

Le web contemporain est devenu un terrain de jeu pour qui aime les données — bien loin de l’époque où un « clic droit, enregistrer sous » réglait l’affaire. Les sites, désormais, tiennent du labyrinthe : contenus dynamiques, liens dissimulés, pop-ups en cascade et menus déroulants à n’en plus finir. Quiconque a déjà voulu rassembler l’intégralité des fiches produits d’un site marchand, ou chaque annonce d’un portail immobilier, l’a constaté : les extracteurs web classiques ont atteint leurs limites. C’est là qu’interviennent les deep crawlers, cette génération d’outils taillée pour creuser en profondeur et remonter l’information utile, jusque dans les recoins les mieux dissimulés du web.
Mais de quoi parle-t-on, au juste, quand on évoque un deep crawler ? Pourquoi séduit-il autant, des commerciaux aux analystes ? Et par quel tour de force un outil comme Thunderbit rend-il le deep crawling aussi accessible qu’un double-clic, sans une ligne de code ? Voyons cela ensemble, des fondamentaux à l’impact business, pour saisir pourquoi les deep crawlers s’imposent comme l’arme secrète de l’extraction de données web.
Deep Crawler : le b.a.-ba
Utilisez l’IA pour extraire des données de n’importe quel site web Get Started Free
Extracteur web taillé pour naviguer et récolter des données sur des sites complexes, à plusieurs étages et souvent saturés de contenu dynamique : voilà ce qu’est un deep crawler. Quand les crawlers ordinaires survolent la page d’accueil et ramassent ce qui traîne, lui suit les liens, explore chaque recoin et absorbe sans broncher listes paginées, contenus tapis derrière des onglets ou sections repliables.
Un crawler classique, imaginez-le comme un visiteur qui regarde les ouvrages en vitrine d’une bibliothèque. Le deep crawler, à l’inverse, arpente chaque rayon, ouvre chaque livre, lit les notes de bas de page et passe même la tête derrière la porte « réservé au personnel » — tant qu’elle n’est pas verrouillée.
Dans la pratique, un deep crawler est capable de :
- Naviguer à travers plusieurs niveaux d’un site (catégories, sous-catégories, pages de détails)
- Extraire du contenu dynamique chargé par JavaScript ou caché derrière des interactions utilisateur
- Gérer la pagination complexe et le scroll infini
- Suivre les liens internes pour ne rien laisser passer d’important
 Le volume mondial de données web ayant atteint 149 zettaoctets en 2024, et les sites gagnant sans cesse en complexité, les deep crawlers se sont rendus indispensables à qui veut dépasser le simple survol du web.
Le volume mondial de données web ayant atteint 149 zettaoctets en 2024, et les sites gagnant sans cesse en complexité, les deep crawlers se sont rendus indispensables à qui veut dépasser le simple survol du web.
Deep Crawler vs. Crawler classique : le match
Posons les choses clairement : qu’est-ce qui sépare vraiment un deep crawler d’un crawler « ordinaire » ?
Crawlers classiques : le survol express
Aller vite et ratisser large, telle est la vocation des extracteurs web classiques — ces « crawlers superficiels ». Ils balaient un site à toute allure, prélèvent ce qui s’affiche sur les pages principales, puis passent à la suite. Les moteurs de recherche procèdent ainsi : indexer le plus de pages possible, le plus vite possible, sans forcément fouiller chaque recoin.
Leurs limites :
- Ils passent à côté des données cachées derrière la navigation, les onglets ou les éléments dynamiques
- Ils peinent avec les sites bourrés de JavaScript ou les contenus qui se chargent après coup
- Ils ne gèrent pas les navigations à plusieurs étapes ni les structures de pages complexes
- Résultat : des jeux de données souvent incomplets ou fragmentés
Deep Crawlers : l’exploration en profondeur
Le deep crawler, lui, est pensé pour explorer un site de fond en comble : chaque lien utile suivi, chaque liste paginée cliquée, chaque sous-page, pop-up ou contenu dynamique fouillé pour en tirer l’information. Ici, ce n’est pas la vitesse qui prime, mais la précision et la complétude.
Ce qui fait la force des deep crawlers :
- Navigation avancée : suit les liens de manière récursive, gère les sites à plusieurs niveaux, contourne les impasses et les doublons (SEO-Wiki).
- Extraction de contenu dynamique : interagit avec le JavaScript, déplie les sections cachées, récupère les données qui surgissent après une action de l’utilisateur (Scientific Reports).
- Efficacité : cible les zones réellement utiles, évite les doublons et les données superflues, ne laisse rien d’important de côté (Medium).
- Données complètes : capture tous les niveaux d’info — listes principales, pages de détails, documents associés — en une seule passe.
Extraire tous les avis d’un produit, ou récupérer chaque annonce d’un portail immobilier avec les coordonnées de l’agent planquées sur une sous-page : qui a déjà tenté l’exercice a buté sur les limites des crawlers classiques. C’est là que le deep crawler creuse l’écart.
Comment les Deep Crawlers assurent une collecte complète et une navigation intelligente
Comment un deep crawler opère-t-il ? Tout tient à trois ressorts : le suivi des liens, la navigation récursive et une gestion fine du contenu dynamique.
Extraction sur sous-pages et navigation à plusieurs étages
La première page ne l’arrête pas. Un deep crawler va :
- Repérer les liens internes (du type « Voir les détails », « Page suivante », « En savoir plus »)
- Suivre ces liens vers les sous-pages, les vues détaillées ou même les pop-ups
- Extraire les données à chaque niveau, pour tout rassembler dans un tableau bien structuré
On désigne cette technique par « crawling récursif » ou « extraction multi-niveaux ». Elle excelle sur les sites où l’information se disperse d’une page à l’autre — listes de produits doublées de pages de détails, ou annuaires dont les coordonnées ne surgissent qu’après un clic.
Pagination et contenu dynamique : rien ne leur échappe
Boutons « Charger plus », scrolls infinis, onglets pilotés par JavaScript : les sites modernes adorent cacher l’information. Les deep crawlers, eux, savent :
- Détecter et actionner les contrôles de pagination
- Faire défiler ou interagir avec les éléments dynamiques
- Patienter que tout soit chargé avant d’extraire les données
D’où un jeu de données complet à l’arrivée, et non le seul contenu visible au premier chargement (Thunderbit Blog).
Suivi des liens profonds et extraction multi-couches
Ne pas laisser filer les données cachées ou imbriquées : voilà le vrai défi du deep crawling. Les deep crawlers mobilisent pour cela des algorithmes chargés de :
- Garder trace des liens déjà visités (afin d’éviter doublons et boucles)
- Prioriser les pages importantes (vues détaillées, documents à télécharger…)
- Traiter les cas particuliers (pop-ups, sections repliables, contenu chargé via AJAX)
Pour un professionnel, l’enjeu est de taille : un contact oublié ou une caractéristique produit manquante, c’est parfois une opportunité perdue ou une analyse faussée (Simplescraper).
Thunderbit : le deep crawling à la portée de tous grâce à l’IA
Disons-le sans détour : le deep crawling relevait autrefois du domaine réservé des développeurs chevronnés. Scripts maison à coder, cas tordus à gérer, tout à recommencer au moindre changement de site… Avec Thunderbit, le pari est inverse : ouvrir le deep crawling à tous, sans la moindre ligne de code.
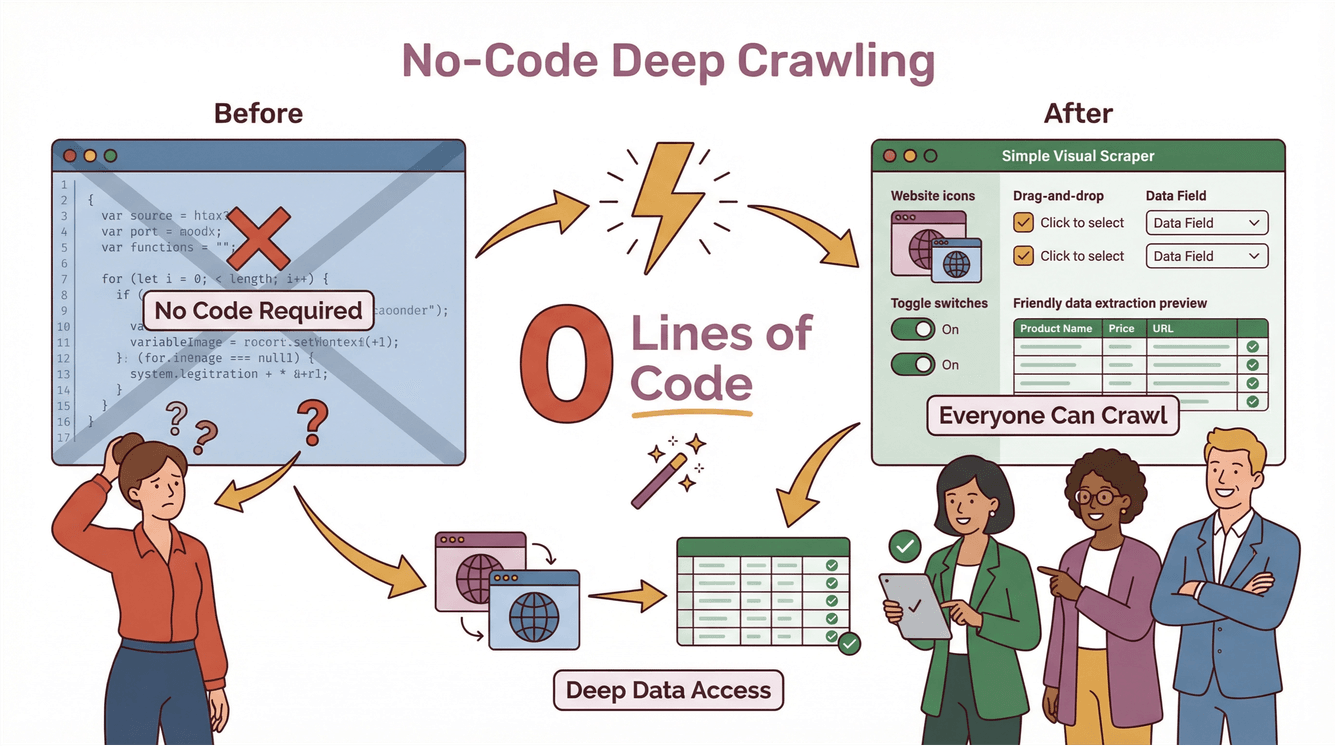
Les points forts du Deep Crawler Thunderbit
Voici comment Thunderbit vous facilite la tâche :
- AI Suggest Fields : un clic sur « Suggérer les champs par IA » et l’IA analyse la page, recommande les meilleures colonnes à extraire et génère même un prompt pour chacune.
- Extraction sur sous-pages : envie d’aller plus loin ? Thunderbit visite chaque sous-page (détails produits, profils d’agents, onglets d’avis…) et enrichit votre tableau de l’ensemble des données.
- Gestion du contenu dynamique : pagination, scroll infini, éléments dynamiques — Thunderbit s’en occupe sans la moindre configuration.
- Processus sans code en deux étapes : décrivez ce que vous voulez, cliquez sur « Extraire », et Thunderbit prend le relais. Vos données partent ensuite vers Excel, Google Sheets, Notion ou Airtable — sans frais cachés ni limites (Thunderbit Blog).
Essayez gratuitement le Deep Crawler Thunderbit
Exemple concret : deep crawling avec Thunderbit
Mettons que vous vouliez extraire toutes les annonces immobilières d’un site, coordonnées des agents cachées sur des sous-pages comprises :
- Ouvrez la page des annonces dans Chrome.
- Cliquez sur l’extension Thunderbit.
- Utilisez « Suggérer les champs par IA » pour que Thunderbit vous propose des colonnes comme « Titre de l’annonce », « Prix », « Adresse » et « Lien vers l’agent ».
- Cliquez sur « Extraire ». Thunderbit récupère toutes les annonces principales.
- Cliquez sur « Extraire les sous-pages ». Thunderbit parcourt chaque profil d’agent, en tire numéros de téléphone, emails, etc., et fusionne le tout dans votre tableau principal.
- Exportez vos données vers Google Sheets ou Excel — prêtes à l’emploi pour vos équipes.
Aucun code, aucun modèle à bidouiller, aucune prise de tête. Et si le site évolue, l’IA se réadapte toute seule (Thunderbit Docs).
Les bénéfices business : pourquoi les deep crawlers font la différence
Les deep crawlers séduisent, soit — mais que gagne votre entreprise, concrètement ? C’est ici que l’affaire devient intéressante.
Des insights précieux pour l’e-commerce, l’immobilier et la veille concurrentielle
Pour les équipes commerciales et marketing, le deep crawler tient de la mine d’or. Il permet de :
- Extraire chaque produit, prix et avis sur les sites e-commerce — même quand l’information s’enterre sous plusieurs couches ou onglets
- Agréger les annonces immobilières (y compris les informations cachées sur les agents ou les détails des biens)
- Surveiller les sites concurrents pour repérer les nouveaux produits, les changements de prix ou les tendances du marché (GetMonetizely)
- Constituer des listes de prospects enrichies en capturant les coordonnées sur des annuaires, sites d’événements ou portails spécialisés
Le deep crawling ne vous fournit pas seulement davantage de données : il vous livre des données plus pertinentes et directement exploitables, de celles qui font avancer une entreprise.
Deep scraping pour la veille concurrentielle
Imaginez une équipe commerciale décidée à cibler les entreprises qui viennent de lancer un produit. Un deep crawler saura :
- Passer au crible les sites concurrents à la recherche de nouvelles pages produits
- Suivre les liens vers les communiqués de presse ou les actus investisseurs
- Extraire les infos clés (dates de lancement, prix, fonctionnalités)
- Verser le tout dans votre CRM ou vos outils d’analyse
Au bout du compte : des décisions plus rapides, mieux informées — et une longueur d’avance sur ceux qui se cantonnent au scraping de surface.
Conformité et bonnes pratiques : deep crawling responsable
À grand pouvoir d’extraction, grande responsabilité. Les deep crawlers ouvrent l’accès à une masse de données, mais ce n’est pas un blanc-seing pour tout aspirer sans discernement. Quelques repères :
Données perso et droits d’auteur
- Respectez les conditions d’utilisation des sites : nombre d’entre eux détaillent dans leurs CGU ce qui est permis. Passer outre peut vous exposer à des ennuis juridiques (Apify Blog).
- N’extrayez pas de données personnelles ou confidentielles sans autorisation explicite.
- Prudence avec le droit d’auteur : ne republiez ni ne revendez de contenu extrait sans en avoir vérifié les droits.
Extraction responsable
- Espacez vos requêtes : n’inondez pas les sites de demandes en rafale.
- Consultez le fichier robots.txt : rien d’obligatoire sur le plan légal, mais une marque de respect.
- Restez informé de la loi : des cadres comme le RGPD ou le CCPA peuvent influer sur ce que vous collectez et sur l’usage que vous en faites (Octoparse).
Pour approfondir, jetez un œil à Le scraping web est-il légal en 2025 ?.
Choisir le bon Deep Crawler pour votre équipe
Voir les tarifs Thunderbit Deep crawling abordable pour toutes les équipes. Get Started Free
Sur quels critères arrêter votre choix ? Voici les miens :
- Facilité d’utilisation : même les profils non techniques s’en sortent-ils sans peine ? (Thunderbit : oui.)
- Scalabilité : l’outil encaisse-t-il les gros sites, les milliers de pages et le contenu dynamique ?
- Outils de conformité : aide-t-il à rester dans les clous côté légalité ?
- Intégration : peut-on exporter les données vers les outils déjà en place (Excel, Sheets, Notion, Airtable) ?
- Maintenance : s’adapte-t-il seul aux changements de sites, ou faut-il rafistoler des scripts chaque semaine ?
Thunderbit a justement été conçu pour cocher toutes ces cases. Adopté par plus de 30 000 utilisateurs dans le monde, du freelance à la grande entreprise, il ouvre la porte aux petites équipes dès 15 $/mois (environ 14 €/mois).
Commencez le deep crawling avec Thunderbit
À retenir : le deep crawling, un atout clé pour la data en entreprise
L’essentiel en quelques points :
- Les deep crawlers sont devenus indispensables pour extraire des données complètes et fiables sur les sites web complexes et dynamiques d’aujourd’hui.
- Ils vont bien plus loin que les crawlers classiques en gérant la navigation multi-niveaux, le contenu dynamique et les infos cachées.
- Les équipes business s’en emparent pour dégager des insights, dynamiser les ventes, surveiller la concurrence et accélérer la prise de décision.
- La conformité reste la base : extrayez toujours de façon responsable, respectez la vie privée et les règles du secteur.
- Thunderbit rend le deep crawling accessible à tous, grâce à l’IA, une interface sans code et l’export en un clic.
Prêt à explorer le web en profondeur ? Téléchargez l’extension Chrome Thunderbit et jugez par vous-même de la simplicité du deep crawling. Pour d’autres astuces, faites un tour sur le Blog Thunderbit : guides, bonnes pratiques et nouveautés sur l’extraction web portée par l’IA.
FAQ
1. C’est quoi un deep crawler et en quoi diffère-t-il d’un crawler web classique ?
Un deep crawler est un extracteur web qui navigue à travers toutes les couches d’un site et extrait les données des sous-pages, du contenu dynamique et des sections cachées. Contrairement aux crawlers classiques, qui restent en surface, les deep crawlers garantissent une collecte complète en suivant les liens et en gérant les structures complexes.
2. Pourquoi les entreprises ont-elles besoin de deep crawlers en 2025 ?
Les sites web sont plus complexes que jamais, avec des infos souvent reléguées derrière la navigation, des onglets ou des éléments dynamiques. Les deep crawlers permettent aux entreprises d’extraire des jeux de données complets pour la vente, le marketing, la veille ou la recherche concurrentielle — ce que les extracteurs classiques ne peuvent pas offrir.
3. Comment Thunderbit facilite-t-il le deep crawling pour les non-techniciens ?
Thunderbit s’appuie sur l’IA pour suggérer les champs, gérer l’extraction sur sous-pages et le contenu dynamique — le tout via une interface simple et sans code. Il suffit de décrire ce que vous voulez, de cliquer sur « Extraire » et d’exporter les résultats vers vos outils préférés.
4. Quelles questions de conformité se poser avec un deep crawler ?
Respectez toujours les conditions d’utilisation des sites, évitez d’extraire des données personnelles ou confidentielles sans autorisation, et tenez-vous au courant de lois comme le RGPD ou le CCPA. Une extraction responsable et un usage éthique des données sont essentiels pour éviter les ennuis juridiques.
5. Les deep crawlers peuvent-ils aider mes équipes commerciale et marketing à performer ?
Sans hésiter. Les deep crawlers donnent accès à des données plus riches et exploitables sur l’e-commerce, l’immobilier ou la concurrence — pour générer des leads, analyser le marché et accélérer la prise de décision. Avec des outils comme Thunderbit, même les équipes non techniques accèdent aux insights qui font la différence.
Essayez l’AI Deep Crawler avec Thunderbit Get Started Free
Pour aller plus loin




