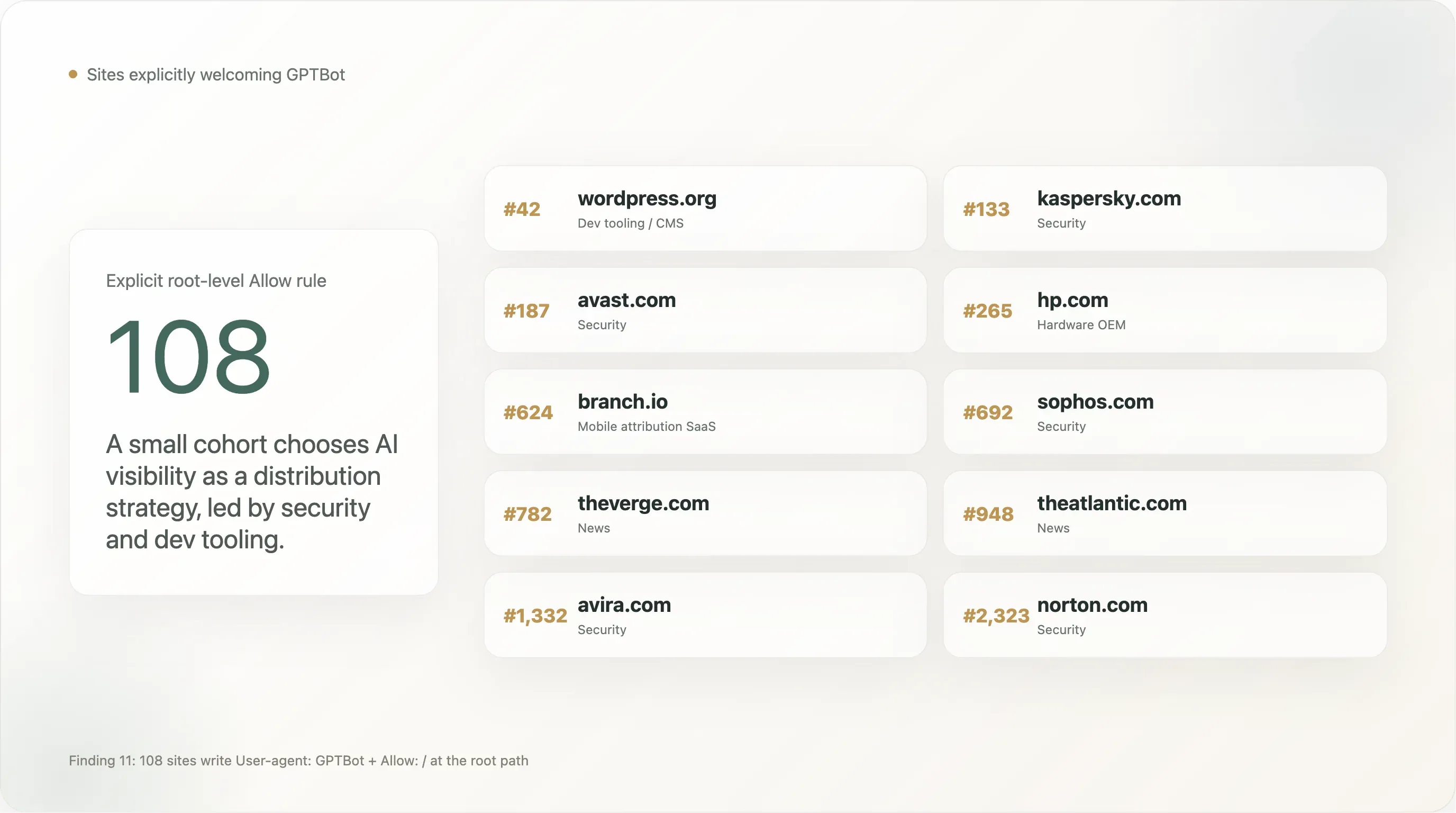
| Rang | Domein | Sector |
|---|---|---|
| 42 | wordpress.org | Ontwikkeltools / CMS |
| 133 | kaspersky.com | Security |
| 187 | avast.com | Security |
| 265 | hp.com | Hardware-OEM |
| 624 | branch.io | Mobile attribution SaaS |
| 692 | sophos.com | Security |
| 782 | theverge.com | Nieuws |
| 905 | rambler.ru | Russisch portaal |
| 945 | kleinanzeigen.de | Duits handelsplatform |
| 948 | theatlantic.com | Nieuws |
| 1.092 | lge.com | LG Electronics |
| 1.300 | justdial.com | Indiase lokale zoekdienst |
| 1.332 | avira.com | Security |
| 1.412 | youm7.com | Egyptisch nieuws |
| 1.530 | goodreturns.in | Indiase finance |
| 1.621 | publi24.ro | Roemeense advertenties |
| 1.807 | geocomply.com | Compliance SaaS |
| 1.908 | nba.com | Sport |
| 1.956 | oneindia.com | Indiaas nieuws |
| 1.974 | mindbox.ru | Russische SaaS |
| 2.009 | thesun.co.uk | Nieuws |
| 2.126 | vox.com | Nieuws |
| 2.140 | mgid.com | Native advertising |
| 2.314 | ninjarmm.com | IT-management SaaS |
| 2.323 | norton.com | Security |
Een paar patronen:
Securitybedrijven zijn opvallend oververtegenwoordigd. Kaspersky, Avast, Sophos, Avira, Norton, NinjaRMM staan allemaal expliciet GPTBot toe. Dit is een bewuste distributiestrategie: wanneer een gebruiker ChatGPT vraagt “wat is de beste antivirus voor mijn Windows-computer?”, beïnvloedt het feit dat het merk in het trainingscorpus van het model zit direct de aanbeveling. Security is een van de weinige B2C-productcategorieën waar AI-zoekopdrachten SEO al aan het vervangen zijn als primaire acquisitiekanaal, en deze merken bewegen als eerste. We verwachten dat de rest van de securitysector binnen 12 maanden volgt.
Sommige grote nieuwsmerken staan op deze lijst, niet op de blokkadelijst. The Verge, The Atlantic, Vox, The Sun, NBA.com. Dat is geen tegenstelling — deze uitgevers lijken te hebben besloten dat citeren binnen ChatGPT-zoekopdrachten waardevoller is dan bescherming tegen training, en ze schreven de expliciete Allow-regel om zichzelf te beschermen tegen toekomstige overblokkering door hun CDN of CMS. Vergelijk dit met de houding van NYT / Reuters / BBC / Forbes / Guardian van expliciete Disallow. Beide standpunten zijn verdedigbaar; de nieuwssector is niet monolithisch.
De aanwezigheid van The Sun is opvallend omdat dezelfde site elders in zijn bestand een User-agent: * deny-all gebruikt. De regel van The Sun moet je het best lezen als “AI-training is verboden, AI-zoekopdrachten zijn toegestaan, en we hebben GPTBot expliciet op de allowlist gezet als uitzondering op de deny-all om ervoor te zorgen dat ChatGPT vragen kan beantwoorden die The Sun citeren.” Dit is de juridisch meest verfijnde van de GPTBot-Allow-regels — het is een opt-out plus een single-vendor opt-in.
De aanwezigheid van WordPress.org is de meest impactvolle afzonderlijke vermelding op de lijst. Een niet-verwaarloosbaar deel van het wereldwijde open-source CMS-ecosysteem verwijst naar WordPress.org voor documentatie of host daarvandaan plugins. Door GPTBot expliciet toe te staan in wordpress.org/robots.txt, heeft de WordPress Foundation feitelijk gezegd dat het WordPress-documentatie-ecosysteem vrij is voor training — met gevolgen voor hoe goed Claude, Gemini en ChatGPT “hoe doe ik…”-vragen over WordPress kunnen beantwoorden.
De overige 83 sites op de volledige Allow-GPTBot-lijst vormen een lange staart van regionaal nieuws, kleinere securityleveranciers, advertentieplatforms in niet-Engelse markten en B2B-SaaS. Voor zover we kunnen zien is er geen sectorbrede coördinatie vergelijkbaar met “Allow-GPTBot” — de regel wordt site voor site overgenomen door operators die hebben besloten dat in het corpus zitten de strategische keuze is.
Bevinding 12 — llms.txt is op deze schaal nauwelijks meer dan een gerucht
llms.txt, het voorgestelde alternatieve bestandsformaat voor LLM-vriendelijke contentontdekking (sinds eind 2024 gepromoot door Mintlify, Anthropic, Vercel en een handvol dev-tooling-vendors), heeft in onze steekproef bijna nergens zichtbare adoptie.
Van de 6.638 sites die een parseerbaar robots.txt teruggaven, noemen 83 (1,15%) llms.txt — meestal als regel Sitemap: https://example.com/llms.txt. Dat is twee ordegroottes lager dan dezelfde metriek in commerce-steekproeven met veel dev-tooling, waar de standaardinstellingen van Vercel en Mintlify de adoptie opblazen.
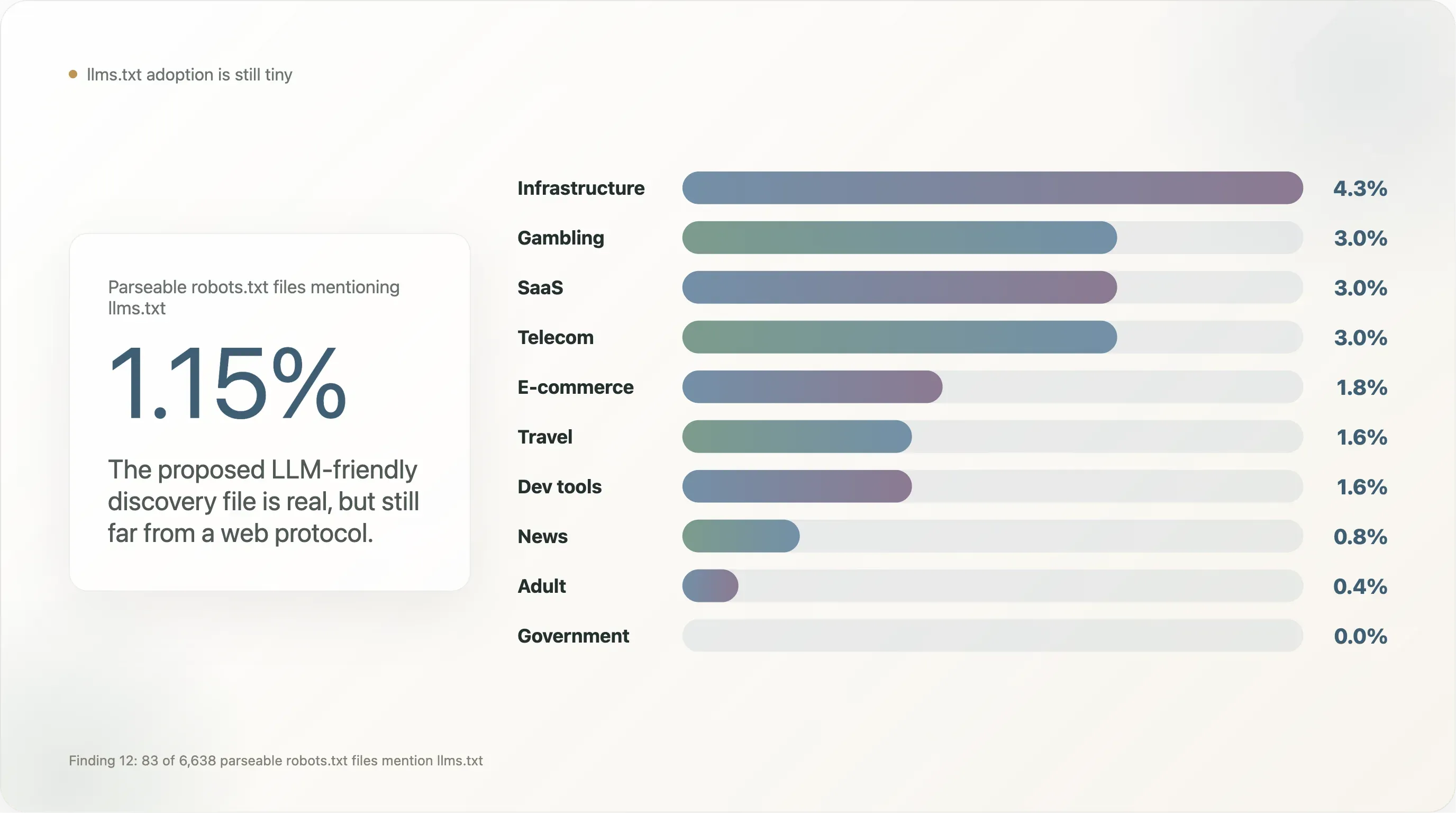
De verdeling per categorie:
| Sector | n | % met vermelding van llms.txt |
|---|---|---|
| Infrastructuur | 47 | 4,3% |
| Gambling | 100 | 3,0% |
| SaaS | 369 | 3,0% |
| Telecom | 33 | 3,0% |
| E-commerce | 224 | 1,8% |
| Reizen | 64 | 1,6% |
| Ontwikkeltools | 129 | 1,6% |
| Nieuws | 650 | 0,8% |
| Adult | 254 | 0,4% |
| Overheid | 172 | 0,0% |
| Academia | 268 | 0,0% |
| Search | 12 | 0,0% |
llms.txt is geconcentreerd in SaaS rond de rand van ontwikkeltools, gambling (dat nieuwe robots.txt-features sneller overneemt dan andere gereguleerde sectoren omdat het compliance-teams heeft die gewend zijn extra metadata toe te voegen), en B2B e-commerce. Het ontbreekt opvallend in nieuws en overheid — de twee segmenten die het meest betrokken zijn bij AI-beleid en waarvan de adoptie nodig zou zijn om de standaard van “vendor-experiment” naar “webprotocol” te laten doorgroeien. Tot die tijd is llms.txt echt, maar klein, en een follow-up audit eind 2026 zal een nuttige herhalingstest zijn.
Het structurele probleem voor llms.txt is dat het niet door een IETF-proces is gestandaardiseerd en dat de grote AI-vendors zich niet hebben vastgelegd om het te respecteren. Een robots.txt-regel heeft 30 jaar crawler-infrastructuur achter zich; een llms.txt-regel heeft dat niet. Zolang ten minste één grote vendor (OpenAI, Anthropic, Google, Cloudflare) geen formele ondersteuning verklaart, is het bestand in wezen een marketingartifact van het Mintlify-/Vercel-ecosysteem. We verwachten niet dat dit in 2026 verandert.
Bevinding 13 — Toegankelijkheid: robots.txt is nog steeds leesbaar voor twee derde van het topweb
Een bijobservatie die geen bevinding had moeten worden: 66% van de top 10.000 sites gaf een parseerbaar robots.txt terug aan één onderzoeks-IP, en slechts 7 van 10.000 (0,07%) gaven 429 Too Many Requests terug. Dat is goed nieuws voor robots.txt als publiek protocol.
Ter vergelijking: dezelfde pipeline op een commerce-steekproef van 1.008 domeinen uit het middensegment twee maanden eerder kreeg 429 van 52% van de opgeloste domeinen — Shopify- en Cloudflare-CDN’s die agressief rate-limiten voor elke UA die geen grote zoekmachine is. Het web met veel verkeer is veel vriendelijker: top-sites hebben vaker óf (a) minder agressieve botmanagementlagen, óf (b) expliciete allowlists voor bekende onderzoekscrawlers, of beide.
Het fetch_failed-percentage van 21% op de top-10k wordt gedomineerd door CDN-apexdomeinen (akamai.net, cloudfront.net, fastly.net, apple-dns.net, gtld-servers.net) die geen webserver op / draaien. Ze blokkeren ons niet; ze hebben niets te serveren. Als je die uitsluit, ligt de echte foutfractie van “probeerde te lezen maar kon niet” in de lage enkelcijfers.
Dat betekent dat toekomstige versies van dit rapport — kwartaalmomentopnames, jaar-op-jaarvergelijkingen — goedkoop en reproduceerbaar op één machine kunnen worden uitgevoerd. Het auditvenster blijft open aan de top van de curve. De asymmetrische casus is de lange staart en het commerce-segment, waar CDN-throttling robots.txt feitelijk al heeft geprivatiseerd. We verwachten dat deze divergentie groter wordt: top-sites blijven leesbaar omdat zoekmachines leesbaarheid eisen; de lange staart in commerce wordt minder leesbaar naarmate Cloudflare’s bot-fight-lagen agressiever worden. De publieke auditbaarheid van robots.txt splitst zich langs dezelfde lijn die “het zichtbare web” scheidt van “het operationeel beschermde web.”
IV. Wat dit alles betekent
Vier claims, in volgorde van hoe sterk de data ze ondersteunt.
1. Het internet heeft een sector-specifiek, geen globaal, AI-beleid. De spreiding van 12× tussen nieuws en telecom domineert elk geaggregeerd cijfer. Rapporteren “X% van het web blokkeert AI” zonder sectorale uitsplitsing overschat SaaS/overheid/dev en onderschat nieuws/reizen/sociaal. Sector per sector is de enige eerlijke framing.
2. Artikel 4 van de EU-auteursrechtrichtlijn is het enige juridische regime dat zichtbaar de cijfers beweegt. EU-ccTLD-sites blokkeren AI op 35% tegenover de wereldwijde basislijn van 19%. De Amerikaanse rechtszaken (NYT v. OpenAI, het rapport van het Copyright Office van januari 2025) hebben de Amerikaanse nieuwscohort verschoven, maar niet het bredere Amerikaanse web. Het EU-raamwerk lekt ook wereldwijd door via Cloudflare’s sjabloon, dat Richtlijn 2019/790 citeert in de standaardtekst, ongeacht de jurisdictie van de klant.
3. Er worden twee parallelle “AI-beleidslijnen” uitgedrukt en die spreken elkaar niet altijd. Het bewuste, handgeschreven beleid (17,8%, vooral nieuws/sociaal/reizen/e-commerce) en het geërfde Cloudflare-managed beleid (4,5%) overlappen inhoudelijk, maar verschillen in legitimiteit. In een wereld waarin AI-operators juridische dekking zoeken om robots.txt te negeren, is de verdediging “wij hebben het geschreven en beoordeeld” structureel sterker dan “ik heb het gewoon aangezet.” De prikkel in rechtszaken is om beleid van de tweede categorie naar de eerste te verplaatsen.
4. Het corpus, niet het model, is wat uitgevers blokkeren. CCBot op 16,3% — hoger dan welke modelmerk-bot dan ook — is de duidelijkste uitdrukking hiervan. OpenAI disallowen haalt een uitgever niet uit training; CCBot disallowen wel. 14,1% van het top-10k-web blokkeert CCBot terwijl Googlebot welkom blijft. Het patroon “blokkeer training, behoud zoekverkeer” is de modale AI-regel in 2026.
Voor sites die hun eigen houding overwegen: de mediane houding is stilte — 80% van de top 10k zegt niets over AI. De 17% die regels schrijft, clustert rond Disallow, maar een kleine, groeiende groep (de 1,5% expliciete Allow-GPTBot-lijst, aangevoerd door securityvendors) kiest publiekelijk het omgekeerde. Er is geen sectorsconsensus en die komt er de komende twaalf maanden ook niet.
Voor AI-operators: de stelling dat robots.txt een legacy protocol is met ambigue semantiek wordt steeds moeilijker vol te houden wanneer 17% van ’s werelds grootste sites expliciete, bewuste regels heeft geschreven die bots bij naam noemen, en 3,8% van de bestanden specifieke EU-wetgeving per artikelnnummer citeert. Of je die regels respecteert is een zakelijke keuze; of ze bestaan is nu een empirisch feit.
V. Vooruitblik: wat we verwachten tegen eind 2026
Drie trends die zichtbaar zijn in de dataset:
Cloudflare Managed zal zijn aandeel meer dan verdubbelen, waarschijnlijk tot 10%+ van de parseerbare top-10k. Cloudflare’s roadmap bespreekt openbaar een default-on Block AI Bots voor nieuwe accounts. Als de schakelaar standaard aan wordt geleverd, stijgt het wereldwijde blokkeercijfer met 5–8 procentpunten zonder dat een uitgever een beslissing neemt. We weten dat dit gebeurt wanneer het Cloudflare Managed-aandeel van de bucket 5.001–10.000 boven de huidige 5,7% uitkomt.
Sectieniveau-AI-beleid (in Spiegel-stijl) zal zich verspreiden onder de grote nieuwsflagships. De economische logica — laat AI laag-risicocontent citeren, bescherm de moat-content — is overtuigend genoeg om te verwachten dat minstens 10 extra toonaangevende redacties tegen eind 2026 sectieregels uitrollen. Kijk eerst naar de Duitse en Franse middenmoot; het juridische kader beloont daar experimenteren.
De expliciete Allow-GPTBot-cohort zal groeien, aangevoerd door B2B SaaS en ontwikkeltools. Zodra AI-zoekopdrachten een meetbaar acquisitiekanaal worden voor softwareleveranciers (zoals dat al het geval is voor security), zal de marginale CMO User-agent: GPTBot \n Allow: / schrijven om toevallige overblokkering te voorkomen. We verwachten dat de lijst van 108 sites tegen het einde van het jaar ongeveer zal verdubbelen.
Wat we niet verwachten: een betekenisvolle verandering in het aandeel stille meerderheid. De 80% van het web die niets over AI zegt, omvat sectoren (overheid, telecom, infrastructuur, B2B SaaS) waarvoor geen economische reden bestaat om een regel te schrijven en geen juridische druk om dat te doen. Universeel AI-beleid komt er niet.
VI. Beperkingen
- Bias van één momentopname. De fetches liepen over een venster van 36 uur in begin mei 2026. Het bestand wijzigt dagelijks aan de top 100; reken op 1–2 procentpunt drift per kwartaal op de headline-cijfers.
- Hiaten in sectorclassificatie. 6.593 van de 10.000 sites bleven
unknownna de vierlagige classifier. Sectoraandelen zijn robuust waar n groot is (nieuws: 650, streaming: 440, saas: 369, academia: 268, adult: 254, ecommerce: 224, gov: 172, finance: 129, dev: 129) en ruisiger onder n=30. De nieuwssplitsing per land is evenzeer beperkt — DE/FR/UK hebben n≥15, Korea/Zweden/Tsjechië rusten op n=20–25. robots.txtis vrijwillig. EenDisallowis een verzoek, geen barrière.Bytespider,PerplexityBoten anderen negeren gedocumenteerd regels. We hebben beleidsverklaringen gemeten, niet beleidsafdwinging.- Single-IP, VS-gebaseerde audit. We konden 21% van de opgeloste domeinen niet lezen. De meeste zijn CDN-apexpunten zonder webserver; een klein deel zijn sites waarvan het CDN ons blokkeerde voordat we de origin bereikten. Dit vertekent de steekproef licht in de richting van oudere infrastructuur en tegen country-of-origin-geofencing-sites in.
- Semantiek van de Tranco-lijst. Tranco filtert op stabiliteit; het is geen echte gebruiksvolgorde. Geaggregeerde cijfers zijn robuust tegen de lijsta keuze; specifieke rangposities niet.
- Geen verkeersdata. We hebben
robots.txt-beleid gemeten, niet het daadwerkelijke volume van AI-bots. Beleid en verkeer komen niet altijd overeen.
VII. Dit reproduceren
Alles wat is gebruikt om dit rapport te produceren, zit in de aflevermap.
- tranco_top10k.csv — invoerlijst
- out/sites.csv — domein × rang × sector × taal × robots.txt-status (10.000 rijen)
- out/fetch_meta.csv — fetch-uitkomst per domein (status, schema, bytes, fout)
- out/bot_status.csv — domein × bot-grid (250.000 rijen: geblokkeerd, heeft_regel, fetch_status)
- out/site_meta.csv — één analytisch record per site (sjabloon, samenvattingsbooleans)
- out/analysis.json — elke metriek die in het rapport wordt genoemd
- 01_fetch_robots.py, 02_classify.py, 03_parse_and_analyze.py — volledige Python-pipeline
Correcties op de methodologie, datasetproblemen en vervolganalyses zijn welkom via support@thunderbit.com. Dit rapport is onafhankelijk gepubliceerd van elke commerciële positie van Thunderbit; we bouwen een AI-gestuurde webscraper, en we hebben een structureel belang bij het feit dat robots.txt een betekenisvol, machineleesbaar contract op het openbare web blijft. De data in dit rapport staat op zichzelf. — Het Thunderbit-onderzoeksteam, mei 2026.