Una ricerca su GitHub per "tiktok scraper" restituisce . Circa non riceve un push da oltre un anno, e almeno .
Se hai mai clonato un repository popolare di TikTok scraper, passato un’ora a litigare con le dipendenze e poi ottenuto zero output, non sei il solo. Lo scraper TikTok più stellato su GitHub, drawrowfly/tiktok-scraper, ha ancora oltre 5.000 stelle. Ma il suo tracker è pieno di thread come e — entrambi segnalano zero output. Da mesi, in Thunderbit monitoro lo stato dei repository per lo scraping di TikTok, e il pattern è chiaro: questi strumenti si rompono in fretta e la maggior parte non viene mai sistemata. Questo articolo è la guida pratica di sopravvivenza che avrei voluto avere quando ho iniziato a valutare questi repository. Vedremo cosa è ancora vivo, cosa è morto, cosa usare al posto loro e come smettere di buttare ore su codice che aveva già smesso di funzionare prima ancora che tu lo trovassi.
Perché la maggior parte degli scraper TikTok su GitHub si rompe (e continua a rompersi)
TikTok non è un target di scraping come gli altri. La sua superficie web cambia continuamente. A differenza di una pagina prodotto statica di e-commerce o di un elenco in una directory, TikTok aggiorna endpoint, fingerprint anti-bot, modalità di rendering delle pagine e requisiti di sessione/token — a volte nel giro di poche settimane dall’ultima modifica.
Chi mantiene progetti open source lo fa volontariamente. Quando TikTok rilascia un aggiornamento che rompe il flusso di richieste dello scraper, il repository può restare rotto per giorni, settimane o per sempre. Non è una critica ai maintainer: è un divario strutturale tra una piattaforma molto dinamica e ben finanziata e sviluppatori non retribuiti che hanno anche un lavoro principale.
Anche i migliori repository di TikTok scraper vivono in un ciclo continuo di rottura e riparazione. Se vuoi usarne uno, ti serve una strategia per valutarlo, risolvere i problemi e avere sempre un piano B.
Le difese anti-bot di TikTok: con cosa hai a che fare
- Rate limiting. Le di TikTok riportano esplicitamente quote di richieste anche per le integrazioni approvate. Gli scraper non ufficiali raggiungono questi limiti molto più in fretta.
- Blocco basato su cookie e sessione. Repository moderni come richiedono un
ms_token; repository più vecchi come mostranott_webid_v2nei loro esempi; documentamsToken,ttwid,X-BoguseA_Bogus. TikTok verifica se la richiesta sembra arrivare da una vera sessione di navigazione. - Browser fingerprinting. Le spiegano perché i siti confrontano header, cookie, firme TLS e caratteristiche del browser esposte da JavaScript con il traffico reale degli utenti. La loro copre Canvas, WebGL, WebRTC, font e segnali di runtime. Il fingerprinting è come se TikTok controllasse la carta d’identità del tuo browser: se browser, cookie, tempistiche e firma di rete non coincidono, la richiesta sembra falsa ancora prima che venga restituito qualsiasi contenuto.
- Rilevamento comportamentale. I sullo scraping di TikTok citano spesso sessioni Playwright nuove che fanno scattare CAPTCHA. I post della community del descrivono sempre più spesso un rilevamento che osserva i tempi delle azioni e la qualità dell’interazione, non solo il riuso dell’IP.
- Parametri di richiesta cifrati/firmati. Evil0ctal documenta
X-BoguseA_Bogus; vecchi gist della community ruotano attorno alla firma degli URL e alla generazione di token. TikTok si aspetta sempre di più che le richieste arrivino con gli stessi "timbri" del traffico del suo browser/app. - CAPTCHA e flussi di verifica. L’esistenza di e di conferma che il CAPTCHA fa ancora parte della superficie anti-bot.
Perché i maintainer open source non riescono a starci dietro
Il ciclo è sempre lo stesso. Uno sviluppatore crea uno scraper TikTok. Diventa virale su GitHub. TikTok lo mette fuori gioco. Il maintainer lo sistema oppure passa ad altro.
Due repository illustrano perfettamente il pattern:
- drawrowfly/tiktok-scraper ha ancora 5.052 stelle e 889 fork, ma il suo . È lo scraper TikTok con la frase esatta più stellato su GitHub, e oggi sembra un reperto storico: alta visibilità, alta fiducia, nessuna manutenzione attuale.
- davidteather/TikTok-Api mostra . Il suo mostra manutenzione reale ad aprile 2025, luglio 2025, ottobre 2025 e aprile 2026 — inclusi fix per il crawling dei video utente e nuovi controlli proxy/sessione. Ma anche questo progetto più sano avverte apertamente che TikTok blocca le richieste e che gli utenti potrebbero aver bisogno di proxy, Playwright e logica di sessione personalizzata.
Il pattern è semplice:
- Un repository TikTok scraper obsoleto è probabilmente morto.
- Un repository TikTok scraper attivo è probabilmente ancora fragile.
- La vera differenza è solo se questo mese c’è ancora qualcuno disponibile a sistemare i problemi.
La checklist dei vitali del repository in 60 secondi: come valutare qualsiasi scraper TikTok su GitHub
Prima di clonare qualsiasi cosa, esegui questa checklist. Richiede meno di un minuto e ti fa risparmiare ore di frustrazione.
| Segnale | 🟢 Sano | 🟡 Rischioso | 🔴 Morto |
|---|---|---|---|
| Ultimo push significativo | Meno di 3 mesi fa | Da 3 a 12 mesi fa | Oltre 12 mesi fa |
| Numero di issue aperte | Basso, le issue recenti ricevono risposta | In aumento, con qualche attività del maintainer | Molte segnalazioni senza risposta su "rotto/bloccato/non funziona" |
| Reclami recenti degli utenti | Soprattutto domande di configurazione | Mix di problemi di setup e rotture | Ripetuti "zero output", "403", "funziona ancora?" |
| Modello attuale di auth/sessione | Percorso sessione/cookie documentato | Molto basato su token ma documentato | Si appoggia a vecchi endpoint web senza guida auth aggiornata |
| Superficie di installazione | Setup riproducibile e testato | Alcuni passaggi manuali | Vecchie dipendenze, nessuna nota sul setup moderno |
| CI/test | I test esistono e sono aggiornati | I test esistono ma la copertura non è chiara | Nessun test o action obsolete |
| Corrispondenza con il tuo ambito dati | Si allinea al tuo caso d’uso reale | Supporta solo una parte del caso d’uso | Risolve un problema del tutto diverso |
Come controllare ogni segnale in meno di 60 secondi
- Data dell’ultimo push: guarda l’header del repository su GitHub. Se dice "last pushed 2 years ago", puoi già chiuderlo.
- Issue aperte: clicca la scheda Issues. Scorri i titoli più recenti. Cerca
not working,403,blocked,captchaozero output. - Reclami degli utenti: se le prime 5 issue aperte sono tutte varianti di "non funziona più", hai già la risposta.
- Modello auth/sessione: apri il README. Cerca indicazioni aggiornate come
ms_token, configurazione Playwright o note sui proxy. Se il README cita endpoint del 2023, passa oltre. - Superficie di installazione: verifica se c’è un file requirements, supporto Docker o istruzioni chiare di setup. Se il README dice "npm install" e l’ultima versione di Node testata è la 14, aspettati problemi.
- CI/test: controlla la scheda Actions. Se i test falliscono o mancano, la rottura è solo un’ipotesi.
- Corrispondenza con i dati che ti servono: il repository descrive davvero i tipi di dati che ti servono (profili, metadati video, commenti, hashtag)? Molti repository fanno solo download video, non estrazione strutturata.
Campanelli d’allarme che significano "lascia perdere"
- Il repository è archiviato.
- Il README dice "no longer maintained".
- L’ultimo commit fa riferimento a una versione dell’API TikTok di oltre 2 anni fa.
- Le issue sono piene di segnalazioni "doesn't work" e il maintainer non risponde da mesi.
- Il repository ha molte stelle ma nessun fork recente o pull request.
Consiglio pratico: cerca nella scheda Issues is:issue is:open "not working" oppure is:issue is:open "403". Se i risultati sono numerosi e recenti, il repository è probabilmente rotto.
Repository GitHub popolari per scraper TikTok: verifica onesta dello stato (2026)
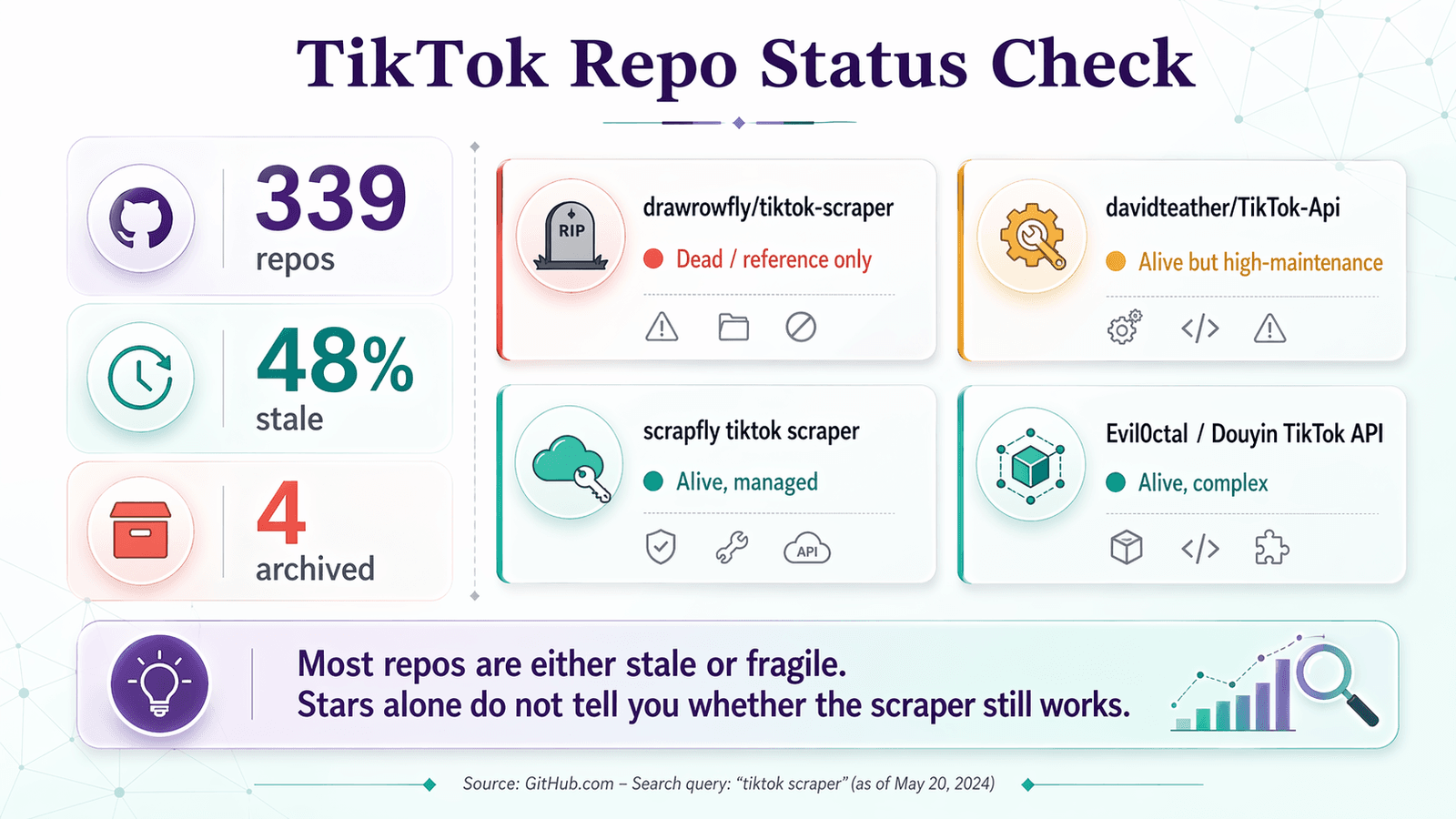
Ecco la checklist dei vitali del repository applicata ai repository che troverai davvero cercando "tiktok scraper" su GitHub:
| Repo | Ultimo push | Stelle | Issue aperte | Verdetto | Nota |
|---|---|---|---|---|---|
| drawrowfly/tiktok-scraper | 2023-05-19 | 5,052 | 58 | 🔴 Morto / solo come riferimento | Ancora famoso, ma troppo obsoleto per l'uso in produzione nel 2026 |
| davidteather/TikTok-Api | 2026-04-01 | 6,301 | 134 | 🟡 Vivo ma ad alta manutenzione | La scelta OSS più forte; richiede Playwright, token e spesso proxy |
| scrapfly/scrapfly-scrapers/tiktok-scraper | 2026-04-21 | 938 (parent) | ~0 (monorepo) | 🟡 Vivo, ma non puro OSS | Attuale e utile, ma richiede una chiave API ScrapFly |
| Evil0ctal/Douyin_TikTok_Download_API | 2025-10-12 | 17,397 | 135 | 🟡 Vivo, ampio, complesso | Progetto multi-piattaforma ricco di funzionalità; più vicino a una piattaforma per power user |
| naseif/tiktok-scraper | 2024-07-26 | 107 | 13 | 🟡 Rischioso | Repository più piccolo con reclami aperti su informazioni utente e flussi hashtag |
| loewehancara1rmyv/Tiktok-scraper | 2026-01-12 | 4 | 0 | 🔴 Troppo nuovo per fidarsi | Repository vetrina, non provato dalla community |
drawrowfly/tiktok-scraper
Per anni, questo scraper/downloader in TypeScript è stato la risposta predefinita a "tiktok scraper github" — gestendo feed di utenti, trend, hashtag e musica. Nel 2026 è meglio considerarlo documentazione storica. L', e la coda delle issue contiene ancora segnalazioni irrisolte di e dal 2023 al 2025. Se stai leggendo questo articolo perché hai clonato questo repository e non hai ottenuto nulla, sei in buona compagnia.
davidteather/TikTok-Api
Il wrapper open source più credibile per i dati TikTok ancora vivo nel 2026. È attivo, ha e documenta esplicitamente configurazione Playwright, uso asincrono, gestione dei token, supporto proxy e funzionalità di recupero sessione. Ma non è uno strumento "clona e via". Il suo stesso README dice che EmptyResponseException di solito significa che TikTok sta bloccando la richiesta, e la mostra problemi ricorrenti con ms_token, estrazione commenti rotta, KeyError: 'ItemModule' e fallimenti specifici per endpoint. Verdetto: vivo, utile, solo per sviluppatori e ad alta manutenzione.
Altri repository degni di nota
- : attuale e tecnicamente rilevante, ma il README richiede una
SCRAPFLY_KEY. È un esempio di codice per una piattaforma di scraping gestita, non uno strumento gratuito stand-alone. - : copre TikTok e Douyin, documenta la logica di firma (
X-Bogus,A_Bogus,msToken) e supporta commenti, follower, playlist e altro. È tecnicamente impegnativo e sempre più intrecciato con riferimenti ad API a pagamento. Il tracker delle issue mostra nel 2026 bug ancora aperti su link video ed endpoint delle informazioni utente. Vivo e ricco di funzionalità, ma complesso. - : più piccolo, con reclami aperti. Rischioso per l’uso in produzione.
- : 4 stelle, 0 issue, troppo nuovo per fidarsi. L’articolo Medium che lo promuoveva lo faceva in modo acritico.
TikTok API ufficiale vs scraper GitHub vs strumenti no-code: un framework decisionale

La maggior parte degli articoli della concorrenza ignora i percorsi di accesso ufficiali di TikTok oppure passa direttamente da "usa GitHub" a "compra il nostro servizio". Ecco un confronto neutrale dei tre percorsi:
| Fattore | TikTok Research API | Scraper GitHub | Strumenti no-code (es. Thunderbit) |
|---|---|---|---|
| Barriera di accesso | Richiesta accademica/business; ~4 settimane per l'approvazione | Clone Git + setup | Installazione estensione browser |
| Ambito dei dati | Solo endpoint approvati (account, video, commenti, shop) | Ampio (profili, video, commenti, hashtag, shop) | Dati visibili della pagina (profili, video, engagement, hashtag) |
| Carico di manutenzione | Basso (ufficiale, stabile) | Alto (i repo si rompono quando TikTok si aggiorna) | Nessuno (l'AI si adatta ai cambiamenti del layout) |
| Rischio anti-ban | Nessuno (autorizzato) | Alto | Basso (basato sul browser, imita un utente reale) |
| Costo | Gratis (se approvato) | Gratis (ma richiede tempo) | Piano gratuito disponibile; piani a credito da 15 $/mese |
| Coding richiesto | Sì (Python/R) | Sì (Python/Node.js) | No |
| Ideale per | Ricercatori, accademici, organizzazioni approvate | Sviluppatori a loro agio con la manutenzione | Marketer, team sales, operations, non sviluppatori |
Quando ha senso la TikTok Research API
La di TikTok è il percorso ufficiale più pulito se rientri nei requisiti. I ricercatori idonei negli possono candidarsi per studiare contenuti pubblici e dati degli account. Le categorie di dati disponibili includono account, follower/following, video piaciuti, video fissati, video ripubblicati, contenuti, commenti e shop.
Il espone campi come video_description, view_count, like_count, comment_count, share_count, e campi a livello di commento come text, reply_count e create_time.
Il rovescio della medaglia: l’idoneità è limitata a istituzioni accademiche e a ricercatori indipendenti o nonprofit idonei in regioni specifiche, oltre ai . Se sei un team growth o un’agenzia che ha bisogno rapidamente di dati operativi, questa non è la tua strada.
TikTok offre anche una per annunci e dati sui contenuti degli advertiser, utile per la ricerca sulla trasparenza ma non per lo scraping generico.
Quando ha ancora senso uno scraper GitHub
Gli scraper GitHub hanno ancora senso per gli sviluppatori che hanno bisogno di accesso non ufficiale a dati pubblici oltre il gate di approvazione dell’API ufficiale e sono disposti a mantenere lo stack. Questo include casi d’uso come lo scraping di griglie profilo visibili, hashtag, commenti, playlist o metadati video in una pipeline personalizzata in cui fare fork del repository e applicare patch è accettabile.
La nota onesta: non è una configurazione una tantum. Anche il repository più affidabile del 2026, , dice ancora agli utenti che potrebbero servire Playwright, cookie/token, proxy e factory personalizzate per pagine/sessioni.
Quando ha senso uno strumento no-code come Thunderbit
Non sei uno sviluppatore? O sei uno sviluppatore stanco del ciclo di rottura e correzione? Uno strumento AI basato sul browser è il modo più veloce per ottenere dati TikTok strutturati.
Abbiamo creato come uno scraper web AI che funziona come estensione Chrome. Su TikTok legge qualsiasi pagina visibile (profilo, video, hashtag, risultati di ricerca), suggerisce colonne tramite "AI Suggest Fields" e ti permette di fare clic su "Scrape" per estrarre dati strutturati. La documenta campi come data di pubblicazione, durata del video, like, condivisioni, salvataggi, commenti, visualizzazioni e hashtag. Il mostra come raccogliere miniature dei post, URL, didascalie, handle dei creator e segnali di engagement dalle pagine profilo. Il copre URL del video, username del creator, descrizione, orario di pubblicazione, visualizzazioni, like, commenti, condivisioni, audio/sound e URL dell’immagine di copertina.
Lo scraping delle sottopagine ti consente di visitare ogni pagina video da un elenco profilo e arricchire la tabella con metriche di engagement, didascalie e hashtag — utile per i marketer che costruiscono database di influencer o fanno audit dei contenuti dei competitor.
Nessuna manutenzione, nessuna risoluzione dei problemi di installazione, nessuna configurazione anti-ban. L’AI si adatta automaticamente ai cambiamenti del layout. L’esportazione è gratuita verso Google Sheets, Excel, Airtable, Notion, CSV o JSON.
Se hai perso ore su repository GitHub rotti, questa è un’alternativa legittima — non una forzatura commerciale.
Risoluzione problemi di installazione: come correggere i 5 errori più comuni nel setup degli scraper TikTok su GitHub
I problemi di installazione sono il terzo punto dolente più citato nei forum sullo scraping TikTok, e nessuna guida importante aiuta davvero a risolverli. Ecco cosa va storto.
Conflitti con la versione di Node.js
Problema: molti repository più vecchi di TikTok scraper (soprattutto drawrowfly/tiktok-scraper) erano costruiti per Node.js 14–16. Se usi Node 20+, npm install può fallire in silenzio o produrre binari incompatibili.
Soluzione: usa nvm (Node Version Manager) per installare e passare alla versione corretta:
1nvm install 16
2nvm use 16
3npm installSe il repository non specifica una versione di Node, controlla il campo engines in package.json oppure guarda la configurazione CI.
Problemi con le dipendenze Python e configurazione Playwright
Problema: richiede e Playwright con binari del browser specifici. Gli utenti ricevono errori come "browser not found" o conflitti tra dipendenze.
Soluzione: usa sempre un ambiente virtuale e poi installa esplicitamente i browser di Playwright:
1python -m venv .venv
2source .venv/bin/activate # Su Windows: .venv\Scripts\activate
3pip install TikTokApi
4python -m playwright installSe playwright install fallisce, controlla nel package manager di sistema eventuali dipendenze mancanti (per esempio libnss3 su Ubuntu).
Errori di permessi su Linux/Ubuntu
Problema: eseguire sudo pip install corrompe l’ambiente Python di sistema e provoca problemi a cascata con le dipendenze.
Soluzione: non usare mai sudo pip install. Crea sempre prima un ambiente virtuale:
1python3 -m venv .venv
2source .venv/bin/activate
3pip install -r requirements.txtIn questo modo le dipendenze dello scraper restano isolate dal Python di sistema.
Problemi di percorso e codifica su Windows
Problema: il CMD di Windows ha problemi di codifica e limiti sulla lunghezza dei percorsi che rompono le installazioni degli scraper, soprattutto quando Playwright scarica i binari del browser in directory molto profonde.
Soluzione: usa WSL (Windows Subsystem for Linux) o Git Bash invece del CMD. WSL ti dà un ambiente Linux completo dentro Windows:
1wsl --install
2# Poi apri un terminale WSL e segui i passaggi di setup LinuxLa scorciatoia Docker: salta del tutto i problemi di dipendenze
Problema: tutto quanto sopra.
Soluzione: se ti senti a tuo agio con Docker, containerizza l’ambiente dello scraper. Un Dockerfile base per uno scraper TikTok basato su Python ha questo aspetto:
1FROM python:3.11-slim
2RUN apt-get update && apt-get install -y libnss3 libatk-bridge2.0-0 libdrm2 libxcomposite1 libxdamage1 libxrandr2 libgbm1 libasound2
3RUN pip install TikTokApi playwright && python -m playwright install --with-deps chromium
4WORKDIR /app
5COPY . .
6CMD ["python", "scrape.py"]Questo garantisce un ambiente riproducibile indipendentemente dal sistema operativo host. Se lo scraper funziona in Docker, qualsiasi errore fuori da Docker è un problema di ambiente, non di codice.
Flusso di troubleshooting:
- Il repository riesce a eseguire con successo il proprio esempio? → Se no, controlla la versione runtime.
- La versione runtime è corretta? → Controlla l’installazione di browser/Playwright.
- Il browser è installato? → Controlla token/cookie.
- Token/cookie validi? → Controlla se TikTok sta bloccando la sessione.
- Falliscono tutti i controlli precedenti? → Considera rotto il repository, non l’errore dell’utente. Cambia strumento.
Migliori pratiche anti-ban per lo scraping TikTok (senza pagare proxy)
Gli utenti dei forum si lamentano continuamente di ban e rilevamento: "ti fanno bannare gli account, che è una spesa aggiuntiva" e "senza usare Apify o costose API a pagamento". Ecco workaround gratuiti e pratici che non richiedono un abbonamento proxy a pagamento.

| Pratica | Difficoltà | Costo | Efficacia |
|---|---|---|---|
| Ritardi casuali tra le richieste (jitter 2–8s) | Facile | Gratis | Moderata |
| Rotazione di sessione/cookie | Media | Gratis | Moderata |
| Scraping solo di pagine pubbliche senza login | Facile | Gratis | Moderata |
Rispetto di robots.txt + header di rate limit | Facile | Gratis | Base |
| Randomizzazione del fingerprint del browser headless (Playwright) | Media | Gratis | Alta |
| Uso degli endpoint API mobile di TikTok (meno rilevamento) | Difficile | Gratis | Alta |
| Rotazione di proxy residenziali | Media | 20–100 $/mese | Alta |
Tecniche gratuite che aiutano davvero
Ritardi casuali nelle richieste. Non inviare richieste in un loop serrato. Aggiungi un jitter casuale di 2–8 secondi tra una richiesta e l’altra. È la cosa più semplice che puoi fare:
1import time, random
2time.sleep(random.uniform(2, 8))Riutilizzo di sessione e cookie. Non creare una sessione nuova di zecca per ogni richiesta. Riutilizza cookie e stato di sessione su un gruppo di richieste, poi ruota. È esattamente il motivo per cui i repository moderni chiedono ms_token invece di promettere uno scraping stateless.
Scraping solo di pagine pubbliche senza login. di non supportare rotte con autenticazione utente e di funzionare solo sui dati visibili quando si è disconnessi. Lo scraping senza login ha un profilo di rilevamento più basso rispetto alle sessioni autenticate.
Rispetta robots.txt. Il blocca del tutto molti agent e consente solo un insieme limitato di percorsi pubblici per il crawling generale. Non è un via libera per uno scraping aggressivo, ma rispettarlo riduce la probabilità di un blacklisting immediato dell’IP.
Tecniche intermedie per tassi di successo più alti
Randomizzazione del fingerprint del browser headless. Se usi Playwright, randomizza la dimensione del viewport, la stringa user-agent, il fuso orario e la locale per ogni sessione. Così lo scraper sembra ogni volta un utente reale diverso, invece dello stesso bot con un IP fresco.
Uso degli endpoint API mobile di TikTok. Alcuni membri della community segnalano tassi di rilevamento più bassi quando puntano a endpoint in stile mobile invece che al frontend web. È più difficile da implementare e meno documentato, ma è una tecnica reale per utenti avanzati.
Quando ti serve davvero un proxy (e opzioni economiche)
Su larga scala, le tecniche gratuite non bastano. La rotazione di proxy residenziali è l’approccio standard per lo scraping TikTok ad alto volume. Qui non consiglierò un servizio proxy specifico a pagamento, ma il consiglio generale è: evita i proxy datacenter (TikTok li segnala in modo aggressivo) e cerca pool di proxy residenziali o mobile con rotazione per richiesta.
In alternativa, strumenti browser-based come aggirano del tutto la questione proxy perché girano nella tua sessione browser, mimando un utente reale. Questo non li rende immuni al rilevamento su larga scala, ma per i casi d’uso tipici di marketing o ricerca (da decine a centinaia di pagine, non milioni) è una strada molto più semplice.
Quali dati ottieni davvero? Esempi reali di output dagli scraper TikTok
Gli utenti vogliono sapere quali dati otterranno davvero prima di impegnarsi con uno strumento — e la maggior parte delle guide salta del tutto questo aspetto. Ecco strutture di campi rappresentative, basate sulla documentazione sorgente.
Dati profilo
| Username | Nome visualizzato | Follower | Seguiti | Like totali | Bio | Verificato | URL profilo |
|---|---|---|---|---|---|---|---|
| @examplecreator | Jane Doe | 1.240.000 | 312 | 48.700.000 | "Cucina + comicità 🍳" | ✅ | tiktok.com/@examplecreator |
| @travelwithmark | Mark S. | 890.000 | 150 | 22.100.000 | "Travel vlogger 🌍" | ❌ | tiktok.com/@travelwithmark |
| @fitnessmaya | Maya L. | 2.100.000 | 88 | 91.300.000 | "Allenamenti e benessere" | ✅ | tiktok.com/@fitnessmaya |
Disponibile da: scraper GitHub (TikTok-Api, Evil0ctal), Research API, Thunderbit (dalle pagine profilo visibili).
Metadati video
| URL video | Didascalia | Visualizzazioni | Like | Commenti | Condivisioni | Musica | Hashtag | Data pubblicazione | Durata |
|---|---|---|---|---|---|---|---|---|---|
| tiktok.com/@ex/video/123 | "Il miglior trucco per la pasta di sempre 🍝" | 4.200.000 | 312.000 | 8.400 | 21.000 | "Italian Vibes – DJ Marco" | #pasta #cooking #hack | 2026-03-15 | 0:42 |
| tiktok.com/@ex/video/456 | "POV: il tuo gatto ti giudica" | 9.100.000 | 1.100.000 | 23.000 | 55.000 | "Original Sound" | #cat #pov #funny | 2026-04-01 | 0:18 |
| tiktok.com/@ex/video/789 | "Routine del mattino che nessuno ha chiesto" | 1.800.000 | 98.000 | 3.200 | 7.500 | "Chill Morning – LoFi" | #routine #morning | 2026-04-10 | 1:02 |
Disponibile da: scraper GitHub (TikTok-Api, Evil0ctal), (i campi includono video_description, view_count, like_count, comment_count, share_count, music_id, hashtag_names, video_duration), Thunderbit ().
Dati commenti
| Autore commento | Testo commento | Like | Timestamp | Risposte |
|---|---|---|---|---|
| @user_abc | "Ho provato e funziona davvero 😂" | 1.200 | 2026-03-16T08:12:00Z | 14 |
| @chef_dan | "Aggiungi l'aglio la prossima volta, fidati" | 890 | 2026-03-16T09:45:00Z | 7 |
| @randomfan99 | "Questo è il contenuto che cercavo" | 340 | 2026-03-16T11:30:00Z | 2 |
Disponibile da: scraper GitHub (TikTok-Api, Evil0ctal), (i campi includono text, like_count, reply_count, create_time), Thunderbit (dalle sezioni commenti visibili).
Dati hashtag e ricerca
| Hashtag | URL del video top | Visualizzazioni aggregate | In tendenza |
|---|---|---|---|
| #pasta | tiktok.com/@ex/video/123 | 4.200.000 | Sì |
| #cooking | tiktok.com/@chef/video/321 | 11.000.000 | Sì |
| #hack | tiktok.com/@tips/video/654 | 2.900.000 | No |
Disponibile da: scraper GitHub (varia in base al repo), Thunderbit ().
Nota: nessun repository garantisce tutti i campi, sempre. Le strutture di risposta di TikTok cambiano, e persino i maintainer lo avvertono. Considerali esempi rappresentativi, non garanzie.
Come estrarre dati TikTok in 2 clic con Thunderbit (passo dopo passo)
Stanco del ciclo di rottura e correzione? Ecco il percorso no-code — la via d’uscita per chi ha provato e fallito con i repository GitHub.
- Installa la .
- Vai alla pagina TikTok che vuoi estrarre — un profilo, una pagina di risultati di ricerca, una pagina hashtag o un singolo video.
- Fai clic su "AI Suggest Fields." L’AI di Thunderbit legge la pagina e suggerisce colonne: username, follower, didascalia video, like, hashtag, ecc.
- Regola i campi se necessario, poi fai clic su "Scrape." I dati vengono popolati in una tabella strutturata.
- Usa lo Scraping delle sottopagine per arricchire i dati. Apri ogni video dalla lista profilo e recupera campi aggiuntivi: didascalia completa, dettagli della musica, numero di commenti, numero di condivisioni.
- Esporta in Google Sheets, Excel, Airtable o Notion — completamente gratis.
Nessuna manutenzione, nessuna risoluzione dei problemi di installazione, nessuna configurazione anti-ban. L’AI si adatta automaticamente ai cambiamenti del layout di TikTok.
Arricchire i dati TikTok con lo scraping delle sottopagine
Dopo aver estratto un elenco di video da un profilo o da una pagina hashtag, fai clic su "Scrape Subpages" per far sì che l’AI visiti ogni pagina video e recuperi campi aggiuntivi. È particolarmente utile per i marketer che costruiscono database di influencer o fanno audit dei contenuti dei competitor: ottieni una tabella completa dei dati di engagement a livello video senza dover cliccare manualmente decine di pagine.
Esportare e usare i dati TikTok
Thunderbit esporta in Google Sheets, Excel, Airtable, Notion, CSV o JSON — tutto gratis. Casi d’uso comuni:
- Inserire i dati in un foglio di calcolo per l’analisi dell’engagement.
- Inviarli ad Airtable per un tracker influencer in stile CRM.
- Portarli in Notion per collaborare in team sulla ricerca dei contenuti.
Per uno sguardo più approfondito su come Thunderbit gestisce l’estrazione di dati web, dai un’occhiata alla nostra oppure guarda i tutorial sul .
Rimanere legali: Termini di servizio di TikTok e conformità allo scraping
La posizione legale di TikTok è chiara. Il della piattaforma afferma che i Termini di servizio vietano script automatizzati che raccolgono informazioni o interagiscono con il servizio in modi non autorizzati, e cita esplicitamente il superamento delle restrizioni di accesso. Anche le di TikTok vietano tentativi ingannevoli di ottenere informazioni tramite script automatizzati o web crawling.
Indicazioni pratiche:
- Attieniti ai dati pubblicamente disponibili. Non estrarre contenuti privati o protetti da login.
- Rispetta i rate limit. Non martellare i server di TikTok.
- Conformati alle leggi sulla privacy dei dati. GDPR e CCPA si applicano ancora se raccogli, conservi o analizzi dati personali.
- Usa la Research API quando ne hai diritto. È il percorso più sicuro dal punto di vista della conformità.
- Questo non è un consiglio legale. Consulta un professionista per il tuo caso specifico.
Per approfondire il quadro legale, vedi la nostra guida sulle .
Cosa fare quando il tuo repository GitHub per TikTok scraper muore
In breve:
- Esegui sempre la checklist dei vitali del repository in 60 secondi prima di clonare qualsiasi scraper TikTok da GitHub. La maggior parte dei repository è già morta.
- Capisci le tue opzioni. API ufficiale, scraper GitHub e strumenti no-code servono utenti e casi d’uso diversi.
- Se scegli la strada GitHub, metti in conto tempo per risolvere i problemi di installazione e configurare l’anti-ban. Aspettati manutenzione continua.
- Sappi quali dati otterrai davvero prima di impegnarti con uno strumento. Controlla i campi di output, non solo il numero di stelle.
- Se non sei uno sviluppatore (o sei stanco di repository rotti), prova uno strumento no-code come — due clic, dati strutturati, export gratuito.
I dati TikTok di cui hai bisogno sono accessibili. La vera domanda è se vuoi spendere il tuo tempo a mantenere uno scraper o a usare davvero quei dati. Scegli l’approccio che si adatta al tuo livello di competenza e al tuo caso d’uso, e non lasciare che un repository GitHub morto ti faccia perdere un altro pomeriggio.
FAQ
Esistono scraper TikTok su GitHub che funzionano ancora nel 2026?
Sì, ma la lista è breve. è l’opzione open source più credibile con manutenzione attiva ad aprile 2026. è anch’esso vivo ma più complesso. Il repository con più stelle, drawrowfly/tiktok-scraper, non viene aggiornato da maggio 2023 ed è di fatto morto. Esegui sempre la checklist dei vitali del repository prima di investire tempo in qualsiasi repo.
È legale fare scraping di TikTok?
I Termini di servizio di TikTok vietano esplicitamente lo scraping automatizzato. I dati visibili pubblicamente si trovano in una zona grigia legale che varia a seconda della giurisdizione. Il percorso più sicuro è l' ufficiale per i ricercatori idonei. Se fai scraping di dati pubblici, attieniti ai contenuti accessibili pubblicamente, rispetta i rate limit e conformati a GDPR/CCPA. Questo non è un consiglio legale — consulta un professionista per il tuo caso.
Posso fare scraping di TikTok senza programmare?
Sì. Strumenti AI basati sul browser come ti permettono di estrarre dati TikTok strutturati (profili, metadati video, hashtag, metriche di engagement) senza scrivere codice. Anche la TikTok Research API richiede una quantità minima di coding per i richiedenti approvati. Per chi non sviluppa, gli strumenti no-code sono il percorso più veloce e affidabile.
Quali dati posso ottenere da uno scraper TikTok?
I tipi di dati più comuni includono informazioni profilo (username, follower, bio, stato di verifica), metadati video (didascalia, visualizzazioni, like, commenti, condivisioni, musica, hashtag, durata, data di pubblicazione), commenti (testo, like, timestamp, risposte) e dati hashtag/ricerca (video top, visualizzazioni aggregate, stato di tendenza). I campi esatti dipendono dallo strumento e dal metodo — vedi la sezione degli esempi di output qui sopra per i dettagli.
Perché il mio scraper TikTok continua a essere bloccato?
TikTok usa più livelli di difesa anti-bot: rate limiting, blocco basato su cookie/sessione, browser fingerprinting, rilevamento comportamentale, parametri di richiesta cifrati e flussi CAPTCHA. Le cause più comuni del blocco includono l’invio troppo rapido di richieste, l’uso di una sessione pulita/nuova per ogni richiesta, l’esecuzione di un browser headless con fingerprint predefiniti o l’uso di proxy datacenter. Vedi la sezione sulle migliori pratiche anti-ban qui sopra per workaround gratuiti e a pagamento.