

Er web scraping ulovlig? Det er millionkronerspørsmålet jeg hører fra gründere, markedsførere og dataentusiaster hver eneste uke.
Med 51 % av all internettrafikk som nå kommer fra boter—første gang automatisk trafikk har passert menneskelig aktivitet—og en stor andel av dette som web scraping for forretningsinnsikt, salg og AI-trening, er det ikke rart at alle prøver å finne ut hvor de juridiske grensene går.
Én dag ser du en overskrift om en dom som sier at scraping av offentlige data er helt greit. Neste dag advarer regulatorer mot «ulovlig» datainnsamling fra sosiale medier. Det er forvirrende, selv for folk som meg som bruker dagene på å bygge AI web scraping-verktøy hos Thunderbit.
Så, er web scraping ulovlig? Svaret er verken et enkelt ja eller nei. Det kommer an på hva du scraper, hvor du scraper det fra, hvordan du bruker dataene, og hva loven sier i landet ditt.
I denne grundige gjennomgangen forklarer jeg det juridiske landskapet, avliver noen vanlige myter og deler praktiske råd (pluss et par lærdommer fra virkeligheten) for å holde deg innenfor regelverket—enten du er en sologründer eller et datateam i et Fortune 500-selskap.
Web scraping og loven: Finnes det en klar grense?
Hvis du håper på et svar i én setning, sparer jeg deg litt tid: loven har ikke trukket en tydelig og klar grense for web scraping.
I stedet finnes det et lappeteppe av overlappende regler—dataeierskap, personvern, immaterielle rettigheter, anti-hacking-lover og de beryktede bruksvilkårene (ToS). Alle kan komme inn i bildet, og svaret avhenger ofte av den konkrete situasjonen din (multilogin.com).
La oss dele det inn i tre store juridiske kategorier:
- Dataeierskap: Generelt er fakta og offentlig informasjon (som priser eller telefonnumre) ikke opphavsrettsbeskyttet. Men kreativt innhold (artikler, bilder) og proprietære databaser kan være beskyttet—særlig i EU, der «database rights» finnes (cliffordchance.com).
- Personvern: Moderne personvernlovgivning (tenk GDPR i Europa, PIPL i Kina) behandler personopplysninger som en regulert ressurs—selv om de er publisert offentlig. Å scrape navn, e-poster eller profiler i sosiale medier uten gyldig behandlingsgrunnlag kan fort gi deg problemer (ico.org.uk).
- Kontrakter (bruksvilkår): Mange nettsteder forbyr eksplisitt scraping i ToS. Selv om ToS ikke er lover, kan domstoler behandle dem som bindende kontrakter. Brudd kan føre til søksmål, og i noen tilfeller til og med utløse anti-hacking-bestemmelser hvis du omgår tekniske sperrer (cliffordchance.com).
Så, er web scraping ulovlig? Noen ganger ja, noen ganger nei, og ofte «det kommer an på». Det er detaljene som avgjør.
Sammenligning av juridiske perspektiver: USA, EU, Storbritannia, Kina
Her er en rask tabell som viser hvordan store regioner ser på web scraping:
| Region | Scraping av offentlige data | Scraping av personlige/private data | Håndheving og viktige punkter |
|---|---|---|---|
| USA | Vanligvis tillatt for offentlige data (se hiQ v. LinkedIn). Brudd på ToS kan føre til sivile søksmål. | Begrenset/ulovlig hvis du bryter innlogging eller misbruker personopplysninger. Delstatslover (som CCPA) kan gjelde. | Pålegg om å stanse, IP-blokkering, søksmål. CFAA gjelder hvis du omgår tekniske barrierer. |
| EU | Tillatt på vilkår for ikke-personlige, offentlige data. Database rights kan gjelde. EU AI Act (2026) legger til krav om åpenhet for AI-treningsdata. | Strengt regulert under GDPR—selv offentlig tilgjengelige personopplysninger må ha et rettslig grunnlag. | Datatilsyn kan ilegge bøter ved personvernbrudd. Opphavsrett og database rights håndheves også. EU AI Act forbyr scraping av ansiktsbilder til AI. |
| Storbritannia | Ligner på EU. Offentlige, ikke-personlige data kan scrapes, men du må respektere datar rettigheter og kontrakter. | Strengt når det gjelder personopplysninger—UK GDPR gjelder. Computer Misuse Act kriminaliserer uautorisert tilgang. | ICO kan sanksjonere brudd på personvernreglene. Domstoler kan håndheve ToS. |
| Kina | Strengt kontrollert. Offentlige, ikke-personlige data kan scrapes til intern bruk, men miljøet er forsiktig. | Sterkt begrenset—PIPL krever samtykke for personopplysninger. Lover mot illojal konkurranse gjelder. | Straffesaker ved storskala scraping. Domstoler bruker konkurranserett til å stanse uautorisert scraping. |
Er web scraping ulovlig? Viktige juridiske faktorer å vurdere
Så hva er det egentlig som avgjør om scraping-prosjektet ditt er lovlig eller risikabelt? Her er de viktigste faktorene:
- Offentlige vs. private data: Å scrape data alle kan se på det åpne nettet er som regel tryggere. Å scrape noe som ligger bak innlogging, betalingsmur eller teknisk sperre? Det er sannsynligvis ulovlig (thunderbit.com).
- Datatypen: Personopplysninger (navn, e-poster, profiler) utløser personvernlovgivning. Opphavsrettsbeskyttet innhold (artikler, bilder) kan ikke kopieres i sin helhet. Rene fakta (priser, vær) er vanligvis fritt frem (oxylabs.io).
- Tilsiktet bruk: Intern analyse eller forskning vurderes som regel mildere enn republisering eller salg av scraped data. Å bruke scraped data til å konkurrere direkte med kilden? Det er et søksmål som venter på å skje (thunderbit.com).
- Etterlevelse av nettstedets regler: Sjekk alltid robots.txt og ToS. Robots.txt er ikke juridisk bindende, men det er god praksis å respektere den. Brudd på ToS kan føre til sivile søksmål eller verre (promptcloud.com).
- Tekniske tiltak: Det er viktig å scrape i menneskelignende tempo og ikke omgå sikkerhetstiltak. Å hamre løs på en server eller lure seg unna CAPTCHA-er kan krysse grensen til hacking (cliffordchance.com).
Hva som endret seg i 2024–2026: Viktige dommer og reguleringer
Det juridiske landskapet for web scraping har endret seg dramatisk siden 2023. Her er utviklingen alle som scraper bør kjenne til:
Viktige rettsavgjørelser
-
Meta v. Bright Data (2024): En amerikansk føderal domstol fastslo at Metas bruksvilkår ikke forbyr scraping av offentlige data av brukere som ikke er innlogget. Dommeren mente at «en besøkende ikke regnes som en ‘user’ med mindre vedkommende har en konto». Meta trakk resten av kravene kort tid etter. Dette er en historisk seier for scraping av offentlige data.
-
X Corp v. Bright Data (2024): Twitter (nå X) tapte en lignende sak, noe som forsterket det samme prinsippet: scraping av offentlig tilgjengelige data uten innlogging er ikke et brudd på ToS, fordi scraperen aldri godtok vilkårene.
-
Reddit v. Perplexity AI (oktober 2025): Reddit saksøkte Perplexity AI og flere scraping-leverandører, med henvisning til DMCA og påstand om omgåelse av anti-bot-systemer. Dette signaliserer en ny juridisk strategi: plattformer går i økende grad til opphavsrett og krav om omgåelsesforbud i stedet for CFAA.
-
NYT v. OpenAI (mars 2025): En føderal dommer tillot at New York Times' opphavsrettssak mot OpenAI kunne fortsette, og avviste OpenAIs krav om å få saken avvist. Dette kan bli en viktig presedens for om scraping av innhold for å trene AI-modeller regnes som «fair use».
-
Anthropic-forliket (september 2025): Anthropic gikk med på å betale 1,5 milliarder dollar for å gjøre opp i et amerikansk gruppesøksmål om bruk av opphavsrettsbeskyttede tekster til å trene AI-modellen deres—et tydelig tegn på at kostnadene ved scraping for AI er svært reelle.
Den store trenden: Fra CFAA til kontrakts- og opphavsrettslov
Mønsteret er tydelig: CFAA (Computer Fraud and Abuse Act) mister kraft som våpen mot scrapers av offentlige data. Selskaper som forsøkte å bruke CFAA mot scraping av offentlige data—Meta, X, LinkedIn—har i stor grad mislyktes. I stedet flyttes den juridiske kampen til:
- Kontraktsrett (brudd på ToS—men domstolene sier at ikke-brukere ikke er bundet av ToS)
- Opphavsrettskrav (særlig for AI-treningsdata)
- Anti-omgåelsesbestemmelser (DMCA § 1201)
For scrapers betyr dette at den juridiske risikoen ikke har forsvunnet—den har bare flyttet seg.
Regulatoriske endringer
- CCPA-oppdateringer for 2026: Californias reviderte CCPA-regler trådte i kraft 1. januar 2026, med nye regler for teknologi for automatisert beslutningstaking (ADMT), risikovurderinger og plikter for dataformidlere.
- Nye personvernlovene i USA: Indiana, Kentucky og Rhode Island vedtok omfattende personvernlovgivning som gjelder fra 2026.
- EU AI Act: Full håndheving starter 2. august 2026—det krever at AI-utviklere opplyser om treningsdatakilder, respekterer reservasjonsmuligheter for opphavsrett og forbyr scraping av ansiktsbilder for AI-systemer.
- AI Accountability for Publishers Act (februar 2026): Et foreslått amerikansk lovforslag som vil kreve at AI-selskaper får tillatelse og betaler utgivere før de scraper innholdet deres.
Scraping-regler hos store plattformer: Dette må du vite
Ikke alle nettsteder behandler scraping likt. Her er en plattform-for-plattform-gjennomgang av hva de største sidene tillater, hva de blokkerer, og hva domstolene har sagt:
| Plattform | ToS om scraping | Tekniske forsvar | Juridisk håndheving | Hva som er praktisk trygt |
|---|---|---|---|---|
| Google (Søk og Maps) | Forbyr automatisert tilgang i ToS. Maps Platform har en eksplisitt «No Scraping»-bestemmelse. | SearchGuard JS-utfordringer, CAPTCHA-er, hastighetsbegrensning. Oppdatert robots.txt i 2025 for å blokkere AI-crawlere. | Saksøkte scrapers i desember 2025 med DMCA. Blokkerer aktivt AI-crawlere (Anthropic, Meta, OpenAI). | Scraping av offentlige Google Maps-forretningsdata er juridisk forsvarlig (hiQ-presedens), men forvent tekniske sperrer. Bruk offisielle API-er når det er mulig. |
| Amazon | Forbyr uttrykkelig all scraping i bruksvilkårene («no robot, spider, scraper, or other automated means»). | Aggressiv botdeteksjon, CAPTCHA, IP-blokkering. robots.txt blokkerer alle boter bortsett fra Googlebot/Bingbot. Blokkerer uttrykkelig AI-crawlere siden 2025. | Saksøkte Perplexity AI i november 2025. Sender jevnlig brev med krav om å stanse. Oppdatert BSA i mars 2026 med regler for AI-agenter. | Offentlige produktdata (priser, oppføringer) er fakta og kan scrapes etter amerikansk lov, men Amazon kjemper hardt imot. Begrens forespørsler og unngå personopplysninger. |
| Forbyr scraping i ToS; krever brukersamtykke for å få tilgang til tjenestene. | Innloggingsmurer for mesteparten av profildataene, anti-bot-deteksjon, hastighetsbegrensning. | hiQ-saken bekreftet at scraping av offentlige profiler ikke er brudd på CFAA, men LinkedIn vant på kontrakts- og illojal konkurranse-krav da falske kontoer ble brukt. | Offentlige profiler (synlige uten innlogging) er juridisk forsvarlige å scrape. Opprett aldri falske kontoer eller scrape innloggede data. | |
| Meta (Facebook og Instagram) | ToS forbyr scraping; egne regler for innloggede og utloggede data. | Innloggingsmurer for det meste av innholdet, avansert botdeteksjon. | Tapte mot Bright Data i 2024—domstolen slo fast at ToS ikke gjelder for scrapers som ikke er innlogget. Trakk resten av kravene. | Offentlige data (bedriftssider, offentlige innlegg) som er synlige uten innlogging står på tryggere grunn. Scrape aldri private profiler eller data bak innlogging. |
| X (Twitter) | Oppdaterte ToS i 2023 for å forby all scraping og crawling uten skriftlig samtykke. Fjernet det gamle unntaket for robots.txt. | robots.txt blokkerer alle crawlere (Disallow: /). Cloudflare Turnstile-utfordringer. Strenge hastighetsgrenser (300 forespørsler/time). IP-omdømmescore. | Tapte mot Bright Data på offentlige data, men begrenser fortsatt teknisk tilgang hardt. | Offentlige tweets og profiler er juridisk forsvarlige, men Xs tekniske barrierer er blant de tøffeste i 2026. Forvent blokkeringer uten premium proxy-infrastruktur. |
Hovedpoenget: Domstolene har konsekvent slått fast at scraping av offentlig synlige data uten innlogging ikke bryter CFAA. Men plattformer kan fortsatt gå etter deg med kontraktsrett, opphavsrett eller regler mot omgåelse—og de vil gjøre livet ditt vanskelig med tekniske barrierer. Scrape alltid ansvarlig.
AI-treningsdata og web scraping: Den nye juridiske fronten
Hvis du følger med på nyhetene i 2026, vet du at å scrape data for å trene AI-modeller har blitt den heteste juridiske slagmarken. Dette skjer nå:
- Opphavsrettssøksmålene kommer på løpende bånd. New York Times, forfattere og utgivere har saksøkt OpenAI, Anthropic og andre, og hevder at masseskraping av opphavsrettsbeskyttet innhold for å trene LLM-er ikke er «fair use». Anthropic gjorde opp i et stort gruppesøksmål for 1,5 milliarder dollar i 2025—et tydelig signal om at kostnadene ved scraping for AI er svært reelle.
- Forsvaret med «fair use» er usikkert. Amerikanske domstoler har ennå ikke avsagt en endelig dom om hvorvidt trening av AI på scraped data er fair use. Tidlige avgjørelser tyder på at det i stor grad avhenger av hvordan dataene ble innhentet og hva som gjøres med AI-resultatet.
- Ny lovgivning er på vei. AI Accountability for Publishers Act (fremlagt i februar 2026) har som mål å kreve at AI-selskaper får tillatelse og betaler utgivere før de scraper innholdet deres.
- EU AI Act (full håndheving august 2026) krever at AI-utviklere opplyser om treningsdatakilder, respekterer maskinlesbare reservasjonsmuligheter for opphavsrett (under TDM-unntaket i opphavsrettsdirektivet) og merker AI-generert innhold. Den forbyr også AI-systemer som scraper ansiktsbilder fra internett.
- AI/LLM-crawlere eksploderer. AI-crawlere firedoblet andelen av nettrafikken sin fra 2,6 % til 10,1 % på bare åtte måneder. OpenAIs GPTBot alene vokste med 305 %. Som svar oppdaterer store nettsteder (Amazon, Reddit, NYT) robots.txt for uttrykkelig å blokkere AI-crawlere.
Hva dette betyr for deg: Hvis du scraper data til tradisjonelle forretningsformål (leadgenerering, prisovervåking, markedsundersøkelser), gjelder kanskje ikke disse AI-spesifikke reglene direkte. Men hvis du mater scraped data inn i AI-modeller, må du gå svært forsiktig frem—og få juridisk råd.
Web scraping-lover rundt om i verden: En rask sammenligning
La oss zoome ut og se hvordan reglene slår ut globalt:
- USA: Ikke noe generelt forbud. Scraping av offentlig tilgjengelige nettsteder er som regel lovlig (hiQ v. LinkedIn), og dommene mot Meta og X Corp i 2024 har styrket saken for scraping av offentlige data ytterligere. Men scraping bak innlogging eller tekniske sperrer kan fortsatt utløse CFAA. Nå går utviklingen mer mot at selskaper bruker kontraktsrett og opphavsrettskrav i stedet. Personvernlovene vokser raskt: CCPA fikk store oppdateringer med virkning fra 1. januar 2026, inkludert nye regler for automatisert beslutningstaking og plikter for dataformidlere. Indiana, Kentucky og Rhode Island vedtok også omfattende personvernlovgivning i 2026.
- EU: Strenge personvernregler. GDPR gjelder selv for offentlige personopplysninger. Database rights kan stanse storskala scraping av strukturerte data (cliffordchance.com). NYTT: EU AI Act trer inn i full håndheving 2. august 2026, og krever at AI-utviklere opplyser om treningsdatakilder og respekterer reservasjonsmuligheter for opphavsrett. Loven forbyr scraping av ansiktsbilder fra internett for AI-systemer.
- Storbritannia: Ligner på EU-reglene etter Brexit. Offentlige data kan scrapes, men scraping av personopplysninger er strengt regulert. Computer Misuse Act kan kriminalisere uautorisert tilgang.
- Kina: Veldig restriktivt. PIPL og Data Security Law krever samtykke for personopplysninger. Domstoler bruker konkurranserett til å stanse scraping som skader virksomheter (malwarebytes.com).
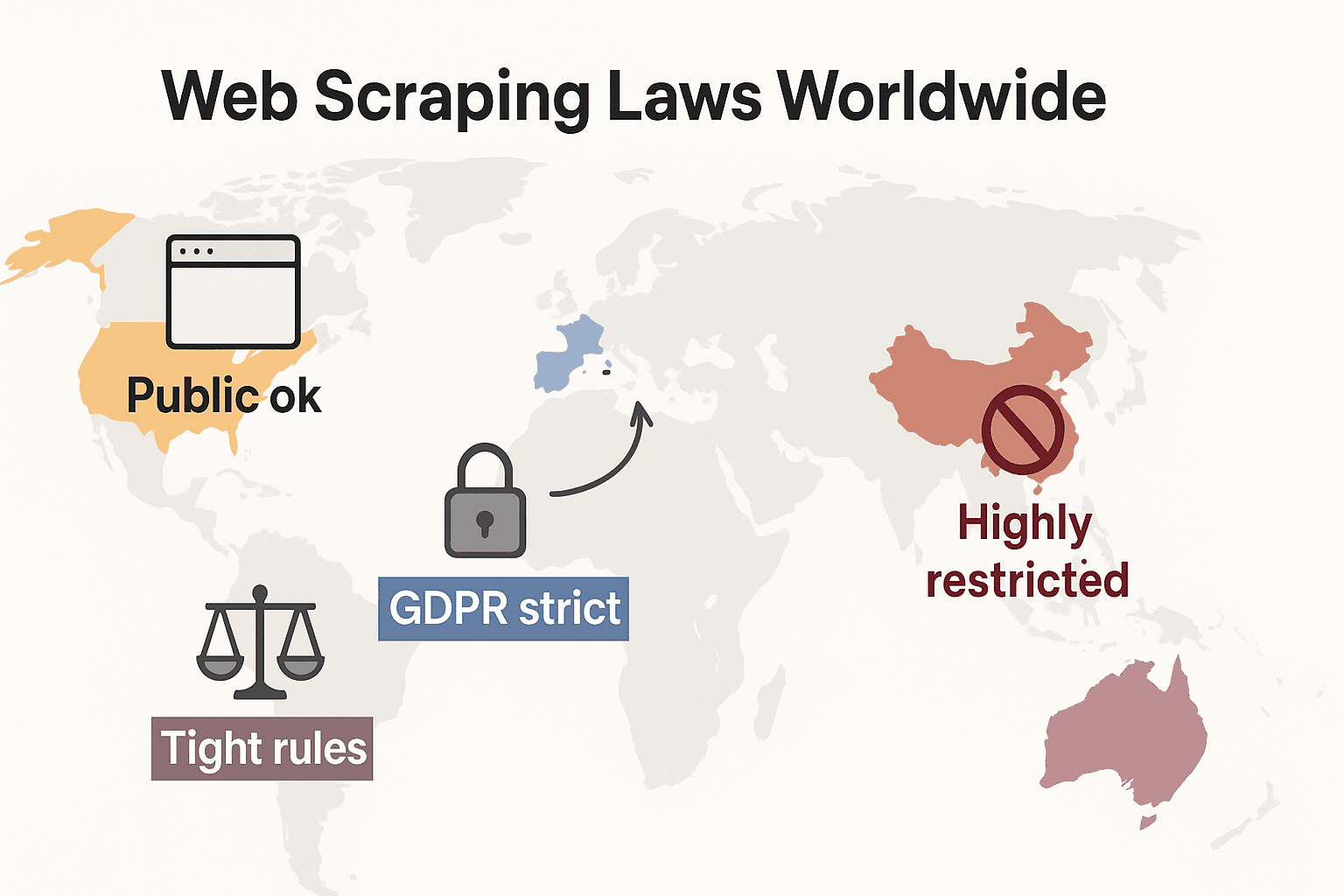
Konklusjonen er enkel: å scrape offentlige, ikke-personlige data til intern bruk er som regel det tryggeste. Alt annet? Sjekk de lokale lovene og vær forsiktig.
Vanlige myter om lovligheten av web scraping
La oss avlive noen myter jeg hører hele tiden:
- Myte 1: «Web scraping er ulovlig, punktum.»
Feil. Det finnes ingen lov som forbyr all web scraping. Det er hvordan og hva du scraper som betyr noe (oxylabs.io). - Myte 2: «Hvis data er offentlige, kan jeg gjøre hva jeg vil med dem.»
Ikke helt. Offentlige data kan fortsatt være beskyttet av personvern- eller opphavsrettslovgivning, og ToS kan begrense visse bruksområder (ico.org.uk). - Myte 3: «Web scraping er det samme som hacking.»
Nei. Å scrape offentlige nettsider er ikke hacking. Å omgå innlogging eller tekniske barrierer er noe helt annet (calawyers.org). - Myte 4: «Hvis jeg ikke blir tatt, går det fint.»
Risikabel tankegang. Mange nettsteder bruker anti-bot-teknologi og vil oppdage deg. Stillhet er ikke samtykke. - Myte 5: «Hvis jeg gir kreditering eller bruker dataene internt, er det greit.»
Kreditering overstyrer ikke opphavsrett eller personvernregler. Intern bruk er tryggere, men det er ikke frikort. - Myte 6: «All web scraping bryter personvernet.»
Ikke all scraping innebærer personopplysninger. Men scraping av store mengder personinformasjon uten sikkerhetstiltak er nesten alltid ulovlig (oxylabs.io). - Myte 7: «Hvis nettstedets ToS forbyr scraping, er det alltid ulovlig å scrape.»
Ikke nødvendigvis. I 2024 slo domstolene i Meta v. Bright Data og X Corp v. Bright Data fast at ToS ikke kan binde brukere som aldri har godtatt dem—altså, hvis du scraper uten å logge inn eller opprette en konto, kan nettstedets ToS hende at ikke gjelder for deg. Dette er fortsatt et område i utvikling, men det er et viktig skifte.
Hvordan scrape data lovlig: Beste praksis for etterlevelse
Her er sjekklisten min for lovlig og etisk web scraping:
- Les og respekter nettstedets bruksvilkår. Hvis det står «no scraping», bør du vurdere å stoppe eller be om tillatelse (ql2.com).
- Hold deg til offentlige data. Hvis du trenger et passord, er dataene begrenset—ikke scrape dem (thunderbit.com).
- Sjekk robots.txt og crawl høflig. Ikke juridisk bindende, men god etikette. Ikke overbelast servere—spred forespørslene dine (promptcloud.com).
- Unngå personopplysninger med mindre du har et lovlig grunnlag. Hvis du må samle dem inn, følg GDPR/CCPA og minimer mengden du samler inn.
- Ikke republiser scraped innhold i sin helhet. Legg til verdi eller analyse, eller få tillatelse (thunderbit.com).
- Ikke mat scraped innhold inn i AI-modeller uten å sjekke opphavsretten. Det juridiske landskapet endrer seg raskt—få råd hvis dette er bruksområdet ditt.
- Bruk offisielle API-er eller dataeksporter når de finnes. De er laget for dette formålet og er som regel tryggere (thunderbit.com).
- Vær åpen og ansvarlig. Hvis du samler inn personopplysninger, informer folk og før logg over aktivitetene dine.
- Minimer og sikre dataene dine. Samle bare inn det du trenger, hold dem oppdaterte og lagre dem trygt.
- Hold deg oppdatert og søk juridisk hjelp ved grensetilfeller. Lover og dommer endrer seg raskt—særlig EU AI Act og delstatslover om personvern i USA. Når du er i tvil, spør en fagperson.
Prøv Thunderbit Chrome-utvidelsen for etterlevelsesvennlig scraping
Bruk av web scraping-verktøy lovlig: Hva bedrifter må vite
Web scraping-verktøy som Thunderbit gjør datainnsamling tilgjengelig for folk uten kodeferdigheter, men du må fortsatt bruke dem ansvarlig:
- Velg verktøy med fokus på etterlevelse. Thunderbit scraper for eksempel bare det du kan se i nettleseren din—ingen skjulte API-triks eller uautorisert tilgang (thunderbit.com).
- Hold deg til legitime bruksområder. Intern analyse, markedsundersøkelser og overvåking av konkurrenters priser er som regel trygt. Republisering eller salg av scraped data? Mye mer risikabelt.
- Konfigurer verktøyene for etterlevelse. Sett forsinkelser mellom crawlene, følg robots.txt og bruk maler som bare samler inn det du trenger.
- Hold det internt. Å bruke scraped data internt er tryggere enn å republisere dem.
- Lær opp teamet ditt. Sørg for at alle forstår reglene og beste praksis.
- Utnytt innebygde funksjoner for etterlevelse. Thunderbit varsler brukere om risikable nettsteder, scraper i menneskelignende tempo og lagrer ikke dataene dine på serverne sine.
- Ikke tving det fram. Hvis et verktøy ikke kan scrape et nettsted, ikke prøv å hacke deg rundt det. Ikke all data kan hentes uten risiko.
Thunderbits tilnærming: AI web scraping som er i tråd med regelverket
Hos Thunderbit har vi brukt mye tid på å tenke på etterlevelse. Slik hjelper vår AI Web Scraper brukere med å holde seg på riktig side av loven:
- Scraper bare det du kan se. Thunderbit jobber i nettlesersesjonen din, så den kan ikke få tilgang til data du ikke kunne kopiert manuelt.
- Veileder brukerne med advarsler. Hvis du prøver å scrape et nettsted med strenge anti-scraping-regler, varsler Thunderbit deg.
- Menneskelignende hastighet. Enten du scraper lokalt eller i skyen, unngår Thunderbit å hamre løs på servere.
- Tilpasset datavalg. AI-en vår foreslår relevante kolonner, slik at du bare samler inn det du trenger.
- Håndtering av undersider og paginering. Thunderbit navigerer nettsteder som en ekte bruker og respekterer strukturen deres.
- Personvern og sikkerhet. Dataene dine forblir hos deg—Thunderbit lagrer eller gjenbruker dem ikke.
- Etterlevelsesvennlige eksportmuligheter. Eksporter direkte til Google Sheets, Airtable, Notion eller CSV for sikker intern bruk.
- Planlegging og automatisering. Sett opp gjentakende scraping med ansvarlige intervaller.
- Flerspråklig støtte. Thunderbits grensesnitt støtter 34 språk, noe som gjør etterlevelse tilgjengelig globalt.
- Regelmessige maloppdateringer. Våre øyeblikkelige maler for populære nettsteder holdes oppdatert med juridiske og tekniske endringer.
Ved å bygge inn etterlevelse i produktet hjelper Thunderbit team med å samle inn dataene de trenger—uten juridisk hodebry.
Vær i forkant: Tilpass deg juridiske og tekniske endringer i web scraping
Utforsk flere guider om web scraping Get Started Free
Web scraping er ikke noe du kan sette på autopilot og glemme. Lover og nettstedstrukturer utvikler seg hele tiden. Slik holder du deg i forkant:
- Følg med på juridisk utvikling. Endringstakten økte i 2024–2026—følg nyheter om teknologijuss, regulatoroppdateringer og bransjeblogger (som Thunderbits). Ha et øye på håndhevingen av EU AI Act (august 2026), nye personvernlovgivninger i USA og pågående opphavsrettssaker om AI.
- Tilpass deg tekniske endringer. Nettsteder oppdaterer layouten og anti-bot-forsvaret sitt hele tiden. Store plattformer (Amazon, X, Google) skjerpet forsvarene sine betydelig i 2025–2026. Thunderbits AI og maler er laget for å tilpasse seg automatisk.
- Bruk offisielle API-er når de finnes. Hvis et nettsted går over til en betalt API-modell, bør du vurdere å bytte for bedre driftssikkerhet og etterlevelse.
- Revider scraping-prosessen jevnlig. Dokumenter kildene dine, sjekk om ToS eller policyer er endret, og juster strategien etter behov.
- Utnytt Thunderbits maloppdateringer. Teamet vårt holder malene oppdatert, så du slipper å bekymre deg for breaking changes eller nye krav til etterlevelse.
- Vær fleksibel. Hvis en datakilde blir for risikabel, bytt til en annen eller se etter et samarbeid.
Med riktige verktøy og riktig tankesett kan du holde datapipelinen i gang—uten å tråkke på juridiske landminer.
Konklusjon: Å navigere i det juridiske landskapet for web scraping
Web scraping er ikke i seg selv ulovlig—det er et kraftig verktøy for forretning, forskning og innovasjon. Men som alle verktøy kommer det med regler. Nøkkelen er å forstå hva du scraper, hvordan du scraper det, og hva du skal gjøre med dataene. Respekter lokale lover, følg nettstedenes retningslinjer, og bruk etterlevelsesfokuserte verktøy som Thunderbit for å holde driften din på riktig side av regelverket.
Rettssakene i 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) har styrket saken for scraping av offentlige data, men nye risikoer vokser frem rundt AI-treningsdata, opphavsrettskrav og EU AI Act. Plattformspesifikke retningslinjer varierer mye—Google, Amazon, LinkedIn, Meta og X håndhever alle reglene sine forskjellig—så kjenn landskapet før du scraper.
Hvis du noen gang er usikker, søk juridisk rådgivning—særlig for store eller sensitive prosjekter. Og husk: det juridiske landskapet endrer seg hele tiden, så hold deg oppdatert og smidig.
Vil du lære mer om web scraping, etterlevelse og automatisering? Sjekk ut Thunderbit-bloggen for flere guider, eller prøv Thunderbits Chrome-utvidelse selv.
Kom i gang med etterlevelsesvennlig web scraping med Thunderbit
Vanlige spørsmål
1. Er web scraping ulovlig overalt?
Nei. Web scraping er ikke i seg selv ulovlig, men lovligheten avhenger av hva du scraper, hvordan du scraper det, og hvor du befinner deg. Å scrape offentlige, ikke-personlige data til intern bruk er vanligvis tillatt i de fleste regioner, men scraping av personlige eller opphavsrettsbeskyttede data, eller brudd på nettstedets vilkår, kan være ulovlig (oxylabs.io).
2. Gjør robots.txt scraping ulovlig hvis jeg ignorerer den?
Robots.txt er ikke juridisk bindende, men det er god praksis å respektere den. Å ignorere robots.txt i seg selv gir deg ikke søksmål mot deg, men det kan få deg til å se ut som en «bad actor» hvis det blir en tvist (promptcloud.com).
3. Kan jeg scrape Google, Amazon eller LinkedIn?
Det er komplisert. Alle tre forbyr scraping i ToS, men domstolene har fastslått at ToS kanskje ikke binder brukere som ikke er innlogget (se Meta v. Bright Data og X Corp v. Bright Data, begge fra 2024). Scraping av offentlig synlige data (produktpriser, bedriftsoppføringer, offentlige profiler) er vanligvis juridisk forsvarlig i USA. Likevel håndhever hver plattform reglene sine forskjellig: Amazon er mest aggressiv med juridiske tiltak (de saksøkte Perplexity AI i november 2025); LinkedIn baserer seg på tekniske barrierer og kontraktskrav; Google bruker i økende grad håndheving basert på DMCA. Scrape alltid ansvarlig og forvent tekniske mottiltak.
4. Kan jeg scrape Facebook eller Instagram?
Etter Meta v. Bright Data (2024) står scraping av offentlige data fra Facebook og Instagram uten innlogging juridisk sterkere. Domstolen slo fast at Metas ToS ikke gjelder for ikke-brukere. Men opprett aldri falske kontoer eller scrape data bak innloggingsmurer—det går over grensen.
5. Kan jeg scrape X (Twitter)?
X oppdaterte ToS i 2023 for å forby all scraping uten skriftlig samtykke og har tatt i bruk aggressive tekniske forsvarstiltak (Cloudflare Turnstile, hastighetsgrenser på 300 forespørsler/time, IP-omdømmescore). Bright Data vant imidlertid en sak på lignende grunnlag—offentlige data som scrapes uten konto er ikke bundet av Xs ToS. Teknisk sett er X en av de vanskeligste plattformene å scrape i 2026.
6. Er det lovlig å scrape data for å trene AI-modeller?
Dette er det største åpne spørsmålet i 2026. Store søksmål (NYT v. OpenAI, Anthropics forlik på 1,5 mrd. dollar) tyder på betydelig juridisk risiko. EU AI Act krever at treningsdatakilder oppgis og at reservasjonsmuligheter for opphavsrett respekteres. Det foreslåtte AI Accountability for Publishers Act vil kreve tillatelse og betaling. Hvis du scraper for å trene AI, bør du få juridisk rådgivning før du går videre.
7. Hva er den tryggeste måten å bruke web scraping-verktøy som Thunderbit på?
Hold deg til scraping av offentlige data, respekter nettstedets vilkår, unngå personopplysninger med mindre du har et lovlig grunnlag, og bruk dataene internt. Thunderbit er laget for å hjelpe deg med å holde deg innenfor regelverket ved å scrape bare det som er synlig i nettleseren din og varsle deg om risikable nettsteder (thunderbit.com).
8. Kan jeg scrape data til kommersiell bruk?
Det kommer an på. Å bruke scraped data til intern analyse eller forskning er vanligvis tryggere. Republisering eller salg av scraped data, spesielt hvis de er opphavsrettsbeskyttede eller personlige, er mye mer risikabelt og kan kreve tillatelse eller lisens.
9. Hvordan holder jeg meg oppdatert på juridiske og tekniske endringer i web scraping?
Følg nyheter om teknologijuss, overvåk målrettede nettsteder for endringer i ToS eller policy, og bruk verktøy som Thunderbit som oppdaterer malene og etterlevelsesfunksjonene sine jevnlig. Viktige ting å følge med på i 2026: håndheving av EU AI Act (august), pågående opphavsrettssaker om AI og nye personvernlovgivninger i USA. Når du er i tvil, rådfør deg med en jurist.
Prøv AI Web Scraper Get Started Free




