
Har du noen gang fått en bunke PDF-filer av sjefen og blitt bedt om å hente ut data som skal være både nøyaktige og pent formatert? Å gjøre det manuelt er en sikker vei til overtid. Å hente ut data fra PDF-er kan være skikkelig tidkrevende, fordi PDF-er ofte har ujevn formatering, i motsetning til webdata. Noen PDF-er inneholder tabeller, andre er bare bilder eller skannede dokumenter, noe som gjør direkte uthenting ganske krevende.
Hvis du for eksempel vil hente ut e-postadresser fra en PDF, kan noen av dem være i bildeformat, mens andre gjemmer seg i kompliserte tegnkodinger. Ta dette eksempelet: {john.doe,jane.doe}@example.com. Det representerer faktisk to separate e-poster: john.doe@example.com og jane.doe@example.com. Og så har du {first.last}@example.com, der du erstatter «first» og «last» med henholdsvis forfatterens fornavn og etternavn. Tradisjonelle verktøy for tekstgjenkjenning strekker ikke til her. Det er her et nyttig verktøy, PDF Scraper, kommer inn og redder dagen.
Hva er en PDF Scraper
En PDF Scraper er et smart verktøy som automatisk henter ut data fra PDF-filer og konverterer innhold som tabeller og tekst til formatene du trenger, som Excel, CSV eller JSON. Enkelt sagt gjør det kjedelig kopi- og lim-arbeid om til en løsning med ett klikk.
Tenk deg en stabel med fakturaer, kontrakter, fagartikler eller til og med skannede PDF-er som det ville tatt timer å skrive inn manuelt. Med en PDF Scraper laster du bare opp filen, og i løpet av sekunder er dataene hentet ut. Det sparer tid og arbeid, samtidig som nøyaktigheten ivaretas. Si farvel til bryet med manuell datainntasting.
Hvis PDF-en din inneholder ulike datatyper som tabeller, lenker og bilder, kan du la en AI-basert PDF Scraper ta seg av jobben. AI PDF Scrapers bruker store språkmodeller (LLM) som kan behandle tekst, bilder og tabeller samtidig, og leverer imponerende resultater.
Fordelene med en AI PDF Scraper handler ikke bare om effektivitet og nøyaktighet; fleksibiliteten gjør den også til et stressfritt valg. Enten du jobber med skannede dokumenter, bilder eller flerspråklige PDF-er, håndterer AI alt uten problemer. Det finnes mange gode AI-verktøy, som , og , hver med sine egne funksjoner for ulike behov. Enten du trenger å hente ut data raskt eller analysere komplekse dokumenter, kan riktig verktøy gjøre jobben enklere og mer effektiv.
Prøv det selv: Hent ut data fra PDF-er med AI
Prøv det! Du kan klikke, utforske og kjøre arbeidsflyten mens du ser på.
Slik velger du riktig PDF Scraper
Å velge en PDF Scraper er litt som å kjøpe bil; den beste er den som passer behovene dine. Her er noen punkter du bør tenke på:
| Funksjon | Beskrivelse |
|---|---|
| Nøyaktighet og stabilitet | Sjekk om verktøyet henter ut data nøyaktig, spesielt når det gjelder kritisk informasjon. |
| Utdataformater | Forsikre deg om at verktøyet støtter formatene du trenger, som Excel, CSV eller JSON. |
| Integrasjon med andre verktøy | Hvis du må koble det til bedriftens systemer, bør du se etter sømløs integrasjonsstøtte. |
| Brukervennlig grensesnitt | Et brukervennlig verktøy passer best for vanlige brukere, mens mer avanserte verktøy kan egne seg for tekniske team. |
Ulike verktøy har sine styrker, og riktig valg kan øke produktiviteten betydelig. Her er tre populære PDF Scrapers, hver med funksjoner som passer ulike behov:
| Verktøy | Fordeler | Ulemper |
|---|---|---|
| Thunderbit | Rask uthenting; enkel å bruke som nettleserutvidelse; godt egnet for teamsamarbeid | Begrenset skala for databehandling |
| ChatPDF | Enkelt å bruke, datauthenting i chat-stil | Mindre nøyaktig med komplekse filer |
| ChatGPT | Fleksibel ved komplekse betydninger, bredt anvendelig | Krever at du skriver inn prompten manuelt hver gang |
Kom i gang med AI PDF Scraper
Thunderbit
Vil du hente ut data fra PDF-er raskt uten å bruke for mye tid og energi? Thunderbit er verktøyet for deg. Det er enkelt å bruke, og med bare ett klikk kan du få alt gjort. Følg disse trinnene for enkelt å konvertere kompliserte PDF-data til formatet du trenger, og øk effektiviteten betydelig:
-
Legg til Thunderbit i Chrome og registrer deg:
Gå til den og legg til -utvidelsen i Chrome-nettleseren din. Registrer deg med Google-kontoen din eller en annen e-post.

-
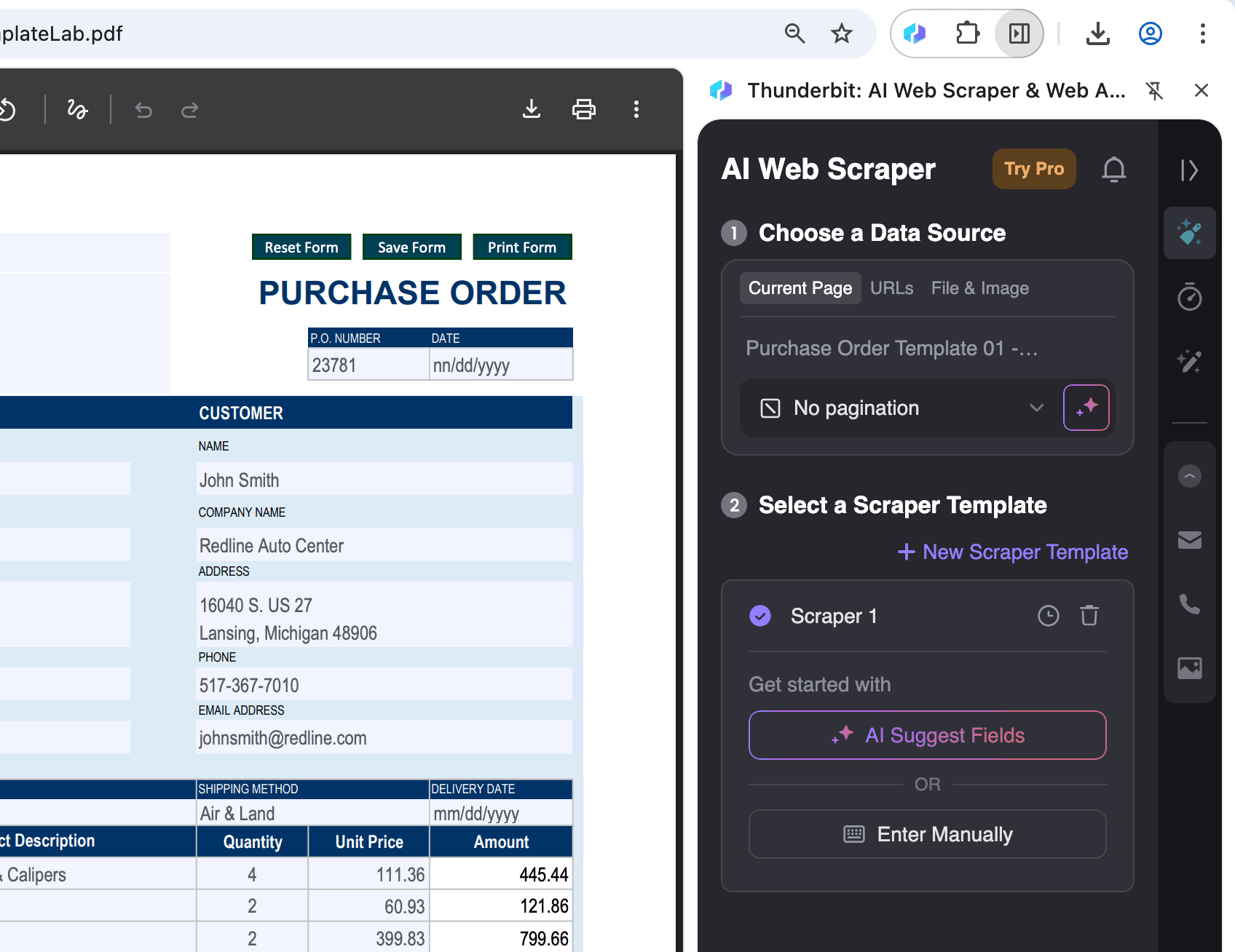
Åpne PDF-en i Chrome:
Åpne PDF-filen du vil hente data fra i Chrome, og klikk på Thunderbit-ikonet øverst til høyre.
-
Velg utdataformat og eksporter:
Etter at du har valgt AI Suggest Columns, kan du filtrere eller justere dataene etter behov. Velg deretter ønsket eksportformat (CSV, Google Sheets, Airtable eller Notion), og klikk Scrape for å eksportere dataene.
 De eksporterte dataene kan kobles direkte til , eller for enkelt teamsamarbeid.
De eksporterte dataene kan kobles direkte til , eller for enkelt teamsamarbeid.
Thunderbit er et enkelt verktøy for uthenting av PDF-data som lar deg raskt hente ut informasjonen du trenger fra PDF-filer og konvertere den til et brukbart format. Enten det er til personlig bruk eller teamsamarbeid, kan Thunderbit øke produktiviteten din betydelig og gjøre datauthenting enklere og mer praktisk.
ChatPDF
Hvis du trenger å behandle mange PDF-er samtidig og bare vil hente ut spesifikk nøkkelinformasjon i stedet for hele innholdet, er en god hjelper. Det lar deg hente ut data på en samtalebasert måte, noe som gjør det godt egnet for nybegynnere.
Slik henter du ut PDF-data med ChatPDF:
- Besøk ChatPDF-nettsiden: Åpne -nettsiden eller den tilhørende plattformen.
- Last opp PDF-filer: Klikk på knappen «Upload File» for å dra og slippe eller velge PDF-dokumentet du vil analysere. Den støtter ulike filtyper, som kontrakter, fagartikler eller årsregnskap.
- Analyser PDF-en: Når filen er lastet opp, vil ChatPDF automatisk tolke innholdet og generere et strukturert dokumentsammendrag. Deretter kan du se nøkkelinformasjonen som er hentet ut.
- Interaktiv forespørsel: Bruk inntastingsfeltet til å stille spørsmål som «Hva er konklusjonen i denne rapporten?» eller «Hva er det totale beløpet som er ført i fakturaen?» ChatPDF henter ut relevant innhold basert på spørsmålet ditt.
- Eksporter resultater: Hvis du vil, kan du eksportere den uthentede informasjonen som CSV, Excel eller JSON for enkel organisering og bruk.
ChatPDF gir en interaktiv opplevelse, og passer derfor særlig godt når du raskt vil finne dokumentinformasjon, for eksempel viktige detaljer eller et sammendrag av dokumentinnholdet.
ChatGPT
utmerker seg når det gjelder håndtering av komplekse semantiske data, for eksempel tolkning av klausuler i juridiske dokumenter. Verktøyet er svært fleksibelt og lar deg tilpasse promptene for å hente ut spesifikke data eller analysere innhold. Du må imidlertid bruke den samme prompten gjentatte ganger for lignende oppgaver, og det krever god forståelse av hvordan man skriver gode prompts.
Her er en ferdigskrevet prompt du kan tilpasse etter behov (husk å bytte ut kolonnene med informasjonen du vil hente ut):
1Du er nå en PDF Scraper, og jobben din er å hente ut innhold fra en PDF basert på kolonnene brukeren gir deg. Svaret ditt skal være en CSV-fil.
2Her er kolonnene:
31. Navn
42. E-post
53. Telefonnummer
64. ...- Registrer deg eller logg inn: Åpne -nettsiden og opprett en konto. Hvis du allerede har en konto, er det bare å logge inn.
- Last opp PDF og skriv inn spørsmålet ditt: Skriv spørsmålet direkte i inntastingsfeltet; jo mer spesifikt, desto bedre. For eksempel: «Dette PDF-dokumentet inneholder tre diagrammer, eksporter dem som tabeller.»
- Se gjennom og juster resultatene: Sjekk om svaret møter forventningene dine. Hvis ikke, kan du finjustere resultatene ved å stille oppfølgingsspørsmål eller justere prompten.
- Eksporter data som Excel eller CSV: Hvis dataene ChatGPT har hentet ut er det du ønsker, skriver du i inntastingsfeltet: «Eksporter disse dataene som Excel eller CSV.»
- Lagre resultatene: Klikk på fillenken som ChatGPT gir deg for å laste ned filen.
Praktiske bruksområder for AI PDF Scraper
AI PDF Scraper er som en allsidig assistent i arbeidet ditt, enten du jobber med fakturaer, kontrakter, finansrapporter eller innkjøpsordrer. Her er noen praktiske scenarier der den virkelig kommer til sin rett:
Behandling av fakturaer og kvitteringer
Behandle bedriftens fakturaer og kvitteringer i batch, og hent ut nøkkelinformasjon som beløp og datoer for klassifisering og arkivering.
- Start , klikk AI Web Scraper og deretter Bulk Pages
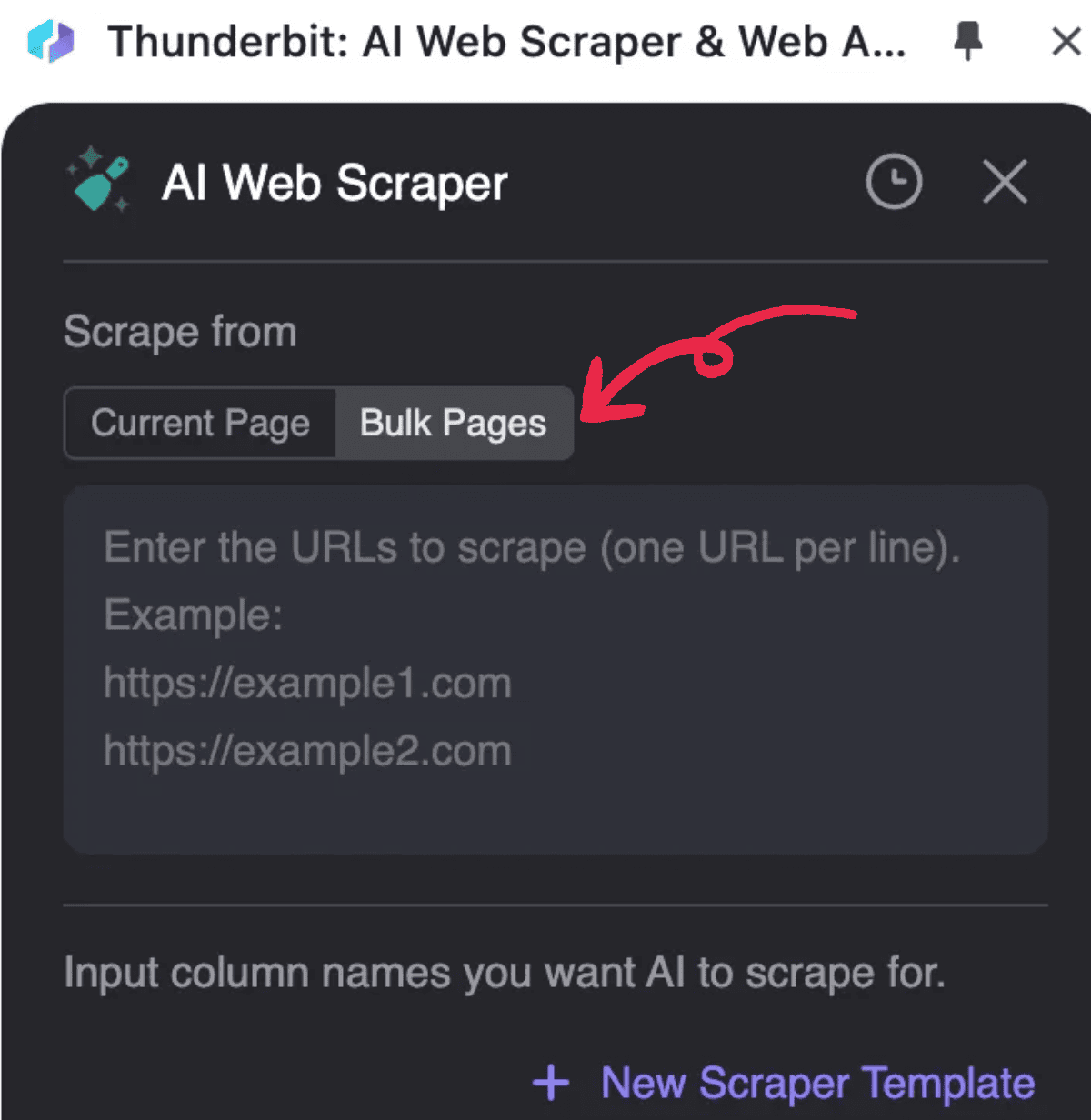 2. Skriv inn PDF-URL-ene du vil behandle, én URL per linje
2. Skriv inn PDF-URL-ene du vil behandle, én URL per linje
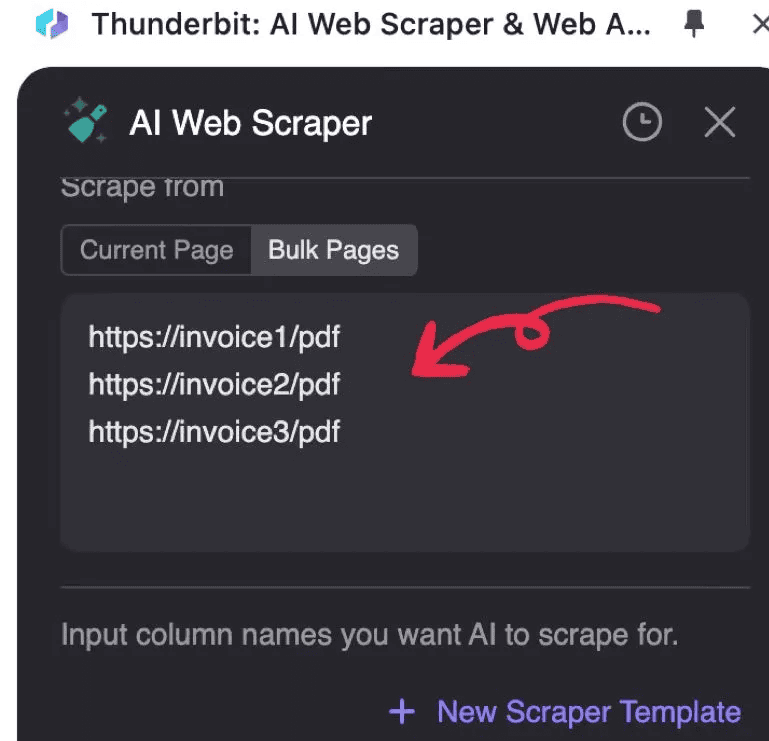 3. Klikk AI Suggest Columns (AI leser PDF-en og foreslår hvordan dataene bør struktureres)
4. Klikk Scrape og eksporter dataene
3. Klikk AI Suggest Columns (AI leser PDF-en og foreslår hvordan dataene bør struktureres)
4. Klikk Scrape og eksporter dataene
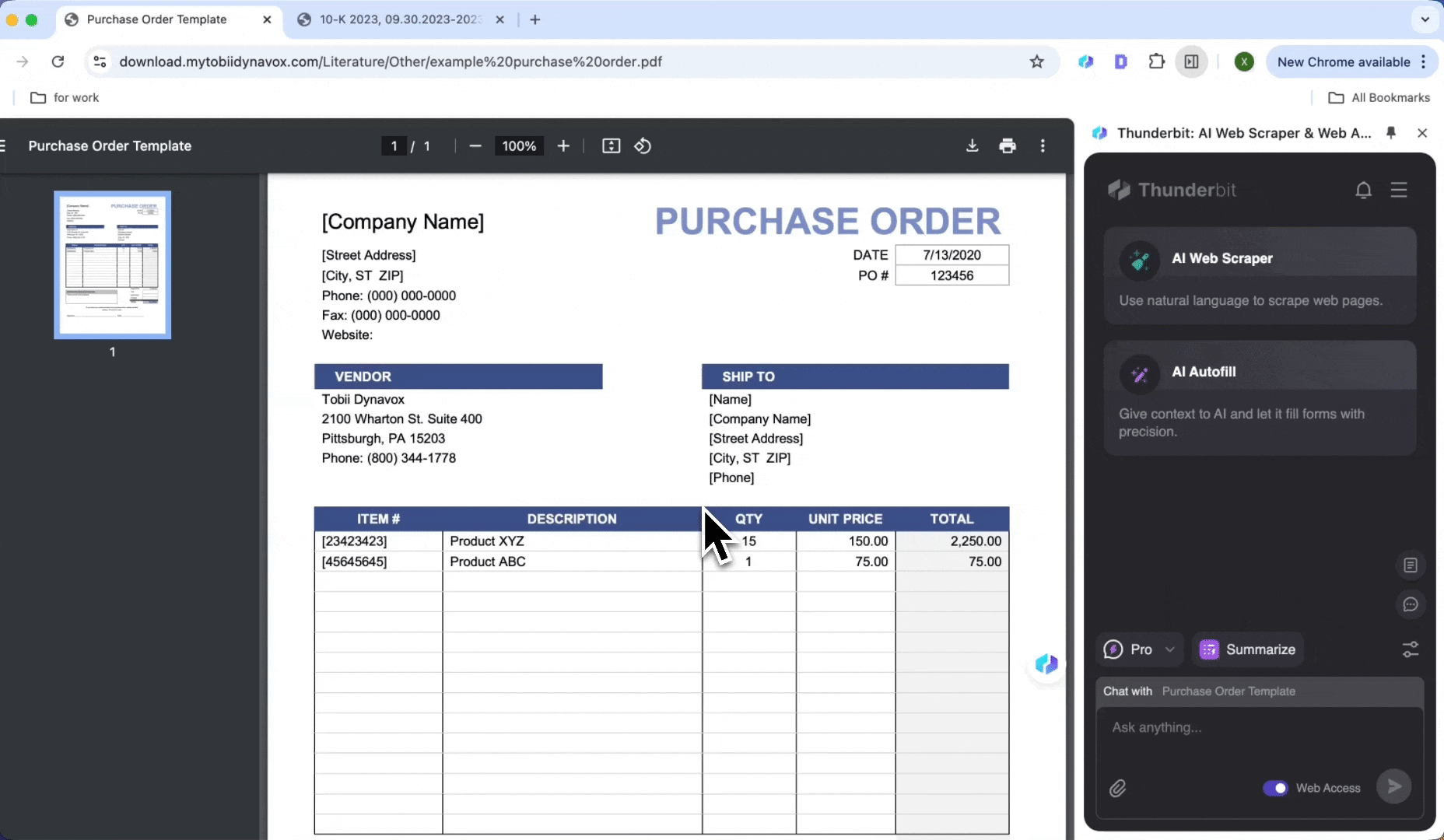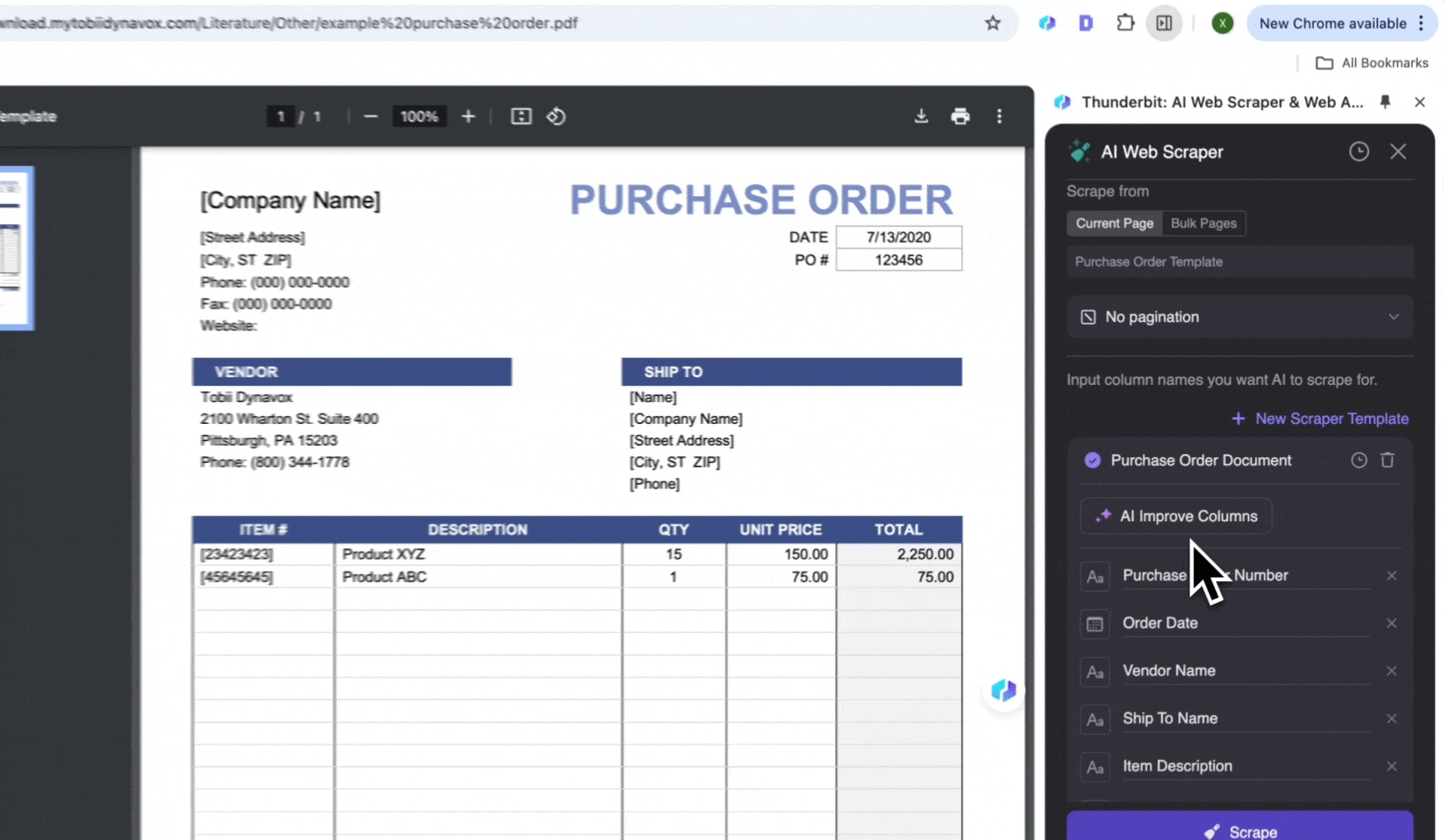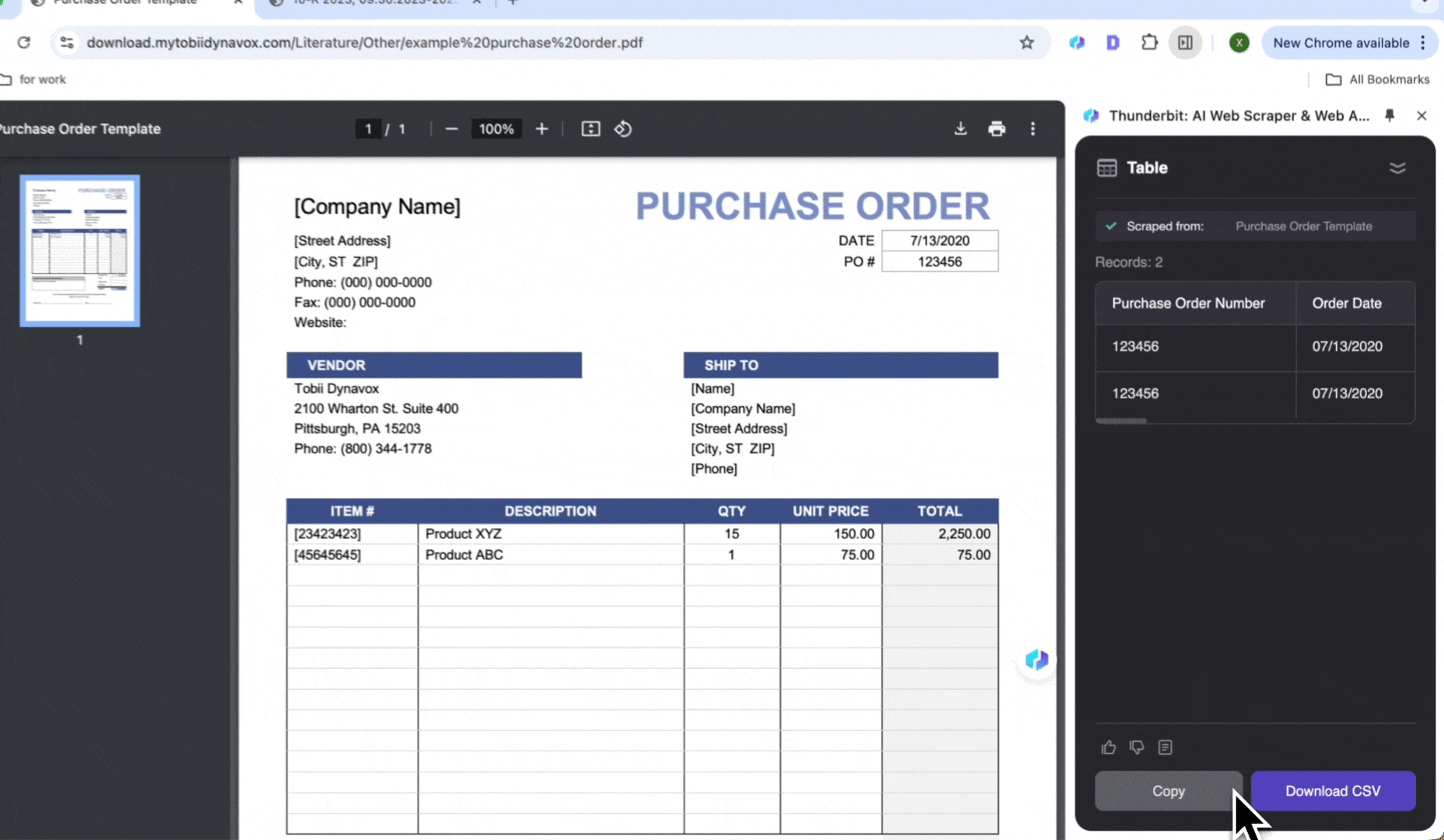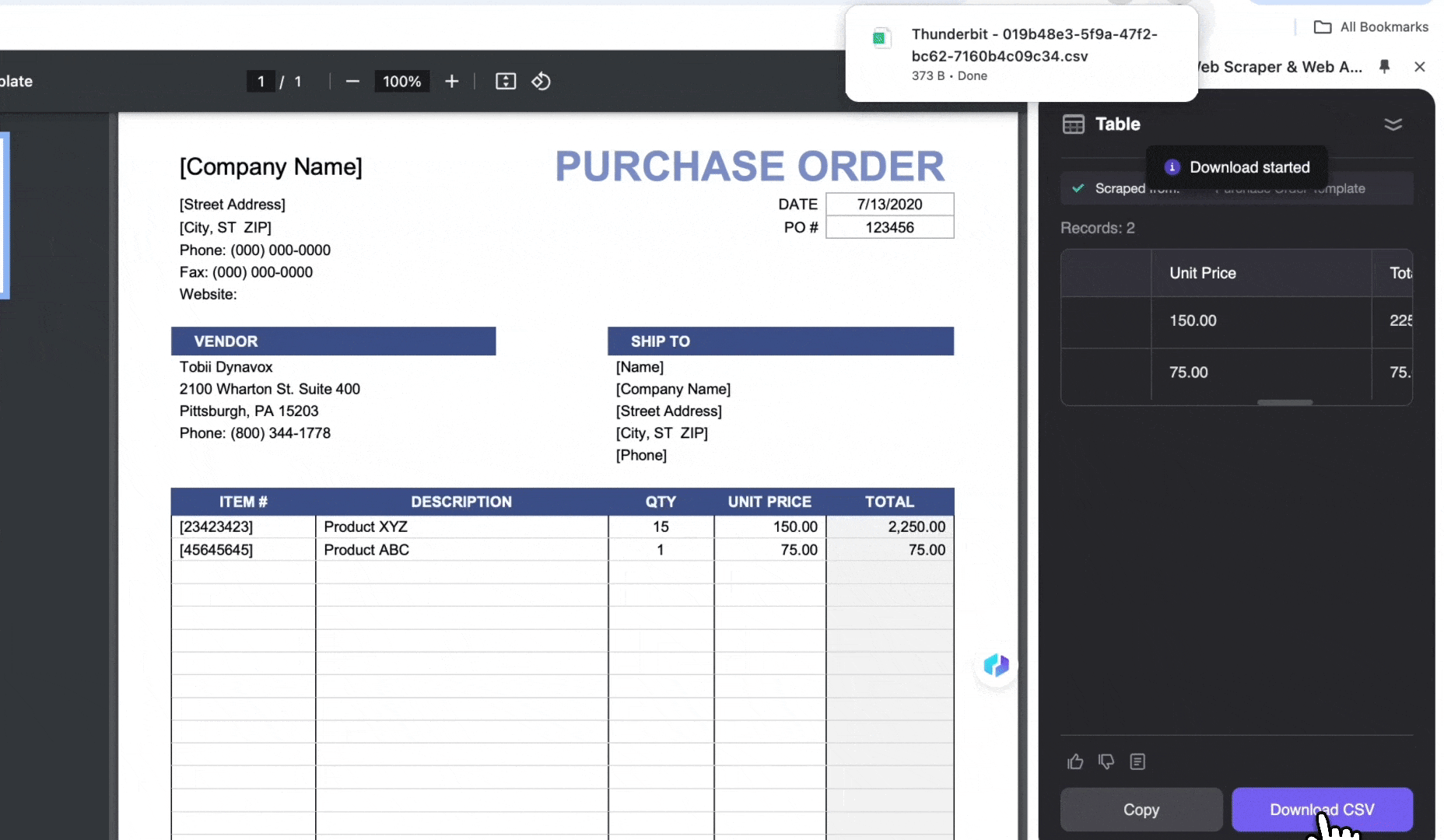
Behandling av innkjøpsordrer
Identifiser automatisk varer, antall og enhetspriser i innkjøpsordrer, generer standardiserte dataposteringer og hent ut data fra PDF-er, slik at du sparer tid på manuell behandling.
- Åpne innkjøpsordren i Chrome og start
- Klikk AI Web Scraper, deretter AI Suggest Columns
- Se gjennom de genererte listenavnene og klikk Scrape
- Klikk Download CSV
Uthenting av finansdata
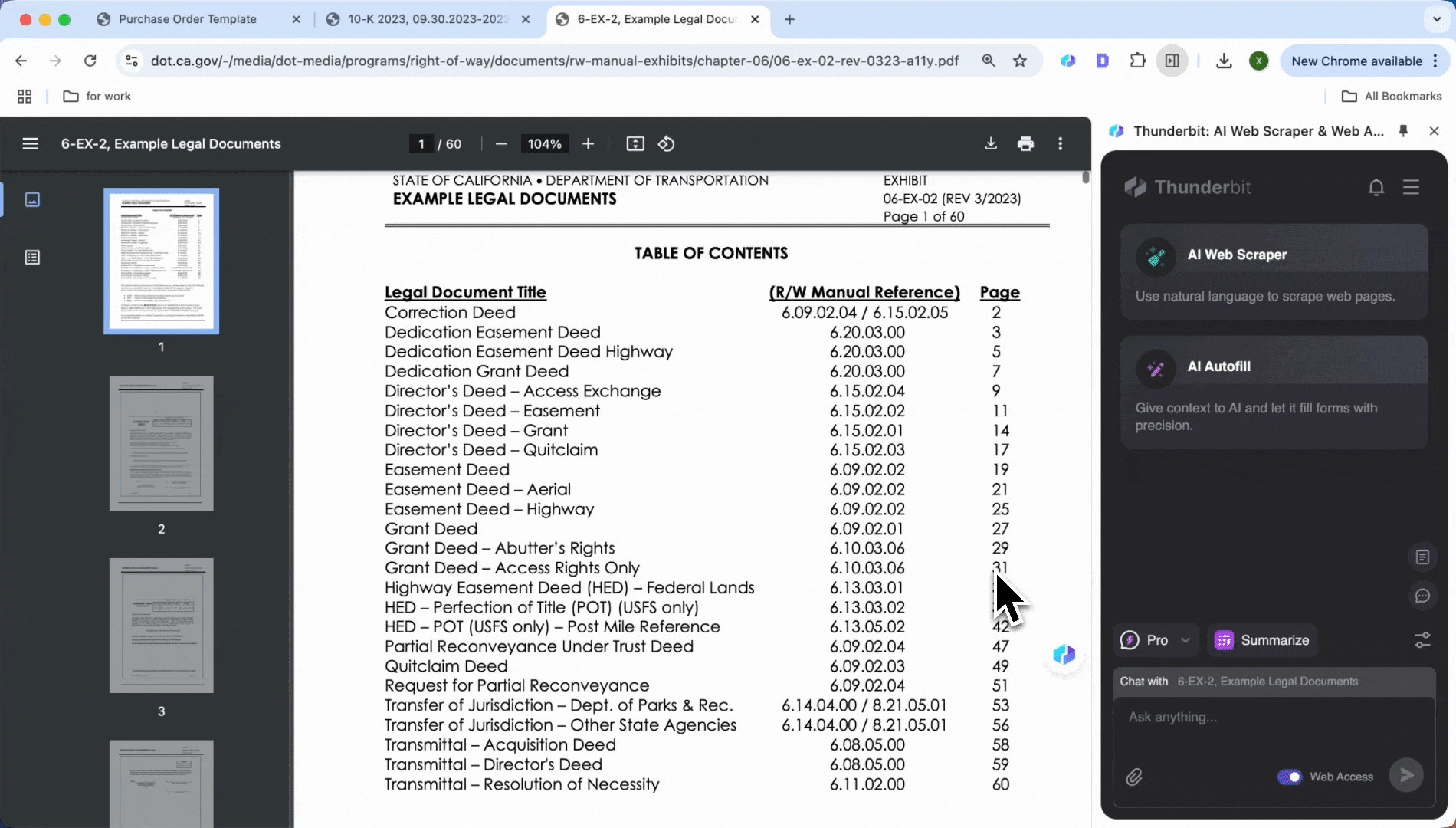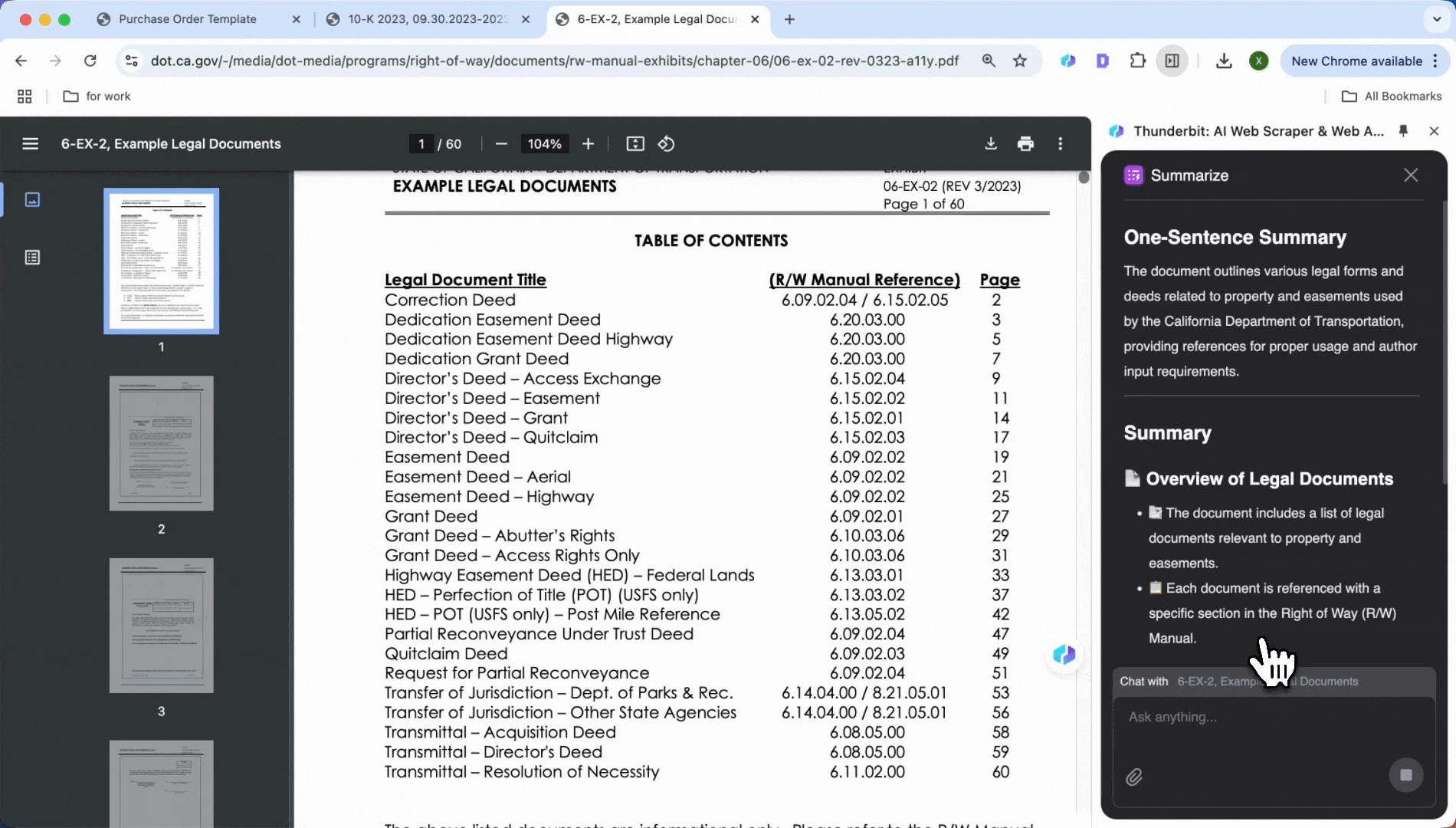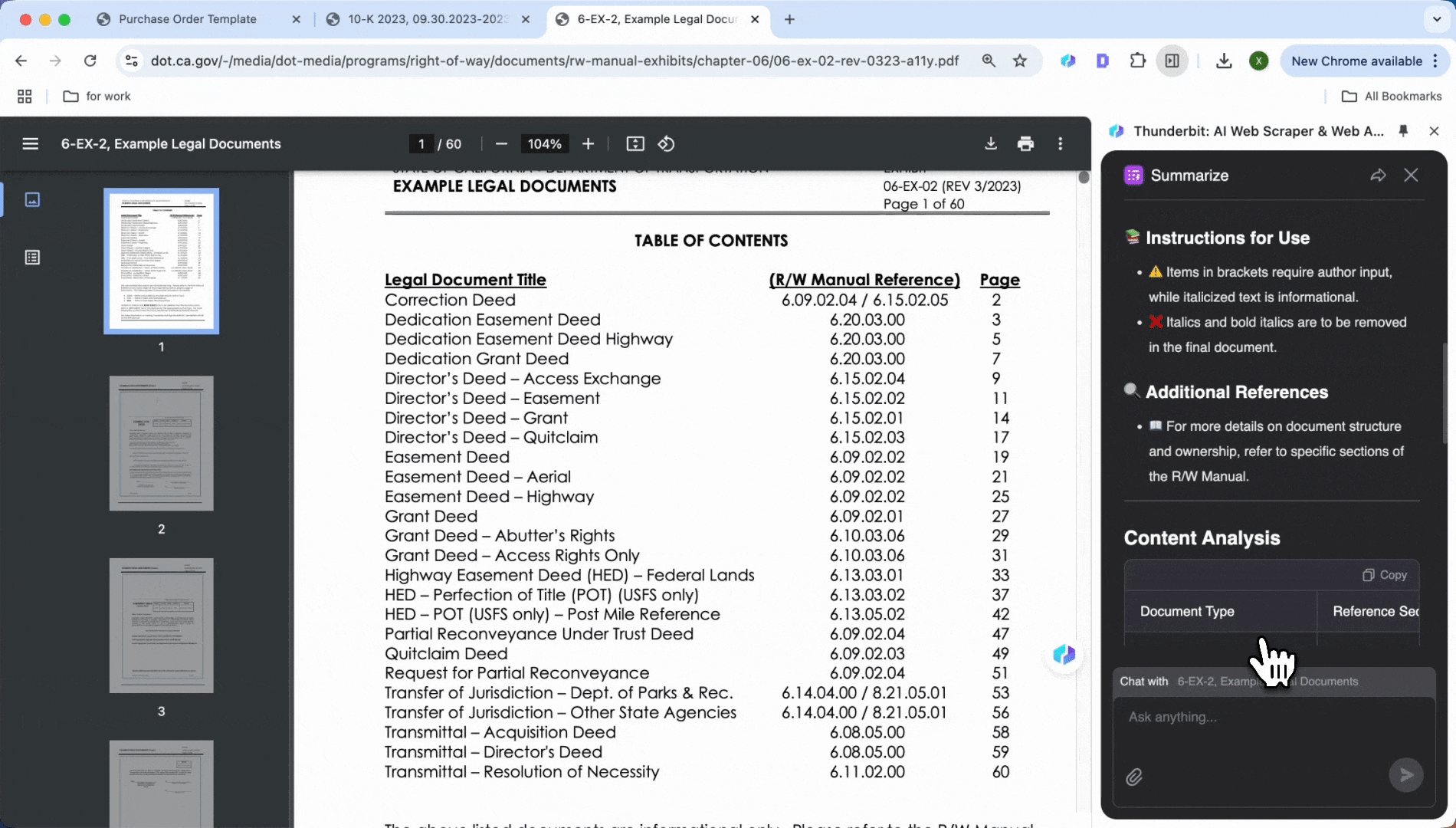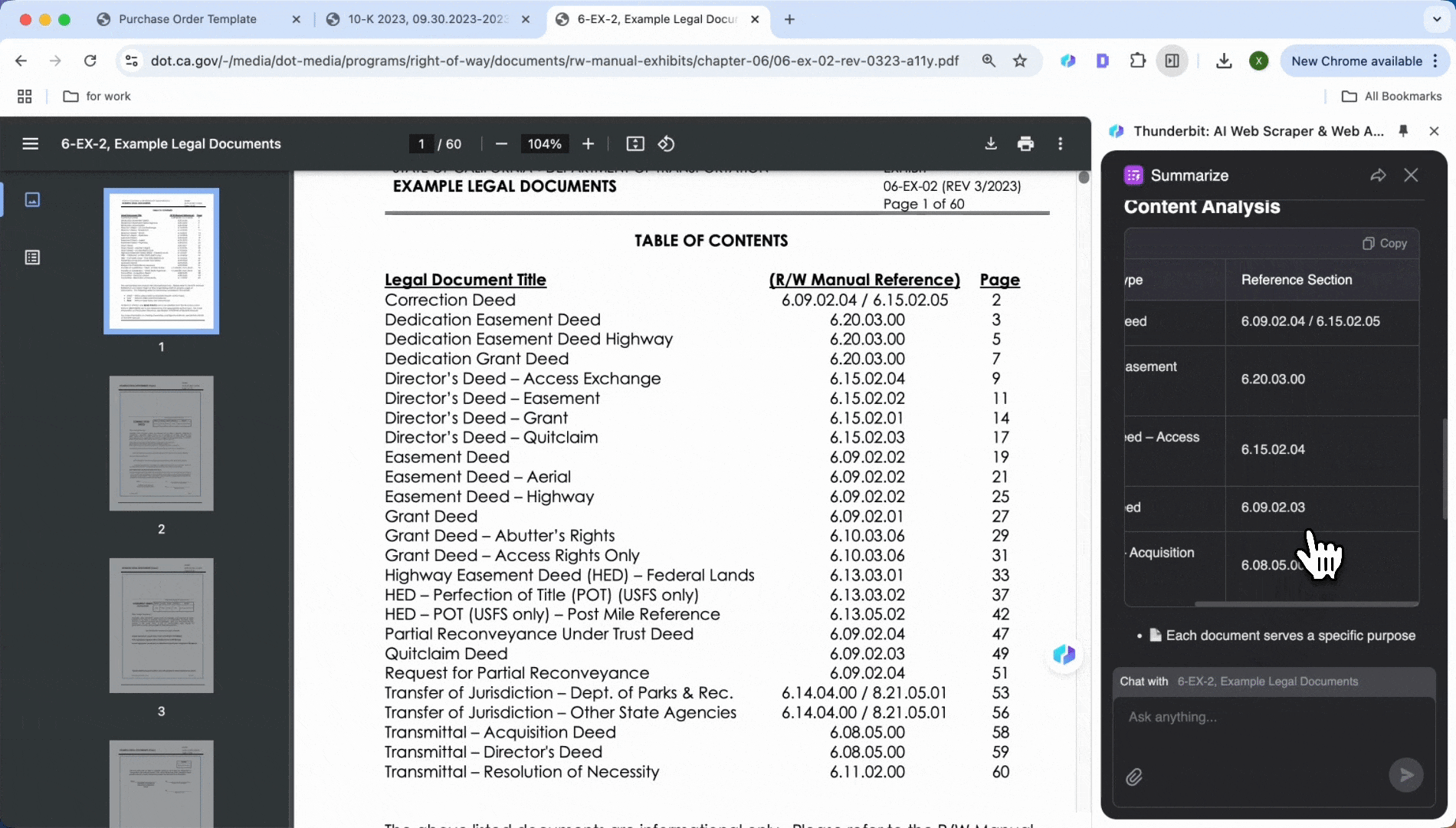
Hent ut data fra finansrapporter med ett klikk, som fortjenestemarginer og salgstall, og slipp den tidkrevende manuelle gjennomgangen.
- Åpne finansrapporten i Chrome og start
- Klikk Summarize
- Generer automatisk et sammendrag av nøkkelinformasjon, inkludert tekst og tabellinnhold
Ikke fornøyd med det automatisk genererte sammendraget? Du kan skrive inn prosjektinformasjonen du ønsker manuelt.
- Åpne finansrapporten i Chrome og start
- Klikk AI Web Scraper, og skriv inn prosjektnavnene du vil ha, som Net Income, Sales osv.
- Klikk Scrape, output Table
Analyse av juridiske dokumenter
Sliter du med klausuler i kontrakter og avtaler? AI-verktøy kan raskt finne betalingsvilkår, bruddklausuler, kontraktsvarighet og andre nøkkelpunkter. Hent dem ut med ett klikk for å lage et kort sammendrag eller en liste over klausuler, slik at du sparer tid og sikrer at ingen detaljer blir oversett.
På samme måte som ved uthenting av nøkkelinformasjon fra finansrapporter, kan du åpne PDF-en og klikke Summarize for å se betalingsvilkår, bruddklausuler, kontraktsvarighet og annen nøkkelinformasjon med ett enkelt klikk.
Vanlige spørsmål
-
Kan jeg hente ut data fra flere PDF-er samtidig?
Ja, avanserte PDF scraping-verktøy lar brukere hente ut data fra flere PDF-er samtidig. Denne batchbehandlingen gir betydelig raskere arbeidsflyt enn manuelle metoder.
-
Er PDF Scraper gratis?
Ja, det finnes flere gratis PDF scraper-verktøy som kan brukes. Mange nettverktøy, som og , tilbyr gratis funksjoner for sideuthenting og datauthenting. Selv om noen avanserte funksjoner kan kreve betaling, er de grunnleggende funksjonene for datauthenting vanligvis gratis.
-
Må jeg kunne programmering for å bruke en PDF scraper?
Nei, mange AI-baserte PDF scrapers, som , er laget for brukere uten programmeringskunnskaper. De har brukervennlige grensesnitt som lar deg laste opp filer og hente ut data med bare noen få klikk.
-
Hvilke typer dokumenter kan behandles med en PDF scraper?
PDF scrapers kan håndtere ulike dokumenttyper, inkludert fakturaer, kontrakter, finansrapporter, fagartikler og annet strukturert eller semistrukturert innhold som finnes i PDF-filer.
-
Er dataene mine trygge når jeg bruker en PDF scraper?
Seriøse PDF scraping-verktøy prioriterer brukersikkerhet og følger ofte regelverk som GDPR. De lagrer vanligvis dataene dine på krypterte servere og får ikke tilgang til dem uten tillatelse.
-
Finnes det andre måter å hente ut data fra PDF på?
Det finnes flere metoder for å hente ut data fra PDF-filer utover manuell inntasting og Python-skripting. Dette inkluderer bruk av PDF-konverterere for å omgjøre filer til formater som Excel eller CSV, spesialiserte verktøy for datauthenting fra PDF, som Tabula og Excalibur for strukturerte dokumenter, AI-drevne løsninger med optisk tegngjenkjenning (OCR) for både opprinnelige og skannede PDF-er, samt open source-verktøy som Extractous og PymuPDF4llm som er laget for effektiv datauthenting. Hver metode har sine fordeler og ulemper, så valget avhenger av de spesifikke behovene og brukerens tekniske kompetanse.
Les mer