Extracteur de News












Des données d’actualité capturées plus vite
Récupérez des données news propres depuis les articles, les listes et les sources, sans le travail manuel fastidieux.
Obtenez tous les détails de l’article
Les pages de listes d’actualité ne donnent souvent qu’un aperçu. Thunderbit visite la page complète de chaque article et récupère tout ce qui compte — titre, résumé, auteur, date de publication, source d’actualité et rubrique. Passez d’une simple liste de liens à un jeu de données complet et structuré, sans travail manuel pénible.
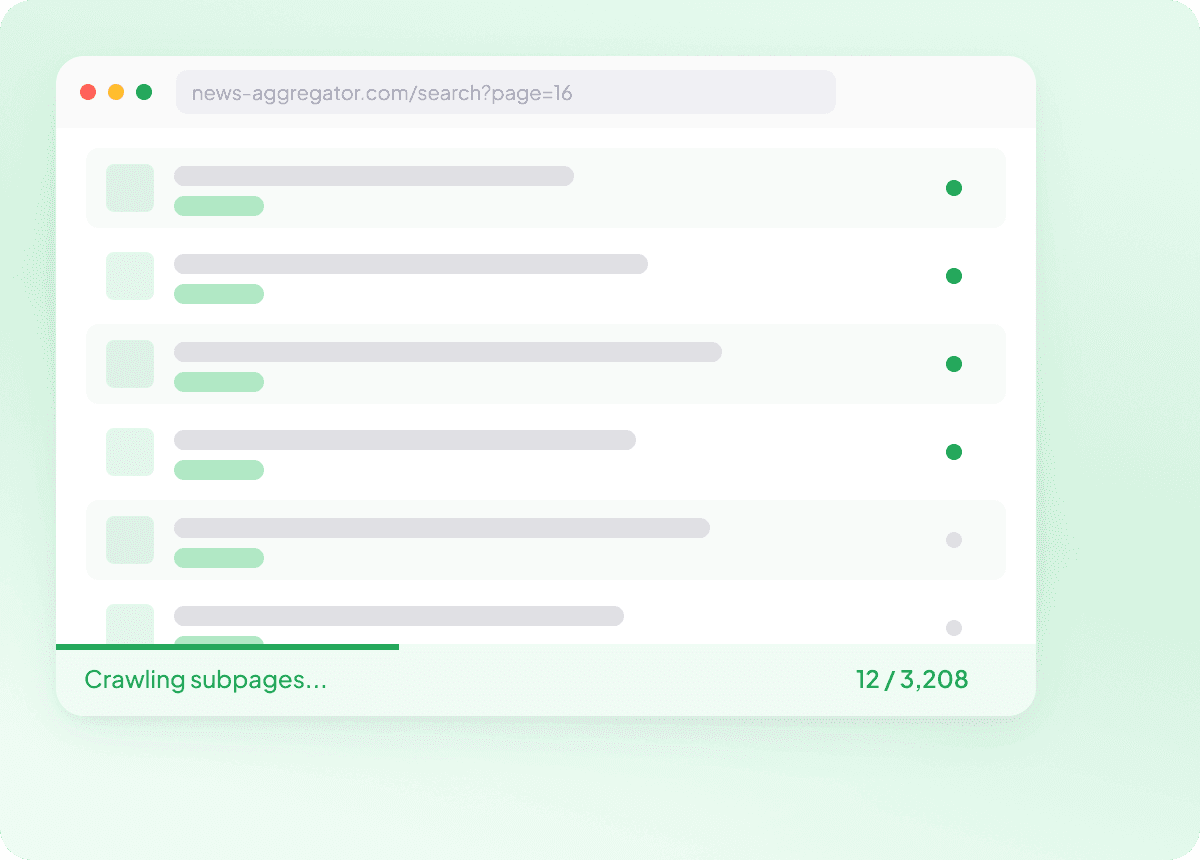
Extraire en masse des listes d’URL News
Extraire les articles un par un n’a rien d’un vrai workflow — c’est une corvée. Collez une liste d’URL d’articles et Thunderbit extrait en masse des centaines de pages en une seule exécution, en capturant tous les champs nécessaires pour chaque article. Rassembler de grands volumes de données news n’a jamais été aussi simple.

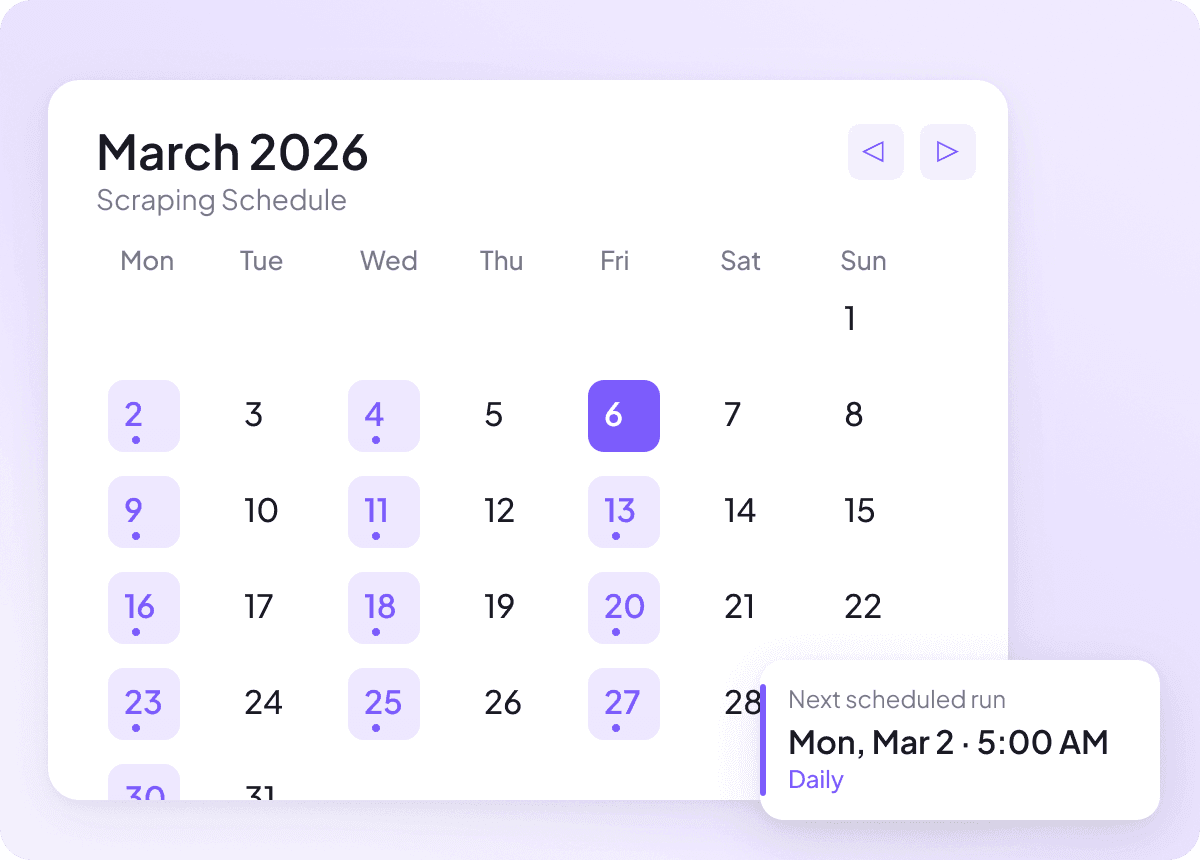
Gardez les données News à jour
L’actualité évolue vite, et les données d’hier perdent rapidement de leur valeur. Programmez votre extraction et Thunderbit fonctionne en pilote automatique — votre feuille de calcul reste alimentée avec des titres, résumés, auteurs, dates de publication, sources et rubriques à la fréquence que vous définissez. Des mises à jour récurrentes, sans effort manuel.
Pourquoi Thunderbit est-il différent des extracteurs de news traditionnels ?
Une manière plus rapide de collecter des données news désordonnées sans casse permanente.
Extracteurs traditionnels
L’ancienne méthodeThunderbit AI
L’approche la plus intelligenteNe nous crois pas sur parole
Découvre ce que nos utilisateurs disent de Thunderbit.







Questions fréquentes
Liés cas d’usage
Explore d’autres cas d’usage du scraper web de Thunderbit.

Extracteur HKTVmall
Extrayez en 2 clics les noms de produits, les prix, les notes et bien plus encore depuis les fiches HKTVmall — sans aucune programmation. Exportez directement vers Excel, Google Sheets ou Notion et transformez les données HKTVmall en informations exploitables.
En savoir plus ->Extracteur Substack
Extrayez en 2 clics les nombres d’abonnés Substack, les titres d’articles et les descriptions de publication — puis exportez vers Excel, Google Sheets ou Notion. Aucun code requis : l’IA de Thunderbit s’occupe de structurer les données pour vous.
En savoir plus ->Extracteur DialIndia
L’Extracteur DialIndia de Thunderbit vous permet de collecter les données des profils d’entreprises et des annuaires de voyage de DialIndia grâce à des suggestions de champs intelligentes par IA. Rassemblez en quelques clics noms d’entreprises, coordonnées, adresses et descriptions pour vos besoins de recherche, de marketing ou de prospection.
En savoir plus ->Extracteur On the Beach
L’Extracteur On the Beach de Thunderbit vous permet d’extraire en quelques secondes les offres de vacances, les hôtels, les prix, les avis et bien plus encore depuis On the Beach. Profitez des suggestions intelligentes de champs pour collecter et organiser rapidement vos données de voyage, que ce soit pour l’analyse, la comparaison ou la planification. Parfait pour les professionnels du tourisme, les analystes et les organisateurs de séjours.
En savoir plus ->Extracteur Tradera
L’Extracteur Tradera de Thunderbit vous permet de collecter facilement des données à partir des annonces et pages produits de Tradera. Grâce à la suggestion intelligente de champs par l’IA, récupérez noms de produits, prix, catégories, images et descriptions pour vos analyses ou la gestion de votre inventaire. Parfait pour les vendeurs e-commerce, collectionneurs et chercheurs souhaitant obtenir des données structurées depuis Tradera.
En savoir plus ->
Extracteur UNIQLO
Extrayez en 2 clics les noms, prix, couleurs et tailles des produits Uniqlo grâce à l’extension Chrome propulsée par l’IA de Thunderbit. Exportez directement vers Google Sheets, Excel ou Notion et gardez votre veille produit toujours à jour.
En savoir plus ->Prêt à booster ton extraction de données ?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
L’essai gratuit offre des crédits illimités pour 8 pages web.



