
Surveiller des centaines de sites concurrents à la main, ça revient à recopier l'annuaire au stylo : impossible sans une petite armée derrière toi (et beaucoup trop de café). Si tu t'es déjà retrouvé dans cette situation, tu n'es pas un cas isolé, loin de là. La donnée web est devenue une vraie matière première pour les entreprises — vente, marketing, recherche, opérations, tout le monde en veut. Le web scraping pèse d'ailleurs aujourd'hui plus d'un tiers du trafic internet, et 81 % des entreprises américaines s'appuient sur des extracteurs automatiques rien que pour surveiller les prix (scrap.io). En clair : ce sont les bots qui font le travail ingrat à notre place.
Reste à comprendre comment ces robots s'y prennent. Et pourquoi tant d'équipes choisissent Node.js — le moteur JavaScript qui propulse une grande partie du web — pour construire leur extracteur. Après plusieurs années passées dans le SaaS et l'automatisation, et en tant que CEO de Thunderbit, j'ai vu à quel point les bons outils peuvent transformer la collecte de données en véritable avantage métier. On va donc voir ensemble ce qu'est un extracteur web Node, comment il fonctionne, et pourquoi tu peux t'y mettre même sans coder.
Extracteur web Node : les bases
Qu'est-ce que le data scraping et comment le faire en 2025 Get Started Free
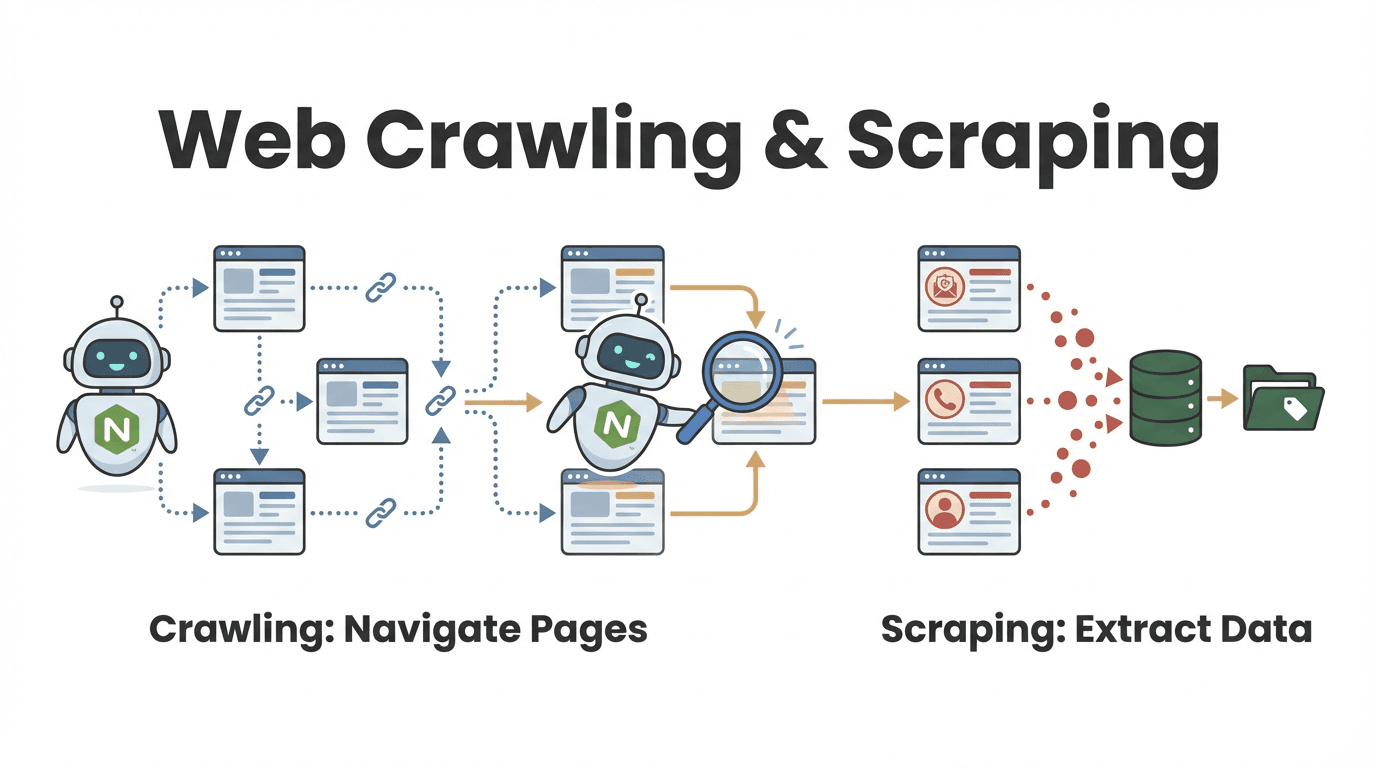
Allons à l'essentiel. Un extracteur web Node, c'est un programme écrit avec Node.js qui parcourt automatiquement des pages web, suit les liens et récupère les informations qui t'intéressent. Vois-le comme un assistant numérique qui ne dort jamais : tu lui donnes une URL de départ, il navigue, il collecte les données et il poursuit jusqu'à avoir ratissé tout ce qu'il te faut sur le site (ou la portion qui te concerne).
Et la différence entre exploration web (web crawling) et extraction web (web scraping), alors ? La question revient souvent, surtout côté métier :
- Exploration web : il s'agit de découvrir et parcourir un grand nombre de pages. Comme si tu feuilletais tous les ouvrages d'une bibliothèque pour repérer ceux qui valent le coup.
- Extraction web : il s'agit de récupérer des informations précises sur ces pages — comme recopier les meilleures citations de chaque livre.
Dans la pratique, la plupart des extracteurs web Node font les deux : ils trouvent les pages utiles et en extraient les données voulues (oxylabs.io). Une équipe commerciale peut par exemple explorer un annuaire pour lister tous les profils d'entreprise, puis extraire les coordonnées de chaque fiche.
Comment fonctionne un extracteur web Node ?
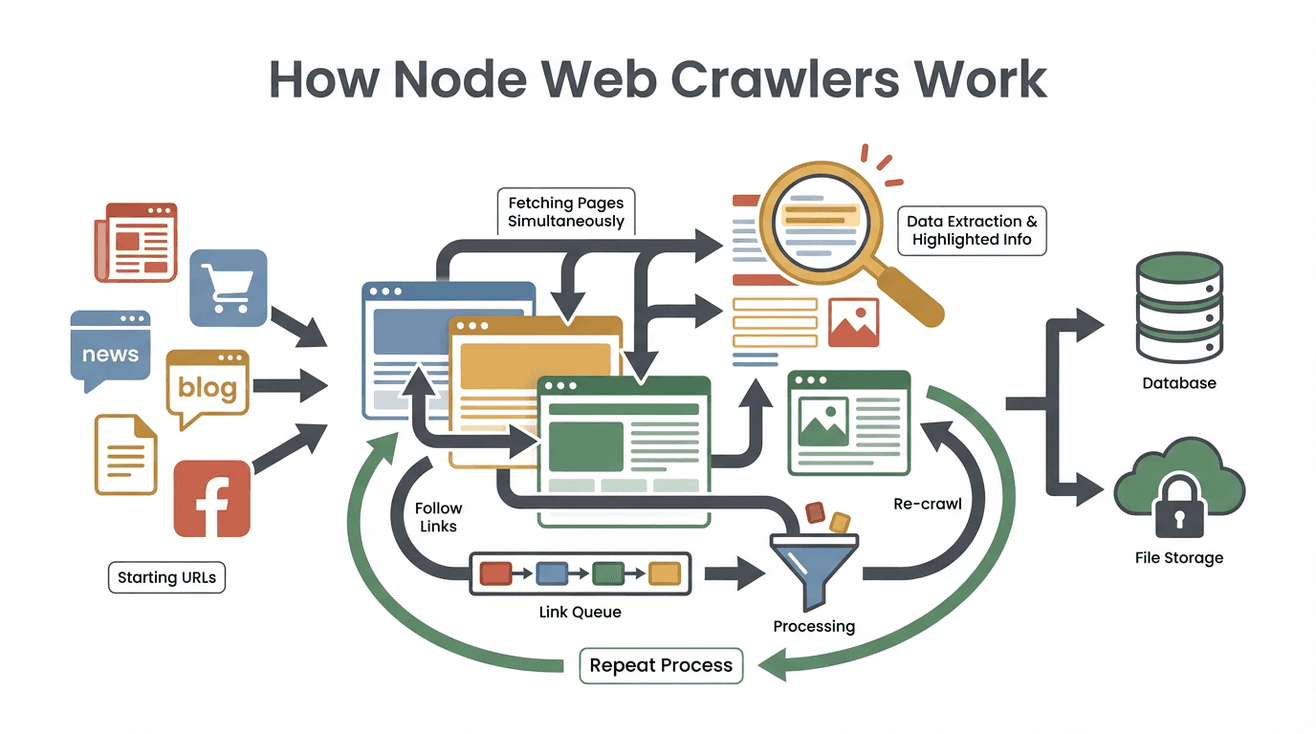
Pas de mystère ici. Voici, étape par étape, comment travaille un extracteur web Node classique :
- Définir les URLs de départ : tu fournis au robot une ou plusieurs adresses initiales (page d'accueil, liste de produits, etc.).
- Télécharger le contenu des pages : l'extracteur récupère le code HTML de chaque page — comme un navigateur, mais sans l'affichage.
- Extraire les données utiles : à l'aide d'outils comme Cheerio (le jQuery de Node), il repère et extrait les informations voulues : noms, prix, emails, etc.
- Détecter et ajouter de nouveaux liens : il analyse chaque page pour y trouver d'autres liens (« page suivante », détails produit) et les ajoute à sa liste de tâches (le « front de crawl »).
- Répéter le processus : l'extracteur visite les nouveaux liens, extrait les données et étend sa couverture jusqu'à avoir tout collecté selon tes critères.
- Stocker les résultats : toutes les données extraites sont sauvegardées — souvent en CSV, en JSON ou directement dans une base de données.
- S'arrêter à la fin : le robot termine quand il n'a plus de nouveaux liens à explorer ou qu'il atteint une limite fixée.
Un cas concret : tu veux toutes les offres d'emploi d'un site carrière. Tu pars de la page principale, tu récupères les liens des annonces, tu visites chaque fiche, tu collectes les détails, et tu continues jusqu'à avoir l'ensemble du catalogue.
Le ressort de tout cela ? L'architecture événementielle et non bloquante de Node.js, qui permet à l'extracteur de traiter une multitude de pages simultanément, sans attendre que chaque site réponde. C'est un peu comme disposer d'une équipe d'assistants travaillant en parallèle — sans la note de pizza à la fin.
Pourquoi Node.js cartonne pour les extracteurs web ?
Pourquoi Node.js plutôt que Python, Java ou autre chose ? Voici ce qui fait sa force pour l'extraction web :
- Entrées/sorties événementielles et non bloquantes : Node.js gère des dizaines, voire des centaines de requêtes en même temps, sans ralentir. Le temps qu'une page charge, il en traite déjà d'autres (blog.apify.com).
- Excellentes performances : Node tourne sur le moteur V8 de Google (le même que Chrome), ce qui le rend très rapide pour analyser et traiter de gros volumes de données web.
- Écosystème complet : il existe une bibliothèque Node pour à peu près tout — Cheerio pour parser le HTML, Got pour les requêtes HTTP, Puppeteer pour la navigation sans interface, et des frameworks comme Crawlee pour les gros volumes (scrapingdog.com).
- Affinité avec JavaScript : la majorité des sites tournant en JavaScript, Node.js s'y intègre naturellement. Il manipule aussi très bien les données JSON, omniprésentes sur le web.
- Capacité temps réel : besoin de surveiller de nombreux sites pour repérer des variations de prix ou des actualités ? Node gère la concurrence quasiment en temps réel.
Rien d'étonnant à ce que des outils Node comme Crawlee et Cheerio soient utilisés par plus d'un tiers des développeurs spécialisés dans l'extraction web.
Fonctions clés d'un extracteur web Node
Les extracteurs web Node tiennent un peu de l'outil tout-en-un de la donnée web. Voici leurs fonctions principales — et la façon dont elles répondent aux besoins métier :
| Fonctionnalité | Comment ça marche avec Node | Exemple d'usage métier |
|---|---|---|
| Navigation automatisée | Suit automatiquement les liens et les pages paginées | Génération de leads : explorer toutes les pages d’un annuaire en ligne |
| Extraction de données | Récupère des champs précis (nom, prix, contact) via des sélecteurs ou motifs | Veille tarifaire : extraire les prix produits chez les concurrents |
| Gestion multi-pages simultanée | Télécharge et traite de nombreuses pages en parallèle (grâce à l’asynchrone Node.js) | Actualités en temps réel : surveiller plusieurs sites d’info à la fois |
| Sortie de données structurée | Sauvegarde les résultats en CSV, JSON ou directement en base de données | Analytics : alimenter des tableaux de bord BI ou des CRM |
| Logique & filtres personnalisés | Ajout de règles, filtres ou nettoyage de données personnalisés dans le code | Contrôle qualité : ignorer les pages obsolètes, transformer les formats de données |
Une équipe marketing peut par exemple s'appuyer sur un extracteur Node pour collecter tous les articles de blog d'un secteur, en extraire les titres et les URLs, puis verser le tout dans Google Sheets afin de planifier ses contenus.
Thunderbit : l'alternative no-code aux extracteurs web Node
Essayez l'Extracteur Web IA Thunderbit Extrayez des données de n'importe quel site en 2 clics — sans coder. Get Started Free
C'est là que ça devient nettement plus accessible pour qui ne code pas. Thunderbit est une extension Chrome d'extraction web pilotée par l'IA, qui te permet de collecter des données web sans écrire la moindre ligne de code.
Le principe ? Tu ouvres l'extension, tu cliques sur « Suggestions IA de champs », et l'IA de Thunderbit analyse la page, te propose les données pertinentes à extraire et les organise dans un tableau. Tu veux tous les noms et prix de produits d'un site ? Tu le formules en français, Thunderbit s'occupe du reste. Besoin d'aller chercher dans les sous-pages ou de gérer la pagination ? Un clic suffit.
Quelques points forts de Thunderbit :
- Interface en langage naturel : tu décris ce que tu veux, l'IA gère la partie technique.
- Suggestions de champs IA : Thunderbit analyse la page et te propose les meilleures colonnes à extraire.
- Exploration de sous-pages sans code : récupère les pages de détail (produits, profils…) et fusionne les données automatiquement.
- Export structuré : envoie tes données directement dans Excel, Google Sheets, Airtable ou Notion.
- Export de données gratuit : aucun frais caché pour télécharger tes résultats.
- Automatisation & planification : programme des extractions récurrentes en langage naturel (« chaque lundi à 9 h »).
- Extraction de contacts : récupère en un clic emails, numéros de téléphone et images — entièrement gratuit.
Pour un professionnel, cela revient à passer de « il me faut ces données » à « voilà mon tableau » en quelques minutes plutôt qu'en plusieurs jours. Et d'après les avis utilisateurs, même des profils non techniques montent des listes de prospects, surveillent les prix et mènent leur veille — sans jamais toucher au code.
Essayez Thunderbit gratuitement sur Chrome
Comparatif : extracteur web Node vs Thunderbit pour les pros
Alors, vers quoi pencher ? Voici un comparatif clair :
| Critère | Extracteur web Node.js (code personnalisé) | Thunderbit (extracteur IA sans code) |
|---|---|---|
| Temps de mise en place | De quelques heures à plusieurs jours (dev, debug, config) | Quelques minutes (installation, clic, extraction) |
| Compétences requises | Programmation nécessaire (Node.js, HTML, sélecteurs) | Aucun code ; langage naturel & clics |
| Personnalisation | Extrêmement flexible ; toute logique ou workflow possible | Limité aux fonctions intégrées et à l’IA |
| Scalabilité | Peut monter en charge (serveurs, proxies, etc.) | Grattage cloud intégré pour des volumes moyens à élevés |
| Maintenance | Continue (adapter le code aux changements de sites) | Minime (l’IA de Thunderbit s’adapte automatiquement) |
| Gestion anti-bot | À gérer soi-même (proxies, délais, navigation headless…) | Géré automatiquement par Thunderbit |
| Intégration | Intégration poussée possible (API, bases, workflows) | Export vers Sheets, Notion, Airtable, Excel, CSV |
| Coût | Outils gratuits, mais temps dev et serveurs à prévoir | Offre gratuite, puis paiement à l’usage ou abonnement |
À privilégier avec Node.js :
- Tu as besoin d'une logique ou d'une intégration très personnalisée.
- Tu disposes de ressources dev et tu veux tout maîtriser.
- Tu fais de l'extraction à très grande échelle ou tu construis un produit autour de la donnée web.
À privilégier avec Thunderbit :
- Tu cherches des résultats rapides, sans complication.
- Tu n'as pas de compétences techniques (ou pas l'envie de coder).
- Tu mènes des extractions variées pour les besoins métier du quotidien.
- Tu places la simplicité et l'adaptabilité de l'IA en priorité.
Beaucoup d'équipes démarrent avec Thunderbit pour avancer vite, puis basculent vers du Node sur-mesure dès que leurs besoins gagnent en ampleur ou en complexité.
Les défis courants avec les extracteurs web Node
Les extracteurs Node sont puissants, mais ils ne vont pas sans quelques difficultés. Voici les principaux écueils — et comment les anticiper :
- Défenses anti-scraping : les sites multiplient les CAPTCHAs, bloquent les IP et détectent les bots. Il faut alors gérer la rotation de proxies, ajuster les en-têtes et parfois simuler une vraie navigation avec Puppeteer (blog.apify.com).
- Contenu dynamique : beaucoup de sites chargent leurs données en JavaScript ou via le défilement infini. Un simple parsing HTML ne suffit pas — il faut parfois simuler la navigation ou passer par des APIs.
- Nettoyage et parsing des données : les pages web sont rarement bien rangées. Il faut composer avec des formats étranges, des données manquantes, des encodages capricieux.
- Maintenance : les sites évoluent. Ton code peut casser. Prévois des mises à jour régulières et une gestion des erreurs solide.
- Aspects légaux et éthiques : respecte toujours le
robots.txt, les conditions d'utilisation et la législation sur la vie privée. N'extrais pas de données sensibles ou protégées.
Bonnes pratiques :
- Appuie-toi sur des frameworks comme Crawlee, qui prennent déjà en charge bon nombre de ces problèmes.
- Prévois des relances, des délais et des journaux d'erreur.
- Mets tes extracteurs à jour régulièrement.
- Reste responsable : ne sature pas les sites et respecte leurs règles.
Intégrer un extracteur web Node avec le cloud
Pour des projets de collecte de données sérieux et récurrents, faire tourner ton extracteur Node sur ta machine ne suffit plus. D'où l'intérêt du cloud :
- Fonctions serverless : déploie ton extracteur Node sous forme de fonction AWS Lambda ou Google Cloud Function. Programme son exécution automatique (chaque jour, chaque heure…), et stocke les résultats sur S3 ou BigQuery (docs.aws.amazon.com).
- Extracteurs conteneurisés : emballe ton extracteur dans un Docker et fais-le tourner sur AWS Fargate, Google Cloud Run ou Kubernetes. Idéal pour traiter des milliers de pages en parallèle.
- Workflows automatisés : sers-toi de planificateurs cloud (AWS EventBridge, entre autres) pour déclencher les extractions, stocker les résultats et alimenter des dashboards ou des modèles d'IA.
Les bénéfices ? Scalabilité, fiabilité et automatisation sans tracas. D'ailleurs, 68 % des extractions web se font désormais dans le cloud — et cette part grimpe d'année en année.
Quand choisir un extracteur web Node ou une solution no-code ?
Tu hésites encore ? Voici un guide express pour trancher :
-
Besoin de personnalisation poussée, de workflows uniques ou d'une intégration avec tes systèmes internes ?
→ Extracteur web Node.js -
Tu veux des données rapidement, sans coder ?
→ Thunderbit (ou un autre outil no-code) -
Tâche ponctuelle ou peu fréquente ?
→ Thunderbit -
Projet critique, récurrent, à grande échelle ?
→ Node.js (avec intégration cloud) -
Tu disposes de ressources dev et de temps pour la maintenance ?
→ Node.js -
Tu veux rendre tes équipes non techniques autonomes sur la donnée ?
→ Thunderbit
Mon conseil ? Commence par le no-code pour des résultats rapides et des prototypes. Si tes besoins évoluent, tu pourras toujours investir dans un extracteur Node sur-mesure. Beaucoup d'équipes constatent que Thunderbit couvre 90 % de leurs cas d'usage — et leur fait gagner un temps précieux.
Commencez avec l'Extracteur Web IA Thunderbit
Conclusion : Libère la puissance de la donnée web pour ton business
L'extraction de données web n'est plus l'affaire des seuls « geeks » : elle est devenue un levier incontournable pour les entreprises. Que tu développes ton propre extracteur web Node ou que tu emploies un outil IA comme Thunderbit, le but reste le même : transformer le chaos du web en informations structurées et exploitables.
Node.js, c'est le summum de la flexibilité et de la puissance, surtout pour les projets lourds ou à grande échelle. Mais pour la plupart des professionnels, la montée en puissance des outils no-code et de l'IA suffit à obtenir les données voulues — vite, de façon fiable et sans coder.
Alors que près de 97 % des organisations investissent dans le Big Data et l'IA, les équipes qui maîtrisent la donnée web prennent une véritable longueur d'avance. Que tu sois développeur, marketeur ou simplement las du copier-coller, le moment est idéal pour mettre la puissance de l'exploration web à ton service.
Envie de tester par toi-même ? Télécharge Thunderbit gratuitement et vois à quel point l'extraction de données web peut être simple. Pour aller plus loin, parcours le blog Thunderbit, riche en guides, astuces et retours d'expérience sur l'automatisation web.
Essayez l'Extracteur Web IA gratuitement Get Started Free
FAQ
1. Quelle est la différence entre un extracteur web Node et un extracteur web classique ?
Un extracteur web Node découvre et parcourt automatiquement les pages web (à la manière d'une araignée sur sa toile), tandis qu'un extracteur web classique se concentre sur la récupération de données précises. La plupart des extracteurs Node font les deux : ils trouvent les pages et en extraient les informations utiles.
2. Pourquoi Node.js est-il populaire pour créer des extracteurs web ?
Node.js est événementiel et non bloquant, ce qui lui permet de traiter de nombreuses requêtes en parallèle. Il est rapide, doté d'un écosystème de bibliothèques considérable, et parfaitement taillé pour l'extraction de données en temps réel ou à grande échelle.
3. Quels sont les principaux défis avec les extracteurs web Node ?
Les difficultés classiques : protections anti-bot (CAPTCHAs, blocages IP), contenu dynamique (sites bourrés de JavaScript), nettoyage des données et maintenance continue au fil des changements de sites. Les frameworks et les bonnes pratiques aident, mais des compétences techniques restent nécessaires.
4. En quoi Thunderbit diffère-t-il d'un extracteur web Node ?
Thunderbit est un extracteur web IA sans code. Plutôt que de coder, tu utilises une extension Chrome et le langage naturel pour extraire tes données. Idéal pour les professionnels qui veulent des résultats rapides, sans programmation.
5. Quand utiliser un extracteur web Node ou Thunderbit ?
Choisis Node.js pour des projets très personnalisés, à grande échelle ou exigeant une intégration poussée — surtout si tu as des ressources dev. Privilégie Thunderbit pour des extractions rapides, quotidiennes, ou pour rendre tes équipes non techniques autonomes sur la donnée.
Prêt à passer à la vitesse supérieure ? Teste Thunderbit ou explore le blog Thunderbit pour aller plus loin. Bonne exploration !
Pour aller plus loin




