Ti iscrivi a ScraperAPI, vedi "100.000 crediti" nel piano Hobby e inizi a fare scraping. Tre giorni dopo, la dashboard mostra che l’80% di quei crediti è già sparito — e hai estratto forse 6.000 pagine. Com’è possibile? La risposta è il sistema dei moltiplicatori di credito, ed è l’aspetto più importante di ScraperAPI che quasi nessuna recensione spiega davvero. Ho passato settimane a studiare la documentazione di ScraperAPI, confrontare i prezzi reali di cinque provider concorrenti e leggere ogni thread su Reddit e ogni recensione su Capterra che sono riuscito a trovare. Questa recensione di ScraperAPI è quella che avrei voluto leggere quando il nostro team ha iniziato a valutare le API di scraping. Ti mostrerò il vero calcolo dei crediti, ti farò vedere dove ScraperAPI dà il meglio e dove invece fallisce del tutto, raccoglierò ciò che dicono gli utenti reali su G2, Capterra e Reddit e, soprattutto, ti aiuterò a capire se ti serve davvero un’API di scraping.
Cos’è ScraperAPI e per chi è pensato?
ScraperAPI è una Web Scraper API che gestisce tutta l’infrastruttura complessa dietro allo scraping su larga scala: rotazione dei proxy su , risoluzione automatica dei CAPTCHA, rendering JavaScript e ritentativi automatici. Ti basta inviare un URL con una semplice chiamata API e ricevi l’HTML in risposta (oppure JSON già elaborato, se usi gli endpoint per i dati strutturati). L’azienda è stata fondata nel 2018 da Daniel Ni, ha sede a Las Vegas e oggi serve tra cui Deloitte, Sony e Alibaba — gestendo .
Il pubblico principale sono team di sviluppatori e operation tecniche che costruiscono pipeline di scraping personalizzate. Se non scrivi codice, ScraperAPI non è progettato per te (ma ne parliamo più avanti).
Le funzioni principali includono: rotazione proxy, rendering JavaScript, geotargeting, endpoint per dati strutturati su siti popolari e ritentativi automatici per le richieste fallite.
Ma c’è un dettaglio che molte recensioni sorvolano: i numeri dei crediti mostrati nella pagina prezzi di ScraperAPI sono molto fuorvianti se non capisci come funzionano i moltiplicatori. E da qui partiamo.
Come funziona davvero il sistema di crediti di ScraperAPI (la parte che quasi tutte le recensioni saltano)
ScraperAPI addebita tutto tramite un sistema a crediti. Il principio base sembra semplice: 1 richiesta API = 1 credito. Ma in realtà quasi mai è così. Il costo reale in crediti dipende da due fattori: il dominio che stai estraendo e le funzionalità attivate. E questi costi si sommano in modo tutt’altro che intuitivo.
La tabella dei moltiplicatori di credito che ogni utente dovrebbe vedere prima di registrarsi

Prima ancora di attivare un solo parametro, è il tipo di sito che stai estrando a determinare il costo base in crediti:
| Categoria dominio | Crediti base per richiesta | Esempi |
|---|---|---|
| Siti normali | 1 | Blog, siti di notizie, HTML semplice |
| E-commerce | 5 | Amazon, eBay, Walmart |
| SERP (motori di ricerca) | 25 | Google, Bing |
| Social media | 30 |
A questo si aggiungono i costi extra delle funzionalità:
| Parametro | Crediti extra | Note |
|---|---|---|
render=true (rendering JS) | +10 | Tutti i piani |
screenshot=true | +10 | Tutti i piani |
premium=true (proxy premium) | +10 | Tutti i piani |
ultra_premium=true | +30 | Solo piani a pagamento |
| Bypass anti-bot (Cloudflare, DataDome, PerimeterX) | +10 ciascuno | Rilevato automaticamente — non lo scegli tu |
premium=true + render=true insieme | +25 | NON +20 |
ultra_premium=true + render=true insieme | +75 | NON +40 |
Ed è proprio l’ultima riga il punto critico. Combinare più funzioni costa più della semplice somma dei singoli costi. Proxy premium (+10) più rendering JavaScript (+10) dovrebbe logicamente costare +20 crediti extra, ma ScraperAPI applica . Ultra-premium (+30) più rendering JavaScript (+10) dovrebbe costare +40, ma in realtà costa — quasi il doppio. Questo stacking non lineare è poco evidenziato nella documentazione ed è il motivo principale per cui gli utenti dicono che i crediti spariscono più in fretta del previsto.
I parametri che non costano crediti extra sono: wait_for_selector, country_code, session_number, device_type, output_format, keep_headers=true, autoparse=true.
Cosa ottieni davvero con ogni piano: dal Free all’Enterprise
Ecco gli di ScraperAPI:
| Piano | Prezzo mensile | Annuale (al mese) | Crediti API | Thread concorrenti | Geotargeting |
|---|---|---|---|---|---|
| Free | $0 | — | 1.000 | 5 | No |
| Hobby | $49 | $44 | 100.000 | 20 | Solo US ed EU |
| Startup | $149 | $134 | 1.000.000 | 50 | Solo US ed EU |
| Business | $299 | $269 | 3.000.000 | 100 | A livello di Paese (50+ Paesi) |
| Scaling | $475 | $427 | 5.000.000 | 200 | A livello di Paese |
| Enterprise | Personalizzato | Personalizzato | 5.000.000+ | 200+ | A livello di Paese |
Ora vediamo il costo effettivo per 1.000 richieste a ciascun livello, tenendo conto dei moltiplicatori:
| Piano | Standard (1×) | Rendering JS (10×) | E-commerce (5×) | SERP (25×) | Ultra-Premium + JS (75×) |
|---|---|---|---|---|---|
| Hobby ($49) | $0,49 | $4,90 | $2,45 | $12,25 | $36,75 |
| Startup ($149) | $0,15 | $1,49 | $0,75 | $3,73 | $11,18 |
| Business ($299) | $0,10 | $1,00 | $0,50 | $2,49 | $7,48 |
| Scaling ($475) | $0,10 | $0,95 | $0,48 | $2,38 | $7,13 |
Un piano da $49 al mese pubblicizzato come "100.000 crediti" in realtà consente solo 1.333 richieste effettive quando si estraggono siti protetti con ultra-premium più rendering JavaScript. Questo equivale a — più costoso di molti servizi di scraping completamente gestiti.
Perché i crediti finiscono più in fretta del previsto
Ci sono tre cose che sorprendono gli utenti.
Prima: il pricing basato sul dominio è automatico. Non sei tu a scegliere il moltiplicatore 5× per Amazon o 25× per Google. Scatta nel momento in cui ScraperAPI rileva il dominio. Lo stesso vale per i crediti di bypass anti-bot (+10 per Cloudflare, DataDome, PerimeterX), aggiunti automaticamente quando vengono rilevati.
Seconda: i crediti non si accumulano. I crediti non utilizzati . Nessun rollover.
E terza — questa fa male — il Pay-As-You-Go è disponibile solo dal piano Scaling ($475/mese) in su. Se sei su Hobby, Startup o Business e finisci i crediti a metà ciclo, vieni semplicemente bloccato fino al periodo di fatturazione successivo. L’unica opzione è passare al piano superiore.
Un utente su Reddit ha raccontato di essersi visto quotare $3.600 per 60 milioni di crediti a 1 credito per richiesta Amazon, ma dopo il pagamento è stato applicato un moltiplicatore 5× senza alcuna comunicazione iniziale. Il suo piano da 60M valeva in pratica solo 12M di richieste — un rispetto alle aspettative.
La trappola dei crediti di DataPipeline
La funzione no-code DataPipeline di ScraperAPI (scraping programmato con consegna via webhook) usa una tabella crediti separata, molto più alta. Una richiesta base normale costa tramite la API standard:
| Tipo di richiesta | API standard | DataPipeline | Rapporto |
|---|---|---|---|
| Richiesta base normale | 1 | 6 | 6× |
| E-commerce base | 5 | 10 | 2× |
| SERP base | 25 | 30 | 1,2× |
| Ultra-premium + JS (normale) | 75 | 80 | 1,07× |
Gli utenti che configurano pipeline no-code aspettandosi costi standard scoprono presto di consumare crediti 6× più velocemente sulle richieste base. È documentato, ma bisogna andarselo a cercare.
Costo reale per richiesta: ScraperAPI vs concorrenza
Il prezzo di facciata non significa nulla se non consideri i moltiplicatori. Ho raccolto i prezzi attuali di cinque provider e ho standardizzato il confronto sul tier da circa $300/mese in tre scenari comuni.
Estrazione HTML base (senza JS, senza proxy premium)
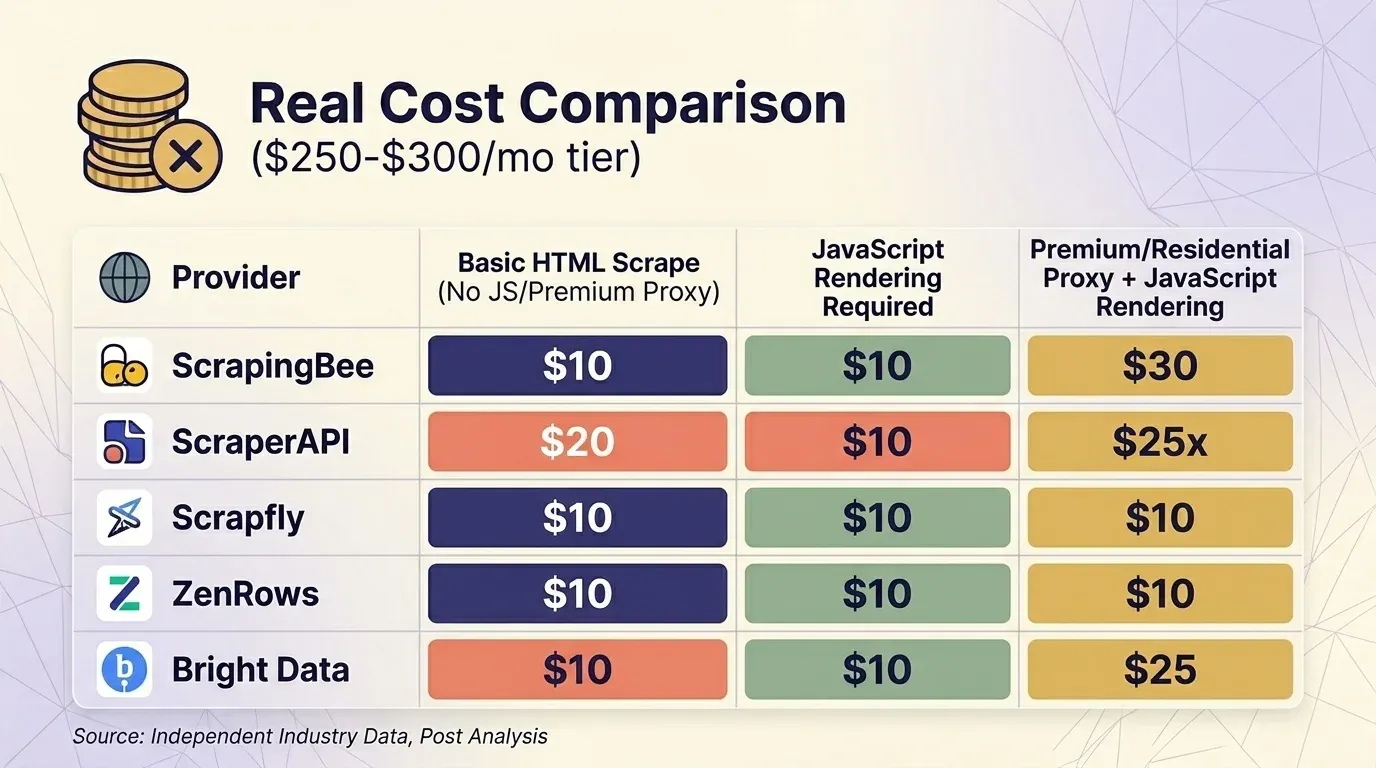
| Provider | Piano | Crediti per richiesta | Richieste effettive | Costo per 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3.000.000 | $0,08 |
| ScraperAPI | Business $299 | 1 | 3.000.000 | $0,10 |
| Scrapfly | Startup $250 | 1 | 2.500.000 | $0,10 |
| ZenRows | Business $300 | $0,28/1K | ~1.071.000 | $0,28 |
| Bright Data | PAYG | $1,50/1K | ~200.000 | $1,50 |
Rendering JavaScript richiesto
| Provider | Piano | Crediti per richiesta | Richieste effettive | Costo per 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5 (attivo di default) | 600.000 | $0,42 |
| Scrapfly | Startup $250 | 6 | 416.667 | $0,60 |
| ScraperAPI | Business $299 | 10 | 300.000 | $1,00 |
| ZenRows | Business $300 | 5× | ~214.000 | $1,40 |
| Bright Data | PAYG | flat | ~200.000 | $1,50 |
Proxy premium/residential + rendering JavaScript (siti protetti)
| Provider | Piano | Crediti per richiesta | Richieste effettive | Costo per 1K |
|---|---|---|---|---|
| Bright Data | PAYG | flat | ~200.000 | $1,50 |
| ScrapingBee | Business $249 | 25 | 120.000 | $2,08 |
| ScraperAPI | Business $299 | 25 | 120.000 | $2,49 |
| Scrapfly | Startup $250 | 31 | 80.645 | $3,10 |
| ZenRows | Business $300 | 25× | ~42.857 | $7,00 |
Il Web Unlocker di Bright Data è l’unico provider che : tutte le richieste hanno lo stesso prezzo flat. Nel tier da circa $300, ScrapingBee e ScraperAPI sono competitivi per lo scraping di siti protetti, mentre ZenRows è il più costoso.
Una nota comportamentale importante: ScrapingBee con costo 5×. Se confronti ScrapingBee e ScraperAPI direttamente, assicurati di usare le stesse impostazioni di rendering.
Un’analisi indipendente di Scrape.do ha rilevato che ScraperAPI costa in media — “più di qualunque altro provider testato” — con un tempo di risposta medio di , rendendolo “uno dei provider più lenti disponibili”. È un dato utile da conoscere prima di impegnarti.
Tassi di successo per sito: dove ScraperAPI eccelle e dove fatica
Nessuna scraping API funziona allo stesso modo su ogni sito. I benchmark indipendenti di Scrapeway (aprile 2026) raccontano una storia molto bimodale.
Prestazioni per categoria di sito
| Sito target | Tasso di successo | Velocità media | Costo per 1K (Business Plan) |
|---|---|---|---|
| Zillow | 100% | 10,5s | $0,49 |
| Etsy | 99% | 4,8s | $4,90 |
| Amazon | 98% | 6,5s | $2,45 |
| 95% | 17,8s | $14,70 | |
| Walmart | 93% | 11,4s | $2,45 |
| Indeed | 90% | 15,8s | $4,90 |
| StockX | 84% | 3,9s | $4,90 |
| Realtor.com | 12% | 11,8s | $0,49 |
| 0% | — | — | |
| Booking.com | 0% | — | — |
| Twitter/X | 0% | — | — |
Tasso medio di successo complessivo: , leggermente sopra la media del settore, pari al 58,2–59,5%. Tempo medio di risposta: 5,2–7,3 secondi, migliore della media di settore di 9,8 secondi.
Dove ScraperAPI va meglio
ScraperAPI è davvero forte su e-commerce (Amazon, Walmart, Etsy) e real estate (Zillow). Gli endpoint per dati strutturati per questi siti restituiscono JSON già parsato con alta affidabilità. Se il tuo caso d’uso principale è estrarre pagine prodotto Amazon o SERP di Google, ScraperAPI è una scelta ragionevole.
Dove ScraperAPI delude
I social media sono una zona morta. Instagram, Twitter/X e Booking.com mostrano tutti un tasso di successo dello 0% nei test indipendenti. LinkedIn funziona al 95%, ma con 30 crediti per richiesta il costo è elevato.
I siti che richiedono login sono esplicitamente esclusi. ScraperAPI supporta la persistenza della sessione tramite il parametro session_number, ma . Non può gestire compilazione di form, autenticazione a due fattori o flussi di login complessi.
Dati non aggiornati sui target protetti. ScraperAPI applica una , quindi se stai estraendo dati sensibili al tempo (prezzi, disponibilità di stock), potresti ricevere risultati vecchi fino a 10 minuti.
Nel benchmark 2025 di Proxyway, ScraperAPI ha avuto il , con l’81,72%.
Riepilogo delle prestazioni per categoria
| Categoria sito | Prestazioni di ScraperAPI | Problemi noti | Alternativa possibile |
|---|---|---|---|
| Amazon / e-commerce | ✅ Forte (endpoint SDP) | Molto dispendioso in crediti su larga scala | Template Thunderbit (1 click, nessun credito per riga per il template) |
| SERP Google | ✅ Forte | Il geotargeting costa extra; peggior successo su Google in un benchmark | — |
| Real estate (Zillow) | ✅ Eccellente (100%) | — | — |
| Instagram / social media | ❌ 0% successo | Fallimento totale | Playwright + proxy (DIY) |
| SPA pesanti in JS | ⚠️ Moderato | Richiede rendering headless da 10× crediti | Scrapfly, ZenRows |
| Siti che richiedono login | ❌ Vietato dai ToS | Nessun supporto a sessioni/auth | Browser scraping di Thunderbit (usa la tua sessione di login) |
| Booking.com / travel | ❌ 0% successo | Fallimento totale | Bright Data |
Cosa dicono i veri utenti: sintesi del sentiment su G2, Capterra e Reddit
Ho raccolto feedback da tre piattaforme. Ecco le valutazioni attuali:
| Piattaforma | Valutazione | Recensioni |
|---|---|---|
| G2 | 4,4/5 | 16 |
| Capterra | 4,6/5 | 62 |
| Trustpilot | 4,5/5 | 43 |
Valutazioni secondarie su Capterra: facilità d’uso 4,9/5, assistenza clienti 4,6/5, funzionalità 4,5/5, rapporto qualità/prezzo 4,5/5.
Sintesi del sentiment per tema
| Tema | Segnali positivi | Segnali negativi |
|---|---|---|
| Facilità di configurazione / documentazione | "Super easy to set up. You can start scraping in minutes." — Latenode community; Capterra Ease of Use 4.9/5 | — |
| Trasparenza dei prezzi | "Affordable entry tier" (più recensioni Capterra) | "Breakdown of credit costs can be confusing" — John S., Founder, Capterra (feb 2025); "Prices increased by 1000% and quality degraded" — CTO, Online Media, Capterra (set 2022) |
| Affidabilità | "Works great for Amazon/Google" (G2, Capterra) | "ScraperAPI becomes shaky for heavy duty jobs" — emcarter, Latenode; "80% failure rate on some targets" (Reddit) |
| Supporto clienti | "Responsive team" (Capterra) | Un utente ha raccontato di essere stato quotato a un prezzo, poi fatturato a 5× la tariffa senza alcuna informazione iniziale (Reddit) |
| Valore nel tempo | Addebita solo le richieste riuscite (200/404) | "If you're running large-scale operations, the expenses can add up quickly" e costruire infrastruttura propria è "more cost-effective in the long run" — mikezhang, Latenode |
Conclusione: ScraperAPI è molto apprezzato per la semplicità di configurazione iniziale e funziona in modo affidabile sui target popolari e ben supportati. Le critiche si concentrano sui costi inattesi (moltiplicatori, aumenti improvvisi) e sull’affidabilità sui target più difficili.
Gli endpoint per dati strutturati di ScraperAPI: valgono i crediti premium?
ScraperAPI offre su 5 piattaforme, restituendo JSON già parsato invece di HTML grezzo:
- Amazon (3 endpoint): dettagli prodotto tramite ASIN, risultati di ricerca, offerte dei competitor. Restituisce oltre 18 campi tra cui prezzi, valutazioni, descrizioni, recensioni, BSR, immagini e informazioni sul venditore. Supporta .
- Google (5 endpoint): (risultati organici, knowledge graph, video, domande correlate, paginazione), Shopping, Maps, News, Jobs.
- Walmart (4 endpoint): prodotto, ricerca, categoria, recensioni.
- eBay (2 endpoint): prodotto, ricerca.
- Redfin (4 endpoint): ricerca, dettagli agente, affitti, immobili in vendita.
Gli SDE sono disponibili su tutti i piani, incluso il Free. ScraperAPI dichiara un tasso di successo del per i domini SDE supportati — anche se i benchmark indipendenti mostrano un quadro più sfumato a seconda del sito.
Completezza dei dati
L’Amazon SDP è l’offerta più forte di ScraperAPI. Restituisce un set completo di campi: prezzo, recensioni, BSR, varianti, immagini, info venditore e altro ancora. L’Google SERP SDP restituisce risultati organici, annunci, featured snippet e People Also Ask. La completezza dei dati è davvero buona su queste due piattaforme.
Efficienza dei crediti: SDP vs parsing fai-da-te
Sul piano Business ($299/mese, 3M crediti), estrarre 10.000 prodotti Amazon tramite SDE costa 50.000 crediti (5 crediti ciascuno) — circa $5 del valore del piano. Costruire un parser proprio con una richiesta standard (1 credito ciascuna) costerebbe solo 10.000 crediti, ma richiederebbe tempo di sviluppo per creare e mantenere il parser.
Per piccoli team senza sviluppatori, gli SDE fanno risparmiare tempo reale.
Per team con capacità ingegneristica che fanno scraping su larga scala, il premium 5× in crediti è difficile da giustificare.
Come gli SDP si confrontano con i template no-code
Questo confronto conta più di quanto molte recensioni lascino intendere. offre template di scraping istantanei per Amazon, Shopify, Zillow e che non richiedono codice e non hanno costi per riga sul template stesso.
| Fattore | ScraperAPI SDP (Amazon) | Template Amazon di Thunderbit |
|---|---|---|
| Tempo di configurazione | 30–60 min (codice + integrazione API) | ~2 minuti (installa l’estensione, apri Amazon, clicca il template) |
| Costo per 1.000 prodotti (Business plan) | ~$5 (50.000 crediti a $0,10/credito) | ~$16,50 (1.000 righe × 1 credito a $0,0165/credito su Pro) |
| Campi restituiti | 18+ (completo) | Nome prodotto, prezzo, valutazione, recensioni, immagini, URL e altro |
| Opzioni di esportazione | JSON (serve codice per il parsing) | Excel, CSV, Google Sheets, Airtable, Notion — 1 clic |
| Manutenzione | ScraperAPI mantiene l’SDP | Il team Thunderbit mantiene i template |
| Competenze tecniche | Python/Node.js richiesti | Nessuna |
Per i team di sviluppo che fanno scraping Amazon ad alto volume, l’SDP di ScraperAPI è più efficiente in termini di costo per prodotto su larga scala. Per utenti business che vogliono i dati Amazon in un foglio di calcolo senza scrivere codice, Thunderbit è molto più rapido da configurare e usare.
Ti serve davvero un’API di scraping? Il percorso no-code che molte recensioni ignorano
Molte persone che cercano una "recensione di Scraper API" non hanno ancora scelto un workflow basato su API. Stanno cercando di capire se ne hanno davvero bisogno.
E sorprendentemente, molti non ne hanno bisogno. Il mercato delle web scraping API vale e cresce a un CAGR del 14–18%, ma questa crescita è trainata soprattutto dai team di ingegneria enterprise — non dal sales ops manager che ha bisogno di 500 lead da un sito.
API di scraping vs strumento no-code: decisione affiancata
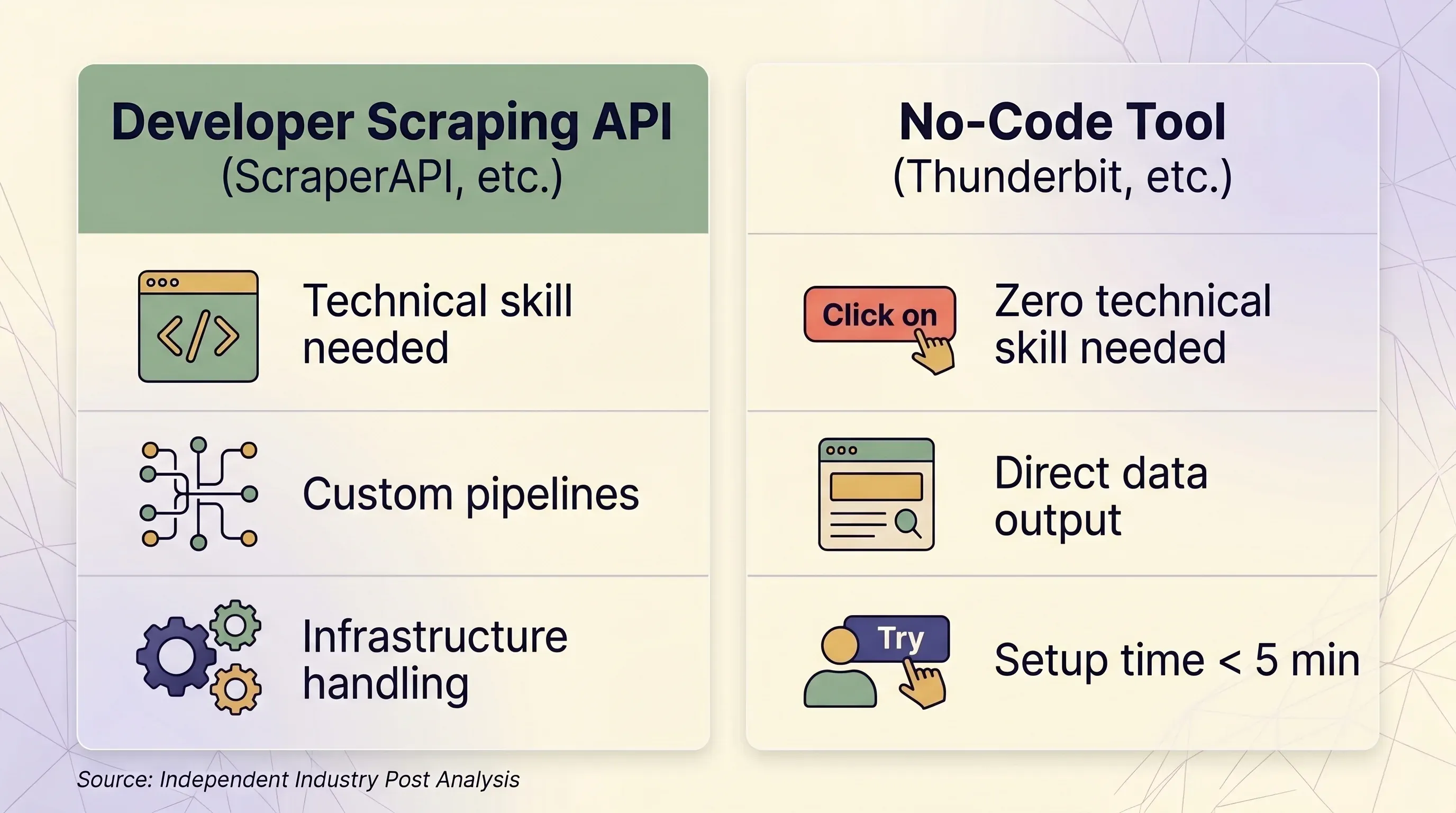
| Fattore | API di scraping (ScraperAPI, ecc.) | Strumento no-code (Thunderbit, ecc.) | |---|---|---|---| | Ideale per | Sviluppatori che costruiscono pipeline dati su larga scala | Utenti business, marketer, team sales, ricercatori | | Competenze richieste | Python/Node.js, concetti HTTP, parsing JSON | Nessuna — click diretto nel browser | | Tempo di configurazione | Minimo 1–2 ore (codice + test + debug) | Meno di 5 minuti | | Gestione anti-bot | Proxy premium (10–75 crediti/richiesta) | Sessione browser reale — bypass naturale delle fingerprint | | Siti che richiedono login | ❌ Vietato dai ToS di ScraperAPI | ✅ Browser Scraping usa la tua sessione esistente | | Scala (pagine/giorno) | 100K–3M+ richieste/mese | Ad hoc, in genere sotto le 1.000 pagine/giorno | | Output dati | HTML grezzo o JSON (serve codice per il parsing) | Righe/colonne strutturate — pronte all’uso | | Esportazione | JSON, CSV (tramite codice) | Excel, CSV, Google Sheets, Airtable, Notion, Word, JSON | | Manutenzione | Devi aggiornare selettori, logica di retry e infrastruttura | Nessuna — l’AI rilegge la struttura della pagina ogni volta | | Unità di prezzo | Crediti per richiesta (variabili: 1–75 crediti/richiesta) | Crediti per riga (1 credito = 1 riga, 2 per le sottopagine) | | Prezzo d’ingresso | $49/mese per 100K crediti | $9/mese per 5.000 crediti (annuale) | | Piano gratuito | 1.000 crediti/mese, 5 concorrenti | 6 pagine/mese, 30 crediti/pagina | | Prevedibilità dei prezzi | Bassa — i moltiplicatori creano costi inattesi | Alta — 1 riga = sempre 1 credito |
Quando ha senso un’API di scraping
- Hai un team di sviluppo o ingegneria
- Devi fare scraping di oltre 100K pagine al giorno in modo programmatico
- Ti servono personalizzazioni profonde di header, sessioni e logica di retry
- I tuoi target sono ben supportati (Amazon, Google, Walmart, Zillow)
Quando ha più senso uno strumento no-code come Thunderbit
- Lavori in sales, e-commerce ops, marketing o real estate — non in ingegneria
- Ti servono dati da decine di siti diversi senza costruire parser dedicati per ciascuno
- Vuoi esportare direttamente in Excel, Google Sheets, Airtable o Notion
- Devi estrarre siti che richiedono login (il di Thunderbit usa la tua sessione)
- Vuoi che l’AI legga ogni volta la pagina da zero — senza mantenimento del codice quando il layout cambia
- Ti serve scraping di sottopagine: Thunderbit può aprire ogni pagina di dettaglio e arricchire automaticamente le righe
Il flusso del è davvero semplice: installi l’estensione, vai su una pagina, clicchi "AI Suggest Fields", poi "Scrape" ed esporti. L’AI capisce quali dati sono presenti nella pagina e suggerisce le colonne — non devi scrivere selettori né codice. Per approfondire, dai un’occhiata alla nostra .
ha subito sforamenti dei costi cloud nel 2024, e le aziende che usano pricing basato sull’utilizzo senza adeguate protezioni registrano a causa dello shock da fattura. La prevedibilità di un modello a crediti per riga vale la pena di essere considerata se in passato sei già rimasto scottato dai costi variabili delle API.
Pro e contro di ScraperAPI in sintesi
| Pro | Contro |
|---|---|
| Infrastruttura proxy solida (40M+ IP, 50+ Paesi) | Sistema di moltiplicatori di credito confuso — combinare funzioni costa più della somma |
| Documentazione eccellente e configurazione iniziale facile (Capterra Ease of Use: 4,9/5) | I crediti non si accumulano da un mese all’altro |
| Affidabile su Amazon, Google, Zillow, Etsy | 0% di successo su Instagram, Twitter/X, Booking.com |
| Addebita solo le richieste riuscite (200/404) | Le risposte 404 consumano comunque crediti |
| 18 endpoint per dati strutturati con output JSON parsato | I siti con login sono esplicitamente vietati |
| Disponibile su tutti i piani, incluso Free | Pay-As-You-Go solo su Scaling ($475/mese) e superiori |
| Politica di rimborso di 7 giorni senza domande | Cache forzata di 10 minuti sui target difficili — rischio dati vecchi |
| Crescita dei ricavi 30–35% YoY indica sviluppo attivo | DataPipeline costa fino a 6× i crediti dell’API standard |
| — | Il geotargeting oltre US ed EU richiede il piano Business ($299/mese) |
| — | Nessun alert proattivo sull’utilizzo — devi controllare manualmente la dashboard |
Consigli pratici per sfruttare al meglio ScraperAPI (se decidi di usarlo)
Monitora ogni giorno il consumo di crediti
La di ScraperAPI fornisce statistiche sull’utilizzo, tra cui latenza media, domini estratti e metriche di concorrenza. Tuttavia, non ci sono alert proattivi di utilizzo — niente email o SMS quando i crediti stanno finendo. Devi controllare manualmente. La cronologia analytics è limitata a 2 settimane nei piani Hobby/Startup e a 6 mesi nei piani Business+.
Imposta un promemoria sul calendario per controllare la dashboard ogni giorno durante il primo mese. Devi capire empiricamente con quale velocità i crediti si consumano sui tuoi target specifici.
Parti dal piano gratuito per testare i tuoi siti target
Usa i 1.000 crediti gratuiti (più una prova di 7 giorni con 5.000 crediti) per testare i tassi di successo sui tuoi siti target prima di passare a un piano a pagamento. Annota quali siti richiedono rendering JavaScript o proxy premium, così potrai stimare i costi mensili reali con i moltiplicatori applicati.
Disattiva le funzioni premium se il target non le richiede
ScraperAPI NON attiva automaticamente proxy premium o rendering JavaScript — devi impostare esplicitamente render=true, premium=true o ultra_premium=true. Ma il pricing basato sul dominio è automatico: Amazon costa sempre 5 crediti, Google sempre 25, LinkedIn sempre 30. Anche i crediti di bypass anti-bot (+10 per Cloudflare, DataDome, PerimeterX) vengono aggiunti automaticamente quando rilevati. Tienilo presente prima di lanciare un batch.
Usa gli endpoint per dati strutturati sui siti supportati
Se stai estraendo dati da Amazon o Google, gli SDE fanno risparmiare tempo di sviluppo anche se costano più crediti. Per i siti non supportati, valuta se uno sia più veloce ed economico di un parser personalizzato.
Prevedi un piano B per i target poco affidabili
Se il tasso di successo di ScraperAPI su un sito specifico scende sotto il 90%, considera di instradare quelle richieste su un altro provider o di usare uno strumento browser-based. Per i siti che richiedono login, ScraperAPI semplicemente non funziona — ti servirà uno strumento come che opera all’interno della tua sessione browser.
Conosci le insidie
- Le risposte 404 consumano crediti — ScraperAPI addebita sia gli status code 200 sia 404
- Le richieste annullate vengono addebitate se le interrompi prima che termini la finestra di elaborazione di 70 secondi
- Cache forzata di 10 minuti sui target difficili — potresti ricevere dati vecchi
- Il Pay-As-You-Go è disponibile solo su Scaling ($475/mese) e superiori — gli utenti dei piani inferiori che esauriscono i crediti vengono bloccati
- Il geotargeting oltre US ed EU richiede il piano Business ($299/mese)
Conclusioni: ScraperAPI è lo strumento giusto per te?
Ecco dove sono arrivato dopo tutta la ricerca:
- ScraperAPI è una scelta solida per team di sviluppo che fanno scraping ad alto volume su target ben supportati come Amazon, Google, Walmart e Zillow. Gli endpoint per dati strutturati sono davvero utili, l’infrastruttura proxy è ampia e la documentazione è sopra la media.
- Il sistema dei moltiplicatori di credito è il rischio più grande. Se non capisci come si sommano i moltiplicatori, spenderai troppo. Il divario tra crediti pubblicizzati e richieste effettive può variare da 5× a 75×. Fai i conti sul tuo caso d’uso specifico prima di abbonarti.
- L’affidabilità dipende dal sito. ScraperAPI è eccellente su e-commerce e real estate, mediocre su job board e social media, e del tutto inutile su Instagram, Twitter/X e Booking.com. Non dare per scontate prestazioni uniformi.
- Per i team non tecnici, ScraperAPI è lo strumento sbagliato. Se lavori in sales, marketing o operations e ti servono dati strutturati senza scrivere codice, uno strumento no-code come ti porta al risultato in due clic — con rilevamento campi tramite AI, esportazione diretta in fogli di calcolo, arricchimento delle sottopagine e zero manutenzione. Dai un’occhiata alla oppure guarda i tutorial sul .
- Per gli sviluppatori con budget limitato, prova il piano gratuito di ScraperAPI sui tuoi target specifici, poi confronta i costi effettivi per richiesta con ScrapingBee, Scrapfly e Bright Data prima di scegliere. L’opzione più economica dipende interamente dal tuo caso d’uso e dai requisiti funzionali.
Vuoi capire come funzionano i numeri per le tue esigenze di scraping? Parti dal piano gratuito di ScraperAPI per testare i tuoi siti target, oppure per vedere quanto lontano possono portarti due clic. Per saperne di più sui , consulta i nostri piani.
FAQ
ScraperAPI è gratuito?
Sì, ScraperAPI offre un piano gratuito con e una prova di 7 giorni con 5.000 crediti. Tuttavia, i moltiplicatori di credito per rendering JavaScript, proxy premium o domini costosi (Amazon = 5×, Google = 25×, LinkedIn = 30×) fanno sì che la capacità reale possa essere molto inferiore a 1.000 richieste. Nel piano Free, i proxy ultra-premium non sono disponibili.
Quanto costa ScraperAPI per richiesta?
Dipende molto dai flag attivati e dal dominio target. Una richiesta standard a un sito HTML semplice costa 1 credito. Una richiesta Amazon costa 5 crediti. Una richiesta SERP Google costa 25 crediti. Aggiungere il rendering JavaScript aggiunge 10 crediti. Combinare proxy ultra-premium con rendering JavaScript costa 75 crediti per richiesta. Nel piano Hobby ($49/mese, 100K crediti), si va da $0,00049 per richiesta (standard) a $0,0368 per richiesta (ultra-premium + JS). Vedi le tabelle complete sopra per i dettagli.
ScraperAPI è valido per fare scraping su Amazon?
L’endpoint Amazon Structured Data di ScraperAPI è una delle sue funzioni più forti, con un nei benchmark indipendenti e un output JSON completo e già parsato (oltre 18 campi). Tuttavia, ogni richiesta Amazon costa almeno 5 crediti, quindi i costi crescono rapidamente su larga scala. Per i piccoli team che vogliono i dati Amazon in un foglio di calcolo senza codice, il offre un’alternativa in 1 clic con esportazione diretta.
Quali sono le migliori alternative a ScraperAPI?
Per gli sviluppatori: (il più economico per HTML base), (ottimo per il rendering JavaScript), (il migliore per i siti protetti — tariffa flat indipendente dal rendering) e . Per chi non programma: — un’estensione Chrome no-code, potenziata dall’AI, con esportazione diretta in Excel, Google Sheets, Airtable e Notion. Consulta il nostro per un’analisi più approfondita.
ScraperAPI può estrarre siti che richiedono login?
ScraperAPI supporta la persistenza della sessione tramite il parametro session_number (stesso IP su più richieste), ma . Non può gestire compilazione di form, autenticazione a due fattori o flussi di auth complessi. Per i siti con login, strumenti browser-based come — che usa la tua sessione browser esistente per estrarre ciò che vedi — sono l’opzione più affidabile.
Scopri di più