Vous est-il déjà arrivé de tomber sur une page web quasi vide, où il faut cliquer sur une ribambelle de liens pour enfin mettre la main sur les infos qu’il vous faut ? C’est franchement galère, surtout que de plus en plus de sites planquent leurs données importantes dans des sous-pages. Résultat : collecter des données en masse devient un vrai parcours du combattant. Les développeurs se retrouvent à coder des scripts pendant des heures pour explorer ces sous-pages, pendant que les moins techniques cliquent à la main sur chaque lien. Heureusement, il existe des solutions efficaces : le list crawling (extraction en masse) et l’extraction de sous-pages.
Aperçu du List Crawling et de l’Extraction de Sous-pages
| Outil | Facilité d'utilisation | Qualité des données | Cas d'usage idéal |
|---|---|---|---|
| List Crawling | ★★ | ★★★ | Sites web volumineux |
| Extraction de Sous-pages | ★★★★★ | ★★★★ | Extraction légère, formats de données spécifiques |
Comprendre le List Crawling
Qu’est-ce que le List Crawling ?
Le list crawling, ou extraction en masse, c’est une technique d’extraction web qui consiste à récupérer des données à partir d’une liste d’URLs. Pour démarrer, il faut d’abord constituer cette fameuse liste d’URLs, souvent à l’aide d’un autre extracteur. La réussite du list crawling dépend donc beaucoup de la qualité de cette liste de départ. Si les URLs mènent à des pages au format différent, les résultats risquent d’être incohérents et le traitement prendra plus de temps. Cette méthode est parfaite pour les boîtes, chercheurs ou analystes qui ont besoin de collecter de gros volumes de données structurées et homogènes. Par contre, il faut souvent retravailler et organiser les données à la main pour qu’elles soient vraiment exploitables.
Comment ça marche ?

Le list crawling se déroule généralement en plusieurs étapes :
- Préparer une liste d’URLs : On commence par rassembler tous les liens des pages à extraire.
- Envoyer des requêtes HTTP : Le système va ensuite envoyer des requêtes à chaque URL pour récupérer le contenu HTML.
- Extraire les données : On utilise des techniques de parsing comme BeautifulSoup, XPath ou les regex pour extraire les infos voulues (texte, images, liens, etc.).
- Stocker les données : Enfin, on organise et sauvegarde les données extraites dans une base de données ou un tableur pour pouvoir les analyser plus tard.
Une fois les données récupérées, il est crucial de les nettoyer et de les analyser avec des méthodes comme les stats descriptives, l’analyse de séries temporelles, la corrélation ou le clustering. L’IA peut vraiment accélérer tout ça, en automatisant les tâches et en boostant la qualité des données.
Testez la fonction Bulk Scraping de l’Extracteur Web IA Thunderbit pour une expérience simplifiée.
Outils recommandés
-
- Points forts : Prise en main rapide, parsing flexible, fonctionnalités avancées
- Points faibles : Nécessite une utilisation locale et dépend du navigateur
- Idéal pour : Collecte de données de qualité, priorité à la précision
- Scrapy
- Points forts : Puissant, très personnalisable, parfait pour l’extraction à grande échelle
- Points faibles : Courbe d’apprentissage raide, demande des compétences en dev
- Idéal pour : Projets de collecte de données massifs
- Beautiful Soup
- Points forts : Simple à utiliser, documentation complète, parsing flexible
- Points faibles : Performances moyennes, pas d’asynchrone
- Idéal pour : Petits projets d’extraction, analyse de données
- Selenium
- Points forts : Gère les pages dynamiques, simule le comportement utilisateur
- Points faibles : Lent à l’exécution, gourmand en ressources
- Idéal pour : Extraction sur des pages générées en JavaScript
Zoom sur l’Extraction de Sous-pages

Qu’est-ce que l’Extraction de Sous-pages ?
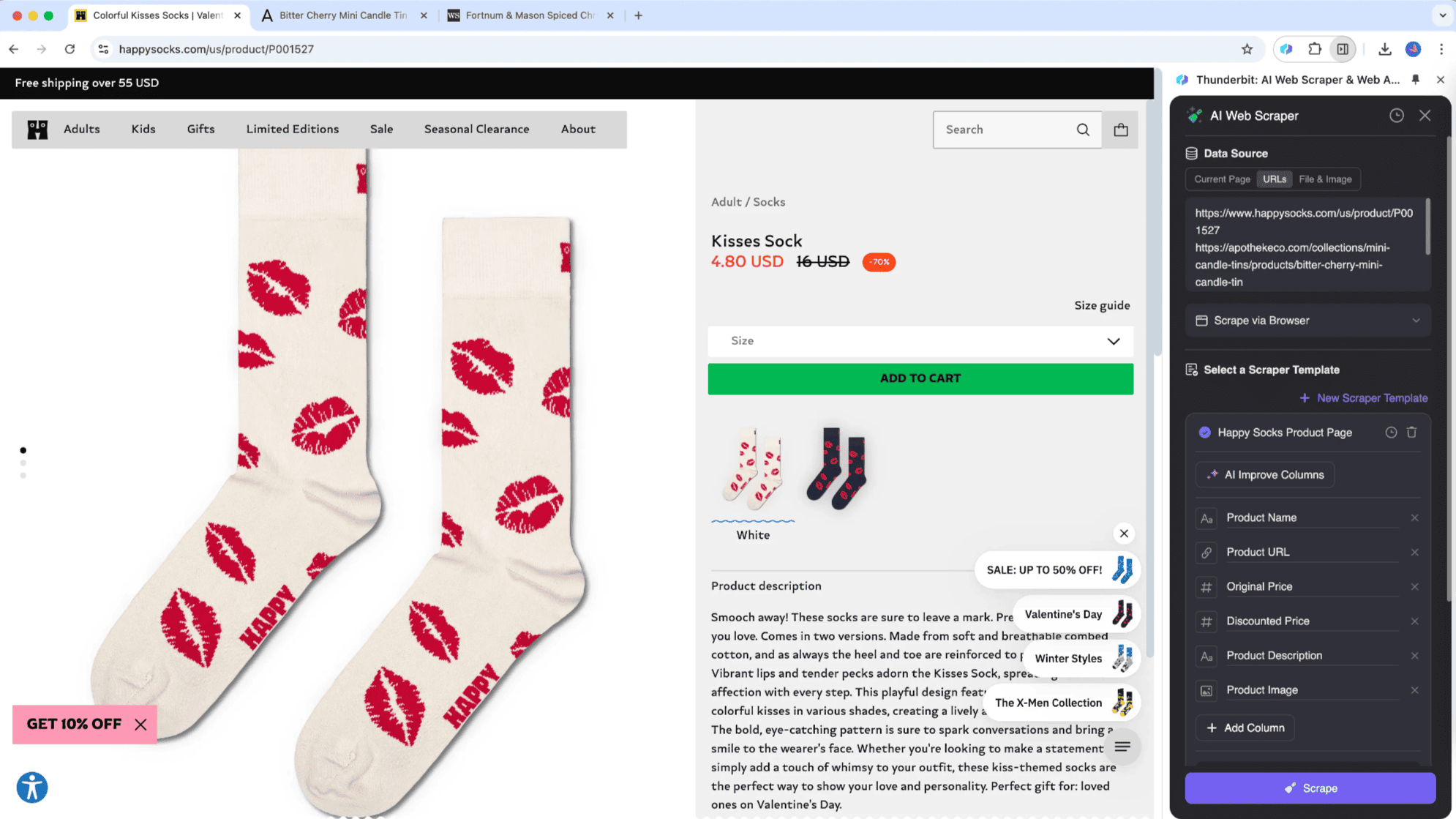
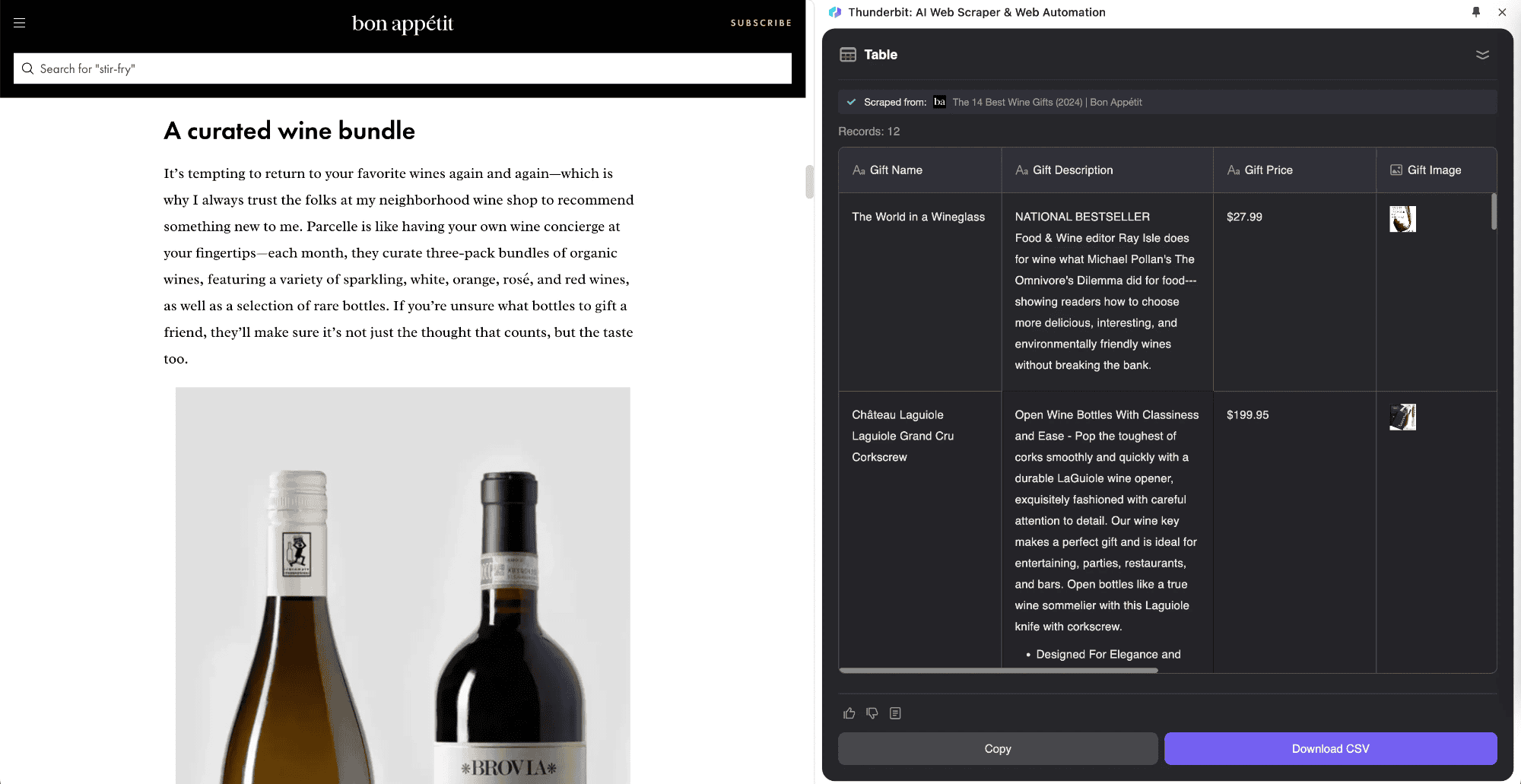
L’extraction de sous-pages, c’est une méthode qui permet de récupérer des données listées sur une page principale, puis de fusionner les infos des sous-pages dans un tableau centralisé. Thunderbit a lancé ce procédé innovant grâce à l’IA de son Extracteur Web IA. Cette approche est idéale pour les sites avec des sous-pages, comme les fiches produits, les blogs ou les annuaires. Son gros avantage : collecter et organiser intelligemment les données issues de ces sous-pages dans un seul tableau.
Par exemple, si tu consultes un article « Bourse aujourd’hui » et que tu veux extraire la liste des cotations, tu peux utiliser . Tu définis ton tableau, et l’outil va extraire automatiquement les cotations, ouvrir les pages de détails en temps réel et fusionner les données dans ton tableau principal. Tu peux ainsi enregistrer des infos précises tout en suivant l’actu. L’Extracteur Web IA de Thunderbit s’adapte à différents types de pages, là où les outils classiques montrent vite leurs limites.
Pourquoi l’utiliser ?
Thunderbit Extracteur Web IA regorge de fonctionnalités qui optimisent la collecte et la fiabilité des données.
Extraction intelligente des données
Thunderbit Extracteur Web IA s’appuie sur l’IA pour extraire les données de façon intelligente, en s’adaptant automatiquement aux changements de structure des pages web. Les utilisateurs peuvent simplement décrire les données recherchées en langage courant, et le système génère les règles d’extraction. Cette méthode réduit la complexité technique et améliore la précision, rendant l’outil accessible même aux débutants. Thunderbit gère différents types de données : texte, liens, images, etc., pour répondre à tous les besoins.
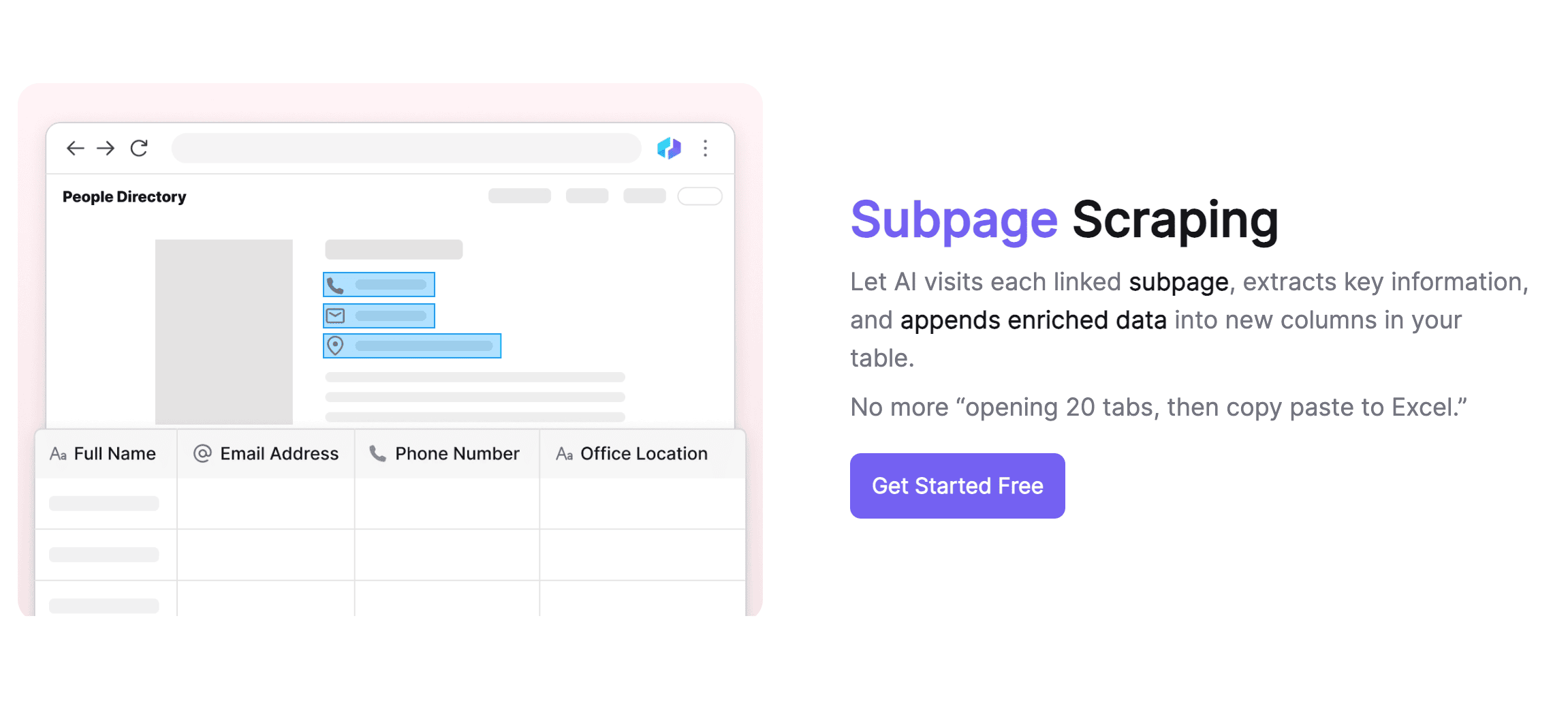
Gestion intelligente des sous-pages
Thunderbit est particulièrement performant pour gérer les sous-pages. Il repère et accède automatiquement aux sous-pages, en utilisant un seul modèle pour différents formats. L’IA s’adapte aux changements de structure, ce qui évite aux utilisateurs de se prendre la tête avec les variations entre sous-pages. Thunderbit fusionne automatiquement le contenu des sous-pages dans le tableau principal, ce qui simplifie l’organisation des infos. Il se démarque aussi par la qualité des données, agissant comme un assistant IA pour nettoyer, formater et étiqueter les données de façon automatisée.
Gestion efficace des données
Thunderbit propose des fonctionnalités avancées pour gérer les données, avec plusieurs formats d’export et des intégrations vers des plateformes comme Google Sheets, Airtable ou Notion. Tu peux lier un modèle d’extraction à une feuille Google Sheets pour centraliser tes données, ou à Notion pour organiser tes infos dans une base de données. Ces options flexibles permettent d’adapter le stockage à tes besoins. L’étiquetage et la classification automatiques s’ajustent aussi aux formats des plateformes de gestion, rendant la suite du traitement plus fluide.
Modèles prédéfinis pratiques
Pour gagner du temps, Thunderbit propose plein de modèles prêts à l’emploi. Ils couvrent la collecte de données e-commerce (, ), l’immobilier (), l’analyse de réseaux sociaux (, ), ou encore la collecte d’informations d’entreprises (sites web, annuaires pros). Ces modèles garantissent un vrai gain de temps et une collecte homogène et fiable.
Mise en œuvre étape par étape
Mettre en place l’Extraction de Sous-pages
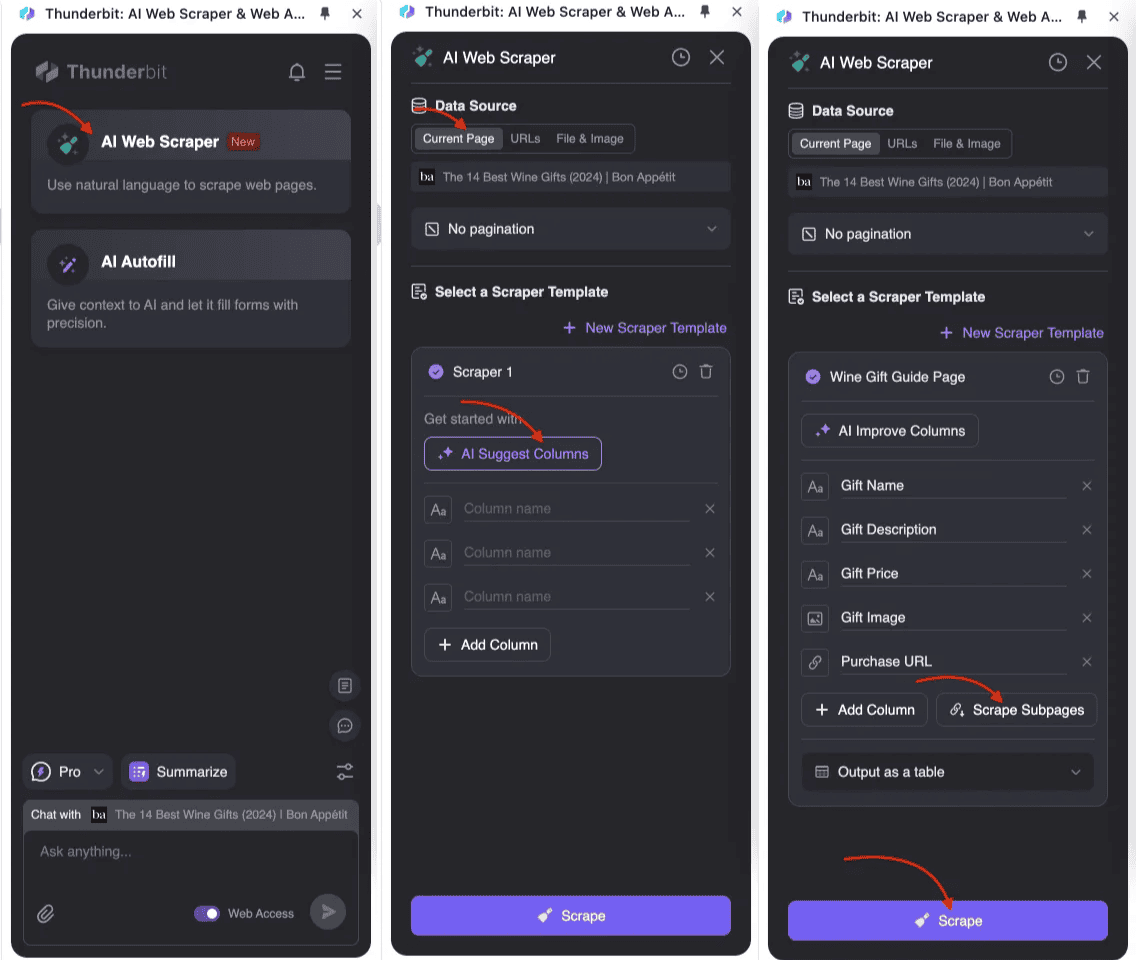
- : Lance Thunderbit Extracteur Web IA et crée un nouveau modèle d’extraction.
- Définir la structure de ton tableau principal : Dans les paramètres, ajoute les champs à collecter (titre, prix, description, etc.). Pour les données issues des sous-pages, crée les champs correspondants et active l’extraction de sous-pages.
- Lancer l’extracteur : Thunderbit extrait d’abord les données de la page principale, puis visite automatiquement chaque sous-page pour en extraire les infos et les fusionner dans le tableau principal. Tout le processus est géré par l’IA, sans prise de tête ni code compliqué.
Mettre en place le List Crawling
Pour les développeurs, il existe plusieurs langages et outils pour faire du list crawling. Python est le plus populaire grâce à sa simplicité et à la richesse de ses bibliothèques. Voici un exemple de script Python utilisant requests et BeautifulSoup pour extraire des données :
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4def scrape_urls(urls):
5 data = []
6 for url in urls:
7 response = requests.get(url)
8 soup = BeautifulSoup(response.text, 'html.parser')
9 titles = soup.find_all('h2', class_='product-title')
10 prices = soup.find_all('span', class_='product-price')
11 for title, price in zip(titles, prices):
12 data.append({
13 'title': title.get_text(),
14 'price': price.get_text()
15 })
16 return pd.DataFrame(data)
17# Exemple d’utilisation
18urls = ['<http://example.com/product1>', '<http://example.com/product2>']
19data_frame = scrape_urls(urls)
20print(data_frame)Conclusion
Aujourd’hui, la donnée est au centre de la stratégie des entreprises. Ceux qui savent la collecter et l’analyser efficacement prennent une vraie avance. Les données permettent de mieux comprendre le marché et les besoins des clients, offrant des infos précieuses pour le développement produit et le marketing. Pourtant, rassembler et organiser efficacement la masse de données éparpillées sur le web reste un sacré défi.
Avec des outils comme Thunderbit, les entreprises n’ont plus à se soucier de la collecte de données. C’est comme avoir un assistant fiable qui t’aide à dénicher les infos clés dans des montagnes de données, pour prendre des décisions plus éclairées. Grâce à ses capacités intelligentes de collecte et de traitement, il devient facile d’accéder à des infos sur la concurrence, les tendances du marché, les avis clients, et bien plus encore.
Thunderbit ne se contente pas de collecter les données : il les nettoie, les structure et génère des rapports clairs pour révéler rapidement des insights cachés. Pour les entreprises qui doivent surveiller régulièrement leur marché, l’automatisation de la collecte est un vrai atout et un gain de temps énorme.
À l’ère de la donnée, avoir un outil comme Thunderbit, c’est clairement un avantage. Il booste l’efficacité de la collecte et accompagne la transformation digitale des entreprises. Alors que la donnée devient centrale dans la prise de décision, des solutions intelligentes comme Thunderbit vont vite devenir des alliés incontournables pour rester dans la course.
FAQ
-
Qu’est-ce que Thunderbit ? est une extension Chrome pensée pour automatiser les tâches web des pros. Elle propose des fonctionnalités comme l’Extracteur Web IA, le Presse-papiers IA et le Chat Web IA pour extraire des données, remplir des formulaires et grâce à l’IA. C’est un vrai outil de productivité qui fait gagner du temps et simplifie les tâches répétitives en ligne.
-
Comment fonctionne l’Extracteur Web IA de Thunderbit ? L’Extracteur Web IA de Thunderbit utilise l’intelligence artificielle pour extraire des données structurées depuis les sites web. L’utilisateur peut cliquer sur « Suggérer des colonnes IA » pour que l’IA propose une méthode d’extraction adaptée au site, puis sur « Extraire » pour collecter les données. Il gère les données de n’importe quel site, PDF ou image en seulement deux clics.
-
Quelle est la différence entre list crawling et extraction de sous-pages ? Le list crawling (extraction en masse) consiste à extraire des données à partir d’une liste d’URLs, idéal pour les sites volumineux. L’extraction de sous-pages, elle, récupère les données d’une page principale et de ses sous-pages, puis fusionne le tout dans un tableau centralisé. L’Extracteur Web IA de Thunderbit excelle dans les deux méthodes, avec une extraction et une gestion intelligentes des données.
-
Thunderbit est-il accessible aux non-développeurs ? Bien sûr ! Thunderbit a été conçu pour être simple à utiliser, même sans compétences techniques. Grâce à l’IA, il suffit de décrire les données recherchées en langage courant, et le système génère les règles d’extraction, rendant l’outil accessible à tous.
-
Quels types de données Thunderbit peut-il gérer ? Thunderbit prend en charge plein de types de données : texte, liens, images, etc. Il s’adapte à tous les besoins, que ce soit pour l’e-commerce, l’immobilier, l’analyse des réseaux sociaux ou la collecte d’informations professionnelles.
-
Comment démarrer avec Thunderbit ? Pour commencer, il suffit de télécharger l’extension Chrome Thunderbit depuis la . Une fois installée, explore ses fonctionnalités comme l’Extracteur Web IA, le Presse-papiers IA ou le Chat Web IA pour booster ta productivité en ligne.
-
Thunderbit propose-t-il des modèles prédéfinis ? Oui, Thunderbit met à disposition de nombreux pour faciliter la collecte de données. Ces modèles couvrent l’e-commerce, l’immobilier, les réseaux sociaux et la veille professionnelle, garantissant gain de temps et cohérence des données.
-
Comment Thunderbit garantit-il la qualité des données ? Thunderbit utilise l’IA pour extraire et traiter les données de façon intelligente, en s’adaptant automatiquement aux changements de structure des pages. Il propose aussi des fonctions de nettoyage et de formatage, jouant le rôle d’assistant IA pour automatiser les tâches répétitives et améliorer la qualité des données.
-
Cas d’usage de l’extraction web Les ont plein d’applications concrètes. Par exemple, tu peux pour tes études de marché, ou pour l’analyse documentaire. Beaucoup d’entreprises ont besoin de pour les analyser. Grâce à l’IA, il est maintenant possible de sans écrire de code compliqué. Pour l’analyse des réseaux sociaux, tu peux utiliser des outils spécialisés comme les ou les pour collecter des données utiles à tes campagnes marketing.
Pour aller plus loin :