Extracteur Xiaohongshu

Approuvé par des professionnels d’entreprises leaders












Débloquez les données Xiaohongshu en deux clics
Extraction de données sans effort en deux clics
Fatigué du code compliqué et des réglages interminables juste pour récupérer des données Xiaohongshu ? Thunderbit vous permet d’extraire des champs essentiels comme note_id, author_id, author_nickname, note_title, note_content et like_count sans écrire une seule ligne de code. Il suffit de pointer les données dont vous avez besoin, et Thunderbit détecte automatiquement les champs avant de les extraire d’un clic.
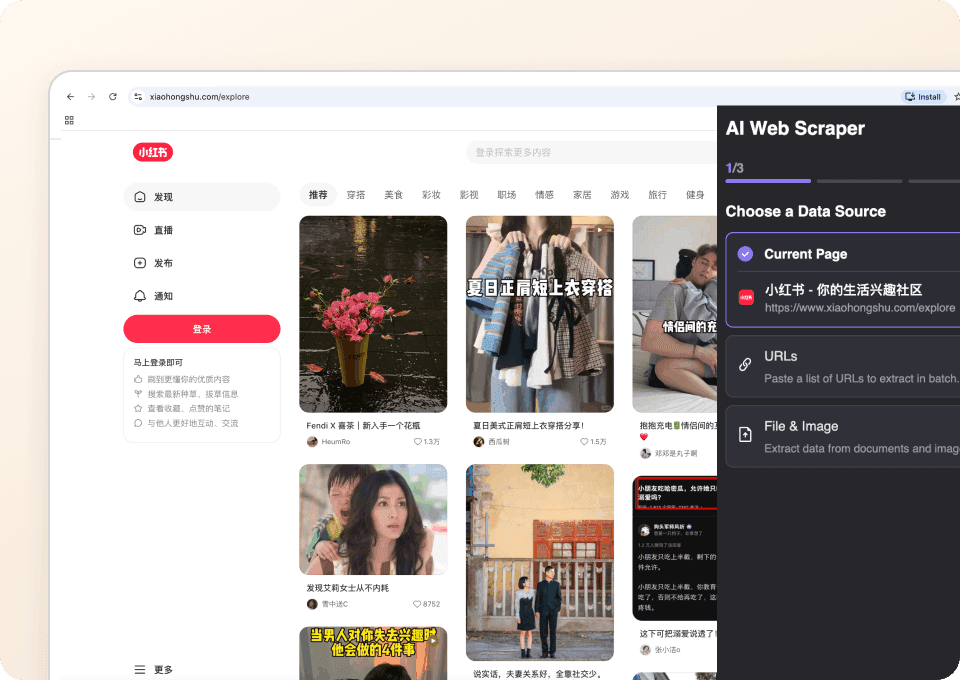
Obtenez l’ensemble du contenu, automatiquement
Les pages de listing Xiaohongshu ne donnent qu’un aperçu. Avec Thunderbit, vous pouvez visiter automatiquement la sous-page de chaque note pour en extraire directement des informations détaillées. Découvrez des informations cachées et obtenez une vision complète en extrayant chaque détail pertinent, le tout ajouté comme de nouvelles colonnes dans la destination de votre choix.
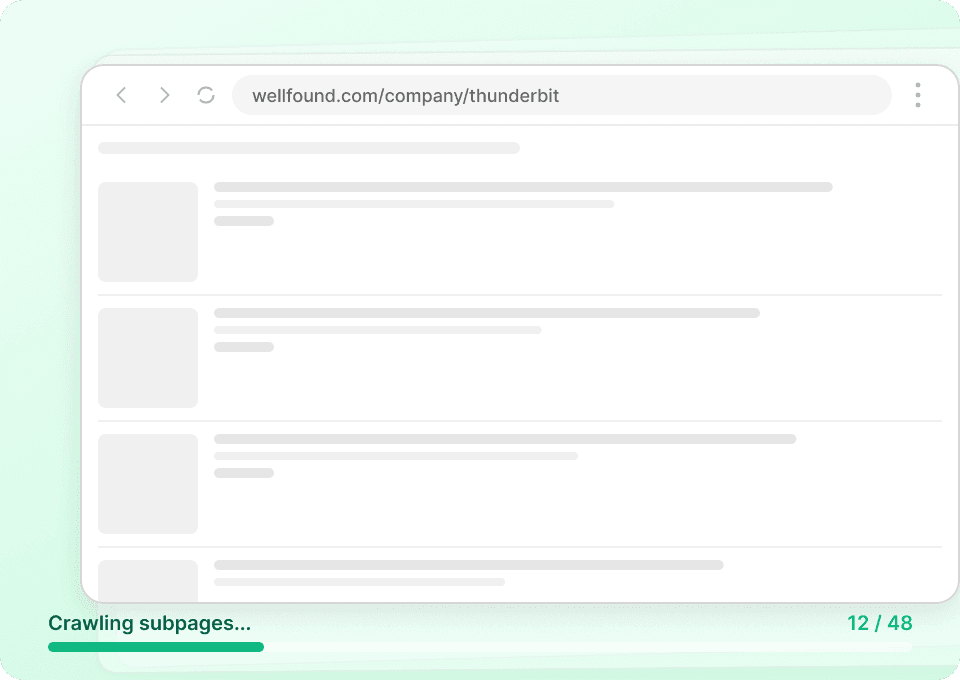
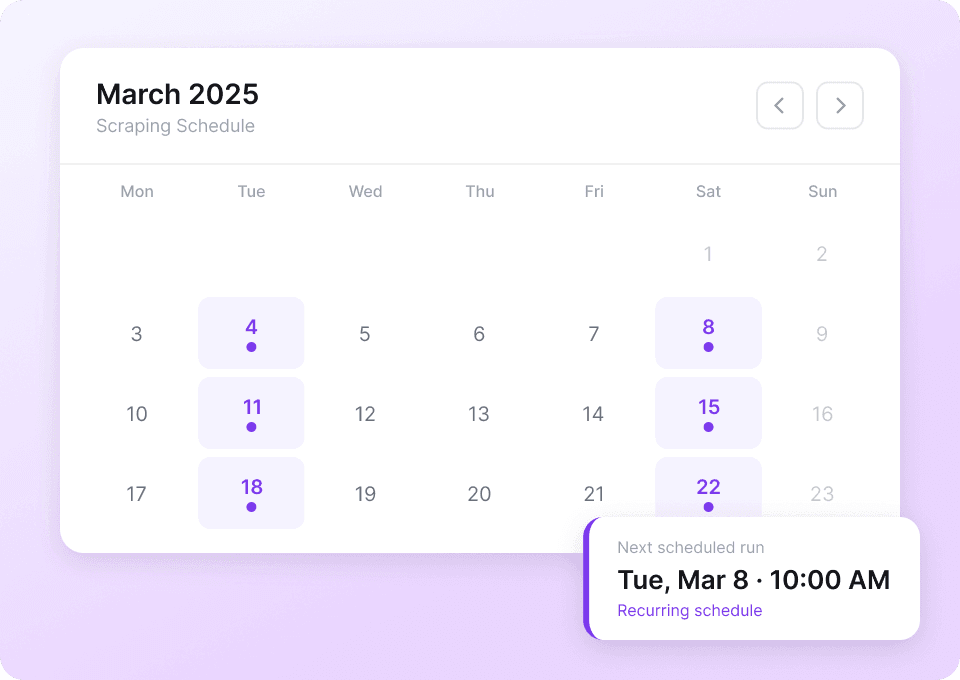
Automatisez la surveillance de vos données Xiaohongshu
Les données Xiaohongshu changent en permanence. Les extraire manuellement chaque jour est fastidieux. L’extraction planifiée de Thunderbit vous permet de créer des tâches récurrentes pour extraire automatiquement des données comme like_count en pilote automatique. Recevez des informations fraîches directement dans Google Sheets, Notion ou Airtable, sans lever le petit doigt.
Vous avez du mal à extraire efficacement Xiaohongshu ?
Découvrez pourquoi Thunderbit est la méthode la plus intelligente pour extraire les données Xiaohongshu.
Traditional Scrapers
The old way of doing thingsThunderbit AI
The smarter approachNe nous crois pas sur parole
Découvre ce que nos utilisateurs disent de Thunderbit.






Foire aux questions
Liés cas d’usage
Explore plus de cas d’usage de l’extracteur web Thunderbit.

Extracteur Pages Blanches
L’Extracteur White Pages de Thunderbit vous permet de collecter rapidement des données issues des annuaires téléphoniques et professionnels White Pages, avec des suggestions de champs intelligentes grâce à l’IA. Rassemblez noms, numéros de téléphone, adresses et sites web pour vos besoins de prospection, de marketing ou de recherche en quelques clics.
En savoir plus ->
Extracteur Tieba
L’Extracteur Tieba de Thunderbit vous permet de collecter facilement des données sur Baidu Tieba, notamment les sujets populaires et les différentes catégories de forums. Grâce aux suggestions intelligentes alimentées par l’IA, récupérez rapidement les noms de sujets, les liens, le nombre de publications et l’activité des utilisateurs pour vos besoins en recherche, marketing ou création de contenu. Parfait pour analyser les tendances et discussions sur les réseaux sociaux de Tieba.
En savoir plus ->
Extracteur Amarillas.com
L’Extracteur Amarillas.com de Thunderbit vous permet d’extraire des données structurées depuis Amarillas.com, y compris les listes de motels et de restaurants. Grâce aux suggestions de champs alimentées par l’IA, récupérez rapidement les noms d’entreprises, adresses, numéros de contact, notes et avis pour vos besoins de recherche, de marketing ou de prospection.
En savoir plus ->
Extracteur ReverseAustralia
L’Extracteur ReverseAustralia de Thunderbit vous permet d’extraire facilement les données des pages de plaintes et de commentaires de ReverseAustralia. Profitez des suggestions de champs alimentées par l’IA pour collecter rapidement numéros de téléphone, descriptions de plaintes, textes de commentaires, noms d’utilisateurs et bien plus, pour vos analyses ou recherches. Parfait pour les marketeurs, chercheurs et entreprises à la recherche de données structurées sur les retours utilisateurs.
En savoir plus ->Extracteur DialIndia
L’Extracteur DialIndia de Thunderbit vous permet de collecter les données des profils d’entreprises et des annuaires de voyage de DialIndia grâce à des suggestions de champs intelligentes par IA. Rassemblez en quelques clics noms d’entreprises, coordonnées, adresses et descriptions pour vos besoins de recherche, de marketing ou de prospection.
En savoir plus ->
Extracteur UpCity
L’Extracteur UpCity de Thunderbit vous permet de récupérer les données des listes d’agences publicitaires et des avis de prestataires sur UpCity. Grâce aux suggestions de champs intelligentes par IA, collectez rapidement noms d’agences, localisations, évaluations, coordonnées et avis détaillés pour vos analyses ou recherches. Parfait pour les marketeurs, chercheurs et entrepreneurs souhaitant obtenir des données structurées d’UpCity.
En savoir plus ->Prêt à booster ton extraction de données ?
Rejoins plus de 100 000 professionnels qui utilisent déjà Thunderbit pour automatiser leurs workflows de web scraping.
L’essai gratuit offre des crédits illimités pour 8 pages web.