
L'Extracteur namu.wiki alimenté par l'IA de Thunderbit est un outil spécialisé conçu pour extraire des données de namu.wiki avec précision et facilité. Grâce à , les utilisateurs peuvent transformer le contenu du site en ensembles de données structurés, en exportant les données en seulement 2 clics.
📚 Qu'est-ce que l'Extracteur namu.wiki
L' est un Extracteur Web IA qui permet aux utilisateurs de récupérer des données du site namu.wiki en utilisant l'intelligence artificielle. En naviguant simplement sur le , les utilisateurs peuvent cliquer sur le bouton AI Suggest Columns et le bouton Scrape pour extraire efficacement des données précieuses.
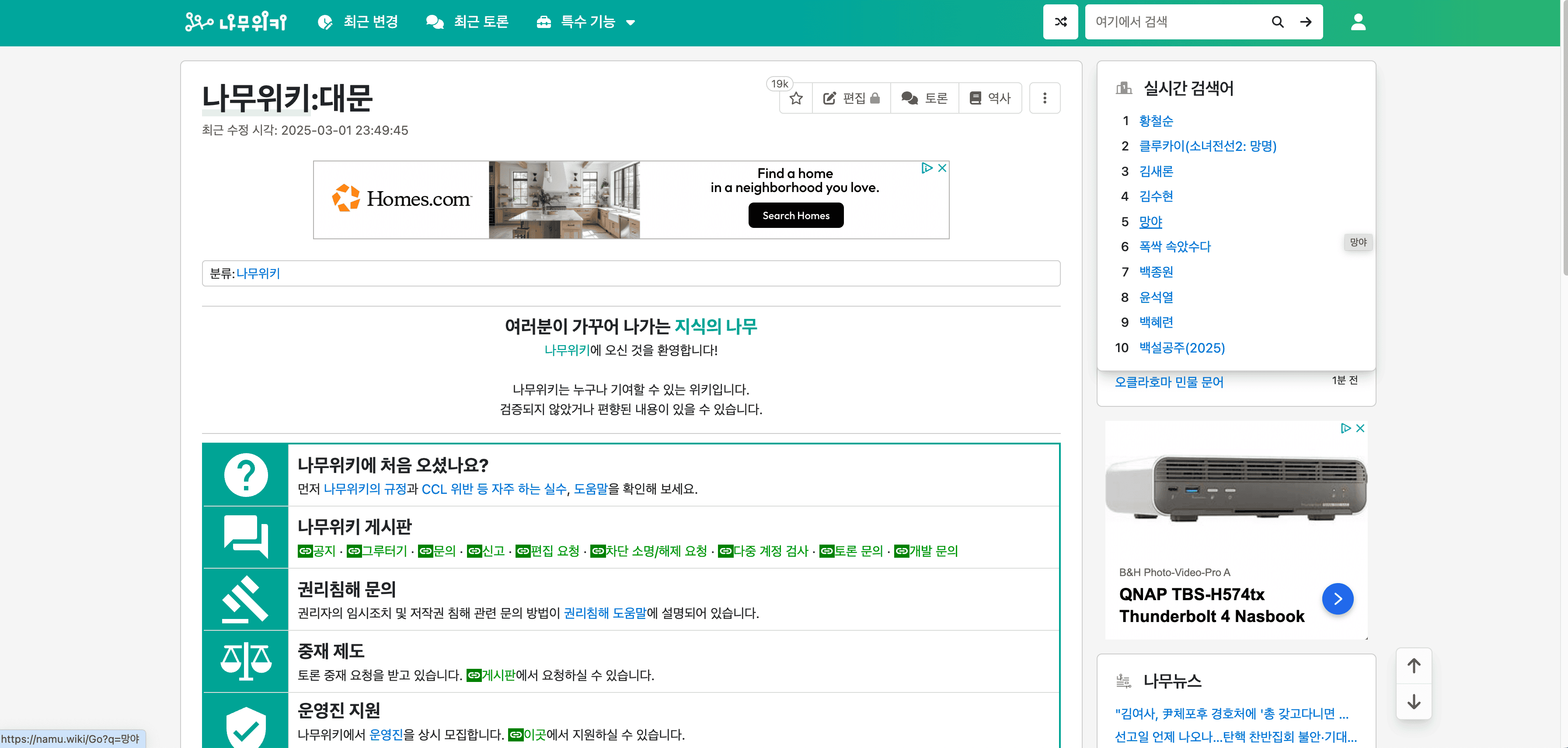
🔍 Que pouvez-vous extraire avec l'Extracteur namu.wiki
📄 Extraire la page de liste des pages nécessaires de NamuWiki
L'extracteur namu.wiki alimenté par l'IA permet aux utilisateurs d'extraire des informations détaillées de la . Cette fonctionnalité est parfaite pour recueillir des informations sur les pages nécessitant une création ou une mise à jour de contenu.
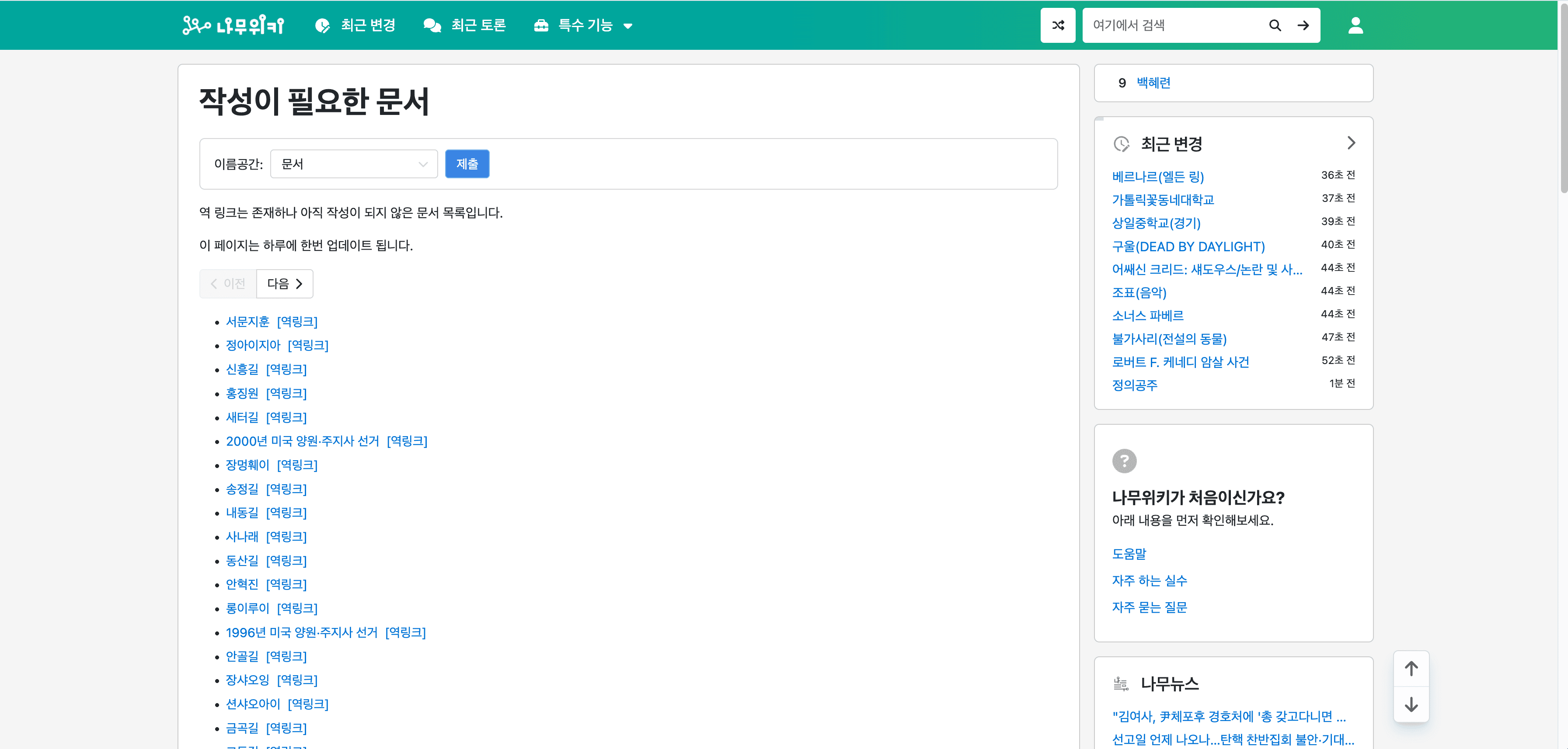
Étapes :
- Téléchargez l' et créez un compte.
- Allez sur la page de destination, par exemple : .
- Cliquez sur AI Suggest Columns, l'IA lit la page web et recommande ensuite des noms de colonnes.
- Cliquez sur Scrape pour exécuter l'extracteur, obtenir les données et télécharger le fichier.
Noms des colonnes
| Colonne | Description |
|---|---|
| 📄 Titre de la page | Le titre de la page nécessaire. |
| 🔗 URL de la page | Le lien vers la page nécessaire. |
| 📅 Dernière modification | La date de la dernière modification de la page. |
| ✍️ Éditeur | Le nom d'utilisateur du dernier éditeur. |
💬 Extraire la page des discussions récentes de NamuWiki
L'extracteur namu.wiki alimenté par l'IA permet également aux utilisateurs d'extraire des informations de la . Cette fonctionnalité est idéale pour surveiller les discussions en cours et les interactions communautaires.
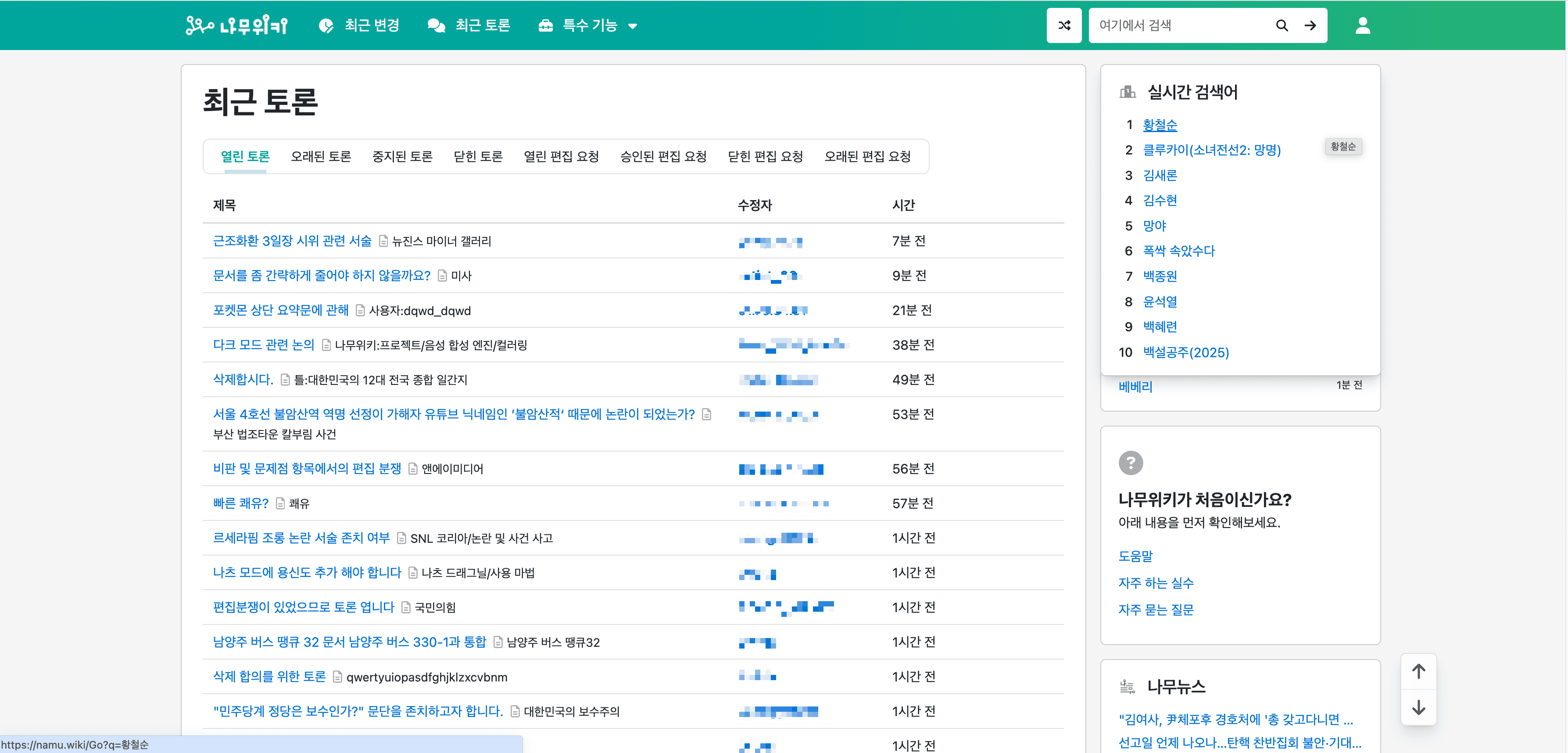
Étapes :
- Téléchargez l' et créez un compte.
- Allez sur la page de destination, par exemple : .
- Cliquez sur AI Suggest Columns, l'IA lit la page web et recommande ensuite des noms de colonnes.
- Cliquez sur Scrape pour exécuter l'extracteur, obtenir les données et télécharger le fichier.
Noms des colonnes
| Colonne | Description |
|---|---|
| 💬 Sujet de la discussion | Le sujet de la discussion. |
| 🔗 URL de la discussion | Le lien vers la page de discussion. |
| 🕒 Dernière activité | L'horodatage de la dernière activité dans la discussion. |
| 👤 Participant | Le nom d'utilisateur du participant à la discussion. |
🤔 Pourquoi utiliser l'outil namu.wiki
Extraire des données de namu.wiki peut fournir des informations précieuses pour divers objectifs :
- Chercheurs : Analyser les lacunes de contenu et les interactions communautaires.
- Créateurs de contenu : Identifier les pages nécessaires pour la création de contenu.
- Gestionnaires de communauté : Surveiller les discussions et interagir avec la communauté.
- Entreprises : Extraire des données structurées pour la recherche de marché et l'analyse.
En extrayant des données précises et bien organisées, vous pouvez prendre des décisions basées sur les données et découvrir de nouvelles opportunités.
🛠️ Comment utiliser l'extension Chrome namu.wiki
- Installez l'extension Chrome de Thunderbit : Téléchargez l'extension et créez votre compte.
- Naviguez vers la page des pages nécessaires ou des discussions récentes : Allez sur la page namu.wiki que vous souhaitez extraire.
- Activez l'extracteur alimenté par l'IA : Cliquez sur AI Suggest Column pour générer des noms de colonnes ou personnalisez les colonnes selon vos besoins.
💰 Tarification pour l'Extracteur namu.wiki
Thunderbit fonctionne sur un système basé sur des crédits, où 1 crédit équivaut à 1 ligne extraite. L'outil est gratuit à essayer, et des plans supplémentaires offrent de la flexibilité pour les utilisateurs occasionnels et à fort volume.
Plans :
| Niveau | Prix mensuel | Prix annuel | Coût total annuel | Crédits/mois | Crédits/an |
|---|---|---|---|---|---|
| Gratuit | Gratuit | Gratuit | Gratuit | 6 pages | N/A |
| Starter | 15 $ | 9 $ | 108 $ | 500 | 5,000 |
| Pro 1 | 38 $ | 16,5 $ | 199 $ | 3,000 | 30,000 |
| Pro 2 | 75 $ | 33,8 $ | 406 $ | 6,000 | 60,000 |
| Pro 3 | 125 $ | 68,4 $ | 821 $ | 10,000 | 120,000 |
| Pro 4 | 249 $ | 137,5 $ | 1,650 $ | 20,000 | 240,000 |
Fonctionnalités gratuites :
- 6 pages par mois sur le plan gratuit.
- 10 pages gratuites avec l'essai gratuit, parfait pour explorer les fonctionnalités de l'extracteur.
❓ FAQ
-
Qu'est-ce que l'Extracteur namu.wiki alimenté par l'IA ?
L'Extracteur namu.wiki alimenté par l'IA est un outil spécialisé conçu pour extraire des informations détaillées des pages nécessaires et des discussions récentes de namu.wiki. Il simplifie la collecte de données en utilisant l'extension Chrome de Thunderbit, permettant aux utilisateurs de rassembler rapidement et facilement des données structurées pour la recherche, la création de contenu ou l'analyse sans nécessiter d'expertise technique.
-
Qu'est-ce que Thunderbit ?
Thunderbit est une extension Chrome de pointe qui simplifie les tâches de web scraping, d'extraction de données et d'automatisation en utilisant l'intelligence artificielle. Elle permet aux utilisateurs d'extraire des données de sites web, de personnaliser les colonnes, de remplir automatiquement des formulaires en ligne et de résumer le contenu. Thunderbit s'adresse aux professionnels du marketing, du commerce électronique, de la recherche, et plus encore, en rendant les tâches fastidieuses basées sur le web plus rapides, plus faciles et plus précises.
-
Combien de pages puis-je extraire avec l'essai gratuit ?
Avec l'essai gratuit de Thunderbit, vous pouvez extraire jusqu'à 10 pages gratuitement. Cela permet aux utilisateurs d'explorer les capacités de l'outil et de décider s'il répond à leurs besoins en matière d'extraction de données avant de passer à un plan payant.
-
Puis-je personnaliser les colonnes et les champs de données à extraire ?
Absolument ! Thunderbit offre des options de personnalisation robustes qui vous permettent de spécifier les champs de données exacts que vous souhaitez extraire. Des détails de la page comme les titres, les URL et les dates de dernière modification aux données de discussion comme les sujets, les URL et les noms des participants, l'extracteur s'adapte à vos besoins.
-
À quelle fréquence puis-je exécuter l'extracteur ?
La fréquence d'exécution de l'extracteur dépend de votre plan d'abonnement et du nombre de crédits disponibles dans votre compte. Les plans de niveau supérieur incluent plus de crédits, permettant des extractions de données à plus grande échelle ou plus fréquentes. Les utilisateurs qui ont besoin d'un accès constant à l'outil peuvent passer à un plan premium pour une utilisation ininterrompue.
-
Que se passe-t-il si je manque de crédits ?
Si vous manquez de crédits, vous pouvez facilement acheter des crédits supplémentaires à la demande ou passer à un plan d'abonnement de niveau supérieur. Cela garantit que vous avez un accès continu aux fonctionnalités de l'extracteur chaque fois que vous en avez besoin.
-
Est-il légal d'extraire des pages et des discussions de namu.wiki ?
L'extraction de données accessibles au public de namu.wiki est généralement permise tant que vous respectez les lois applicables, respectez les droits à la vie privée et évitez de violer les conditions d'utilisation de namu.wiki. Il est essentiel d'utiliser les données de manière responsable et de s'assurer de la conformité avec toutes les réglementations pertinentes pour éviter d'éventuels problèmes.
-
Quels types de données puis-je extraire de namu.wiki ?
Vous pouvez extraire une variété de données de namu.wiki, y compris les titres de pages, les URL, les dates de dernière modification, les sujets de discussion et les noms des participants. Ces données peuvent être utilisées pour l'analyse, la création de contenu et l'engagement communautaire, fournissant des informations précieuses sur le contenu et les interactions de la plateforme.
-
Comment puis-je m'assurer que les données que j'extrais sont précises et à jour ?
L'extracteur alimenté par l'IA de Thunderbit est conçu pour fournir des données précises et à jour en analysant en continu la structure et le contenu du site web. Cependant, il est toujours bon de vérifier manuellement les données et de les recouper avec d'autres sources pour garantir leur précision et leur pertinence.
📖 En savoir plus
Pour plus d'informations sur le web scraping et comment utiliser Thunderbit efficacement, visitez notre et explorez des articles comme et .