

Pour une équipe moderne — en vente, en opérations ou en marketing —, savoir récupérer rapidement des informations sur le web pèse lourd dans la réussite d’un projet. Quand tout repose sur la donnée, les entreprises recherchent des outils rapides, fiables et capables de tenir la charge quand le volume grimpe. C’est exactement le terrain sur lequel Rust commence à s’imposer : ce langage de nouvelle génération gagne du terrain dans l’extraction web, en particulier auprès des équipes attachées à la performance et à la sécurité.
Et ce n’est pas un simple feu de paille : Rust a été sacré « langage préféré » plusieurs années de suite dans le Stack Overflow Developer Survey, et son adoption ne cesse de croître côté back-end et data engineering. Mais qu’implique réellement « l’extraction web avec Rust » pour les professionnels ? Et comment se mesure-t-elle à des solutions no-code comme Thunderbit, pensées pour ceux qui ne codent pas ? Décryptons tout cela, sans noyer le sujet sous le jargon.
L’extraction web avec Rust : les bases à connaître
L’extraction web revient à automatiser la collecte d’informations sur des sites. Pense à un assistant numérique qui parcourt des centaines, voire des milliers de pages, en retire les données qui t’intéressent — prix, contacts, avis… — et te les restitue dans un format propre, directement exploitable. Un vrai gain de temps pour les entreprises qui ont besoin de données fraîches afin de prospecter, surveiller la concurrence, suivre les prix, et bien d’autres usages.
Rust, lui, est un langage système réputé pour sa rapidité, sa gestion irréprochable de la mémoire et sa fiabilité. Là où certains langages plus anciens laissent passer des bugs ou ralentissent, Rust traque les erreurs avant même l’exécution du code. Pour l’extraction web, cela se traduit par des outils très rapides, robustes et qui ne flanchent pas au moindre obstacle — l’idéal pour collecter de la donnée à grande échelle.
Rust ne profite d’ailleurs pas qu’aux développeurs : ses atouts rejaillissent sur les équipes métiers. Davantage de rapidité et de sécurité, c’est des données plus fraîches, moins d’erreurs et des analyses plus solides pour tout le monde.
Pourquoi miser sur Rust pour l’extraction web ? Les points forts pour les boîtes
Pourquoi un nombre croissant d’équipes se tournent-elles vers Rust pour l’extraction web, alors que Python et JavaScript occupent le terrain depuis bien longtemps ? Voici les principaux avantages :
- Performance redoutable : Rust se compile directement en code machine, ce qui le rend bien plus rapide que Python ou JavaScript, des langages interprétés. Sur des extractions massives — des millions de pages, par exemple —, ce gain de vitesse change tout.
- Sécurité mémoire : grâce à sa gestion novatrice (pas de ramasse-miettes, des règles d’ownership strictes), Rust réduit fortement bugs et plantages. Tes extractions risquent moins de s’interrompre, tu gagnes du temps et tu t’épargnes bien des tracas.
- Fiabilité : le compilateur de Rust impose un typage strict et une gestion des erreurs rigoureuse, si bien que de nombreux problèmes se repèrent avant même de lancer le code. À la clé, des workflows d’extraction stables et prévisibles.
- Concurrence : Rust facilite l’écriture de code qui mène plusieurs tâches de front (on y revient juste après), très utile pour extraire de nombreuses pages simultanément.
Comparé à Python ou JavaScript, plus accessibles pour débuter, Rust se distingue par sa robustesse et sa performance dès qu’il faut monter en charge. Tu collectes plus de données, plus vite, avec moins de complications techniques — de quoi conserver une longueur d’avance.
L’atout de l’asynchrone avec Rust : extraire en masse, sans prise de tête
C’est sur la programmation asynchrone que Rust marque vraiment des points. En résumé, le code asynchrone autorise ton extracteur à récupérer des données sur de nombreux sites en parallèle, sans attendre la fin de chaque requête avant d’en lancer une autre. Pour constituer de gros jeux de données en un temps record, c’est décisif.
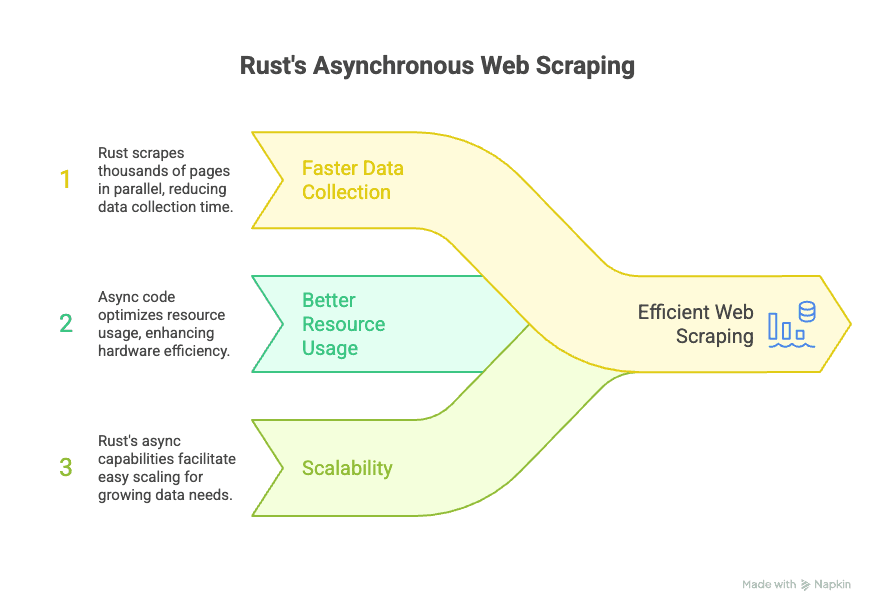
L’écosystème asynchrone de Rust repose sur des bibliothèques telles que Tokio et async-std, qui permettent à ton extracteur de traiter des milliers de requêtes en parallèle sans bloquer le reste. Pour les équipes métiers, cela signifie :
- Collecte ultra rapide : tu extrais des milliers de pages de front et réduis au minimum le temps nécessaire pour alimenter ta base.
- Ressources optimisées : le code asynchrone consomme moins, donc tu fais davantage avec moins de matériel.
- Capacité à grandir : si tes besoins en données explosent, l’asynchrone de Rust te permet de monter en puissance sans tout reconstruire.
En clair, ton équipe peut réagir en temps réel aux mouvements du marché, surveiller la concurrence ou générer des leads sans patienter des heures que les données arrivent.
Comment ça marche l’extraction web avec Rust ? Les grandes étapes
À quoi ressemble un workflow d’extraction web avec Rust ? En voici un aperçu simple, sans complication :
- Définir ce que tu veux : détermine les données à récupérer et les sites concernés.
- Récupérer les pages : appuie-toi sur des bibliothèques comme Reqwest pour télécharger les pages web.
- Analyser le contenu : sers-toi de Scraper ou Select pour extraire du HTML les informations visées (noms de produits, prix, emails, etc.).
- Gérer la pagination/sous-pages : ajoute la logique nécessaire pour passer d’une page à l’autre ou suivre des liens vers des sous-pages (on en parle juste après).
- Exporter les données : enregistre les résultats dans un format structuré (CSV, Excel, base de données) afin que tes équipes les exploitent immédiatement.
Chaque bibliothèque a son rôle : Reqwest pour récupérer les pages, Scraper/Select pour les analyser, et d’autres outils Rust ou externes pour exporter et organiser les résultats.
Gérer les sites complexes : pagination et sous-pages avec Rust
L’extraction se limite rarement à une seule page. Il faut parfois :
- Extraire l’ensemble des produits d’un catalogue paginé
- Récupérer des avis répartis sur plusieurs sous-pages
- Collecter des contacts dans des annuaires imbriqués
Rust se prête particulièrement bien à ces cas de figure. Son typage fort et sa gestion stricte des erreurs simplifient l’écriture de code capable de :
- Repérer et suivre automatiquement les liens de pagination ou les boutons « Suivant »
- Visiter les sous-pages (fiches produits, biographies, etc.) et fusionner ces données dans ton jeu principal
- Composer avec les imprévus (pages absentes, liens cassés) sans faire planter l’extracteur
Concrètement, un extracteur Rust peut partir d’une page de liste de produits, suivre chaque lien de pagination, puis ouvrir chaque fiche pour en tirer prix, description et avis. Le résultat : une base complète et à jour, prête pour l’analyse.
Thunderbit vs. Rust : le no-code qui change la vie des équipes métiers
Soyons honnêtes : tout le monde n’a ni le temps ni l’envie de développer un extracteur Rust sur mesure. C’est précisément là que Thunderbit entre en jeu.
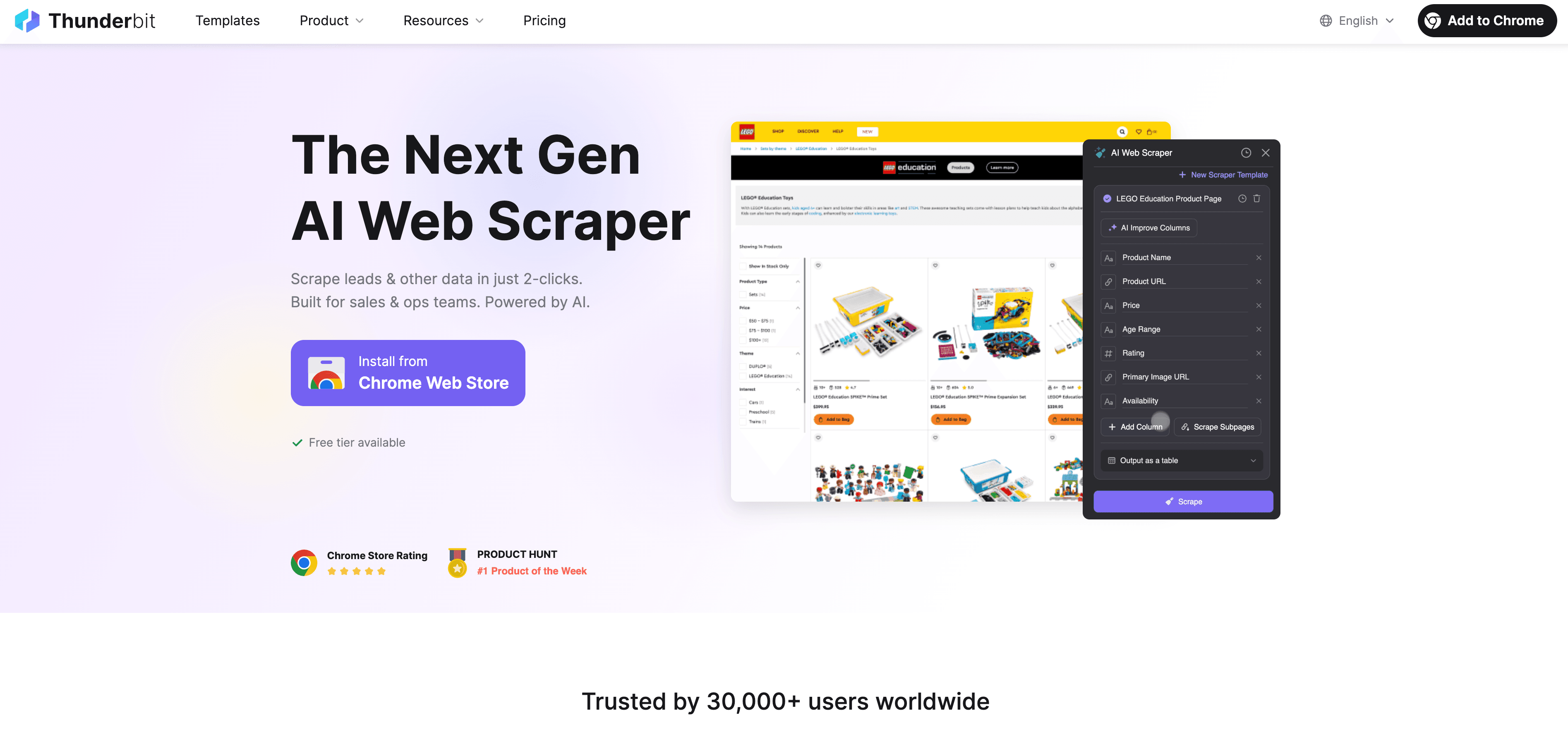
Thunderbit est un extracteur web IA sans code conçu pour les professionnels. Aucune ligne à écrire ; il suffit de :
- Ouvrir l’extension Chrome Thunderbit
- Te rendre sur le site à extraire
- Cliquer sur « Suggestions IA » pour que l’IA de Thunderbit propose les champs à récupérer
- Lancer l’extraction et exporter les résultats vers Excel, Google Sheets, Airtable ou Notion
Pas de template, pas de code, pas de maintenance. Thunderbit prend même en charge la pagination et l’extraction sur sous-pages de lui-même — comme un extracteur Rust sur mesure, mais derrière une interface d’une grande simplicité.
Essayez gratuitement l’Extracteur Web IA Thunderbit
Quand choisir Thunderbit plutôt que Rust ? Le bon choix selon ta situation
Alors, vers quoi pencher ? Voici un tableau récapitulatif :
| Scénario | Thunderbit | Rust |
|---|---|---|
| Génération rapide de leads commerciaux | ✅ Ultra simple et rapide | Possible, mais surdimensionné |
| Veille tarifaire concurrentielle (e-commerce) | ✅ No-code, planifiable | ✅ Pour intégrations sur mesure |
| Extraction de workflows complexes et personnalisés | Possible, mais limité | ✅ Contrôle total, très personnalisable |
| Pipelines de données intégrés à grande échelle | Possible (via API) | ✅ Idéal pour l’intégration profonde |
| Utilisateurs non techniques (vente, ops, marketing) | ✅ Conçu pour vous | ❌ Compétences en code requises |
| Besoin de prototypage rapide ou de tâches ponctuelles | ✅ Installation en 2 clics | Possible, mais plus long à mettre en place |
Pour résumer : Thunderbit convient parfaitement aux professionnels qui veulent extraire des données vite et bien, sans se compliquer la vie. Rust brille dès qu’il s’agit d’un contrôle total, d’une logique sur mesure ou d’une extraction à très grande échelle.
Cas concret : l’extraction web avec Rust en mode pratique
Prenons un exemple. Tu es analyste et tu dois rassembler toutes les informations sur les ordinateurs portables d’un grand site e-commerce. Le site recourt à la pagination (plusieurs pages de produits) et chaque produit dispose d’une fiche détaillée, avec caractéristiques et avis.
Avec Rust, tu vas :
- Utiliser Reqwest pour récupérer la page principale
- Analyser le HTML avec Scraper pour en extraire les liens produits
- Repérer et suivre le bouton « Suivant » afin de parcourir toutes les pages
- Pour chaque produit, ouvrir la fiche détaillée et en extraire les caractéristiques et les avis
- Composer solidement avec les erreurs (pages absentes, etc.), avec des tentatives automatiques
- Exporter le jeu de données final en CSV ou vers ta plateforme d’analyse
L’intérêt côté business ? Tu obtiens une vue complète et à jour du marché, de quoi mieux décider sur les prix, les stocks ou le marketing.
Les défis de l’extraction web avec Rust : ce qu’il faut garder en tête
Malgré tous ses atouts, l’extraction web avec Rust ne va pas sans difficultés. Voici les points à surveiller — et la façon dont Rust aide à les gérer :
- Évolution des sites : si la structure d’un site change, ton extracteur peut cesser de fonctionner. Le typage strict de Rust aide à détecter ces problèmes tôt, mais il faudra tout de même adapter le code.
- Anti-bots : beaucoup de sites recourent à des CAPTCHAs ou limitent les requêtes. La rapidité de Rust peut aider à rester discret, mais il faudra parfois ajouter des délais ou passer par des proxys.
- Qualité des données : les données ne sont pas toujours propres — les outils d’analyse de Rust aident à composer avec du HTML mal formé ou incohérent.
- Maintenance : un extracteur sur mesure réclame un suivi régulier. Pour les équipes métiers, cela suppose de collaborer avec des profils techniques, ou d’opter pour un outil no-code comme Thunderbit sur les tâches récurrentes.
Qu’est-ce que le data scraping et comment le faire en 2025 Get Started Free
Un conseil : que tu retiennes Rust ou Thunderbit, veille toujours à respecter les conditions d’utilisation des sites et la législation sur la vie privée lorsque tu extrais des données.
Conclusion : tirer plus de valeur business de l’extraction web en Rust (et au-delà)
L’extraction web est devenue un levier incontournable pour toute entreprise qui veut garder une longueur d’avance dans un environnement piloté par la donnée. Rust offre une performance, une sécurité et une fiabilité de premier ordre aux équipes techniques en quête de sur-mesure à grande échelle. Reste que la barrière technique demeure bien réelle pour la plupart des professionnels.
C’est là que Thunderbit se démarque : il rend l’extraction web accessible à tous, avec une interface no-code propulsée par l’IA, à même de gérer même les cas épineux comme la pagination ou l’extraction sur sous-pages. Commercial, responsable e-commerce ou analyste, Thunderbit te livre les données dont tu as besoin — rapidement.
À retenir :
- Rust fait référence pour l’extraction web sur mesure à grande échelle — parfait pour les équipes techniques.
- Thunderbit démocratise l’extraction web et la met à la portée de tous, même sans compétences techniques.
- Choisis l’outil adapté à tes besoins : Rust pour la personnalisation avancée, Thunderbit pour la rapidité et la simplicité.
Extraire des données de n’importe quel site avec l’IA Get Started Free
Envie de tester l’extraction web pour ta boîte ? Télécharge Thunderbit et constate à quel point la collecte de données peut être simple. Et si tu préfères investir dans du sur-mesure, explore l’écosystème Rust pour une extraction des plus performantes.
Essayez l’Extracteur Web IA Get Started Free
FAQ
1. C’est quoi l’extraction web avec Rust et en quoi c’est différent des autres langages ?
L’extraction web avec Rust consiste à employer ce langage pour automatiser la collecte de données sur des sites. Rust se distingue par sa rapidité, sa gestion irréprochable de la mémoire et sa fiabilité, ce qui en fait un excellent choix pour les extractions à grande échelle ou critiques, face à Python ou JavaScript.
2. Rust, c’est adapté aux utilisateurs métiers non techniques qui veulent faire de l’extraction web ?
Rust est puissant, mais il exige de savoir coder. Pour les profils non techniques, des outils comme Thunderbit proposent une approche no-code et pilotée par l’IA, qui met l’extraction à la portée de tous.
3. Comment Rust gère les tâches complexes comme la pagination ou les sous-pages ?
Grâce à son typage fort et à ses bibliothèques asynchrones, Rust facilite l’écriture de code qui navigue automatiquement dans les listes paginées, suit les liens vers les sous-pages et compose avec les erreurs — pour des jeux de données plus complets et fiables.
4. Quand utiliser Thunderbit plutôt que de développer un extracteur Rust sur mesure ?
Choisis Thunderbit pour une extraction rapide et simple, sans code — parfait pour les équipes commerciales, marketing ou ops. Opte pour Rust si tu vises un workflow très personnalisé, à grande échelle ou profondément intégré, avec une réelle expertise technique à la clé.
5. Quels sont les principaux défis de l’extraction web avec Rust et comment les gérer ?
Les difficultés classiques : l’évolution des sites, les anti-bots et la maintenance continue. Les fonctionnalités de sécurité de Rust aident à repérer les erreurs tôt, mais il faudra tout de même adapter le code avec le temps. Pour les extractions récurrentes, un outil no-code comme Thunderbit fait gagner du temps et évite bien des tracas.
Pour aller plus loin :




