Je me rappelle encore la toute première fois où j’ai voulu extraire une liste de prospects depuis un site web. Devant un vrai capharnaüm de code HTML, je me retrouvais à copier-coller noms et emails dans Excel, en me demandant s’il n’existait pas une méthode plus futée — ou si je venais tout simplement de me lancer dans une carrière d’archéologue du numérique. Aujourd’hui, l’extraction web a pris une place énorme. Mais voilà le truc : récupérer les données, c’est juste le début. La vraie magie, c’est de parser ces données brutes pour les rendre vraiment utiles à ton équipe.
Le parsing, c’est un peu le héros de l’ombre de l’extraction web. C’est lui qui transforme un gros tas de HTML en un tableau bien propre de prospects, de prix ou de fiches produits. Et vu que , le parsing n’est pas juste un détail technique : c’est ce qui fait la différence entre être noyé sous l’info et prendre des décisions qui comptent. Que tu bosses en vente, marketing, e-commerce ou immobilier, piger le parsing, c’est la clé pour transformer le web en vraie mine d’insights.
On va voir ensemble ce que c’est vraiment que le parsing, pourquoi c’est crucial, et comment des outils modernes (genre ) rendent ça accessible à tout le monde — même à ceux qui n’ont aucune envie de passer leurs week-ends à se prendre la tête avec les regex.
Démystifier le parsing : qu’est-ce que le parsing dans l’extraction web ?
Alors, le parsing, c’est quoi au juste ? Pour faire simple : le parsing, c’est l’art de transformer des données web en vrac et non structurées en un format structuré et exploitable. Imagine que tu traduis une langue étrangère — sauf qu’ici, la « langue », c’est le HTML, et la « traduction », c’est un tableau ou une base de données bien rangée.
Quand tu extrais un site, tu récupères souvent du contenu brut : HTML, JSON, ou un gros bloc de texte. C’est comme recevoir une boîte de pièces de puzzle sans l’image sur la boîte. Le parsing, c’est l’étape où tu tries les pièces, tu trouves les bords, et tu assembles le tout pour obtenir quelque chose de lisible — genre une liste de produits avec leurs prix, ou un annuaire de contacts.
Pour te donner une image : imagine qu’on te file une pile de tickets de caisse dans plein de langues, froissés et tachés de café. Le parsing, c’est lire chaque ticket, en sortir la date, le montant et le commerçant, puis tout rentrer dans un tableau. D’un coup, tes dépenses deviennent claires — sans migraine de traduction.
Exemple concret :
Supposons que tu extrais un site d’actualités et que tu obtiens ce HTML brut :
1<div class="article">
2 <h2>Article 1</h2>
3 <p>This is the first article content.</p>
4</div>
5<div class="article">
6 <h2>Article 2</h2>
7 <p>This is the second article content.</p>
8</div>Le parsing transforme ça en :
1{
2 "articles": [
3 { "title": "Article 1", "content": "This is the first article content." },
4 { "title": "Article 2", "content": "This is the second article content." }
5 ]
6}Au lieu de te battre avec du HTML, tu as maintenant un jeu de données prêt à être analysé. Voilà le parsing en action.
Pour creuser le sujet, va voir .
Pourquoi le parsing est-il important : la valeur métier du parsing de données
Le parsing, ça peut sembler technique, mais son impact business est énorme. Voilà pourquoi :
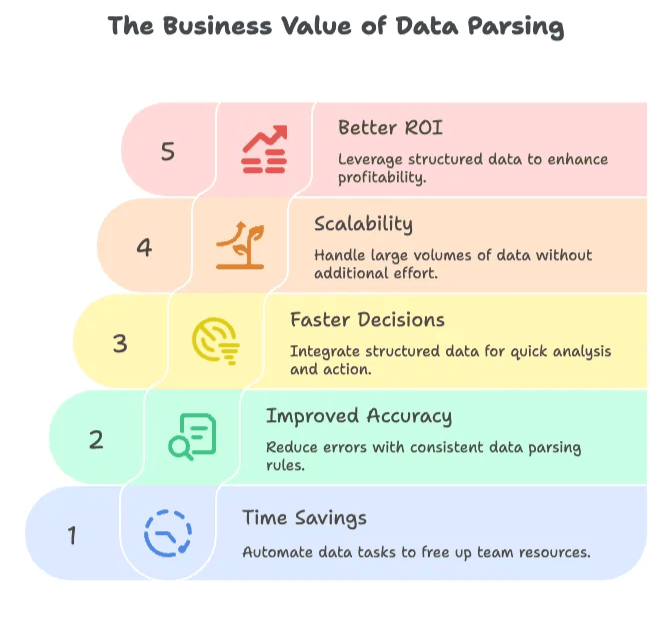
- Gain de temps : Fini le copier-coller à la main ou le nettoyage interminable. Le parsing automatise tout ça, et ton équipe peut se concentrer sur ce qui compte vraiment. grâce à l’automatisation de la collecte et du parsing des données.
- Précision au top : Les erreurs humaines, c’est fini ; un parseur ne se trompe pas et ne fatigue jamais. Les règles sont appliquées pareil pour tout le monde, donc moins de fautes et d’oublis.
- Décisions plus rapides : Les données structurées s’intègrent direct dans tes outils d’analyse ou ton CRM. Plus besoin d’attendre qu’un fichier Excel soit « nettoyé ».
- Scalabilité : Une fois le parseur en place, il peut traiter des centaines ou des milliers de pages sans effort en plus.
- Meilleur ROI : Des données structurées, c’est tout de suite exploitable. Les boîtes qui bossent vraiment leurs données sont .
Petit résumé :
| Bénéfice clé | Comment le parsing de données crée de la valeur |
|---|---|
| Gain de temps | Automatise l’extraction et le nettoyage — quelques minutes au lieu d’heures ou de jours |
| Précision & Cohérence | Applique une structure uniforme, réduit les erreurs humaines et garantit la qualité des champs |
| Insights exploitables | Transforme l’information brute en données prêtes à l’analyse pour des décisions immédiates |
| Scalabilité | Gère de gros volumes sans effort supplémentaire |
| Meilleur ROI | Optimise l’utilisation des données extraites pour des résultats concrets |
Sans parsing, tu as une botte de foin numérique. Avec le parsing, tu obtiens une pile d’aiguilles en or — prêtes à l’emploi.
Parsing vs. extraction de données : quelle différence ?
On confond souvent les deux : scraping et parsing, ce n’est pas pareil — mais l’un ne va pas sans l’autre.
- Extraction de données (scraping) : c’est la collecte brute des infos sur les sites. Imagine un aspirateur qui ramasse tout : texte, images, HTML, etc.
- Parsing de données : c’est l’organisation de ces données. C’est le filtre qui sépare ce qui compte du reste.
Voilà comment ça s’enchaîne :
- Étape scraping : Tu utilises un outil pour récupérer le HTML brut d’une page produit, par exemple.
- Étape parsing : Tu extrais le nom, le prix et la description du produit, puis tu organises tout ça dans un tableau ou une base de données.
C’est comme extraire de l’or (scraping) puis le transformer en bijoux (parsing). Le scraping te donne la matière première ; le parsing la rend précieuse.
Pour une explication détaillée, va voir .
Comment le parsing propulse les outils modernes d’extraction web
Avant, parser voulait dire coder — beaucoup. Pour extraire des prix d’un site, il fallait plonger dans Python, BeautifulSoup et les expressions régulières. (Si tu ne sais pas ce qu’est une regex, tu peux t’estimer heureux !)
Mais aujourd’hui, tout a changé. Les outils modernes d’extraction web intègrent le parsing directement dans le process — souvent grâce à l’IA. Plus besoin d’être développeur pour transformer des données web en infos prêtes à l’emploi.
Prenons par exemple. Son extracteur web boosté à l’IA ne se contente pas de collecter les données — il les comprend. Quand tu cibles une page, l’IA « lit » le contenu comme un humain, repère les structures (listes de produits, contacts, etc.) et extrait automatiquement les infos clés.
Les outils modernes d’extraction web intègrent le parsing directement dans le flux de travail — souvent grâce à l’IA. Plus besoin d’être développeur pour transformer des données web en informations exploitables.
Parsing intelligent avec Thunderbit : mettez le web à votre service
Voilà comment Thunderbit rend le parsing accessible, même si tu n’as aucune compétence technique :
1. Suggestion de champs par l’IA
Sur une page web, clique simplement sur « Suggestion de champs IA ». L’IA de Thunderbit analyse la page et propose les champs clés — Nom, Entreprise, Email, Prix, etc. Elle suggère même le type de données adapté (texte, nombre, URL…).
Fini de galérer à deviner quelles balises HTML viser. L’IA fait le boulot, tu n’as plus qu’à choisir ce qui t’intéresse.
2. Prompt IA pour chaque champ
Tu veux personnaliser l’extraction d’un champ ? Thunderbit te permet d’ajouter des instructions en langage naturel. Par exemple :
- « Formater le numéro de téléphone au format E.164 »
- « Ne prendre que la première phrase de la description »
- « Traduire tout le texte en anglais »
Tu peux donc étiqueter, formater ou traduire les données à la volée — sans étape en plus.
3. Extraction sur les sous-pages
Parfois, les détails que tu cherches sont sur des sous-pages (fiches produit, profils, etc.). Thunderbit peut aller automatiquement sur chaque sous-page, parser les infos complémentaires et enrichir ton jeu de données principal. C’est comme avoir un assistant qui ne demande jamais d’augmentation (et ne prend pas de pause café).
4. Gestion multilingue et formats intelligents
Thunderbit gère , et l’IA peut traduire ou normaliser les données instantanément. Tu veux tous les prix en USD ? Des dates au même format ? Il suffit de le demander.
5. Données prêtes à l’export
Après parsing, exporte tes données vers Excel, Google Sheets, Airtable, Notion, CSV ou JSON — gratuitement. Plus besoin de copier-coller ou de tout reformater.
Exemple concret :
Tu veux extraire un annuaire de professionnels. Avec Thunderbit :
- Clique sur « Suggestion de champs IA » pour détecter automatiquement Nom, Entreprise, Email, Téléphone…
- Ajoute un prompt pour formater les numéros de téléphone.
- Clique sur « Extraire » et laisse Thunderbit constituer ta liste de prospects.
- Exporte vers Excel, et c’est dans la poche.
Pour un tuto détaillé, va voir notre .
Cas d’usage : où le parsing fait la différence dans l’extraction web
Le parsing, ce n’est pas réservé aux geeks — c’est utile pour tous les métiers. Quelques exemples :
| Cas d’usage | Comment le parsing crée de la valeur |
|---|---|
| Génération de leads | Transforme des annuaires ou résultats LinkedIn en listes structurées (Nom, Email, Entreprise, etc.) |
| Veille tarifaire | Structure les données produits et prix des concurrents pour une comparaison instantanée |
| Études de marché & analyse de sentiment | Organise avis, commentaires ou posts sociaux pour l’analyse de tendances |
| Annonces immobilières | Extrait les détails (adresse, prix, caractéristiques) dans un format uniforme |
| Construction de catalogues produits | Agrège les infos produits de plusieurs sources pour l’e-commerce |
| Agrégation de contenus | Parse les données d’actualités ou de blogs (titres, auteurs, dates) pour la veille ou la curation |
| Collecte de données financières | Structure bilans, cours de bourse ou données alternatives pour l’analyse |
Pour plus d’idées, découvre .
Parsing en pratique : exemple pas à pas pour les utilisateurs métier
Prenons un cas concret — sans écrire une seule ligne de code.
Scénario : Tu bosses en sales ops et tu veux te faire une liste de prospects à partir d’un annuaire sectoriel.
Étape 1 : Va sur la page de l’annuaire dans Chrome.
Étape 2 : Ouvre l’.
Étape 3 : Clique sur « Suggestion de champs IA ». Thunderbit analyse la page et propose des champs comme Nom, Entreprise, Email, URL du profil.
Étape 4 : Ajoute un prompt IA si besoin, genre « mettre l’email en minuscules ».
Étape 5 : Clique sur « Extraire ». Thunderbit collecte et parse les données, qui s’affichent dans un tableau dans l’extension.
Étape 6 : Si des sous-pages existent (profils détaillés), clique sur « Extraire les sous-pages » pour enrichir tes données.
Étape 7 : Prévisualise les données extraites. Ajuste si besoin.
Étape 8 : Exporte vers Excel, Google Sheets ou l’outil de ton choix.
En quelques clics, tu as une liste de prospects propre et structurée — sans copier-coller, sans prise de tête avec le HTML.
Pour plus de visuels étape par étape, va voir notre .
Défis et pièges : à quoi faire attention lors du parsing de données
Le parsing, ce n’est pas toujours un long fleuve tranquille. Voici les principaux pièges — et comment les éviter :
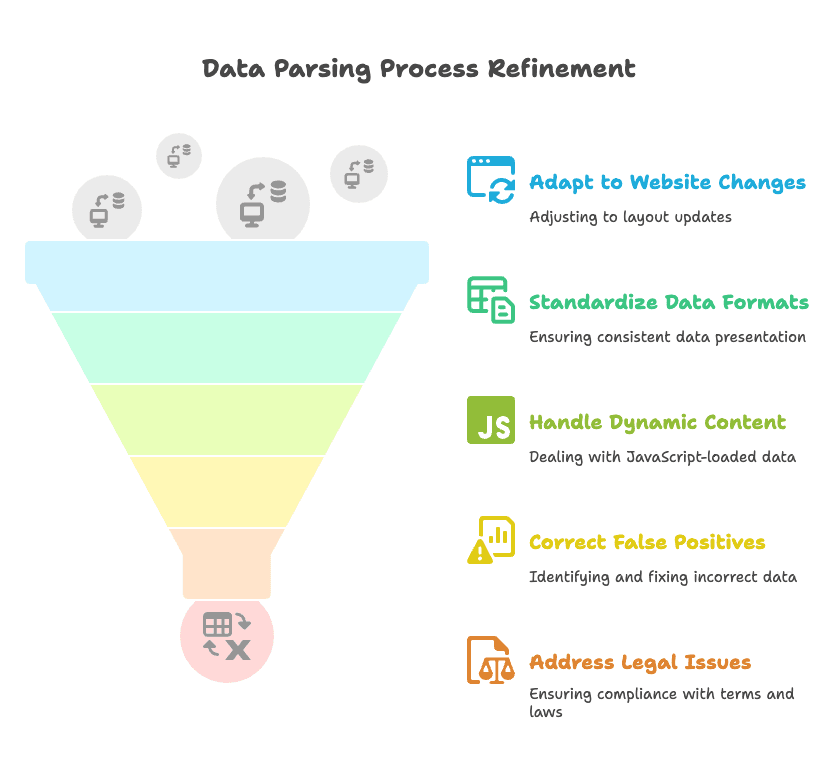
- Changements de structure des sites : Les sites changent, ce qui peut casser les parseurs. Les outils IA comme Thunderbit s’adaptent mieux que le code figé, mais garde toujours un œil sur tes résultats et relance « Suggestion de champs IA » si besoin.
- Formats de données incohérents : Un prix peut s’afficher « 199 € » ou « Prix sur demande ». Utilise les prompts IA pour standardiser, et fais une vérif rapide après parsing.
- Contenu dynamique : Certains sites chargent les données en JavaScript ou cachent des infos derrière des clics. Les outils basés sur navigateur (comme Thunderbit) voient ce que tu vois, mais pour les cas tordus, il faudra parfois ruser.
- Faux positifs : Parfois, le parseur sort la mauvaise info. Prévisualise toujours tes résultats et ajuste les champs si besoin.
- Questions légales et éthiques : Toutes les données ne sont pas en libre accès. Vérifie toujours les conditions d’utilisation du site et respecte la législation sur la vie privée.
Pour plus de conseils, va voir .
Choisir la bonne solution de parsing pour votre entreprise
Faut-il développer son propre parseur ou utiliser un outil tout prêt ? Voici un comparatif rapide :
| Critère | Développer un parseur sur-mesure | Utiliser un outil prêt à l’emploi (ex : Thunderbit) |
|---|---|---|
| Temps de mise en place | Long — nécessite du code et des tests | Court — configuration en quelques minutes avec l’IA |
| Compétences requises | Programmation (Python/JS, HTML/DOM) | Aucun code ; pensé pour les utilisateurs métier |
| Maintenance | À votre charge lors des changements de site | Mises à jour gérées par le fournisseur ; l’IA s’adapte |
| Scalabilité | À vous de gérer l’infrastructure | Scalabilité cloud et gestion des proxys intégrées |
| Personnalisation | Totalement personnalisable si vous codez | Flexible via prompts IA, dans les limites de l’outil |
| Coût | Pas de licence, mais main d’œuvre et maintenance élevées | Abonnement ou paiement à l’usage ; souvent gratuit pour les petits besoins |
| Support | Débrouille maison | Support éditeur et communauté |
| Contrôle des données | Tout reste en interne | Les données transitent par les serveurs du fournisseur (vérifiez la sécurité) |
Pour la plupart des équipes, surtout si tu ne veux pas développer en interne, choisir un outil comme Thunderbit, c’est la solution la plus rapide et économique. Teste-le sur un projet pilote pour voir si ça colle à tes besoins avant de t’engager.
Pour la plupart des équipes, surtout si tu ne veux pas développer en interne, choisir un outil comme Thunderbit, c’est la solution la plus rapide et économique. Teste-le sur un projet pilote pour voir si ça colle à tes besoins avant de t’engager.
Conclusion : libérez la puissance du parsing dans l’extraction web
Le parsing, c’est le pont entre le chaos du web et la donnée exploitable. C’est lui qui transforme une botte de foin numérique en mine d’or d’insights. Dans un monde où , le parsing n’est plus une option — c’est une nécessité.
La bonne nouvelle ? Les outils modernes, boostés par l’IA comme , rendent le parsing accessible à tous. Avec des fonctions comme la suggestion de champs IA, les prompts personnalisés et l’extraction sur sous-pages, tu passes du web brut au tableau structuré en quelques minutes — sans coder, sans prise de tête.
Que tu construises des listes de prospects, surveilles les prix, analyses des avis ou en aies marre du copier-coller, le parsing est ton allié secret. Commence petit, vise grand, et laisse le web bosser pour toi.
Prêt à transformer le web en avantage business ? Essaie et découvre à quel point le parsing peut être simple.
Envie d’en savoir plus ? Va jeter un œil aux autres ressources sur le , comme ou .
FAQ
1. Qu’est-ce que le parsing de données dans l’extraction web ?
Le parsing de données, c’est convertir des infos web brutes ou en vrac — genre du HTML — en formats structurés comme des tableaux, des feuilles de calcul ou des bases de données. C’est l’étape qui rend les données extraites vraiment exploitables pour l’analyse, l’automatisation ou la prise de décision.
2. Quelle est la différence entre parsing et extraction web ?
L’extraction web récupère les données brutes sur les sites, alors que le parsing les organise et les affine pour qu’elles soient utilisables. Imagine le scraping comme la collecte des ingrédients, et le parsing comme la préparation d’un plat prêt à servir.
3. Pourquoi le parsing est-il important pour les entreprises ?
Le parsing fait gagner un temps fou, améliore la précision et fournit des insights exploitables. Il permet d’automatiser des tâches comme la génération de leads, la veille tarifaire ou les études de marché — transformant le contenu web complexe en jeux de données propres pour l’analyse et la décision.
4. Comment Thunderbit facilite-t-il le parsing de données ?
Thunderbit utilise l’IA pour suggérer les champs, formater les données, suivre les sous-pages et exporter des données structurées — sans code. Les utilisateurs peuvent personnaliser la logique de parsing avec des instructions en langage naturel, rendant l’outil accessible même sans compétences techniques.
5. Quels sont les défis courants du parsing de données ?
Les principaux défis sont les changements de structure des sites, les formats incohérents, le contenu dynamique et les faux positifs. Des outils comme Thunderbit limitent ces problèmes grâce au parsing piloté par l’IA, à la gestion des sous-pages et à l’aperçu en temps réel pour garantir la qualité des résultats.