

Internet trabocca di dati — al punto che sono diventati la linfa vitale delle aziende moderne. Che tu lavori nelle vendite, nell’e-commerce, nel real estate o voglia semplicemente tenere d’occhio la concorrenza, avere i dati giusti a portata di mano può fare davvero la differenza. Ma diciamolo chiaramente: nessuno vuole passare ore a fare copia-incolla di informazioni dai siti web nei fogli di calcolo. Ed è qui che entra in gioco il web scraping, e fidati, è molto meno intimidatorio di quanto sembri.
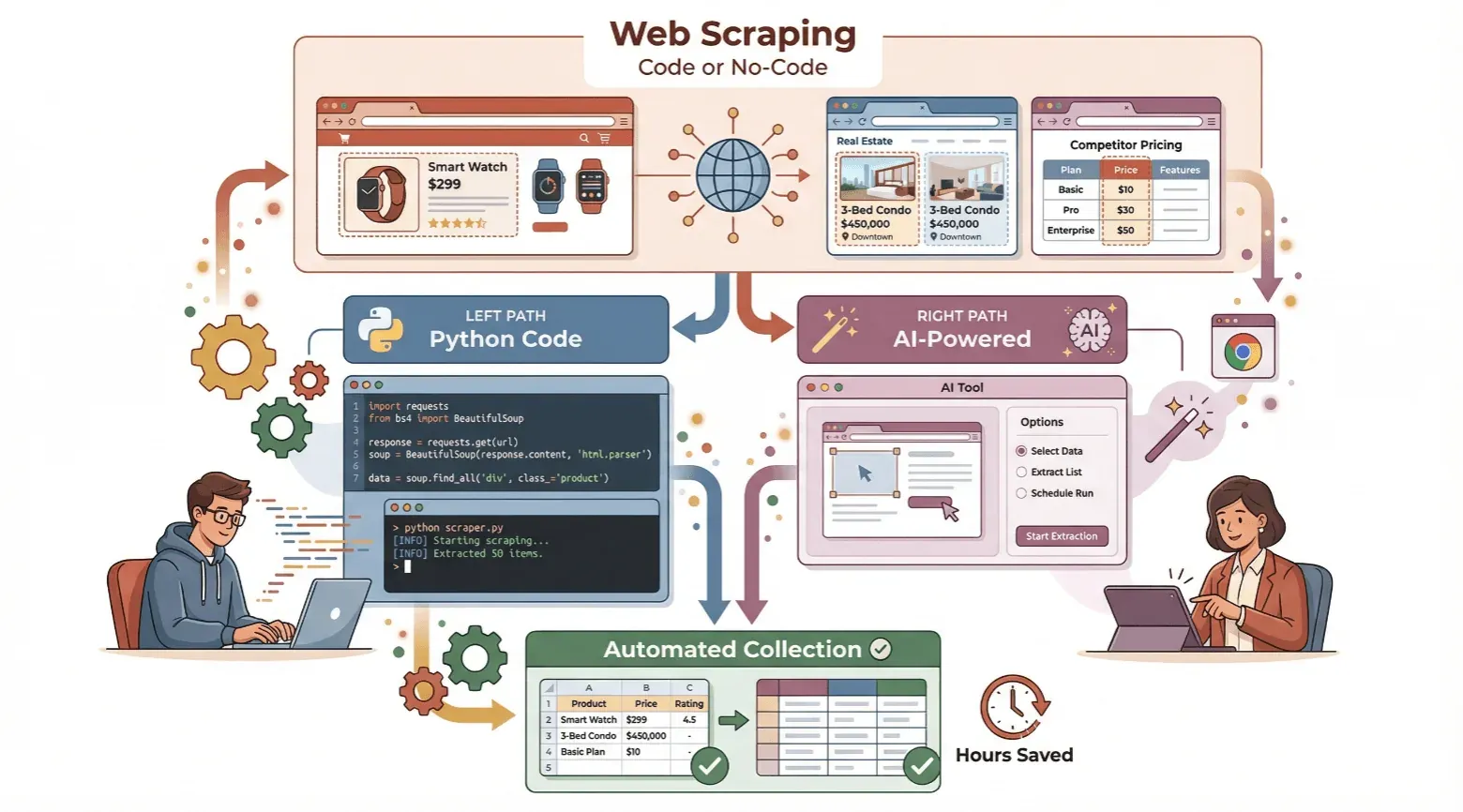
In questa guida ti mostrerò come creare un estrattore web — sia che tu sia alle prime armi e voglia provare a programmare in Python, sia che tu preferisca saltare il codice e usare uno strumento no-code basato su AI come Thunderbit. Ti spiegherò le basi, ti guiderò in entrambi gli approcci passo dopo passo e ti aiuterò a capire quale strada si adatta meglio alle tue esigenze. Pronto a risparmiare tempo e a sbloccare il potenziale della raccolta automatica dei dati? Partiamo.
Che cos’è un Estrattore Web? Le basi
Un estrattore web è semplicemente uno strumento — software o servizio — che estrae automaticamente informazioni dai siti web. Immagina di dover raccogliere un elenco di tutte le caffetterie della tua città, con indirizzi e numeri di telefono. Potresti passare ore a cliccare tra le pagine e copiare ogni dettaglio a mano (ciao, stanchezza da Ctrl+C), oppure lasciare che un estrattore web faccia il lavoro pesante al posto tuo.
Pensa a un estrattore web come a un assistente digitale che legge le pagine web, trova i dati che ti servono (come prezzi, nomi dei prodotti o informazioni di contatto) e li organizza in modo ordinato in un foglio di calcolo o in un database. Invece di passare manualmente da una scheda del browser a Excel, l’estrattore automatizza il processo — recuperando, analizzando e salvando i dati in una frazione del tempo.
Ecco come funziona sotto il cofano:
- Richiesta: l’estrattore invia una richiesta a una pagina web e scarica l’HTML grezzo.
- Analisi: esamina l’HTML per trovare i dati specifici che ti interessano (come il prezzo dentro un tag
<span>). - Estrazione: preleva i dati e li salva in un formato strutturato (CSV, Excel, Google Sheets, ecc.).
Il copia-incolla manuale è come scavare una buca con un cucchiaio. Il web scraping è come arrivare con una scavatrice.
Perché creare un Estrattore Web è importante per il business
Il web scraping non è solo per smanettoni o data scientist: è diventato indispensabile per chiunque abbia bisogno di informazioni affidabili e aggiornate. Quasi il 97% delle grandi organizzazioni investe ormai in decisioni basate sui dati, e le analisi di mercato sul settore del web scraping prevedono costantemente una crescita continua per più anni fino alla fine del decennio.
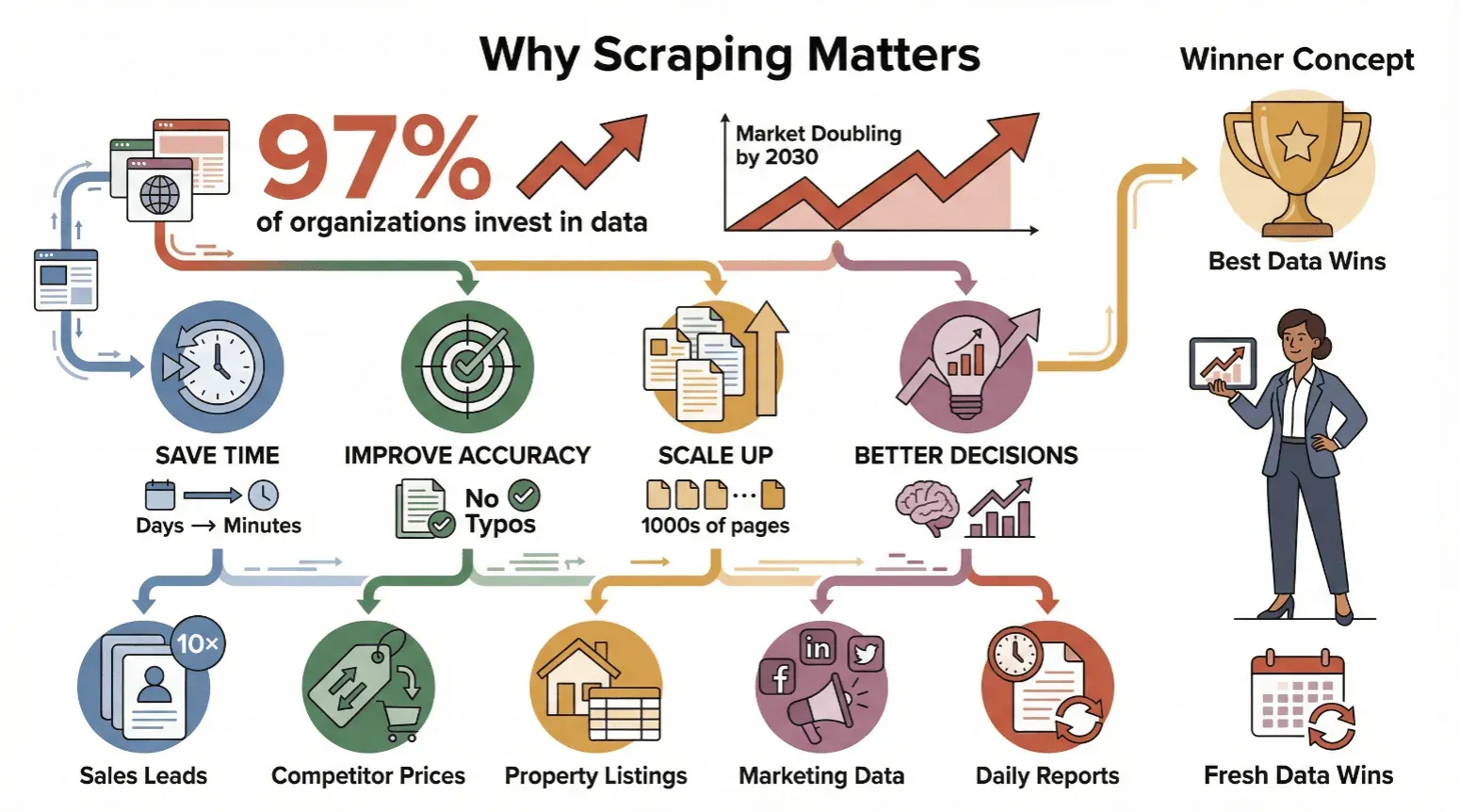
Ecco perché aziende di ogni dimensione stanno adottando il web scraping:
- Risparmiare tempo: l’estrazione automatica trasforma giorni di lavoro manuale in minuti.
- Migliorare la precisione: il software non si stanca e non fa refusi.
- Scalare: estrai dati da migliaia di pagine, non solo da poche.
- Prendere decisioni migliori: dati freschi significano mosse più intelligenti — che si tratti di aggiornare i prezzi, trovare lead o monitorare i trend.
Vediamo alcuni casi d’uso concreti:
| Caso d’uso | Chi ne beneficia | Risultato tipico |
|---|---|---|
| Estrazione di lead commerciali da elenchi | Team di vendita | 10× più lead, ore risparmiate nella ricerca di prospect |
| Monitoraggio dei prezzi dei competitor nei siti e-commerce | Manager e-commerce | Aggiornamenti dei prezzi in tempo reale, protezione dei margini |
| Aggregazione di annunci immobiliari | Agenzie immobiliari | Scoperta più rapida delle opportunità, dati di mercato sempre aggiornati |
| Raccolta di dati marketing dal web/social media | Team marketing | Campagne più mirate, monitoraggio delle performance migliorato |
| Automazione dei report giornalieri sui dati web | Operazioni, analisti | Costi di lavoro ridotti, meno errori, reporting costante e puntuale |
In breve: vince chi ha i dati migliori e più aggiornati.
Guida per principianti: come creare un semplice Estrattore Web con Python
Se sei curioso di capire come funziona il web scraping “sotto il cofano”, Python è un ottimo punto di partenza. Anche se sei alle prime armi con la programmazione, puoi costruire un estrattore di base in pochi passaggi. Ecco come:
Preparare l’ambiente
Per prima cosa, devi avere Python installato sul computer. Scarica l’ultima versione da python.org e segui le istruzioni per il tuo sistema operativo (Windows o Mac). Durante l’installazione, assicurati di selezionare “Add Python to PATH”.
Poi apri il terminale o il prompt dei comandi e installa le librerie necessarie:
pip install requests
pip install bs4
pip install pandas
requeststi permette di recuperare le pagine web.bs4(Beautiful Soup) aiuta ad analizzare l’HTML.pandasè ottimo per salvare i dati in CSV o Excel.
Ispezionare la struttura del sito
Prima di scrivere il codice, devi capire dove si trovano i dati nell’HTML. Apri il sito di destinazione in Chrome, fai clic destro sul dato che ti interessa (come un titolo di lavoro) e seleziona “Ispeziona”. Vedrai l’elemento HTML evidenziato — magari un tag <a> con una classe come jobtitle. Prendi nota di questi tag e di queste classi: serviranno per dire all’estrattore cosa cercare.
Scrivere ed eseguire l’estrattore
Supponiamo che tu voglia estrarre titoli di lavoro e nomi delle aziende da una pagina di annunci. Ecco uno script semplice:
import requests
from bs4 import BeautifulSoup
import pandas as pd
URL = "https://example.com/jobs" # Sostituisci con l'URL di destinazione
response = requests.get(URL)
soup = BeautifulSoup(response.text, 'html.parser')
# Trova tutti i titoli di lavoro e i nomi delle aziende (aggiorna i selettori se necessario)
titles = [t.get_text().strip() for t in soup.find_all('a', class_='jobtitle')]
companies = [c.get_text().strip() for c in soup.find_all('div', class_='company')]
# Salva in CSV
df = pd.DataFrame({'Titolo del lavoro': titles, 'Azienda': companies})
df.to_csv('jobs.csv', index=False)
print("Estrazione completata! Dati salvati in jobs.csv")
- Adatta URL e nomi delle classi in base al sito che vuoi estrarre.
- Esegui lo script nel terminale:
python yourscript.py - Apri
jobs.csvper vedere i risultati.
Consiglio pro: per siti più complessi (con paginazione o contenuti dinamici), dovrai aggiungere cicli o usare strumenti come Selenium. Ma per molte pagine statiche, questo approccio funziona benissimo.
Semplicità no-code: come creare un Estrattore Web con Thunderbit
E se non volessi proprio avere a che fare con il codice? È qui che entra in gioco Thunderbit — un estrattore web no-code basato su AI pensato per gli utenti business. Per pagine semplici e ben strutturate, Thunderbit può portarti da “Mi serve questo dato” a un foglio di calcolo utilizzabile in un paio di clic — i siti più pesanti con login, difese anti-bot o layout insoliti richiedono ancora un po’ di regolazione, ma il punto di partenza è molto più basso rispetto a scrivere un parser da zero.
Estrai dati da qualsiasi sito web usando l’AI Get Started Free
Ecco come funziona:
Passo 1: installa l’estensione Chrome di Thunderbit
Vai alla pagina di download dell’estensione Chrome di Thunderbit e aggiungila al browser. Registrati per un account gratuito (il piano free ti permette di estrarre alcune pagine per provarlo).
Passo 2: vai sul sito di destinazione
Apri la pagina che vuoi estrarre in Chrome. Fai login se necessario e scorri la pagina per caricare eventuali contenuti dinamici.
Passo 3: descrivi i dati che ti servono
Fai clic sull’icona di Thunderbit per aprire la barra laterale. Puoi:
- Fare clic su “AI Suggest Fields” e lasciare che l’AI di Thunderbit analizzi la pagina e proponga le colonne (come “Nome prodotto”, “Prezzo”, “Immagine”).
- Oppure digitare un prompt in linguaggio naturale (per esempio: “Estrai tutti i titoli dei libri e gli autori da questa pagina”).
L’AI di Thunderbit suggerirà automaticamente campi e tipi di dati. Potrai rinominare, aggiungere o eliminare i campi in base alle tue esigenze.
Passo 4: esegui la tua prima estrazione
Una volta impostati i campi, premi “Scrape”. Thunderbit estrarrà i dati, gestirà la paginazione se necessario e mostrerà tutto in una tabella ordinata. Se vuoi più dettagli dalle sottopagine (come le pagine dei singoli prodotti), fai clic su “Scrape Subpages” — Thunderbit visiterà ogni link e raccoglierà informazioni extra.
Passo 5: revisione ed esportazione dei risultati
Controlla i dati nella tabella di Thunderbit. Quando sei soddisfatto, fai clic su “Export” e scegli il formato: Excel, CSV, Google Sheets, Airtable, Notion o JSON. Le esportazioni sono gratuite e illimitate.
Tutto qui. Niente codice, niente template, niente stress.
Prova gratis Thunderbit AI Web Scraper
Confronto tra soluzioni tradizionali e no-code per l’Estrattore Web
Vediamo come si confrontano i due approcci:
| Soluzione | Tempo di configurazione | Competenze richieste | Manutenzione | Flessibilità | Opzioni di esportazione |
|---|---|---|---|---|---|
| Python + Beautiful Soup | Ore/giorni | Programmazione, basi HTML | Alta (si rompe facilmente) | Molto alta | CSV, Excel, JSON (tramite codice) |
| Vecchi strumenti no-code | 30-60 min | Un po’ di competenze tecniche | Media (correzione manuale) | Buona per siti statici | CSV, Excel |
| Thunderbit (AI no-code) | Minuti | Nessuna (italiano semplice) | Bassa (l’AI si adatta) | Alta (siti dinamici) | Excel, CSV, Sheets, Notion... |
L’approccio basato su AI di Thunderbit significa meno tempo speso a configurare e correggere gli estrattori, e più tempo a usare davvero i tuoi dati.
Superare le sfide dei tradizionali Estrattori Web
Gli estrattori tradizionali hanno alcuni punti dolenti ben noti:
- Cambiamenti del sito: se un sito aggiorna il layout, il codice può rompersi. L’AI di Thunderbit si adatta automaticamente alla maggior parte dei cambiamenti, quindi non devi riscrivere nulla.
- Misure anti-bot: molti siti bloccano gli script automatici. Thunderbit può funzionare nel browser (usando il tuo login/sessione) oppure nel cloud per maggiore velocità.
- Contenuti dinamici: pagine con scroll infinito o pulsanti “Carica altro” possono mettere in difficoltà gli estrattori base. L’AI di Thunderbit gestisce automaticamente lo scrolling e gli elementi interattivi.
- Dati accessibili solo dopo login: con la modalità browser di Thunderbit, se puoi vederlo in Chrome, puoi estrarlo.
In breve, Thunderbit è progettato per gestire la realtà spesso caotica dei siti moderni — così non devi farlo tu.
Aumentare l’efficienza: le funzionalità avanzate di web scraping di Thunderbit
Thunderbit non serve solo a ottenere dati: serve a ottenerli velocemente, in modo pulito e pronti all’uso. Ecco alcune funzioni che apprezzo particolarmente:
Paginazione automatica ed estrazione delle sottopagine
Devi estrarre centinaia di prodotti su più pagine? Thunderbit rileva la paginazione (pulsanti Avanti, scroll infinito) e raccoglie tutto in una volta. Vuoi più dettagli dalle sottopagine? Fai clic su “Scrape Subpages” e Thunderbit visiterà ogni link, recuperando campi aggiuntivi (come informazioni sul venditore o specifiche del prodotto).
Suggerimenti AI per i campi e strutturazione dei dati
L’AI di Thunderbit non si limita a indovinare le colonne: capisce il contesto. Può etichettare le colonne, assegnare tipi di dati (testo, numero, immagine, email) e persino applicare istruzioni personalizzate (come “solo prezzi sopra i 100 dollari” o “traduci le descrizioni in inglese”). Puoi aggiungere prompt per classificare, riassumere o riformattare i dati mentre vengono estratti.
Template ed estrazione istantanea
Per i siti più popolari (Amazon, Zillow, Google Maps, Instagram), Thunderbit offre template istantanei — ti basta scegliere il sito e tutti i campi sono già configurati. Nessuna configurazione richiesta.
Pianificazione e automazione
Ti servono dati freschi ogni giorno? Imposta una pianificazione (“ogni lunedì alle 9”) e Thunderbit estrarrà automaticamente i dati, aggiornando il tuo Google Sheet o database senza che tu debba muovere un dito.
Estrazione nel cloud vs. in locale
Puoi scegliere se eseguire le estrazioni nel browser (ottimo per siti con login o interattivi) oppure nel cloud (più veloce per dati pubblici — fino a 50 pagine alla volta).
Che cos’è il Data Scraping e come farlo nel 2025 Get Started Free
Le funzionalità avanzate di Thunderbit lo rendono una scelta eccellente per gli utenti business che cercano un web scraping affidabile, scalabile e facile da usare.
Guida passo dopo passo: come creare un Estrattore Web con Thunderbit
Ecco la checklist rapida per partire:
- Installa Thunderbit: aggiungi l’estensione Chrome e registrati.
- Apri il sito di destinazione: fai login se necessario, scorri per caricare i contenuti.
- Apri la barra laterale di Thunderbit: fai clic sull’icona dell’estensione.
- Descrivi i dati: fai clic su “AI Suggest Fields” oppure digita il tuo prompt.
- Rivedi i campi: rinomina, aggiungi o elimina le colonne se necessario.
- Fai clic su “Scrape”: lascia fare a Thunderbit.
- (Opzionale) Estrai le sottopagine: per dati più approfonditi, fai clic su “Scrape Subpages”.
- Controlla i risultati: verifica l’accuratezza della tabella.
- Esporta i dati: scegli Excel, CSV, Google Sheets, Notion, Airtable o JSON.
- Salva/Template/Pianifica: salva la configurazione per la prossima volta o pianifica estrazioni ricorrenti.
Consigli per la risoluzione dei problemi:
- Se mancano dei dati, prova a riformulare il prompt o a usare istruzioni personalizzate.
- Per contenuti dinamici, assicurati di essere in modalità browser.
- Se raggiungi il limite del piano gratuito, valuta un upgrade per estrarre più pagine.
Scopri prezzi e piani di Thunderbit
Conclusione e punti chiave
Creare un estrattore web non è più solo per programmatori. Che tu voglia rimboccarti le maniche e scrivere in Python, oppure lasciare che sia l’AI a fare il lavoro pesante, oggi gli strumenti sono più accessibili che mai.
Ecco cosa ricordare:
- Il web scraping fa risparmiare tempo, aumenta la precisione e sblocca decisioni basate sui dati.
- Python è ottimo per imparare e per progetti personalizzati, ma richiede programmazione e manutenzione.
- Thunderbit offre una soluzione rapida e no-code — basta descrivere ciò che vuoi e fare clic su “Scrape”.
- Funzionalità avanzate come la paginazione automatica, l’estrazione delle sottopagine e i suggerimenti AI per i campi rendono Thunderbit uno strumento potentissimo per gli utenti business.
- Puoi provare Thunderbit gratis e vedere i risultati in pochi minuti.
Pronto a smettere di fare copia-incolla e iniziare ad automatizzare? Scarica Thunderbit e scopri quanto può essere semplice il web scraping. E se vuoi approfondire, visita il blog di Thunderbit per altri tutorial e consigli.
Prova gratis Thunderbit AI Web Scraper Get Started Free
FAQ
1. Devo saper programmare per creare un estrattore web?
No! Anche se programmare (come con Python + Beautiful Soup) ti dà il pieno controllo, gli strumenti no-code come Thunderbit permettono a chiunque di creare potenti estrattori web usando prompt in italiano semplice e un paio di clic.
2. Che tipo di dati posso estrarre con Thunderbit?
Thunderbit può estrarre testo, numeri, immagini, email, numeri di telefono e molto altro da quasi qualsiasi sito web — inclusi elenchi con paginazione e sottopagine. Puoi anche usare template per i siti più popolari.
3. Come gestisce Thunderbit i siti che cambiano layout?
L’AI di Thunderbit si adatta automaticamente alla maggior parte dei cambi di layout. A differenza degli estrattori tradizionali, che si rompono quando un sito si aggiorna, Thunderbit usa una comprensione semantica per continuare a funzionare con modifiche minime.
4. Il web scraping è legale e sicuro?
Il web scraping è legale quando raccogli dati disponibili pubblicamente e rispetti i termini di servizio del sito. Thunderbit promuove un uso responsabile e offre funzioni che ti aiutano a rimanere conforme.
5. Posso pianificare estrazioni ricorrenti o automatizzare le esportazioni?
Sì! Thunderbit ti permette di programmare estrazioni a qualsiasi intervallo (giornaliero, settimanale, ecc.) ed esportare i risultati direttamente in Google Sheets, Notion, Airtable, Excel o CSV — senza lavoro manuale.
Pronto ad automatizzare la raccolta dei tuoi dati? Prova Thunderbit gratis e scopri quanto può essere semplice il web scraping per tutti.
Scopri di più
- Come iniziare a costruire un Estrattore Web: guida per principianti
- Come estrarre un sito web: guida per principianti per il 2025
- Come eseguire il crawling dei siti web: guida passo dopo passo per principianti
- Come scrivere un Estrattore Web con Python: dall’inizio alla fine
- Guida completa al web scraping in Python: passo dopo passo




