Extracteur TechCrunch

Approuvé par des professionnels d’entreprises de premier plan












Débloquez les données TechCrunch en deux clics
Extraction TechCrunch simple en deux clics
Copier manuellement le titre d’un article, l’auteur, la date de publication ou même le contenu intégral depuis TechCrunch est fastidieux. Thunderbit vous évite cette corvée. Il vous suffit de pointer les données dont vous avez besoin, et notre IA s’occupe du reste. Deux clics suffisent pour extraire des données, sans écrire une seule ligne de code ni gérer des configurations compliquées.
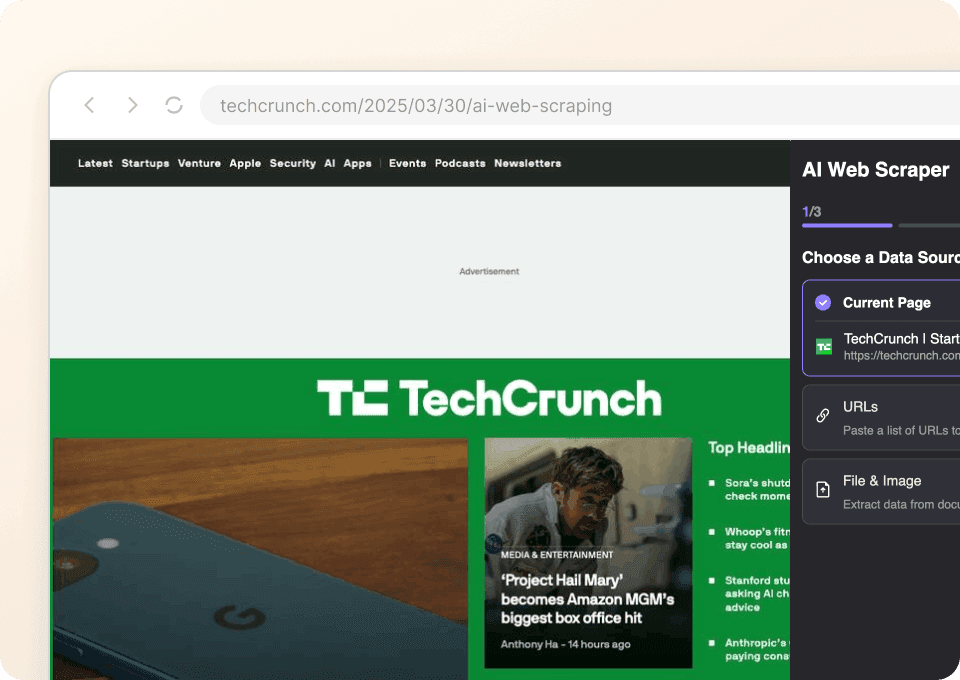
Obtenez instantanément des données TechCrunch propres
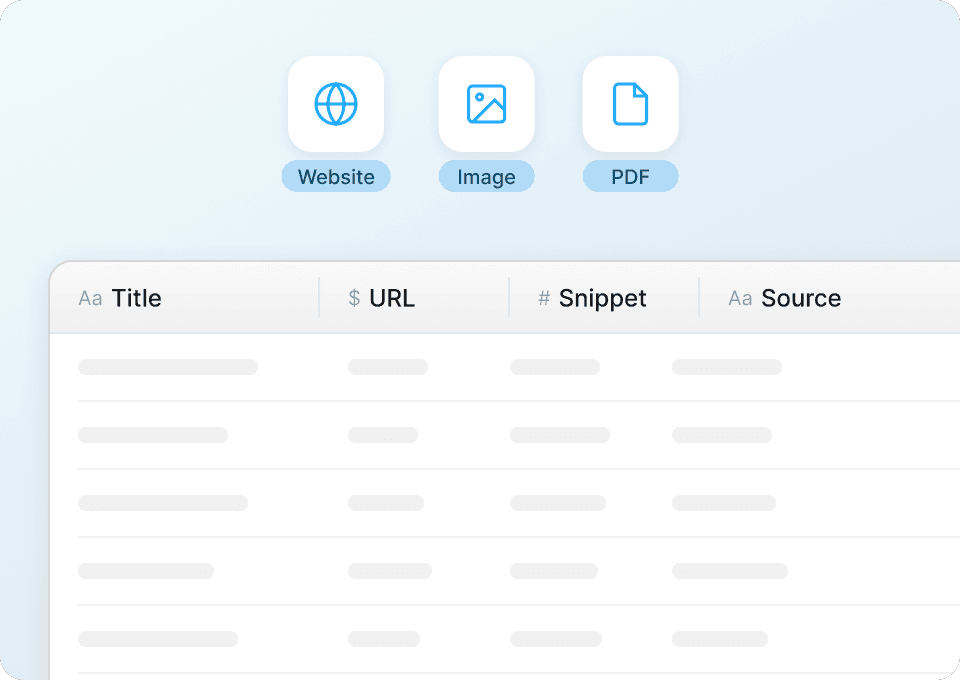
Extraire du HTML brut depuis TechCrunch ne vous mène nulle part — il vous faut des données propres et structurées. Thunderbit nettoie et met automatiquement en forme les données pendant l’extraction, afin que vous puissiez analyser immédiatement les catégories d’articles, suivre les auteurs ou comparer les dates de publication. Exportez directement vers Google Sheets, Notion ou Airtable et commencez à travailler tout de suite avec des données organisées, sans la corvée du nettoyage manuel.
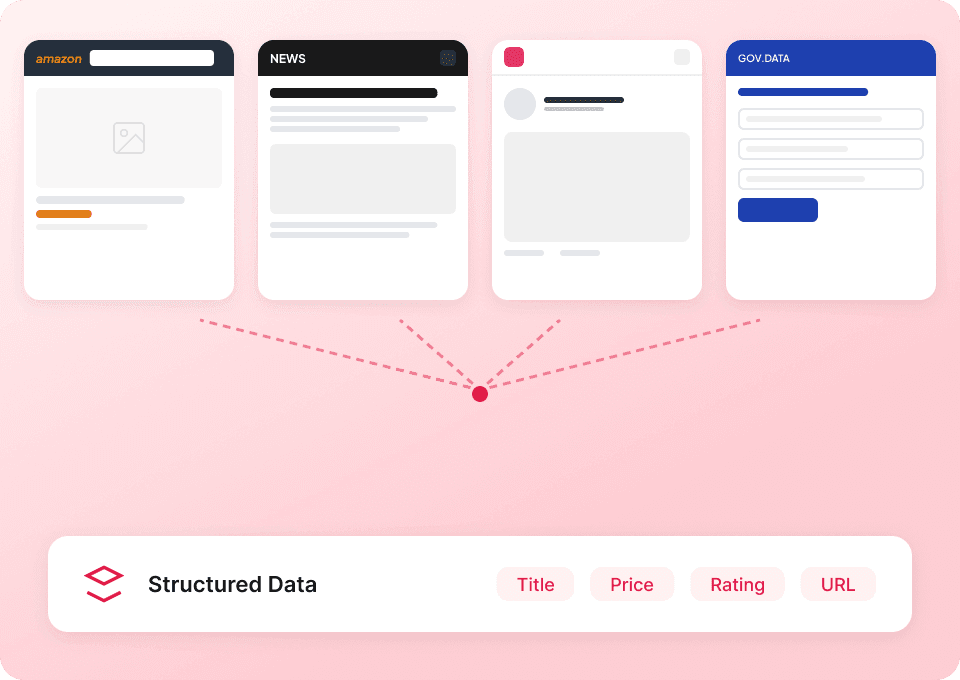
Extrayez n’importe quel site, pas seulement TechCrunch
Pourquoi apprendre un nouvel outil pour chaque site web ? Thunderbit fonctionne sur pratiquement n’importe quel site, y compris TechCrunch. Nous proposons aussi plus de 50 modèles prêts à l’emploi pour vous aider à démarrer encore plus vite. Que vous cherchiez du contenu d’articles, des tags ou d’autres détails, Thunderbit est votre solution unique pour extraire des données sur le web.
Vous avez du mal à extraire efficacement TechCrunch ?
Découvrez comment Thunderbit simplifie l’extraction des données TechCrunch par rapport aux méthodes traditionnelles.
Extracteurs traditionnels
L’ancienne méthodeThunderbit
L’approche la plus intelligenteNe vous fiez pas seulement à notre parole
Découvrez ce que nos utilisateurs disent de Thunderbit.






Questions fréquemment posées
Similaires cas d’usage
Explorez d’autres cas d’usage de l’extracteur web Thunderbit.

Extracteur HKTVmall
Récupérez en quelques clics les noms de produits, les prix et même les notes clients depuis les annonces HKTVmall, sans aucune configuration complexe.
En savoir plus ->
Extracteur ReverseAustralia
L’Extracteur ReverseAustralia de Thunderbit vous permet d’extraire facilement les données des pages de plaintes et de commentaires de ReverseAustralia. Profitez des suggestions de champs alimentées par l’IA pour collecter rapidement numéros de téléphone, descriptions de plaintes, textes de commentaires, noms d’utilisateurs et bien plus, pour vos analyses ou recherches. Parfait pour les marketeurs, chercheurs et entreprises à la recherche de données structurées sur les retours utilisateurs.
En savoir plus ->
Extracteur iBegin
L'Extracteur iBegin de Thunderbit vous permet d'extraire les résultats de recherche d'entreprises ainsi que des informations détaillées depuis le site iBegin. Grâce aux suggestions de champs alimentées par l'IA, rassemblez rapidement noms d'entreprises, coordonnées, adresses, notes et bien plus encore pour la génération de leads, la recherche ou l'analyse marketing.
En savoir plus ->
Extracteur de Listes d'Entreprises TripAdvisor
L’Extracteur TripAdvisor de Thunderbit vous permet de collecter des données issues des fiches d’établissements, du centre de ressources et du forum des propriétaires sur TripAdvisor. Grâce aux suggestions intelligentes de champs, rassemblez rapidement noms de ressources, liens, descriptions, sujets de forum, auteurs et contenus de posts pour vos besoins de recherche, de marketing ou d’analyse.
En savoir plus ->Extracteur Substack
Obtenez les nombres d’abonnés Substack, les titres d’articles et les descriptions de publication dans un tableau clair — sans code, l’IA se charge de la structuration.
En savoir plus ->Extracteur Tradera
L’Extracteur Tradera de Thunderbit vous permet de collecter facilement des données à partir des annonces et pages produits de Tradera. Grâce à la suggestion intelligente de champs par l’IA, récupérez noms de produits, prix, catégories, images et descriptions pour vos analyses ou la gestion de votre inventaire. Parfait pour les vendeurs e-commerce, collectionneurs et chercheurs souhaitant obtenir des données structurées depuis Tradera.
En savoir plus ->Prêt à booster votre extraction de données ?
Rejoignez plus de 100 000 professionnels qui utilisent déjà Thunderbit pour automatiser leurs workflows de web scraping.
L’essai gratuit offre des crédits illimités pour 8 pages web.