

La maggior parte degli articoli su "Playwright vs Puppeteer" parte dall’idea che uno dei due debba per forza essere lo scraper migliore. Ma così si danno per scontate troppe cose. Ho messo entrambe le librerie davanti allo stesso identico set di pagine — un catalogo statico, un catalogo renderizzato in JavaScript, un articolo, un errore 500, un piccolo grafo di crawl e due siti pubblici di test — e i risultati sono stati quasi impossibili da distinguere. Stesso recall, stesso rendering, stesse schermate, stesse lacune.
Quindi questo non è un incoronamento. Nei compiti che contano davvero per capire se uno strumento di browser automation può fare web scraping su una pagina, nessuno dei due ha preso il sopravvento. Quello che segue è l’unica vera differenza che dovrebbe guidare la scelta, l’elemento che entrambi lasciano silenziosamente a te da costruire, e una nota sul divario di versioni con cui ho fatto i test (aggiornato al 2026-07-09).
Perché il confronto è davvero equo
Gli articoli comparativi hanno la brutta abitudine di testare ogni strumento su pagine diverse e poi annunciare un vincitore — il che dice più sulle pagine che sugli strumenti. Ho evitato questo problema eseguendo Playwright e Puppeteer sullo stesso server locale di fixture e sugli stessi demo pubblici, Books to Scrape e Quotes to Scrape, così ogni numero si allinea colonna per colonna.
Questo è l’unico modo in cui l’affermazione di un "pareggio" ha senso. Se le fixture sono diverse, un pareggio è solo rumore. Quando invece sono identiche byte per byte, risultati uguali sono un segnale sulle librerie stesse.
Che cosa sono davvero i due strumenti
Puppeteer è una API JavaScript per controllare Chrome, tramite il Chrome DevTools Protocol. Il posizionamento ufficiale è proprio questo: "una API JavaScript per controllare Chrome (e sperimentalmente Firefox)." È maturo, orientato a Chrome e basato su Node.
Playwright si presenta in modo diverso: "un framework per Web Testing e Automation" che controlla Chromium, Firefox e WebKit attraverso una sola API, con client ufficiali in JavaScript, Python, Java e .NET. I due condividono lo stesso DNA (Playwright nasce dal team di Puppeteer in Google, prima del passaggio a Microsoft), ed è per questo che sembrano più cugini che rivali.
Per lo scraping, però, si comportano allo stesso modo. Avvii un browser reale, apri una pagina, lasci girare gli script e poi leggi il DOM renderizzato. È esattamente il motivo per cui useresti uno dei due invece di un parser HTTP: vuoi la pagina dopo l’esecuzione del JavaScript, non il guscio vuoto prima. Tutto ciò che segue deriva da questo meccanismo condiviso — ed è anche il motivo per cui gran parte di quello che fanno finisce per equivalersi.
I risultati, affiancati
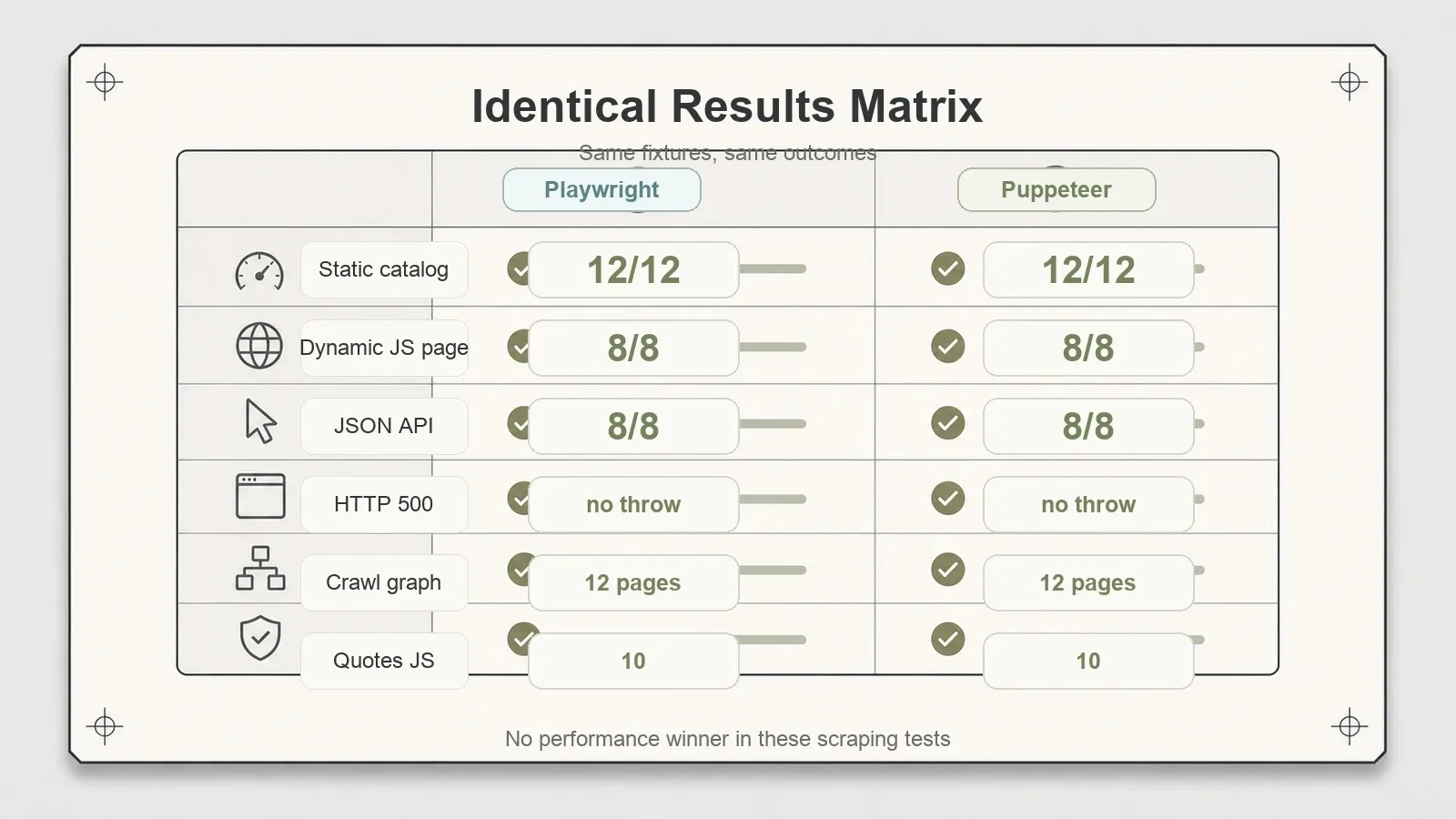
Qui l’idea che "uno sia chiaramente migliore" crolla in silenzio. Stesse fixture, stessi numeri, in ogni test.
| Test | Playwright | Puppeteer |
|---|---|---|
| Catalogo statico (12 prodotti) | 12/12, recall 1.0 | 12/12, recall 1.0 |
| Articolo (titolo + 3 paragrafi) | 3/3, separazione del boilerplate | 3/3, separazione del boilerplate |
| Pagina dinamica JS (render nativo) | 8/8 + screenshot | 8/8 + screenshot |
| API JSON dinamica | 8/8, recall 1.0 | 8/8, recall 1.0 |
| Gestione HTTP 500 | ispezionabile, nessuna eccezione | ispezionabile, nessuna eccezione |
| Grafo di crawl (BFS scritta a mano) | 12 pagine, profondità {0,1,2} | 12 pagine, profondità {0,1,2} |
| Books to Scrape | 20 prodotti | 20 prodotti |
| Quotes JS (pubblico) | 10 citazioni | 10 citazioni |
Entrambi hanno renderizzato JavaScript in modo nativo, senza nessuna configurazione speciale. Entrambi hanno catturato screenshot dell’intera pagina. Entrambi hanno gestito l’errore 500 restituendo un oggetto response ispezionabile invece di lanciare un’eccezione — un dettaglio piccolo, ma importante quando fai web scraping su larga scala e vuoi registrare uno status errato invece di far saltare un’intera esecuzione.

Ripeto un avvertimento perché è facile abusarne: queste sono osservazioni su una singola macchina e in una singola esecuzione, non benchmark. Non sto dicendo che uno sia più veloce dell’altro di qualche millisecondo, perché un cronometro pagina per pagina su un solo laptop non è un vero test di velocità. Sto dicendo qualcosa di più ristretto e meglio supportato: su capacità di estrazione e comportamento di rendering, su otto tipi di pagina diversi, i risultati coincidono. Se speravi che uno dei due staccasse l’altro su una pagina reale, non è successo.
L’unica differenza che dovrebbe decidere la scelta
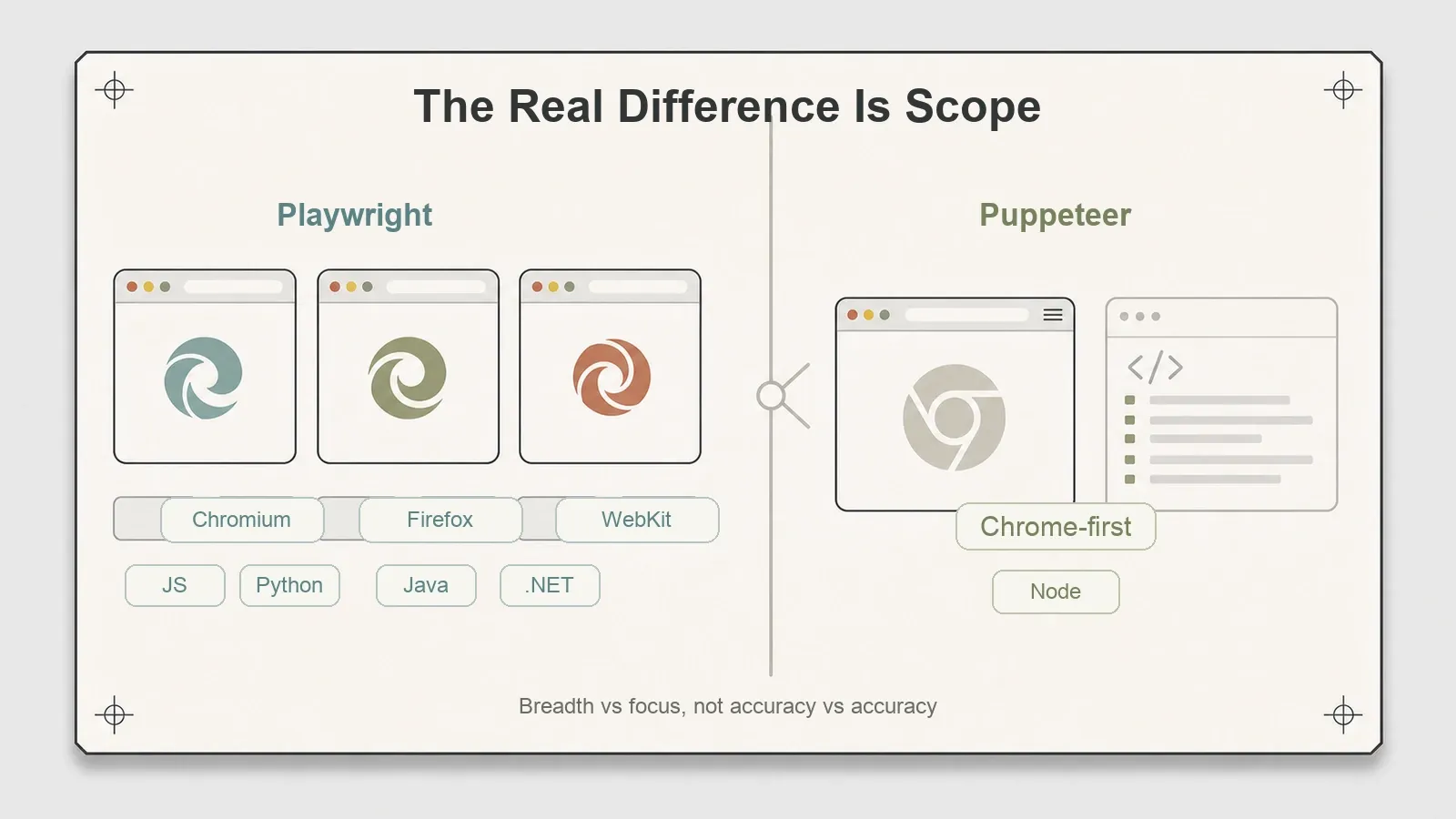
La vera biforcazione non è nei numeri. È nell’ambito.
Playwright controlla tre engine — Chromium, Firefox e WebKit — tramite una sola API, e offre client di prima classe in Python, Java e .NET oltre a JavaScript. Questo è un punto di forza documentato, e voglio essere preciso sulla parola "documentato": in questo test ho usato solo Chromium, quindi sto riportando il supporto a tre engine di Playwright come una capacità dichiarata che non ho verificato direttamente, non come qualcosa che ho testato. Se ti serve fare scraping su un sito che si comporta in modo diverso sotto WebKit di Safari, oppure il tuo team lavora in Python, questa ampiezza è l’argomento di Playwright.
Puppeteer è orientato a Chrome, e qui la semplificazione diffusa sbaglia. "Solo Chrome" non è più corretto. Da Puppeteer v23 offre supporto pronto per la produzione a Firefox tramite WebDriver BiDi, pur continuando a usare CDP come impostazione predefinita per Chrome per mantenere intatte le automazioni esistenti — un cambiamento documentato sia da Chrome for Developers sia da Mozilla. La versione che ho testato (24.16.0) è ben oltre la v23, quindi il confronto reale non è "Chrome contro tre engine". È questo: Puppeteer copre Chrome (CDP) più Firefox (BiDi), ma non WebKit, e la sua storia cross-engine è più giovane di quella di Playwright. L’engine che Playwright ha e Puppeteer no è WebKit.
Questa è la decisione, in sintesi. Non la velocità, non l’accuratezza, non la fedeltà del rendering — su questi aspetti sono pari. È una questione di ampiezza: ti serve copertura WebKit o client in un linguaggio diverso da JavaScript, oppure Chrome e Firefox da Node sono sufficienti per i tuoi obiettivi? Per una larga parte dei lavori di web scraping, uno qualunque dei due supera la soglia, e la scelta dipende dallo stack più che dalle capacità.
Quello che nessuno dei due fa
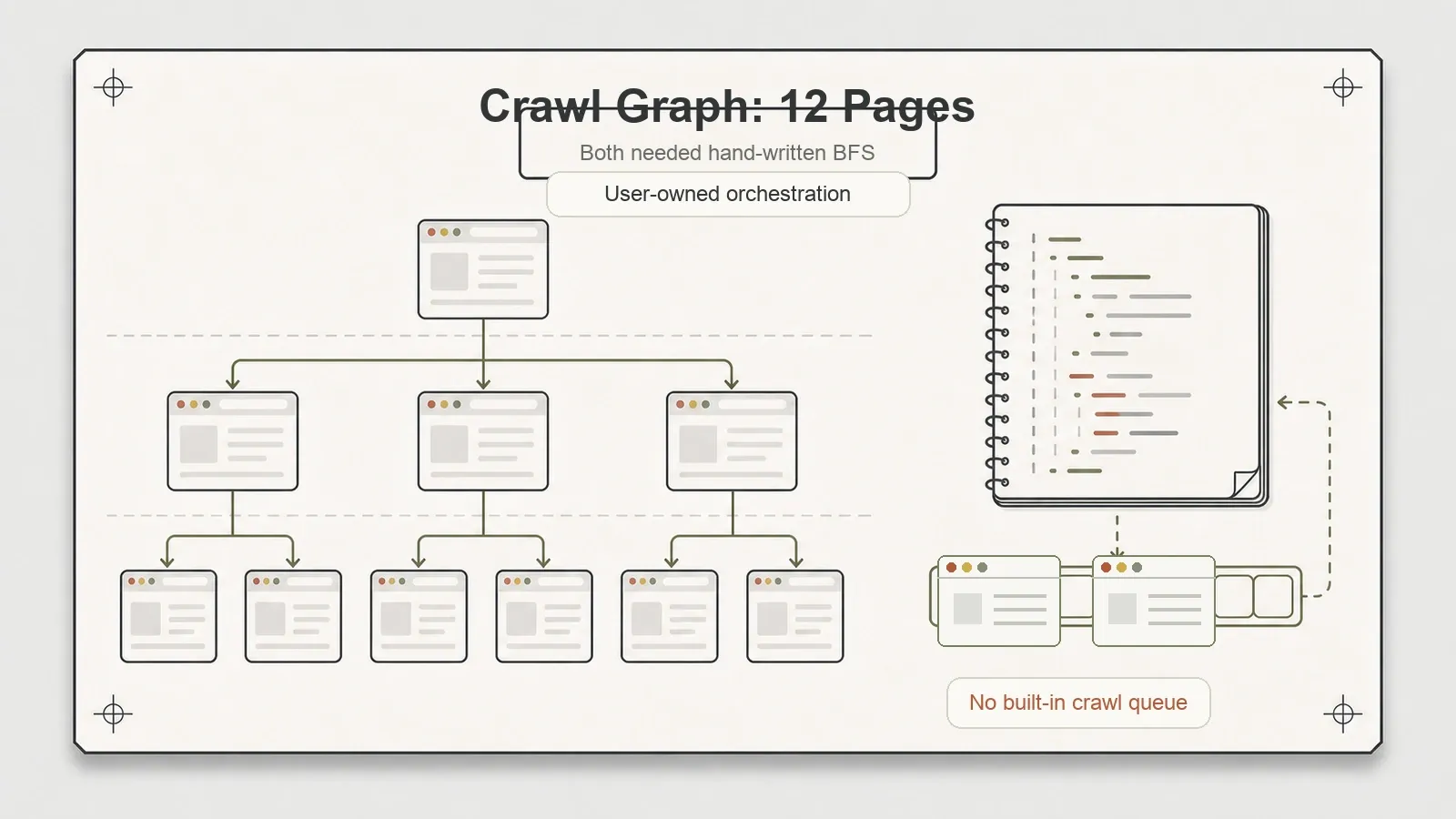
Entrambi lasciano sulla tua scrivania la stessa attività: l’orchestrazione del crawl. Nessuno dei due include una coda di richieste, un writer per il dataset o un sistema di throttling automatico. Il mio test sul grafo di crawl — seguire i link interni, tracciare la profondità, non rivisitare un URL — ha richiesto in entrambi i casi una breadth-first search scritta a mano. Dodici pagine, profondità {0,1,2}, la mia BFS, entrambe le volte.
Per poche pagine va benissimo; una BFS piccola sono una dozzina di righe. Per il crawling su larga scala — centinaia o migliaia di URL con deduplicazione, retry e ritardi di cortesia — dovrai costruire tu questa logica oppure affidarti a qualcosa che avvolga questi engine. Crawlee fa esattamente questo, offrendo un vero livello di crawling sopra sia Playwright sia Puppeteer.
Non è un difetto, e voglio attribuirlo correttamente: Playwright e Puppeteer sono framework di browser automation, non framework di crawling. La coda mancante è un confine di scope, non un bug. Il modello mentale corretto è che questi strumenti sono la metà "vedere la pagina" di uno scraper. L’altra metà — "percorrere il sito" — devi ancora portarla tu: scriverla, oppure agganciarci un wrapper che la includa.
Setup e nota sulle versioni
L’installazione è molto simile. npm install scarica la libreria più il binario del browser, e il binario è la parte pesante — Puppeteer include automaticamente il download di Chrome (installazione pulita nel mio test, nessuna vulnerabilità segnalata), mentre Playwright usa un npx playwright install separato per le build del browser. Nessuno dei due è complicato da installare, ma devi mettere in conto il download in entrambi i casi; il peso del browser e il costo per pagina sono la vera tassa che paghi per il rendering, rispetto a uno strumento solo HTTP.
Ora la disclosure che ti devo. Ho testato Playwright 1.56.0 contro la release più recente 1.61.1, e Puppeteer 24.16.0 contro la latest di npm 25.3.0 — quindi Puppeteer era indietro di una versione major completa, tutto al 2026-07-09. Le API che ho usato sono stabili attraverso questi scarti, quindi i risultati restano validi. Ma se stai leggendo questo tempo dopo la pubblicazione, rifai i test con le versioni attuali prima di basare numeri esatti su di esse. E lo ripeto ancora una volta: in Playwright ho usato solo Chromium, quindi non faccio alcuna affermazione sulla parità con Firefox o WebKit oltre al fatto che "è documentata".
Playwright e Puppeteer: pro e contro
Il pareggio rende l’elenco di pro e contro meno una gara e più una questione di ciò che stai davvero scegliendo di adottare.
Playwright
- Pro: supporto documentato a tre engine (Chromium, Firefox, WebKit) tramite una sola API; client ufficiali per Python, Java e .NET; rendering JS nativo con recall completo; ampliamento attivo del supporto.
- Contro: nessuna coda di crawl integrata; peso del browser e costo per pagina; in questo test ho usato solo Chromium; la versione testata era indietro rispetto all’ultima release.
Puppeteer
- Pro: automazione Chrome matura e stabile tramite CDP; rendering JS nativo con recall completo; gestione pulita dell’HTTP 500 (oggetto response, nessuna eccezione); ecosistema profondo e rodato; supporto documentato a Firefox via WebDriver BiDi dalla v23.
- Contro: orientato a Chrome e Node, senza engine WebKit; nessuna coda di crawl integrata; peso del browser; la versione testata era indietro di una major rispetto alla latest di npm.
Chi dovrebbe scegliere cosa
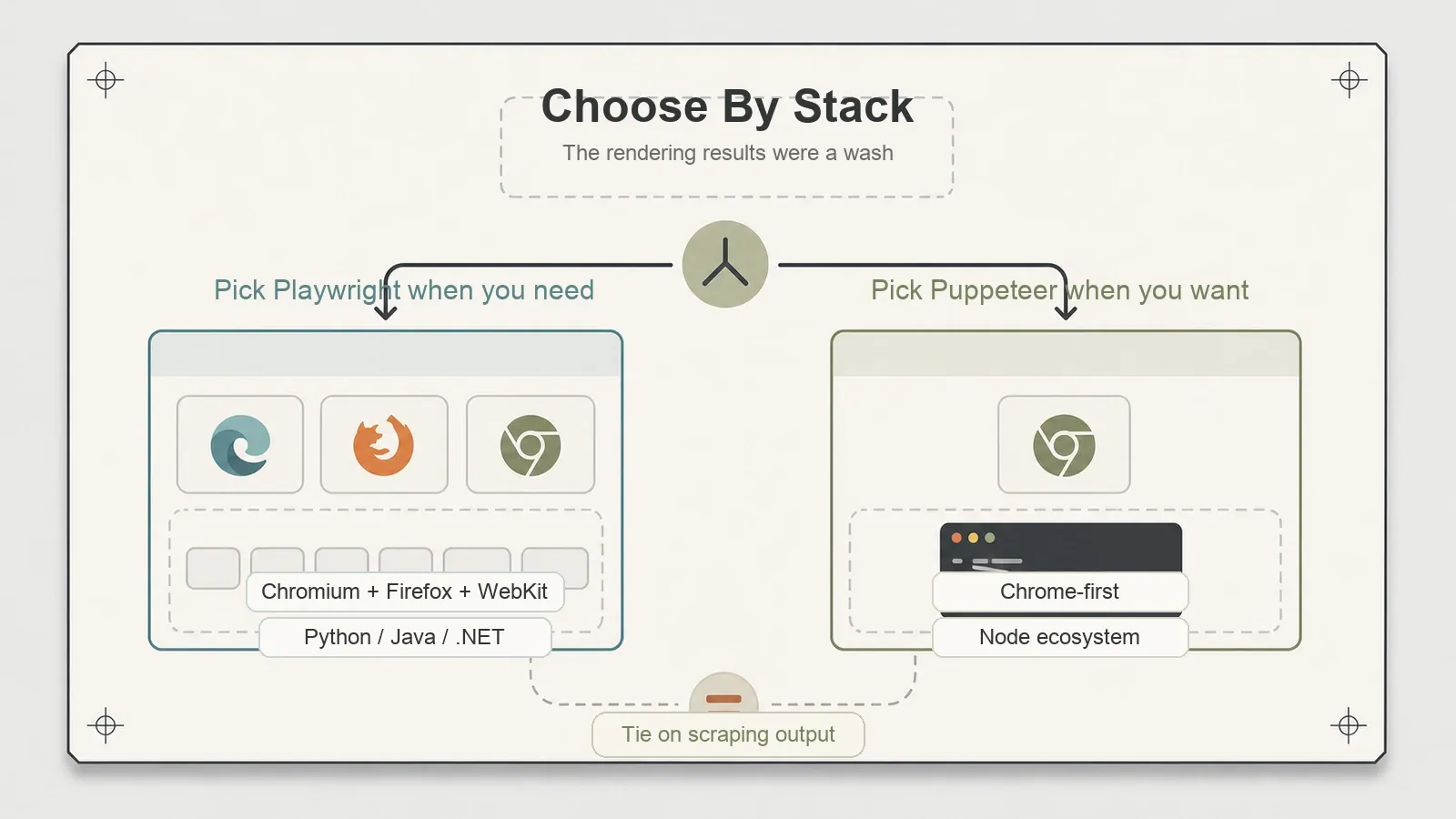
Scegli Puppeteer se lavori in Node, i tuoi target rendono bene in Chrome (come succede nella maggior parte dei casi), e vuoi una libreria matura, focalizzata, con un ecosistema profondo e un asse di complessità in meno da gestire. L’opzione Firefox via BiDi c’è, se in futuro ti servirà.
Scegli Playwright se ti serve copertura WebKit, vuoi scrivere il tuo scraper in Python o .NET, oppure preferisci puntare sul progetto con la superficie più ampia per engine e linguaggi. Solo questo allineamento linguistico è spesso il motivo più chiaro per cui un team Python finisce su Playwright.
E c’è una terza risposta che gli articoli comparativi saltano: non scegliere nessuno dei due se le tue pagine non hanno davvero bisogno di JavaScript per mostrare i dati. Se una richiesta HTTP e un parser ti danno già il contenuto, un browser headless è un sovradimensionamento costoso — appartiene a un’altra categoria di strumenti, e usarlo lì significa solo sprecare memoria e tempo di setup senza motivo.
Dove entra in gioco un’API gestita, incluso Thunderbit
Prova Thunderbit per l’estrazione di dati web
Sia Playwright sia Puppeteer sono librerie gratuite e open source che installi e gestisci da solo. Sei tu a occuparti dell’ambiente browser, degli aggiornamenti, del codice di crawl che aggiungi attorno e della corsa agli armamenti contro i bot. Per molti progetti questa responsabilità è esattamente la scelta giusta, e qui non c’è nulla contro di essa.
Ma guarda quanta parte del lavoro reale di scraping resta fuori da questi strumenti. Renderizzano bene una pagina; non mettono in coda gli URL, non ruotano attorno ai blocchi, non ti restituiscono JSON strutturato, e devi tenere in vita la flotta di browser. È un livello diverso dello stack rispetto a un servizio di estrazione gestito, ed è utile dirlo chiaramente a chi deve valutare build vs buy. Il nostro stack per sviluppatori Thunderbit si colloca proprio su quell’altro livello: POST /distill trasforma una pagina in Markdown pulito, pronto per un LLM, e POST /extract restituisce JSON strutturato in base a uno schema definito da te, con rendering JavaScript, gestione anti-bot e CAPTCHA gestiti lato server invece che sul tuo portatile. Esiste un Thunderbit MCP server per agenti AI e assistenti di coding (dove thunderbit_suggest_fields è gratuito prima che tu spenda qualcosa), e una CLI tramite npx @thunderbit/thunderbit-cli per CI e cron.
Non farò finta che sia oggettivamente meglio — è un compromesso di tipo diverso. Con Playwright o Puppeteer controlli tu il rendering e tutto ciò che costruisci attorno, a costo zero per chiamata. Con un’API gestita scarichi rendering, anti-bot e infrastruttura di crawling, e paghi per richiesta (nel caso di Thunderbit, a consumo per chiamata — un credito per un distill, venti per un extract — non per riga). Progetto piccolo, in hosting autonomo, e ti piace possedere il browser? Queste librerie sono gli strumenti giusti. Devi scalare, e preferisci non gestire una flotta headless più un crawler più un livello di rotazione dei blocchi? Un percorso gestito elimina quell’intera categoria di lavoro.
Per il panorama più ampio, il nostro team ha testato anche l’approccio a due engine di Crawlee e una serie di framework HTTP-first sulle stesse fixture, che è il passo successivo utile se hai deciso che un browser completo è più di quanto le tue pagine richiedano.
Verdetto
Dovresti usare Playwright o Puppeteer? Per il rendering di pagine JavaScript, uno qualunque dei due: hanno pareggiato in ogni test che conta qui, quindi non stai rinunciando a capacità scegliendo in base ad altri criteri. Scegli Puppeteer se ti bastano Chrome e Firefox da Node e vuoi maturità e focalizzazione. Scegli Playwright se ti serve arrivare a WebKit o usare client non JavaScript.
Due aspetti che gli articoli comparativi tendono a tralasciare vale la pena portarseli a casa. Primo: nelle attività di web scraping reali questi due strumenti sono davvero in parità, quindi non serve preoccuparsi per un gap prestazionale che non è emerso in otto test diversi. Secondo: nessuno dei due è un crawler — renderizzano, e il crawling lo devi fare tu o affidarti a un wrapper come Crawlee. Se metti bene a fuoco questi due punti e fai coincidere lo scope con il tuo stack, la scelta si riduce molto. La decisione sul motore conta molto meno della metà del lavoro che nessuno dei due fa al posto tuo.
Scopri di più
- Recensione di Crawlee
- Recensione di Crawl4AI
- Recensione di Scrapy
- Recensione di Colly
- Recensione di Scrapling
Prova Thunderbit per l’estrazione di dati web Get Started Free
FAQ
Playwright o Puppeteer è più veloce per il web scraping? Su fixture identiche, sono stati di fatto pari — stesso recall su statico (12/12), dinamico (8/8) ed estrazione da API JSON, stesso rendering nativo, stessa gestione dell’HTTP 500. Si trattava di osservazioni su una singola esecuzione e una singola macchina, non di benchmark, quindi le differenze di tempo per pagina non sono una vera misura di velocità. Scegli in base a scope e linguaggio, non a un divario di performance che non è emerso.
Qual è la differenza reale tra Playwright e Puppeteer? Ambito di engine e linguaggi. Playwright controlla Chromium, Firefox e WebKit tramite una sola API, con client per Python, Java e .NET. Puppeteer è orientato a Chrome tramite CDP, con supporto documentato a Firefox via WebDriver BiDi dalla v23, ma senza WebKit, ed è basato su Node. Entrambi renderizzano JavaScript in modo nativo, e nessuno dei due include l’orchestrazione del crawl integrata.
Posso fare crawling di un intero sito con Playwright o Puppeteer? Non subito. Nessuno dei due ha una coda di richieste, un writer per il dataset o il throttling automatico — il mio test sul grafo di crawl ha richiesto in entrambi i casi una BFS scritta a mano, dodici pagine a profondità {0,1,2}. Per scalare, aggiungi un livello di crawling come Crawlee, che avvolge entrambi gli engine con la vera infrastruttura di crawl.
Mi serve davvero uno strumento browser per fare scraping? Solo se la pagina ha bisogno di JavaScript per mostrare i dati. Se una richiesta HTTP più un parser ti restituiscono il contenuto che vuoi, un browser headless è un sovradimensionamento costoso — usa invece uno strumento HTTP-first e salta del tutto il peso del browser.
Cosa dovrebbe scegliere un team Python? Playwright, perché ha un client Python di prima classe. Puppeteer è basato su Node, quindi usarlo da Python significa costruire un ponte da mantenere. Questa compatibilità con il linguaggio è uno dei motivi più chiari per scegliere Playwright al posto di Puppeteer.




