Walmart.com ha oltre , circa 50 miliardi di dollari di vendite nette legate all’ecommerce e alcune delle difese anti-bot più aggressive del retail. Se hai mai provato a estrarre dati di prodotto da Walmart — prezzi, livelli di stock, informazioni sul venditore — probabilmente ti sei scontrato con una pagina vuota o con un CAPTCHA invece dei dati che ti servivano.
Per settimane ho testato 9 strumenti diversi per lo scraping di Walmart, da estensioni Chrome no-code ad API di livello enterprise. Il mio obiettivo era semplice: capire quali restituiscono davvero dati di prodotto Walmart utilizzabili nel 2026 e quali si limitano a bruciare i crediti. La risposta dipende molto da chi sei: un venditore individuale che monitora 50 SKU, uno sviluppatore che sta costruendo una pipeline o un team enterprise che controlla migliaia di prodotti ogni giorno. Qui sotto ti mostro cosa ha funzionato, cosa no e come scegliere lo strumento giusto per il tuo caso.
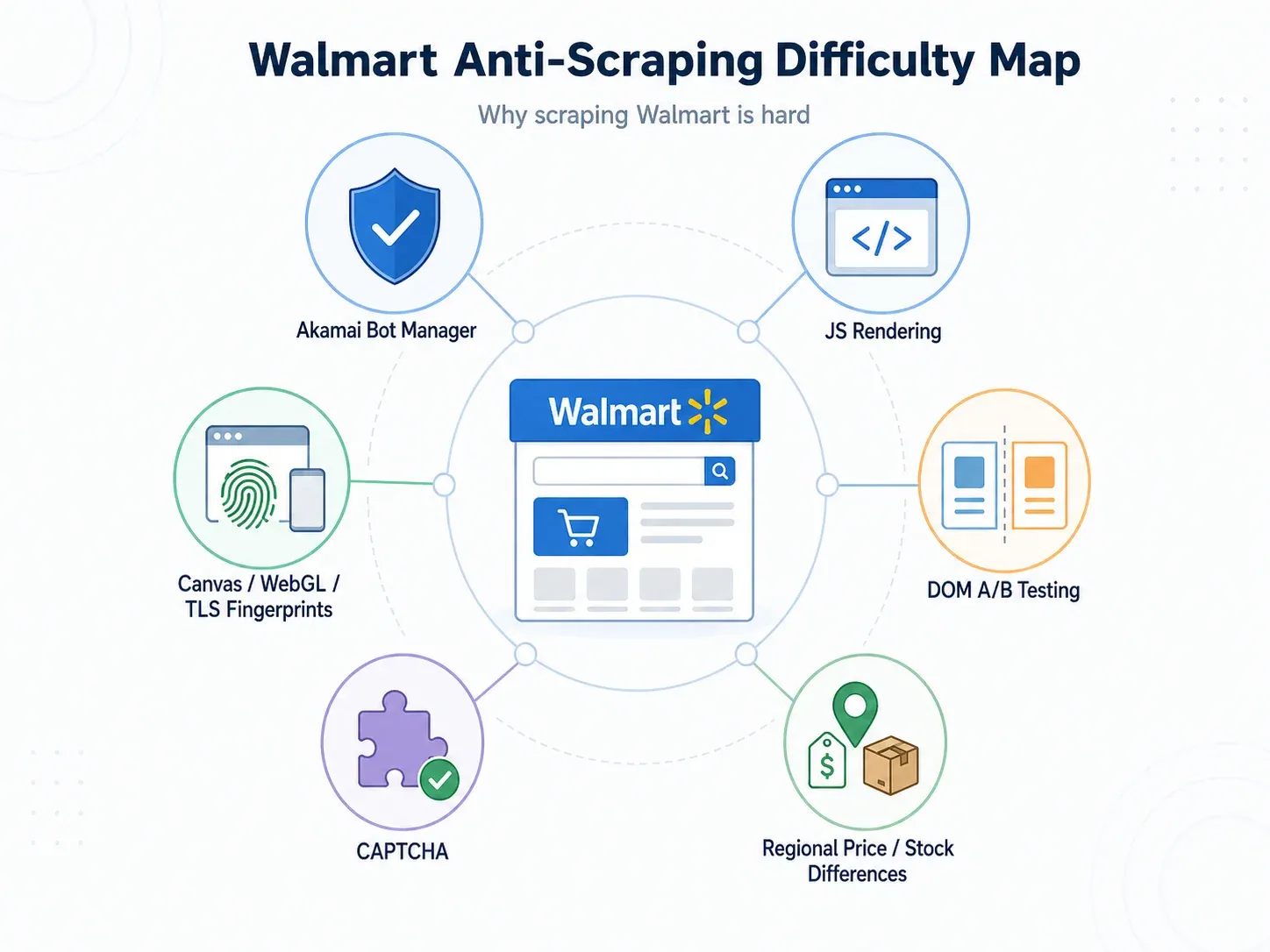
Perché estrarre dati da Walmart è più difficile di molti altri siti retail
Molte persone pensano che fare scraping su Walmart sia come farlo su qualsiasi altro sito retail. Non è così. Lo stack anti-bot di Walmart viene spesso valutato 9/10 in difficoltà dalle fonti del settore, e per buoni motivi.
Ecco cosa devi affrontare davvero:
- Akamai Bot Manager: Walmart usa , che assegna un punteggio alle richieste tramite analisi comportamentali guidate da AI/ML, fingerprinting del browser/dispositivo, rilevamento di anomalie HTTP e segnali di interazione utente. Akamai gestisce 40 miliardi di richieste bot al giorno e analizza 946 TB di nuovi dati di sicurezza al giorno.
- Contenuti renderizzati in JavaScript: prezzi, opzioni di fulfillment, informazioni sul venditore e disponibilità spesso non compaiono nell’HTML iniziale. Serve il rendering completo nel browser per vederli.
- Fingerprinting Canvas/WebGL/TLS: come ha scritto un team in produzione, «Walmart fa fingerprinting di molto più del tuo IP — canvas, WebGL, timing, TLS». La semplice rotazione dei proxy standard non basta.
- Cambiamenti frequenti del DOM dovuti ad A/B test: Walmart esegue esperimenti continui sul layout. Un selettore CSS che prendeva il prezzo il lunedì può restituire una stringa vuota entro mercoledì — senza errori evidenti.
- Intercettazione dei CAPTCHA: alcuni scraper ingeriscono in modo silenzioso una pagina di sfida CAPTCHA e la trattano come un «successo», lasciandoti dati inutili.
Il risultato pratico? Uno scraper che «funziona» su molti siti retail spesso fallisce in modo silenzioso su Walmart — restituendo risposte HTTP 200 con dati mancanti o errati.
Matrice delle sfide anti-bot
| Sfida | Cosa succede | Strumenti che la gestiscono |
|---|---|---|
| Serve il rendering JS | Il normale HTTP restituisce un guscio HTML vuoto | Thunderbit, Bright Data, Oxylabs, Zyte, ScraperAPI, ScrapingBee, Decodo |
| Fingerprinting Canvas/WebGL | Rilevamento bot anche con proxy | Bright Data, Decodo, Zyte, Oxylabs |
| Rottura dei selettori (test A/B) | I campi dati risultano vuoti o errati | Thunderbit (l’AI legge la pagina da zero ogni volta), Zyte AI, API strutturate di Bright Data/Oxylabs |
| Intercettazione CAPTCHA | Il parser ingerisce in silenzio la pagina CAPTCHA | ScraperAPI, Bright Data, Oxylabs, ScrapingBee |
| Prezzi/inventario regionali | Il prezzo dipende dal CAP/negozio | Geo-targeting di Bright Data, Oxylabs, Decodo, ScraperAPI, ScrapingBee |
Cosa cercavo testando questi scraper per Walmart
Non tutti gli scraper per Walmart risolvono lo stesso problema. Un venditore individuale che controlla 30 prezzi non è la stessa cosa di un team enterprise che monitora 10.000 SKU al giorno. Ecco i criteri che ho valutato su tutti e 9 gli strumenti:
- Tasso di successo anti-bot: restituisce dati reali del prodotto o solo HTTP 200 con campi vuoti?
- Completezza dei campi: riesce a estrarre titolo, prezzo, disponibilità, venditore, valutazione, numero di recensioni, UPC, immagini, opzioni di fulfillment e specifiche?
- Rendering JS: gestisce il rendering lato client di Walmart?
- Modello di fatturazione: pay-per-successo (non paghi per le richieste bloccate) contro pay-per-request (i crediti si consumano anche in caso di errore).
- Impegno di configurazione: no-code (click e via) contro API (serve scrivere codice per integrare).
- Impegno di manutenzione: i selettori fissi si rompono spesso su Walmart. L’estrazione AI/semantica o endpoint mantenuti dal vendor riducono il problema.
- Export/output: gli utenti business hanno bisogno di Sheets/Excel/Airtable/Notion. Gli sviluppatori hanno bisogno di JSON/CSV/webhook.
- Scalabilità: una ricerca occasionale, monitoraggio giornaliero e dataset di catalogo massivi sono lavori diversi.
- Piano gratuito: cosa si riesce davvero a fare con 0 €?
I benchmark indipendenti hanno aiutato a calibrare le aspettative. Il ha testato 200 URL con 2.000 richieste totali e confrontato output strutturato, copertura dei campi e tempo di risposta. Il classifica Walmart come target Akamai e confronta 10 provider per tasso di successo e velocità. L’articolo di classifica Walmart di Bright Data riporta tempi di risposta da 2,31 s a 11,12 s e un numero di campi da meno di 300 a oltre 650 per pagina prodotto tra gli strumenti esaminati.
I 9 migliori scraper per Walmart in sintesi
| Strumento | Tipo | Gestione anti-bot | Piano gratuito | Prezzo di partenza | Ideale per | Serve codice? |
|---|---|---|---|---|---|---|
| Thunderbit | Estensione Chrome / scraper AI | Scraping browser/cloud, estrazione AI adattiva | 6 pagine/mese (10 con prova) | ~9 $/mese | Team non tecnici | No |
| Bright Data | API / dataset / scraping browser per Walmart | Sblocco gestito, JS, CAPTCHA, geo | Prova/crediti | ~0,75 $/1K richieste riuscite | Scala enterprise | Opzionale |
| Oxylabs | Web Scraper API | Rendering JS, proxy/sblocco, parser | Fino a 2.000 risultati di prova | 49 $/mese | Completezza dei dati | Sì |
| Decodo | API per scraping ecommerce | JS, modalità premium, anti-bot | 2K regolari o 667 premium+JS | ~9 $/mese | Miglior valore API | In gran parte sì |
| Zyte API | API generica di scraping | Tiering automatico, richieste browser | 5 $ di credito | Da 0,06 $/1K | Workflow API veloci | Sì |
| ScraperAPI | Endpoint Walmart / API REST | Rotazione proxy, rendering, modalità premium | 7 giorni / 5.000 crediti | 49 $/mese | Sviluppatori con budget limitato | Sì |
| Apify | Marketplace / piattaforma di actor | Dipende da actor/proxy | 5 $/mese di crediti piattaforma | 49 $/mese + utilizzo | Workflow personalizzati | Opzionale |
| Octoparse | Scraper desktop/cloud no-code | Selettori visuali, add-on cloud/proxy | Piano gratuito (limitato) | 69 $/mese Standard | Principianti | No |
| ScrapingBee | API Walmart / API HTML | JS, proxy premium/stealth, CAPTCHA | 1.000 crediti | 49 $/mese | Progetti API leggeri | Sì |
Prezzi aggiornati ad aprile 2026; verifica prima di acquistare.
1. Thunderbit
è un’estensione Chrome basata su AI e un web scraper pensato per utenti business che hanno bisogno di dati strutturati da Walmart — senza scrivere codice, configurare selettori o gestire proxy.
Il flusso di lavoro è davvero di due clic. Apri una pagina risultati di ricerca Walmart o una scheda prodotto, fai clic su «AI Suggest Fields» e Thunderbit legge la pagina visibile proponendo colonne come Nome prodotto, Prezzo, Valutazione, Stato stock, Venditore, Numero recensioni, URL immagine, URL prodotto. Fai clic su «Scrape» e la tabella si riempie. Ti serve un dato più ricco? Fai clic su «Scrape Subpages» e Thunderbit visita ogni pagina prodotto per estrarre specifiche, UPC, descrizioni dettagliate e altro.
Il vero elemento distintivo, in particolare per Walmart, è l’estrazione adattiva. Gli scraper tradizionali si basano su selettori CSS o XPath fissi, che si rompono ogni volta che Walmart lancia un test A/B o aggiorna il DOM. L’AI di Thunderbit legge la struttura della pagina da zero ogni volta, comprendendo il contenuto in modo semantico e non in base alla posizione. Nei miei test, questo ha significato non dover sistemare selettori rotti dopo i cambi di layout di Walmart — una seccatura di manutenzione che affligge gli strumenti basati su selettori.
Funzionalità chiave per lo scraping di Walmart
- AI Suggest Fields: legge le pagine Walmart e genera automaticamente nomi colonna e tipi di dato — nessuna configurazione manuale dei selettori.
- Scraping delle sottopagine: estrai una pagina elenco e poi arricchisci ogni riga con specifiche dettagliate dalle singole pagine prodotto.
- Paginazione e scroll infinito: gestisce i risultati di ricerca paginati di Walmart e i pattern «carica altro».
- Scraping pianificato: imposta esecuzioni ricorrenti per monitoraggio quotidiano o settimanale di prezzi e stock.
- Export gratuiti: Excel, CSV, Google Sheets, Airtable, Notion — nessun costo nascosto per il download.
- Modalità browser + cloud: scraping browser per contenuti con accesso autenticato o specifici del negozio; scraping cloud per esecuzioni più rapide sulle pagine pubbliche (fino a 50 pagine contemporaneamente).
- Estrattori gratuiti di email e telefono: utili se stai estraendo dati dalle pagine venditore di Walmart Marketplace.
- Supporto per 34 lingue.
Pro e contro
| Pro | Contro |
|---|---|
| Nessuna configurazione, nessun codice | Il piano gratuito è piccolo per il monitoraggio intensivo |
| L’AI si adatta ai cambi di layout — niente manutenzione dei selettori | Non è un’API enterprise dedicata solo a Walmart |
| Export gratuiti su Sheets, Excel, Airtable, Notion | Per lavori più grandi su sottopagine/paginazione serve un piano a pagamento |
| Lo scraping delle sottopagine arricchisce i dati dell’elenco | Strumento più recente rispetto ai vendor API enterprise |
| Modalità browser e cloud per flussi diversi |
Prezzi: piano gratuito (6 pagine/mese, 10 con prova). Piani a pagamento da circa 9 $/mese. 1 credito = 1 riga di output.
Ideale per: team non tecnici — sales ops, operatori ecommerce, VA, piccoli venditori — che vogliono i dati di prodotto Walmart in un foglio di calcolo senza scrivere codice o gestire infrastruttura.
2. Bright Data
Bright Data è la piattaforma enterprise più completa per i dati di Walmart — non solo una singola API. Offre una dedicata Walmart Scraper API, dataset Walmart pre-aggregati (oltre 267 milioni di record), un Scraping Browser per la gestione di JS/CAPTCHA e un MCP Server per workflow AI/LLM.
Nei test di benchmark, Bright Data ha dichiarato un tasso di successo del 98,44% su 11 provider in un benchmark indipendente di Scrape.do. Il suo modello pay-per-successo significa che non paghi quando Walmart blocca una richiesta. Su larga scala, questa differenza conta moltissimo.
Funzionalità chiave per lo scraping di Walmart
- Endpoint Walmart dedicato: output JSON strutturato con campi come URL, prezzo finale, SKU, valuta, GTIN, specifiche, URL immagine e recensioni principali.
- Dataset pre-aggregati: accesso massivo e storico ai dati prodotto di Walmart.
- Scraping Browser: gestisce rendering JS, risoluzione CAPTCHA ed evasione del fingerprinting.
- Geo-targeting a livello città: fondamentale per l’intelligence sui prezzi regionali.
- Rete proxy: oltre 150 milioni di IP residenziali.
- MCP Server: per l’integrazione con LLM e agenti AI.
Pro e contro
| Pro | Contro |
|---|---|
| Il più alto tasso di successo nei benchmark | Prezzi premium e complessità |
| Fatturazione pay-per-successo | Le diverse linee prodotto possono creare confusione |
| Geo-targeting per prezzi regionali | Spesa minima per i piani enterprise |
| Dataset per accesso storico massivo |
Prezzi: Walmart Scraper API da circa 0,75 $/1K richieste riuscite. Dataset da circa 50 $/100K record. Piani enterprise con minimi di spesa.
Ideale per: team enterprise che hanno bisogno di massima affidabilità, geo-targeting e dati Walmart strutturati su larga scala.
3. Oxylabs
Oxylabs è una valida alternativa enterprise con forte attenzione alla completezza dei dati. La sua Web Scraper API elenca direttamente target Walmart: Walmart Product (59 punti dati parsati), Walmart Search (58 punti dati parsati) e Walmart URL con output raw HTML o parsato.
Nei riepiloghi dei benchmark, Oxylabs viene citata per la profondità dei campi — circa 620+ campi per pagina prodotto Walmart in alcuni test. La prova gratuita include fino a 2.000 risultati e i piani a pagamento partono da 49 $/mese.
Funzionalità chiave per lo scraping di Walmart
- Alto numero di campi: 59 punti dati parsati per pagina prodotto Walmart.
- Gestione anti-bot: gestisce i livelli Akamai e HUMAN Security.
- Formati di output multipli: JSON parsato e HTML raw.
- Architettura API scalabile.
Pro e contro
| Pro | Contro |
|---|---|
| Estrazione profonda dei dati (59+ campi) | Prezzo più alto |
| Gestione anti-bot affidabile | Serve codice per integrare l’API |
| Buona prova gratuita (2.000 risultati) | Curva di apprendimento più ripida per utenti non tecnici |
| Supporto enterprise |
Prezzi: prova gratuita fino a 2.000 risultati. A pagamento da 49 $/mese. Rendering JS circa 0,35 $/1K risultati.
Ideale per: team che hanno bisogno della massima copertura dei campi e di dati Walmart strutturati via API.
4. Decodo
Decodo (ex Smartproxy) offre il miglior equilibrio tra prezzo e prestazioni per lo scraping Walmart su scala media. La sua eCommerce Scraper API supporta Walmart con template pronti all’uso, bypass anti-bot e rendering JS.
Il piano gratuito offre fino a 2K richieste standard o 667 richieste premium+JS — abbastanza per verificare se le pagine Walmart restituiscono dati utilizzabili prima di impegnarsi. I piani a pagamento partono da circa 9 $/mese, con prezzi di fascia media anche a 0,30 $/1K richieste standard.
Funzionalità chiave per lo scraping di Walmart
- Prezzo per richiesta conveniente.
- API focalizzata sull’ecommerce con template.
- Gestione CAPTCHA e anti-bot.
- Targeting geografico.
- Piano starter gratuito per i test.
Pro e contro
| Pro | Contro |
|---|---|
| Prezzi competitivi | Meno funzionalità specifiche per Walmart rispetto a Bright Data |
| Buone prestazioni rispetto al prezzo | Serve codice |
| Piano gratuito generoso per i test | I moltiplicatori di modalità possono aumentare il costo effettivo |
| Buono per progetti di scala media | Rete proxy più piccola rispetto ai leader enterprise |
Prezzi: piano gratuito (2K richieste standard). A pagamento da circa 9 $/mese.
Ideale per: team che vogliono una buona API per Walmart senza prezzi enterprise — soprattutto per monitoraggi di media scala o costruzione di cataloghi.
5. Zyte API
Zyte è l’opzione più veloce nei riepiloghi dei benchmark, con un tempo di risposta mediano dichiarato di 2,31 secondi e un tasso di successo del 96,22% sulle pagine Walmart. La sua API usa un tiering automatico — selezionando per ogni richiesta tecnologie datacenter, residenziali o di rendering — così paghi solo ciò che serve.
I nuovi utenti ricevono 5 $ di credito gratuito. I prezzi partono da 0,06 $/1K risposte riuscite, mentre le richieste di livello browser costano di più.
Funzionalità chiave per lo scraping di Walmart
- Tempi di risposta rapidi (~2–3 secondi mediani).
- Estrazione AI strutturata per dati ecommerce.
- Prezzi flessibili pay-per-request con tiering automatico.
- Richieste browser per pagine Walmart renderizzate in JS.
Pro e contro
| Pro | Contro |
|---|---|
| Tempo di risposta più rapido nei benchmark | Piano gratuito più piccolo |
| Capacità di estrazione AI | Meno strumenti specifici per Walmart rispetto a Bright Data |
| Prezzi flessibili | Richiede configurazione tecnica |
| Buono per il monitoraggio in tempo reale | Il tiering automatico rende i costi esatti meno prevedibili |
Prezzi: 5 $ di credito gratuito. Da 0,06 $/1K risposte riuscite; i tier browser costano di più.
Ideale per: sviluppatori che costruiscono pipeline di monitoraggio in tempo reale e hanno bisogno di velocità e prezzi flessibili.
6. ScraperAPI
ScraperAPI ha una delle offerte più chiare per gli sviluppatori, specifica per Walmart. Il suo Walmart Scraper offre endpoint strutturati per pagine prodotto, ricerca, categorie e recensioni — con opzioni sincrone e asincrone.
La prova di 7 giorni offre 5.000 crediti e i piani a pagamento partono da 49 $/mese con 100.000 crediti. Ma c’è un problema: il sistema di crediti di ScraperAPI addebita 1 credito per le richieste base, 10 per il rendering JS, 25 per premium+render e fino a 75 per ultra premium+render. Walmart quasi sempre richiede il rendering JS, quindi il numero effettivo di pagine è molto più basso del credito nominale.
Funzionalità chiave per lo scraping di Walmart
- Endpoint Walmart dedicati (prodotto, ricerca, categoria, recensioni).
- Integrazione API REST semplice.
- Rotazione proxy automatica e gestione CAPTCHA.
- Rendering JavaScript.
- Targeting geografico.
Pro e contro
| Pro | Contro |
|---|---|
| Prezzo d’ingresso conveniente | I crediti si consumano in fretta su Walmart (JS = 10+ crediti/pagina) |
| API semplice con buona documentazione | Tasso di successo inferiore ai tool enterprise su Walmart |
| Endpoint Walmart dedicati | I crediti vengono consumati anche in caso di richieste fallite |
| Prova gratuita |
Prezzi: prova di 7 giorni (5.000 crediti). A pagamento da 49 $/mese.
Ideale per: sviluppatori che vogliono un’API Walmart semplice a un prezzo ragionevole — ma che capiscono la matematica del moltiplicatore dei crediti.
7. Apify
Apify è una piattaforma e un marketplace di actor, non un singolo scraper. Puoi trovare actor Walmart già pronti come automation-lab/walmart-scraper (circa 0,004 $/prodotto più i costi di esecuzione), actor Axesso per lookup/ricerca Walmart e altri mantenuti da sviluppatori della community.
Il piano gratuito offre 5 $/mese in crediti d’uso. I piani a pagamento partono da 49 $/mese più compute pay-as-you-go. La piattaforma supporta pianificazione, elaborazione batch, webhook, export di dataset e client API.
Funzionalità chiave per lo scraping di Walmart
- Actor scraper Walmart predefiniti nel marketplace.
- Piattaforma cloud scalabile per eseguire attività.
- API per integrazioni personalizzate e costruzione di pipeline.
- Pianificazione ed elaborazione batch.
- Molteplici formati di export (JSON, CSV, Excel).
Pro e contro
| Pro | Contro |
|---|---|
| Flessibile e personalizzabile | La qualità degli actor varia a seconda del manutentore |
| Marketplace valido con actor Walmart | I costi aumentano con uso intensivo |
| Infrastruttura cloud scalabile | Richiede più competenze tecniche per actor personalizzati |
| API adatte agli sviluppatori | La gestione proxy/anti-bot dipende dalla configurazione dell’actor |
Prezzi: piano gratuito (5 $/mese di crediti). Starter da 49 $/mese + utilizzo.
Ideale per: team che hanno bisogno di workflow personalizzati di scraping Walmart con pianificazione, batch e integrazione API.
8. Octoparse
Octoparse è il classico scraper no-code point-and-click. Il suo builder visuale ti permette di selezionare elementi su una pagina Walmart, configurare le regole di estrazione ed eseguire gli scraper nel cloud o in locale. Offre un per una configurazione più rapida.
Il piano gratuito include estrazione ed export locali limitati. I piani a pagamento partono da 69 $/mese (Standard, fatturazione annuale).
Funzionalità chiave per lo scraping di Walmart
- Builder visuale point-and-click per i workflow.
- Opzioni di scraping cloud e locale.
- Scraping pianificato per monitoraggi ricorrenti.
- Libreria di template che include Walmart.
- Molteplici formati di export (CSV, Excel).
Pro e contro
| Pro | Contro |
|---|---|
| Nessuna programmazione necessaria | I selettori fissi si rompono quando Walmart cambia layout |
| Interfaccia visuale per principianti | Esecuzione cloud più lenta |
| Limiti di righe generosi nel piano gratuito | Più costoso per i team |
| Scraping pianificato | Meno adattamento AI rispetto a Thunderbit |
Prezzi: piano gratuito (limitato). A pagamento da 69 $/mese Standard.
Ideale per: principianti che vogliono un’interfaccia visuale no-code e sono disposti a mantenere i selettori quando il layout di Walmart cambia.
La differenza chiave tra Octoparse e Thunderbit: entrambi sono no-code, ma Thunderbit usa l’AI per adattarsi automaticamente ai cambiamenti di pagina, mentre Octoparse si affida a selettori fissi che richiedono aggiornamenti manuali quando il DOM di Walmart cambia.
9. ScrapingBee
ScrapingBee è un’API leggera per sviluppatori che vogliono una semplice rotazione dei proxy e rendering JS senza una piattaforma pesante. Offre sia una generica API HTML sia una dedicata Walmart Scraper API per l’estrazione di prodotti e ricerche.
Il piano gratuito offre 1.000 crediti. I piani a pagamento partono da 49 $/mese (Freelance, 250.000 crediti). Ma il sistema di crediti di ScrapingBee addebita 1 credito per le richieste classiche senza JS, 5 per il rendering JS, 10 per premium senza JS, 25 per premium con JS e fino a 75 per la modalità stealth. Dato che Walmart richiede almeno il rendering JS, il tuo free tier effettivo è più vicino a 200 pagine — o meno se serve il livello premium/stealth.
Funzionalità chiave per lo scraping di Walmart
- API REST semplice con rotazione proxy.
- Rendering JavaScript (necessario per Walmart).
- Targeting geografico.
- Gestione CAPTCHA.
- Endpoint API specifici per Walmart.
Pro e contro
| Pro | Contro |
|---|---|
| API semplice | I crediti si consumano in fretta su Walmart (JS = 5+ crediti/pagina) |
| Gestisce il rendering JS | Piano gratuito limitato per Walmart |
| Supporto per il geo-targeting | Serve codice |
| Prezzo d’ingresso ragionevole | Meno ottimizzazione specifica per Walmart rispetto ai tool enterprise |
Prezzi: 1.000 crediti gratuiti. A pagamento da 49 $/mese.
Ideale per: sviluppatori che hanno bisogno di un’API leggera e semplice per progetti Walmart — e che sanno modellare la matematica dei crediti prima di impegnarsi.
Quale scraper per Walmart si adatta al tuo flusso di lavoro
Nessun articolo concorrente che ho trovato segmenta chiaramente gli strumenti per caso d’uso. Questa è la tabella decisionale che avrei voluto avere quando ho iniziato:
| Caso d’uso | Strumento/i migliore/i | Perché |
|---|---|---|
| Ricerca rapida di prodotti (<100 articoli, senza codice) | Thunderbit, Octoparse | Configurazione in 2 clic, interfaccia visuale, export su Sheets |
| Monitoraggio prezzi su larga scala (1.000+ SKU al giorno) | Bright Data, Oxylabs | Pay-per-successo, output strutturato, tassi di successo elevati |
| Creazione di cataloghi per dropshipping | Thunderbit, Apify | Lo scraping delle sottopagine arricchisce le schede; esecuzioni batch basate su template |
| Competitive intelligence (prezzi + recensioni) | Zyte, Decodo, Bright Data | Pipeline API, campi strutturati, analisi ricorrenti |
| Sviluppatore che costruisce una pipeline dati | ScraperAPI, ScrapingBee, Zyte | API REST semplici, controllo del response raw, orientate al codice |
| Intelligence sui prezzi regionali enterprise | Bright Data, Oxylabs | Geo-targeting, infrastruttura, supporto enterprise, dataset |
Thunderbit è naturalmente adatto agli operatori ecommerce non tecnici e ai piccoli team che hanno bisogno di dati prodotto senza scrivere codice. La funzione «AI Suggest Fields» legge le pagine Walmart e propone automaticamente le colonne, e lo scraping delle sottopagine può arricchire una pagina elenco con le specifiche dettagliate di ciascun prodotto.
Scraper fai-da-te vs API di scraping vs strumento no-code: il vero costo dello scraping di Walmart

Vedo questa domanda continuamente nei forum: «Dovrei costruire il mio scraper per Walmart o pagare per uno strumento?». La risposta dipende dai costi reali — non solo dal prezzo dell’abbonamento.
| Approccio | Costo iniziale | Costo mensile di esercizio (1.000 pagine/giorno) | Manutenzione | Tasso di successo orientativo |
|---|---|---|---|---|
| Fai-da-te (Playwright + proxy residenziali) | 0 $ (open source) | 200–500 $+ (proxy + server + infrastruttura browser) | ALTA (correzioni settimanali) | ~70–85% |
| API di scraping (ScraperAPI, ScrapingBee) | 0 $ (piano gratuito) | 49–149 $/mese | BASSA | ~85–95% |
| API enterprise (Bright Data, Oxylabs) | 0 $ (prova) | 300–1.000 $+/mese | MOLTO BASSA | ~95–99% |
| Strumento no-code (Thunderbit, Octoparse) | 0 $ (piano gratuito) | 9–99 $/mese | NESSUNA per gli strumenti AI (l’AI si adatta) | ~85–95% |
Costi nascosti che spesso vengono sottovalutati:
- RAM: ogni istanza Chromium consuma circa 150–300 MB di RAM. A 1.000 pagine concorrenti, la bolletta infrastrutturale rivaleggia con i costi delle API a pagamento.
- Complessità dei proxy: i proxy residenziali si fatturano in GB, non per richiesta. Le pagine Walmart molto pesanti in JS possono costare più del previsto.
- Richieste fallite: alcune API consumano ancora crediti anche sulle richieste bloccate.
- Fallimenti silenziosi: un prezzo vuoto o un valore stock mancante sono un fallimento di business, anche se lo scraper dice «successo».
- Tempo degli sviluppatori: le ore spese a sistemare selettori rotti dopo i cambi di layout di Walmart hanno un costo reale.
Per la maggior parte dei team, il punto di pareggio favorisce uno strumento a pagamento, a meno che non abbiate già ingegneri dedicati allo scraping e l’infrastruttura pronta.
Com’è davvero il dato estratto da Walmart
Nessun articolo concorrente che ho esaminato mostra un’anteprima dati reale. Qui sotto trovi un esempio di cosa restituisce in genere uno scraping di un prodotto Walmart — in formato foglio di calcolo (output di Thunderbit) e in JSON API (output degli strumenti per sviluppatori):
Output su foglio di calcolo (Thunderbit)
| Nome prodotto | Prezzo | Disponibilità | Venditore | Valutazione | Recensioni | URL immagine | UPC | Fulfillment |
|---|---|---|---|---|---|---|---|---|
| Great Value Sparkling Water 12pk | $4.98 | Disponibile | Walmart.com | 4,6 | 1.284 | https://i5.walmartimages.com/...jpg | 078742000000 | Ritiro / Consegna |
| onn. Wireless Earbuds | $19.88 | Disponibile online | Walmart.com | 4,3 | 3.912 | https://i5.walmartimages.com/...jpg | 681131000000 | Spedizione / Ritiro |
{kind=link}
Risposta JSON API (strumenti per sviluppatori)
1{
2 "title": "onn. Wireless Earbuds",
3 "url": "https://www.walmart.com/ip/example",
4 "price": 19.88,
5 "currency": "USD",
6 "availability": "In stock",
7 "seller": "Walmart.com",
8 "rating": 4.3,
9 "review_count": 3912,
10 "sku": "123456789",
11 "gtin": "681131000000",
12 "images": ["https://i5.walmartimages.com/...jpg"],
13 "fulfillment": {
14 "shipping": true,
15 "pickup": true,
16 "delivery": "store-dependent"
17 }
18}I campi principali supportati dalle API testate nei benchmark includono titolo, URL, prezzo, valuta, immagine, numero di recensioni, disponibilità, breadcrumb e valutazione. Fonte: .
Per Thunderbit, il flusso visivo è: AI Suggest Fields propone le colonne → Scrape compila la tabella → export su Google Sheets, Excel, Airtable o Notion. Nessun parsing JSON richiesto.
Sfida del piano gratuito: cosa puoi davvero estrarre da Walmart con 0 €?
Se sei uno studente, un venditore individuale o stai solo facendo delle prove, ecco cosa ti permette davvero di ottenere il piano gratuito di ogni strumento su Walmart:
| Strumento | Limite del piano gratuito | Funziona gratis su Walmart? | Formati di output | Limite principale |
|---|---|---|---|---|
| Thunderbit | 6 pagine/mese (10 con prova) | ✅ Sì (scraping browser) | Excel, CSV, Sheets, Airtable, Notion | Limite sul numero di pagine |
| ScraperAPI | 5.000 crediti (7 giorni) | ⚠️ Limitato (~500 pagine se JS = 10 crediti) | JSON | I crediti si consumano in fretta |
| Apify | 5 $ di crediti gratuiti/mese | ⚠️ ~50 pagine (dipende dall’actor) | JSON, CSV, Excel | Limiti di esecuzione degli actor |
| Octoparse | Piano gratuito (locale limitato) | ✅ Sì (estrazione locale) | CSV, Excel | Funzioni cloud/proxy a pagamento |
| ScrapingBee | 1.000 crediti | ⚠️ ~200 pagine (JS = 5 crediti) | JSON, HTML | I crediti si consumano in fretta |
| Decodo | 2K regolari o 667 premium+JS | ✅ Sì per i test | HTML, JSON, CSV | I moltiplicatori di modalità contano |
| Zyte | 5 $ di credito gratuito | ✅ Sì per i test | Risposte HTTP/browser | Il tiering automatico rende incerto il numero di pagine |
| Bright Data | Prova/crediti (varia) | ✅ Se approvato | JSON, NDJSON, CSV | Idoneità commerciale/prova |
| Oxylabs | Fino a 2.000 risultati di prova | ✅ Per i test | JSON parsato, HTML raw | Richiede configurazione API |
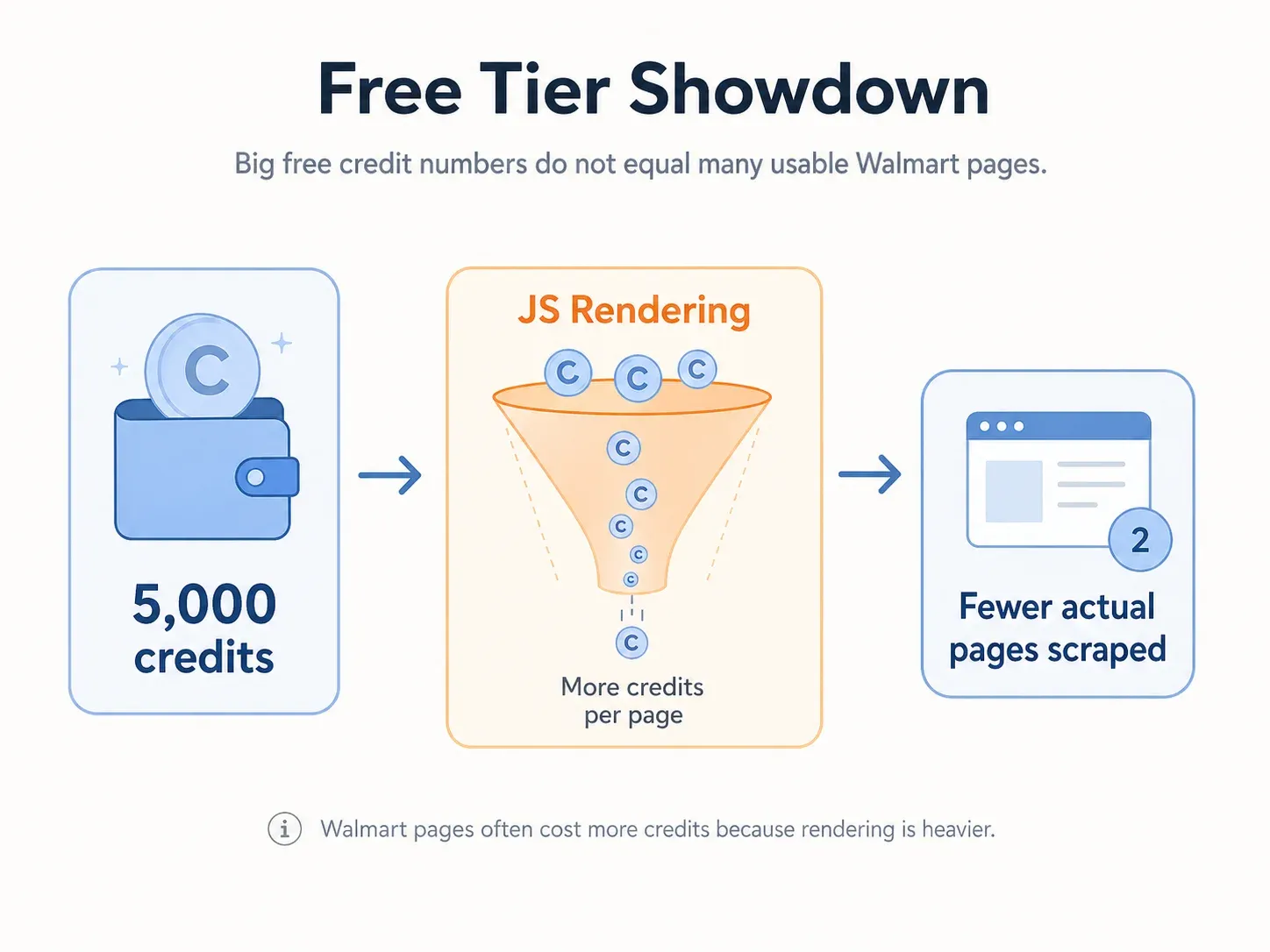
Un’osservazione importante per chi ha budget limitati: l’export gratuito di Thunderbit (Excel, Google Sheets, Airtable, Notion) significa che anche nel piano gratuito ottieni un output pulito senza costi nascosti per il download — qualcosa che diversi strumenti basati su API fanno pagare a parte. Inoltre, gli estrattori email e telefono sono completamente gratuiti se stai raccogliendo i contatti dei venditori dalle pagine marketplace.
Confronto affiancato: tutti e 9 gli scraper Walmart
| Strumento | Tipo | Gestione anti-bot | Piano gratuito | Prezzo di partenza | Ideale per | Serve codice? |
|---|---|---|---|---|---|---|
| Thunderbit | Estensione Chrome / scraper AI | AI adattiva, browser/cloud | 6 pagine/mese | ~9 $/mese | Team non tecnici | No |
| Bright Data | API / dataset / browser Walmart | Sblocco gestito, geo, CAPTCHA | Prova | ~0,75 $/1K successi | Scala enterprise | Opzionale |
| Oxylabs | Web Scraper API | JS, proxy, parser | 2.000 risultati di prova | 49 $/mese | Completezza dei dati | Sì |
| Decodo | API ecommerce | JS, premium, anti-bot | 2K regolari | ~9 $/mese | Miglior valore API | In gran parte sì |
| Zyte | API generica | Tiering automatico, browser | 5 $ di credito | 0,06 $/1K | API veloci | Sì |
| ScraperAPI | Endpoint Walmart / REST | Proxy, rendering, premium | 5.000 crediti (7 giorni) | 49 $/mese | Sviluppatori con budget limitato | Sì |
| Apify | Marketplace di actor | Dipende dall’actor | 5 $/mese di crediti | 49 $/mese + utilizzo | Workflow personalizzati | Opzionale |
| Octoparse | Desktop/cloud no-code | Selettori visuali | Piano gratuito | 69 $/mese | Principianti | No |
| ScrapingBee | API HTML/Walmart | JS, premium, CAPTCHA | 1.000 crediti | 49 $/mese | API leggere | Sì |
Se ti serve affidabilità enterprise, scegli Bright Data o Oxylabs. Se vuoi la configurazione no-code più veloce per Walmart, prova Thunderbit. Se sei uno sviluppatore con un budget limitato, ScraperAPI o Decodo sono ottimi punti di partenza.
Conclusione: come scegliere il miglior scraper Walmart per le tue esigenze
Walmart è uno dei siti retail più difficili da estrarre in modo affidabile. Lo strumento giusto dipende dal tuo caso d’uso, dal budget e dal livello tecnico. Ecco la mia raccomandazione rapida per profilo:
- Team non tecnici che vogliono risultati rapidi → . Due clic, con AI, export su Sheets/Excel/Airtable/Notion.
- Team enterprise che hanno bisogno della massima affidabilità su larga scala → Bright Data o Oxylabs. Pay-per-successo, geo-targeting, endpoint strutturati.
- Sviluppatori che costruiscono pipeline dati → ScraperAPI, ScrapingBee o Zyte. API REST semplici, orientate al codice.
- Utenti attenti al budget che cercano il miglior valore → Decodo o il piano gratuito di Thunderbit.
- Chi costruisce workflow personalizzati → Apify per la componibilità basata su actor.
Il mio consiglio: parti da un piano gratuito per verificare se uno strumento restituisce davvero i campi Walmart che ti servono. Non impegnarti in un piano a pagamento finché non hai validato la qualità dell’output sulle tue specifiche categorie di prodotto — perché le difese di Walmart colpiscono pagine diverse in modi diversi.
Se vuoi vedere com’è lo scraping Walmart con AI senza scrivere una riga di codice, . Per esperienza, è il modo meno macchinoso per portare dati Walmart puliti in un foglio di calcolo. E se sei più orientato allo sviluppo, gli strumenti API qui sopra ti danno il controllo e la scalabilità di cui hai bisogno.
Buono scraping — e che i tuoi prezzi siano sempre aggiornati e i tuoi campi mai vuoti.
FAQ
1. È legale fare scraping dei dati prodotto di Walmart?
L’estrazione di dati prodotto pubblicamente disponibili è generalmente considerata meno rischiosa rispetto all’estrazione di dati protetti da login o personali. Tuttavia, i limitano esplicitamente l’uso di robot, spider o dispositivi automatizzati per recuperare o indicizzare contenuti senza consenso scritto. Gli utenti dovrebbero rispettare i termini di servizio, il file robots.txt, i rate limit ed evitare di estrarre contenuti personali o protetti da copyright. Per usi commerciali, consulta un legale.
2. Mi servono competenze di programmazione per fare scraping su Walmart?
No. Strumenti come Thunderbit e Octoparse offrono interfacce completamente no-code — clicca, configura, esporta. Gli strumenti API come ScraperAPI, ScrapingBee e Zyte richiedono competenze base di programmazione. Le piattaforme enterprise come Bright Data e Oxylabs offrono sia accesso API sia opzioni dashboard/template.
3. Quanto spesso Walmart cambia il layout del sito?
Frequentemente. Walmart esegue A/B test e aggiorna regolarmente la struttura del DOM. I report della community menzionano costantemente selettori che si rompono e campi vuoti dopo i cambi di layout. Ecco perché gli strumenti AI che rileggono la pagina da zero ogni volta (come Thunderbit) o gli endpoint strutturati mantenuti dal vendor (come Bright Data, Oxylabs) richiedono meno manutenzione degli approcci basati su selettori fissi.
4. Quali dati posso estrarre dalle pagine prodotto di Walmart?
I campi più comuni includono: nome prodotto, URL, prezzo (attuale e precedente/rollback), disponibilità, venditore, valutazioni, numero di recensioni, URL immagini, UPC/GTIN, SKU/ID articolo, specifiche, opzioni di fulfillment (spedizione, ritiro, consegna), varianti, breadcrumb/categoria e talvolta il contesto negozio/corridoio quando sono disponibili dati di localizzazione.
5. Qual è il miglior scraper Walmart gratuito per test rapidi?
Per utenti non tecnici, Thunderbit (6 pagine gratuite, 10 con prova) e Octoparse (piano gratuito con estrazione locale) sono i più semplici da cui iniziare. Per gli sviluppatori, ScraperAPI (5.000 crediti), ScrapingBee (1.000 crediti), Decodo (2K richieste) e Zyte (5 $ di credito) offrono tutti piani gratuiti utilizzabili — ma ricorda che le pagine Walmart consumano più crediti dei siti statici semplici a causa del rendering JS richiesto.
Scopri di più