Lo scraping web è illegale? È la domanda da un milione di dollari che sento ogni settimana da founder, marketer e appassionati di dati.
Con il —la prima volta in cui il traffico automatizzato ha superato l’attività umana—e con una grossa fetta di questo traffico dedicata allo scraping web per business intelligence, vendite e training dell’AI, non c’è da stupirsi che tutti cerchino di capire dove siano tracciati i confini legali.
Un giorno leggi un titolo su una sentenza che dichiara lecito lo scraping dei dati pubblici. Il giorno dopo, i regolatori avvertono contro la raccolta “illecita” di dati dai social media. È un quadro confuso, anche per chi, come me, passa le giornate a costruire strumenti di AI Web Scraper in .
Quindi, lo scraping web è illegale? La risposta non è un semplice sì o no. Dipende da cosa stai raccogliendo, da dove lo raccogli, da come usi i dati e da cosa prevede la legge nel tuo Paese.
In questa analisi approfondita, farò chiarezza sul panorama legale, sfaterò alcuni miti comuni e condividerò consigli pratici (più qualche storia di guerra) per restare conformi, che tu sia un founder indipendente o un team dati di una Fortune 500.
Web Scraping e legge: esiste un confine chiaro?
Se speri in una risposta in una sola frase, ti faccio risparmiare tempo: la legge non ha tracciato una linea netta e inequivocabile sullo scraping web.
Al suo posto c’è un mosaico di regole che si sovrappongono: proprietà dei dati, privacy, proprietà intellettuale, norme anti-hacking e quei famigerati Termini di servizio (ToS). Ciascuno può entrare in gioco, e la risposta dipende spesso dal tuo caso specifico ().
Vediamo le tre grandi aree legali:
- Proprietà dei dati: in generale, fatti e informazioni pubbliche (come prezzi o numeri di telefono) non sono protetti da copyright. Ma contenuti creativi (articoli, immagini) e database proprietari possono esserlo, soprattutto nell’UE, dove esistono i “database rights” ().
- Privacy: le moderne leggi sulla privacy (pensa al GDPR in Europa e al PIPL in Cina) trattano i dati personali come un bene regolamentato, anche se sono stati pubblicati apertamente. Raccogliere nomi, email o profili social senza una base giuridica può metterti nei guai ().
- Contratti (Termini di servizio): molti siti vietano esplicitamente lo scraping nei ToS. Anche se i ToS non sono leggi, i tribunali possono considerarli contratti vincolanti. Violandoli rischi cause legali e, in alcuni casi, perfino l’applicazione di norme anti-hacking se aggiri blocchi tecnici ().
Quindi, lo scraping web è illegale? A volte sì, a volte no, e spesso “dipende”. Il diavolo è nei dettagli.
Confronto dei punti di vista legali: USA, UE, Regno Unito, Cina
Ecco una tabella rapida per mostrare come le principali regioni affrontano lo scraping web:
| Regione | Scraping di dati pubblici | Scraping di dati personali/privati | Applicazione e punti rilevanti |
|---|---|---|---|
| USA | In genere consentito per dati pubblici (vedi hiQ v. LinkedIn). Violare i ToS può portare a cause civili. | Limitato/illegale se violi login o usi impropriamente dati personali. Possono applicarsi leggi statali come il CCPA. | Lettere di diffida, blocco IP, cause legali. Il CFAA si applica se aggiri barriere tecniche. |
| UE | Consentito con condizioni per dati pubblici non personali. Possono applicarsi i diritti sui database. L’EU AI Act (2026) aggiunge obblighi di trasparenza per i dati di training dell’AI. | Fortemente regolato dal GDPR: anche i dati personali pubblici richiedono una base giuridica. | Le Autorità per la protezione dei dati possono multare per violazioni della privacy. Si applicano anche copyright e diritti sui database. L’EU AI Act vieta lo scraping di immagini facciali per l’AI. |
| Regno Unito | Simile all’UE. I dati pubblici non personali possono essere sottoposti a scraping, ma bisogna rispettare diritti sui dati e contratti. | Molto severo sui dati personali: si applica il GDPR britannico. Il Computer Misuse Act criminalizza l’accesso non autorizzato. | L’ICO può sanzionare le violazioni della protezione dei dati. I tribunali possono far rispettare i ToS. |
| Cina | Fortemente controllato. I dati pubblici non personali possono essere raccolti per uso interno, ma l’ambiente è prudente. | Molto limitato: il PIPL richiede il consenso per i dati personali. Si applicano le norme contro la concorrenza sleale. | Casi penali per scraping su larga scala. I tribunali usano il diritto della concorrenza sleale per fermare lo scraping non autorizzato. |
(, )
Lo scraping web è illegale? I fattori legali chiave da considerare
Quindi, cosa determina davvero se il tuo progetto di scraping è legale o rischioso? Ecco i fattori principali:
- Dati pubblici vs. privati: raccogliere dati che chiunque può vedere sul web aperto è in genere più sicuro. Raccogliere dati dietro login, paywall o barriere tecniche? Probabilmente è illegale ().
- Natura dei dati: i dati personali (nomi, email, profili) attivano le leggi sulla privacy. I contenuti protetti da copyright (articoli, immagini) non possono essere copiati integralmente. I fatti puri (prezzi, meteo) sono di solito utilizzabili ().
- Uso previsto: l’analisi interna o la ricerca sono viste con maggiore tolleranza rispetto alla ripubblicazione o alla vendita dei dati estratti. Usare dati raccolti tramite scraping per competere direttamente con la fonte? È un contenzioso praticamente assicurato ().
- Conformità alle regole del sito: controlla sempre robots.txt e i ToS. Robots.txt non è vincolante dal punto di vista legale, ma rispettarlo è la best practice. Violare i ToS può significare cause civili o peggio ().
- Misure tecniche: è fondamentale procedere a velocità simili a quelle umane e non aggirare le misure di sicurezza. Martellare un server o eludere i CAPTCHA può sconfinare nell’hacking ().
Cosa è cambiato nel 2024–2026: casi giudiziari e norme chiave
Il panorama legale dello scraping web è cambiato in modo drastico dal 2023. Ecco gli sviluppi che ogni scraper dovrebbe conoscere:
Sentenze importanti
-
Meta v. Bright Data (2024): un tribunale federale statunitense . Il giudice ha ritenuto che “un visitatore non è considerato un ‘utente’ se non ha un account”. Poco dopo Meta ha ritirato le altre richieste. È una vittoria storica per lo scraping dei dati pubblici.
-
X Corp v. Bright Data (2024): Twitter (oggi X) ha perso una causa simile, rafforzando lo stesso principio: scrapare dati accessibili pubblicamente senza fare login non viola i ToS, perché lo scraper non ha mai accettato quei termini.
-
Reddit v. Perplexity AI (ottobre 2025): Reddit , invocando il DMCA e accusando l’elusione dei sistemi anti-bot. Questo segnala una nuova strategia legale: le piattaforme si stanno orientando verso copyright e violazione delle norme anti-elusione invece che sul CFAA.
-
NYT v. OpenAI (marzo 2025): un giudice federale , respingendo la mozione di archiviazione di OpenAI. Questo potrebbe creare un precedente importante su se lo scraping di contenuti per addestrare modelli AI rientri nel “fair use”.
-
Accordo Anthropic (settembre 2025): Anthropic ha accettato di pagare 1,5 miliardi di dollari per chiudere una class action statunitense sul copyright relativa all’uso di testi protetti per addestrare il proprio modello AI, segnalando che i costi dello scraping per l’AI sono molto reali.
Il grande trend: dal CFAA al diritto contrattuale e al copyright
Il quadro è chiaro: il CFAA (Computer Fraud and Abuse Act) sta perdendo efficacia come arma contro chi fa scraping di dati pubblici. Le aziende che hanno provato a usarlo contro lo scraping di dati pubblici—Meta, X, LinkedIn—hanno in gran parte fallito. Il terreno di scontro legale si sta invece spostando su:
- diritto contrattuale (violazioni dei ToS, ma i tribunali stanno dicendo che i non-utenti non sono vincolati dai ToS)
- azioni per copyright (soprattutto per i dati di training dell’AI)
- norme anti-elusione (DMCA Section 1201)
Per chi fa scraping, questo significa che il rischio legale non è scomparso: si è solo spostato.
Cambiamenti normativi
- Aggiornamenti CCPA 2026: le normative CCPA della California riviste , aggiungendo nuove regole per le tecnologie di decisione automatizzata (ADMT), le valutazioni del rischio e gli obblighi dei data broker.
- Nuove leggi statali sulla privacy negli USA: Indiana, Kentucky e Rhode Island hanno approvato leggi organiche sulla privacy entrate in vigore nel 2026.
- EU AI Act: l’applicazione completa inizia e richiede agli sviluppatori di AI di divulgare le fonti dei dati di training, rispettare le esclusioni del copyright e vieta lo scraping di immagini facciali per i sistemi AI.
- AI Accountability for Publishers Act (febbraio 2026): una proposta di legge statunitense che richiederebbe alle aziende AI di ottenere autorizzazione e pagare gli editori prima di fare scraping dei loro contenuti.
Politiche di scraping delle principali piattaforme: cosa devi sapere
Non tutti i siti trattano lo scraping allo stesso modo. Ecco una panoramica piattaforma per piattaforma di ciò che i siti maggiori consentono, bloccano e su cui i tribunali si sono espressi:
| Piattaforma | ToS sullo scraping | Difese tecniche | Applicazione legale | Cosa è praticamente sicuro |
|---|---|---|---|---|
| Google (Search e Maps) | Vieta l’accesso automatizzato nei ToS. La Maps Platform ha una clausola esplicita “No Scraping”. | Sfide SearchGuard JS, CAPTCHA, rate limiting. Robots.txt aggiornato nel 2025 per bloccare i crawler AI. | Ha citato in giudizio gli scraper nel dicembre 2025 usando il DMCA. Blocca attivamente i crawler AI (Anthropic, Meta, OpenAI). | Lo scraping dei dati pubblici di Google Maps relativi alle attività commerciali è difendibile dal punto di vista legale (precedente hiQ), ma aspettati blocchi tecnici. Usa le API ufficiali quando possibile. |
| Amazon | Vieta esplicitamente ogni scraping nelle Condizioni d’uso (“nessun robot, spider, scraper o altro mezzo automatizzato”). | Rilevamento aggressivo dei bot, CAPTCHA, blocco IP. robots.txt blocca tutti i bot tranne Googlebot/Bingbot. Dal 2025 blocca esplicitamente i crawler AI. | Ha citato in giudizio Perplexity AI nel novembre 2025. Invia regolarmente lettere di diffida. Ha aggiornato il BSA nel marzo 2026 con regole per gli agenti AI. | I dati pubblici dei prodotti (prezzi, inserzioni) sono fattuali e possono essere raccolti secondo la legge statunitense, ma Amazon reagisce con forza. Limita le richieste ed evita i dati personali. |
| Vietato lo scraping nei ToS; per accedere ai servizi è richiesto l’accordo dell’utente. | Login wall per la maggior parte dei dati dei profili, rilevamento anti-bot, rate limiting. | Il caso hiQ ha confermato che lo scraping dei profili pubblici non viola il CFAA, ma LinkedIn ha vinto sulle rivendicazioni contrattuali/concorrenza sleale quando sono stati usati account falsi. | I profili pubblici (visibili senza login) sono legalmente difendibili da raccogliere. Non creare mai account falsi e non fare scraping di dati dietro login. | |
| Meta (Facebook e Instagram) | I ToS vietano lo scraping; regole separate per i dati con login e senza login. | Login wall per la maggior parte dei contenuti, rilevamento avanzato dei bot. | Ha perso contro Bright Data nel 2024: il tribunale ha stabilito che i ToS non si applicano agli scraper non autenticati. Ha ritirato le altre richieste. | I dati pubblici (pagine aziendali, post pubblici) visibili senza login sono in una posizione più sicura. Non fare mai scraping di profili privati o dati dietro login. |
| X (Twitter) | Ha aggiornato i ToS nel 2023 per vietare ogni scraping e crawling senza consenso scritto. Ha eliminato la vecchia eccezione robots.txt. | Robots.txt blocca tutti i crawler (Disallow: /). Sfide Cloudflare Turnstile. Limiti di richiesta molto rigidi (300 req/ora). Scoring della reputazione IP. | Ha perso contro Bright Data sui dati pubblici, ma limita in modo aggressivo l’accesso tecnico. | Tweet e profili pubblici sono legalmente difendibili, ma le barriere tecniche di X sono tra le più dure del 2026. Aspettati blocchi senza un’infrastruttura proxy premium. |
In sintesi: i tribunali hanno stabilito con coerenza che raccogliere dati visibili pubblicamente senza fare login non viola il CFAA. Ma le piattaforme possono comunque perseguirti sul piano contrattuale, del copyright o dell’anti-elusione—e ti renderanno la vita difficile con barriere tecniche. Fai sempre scraping in modo responsabile.
Dati di training per l’AI e web scraping: la nuova frontiera legale
Se segui le notizie nel 2026, sai che lo scraping di dati per addestrare modelli AI è diventato il campo di battaglia legale più caldo. Ecco cosa sta succedendo:
- Le cause per copyright si stanno moltiplicando. Il New York Times, autori ed editori hanno citato in giudizio OpenAI, Anthropic e altri, sostenendo che lo scraping massivo di contenuti protetti per addestrare gli LLM non rientra nel “fair use”. Anthropic ha chiuso una grande class action nel 2025 per 1,5 miliardi di dollari, segnalando che i costi dello scraping per l’AI sono molto concreti.
- La difesa del “fair use” è fragile. I tribunali statunitensi non hanno ancora emesso una decisione definitiva su se addestrare l’AI con dati raccolti via scraping sia fair use. Le prime decisioni suggeriscono che dipende molto da come i dati sono stati ottenuti e da cosa viene fatto con l’output dell’AI.
- Nuova legislazione in arrivo. L’ (presentato nel febbraio 2026) mira a imporre alle aziende AI di ottenere autorizzazione e pagare gli editori prima di fare scraping dei loro contenuti.
- L’EU AI Act (applicazione completa ) richiede agli sviluppatori di AI di divulgare le fonti dei dati di training, rispettare le esclusioni del copyright leggibili dalle macchine (nell’ambito dell’eccezione TDM della Direttiva sul copyright) e etichettare i contenuti generati dall’AI. Vieta anche i sistemi AI che fanno scraping di immagini facciali da internet.
- I crawler AI/LLM stanno esplodendo. I crawler AI hanno quadruplicato la loro quota di traffico web, passando dal 2,6% al 10,1% in soli otto mesi. Solo GPTBot di OpenAI è cresciuto del 305%. In risposta, grandi siti (Amazon, Reddit, NYT) stanno aggiornando robots.txt per bloccare esplicitamente i crawler AI.
Cosa significa per te: se fai scraping per scopi aziendali tradizionali (lead generation, monitoraggio prezzi, ricerche di mercato), queste regole specifiche per l’AI potrebbero non applicarsi direttamente. Ma se inserisci i dati raccolti in modelli AI, muoviti con estrema cautela e chiedi consulenza legale.
Leggi sullo scraping web nel mondo: confronto rapido
Facciamo un passo indietro e vediamo come le regole cambiano a livello globale:
- Stati Uniti: nessun divieto generale. Lo scraping di siti pubblicamente accessibili è in genere lecito (), e le sentenze Meta e X Corp del 2024 hanno rafforzato ulteriormente il caso dello scraping dei dati pubblici. Ma lo scraping dietro login o barriere tecniche può ancora far scattare il CFAA. Ora la tendenza è che le aziende usino invece il diritto contrattuale e le rivendicazioni di copyright. Le leggi sulla privacy si stanno espandendo rapidamente: il CCPA ha ricevuto aggiornamenti importanti entrati in vigore il 1° gennaio 2026, con nuove regole per la decisione automatizzata e gli obblighi dei data broker. Indiana, Kentucky e Rhode Island hanno inoltre approvato leggi organiche sulla privacy nel 2026.
- Unione Europea: leggi sulla privacy molto severe. Il GDPR si applica anche ai dati personali pubblici. I diritti sui database possono bloccare lo scraping su larga scala di dati strutturati (). NOVITÀ: l’ entra in piena applicazione il 2 agosto 2026, richiedendo agli sviluppatori AI di divulgare le fonti dei dati di training e rispettare le esclusioni del copyright. L’atto vieta lo scraping di immagini facciali da internet per i sistemi AI.
- Regno Unito: segue le regole UE dopo la Brexit. I dati pubblici possono essere raccolti, ma lo scraping di informazioni personali è strettamente regolato. Il Computer Misuse Act può criminalizzare l’accesso non autorizzato.
- Cina: molto restrittiva. Il PIPL e il Data Security Law richiedono il consenso per i dati personali. I tribunali usano il diritto della concorrenza sleale per bloccare lo scraping che danneggia le aziende ().
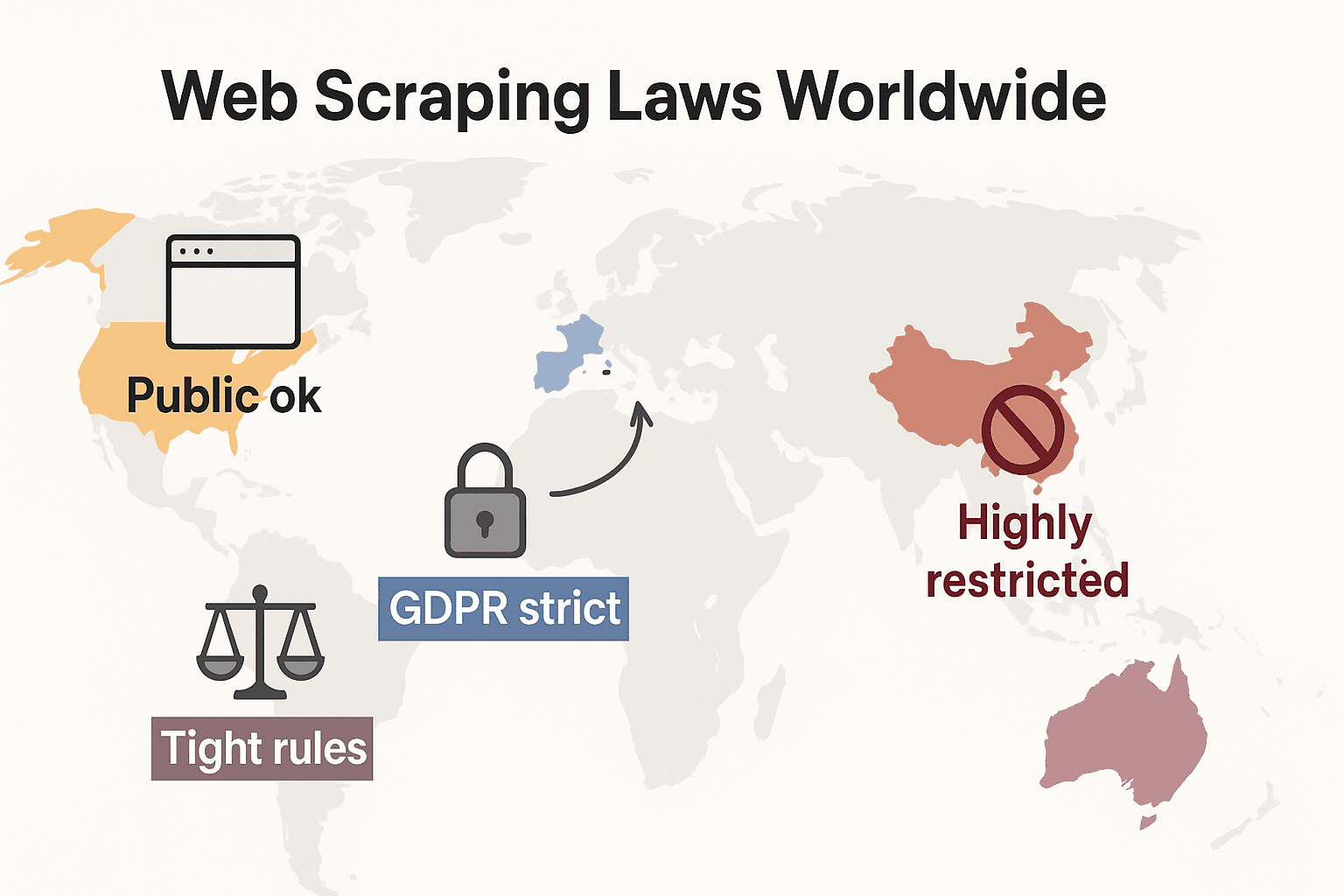
In breve: raccogliere dati pubblici e non personali per uso interno è in genere la scelta più sicura. Tutto il resto? Controlla le leggi locali e procedi con prudenza.
Miti comuni sulla legalità dello scraping web
Sfatiamo alcuni miti che sento continuamente:
- Mito 1: “Lo scraping web è illegale, punto.”
Falso. Non esiste una legge che vieti tutto lo scraping web. Conta come e cosa raccogli (). - Mito 2: “Se i dati sono pubblici, posso farne quello che voglio.”
Non proprio. I dati pubblici possono comunque essere protetti da privacy o copyright, e i ToS possono limitare determinati usi (). - Mito 3: “Lo scraping web è la stessa cosa dell’hacking.”
No. Raccogliere pagine web pubbliche non è hacking. Aggirare login o barriere tecniche è un’altra storia (). - Mito 4: “Se non mi beccano, va bene.”
Pensiero rischioso. Molti siti usano tecnologie anti-bot e se ne accorgono. Il silenzio non è consenso. - Mito 5: “Basta citare la fonte o usare i dati internamente per essere a posto.”
L’attribuzione non supera il copyright o la privacy. L’uso interno è più sicuro, ma non è una licenza gratuita. - Mito 6: “Tutto lo scraping web viola la privacy.”
Non tutto lo scraping riguarda dati personali. Ma raccogliere grandi volumi di informazioni personali senza protezioni è quasi sempre illegale (). - Mito 7: “Se i ToS di un sito vietano lo scraping, allora è sempre illegale farlo.”
Non necessariamente. Nel 2024, i tribunali nelle cause Meta v. Bright Data e X Corp v. Bright Data hanno stabilito che i ToS non possono vincolare utenti che non li hanno mai accettati—cioè, se fai scraping senza login o senza creare un account, i ToS del sito potrebbero non applicarsi a te. È ancora un’area in evoluzione, ma si tratta di un cambiamento importante.
Come fare scraping dei dati in modo legale: best practice per la conformità
Ecco la mia checklist di riferimento per uno scraping web legale ed etico:
- Leggi e rispetta i Termini di servizio del sito. Se dicono “no scraping”, valuta di fermarti o chiedi un’autorizzazione ().
- Attieniti ai dati pubblici. Se serve una password, il contenuto è riservato: non fare scraping ().
- Controlla robots.txt e fai crawling con moderazione. Non è vincolante legalmente, ma è buona educazione. Non martellare i server: distribuisci le richieste nel tempo ().
- Evita i dati personali a meno che non abbia una base giuridica. Se devi raccoglierli, rispetta GDPR/CCPA e minimizza ciò che raccogli.
- Non ripubblicare integralmente i contenuti estratti. Aggiungi valore o analisi, oppure chiedi il permesso ().
- Non alimentare modelli AI con contenuti raccolti via scraping senza verificare il copyright. Il quadro legale sta cambiando rapidamente: chiedi consiglio se questo è il tuo caso d’uso.
- Usa API ufficiali o esportazioni di dati quando disponibili. Sono progettate per questo scopo e di solito sono più sicure ().
- Sii trasparente e responsabile. Se raccogli dati personali, informa le persone e conserva un registro delle attività.
- Riduci al minimo e proteggi i dati. Raccogli solo ciò che ti serve, mantienilo accurato e conservalo in modo sicuro.
- Resta aggiornato e chiedi consulenza legale nei casi limite. Le leggi e le sentenze cambiano rapidamente, soprattutto l’EU AI Act e le leggi statali sulla privacy negli USA. In caso di dubbio, rivolgiti a un professionista.
Usare legalmente gli strumenti di web scraping: cosa devono sapere le aziende
Gli strumenti di web scraping come rendono la raccolta dati accessibile anche a chi non programma, ma vanno comunque usati in modo responsabile:
- Scegli strumenti orientati alla conformità. Thunderbit, per esempio, estrae solo ciò che puoi vedere nel browser—niente hack furtivi delle API o accessi non autorizzati ().
- Attieniti a casi d’uso legittimi. Analisi interne, ricerche di mercato e monitoraggio competitivo dei prezzi sono in genere sicuri. Ripubblicare o vendere i dati estratti? Molto più rischioso.
- Configura gli strumenti per la conformità. Imposta ritardi tra le richieste, rispetta robots.txt e usa modelli che raccolgano solo ciò che serve.
- Tienilo in casa. Usare i dati estratti internamente è più sicuro che ripubblicarli.
- Forma il tuo team. Assicurati che tutti conoscano regole e best practice.
- Sfrutta le funzioni di conformità integrate. Thunderbit avvisa gli utenti sui siti rischiosi, effettua lo scraping a velocità simili a quelle umane e non conserva i tuoi dati sui propri server.
- Non forzare la mano. Se uno strumento non riesce a raccogliere un sito, non cercare di aggirarlo. Non tutti i dati si possono ottenere senza rischi.
L’approccio di Thunderbit: abilitare uno scraping AI conforme
In , abbiamo dedicato molto tempo a riflettere sulla conformità. Ecco come il nostro AI Web Scraper aiuta gli utenti a restare dalla parte giusta della legge:
- Raccoglie solo ciò che puoi vedere. Thunderbit funziona nella tua sessione del browser, quindi non può accedere a dati che non potresti copiare manualmente.
- Guida gli utenti con avvisi. Se provi a fare scraping di un sito con politiche anti-scraping molto rigide, Thunderbit ti avverte.
- Velocità di scraping simili a quelle umane. Che tu lavori in locale o nel cloud, Thunderbit evita di sovraccaricare i server.
- Selezione dati personalizzabile. La nostra AI suggerisce le colonne rilevanti, aiutandoti a raccogliere solo ciò che serve.
- Gestione di sottopagine e paginazione. Thunderbit naviga i siti come farebbe un utente reale, rispettandone la struttura.
- Privacy e sicurezza. I tuoi dati restano tuoi: Thunderbit non li archivia né li riutilizza.
- Esportazioni orientate alla conformità. Esporta direttamente in Google Sheets, Airtable, Notion o CSV per un uso interno sicuro.
- Pianificazione e automazione. Imposta scraping ricorrenti a intervalli responsabili.
- Supporto multilingue. L’interfaccia di Thunderbit supporta 34 lingue, rendendo la conformità accessibile a livello globale.
- Aggiornamenti regolari dei modelli. I nostri modelli istantanei per i siti più popolari vengono mantenuti aggiornati rispetto ai cambiamenti legali e tecnici.
Integrando la conformità nel prodotto, Thunderbit aiuta i team a raccogliere i dati di cui hanno bisogno—senza grattacapi legali.
Restare un passo avanti: adattarsi ai cambiamenti legali e tecnici nello scraping web
Lo scraping web non è un’attività da impostare e dimenticare. Le leggi e le strutture dei siti evolvono continuamente. Ecco come restare al passo:
- Monitora gli sviluppi legali. Il ritmo del cambiamento è accelerato nel 2024–2026: segui le notizie sul diritto tecnologico, gli aggiornamenti dei regolatori e i blog di settore (come ). Tieni d’occhio l’applicazione dell’EU AI Act (agosto 2026), le nuove leggi statali sulla privacy negli USA e le cause ancora aperte sul copyright AI.
- Adattati ai cambiamenti tecnici. I siti aggiornano continuamente layout e difese anti-bot. Le principali piattaforme (Amazon, X, Google) hanno rafforzato in modo significativo le difese nel 2025–2026. L’AI e i template di Thunderbit sono progettati per adattarsi automaticamente.
- Abbraccia le API ufficiali quando disponibili. Se un sito passa a un modello API a pagamento, valuta il passaggio per affidabilità e conformità.
- Fai audit regolari dello scraping. Documenta le fonti, controlla eventuali cambiamenti nei ToS o nelle policy e adatta la strategia quando serve.
- Sfrutta gli aggiornamenti dei template di Thunderbit. Il nostro team mantiene i template aggiornati, così non devi preoccuparti di breaking change o nuovi requisiti di conformità.
- Resta flessibile. Se una fonte di dati diventa troppo rischiosa, passa a un’altra o cerca una partnership.
Con gli strumenti e la mentalità giusti, puoi mantenere il tuo flusso dati attivo—senza finire su mine legali.
Conclusione: orientarsi nel panorama legale dello scraping web
Lo scraping web non è di per sé illegale: è uno strumento potente per business, ricerca e innovazione. Ma, come ogni strumento, ha delle regole. La chiave è capire cosa stai raccogliendo, come lo stai raccogliendo e cosa farai con quei dati. Rispetta le leggi locali, osserva le policy dei siti e usa strumenti orientati alla conformità come per mantenere le tue attività in regola.
Le sentenze del 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) hanno rafforzato la posizione dello scraping dei dati pubblici, ma stanno emergendo nuovi rischi legati ai dati di training per l’AI, alle rivendicazioni di copyright e all’EU AI Act. Le policy dei singoli platform variano molto—Google, Amazon, LinkedIn, Meta e X applicano regole diverse—quindi conosci il contesto prima di fare scraping.
Se hai dubbi, chiedi sempre una consulenza legale, soprattutto per progetti grandi o sensibili. E ricorda: il panorama legale cambia continuamente, quindi resta informato e agile.
Vuoi saperne di più su web scraping, conformità e automazione? Dai un’occhiata al per altre guide, oppure prova tu stesso .
Domande frequenti
1. Lo scraping web è illegale ovunque?
No. Lo scraping web non è intrinsecamente illegale, ma la sua legalità dipende da cosa raccogli, da come lo raccogli e da dove ti trovi. Lo scraping di dati pubblici e non personali per uso interno è generalmente consentito nella maggior parte delle regioni, ma raccogliere dati personali o protetti da copyright, oppure violare i termini del sito, può essere illegale ().
2. Se ignoro robots.txt, lo scraping diventa illegale?
Robots.txt non è vincolante dal punto di vista legale, ma è buona pratica rispettarlo. Ignorarlo non ti farà fare causa da solo, ma può farti apparire come un “cattivo attore” in caso di controversia ().
3. Posso fare scraping di Google, Amazon o LinkedIn?
È complicato. Tutti e tre vietano lo scraping nei ToS, ma i tribunali hanno stabilito che i ToS potrebbero non vincolare gli utenti non autenticati (vedi Meta v. Bright Data e X Corp v. Bright Data, entrambe del 2024). Lo scraping di dati visibili pubblicamente (prezzi dei prodotti, inserzioni aziendali, profili pubblici) è in genere difendibile dal punto di vista legale negli USA. Tuttavia, ogni piattaforma applica le regole in modo diverso: Amazon è la più aggressiva sul fronte legale (ha citato in giudizio Perplexity AI nel novembre 2025); LinkedIn fa affidamento su barriere tecniche e rivendicazioni contrattuali; Google usa sempre più spesso azioni basate sul DMCA. Fai sempre scraping in modo responsabile e aspettati contromisure tecniche.
4. Posso fare scraping di Facebook o Instagram?
Dopo Meta v. Bright Data (2024), fare scraping di dati pubblici da Facebook e Instagram senza fare login è su basi legali più solide. Il tribunale ha stabilito che i ToS di Meta non si applicano ai non-utenti. Ma non creare mai account falsi e non raccogliere dati dietro login wall: quello supera il limite.
5. Posso fare scraping di X (Twitter)?
X ha aggiornato i propri ToS nel 2023 per vietare ogni scraping senza consenso scritto e ha adottato difese tecniche aggressive (Cloudflare Turnstile, limiti di 300 richieste/ora, scoring della reputazione IP). Tuttavia, Bright Data ha vinto in tribunale su basi simili: i dati pubblici raccolti senza un account non sono vincolati dai ToS di X. Dal punto di vista tecnico, X è una delle piattaforme più difficili da sottoporre a scraping nel 2026.
6. È legale fare scraping dei dati per addestrare modelli AI?
Questa è la grande domanda aperta del 2026. Le principali cause legali (NYT v. OpenAI, l’accordo da 1,5 miliardi di Anthropic) indicano un rischio legale significativo. L’EU AI Act richiede di divulgare le fonti dei dati di training e di rispettare le esclusioni del copyright. La proposta AI Accountability for Publishers Act imporrebbe autorizzazione e pagamento. Se fai scraping per addestrare l’AI, chiedi una consulenza legale prima di procedere.
7. Qual è il modo più sicuro per usare strumenti di web scraping come Thunderbit?
Attieniti allo scraping di dati pubblici, rispetta i termini del sito, evita le informazioni personali a meno che tu non abbia una base giuridica e usa i dati internamente. Thunderbit è progettato per aiutarti a restare conforme estraendo solo ciò che è visibile nel browser e avvisandoti sui siti rischiosi ().
8. Posso fare scraping di dati per uso commerciale?
Dipende. Usare i dati estratti per analisi interne o ricerche è in genere più sicuro. Ripubblicare o vendere dati estratti, soprattutto se protetti da copyright o personali, è molto più rischioso e può richiedere permesso o licenza.
9. Come faccio a rimanere aggiornato sui cambiamenti legali e tecnici nello scraping web?
Segui le notizie sul diritto tecnologico, monitora i siti target per eventuali cambiamenti nei ToS o nelle policy e usa strumenti come Thunderbit che aggiornano regolarmente template e funzioni di conformità. Nel 2026, le cose principali da tenere d’occhio sono: applicazione dell’EU AI Act (agosto), cause ancora aperte sul copyright AI e nuove leggi statali sulla privacy negli USA. In caso di dubbio, consulta un legale.