

De vraag naar hoogwaardige gelabelde data binnen machine learning is nog nooit zo groot geweest. Elke keer dat ik met teams praat die nieuwe AI-modellen bouwen — of het nu gaat om verkoopprognoses, productaanbevelingen of analyse van klantensentiment — komen steeds dezelfde knelpunten terug: data handmatig labelen is traag, duur en eerlijk gezegd ook behoorlijk vermoeiend. Ik heb projecten wekenlang (of zelfs maanden) stil zien vallen terwijl er werd gewacht op genoeg gelabelde voorbeelden om een fatsoenlijk model te trainen. En als labels niet consistent zijn? Nou ja, laten we zeggen dat de voorspellingen van je model dan ongeveer even betrouwbaar worden als mijn pogingen om parallel te parkeren.
Maar hier is het goede nieuws: geautomatiseerde datalabeling met machine learning verandert het speelveld. Door AI het zware werk te laten doen, versnellen bedrijven niet alleen het labelproces, maar verbeteren ze ook de nauwkeurigheid en consistentie — twee dingen die je ML-project kunnen maken of breken. In deze gids leg ik uit hoe geautomatiseerde datalabeling werkt, waarom het zo cruciaal is voor het bouwen van robuuste modellen, en hoe je tools zoals Thunderbit kunt gebruiken om je eigen geautomatiseerde labelingworkflow op te zetten — zonder code.
Wat is geautomatiseerde datalabeling met machine learning?
Laten we het eenvoudig houden. Geautomatiseerde datalabeling met machine learning betekent dat je algoritmen en AI-tools gebruikt om labels toe te kennen (zoals ‘spam’ of ‘geen spam’, ‘kat’ of ‘hond’, ‘positief’ of ‘negatief’) aan je ruwe data — zonder dat een mens elk afzonderlijk voorbeeld hoeft aan te klikken. Zie het als het verschil tussen duizenden vakantiefoto’s handmatig taggen en gezichtsherkenning gebruiken om ze automatisch te ordenen op persoon, locatie of zelfs stemming.
Traditionele handmatige labeling is precies wat het klinkt: mensen beoordelen data één item tegelijk en wijzen het juiste label toe. Het is nauwkeurig (soms), maar traag, duur en lastig op schaal te brengen. Geautomatiseerde labeling gebruikt daarentegen machine-learningmodellen — getraind op een kleinere set handmatig gelabelde data — om labels voor de rest van je dataset te voorspellen. Het resultaat? Snellere, consistentere en beter schaalbare labeling (GeeksforGeeks).
Voor zakelijke gebruikers betekent dit dat je betere modellen kunt bouwen, sneller, en met minder handwerk. En in de huidige datagedreven wereld is dat een serieus concurrentievoordeel.
Automatiseer datalabeling met Thunderbit Gebruik Thunderbit's AI-aangedreven webscraper om je datalabelingworkflow te automatiseren — zonder code. Get Started Free
Waarom geautomatiseerde datalabeling essentieel is voor hoogwaardige machine-learningmodellen
Hier draait het om: de kwaliteit van je gelabelde data heeft directe invloed op de prestaties van je machine-learningmodellen. Zoals het gezegde luidt: garbage in, garbage out. Als je labels inconsistent of onjuist zijn, leert je model de verkeerde patronen — en daar lijden je voorspellingen onder (DataCamp).
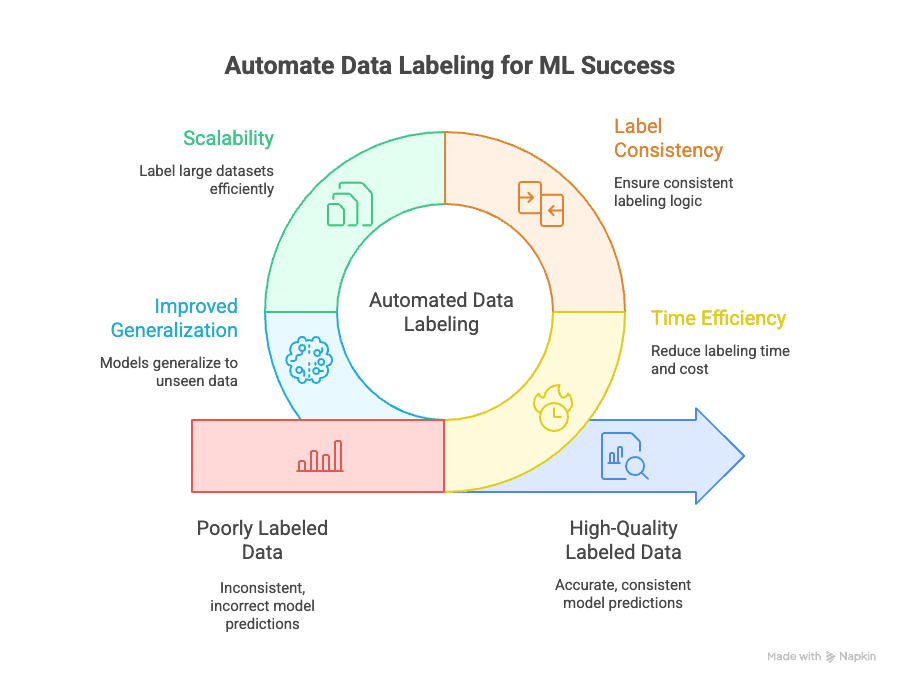
Geautomatiseerde datalabeling pakt verschillende belangrijke uitdagingen aan:
- Tijdsbesparing: Handmatige labeling kan 70% van de totale tijd en kosten van een ML-project opslokken. Automatisering brengt dat terug tot een fractie, zodat je sneller kunt itereren en modellen kunt uitrollen.
- Consistente labels: Machines worden niet moe en raken niet afgeleid. Geautomatiseerde labeling zorgt ervoor dat elk datapunt volgens dezelfde logica wordt gelabeld, waardoor menselijke fouten en bias afnemen (GeeksforGeeks).
- Schaalbaarheid: Moet je 10.000, 100.000 of zelfs een miljoen datapunten labelen? Automatisering maakt het mogelijk — zonder een leger annotatoren aan te nemen (Keylabs).
- Betere generalisatie: Consistente, hoogwaardige labels helpen je modellen beter te generaliseren naar nieuwe, nog niet geziene data, en dat is uiteindelijk het doel van machine learning (Kili Technology).
En de zakelijke impact is echt: Keylabs meldt dat hybride workflows waarin AI-ondersteunde labeling wordt gecombineerd met menselijke controle de labelnauwkeurigheid met tot wel 80% kunnen verbeteren ten opzichte van volledig handmatige processen. Dat vertaalt zich direct naar snellere modeliteraties en betrouwbaardere voorspellingen downstream.
Handmatige versus geautomatiseerde datalabeling vergeleken
Zet ze eens naast elkaar:
| Factor | Handmatige labeling | Geautomatiseerde labeling met ML |
|---|---|---|
| Snelheid | Traag (weken/maanden voor grote datasets) | Snel (minuten/uren voor grote datasets) |
| Nauwkeurigheid | Hoog, maar gevoelig voor menselijke fouten/inconsistentie | Hoog, met consistente logica en minder fouten |
| Schaalbaarheid | Beperkt door menselijke capaciteit | Schaalt moeiteloos naar miljoenen datapunten |
| Kosten | Duur (arbeidsintensief) | Lagere kosten op de lange termijn (Keylabs) |
| Het meest geschikt voor | Kleine, complexe of ambigue datasets | Grote, repetitieve of goed afgebakende datasets |
Handmatige labeling heeft nog steeds een plek — vooral bij randgevallen of ambigue data — maar voor de meeste zakelijke toepassingen is automatisering de beste keuze.
De basisstappen van geautomatiseerde datalabeling met machine learning
Hoe werkt geautomatiseerde datalabeling dan precies? Dit is de end-to-end workflow die ik aanbeveel (en zelf gebruik):
- Dataverzameling en voorbewerking
- Feature-extractie en voorbereiding
- Geautomatiseerde labeling met machine learning
- Kwaliteitscontrole en menselijke beoordeling
Laten we elke stap uitwerken.
Stap 1: Dataverzameling en voorbewerking
Voordat je iets kunt labelen, moet je je data verzamelen en opschonen. Dat kan betekenen dat je productvermeldingen van websites scraped, klantbeoordelingen exporteert of afbeeldingen uit interne databases verzamelt. De sleutel hier is kwaliteit: slechte data leidt tot slechte labels, en die leiden weer tot slechte modellen (Snorkel AI).
Best practices:
- Verwijder duplicaten en irrelevante items
- Standaardiseer formaten (datums, valuta, enz.)
- Pak ontbrekende of onvolledige data aan
Stap 2: Feature-extractie en voorbereiding
Vervolgens bepaal je welke kenmerken relevant zijn voor je labelingtaak. Als je bijvoorbeeld productvermeldingen labelt, kun je eigenschappen extraheren zoals prijs, merk, categorie en beschrijving. In sales of marketing kan dat betekenen dat je bedrijfsnamen, contactgegevens of sentiment uit e-mails haalt.
Zakelijk voorbeeld: Met Thunderbit kun je gestructureerde data van webpagina’s scrapen — zoals productspecificaties, reviews of contactgegevens — zonder ook maar één regel code te schrijven.
Stap 3: Geautomatiseerde labeling met machine learning
Hier gebeurt de magie. Je gebruikt machine-learningmodellen (getraind op een kleinere, handmatig gelabelde dataset) om labels voor de rest van je data te voorspellen. Veelgebruikte technieken zijn onder meer:
- Supervised modellen: Train een classifier op gelabelde voorbeelden en gebruik die vervolgens om nieuwe data te labelen.
- Regelgebaseerde labeling: Gebruik vooraf gedefinieerde regels (bijv. ‘als de prijs > €1000 is, label als “premium”’) voor eenvoudige gevallen.
- Active learning: Het model vraagt om menselijke input bij onzekere gevallen, waardoor het in de loop van de tijd beter wordt (GeeksforGeeks).
- Transfer learning: Gebruik voorgetrainde modellen om labeling in nieuwe domeinen sneller op gang te brengen (GeeksforGeeks).
Het resultaat? Consistente, hoogwaardige labels — op schaal.
Stap 4: Kwaliteitscontrole en menselijke beoordeling
Zelfs de beste modellen hebben een sanity check nodig. Periodieke menselijke controle helpt om randgevallen, ambigue data of modeldrift op te vangen. Praktische QA-stappen zijn onder andere:
- Neem willekeurig gelabelde data steekproefsgewijs door voor handmatige controle
- Vergelijk geautomatiseerde labels met een ‘gold standard’-set
- Gebruik inter-annotator-agreement-metrics om consistentie te meten (Kili Technology)
Hoe je Thunderbit gebruikt voor geautomatiseerde datalabeling met machine learning
Tijd om praktisch aan de slag te gaan. Thunderbit is een AI-aangedreven webscraper en datalabelingtool voor zakelijke gebruikers — zonder code. Zo kun je het gebruiken om je datalabelingworkflow te automatiseren:
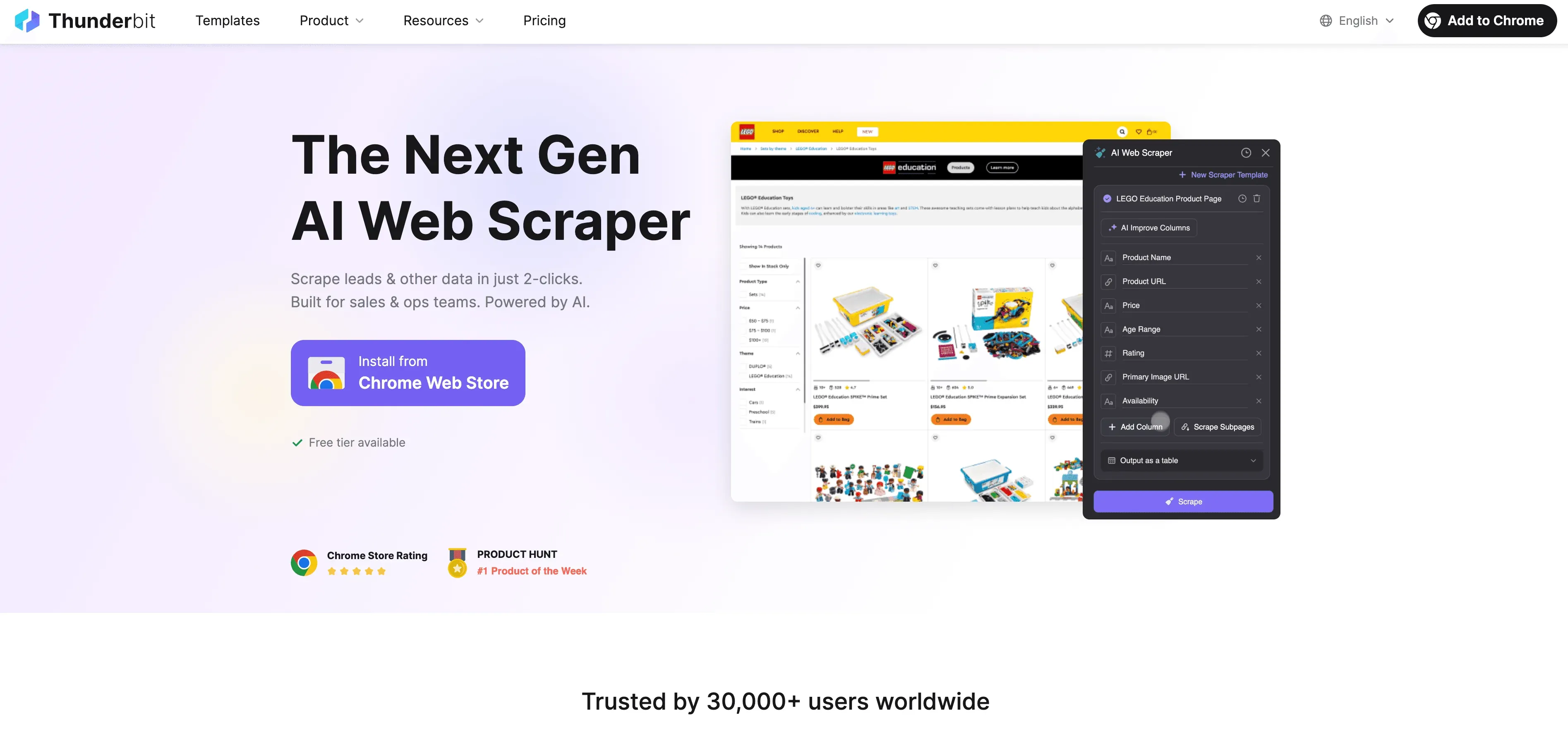
Stapsgewijze handleiding
- Scrape websitegegevens: Gebruik de Thunderbit Chrome-extensie om gestructureerde data van elke website te verzamelen. Open gewoon de extensie, selecteer je databron en laat Thunderbit's AI de beste velden voorstellen om te extraheren.
- Bepaal labelinstructies: Gebruik Thunderbit’s prompts in natuurlijke taal om de AI te vertellen hoe je data gelabeld moet worden. Bijvoorbeeld: “Label alle producten boven €500 als ‘premium’” of “Tag reviews met positief sentiment.”
- Pas geautomatiseerde labeling toe: Met Thunderbit’s Field AI Prompt-feature kun je verfijnen en aanpassen hoe labels worden toegekend — ideaal voor labeltaken met meerdere velden of complexe logica.
- Exporteer gelabelde data: Zodra je data is gelabeld, exporteer je die rechtstreeks naar Excel, Google Sheets, Airtable of Notion — klaar voor modeltraining of analyse.
Het mooiste is dat Thunderbit is gebouwd voor niet-technische gebruikers in sales, marketing, operations en daarbuiten. Je hoeft geen regel code te schrijven of te worstelen met ingewikkelde templates.
Probeer Thunderbit voor geautomatiseerde datalabeling
Thunderbit’s prompts in natuurlijke taal en Field AI-functies
Een van mijn favoriete functies is dat je label-logica in gewone taal kunt definiëren. Wil je leads indelen per regio, producten taggen op categorie of e-mails met urgente taal markeren? Beschrijf gewoon wat je wilt, en Thunderbit’s AI doet de rest.
Voorbeeldprompts:
- “Label alle contacten met een ‘.edu’-e-mailadres als segment ‘Onderwijs’.”
- “Als de review ‘snelle verzending’ noemt, tag dan als ‘Positieve verzendervaring’.”
- “Groepeer producten op merk en prijsklasse.”
Met Thunderbit’s Field AI Prompt kun je nog verder verfijnen — label-logica per kolom aanpassen, regels combineren of labels zelfs vertalen naar meerdere talen.
Subpages scrapen en meerdere velden labelen
Complexe datastructuren? Geen probleem. Met Thunderbit’s subpage-scrapingfunctie kun je data uit geneste pagina’s extraheren en labelen (zoals productdetails of auteursbio’s) en alles samenvoegen in één gestructureerde tabel. Je kunt meerdere velden tegelijk labelen — dat scheelt nog meer tijd.
Praktijkvoorbeeld: Productvermeldingen van een e-commercewebsite scrapen en vervolgens elk product doorlinken om specificaties, reviews en verkopersinformatie te extraheren en te labelen — allemaal in één workflow.
Meerdere datalabelingtools integreren voor meer nauwkeurigheid en efficiëntie
Hoewel Thunderbit een groot deel van de workflow afdekt, heb je soms gespecialiseerde tools nodig voor bepaalde datatypes — zoals afbeeldingannotatie of videolabeling. Daar komen platforms zoals Label Studio of Supervisely van pas.
Pro-tip: Gebruik Thunderbit voor webdata-extractie en eerste labeling, en exporteer daarna je data naar Label Studio of Supervisely voor geavanceerde annotatie (zoals bounding boxes op afbeeldingen of frame-voor-frame videotags). Met deze multi-tool-aanpak benut je de sterke punten van elk platform, wat zowel de nauwkeurigheid als de efficiëntie verhoogt (GeeksforGeeks).
Wanneer je gespecialiseerde tools naast Thunderbit gebruikt
- Afbeeldingen annoteren: Gebruik Supervisely of Label Studio voor taken zoals objectdetectie of segmentatie.
- Video labelen: Gespecialiseerde videotools ondersteunen frame-voor-frame annotatie en tracking.
- Complexe multi-labeltaken: Combineer Thunderbit’s gestructureerde data-extractie met geavanceerde annotatietools voor het beste resultaat.
Best practice: Begin met Thunderbit voor snelle, schaalbare labeling van gestructureerde en semi-gestructureerde data, en schakel gespecialiseerde tools in wanneer diepere annotatie nodig is.
Hoe je data uit PDF’s scrapt met AI Leer hoe je data uit PDF’s kunt extraheren en labelen met Thunderbit's AI-aangedreven tools. Get Started Free
Best practices voor geautomatiseerde datalabeling met machine learning
Wil je het maximale uit je geautomatiseerde labelingworkflow halen? Hier zijn mijn beste tips:
- Definieer duidelijke labelrichtlijnen: Ambigue labels leiden tot inconsistente data — wees specifiek over wat elk label betekent.
- Begin met een hoogwaardige seed set: Label handmatig een kleine, representatieve steekproef om je eerste model te trainen.
- Itereer en verbeter: Gebruik active learning om je model in de loop van de tijd te verfijnen, en concentreer menselijke controle op de lastigste gevallen.
- Valideer regelmatig: Controleer periodiek een willekeurige steekproef van gelabelde data om fouten of drift op te sporen.
- Integreer en automatiseer: Gebruik tools zoals Thunderbit om dataverzameling, labeling en export in één workflow te verbinden.
Veelvoorkomende uitdagingen en hoe je ze overwint
Geautomatiseerde datalabeling is niet zonder obstakels. Zo pak je de meest voorkomende aan:
- Ambigue data: Gebruik duidelijke, gedetailleerde labeldefinities en geef voorbeelden voor randgevallen.
- Modeldrift: Train je labelingmodel regelmatig opnieuw met nieuwe, handmatig gecontroleerde data.
- Randgevallen: Zet een proces op voor menselijke beoordeling van onzekere of nieuwe datapunten.
- Integratieproblemen: Kies tools (zoals Thunderbit) die eenvoudig exporteren naar je favoriete platforms.
Conclusie en belangrijkste inzichten
Geautomatiseerde datalabeling met machine learning is het geheime ingrediënt achter de meest effectieve AI-modellen van vandaag. Het bespaart tijd, verlaagt kosten en — het allerbelangrijkste — levert de consistente, hoogwaardige labels die je modellen nodig hebben om optimaal te presteren. Door tools zoals Thunderbit te combineren met gespecialiseerde annotatieplatforms, kun je een labelingworkflow bouwen die snel, nauwkeurig en schaalbaar is — ongeacht je technische achtergrond.
Klaar om zelf het verschil te zien? Download Thunderbit, probeer geautomatiseerde labeling uit op je volgende project en zie hoe je machine-learningmodellen slimmer en sneller worden. En als je meer tips en best practices wilt, bekijk dan de Thunderbit Blog voor diepgaande artikelen en tutorials.
Automatiseer datalabeling met Thunderbit
Veelgestelde vragen
1. Wat is geautomatiseerde datalabeling met machine learning?
Dat is het proces waarbij AI- en ML-modellen automatisch labels toekennen aan data, in plaats van dat mensen dit handmatig doen. Deze aanpak versnelt het labelen, verbetert de consistentie en schaalt goed op naar grote datasets.
2. Waarom is labelkwaliteit belangrijk voor machine learning?
Modellen leren alleen de patronen die in hun labels zitten, dus inconsistente of verkeerde labels leren het model de verkeerde dingen aan. Praktijkartikelen van labelingleveranciers zoals Keylabs laten zien dat hybride AI-plus-menselijke workflows de labelnauwkeurigheid met tot wel 80% kunnen verhogen ten opzichte van puur handmatige processen — en die winst zie je rechtstreeks terug in modelprestaties.
3. Hoe helpt Thunderbit bij geautomatiseerde datalabeling?
Thunderbit laat je webdata scrapen en labelen met AI, met prompts in natuurlijke taal en aanpasbare veldlogica — zonder code. Het is ideaal voor zakelijke gebruikers in sales, marketing en operations.
4. Kan ik Thunderbit combineren met andere labelingtools?
Absoluut. Gebruik Thunderbit voor gestructureerde data-extractie en eerste labeling, en exporteer daarna naar tools zoals Label Studio of Supervisely voor geavanceerde afbeelding- of video-annotatie.
5. Wat zijn de best practices voor geautomatiseerde datalabeling?
Definieer duidelijke labelrichtlijnen, begin met een kwalitatieve seed set, werk iteratief met active learning, valideer regelmatig en gebruik geïntegreerde tools om je workflow te stroomlijnen.
Klaar om je datalabeling te automatiseren en je machine-learningprojecten een boost te geven? Probeer Thunderbit en ontdek hoeveel tijd — en frustratie — je kunt besparen.
Meer lezen:
- Hoe je data uit PDF’s scrapt met AI
- Wat is data scraping en hoe doe je het in 2025
- Wat is list crawling en hoe doe je het met AI
- Hoe je elke website scraped met AI
Probeer AI-webscraper voor geautomatiseerde datalabeling Get Started Free




