
Il web è una miniera infinita di dati: oggi sono il carburante di qualsiasi attività moderna. Che tu sia nel commerciale, nell’e-commerce, nel real estate o semplicemente voglia tenere d’occhio i competitor, avere le informazioni giuste fa davvero la differenza. Ma diciamocelo: nessuno ha voglia di perdere ore a copiare e incollare dati dai siti nei fogli Excel. Qui entra in gioco l’estrazione dati dal web, e ti assicuro che è molto più facile di quanto sembri.
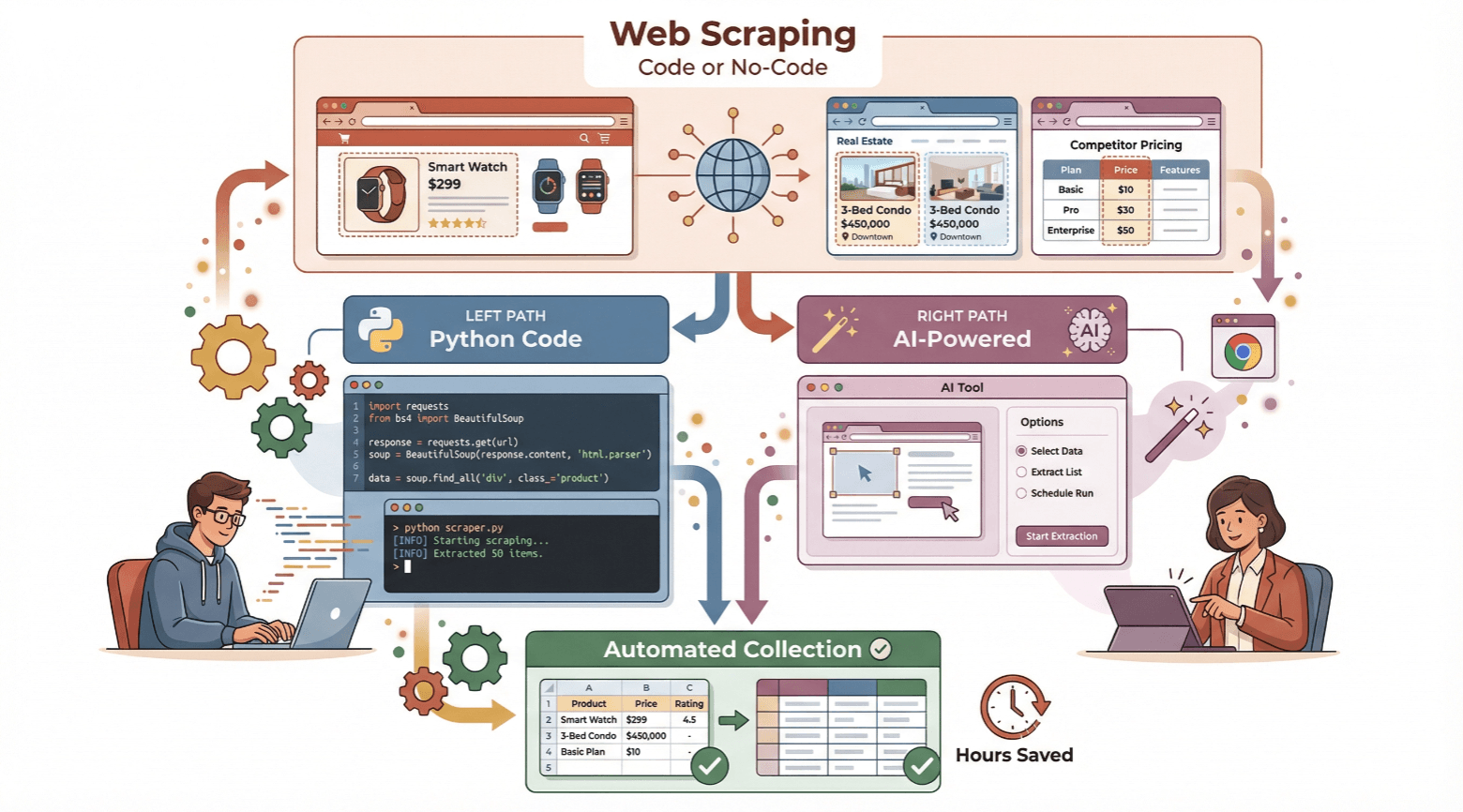
In questa guida ti spiego come fare e creare un estrattore web, sia che tu voglia smanettare un po’ con Python, sia che preferisca una soluzione senza codice e con intelligenza artificiale come . Ti racconto i concetti base, ti accompagno passo dopo passo in entrambe le modalità e ti aiuto a scegliere quella più adatta a te. Pronto a risparmiare tempo e sfruttare la potenza dell’automazione? Partiamo subito.
Cos’è un Estrattore Web? Le Basi da Conoscere
Un estrattore web è semplicemente uno strumento—software o servizio—che raccoglie in automatico informazioni dai siti internet. Immagina di dover mettere insieme una lista di tutte le caffetterie della tua città, con indirizzi e numeri di telefono. Potresti passare ore a cliccare e copiare ogni dettaglio a mano (addio dita!), oppure lasciare che un estrattore web faccia tutto per te.
Pensa all’estrattore web come a un assistente digitale che legge le pagine online, trova i dati che ti servono (prezzi, nomi prodotti, contatti, ecc.) e li organizza in modo ordinato in un foglio di calcolo o in un database. Invece di saltare tra browser ed Excel, l’estrattore automatizza tutto: raccoglie, analizza e salva i dati in pochissimo tempo.
Ecco come funziona in pratica:
- Richiesta: L’estrattore invia una richiesta alla pagina web e scarica il codice HTML.
- Analisi: Esamina l’HTML per individuare i dati che ti servono (ad esempio, il prezzo dentro un tag
<span>). - Estrazione: Preleva le informazioni e le salva in un formato strutturato (CSV, Excel, Google Sheets, ecc.).
Copiare e incollare a mano è come scavare una buca con un cucchiaino. L’estrattore web è la ruspa che fa tutto in un attimo.
Perché Creare un Estrattore Web è una Mossa Furba per il Business
L’estrazione dati dal web non è più roba da smanettoni o data scientist: oggi è fondamentale per chiunque abbia bisogno di informazioni fresche e affidabili. Ormai quasi il prende decisioni guidate dai dati, e il mercato globale dell’estrazione web è destinato a raddoppiare entro il 2030.
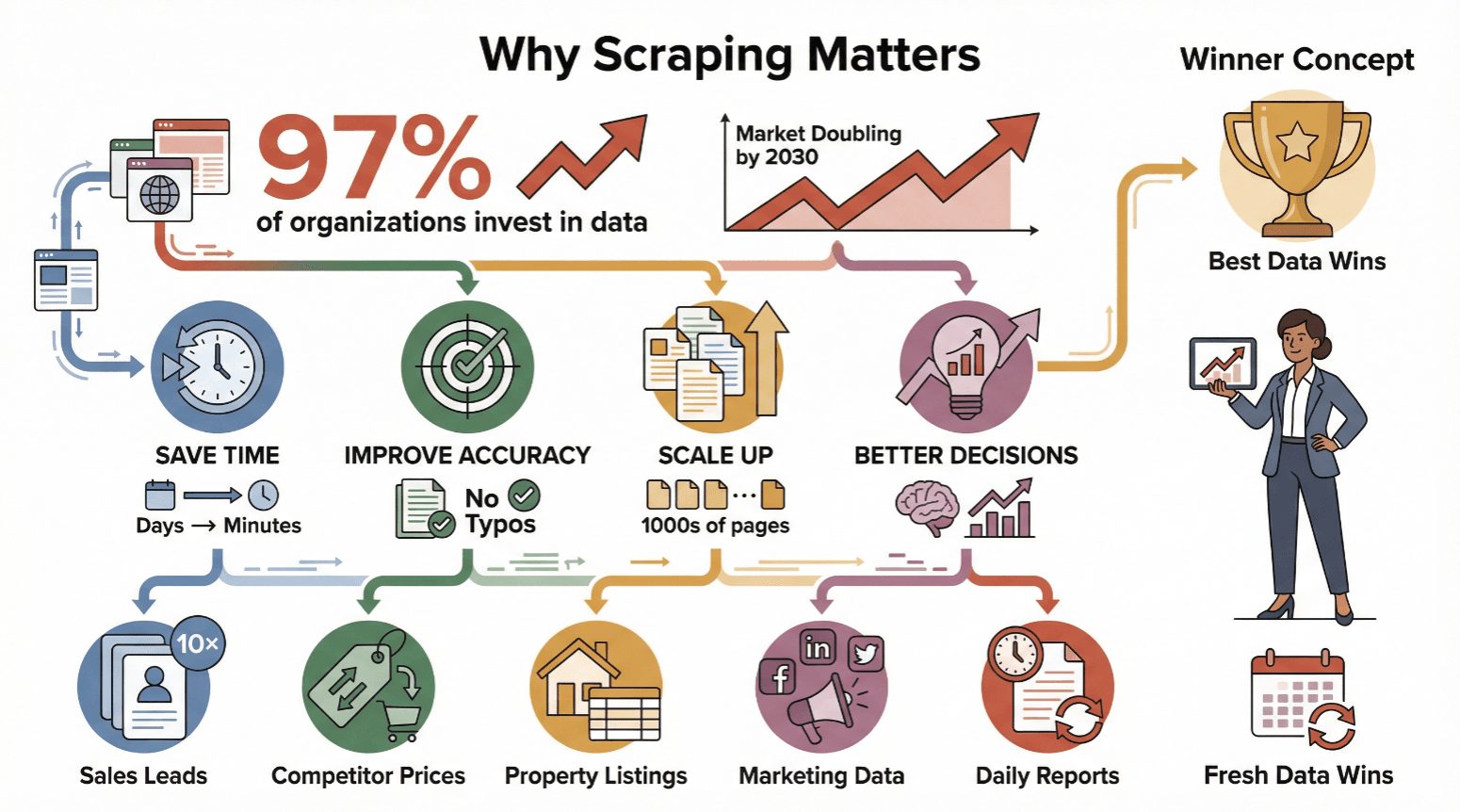
Ecco perché sempre più aziende puntano sull’estrazione web:
- Risparmio di tempo: Automatizzare significa trasformare giorni di lavoro manuale in pochi minuti.
- Maggiore precisione: Il software non si stanca e non sbaglia a digitare.
- Scalabilità: Puoi estrarre dati da migliaia di pagine, non solo da poche.
- Decisioni migliori: Dati freschi = scelte più intelligenti, che si tratti di prezzi, lead o trend di mercato.
Ecco qualche esempio concreto:
| Caso d’uso | Chi ne beneficia | Risultato tipico |
|---|---|---|
| Estrazione di lead da elenchi online | Team commerciali | 10× più contatti, ore risparmiate nella ricerca |
| Monitoraggio prezzi dei concorrenti e-commerce | Manager e-commerce | Aggiornamenti in tempo reale, protezione dei margini |
| Raccolta annunci immobiliari da portali | Agenzie immobiliari | Scoperta più rapida di opportunità, dati di mercato sempre aggiornati |
| Raccolta dati marketing da web/social | Team marketing | Campagne più mirate, monitoraggio delle performance migliorato |
| Automazione report web giornalieri | Operazioni, analisti | Riduzione costi, meno errori, report puntuali e consistenti |
In breve: chi ha i dati migliori e più aggiornati, vince.
Guida Facile: Come Creare un Estrattore Web Semplice con Python
Se vuoi capire davvero come funziona l’estrazione web, Python è un ottimo punto di partenza. Anche senza essere un programmatore, puoi realizzare un estrattore base in pochi passaggi. Ecco come fare:
Prepara l’Ambiente
Per prima cosa, installa Python sul tuo computer. Scarica l’ultima versione da e segui le istruzioni per Windows o Mac. Durante l’installazione, ricordati di spuntare “Add Python to PATH”.
Poi, apri il terminale o prompt dei comandi e installa le librerie che ti servono:
1pip install requests
2pip install bs4
3pip install pandasrequestsserve per scaricare le pagine web.bs4(Beautiful Soup) ti aiuta a leggere l’HTML.pandasè perfetto per salvare i dati in CSV o Excel.
Analizza la Struttura del Sito
Prima di scrivere codice, devi capire dove sono i dati nell’HTML. Apri il sito che ti interessa con Chrome, fai clic destro sul dato che vuoi (ad esempio, il titolo di un lavoro) e scegli “Ispeziona”. Vedrai evidenziato l’elemento HTML—magari un tag <a> con una classe come jobtitle. Segnati questi dettagli: ti serviranno per dire all’estrattore cosa cercare.
Scrivi ed Esegui l’Estrattore
Supponiamo tu voglia estrarre titoli di lavoro e nomi azienda da una pagina di annunci. Ecco uno script di esempio:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4URL = "https://example.com/jobs" # Sostituisci con l’URL che ti interessa
5response = requests.get(URL)
6soup = BeautifulSoup(response.text, 'html.parser')
7# Trova tutti i titoli e le aziende (aggiorna i selettori se necessario)
8titles = [t.get_text().strip() for t in soup.find_all('a', class_='jobtitle')]
9companies = [c.get_text().strip() for c in soup.find_all('div', class_='company')]
10# Salva in CSV
11df = pd.DataFrame({'Titolo Lavoro': titles, 'Azienda': companies})
12df.to_csv('jobs.csv', index=False)
13print("Estrazione completata! Dati salvati in jobs.csv")- Cambia URL e nomi delle classi in base al sito che vuoi estrarre.
- Esegui lo script dal terminale:
python tuo_script.py - Apri
jobs.csvper vedere i risultati.
Dritta: Per siti più complessi (con paginazione o contenuti dinamici), potresti dover aggiungere cicli o usare strumenti come Selenium. Ma per tante pagine statiche, questo metodo va benissimo.
Zero Codice: Come Creare un Estrattore Web con Thunderbit
E se non vuoi scrivere nemmeno una riga di codice? Qui entra in gioco : un estrattore web AI senza codice, pensato per chi lavora in azienda. Con Thunderbit, passi da “mi serve questo dato” a “ecco il mio Excel” in due click.
Ecco come funziona:
Passo 1: Installa l’Estensione Chrome di Thunderbit
Vai alla e aggiungila al browser. Registrati gratis (il piano free ti permette di provare su alcune pagine).
Passo 2: Vai sul Sito da Estrarre
Apri la pagina che ti interessa su Chrome. Se serve, fai login e scorri per caricare tutti i contenuti dinamici.
Passo 3: Descrivi i Dati che Ti Servono
Clicca sull’icona Thunderbit per aprire la barra laterale. Puoi:
- Cliccare su “AI Suggerisci Campi” e lasciare che l’AI di Thunderbit analizzi la pagina e proponga le colonne (es. “Nome Prodotto”, “Prezzo”, “Immagine”).
- Oppure scrivere una richiesta in italiano (es. “Estrai tutti i titoli dei libri e gli autori da questa pagina”).
L’AI di Thunderbit suggerirà automaticamente i campi e i tipi di dato. Puoi rinominare, aggiungere o eliminare colonne come preferisci.
Passo 4: Avvia la Prima Estrazione
Quando hai impostato i campi, premi “Estrai”. Thunderbit raccoglierà i dati, gestirà la paginazione se necessario e mostrerà tutto in una tabella ordinata. Se vuoi dettagli aggiuntivi da sottopagine (come le pagine prodotto), clicca su “Estrai Sottopagine”—Thunderbit visiterà ogni link e raccoglierà le informazioni extra.
Passo 5: Rivedi ed Esporta i Risultati
Controlla i dati nella tabella Thunderbit. Quando sei soddisfatto, clicca su “Esporta” e scegli il formato: Excel, CSV, Google Sheets, Airtable, Notion o JSON. Le esportazioni sono gratuite e illimitate.
Tutto qui. Niente codice, niente modelli, zero complicazioni.
Confronto: Estrattore Web Classico vs. No-Code
Ecco come si confrontano le due soluzioni:
| Soluzione | Tempo di setup | Competenze richieste | Manutenzione | Flessibilità | Opzioni di esportazione |
|---|---|---|---|---|---|
| Python + Beautiful Soup | Ore/giorni | Programmazione, HTML base | Alta (si rompe spesso) | Molto alta | CSV, Excel, JSON (via codice) |
| Vecchi strumenti no-code | 30-60 min | Un po’ di conoscenze tech | Media (fix manuali) | Buona per siti statici | CSV, Excel |
| Thunderbit (AI No-Code) | Minuti | Nessuna (italiano semplice) | Bassa (AI si adatta) | Alta (siti dinamici) | Excel, CSV, Sheets, Notion... |
Con Thunderbit e l’AI, passi meno tempo a configurare e correggere estrattori, e più tempo a usare davvero i tuoi dati.
Come Superare le Difficoltà degli Estrattori Web Classici
Gli estrattori tradizionali hanno qualche grattacapo:
- Cambiamenti nei siti: Se il sito cambia struttura, il codice si rompe. L’AI di Thunderbit si adatta in automatico alla maggior parte delle modifiche, senza bisogno di riscrivere nulla.
- Blocchi anti-bot: Molti siti bloccano gli script automatici. Thunderbit può lavorare direttamente nel browser (usando il tuo login/sessione) o nel cloud per maggiore velocità.
- Contenuti dinamici: Pagine con scroll infinito o pulsanti “Carica altro” possono bloccare gli estrattori base. Thunderbit gestisce scroll automatico e elementi interattivi di default.
- Dati protetti da login: Con la modalità browser di Thunderbit, se puoi vedere i dati su Chrome, puoi estrarli.
In breve, Thunderbit è pensato per affrontare le complessità dei siti moderni—così non devi pensarci tu.
Massimizza l’Efficienza: Le Funzionalità Avanzate di Thunderbit
Thunderbit non si limita a raccogliere dati: li rende subito pronti all’uso, in modo rapido e pulito. Ecco alcune funzioni che fanno la differenza:
Auto-paginazione e Estrazione da Sottopagine
Devi estrarre centinaia di prodotti su più pagine? Thunderbit rileva la paginazione (pulsanti “Avanti”, scroll infinito) e raccoglie tutto in una sola volta. Vuoi dettagli extra da sottopagine? Clicca su “Estrai Sottopagine” e Thunderbit visiterà ogni link, aggiungendo campi come info venditore o specifiche prodotto.
Suggerimenti AI per Campi e Strutturazione Dati
L’AI di Thunderbit non si limita a indovinare le colonne: capisce il contesto. Può etichettare le colonne, assegnare tipi di dato (testo, numero, immagine, email) e applicare istruzioni personalizzate (es. “solo prezzi sopra i 100€” o “traduce le descrizioni in inglese”). Puoi aggiungere prompt per categorizzare, riassumere o riformattare i dati già in fase di estrazione.
Modelli Pronti e Estrazione Istantanea
Per i siti più popolari (Amazon, Zillow, Google Maps, Instagram), Thunderbit offre modelli preimpostati: scegli il sito e tutti i campi sono già configurati. Nessuna impostazione necessaria.
Pianificazione e Automazione
Hai bisogno di dati aggiornati ogni giorno? Imposta una pianificazione (“ogni lunedì alle 9”) e Thunderbit estrarrà automaticamente, aggiornando il tuo Google Sheet o database senza che tu debba fare nulla.
Estrazione in Cloud o Locale
Scegli se eseguire l’estrazione nel browser (ideale per siti con login o interattivi) o nel cloud (più veloce per dati pubblici—fino a 50 pagine alla volta).
Le funzioni avanzate di Thunderbit lo rendono la scelta ideale per chi cerca affidabilità, scalabilità e facilità d’uso nell’estrazione web.
Guida Pratica: Come Creare un Estrattore Web con Thunderbit
Ecco la checklist per iniziare subito:
- Installa Thunderbit: e registrati.
- Apri il sito target: Fai login se serve, scorri per caricare i contenuti.
- Apri la barra laterale Thunderbit: Clicca sull’icona dell’estensione.
- Descrivi i dati: Clicca su “AI Suggerisci Campi” o scrivi la tua richiesta.
- Rivedi i campi: Rinomina, aggiungi o elimina colonne.
- Clicca “Estrai”: Lascia lavorare Thunderbit.
- (Opzionale) Estrai Sottopagine: Per dati più approfonditi, clicca su “Estrai Sottopagine”.
- Controlla i risultati: Verifica la tabella.
- Esporta i dati: Scegli Excel, CSV, Google Sheets, Notion, Airtable o JSON.
- Salva/Modello/Pianifica: Salva la configurazione o pianifica estrazioni ricorrenti.
Tips utili:
- Se mancano dati, prova a riformulare la richiesta o usa istruzioni personalizzate.
- Per contenuti dinamici, assicurati di essere in modalità browser.
- Se raggiungi il limite del piano gratuito, valuta l’upgrade per più pagine.
Conclusioni & Cosa Ricordare
Creare un estrattore web non è più roba da programmatori. Che tu voglia imparare Python o preferisca affidarti all’AI, oggi gli strumenti sono davvero alla portata di tutti.
Ecco i punti chiave:
- L’estrazione web fa risparmiare tempo, aumenta la precisione e permette decisioni basate sui dati.
- Python è ottimo per imparare e per progetti su misura, ma richiede codice e manutenzione.
- Thunderbit offre una soluzione rapida e senza codice: basta descrivere ciò che vuoi e cliccare “Estrai”.
- Funzionalità avanzate come auto-paginazione, estrazione da sottopagine e suggerimenti AI rendono Thunderbit uno strumento potente per le aziende.
- Puoi provare Thunderbit gratis e vedere i risultati in pochi minuti.
Pronto a dire addio al copia-incolla e iniziare ad automatizzare? e scopri quanto è semplice estrarre dati dal web. E se vuoi approfondire, visita il per altre guide e consigli.
Domande Frequenti
1. Devo saper programmare per creare un estrattore web?
No! Anche se programmare (ad esempio con Python + Beautiful Soup) ti dà il massimo controllo, strumenti no-code come Thunderbit permettono a chiunque di creare estrattori potenti usando semplici richieste in italiano e pochi click.
2. Che tipo di dati posso estrarre con Thunderbit?
Thunderbit può raccogliere testo, numeri, immagini, email, numeri di telefono e molto altro da quasi ogni sito—comprese liste paginati e sottopagine. Puoi anche usare modelli pronti per i siti più popolari.
3. Come si comporta Thunderbit se il sito cambia struttura?
L’AI di Thunderbit si adatta automaticamente alla maggior parte dei cambiamenti. A differenza degli estrattori tradizionali che si bloccano, Thunderbit usa la comprensione semantica per continuare a funzionare senza interventi.
4. L’estrazione web è legale e sicura?
L’estrazione web è legale se raccogli dati pubblici e rispetti i termini d’uso del sito. Thunderbit promuove un uso responsabile e offre funzioni per aiutarti a restare conforme.
5. Posso pianificare estrazioni ricorrenti o automatizzare le esportazioni?
Certo! Thunderbit ti permette di programmare estrazioni a qualsiasi intervallo (giornaliero, settimanale, ecc.) ed esportare i risultati direttamente su Google Sheets, Notion, Airtable, Excel o CSV—senza lavoro manuale.
Vuoi automatizzare la raccolta dati? e scopri quanto è facile per tutti estrarre dati dal web.
Scopri di più