

Facciamoci un quadro: sono le ore piccole, hai il caffè in una mano e ti servono adesso gli ultimi prezzi dei concorrenti, lead appena sfornati o i post del momento. Peccato che i tuoi "dati" siano fermi alla settimana scorsa e, quando finalmente metti insieme quel che cercavi, il mercato è già andato oltre. Ci sono passato pure io, e ti assicuro che non è bello. Nel business di oggi, accontentarsi di dati vecchi e impolverati in cache è come presentarsi a una svendita lampo a scaffali ormai vuoti. Ecco perché il live web crawling — i dati in tempo reale, raccolti nell'istante in cui vengono pubblicati — ha smesso da un pezzo di essere un lusso. È l'asso nella manica per restare un passo avanti.
Dopo anni passati a costruire SaaS e strumenti di automazione (e sì, a esagerare col caffè), ho visto coi miei occhi quanto i live crawler possano cambiare il modo di lavorare di un team. Thunderbit oggi è usato da oltre 100.000 persone in giro per il mondo — e una bella fetta lo usa proprio per raccogliere dati in tempo reale, non a blocchi. Con Thunderbit, io e il mio team avevamo un obiettivo preciso: rendere il live crawling così immediato che chiunque — anche chi non ci ha mai messo le mani — possa ottenere i dati web più freschi con un paio di clic. In questa guida ti spiego cosa significa davvero il live crawling, perché conta e come puoi cominciare a usarlo già oggi, codice zero.
Cos'è un live crawler? La scorciatoia verso i dati in tempo reale
Partiamo dall'inizio: cosa diavolo è un "live crawler"? Detta semplice, è uno strumento che va a prendere i dati direttamente da un sito in tempo reale, ogni volta che lo lanci. Immaginalo come sintonizzarti su una diretta invece di guardarti la replica. Gli scraper tradizionali spesso si appoggiano a download periodici o a istantanee salvate in cache — e così sei sempre un passo indietro. Il live crawler, al contrario, visita la pagina in quel preciso momento, vede cosa c'è davvero e si porta a casa le informazioni più recenti non appena spuntano.
C'è chi li chiama "live crawler escort" o "live escort crawler" (che, diciamocelo, suona come un agente segreto al servizio dei tuoi fogli di calcolo). Il senso è che questi crawler non si accontentano di roba datata. Si appoggiano all'automazione del browser o alla navigazione cloud per leggere i contenuti esattamente come li vedrebbe una persona — compresi gli elementi dinamici come JavaScript, scroll infinito e pop-up. Così, che tu stia seguendo un calo di prezzo, un post virale o un nuovo contatto, hai sempre tra le mani i dati più freschi in circolazione (dataprocorp.tech Pricing).
Live vs. crawling statico:
- Crawling statico: come scattare una foto del sito una volta al giorno — comodo per gli archivi, inutile per le notizie dell'ultimo minuto.
- Live crawling: come seguire un video in diretta — quello che vedi sta succedendo proprio ora.
È una differenza che pesa enormemente per chiunque viva di informazioni aggiornate al minuto. Nei mercati che corrono, anche poche ore di ritardo possono tradursi in occasioni perse o decisioni prese su dati ormai stantii (dataprocorp.tech Pricing).
Perché il live crawling conta per l'azienda: casi d'uso e vantaggi
Veniamo al concreto. Perché il live crawling pesa così tanto per vendite, marketing, operations e il resto? La risposta è secca: i dati in tempo reale portano a decisioni migliori. Il briefing 2024 del MIT CISR sul business in tempo reale ha rilevato che le aziende nel quartile più alto per capacità "real-time" hanno messo a segno una crescita del fatturato superiore del 62% e margini di profitto più alti del 97% rispetto a quelle del quartile più basso — tutto fuorché un dettaglio (MIT CISR).
| Caso d'uso | Team/Funzione | Vantaggi/ dati raccolti di esempio |
|---|---|---|
| Monitoraggio prezzi dei concorrenti | Vendite/e-commerce | Tieni d'occhio prezzi e promozioni in tempo reale per un pricing dinamico (promptcloud.com Pricing) |
| Estrazione di lead/contatti | Vendite/marketing | Raccogli da zero contatti freschi (nome, email, telefono) da directory o LinkedIn (Thunderbit Blog) |
| Analisi dei social media e dei trend | Marketing/prodotto | Segui hashtag, argomenti caldi e sentiment man mano che emergono (promptcloud.com Pricing) |
| Aggiornamenti del catalogo prodotti | E-commerce/operations | Tieni in ordine le schede prodotto (prezzi, descrizioni, disponibilità) (datadwip.com Pricing) |
| Dati per il sales pipeline | Vendite | Costruisci automaticamente liste di prospect estraendo dati dalle directory aziendali (Thunderbit Blog) |
| Annunci immobiliari | Immobiliare | Raccogli nuovi immobili e variazioni di prezzo non appena vengono pubblicati (promptcloud.com Pricing) |
E non perdiamo di vista il punto finale: dati più rapidi e più precisi vogliono dire decisioni più rapide e migliori. I team smettono di andare a naso, intercettano i trend mentre nascono e si muovono prima ancora che la concorrenza capisca cosa stia succedendo. In due parole, il live crawling trasforma i dati grezzi del web in insight pronti all'uso — sul momento (cisr.mit.edu).
Thunderbit: il live crawler più semplice, per chiunque
Estrai dati da qualsiasi sito web con l'AI Get Started Free
So già cosa stai pensando: "Bello tutto, ma io non programmo. In pratica come faccio?" È esattamente il nodo che volevamo sciogliere con Thunderbit.
Thunderbit è un'estensione Chrome guidata dall'AI che rende il live crawling immediato come ordinare la cena d'asporto — e, sinceramente, a volte pure più veloce. Ecco cosa lo distingue:
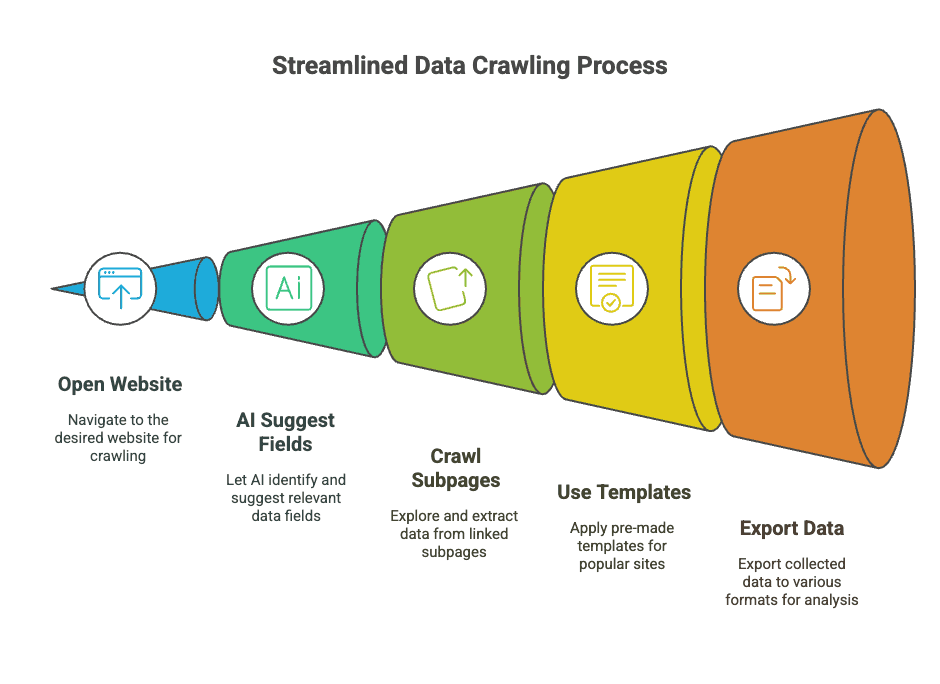
- Codice zero: installa l'estensione, apri il sito che ti interessa e lascia fare all'AI di Thunderbit.
- Suggerimento campi con AI: un clic e Thunderbit analizza la pagina, proponendoti da solo le colonne migliori (tipo "Nome", "Prezzo", "Email") (Thunderbit Blog).
- Crawling delle sottopagine: le informazioni sono nascoste dietro ai link? Thunderbit visita ogni sottopagina (dettagli prodotto, profili contatto e simili) e raccoglie tutto in un'unica tabella.
- Template istantanei: per i siti più gettonati (Amazon, Zillow, LinkedIn e compagnia) hai template già pronti — niente configurazione, niente stress.
- Multilingua: Thunderbit gira in 34 lingue, quindi è tagliato su misura per i team globali (Thunderbit Blog).
- Export gratuito: porti i risultati su Excel, Google Sheets, Airtable, Notion, CSV o JSON — gratis, punto (Thunderbit Blog).
E la cosa migliore? Anche se sei alle prime armi, parti in pochi minuti. Come ha detto un utente: "Mi basta premere due pulsanti e i dati sono pronti in un attimo. La precisione è impressionante" (trustpilot.com).
Live crawler a confronto: Thunderbit vs. strumenti tradizionali
Mettiamola sul piatto: per estrarre dati web in tempo reale ci sono anche altre strade. Se sei uno sviluppatore, puoi costruirti un crawler su misura con Selenium (ancora attivamente mantenuto — la versione 4.4x è uscita nel 2026) o Beautiful Soup, oppure puntare su opzioni più recenti dal sapore AI come Browser Use per flussi browser in linguaggio naturale e Firecrawl per l'estrazione da URL a markdown pensata per gli LLM. Funzionano tutte — ma danno per scontato che tu sappia cavartela da solo con codice, anti-bot e proxy. Se non è il progetto che ti immagini per il weekend, continua a leggere.
| Aspetto | Strumenti tradizionali (Python/Selenium) | Thunderbit AI Crawler |
|---|---|---|
| Setup e competenze | Serve programmare e configurare l'ambiente | Codice zero: installa e parti (Thunderbit Blog) |
| Tempo di setup | Da ore a giorni | Minuti |
| Freschezza dei dati | Istantanee, rischio dati obsoleti | Live, aggiornati al secondo (dataprocorp.tech Pricing) |
| Contenuti dinamici | Complicato (serve codice in più) | Già integrato, gestisce JS e scrolling (Thunderbit Blog) |
| Adattabilità | Si rompe se il sito cambia | L'AI si adatta da sola (dataprocorp.tech Pricing) |
| Manutenzione | Alta (correzioni di continuo) | Bassa (l'AI assorbe quasi tutti i cambiamenti) (dataprocorp.tech Pricing) |
| Formato di output | HTML grezzo, pulizia a mano | Tabelle strutturate, pronte da esportare (Thunderbit Blog) |
| Integrazioni | Serve codice su misura | Export diretto su Sheets, Airtable, Notion, CSV, JSON (Thunderbit Blog) |
Insomma, a meno che tu non stia cercando un nuovo hobby nello scrivere script di web scraping, Thunderbit è la scelta sensata per chi in azienda ha bisogno di risultati rapidi e affidabili.
Passo dopo passo: usare Thunderbit come tuo live crawler
Voglia di vedere il live crawling all'opera? Ecco come usare Thunderbit per raccogliere dati in tempo reale da qualsiasi sito — niente gergo tecnico, niente mal di testa.
Passo 1: installa Thunderbit e apri il sito di destinazione
Per prima cosa, aggiungi al browser l'estensione Chrome di Thunderbit. Ci vuole circa un minuto (sempre che il tuo Wi-Fi non sia mosso a forza di criceti).
A installazione fatta, apri il sito da cui vuoi estrarre. Thunderbit lavora su qualunque sito il browser riesca a mostrare — quindi, se tu puoi fare l'accesso e vedere la pagina, può farlo anche lui.
Prova gratis il Live Crawler di Thunderbit
Passo 2: usa Suggerimento campi con AI per mappare i dati al volo
Qui scatta la magia (ok, l'AI). Premi il pulsante Suggerimento campi con AI di Thunderbit. L'AI legge la pagina e ti propone le colonne migliori da estrarre — "Nome", "Prezzo", "Disponibilità", "Email" o qualsiasi altra informazione utile (Thunderbit Blog).
Questi campi puoi modificarli, rinominarli o aggiungerne di tuoi. Vuoi spingerti oltre? Aggiungi istruzioni su misura per ogni campo — tipo "formatta i numeri di telefono in E.164" oppure "classifica i prodotti per tipo".
Passo 3: estrai i dati live con un clic
Quando i campi sono a posto, premi Estrai. Thunderbit comincia a fare crawling della pagina in tempo reale, seguendo paginazione o scroll infinito dove serve. Se hai attivato il crawling delle sottopagine, apre ogni elemento collegato (dettagli prodotto, profili e simili) e porta quelle informazioni dentro la tua tabella (Thunderbit Blog).
Vedi le righe riempirsi mentre Thunderbit lavora — un po' come guardare i popcorn scoppiettare, ma decisamente più utile.
Passo 4: esporta i dati freschi in Excel, Google Sheets o Notion
A crawl concluso, è ora di mettere i dati al lavoro. Thunderbit ti lascia esportare tutto — gratis, sempre — su Excel, Google Sheets, Airtable, Notion, CSV o JSON (Thunderbit Blog). Scegli il formato e i tuoi dati live sono pronti per analisi, report o condivisione.
Dritte pratiche: spremere al massimo il tuo live crawler
Vuoi tirare fuori il meglio da Thunderbit? Ecco qualche consiglio che ho imparato sulla mia pelle, a volte nel modo più scomodo:
- Pianifica i crawl: usa lo scheduler di Thunderbit per far partire le estrazioni in automatico (per esempio "ogni lunedì alle 9:00"). Perfetto per monitorare prezzi o aggiornare lead in continuazione (Thunderbit Blog).
- Sfrutta le sottopagine: se i dettagli sono nascosti dietro ai link (come i contatti nei profili), attiva il crawling delle sottopagine. Thunderbit visita ogni link e unisce i dati in più.
- Personalizza i prompt dei campi: per dati complessi, aggiungi istruzioni AI su misura — per esempio classificare i prodotti o formattare il testo mentre lo estrai.
- Usa i template istantanei: per i siti più gettonati, controlla se esiste già un template a un clic prima di configurare i campi a mano.
- Non strapazzare i siti: non estrarre più in fretta di quanto serva. Sfrutta la pianificazione e ritardi ragionevoli per non mettere sotto stress i server (scrapingapi.ai Pricing).
- Cloud vs. Browser, scegli con criterio: per i siti pubblici la modalità Cloud è velocissima (fino a 50 pagine alla volta). Per i siti che richiedono accesso, usa la modalità Browser, così Thunderbit lavora dentro la tua sessione.
Restare al sicuro e in regola durante il live crawling
Una nota breve ma da non saltare: rispetta sempre i termini del sito e la privacy. Prima di fare crawling, controlla il file robots.txt e i termini di servizio (scrapingapi.ai Pricing). Alcuni siti limitano l'accesso automatizzato o il ritmo di crawling. Thunderbit ti dà gli strumenti per moderare le richieste e pianificare le esecuzioni, ma usarli con testa dipende da te.
- Rispetta privacy e legge: estrai solo dati pubblici ed evita di raccogliere informazioni personali senza consenso. Se prendi email o numeri di telefono, assicurati di essere in regola con GDPR o CCPA (scrapingapi.ai Pricing).
- Sii un cittadino del web a modo: usa i dati per scopi aziendali legittimi e non intasare i server. Trasparenza e conformità riducono i rischi legali e fanno contenti tutti.
Affrontare gli ostacoli più comuni del live crawler
Esplora il blog di Thunderbit per altre dritte Get Started Free
Il live crawling non è sempre una passeggiata. Ecco gli intoppi più frequenti — e come Thunderbit ti dà una mano a superarli:
- Misure anti-bot: alcuni siti tirano fuori CAPTCHA o blocchi IP. Thunderbit imita la navigazione umana (soprattutto in modalità Browser) e gestisce i nuovi tentativi. Per i CAPTCHA più testardi, può capitare di doverli risolvere a mano.
- JavaScript e pagine dinamiche: qui gli scraper tradizionali arrancano, ma Thunderbit gira in un browser vero, quindi gestisce nativamente script, AJAX e scroll infinito.
- Cambi di layout del sito: quando un sito rinnova il layout, gli scraper tradizionali spesso saltano. L'AI di Thunderbit si adatta da sola alla maggior parte dei cambiamenti — basta premere "Migliora campi con AI" quando serve (dataprocorp.tech Pricing).
- Qualità dei dati: Thunderbit pulisce e struttura i dati mentre li estrae, ma fai sempre un controllo a campione prima di esportare.
- JavaScript pesante: sui siti davvero complessi, prova a passare dalla modalità Cloud a quella Browser, oppure cambia URL se puoi.
- CAPTCHA insistenti: se un sito blocca i bot in modo aggressivo, valuta un'API ufficiale o rallenta il ritmo di crawling.
Nella stragrande maggioranza dei casi, con Thunderbit questi problemi pesano molto meno che con gli script scritti a mano. E se ti dovessi incartare, c'è sempre il Thunderbit Blog con altre dritte e soluzioni.
Conclusione e takeaway chiave: fai un salto di qualità con il live crawling
Facciamo il punto: il live web crawling è la via più rapida per avere dati aggiornati al secondo per la tua azienda. Che tu lavori in vendite, marketing, operations o che sia semplicemente un patito di dati come me, avere le informazioni più fresche significa decisioni migliori, meno tiri a indovinare e un vantaggio vero sulla concorrenza.
Con Thunderbit non devi essere né programmatore né data scientist. Chiunque può impostare un crawl live in pochi minuti, automatizzarlo ed esportare i risultati nei propri strumenti del cuore. E con funzionalità come il rilevamento AI dei campi, il crawling delle sottopagine e i template istantanei, passerai meno tempo a rincorrere i dati e più tempo a farci qualcosa.
In sintesi: il mercato dell'analisi in tempo reale oggi sta crescendo da circa 1,1 miliardi di dollari nel 2025 a una previsione di 5,3 miliardi entro il 2032 — con un CAGR del 25,1%. Il live crawling non è più una tendenza all'orizzonte; è ormai il minimo sindacale. Thunderbit lo mette alla portata di tutti, così smetti di aspettare e cominci a vincere.
Voglia di provarci? Scarica Thunderbit, scegli un sito e scopri quanto può essere facile il live crawling. E se ti va di approfondire, dai un'occhiata alla nostra guida per principianti oppure esplora altri casi d'uso sul Thunderbit Blog.
Leggi la guida per principianti di Thunderbit
Buon crawling — e che i tuoi dati siano sempre più freschi del caffè del mattino.
Prova subito l'AI Live Web Crawler Get Started Free
FAQ
1. Cos'è un live crawler e in cosa si differenzia dagli scraper tradizionali?
Un live crawler è uno strumento che va a prendere i dati in tempo reale dai siti web nell'istante stesso in cui glielo chiedi. A differenza degli scraper tradizionali, che lavorano su base programmata o si appoggiano a dati in cache, i live crawler ti danno informazioni aggiornate al secondo. Spesso integrano anche l'AI per individuare i campi giusti e navigare da soli tra le pagine, risultando così più rapidi e più semplici da usare.
2. Perché i dati in tempo reale contano per i team di vendite e operations?
I dati in tempo reale aiutano i team a decidere all'istante in contesti che cambiano in fretta. Che si tratti di adeguare i prezzi alle mosse dei concorrenti, reagire ai trend dei social o seguire gli aggiornamenti del magazzino, avere sotto mano gli ultimi dati permette alle aziende di restare competitive, evitare ritardi e far crescere il fatturato.
3. In che modo l'AI migliora il live crawling?
L'AI semplifica il live crawling individuando da sola i campi rilevanti, adattandosi ai cambi di layout, gestendo paginazione e sottopagine e perfino trasformando i dati (per esempio traducendo il testo o convertendo le valute). Il risultato è che diventa accessibile anche a chi non è tecnico e riduce il bisogno di configurazioni manuali.
4. Quali sono alcuni casi d'uso concreti del live crawling?
I live crawler servono per monitorare i prezzi sulle piattaforme e-commerce, estrarre commenti da TikTok o Twitter, generare lead di vendita da LinkedIn, raccogliere recensioni dei clienti e tenere d'occhio i contenuti dei concorrenti. Casi d'uso che attraversano settori come retail, immobiliare, marketing e logistica.
5. Come si comincia con uno strumento di live crawler come Thunderbit?
Per partire basta installare l'estensione Chrome di Thunderbit, aprire una pagina web e usare la funzione "Suggerimento campi con AI" per scegliere i dati. Dopo aver premuto "Estrai", lo strumento raccoglie i dati e li restituisce in un formato strutturato, esportabile nei fogli di calcolo o integrabile con strumenti come Google Sheets o Airtable — senza scrivere codice.




