Extracteur d'Articles












Exploitez facilement les données d’articles
Extrayez les informations clés d’un article sans aucune compétence en programmation.
Toujours à jour automatiquement
Fatigué des extracteurs qui cassent à chaque refonte d’un site d’actualité ? Thunderbit comprend le sens d’une page, et pas seulement la position fixe des éléments. Extrayez de façon fiable les titres, auteurs et contenus d’articles, même lorsque la structure du site évolue.

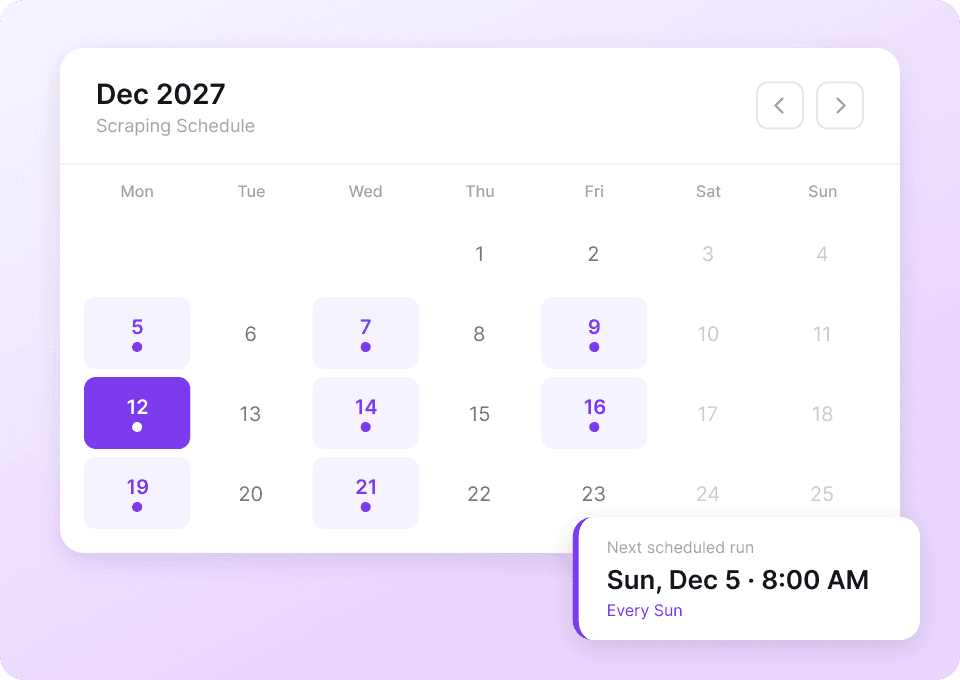
Automatisez la collecte de vos données d’articles
Les métadonnées d’articles comme les dates de publication, les mots-clés et les catégories changent en permanence. Programmez Thunderbit pour extraire les données en pilote automatique, puis recevez du contenu fraîchement collecté directement dans Google Sheets, Notion ou Airtable — sans aucune saisie manuelle.
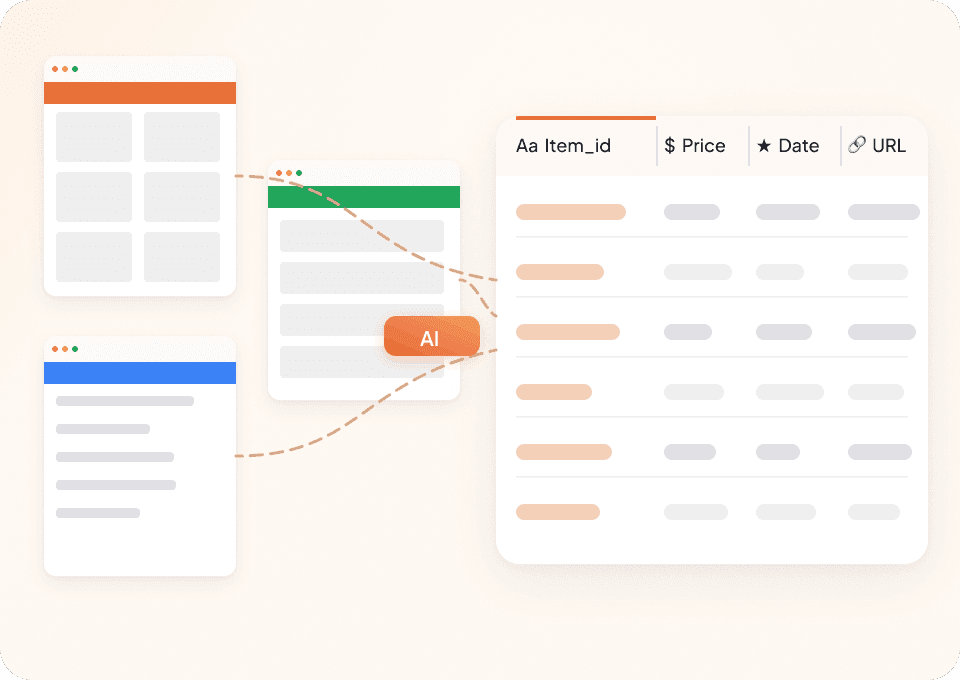
Extrayez des données depuis n’importe quel site
Pourquoi utiliser un extracteur différent pour chaque source d’actualité ? Thunderbit fonctionne immédiatement sur n’importe quel site. Avec plus de 50 modèles prêts à l’emploi, collecter des données d’articles — quelle que soit la publication — ne prend que quelques clics.
Pourquoi Thunderbit est-il différent des extracteurs d’articles traditionnels ?
Thunderbit utilise l’IA pour extraire les données d’articles rapidement et de manière fiable.
Extracteurs traditionnels
L’ancienne façon de faireIA Thunderbit
L’approche la plus intelligenteNe nous crois pas sur parole
Découvre ce que nos utilisateurs disent de Thunderbit.




Questions fréquentes
Liés cas d’usage
Explore d’autres cas d’usage du scraper web de Thunderbit.

Extracteur ReverseAustralia
L’Extracteur ReverseAustralia de Thunderbit vous permet d’extraire facilement les données des pages de plaintes et de commentaires de ReverseAustralia. Profitez des suggestions de champs alimentées par l’IA pour collecter rapidement numéros de téléphone, descriptions de plaintes, textes de commentaires, noms d’utilisateurs et bien plus, pour vos analyses ou recherches. Parfait pour les marketeurs, chercheurs et entreprises à la recherche de données structurées sur les retours utilisateurs.
En savoir plus ->Extracteur DialIndia
L’Extracteur DialIndia de Thunderbit vous permet de collecter les données des profils d’entreprises et des annuaires de voyage de DialIndia grâce à des suggestions de champs intelligentes par IA. Rassemblez en quelques clics noms d’entreprises, coordonnées, adresses et descriptions pour vos besoins de recherche, de marketing ou de prospection.
En savoir plus ->
Extracteur de Listes d'Entreprises TripAdvisor
L’Extracteur TripAdvisor de Thunderbit vous permet de collecter des données issues des fiches d’établissements, du centre de ressources et du forum des propriétaires sur TripAdvisor. Grâce aux suggestions intelligentes de champs, rassemblez rapidement noms de ressources, liens, descriptions, sujets de forum, auteurs et contenus de posts pour vos besoins de recherche, de marketing ou d’analyse.
En savoir plus ->Extracteur Substack
Extrayez en 2 clics les nombres d’abonnés Substack, les titres d’articles et les descriptions de publication — puis exportez vers Excel, Google Sheets ou Notion. Aucun code requis : l’IA de Thunderbit s’occupe de structurer les données pour vous.
En savoir plus ->
Extracteur HKTVmall
Extrayez en 2 clics les noms de produits, les prix, les notes et bien plus encore depuis les fiches HKTVmall — sans aucune programmation. Exportez directement vers Excel, Google Sheets ou Notion et transformez les données HKTVmall en informations exploitables.
En savoir plus ->
Extracteur iBegin
L'Extracteur iBegin de Thunderbit vous permet d'extraire les résultats de recherche d'entreprises ainsi que des informations détaillées depuis le site iBegin. Grâce aux suggestions de champs alimentées par l'IA, rassemblez rapidement noms d'entreprises, coordonnées, adresses, notes et bien plus encore pour la génération de leads, la recherche ou l'analyse marketing.
En savoir plus ->Prêt à booster ton extraction de données ?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
L’essai gratuit offre des crédits illimités pour 8 pages web.



